数据科学手把手:碳中和下的二氧化碳排放分析 ⛵
 气候是全球性的话题,本文基于owid co2数据集,分析了世界各地的二氧化碳排放量,并将二氧化碳排放的主要国家以及二氧化碳排放来源进行了可视化。
气候是全球性的话题,本文基于owid co2数据集,分析了世界各地的二氧化碳排放量,并将二氧化碳排放的主要国家以及二氧化碳排放来源进行了可视化。

💡 作者:韩信子@ShowMeAI
📘 数据分析实战系列:https://www.showmeai.tech/tutorials/40
📘 本文地址:https://www.showmeai.tech/article-detail/322
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容
ShowMeAI在本篇内容中整理了一个数据科学学习的基本项目,我们会分析世界各地的二氧化碳排放量,我们可以看到二氧化碳排放的主要国家以及导致二氧化碳排放的不同来源。这也是『碳中和』大环境下大家关心的主题之一。

大家可以使用本地的jupyter notebook来运行我们下述代码,也可以使用 Google Colab 或 Kaggle notebook来运行。本项目使用的 🏆owid co2 data数据集,大家可以通过ShowMeAI的百度网盘下载获取。
🏆 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [23]碳中和背景下的二氧化碳排放数据分析 『owid co2 data数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
💡 数据处理

数据分析处理涉及的工具和技能,欢迎大家查阅ShowMeAI对应的教程和工具速查表,快学快用。
首先,我们将导入库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
读取数据:
dataset = pd.read_csv('owid-co2-data.csv')
查看数据:
有两个核心的函数可以帮助我们查看数据基本形态:
dataset.head() :显示数据集的前5行。 如果您想查看更多行,调整括号中数字即可。例如dataset.head(10)查看前10行
dataset.shape :显示数据集的行数和列数
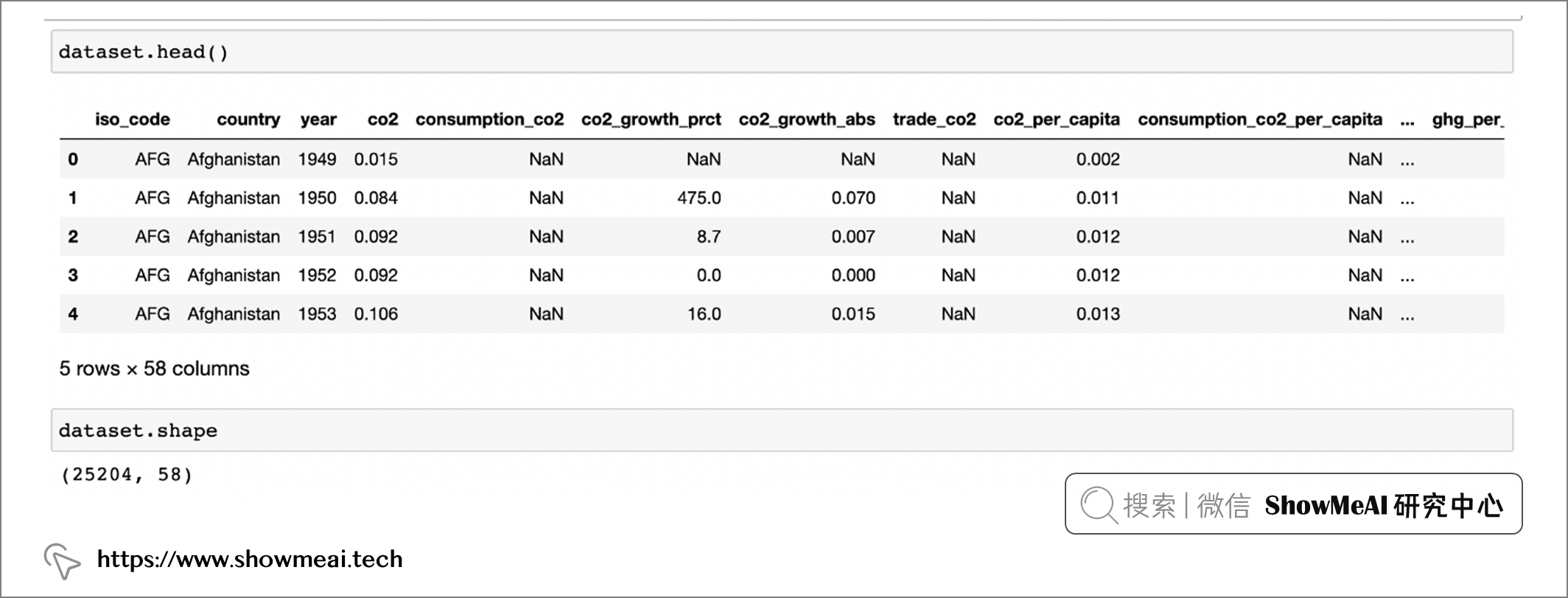
我们本次分析的数据集有 25204 行和 58 列。
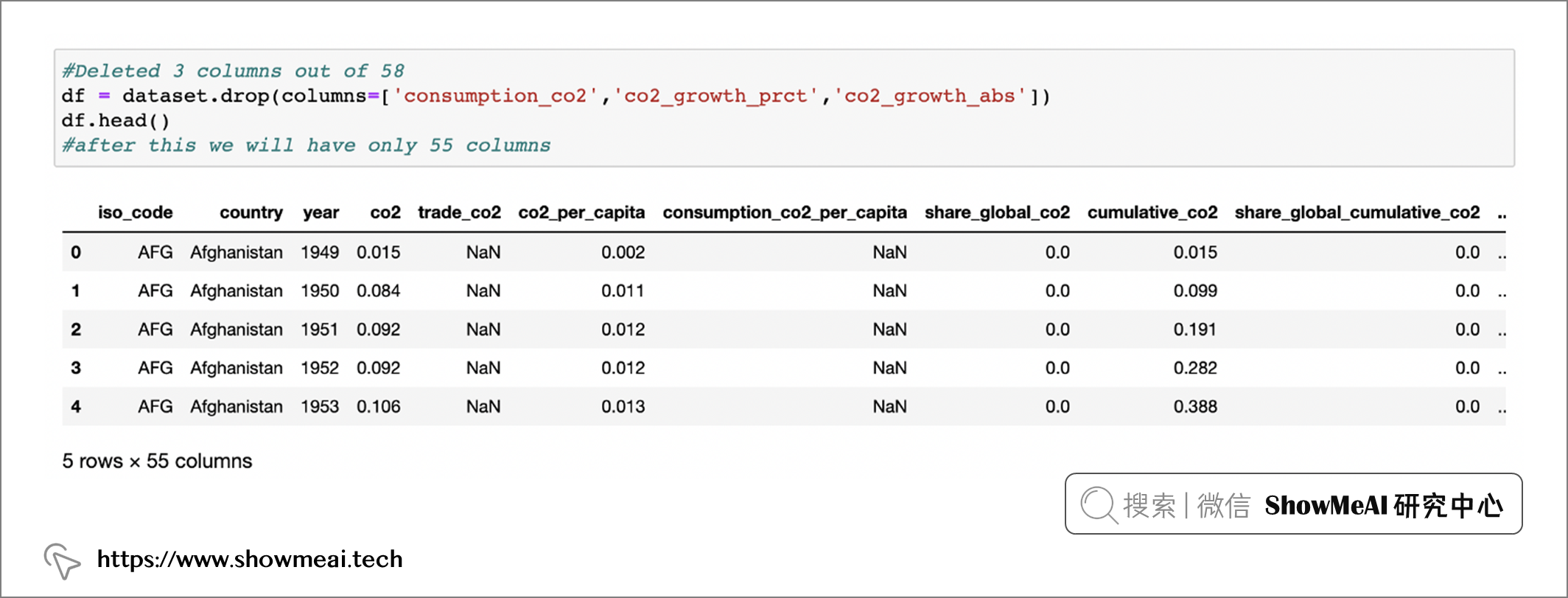
删除列:
我们可以做一些数据处理,比如删除一些数据分析中不适用的字段/列。
df = dataset.drop(columns=[ 'consumption co2','co2 growth _prect','co2 growth_abs' ])
df.head()
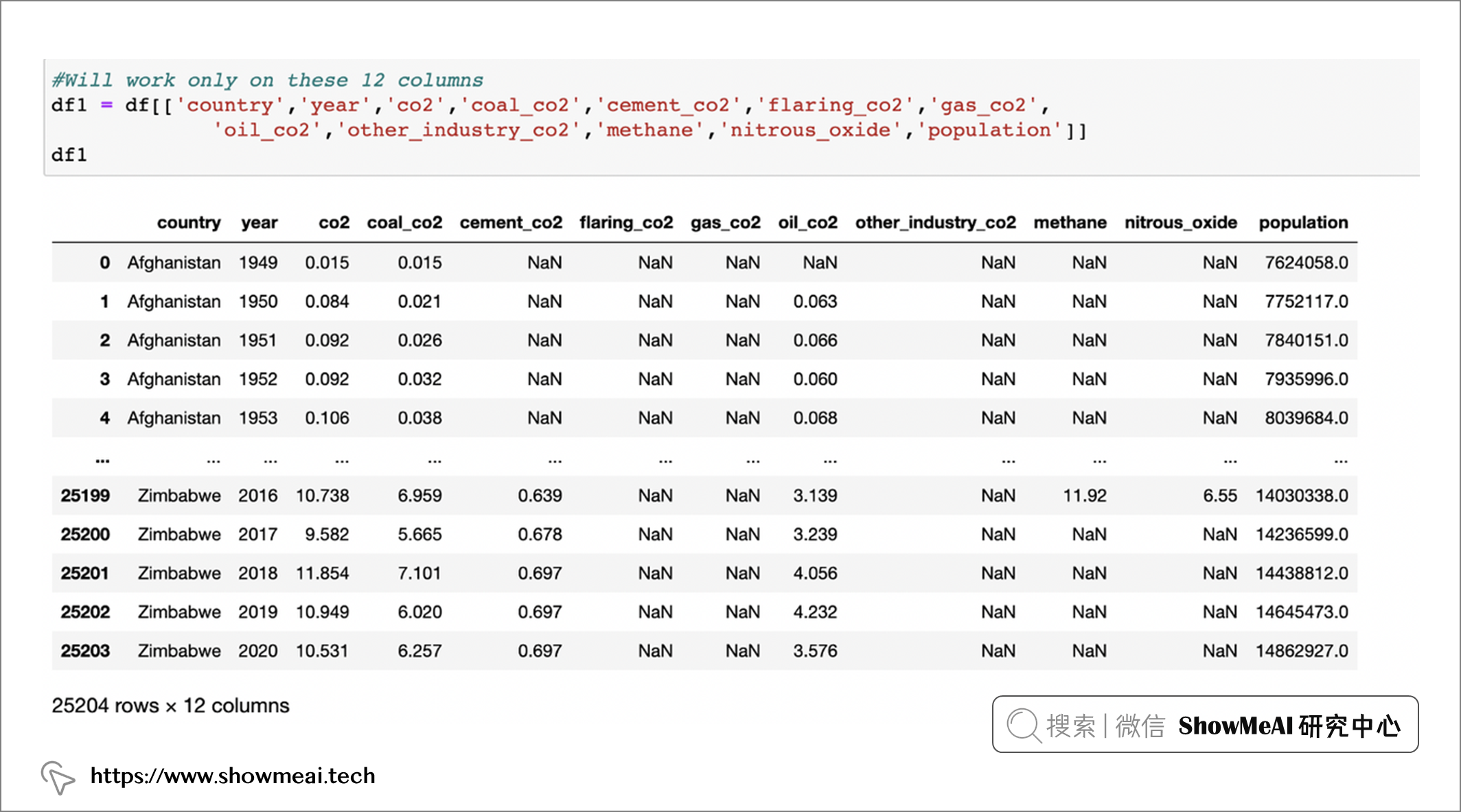
熟悉pandas的同学也知道,我们也可以直接通过字段名选择需要分析的字段,如下代码所示:
df1 = df[['country', 'year','co2','coal_co2','cement _co2', 'flaring_co2','gas_co2','oil _co2', 'other industry co2','methane', 'nitrous_oxide', 'population' ]]
df1
我们可以通过pandas的条件选择来选取数据子集:
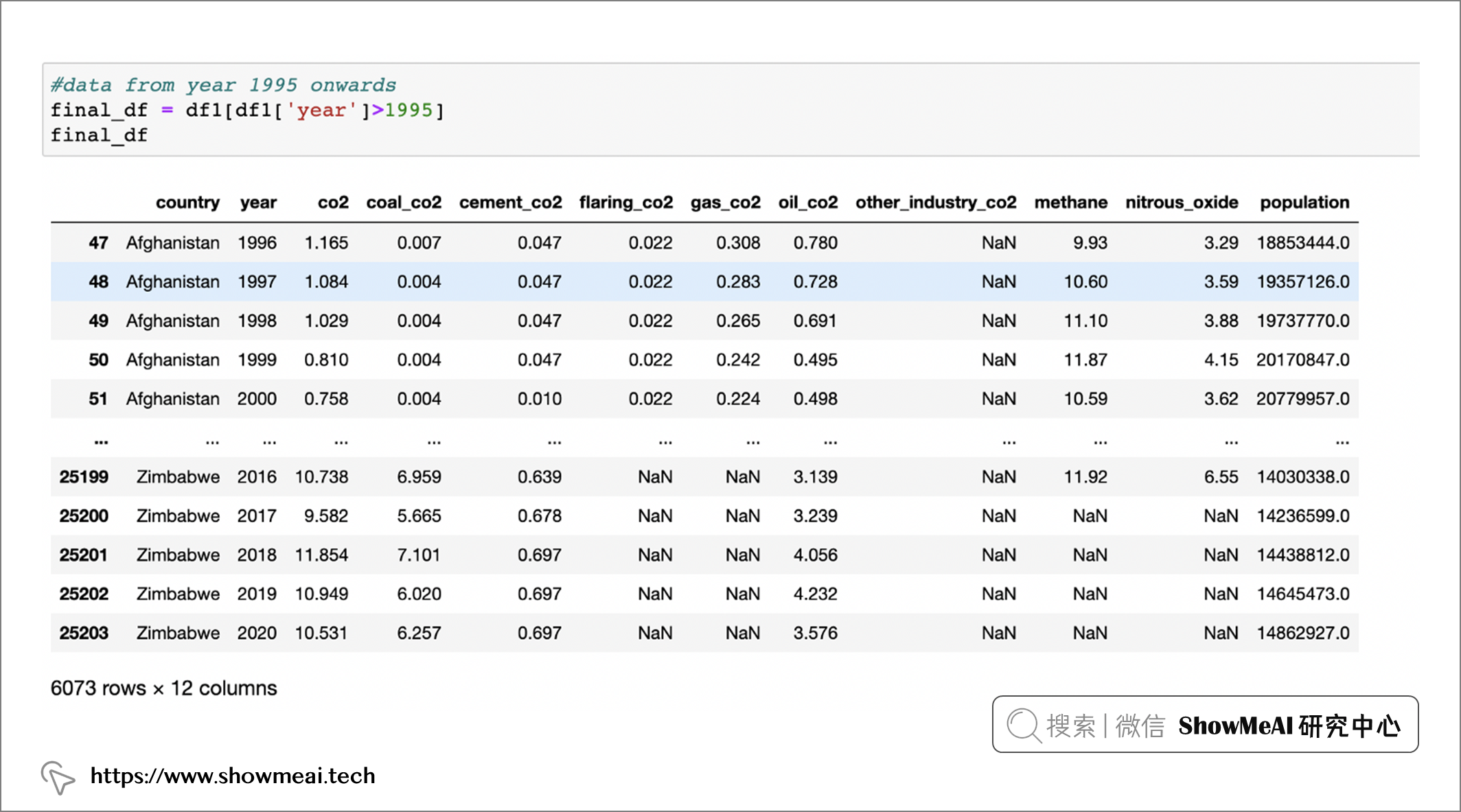
final df = df1[df1['year' ]>1995]
final df
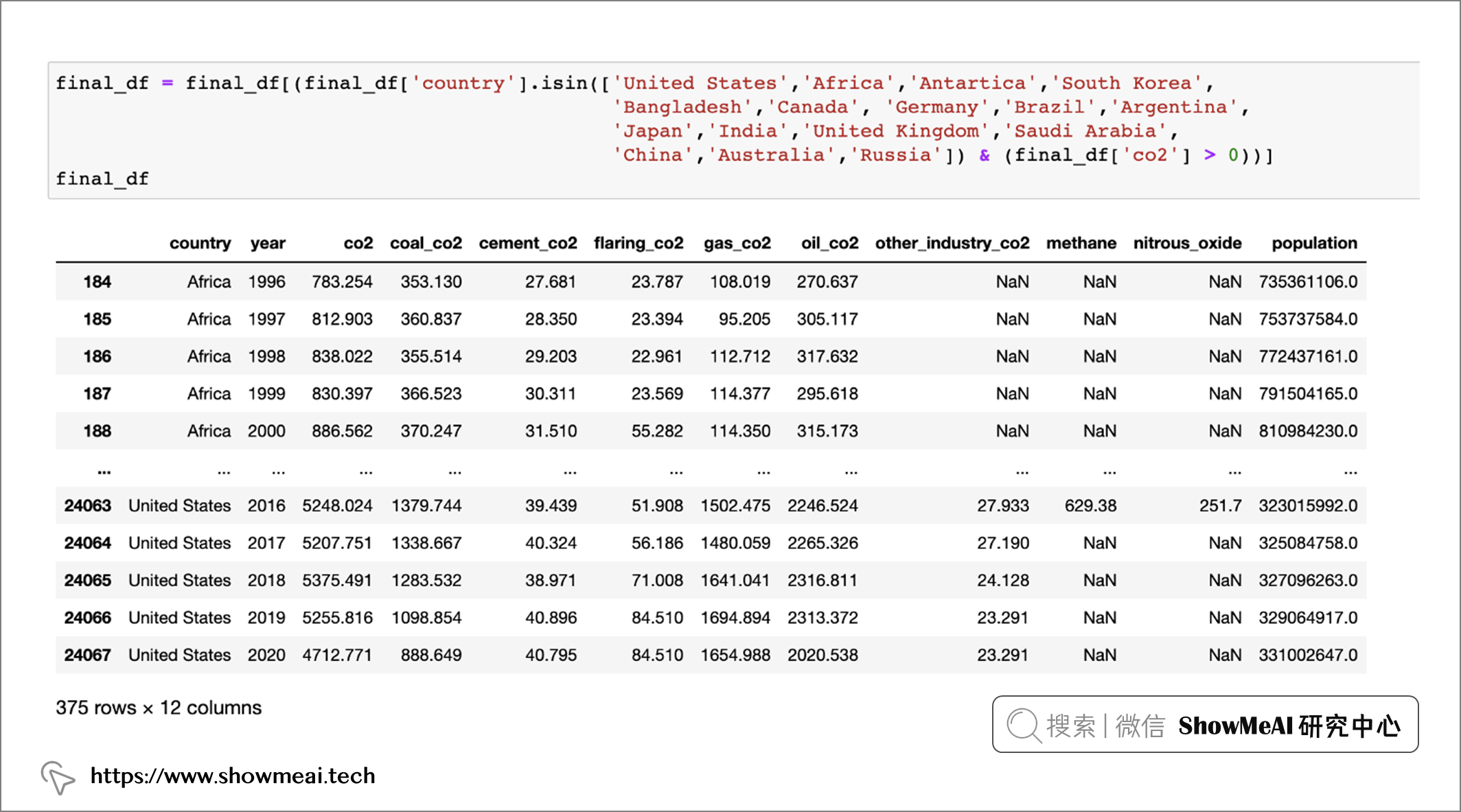
可以通过isin等函数来框定类别型字段的取值,例如下述代码:
final_df = final_df[(final_df['country'].isin(['United States', 'Africa', 'Antartica','South Korea', 'Bangladesh', 'Canada', 'Germany', 'Brazil', 'Argentina','Japan', 'India', 'United Kingdom', 'Saudi Arabia', 'China', 'Australia','Russia']) & (final_df['co2'] > 0))]
final_df
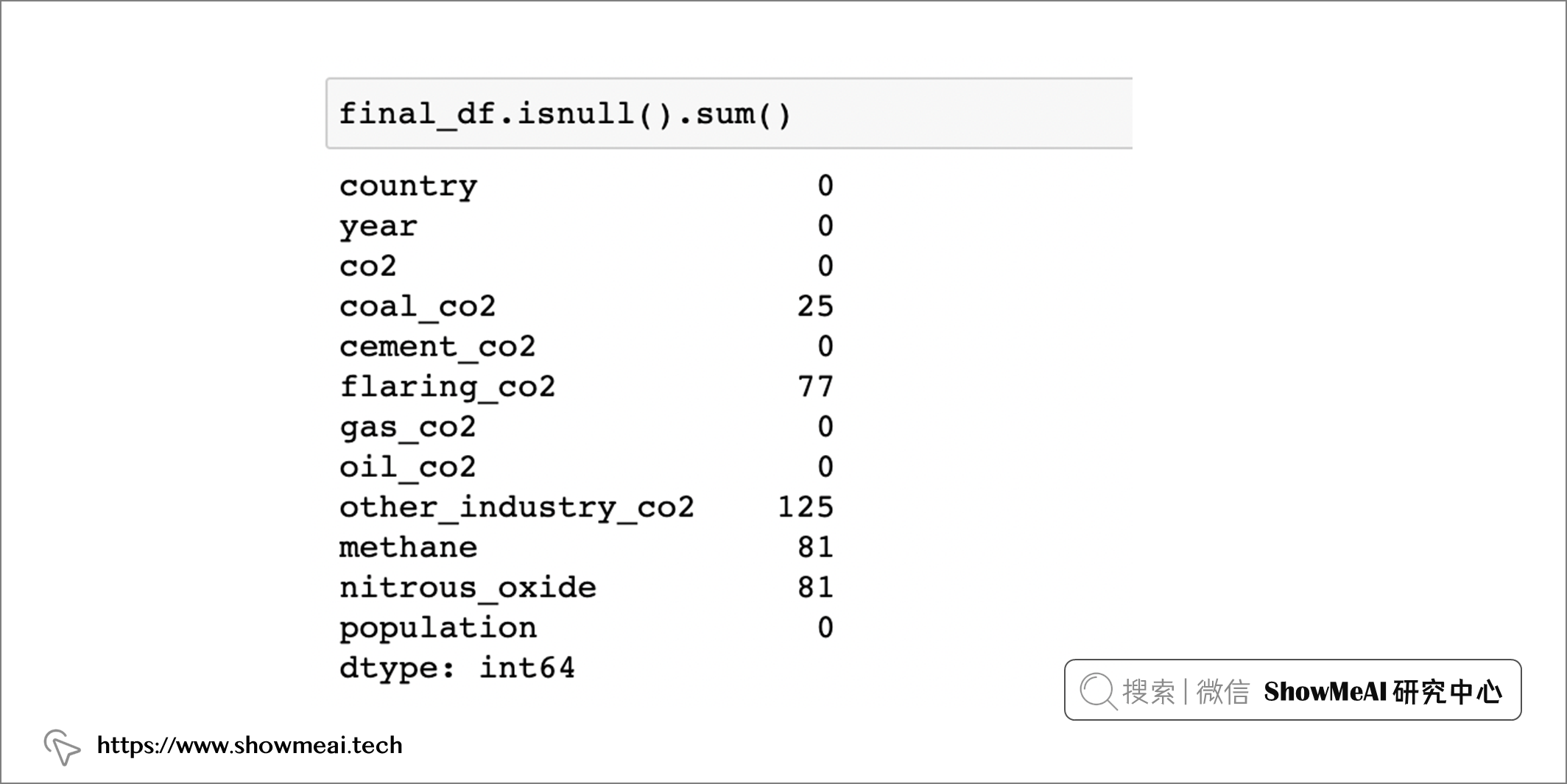
检查缺失值:
final_df.isnull().sum()
💡 数据分析&可视化
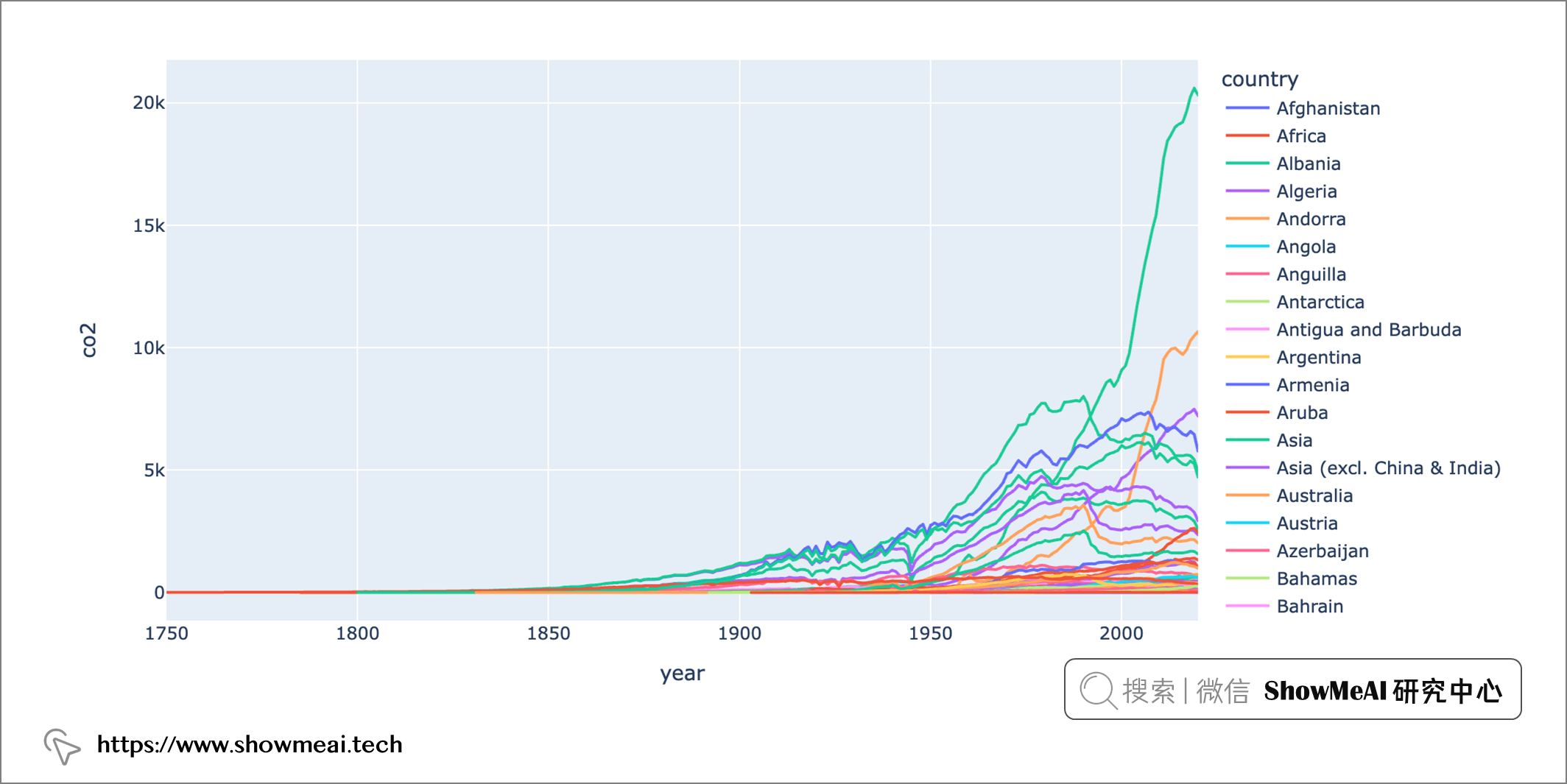
我们将根据我们的数据集绘制图表并分析一些结果。 我们绘制一下随时间线的co2排放趋势图:
px.line(dataset, x = 'year', y = 'co2', color='country')
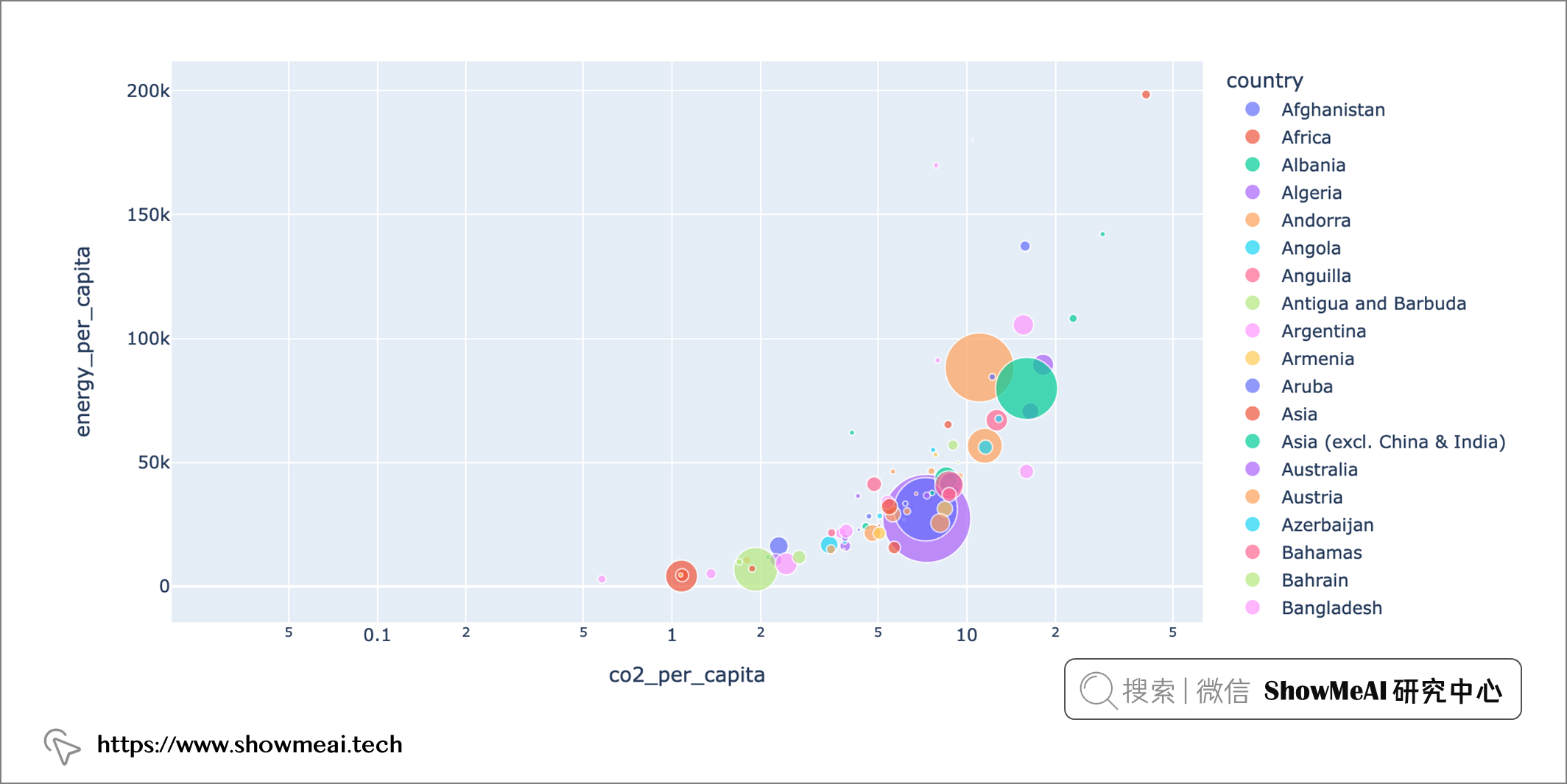
我们按照co2排放量为大小绘制散点图,如下
px.scatter(dataset[dataset['year']==2019], x="co2_per_capita", y="energy_per_capita", size="co2", color="country", hover_name="country", log_x=True, size_max=60)
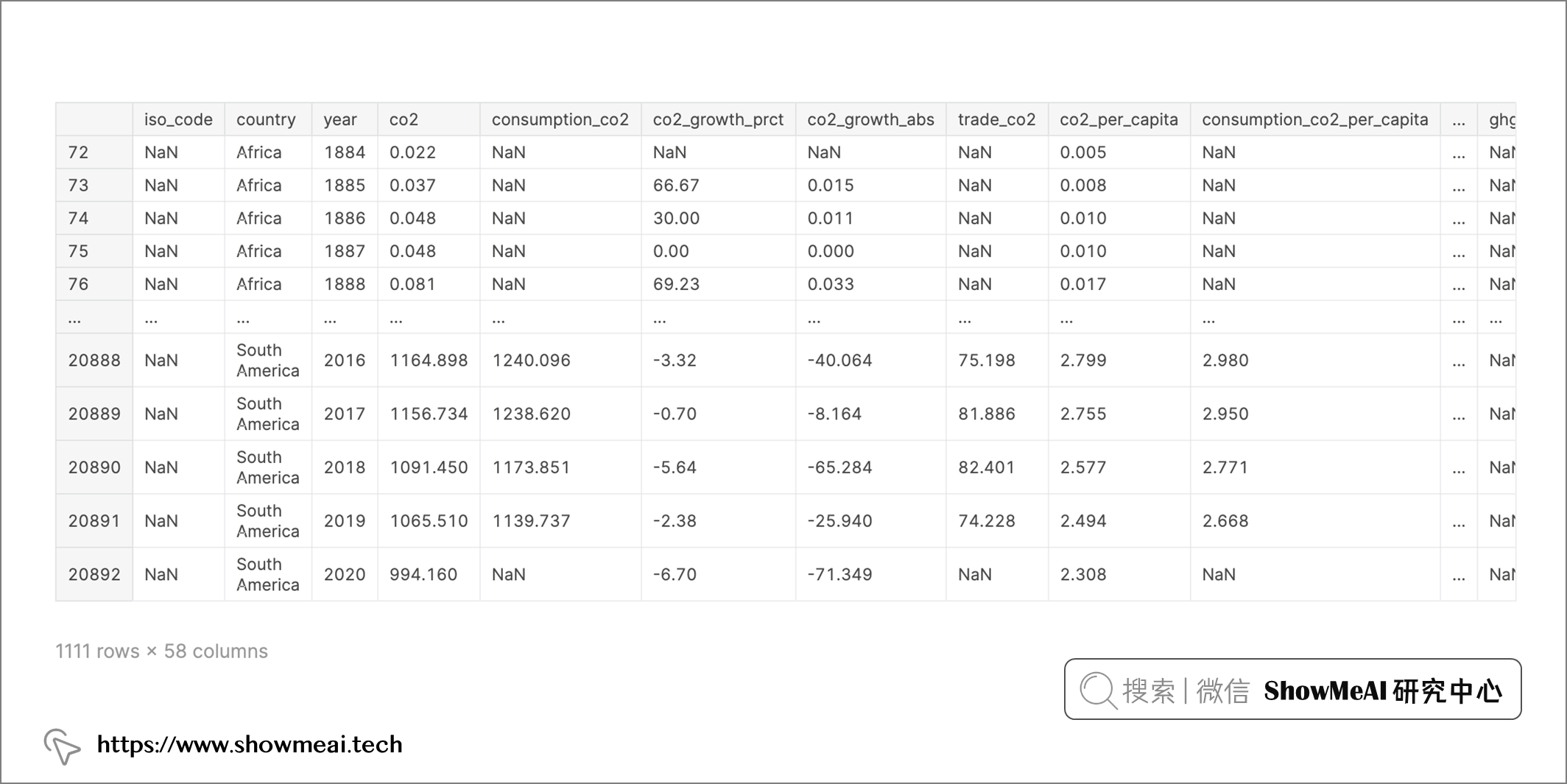
选出各大洲的数据
continent_data = dataset[(dataset['country'].isin(['Europe', 'Africa', 'North America', 'South America', 'Oceania', 'Asia'])) & (dataset['co2'] > 0)]
continent_data
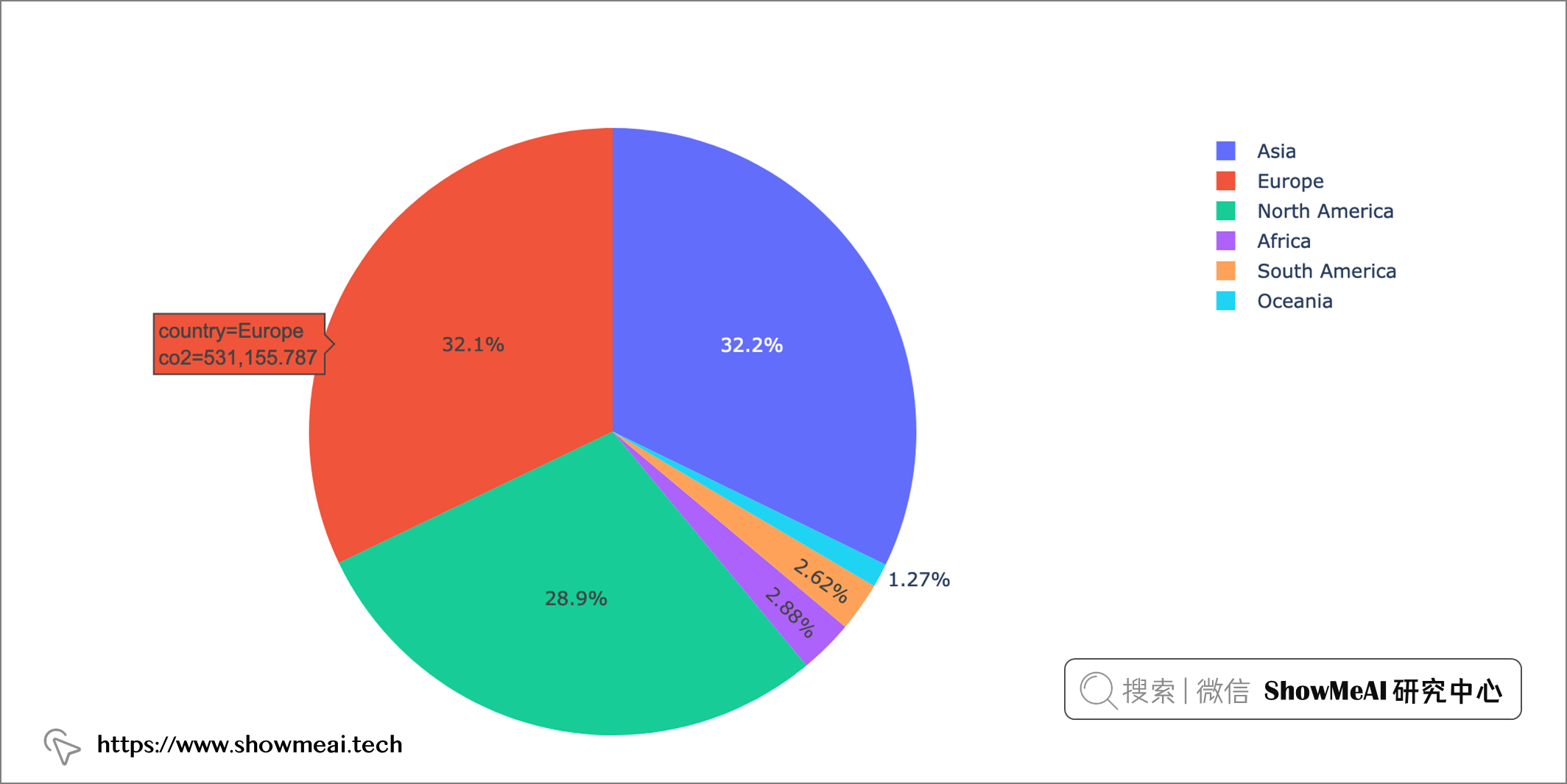
从各大洲来看的占比情况如下
px.pie(continent_data, names='country', values='co2')
下面,我们将根据国家和 Co2 列绘制饼图,看看哪些国家的 Co2 排放量最高。
px.pie(final_df, names='country', values='co2')
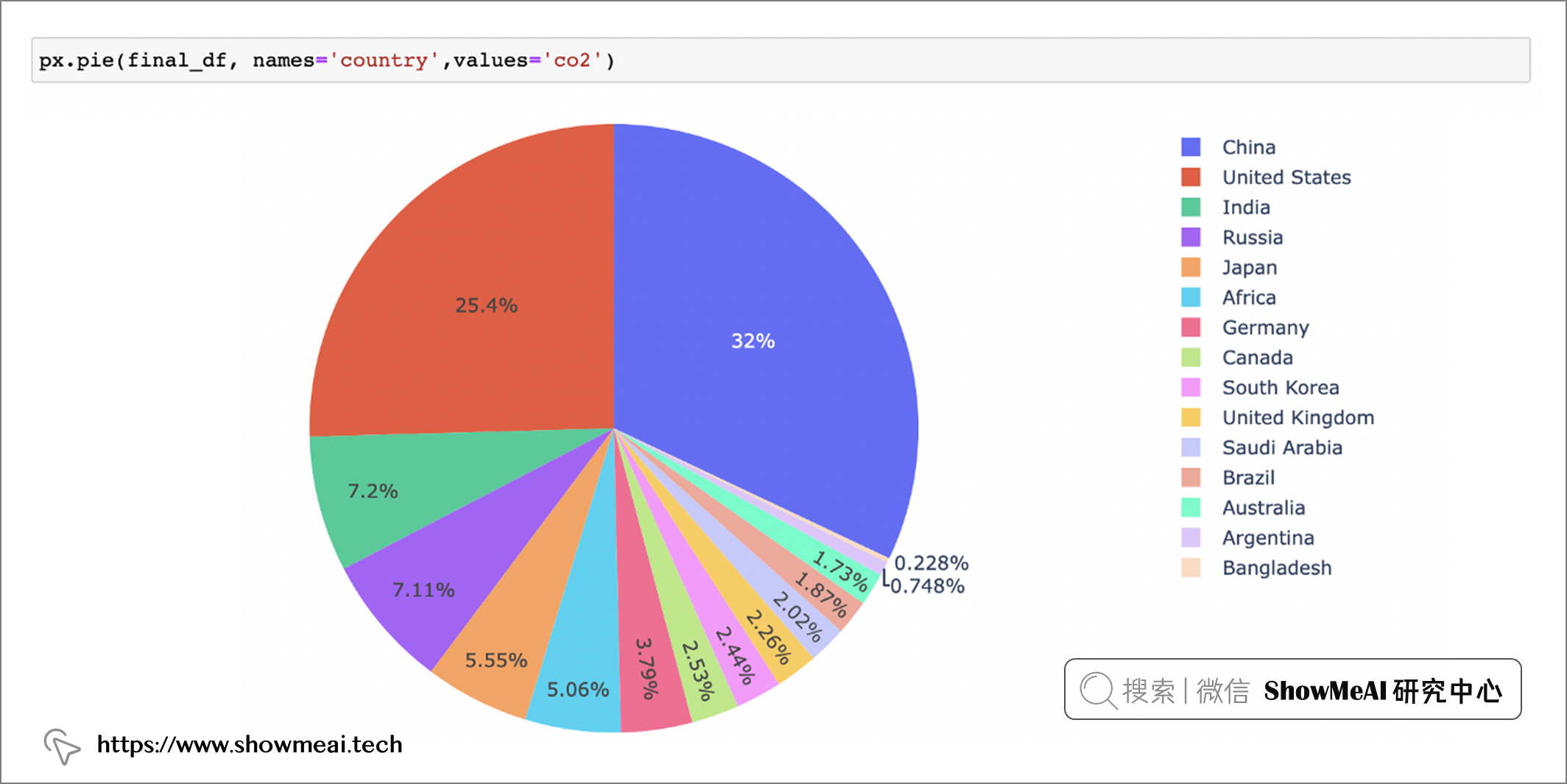
我们可以看到中国、美国、印度都是主要的co2排放大国。如果我们根据二氧化碳的来源进一步分析并仅看 2020 年,那么我们将得到以下结果:
final df 2020 = final _df[(final_df[ 'year' ]==2020) ]
final df 2020
final df 2020[['country','coal_co2','cement_co2','flaring _co2','gas_co2', 'oil _co2','other_ industry co2']].plot(x='country', kind='bar',figsize=(9,5),width=0.9)
plt.title(‘'2020 CO2 consumption')
plt.xlabel('Countries' )
plt.ylabel('CO2 measured in million tonnes')
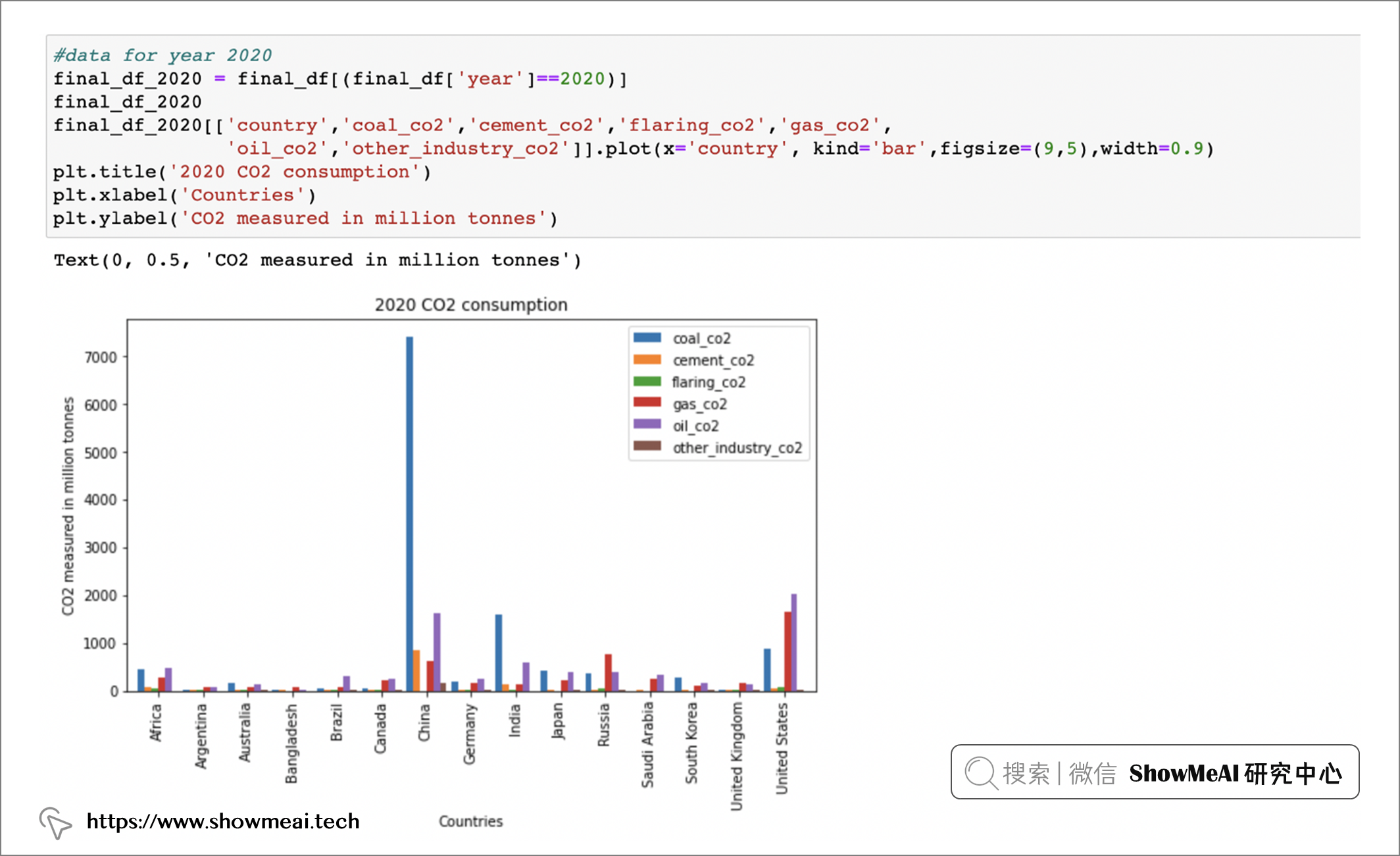
上面的结果中,我们可以看到,三个主要的 Co2 来源是 coal_co2、oil_co2 和 gas_co2。 我们针对这三个主要来源做一点绘图分析,结果会更清晰:
final_df_2020[(['country','coal_co2','gas_co2','o0il_co2')].plot(x='country', kind='bar' ,figsize=(9,5),width=0.9)
plt.title('2020 CO2 consumption')
plt.xlabel('Countries')
plt.ylabel('CO2 measured in million tonnes')
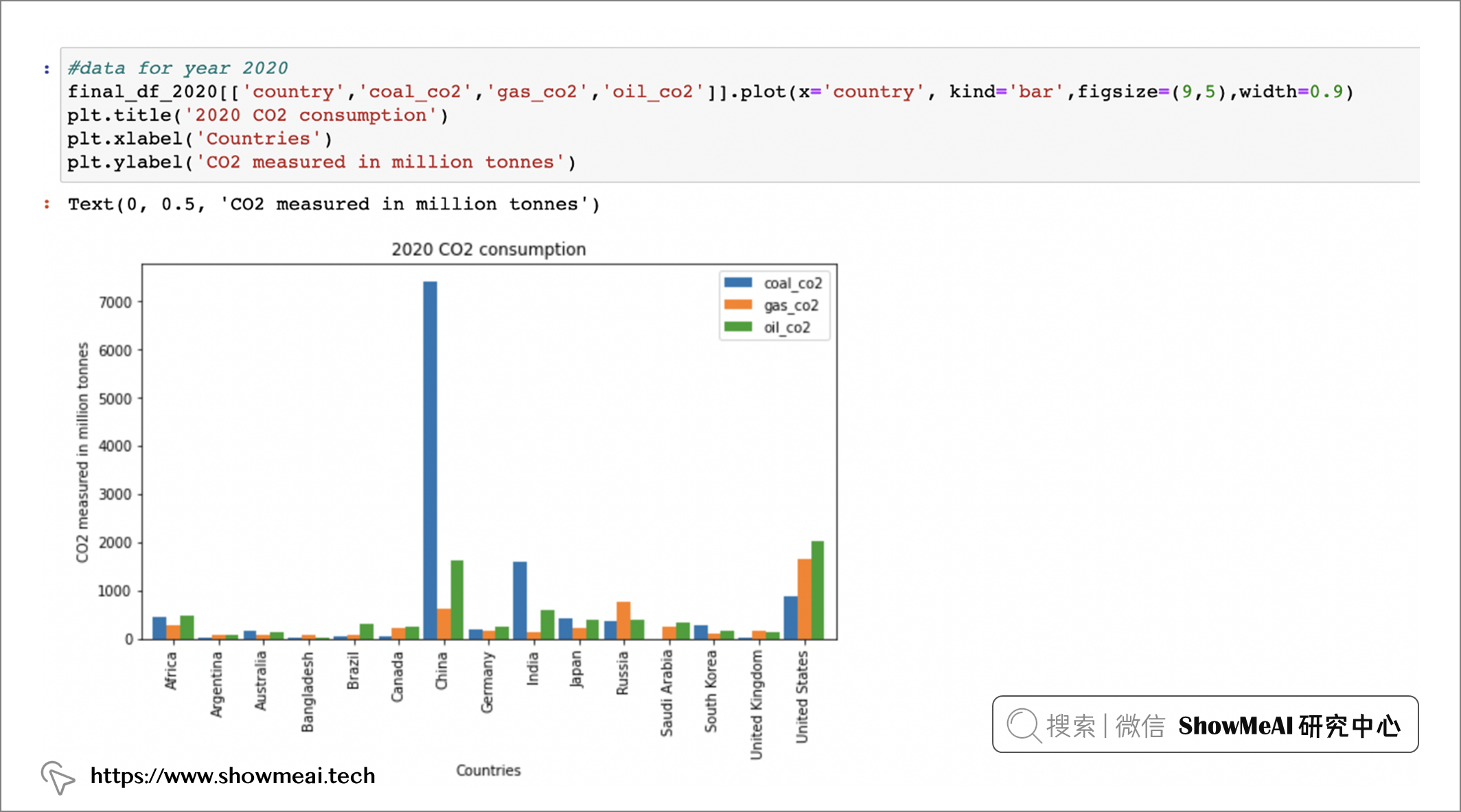
如果我们选定美国进行进一步分析:
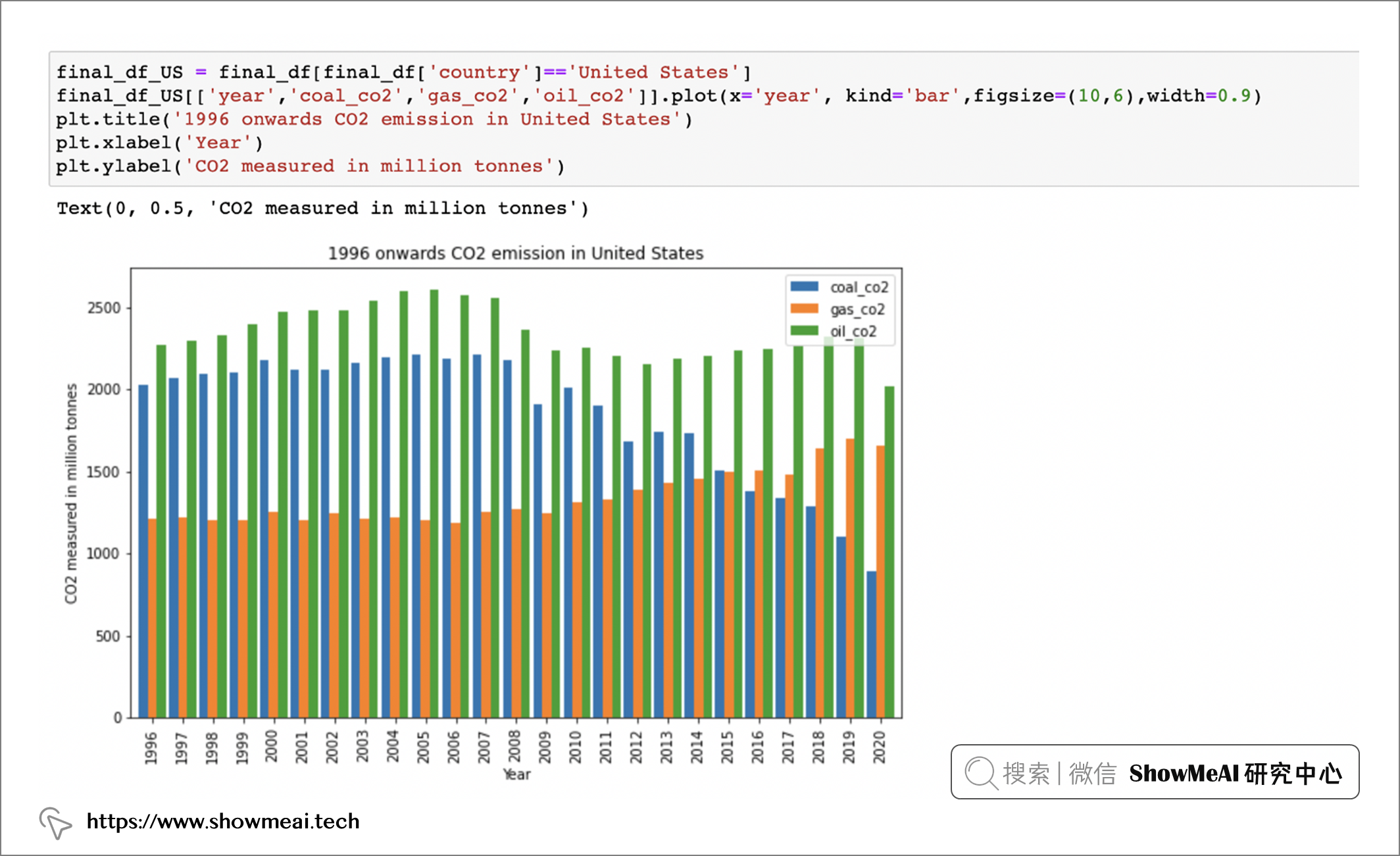
final_df_US = final_df[(final_df['country']=='United States']
final_df_US[['year','coal_co2','gas_co2','0il_co2']].plot(x='year', kind='bar',figsize=(10,6),width=0.9)
plt.title('1996 onwards CO2 emission in United States')
plt.xlabel('Year' )
plt.ylabel(‘'CO2 measured in million tonnes')
图例显示,在美国,coal_co2 和 oil_co2 随着时间的推移而减少,但 gas_co2 多年来一直在增加。
💡 总结
全球气候是全世界都很关心的主题,本篇内容是 Co2 排放的一些简单分析和可视化,大家可以基于上述数据与字段做进一步分析。全球变暖是一个大问题,每个国家都在共同努力,营造更好的环境。
参考资料
- 📘 图解数据分析:从入门到精通系列教程:https://www.showmeai.tech/tutorials/33
- 📘 数据科学工具库速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- 📘 数据科学工具库速查表 | Seaborn 速查表:https://www.showmeai.tech/article-detail/105

 浙公网安备 33010602011771号
浙公网安备 33010602011771号