20 行代码!带你快速构建基础文本搜索引擎 ⛵
 本文使用tf-idf(词频-逆文件频率)、lsi(潜在语义索引)和 doc2vec(文档向量化嵌入)这3种最基础的NLP文档嵌入技术,对文本进行嵌入操作(即构建语义向量)并完成比对检索,构建一个基础版的文本搜索引擎。
本文使用tf-idf(词频-逆文件频率)、lsi(潜在语义索引)和 doc2vec(文档向量化嵌入)这3种最基础的NLP文档嵌入技术,对文本进行嵌入操作(即构建语义向量)并完成比对检索,构建一个基础版的文本搜索引擎。

💡 作者:韩信子@ShowMeAI
📘 机器学习实战系列:https://www.showmeai.tech/tutorials/41
📘 深度学习实战系列:https://www.showmeai.tech/tutorials/42
📘 本文地址:https://www.showmeai.tech/article-detail/321
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容
在本篇内容中,ShowMeAI将带大家,使用最基础的3种NLP文档嵌入技术:tf-idf、lsi 和 doc2vec(dbow),来对文本进行嵌入操作(即构建语义向量)并完成比对检索,完成一个基础版的文本搜索引擎。
💡 文档嵌入技术
文档嵌入(doc embedding)方法能完成文本的向量化表示,我们可以进而将文本搜索问题简化为计算向量之间相似性的问题。我们把『搜索词条』和『文档』都转换为向量(同一个向量空间中)之后,文本比较与检索变得容易得多。
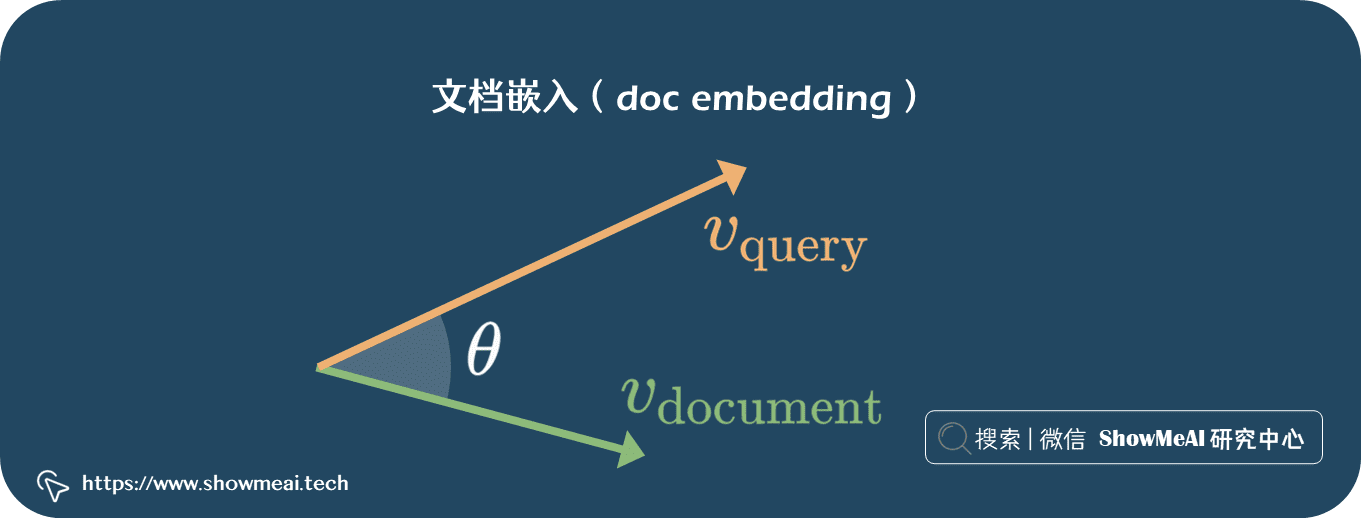
搜索引擎根据『文档』与『搜索词条』的相似度对文档进行评分与排序,并返回得分最高的文档。 比如我们可以使用余弦相似度:

💡 文档嵌入方法与实现
📌 TFIDF / 词频-逆文件频率
TF-IDF(Term Frequency–Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术。TF-IDF 是一种统计方法,用以评估一字词对于一个文档集或一个语料库中的其中一份文档的重要程度。字词的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。简单的解释为,一个单词在一个文档中出现次数很多,同时在其他文档中出现此时较少,那么我们认为这个单词对该文档是非常重要的。
我们可以通过 tfidf 把每个文档构建成长度为 M 的嵌入向量,其中 M 是所有文档中单词构成的词库大小。
一个文档(或查询)d 的 tfidf 向量定义如下:

其中,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。

逆向文件频率 (inverse document frequency,IDF) 的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。

IDF 的计算公式中分母之所以要加1,是为了避免分母为0。
scikit-learn 包带有 tfidf 的实现。 几行代码就可以构建一个基于 tfidf 的原始搜索引擎。
# 数据集处理与tf-idf计算所需工具库
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.datasets import fetch_20newsgroups
# 训练,即统计词表,构建tf-idf映射器
def train(documents):
# Input: 文档列表
# Output: TfidfVectorizer, tfidf矩阵
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(documents.data)
return vectorizer, tfidf
documents = fetch_20newsgroups()
vectorizer, tfidf = train(documents.data)
# 使用构建好的tfidf文档向量化表示,构建简易搜索引擎
from sklearn.metrics.pairwise import linear_kernel
# 距离比对与检索
def search(query, N):
# Input: 检索文本串query, 返回结果条数N
# Output: 所有文档中最相关的N条结果索引
transformed_query = vectorizer.transform([query])
cosine_similarities = linear_kernel(transformed_query, tfidf).flatten()
idx = np.argpartition(cosine_similarities, -N)[-N:]
related_docs_indices = idx[np.argsort((-cosine_similarities)[idx])]
return related_docs_indices, cosine_similarities[related_docs_indices]
# 从索引映射取回原始文档内容
[documents.data[idx] for idx in search('car hunter', 5)[0]]
tfidf 是最经典的信息检索算法,尽管它的原理非常简单,但它仍然被广泛使用。 例如,ElasticSearch 使用了 tfidf 的变体,并且在内存管理、可靠性和检索速度方面比原始版本要好得多。
📌 LSI / 潜在语义索引
上面介绍到的 tfidf 其实只考虑了精确的单词匹配。 然而我们有很多不同的方式来表达同样一个意思,但 tfidf 对于同义词的捕捉能力是很弱的。
优秀的搜索引擎需要处理语义,能在语义层面进行匹配和检索。为了实现这一点,我们需要捕捉文档的语义信息,而LSI可以通过在 tdfidf 矩阵上应用 SVD 来构造这样一个潜在的概念空间。
SVD 将 tfidf 矩阵分解为 3 个较小矩阵的乘积(其中 U 和 V 是正交矩阵,Σ 是 tfidf 矩阵的奇异值的对角矩阵)。

(UΣ) 构建成了我们的文档概念矩阵:它的每一列都带有一个潜在的“主题”。在潜在概念空间中匹配度高的文档,我们认为它们彼此更加接近。
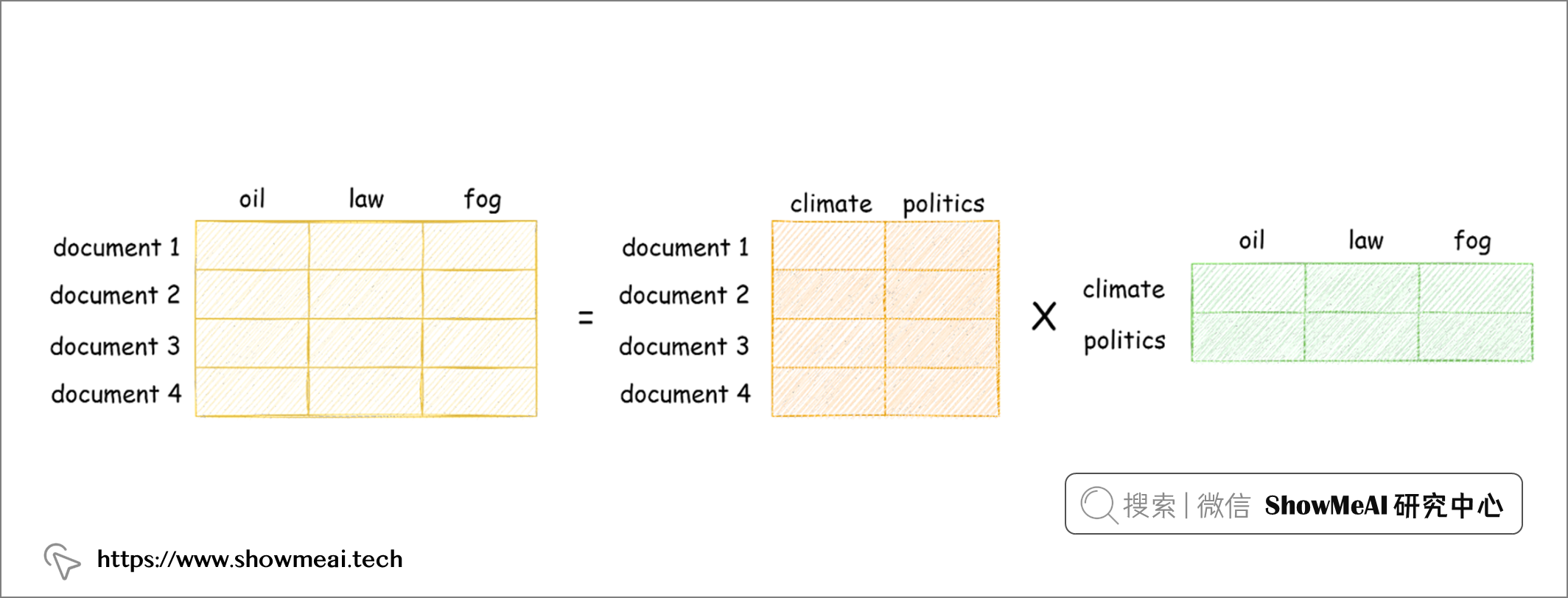
要实现 LSI,我们只需要对上述 tfidf 的实现做一点小改动,在 train 方法中添加一个 svd 步骤。 搜索方法保持完全相同。
# LSI潜在语义索引实现
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import Pipeline
# 注意到得到的tfidf矩阵会进行SVD分解
def train(documents):
vectorizer = TfidfVectorizer()
svd = TruncatedSVD(n_components=1500,
algorithm='randomized',
n_iter=10, random_state=42)
lsi = Pipeline([('tfidf', vectorizer),
('svd', svd)])
matrix = lsi.fit_transform(documents.data)
return lsi, matrix
不过,一些研究人员指出,在上述因式分解中,从矩阵 V 推断词相似度是不太靠谱的。所以大家在有些地方也会看到应用对称 SVD:

📌 Doc2vec / 文档向量化嵌入
上面提到的SVD方法,在数据量很大时会有时间复杂度太高的问题。通过训练浅层神经网络来构建文档向量,可以很好地解决这个问题,Doc2vec 是最典型的方法之一,它有 2 种风格:DM 和 DBOW。

有兴趣更系统全面了解词向量与文档向量的宝宝,建议阅读ShowMeAI整理的自然语言处理相关教程和文章
① DM(A distributed memory model)
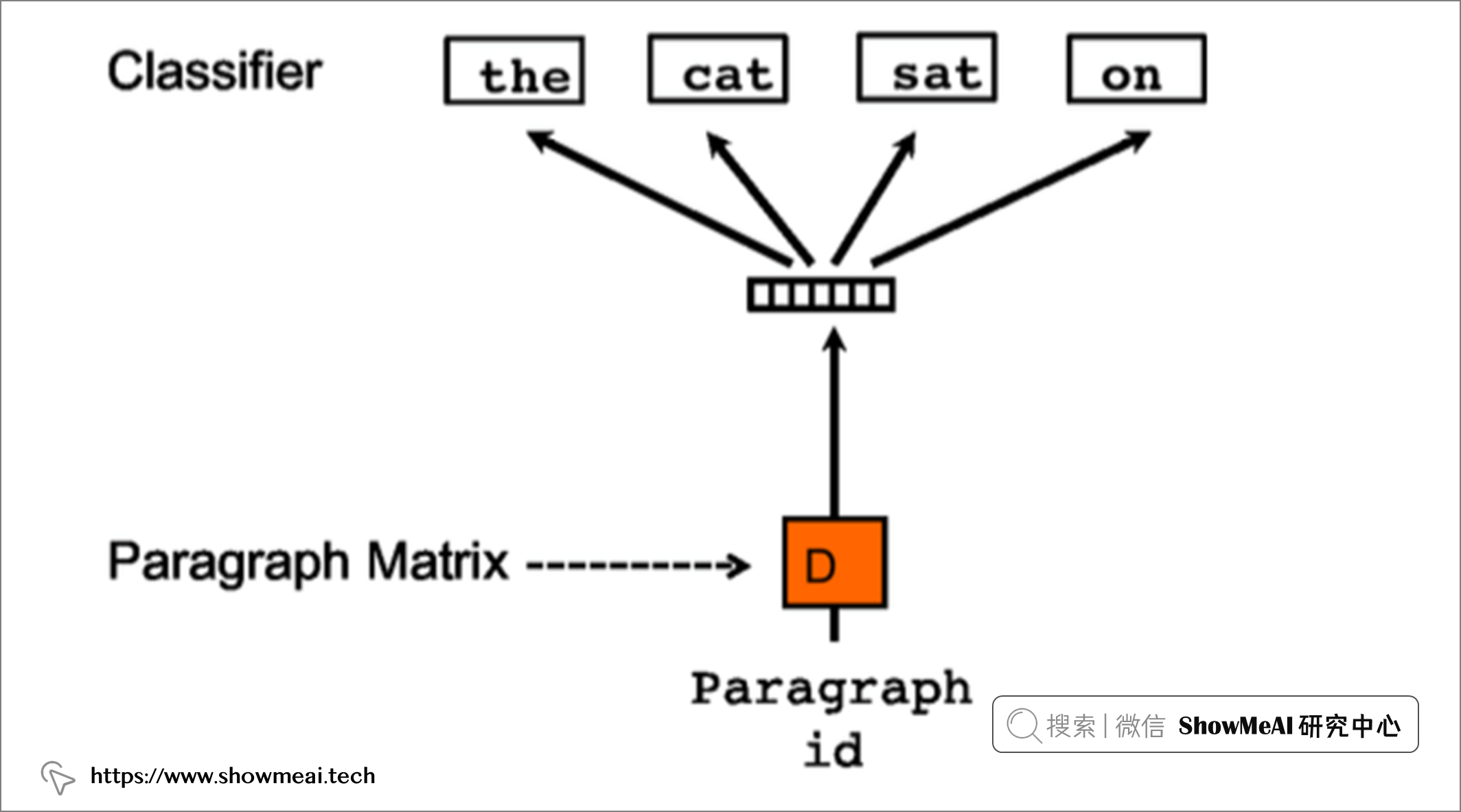
大家可能听说过word2vec训练词向量的方法,训练词向量的核心思想就是说可以根据每个单词的上下文预测,也就是说上下文的单词对是有影响的。训练句向量的方法和词向量的方法非常类似,例如对于一个句子i want to drink water,如果要去预测句子中的单词want,那么不仅可以根据其他单词生成feature, 也可以根据其他单词和句子来生成feature进行预测。因此doc2vec的框架如下所示:

每个段落/句子都被映射到向量空间中,可以用矩阵的一列来表示。每个单词同样被映射到向量空间,可以用矩阵的一列来表示。然后将段落向量和词向量级联或者求平均得到特征,预测句子中的下一个单词。
这个段落向量/句向量也可以认为是一个单词,它的作用相当于是上下文的记忆单元或者是这个段落的主题,所以我们一般叫这种训练方法为Distributed Memory Model of Paragraph Vectors(PV-DM)
在训练的时候我们固定上下文的长度,用滑动窗口的方法产生训练集。段落向量/句向量 在该上下文中共享。
doc2vec的过程可以分为2个核心步骤:
- ① 训练模型,在已知的训练数据中得到词向量W, softmax的参数U和b,以及段落向量/句向量D
- ② 推断过程(inference stage),对于新的段落,得到其向量表达。具体地,在矩阵D中添加更多的列,在固定W,U,b的情况下,利用上述方法进行训练,使用梯度下降的方法得到新的D,从而得到新段落的向量表达
② DBOW(Paragraph Vector without word ordering: Distributed bag of words)
相比上面提到的DM方法,DBOW训练方法是忽略输入的上下文,让模型去预测段落中的随机一个单词。就是在每次迭代的时候,从文本中采样得到一个窗口,再从这个窗口中随机采样一个单词作为预测任务,让模型去预测,输入就是段落向量。如下所示:
我们使用 gensim 工具可以快速构建 doc2vec。
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from sklearn.datasets import fetch_20newsgroups
def train(documents):
# Input: 文档列表
# Output: Doc2vec模型
tagged_doc = [TaggedDocument(doc.split(' '), [i]) for i, doc in enumerate(documents)]
model = Doc2Vec(documents, vector_size=100, window=2, min_count=1, workers=4, dm=0)
model.build_vocab(documents)
model.train(documents, total_examples=len(documents), epochs=10)
return model
# 在训练集上训练
documents = fetch_20newsgroups()
model = train(documents.data)
而 gensim 构建的 doc2vec 模型对象,可以直接进行向量距离比对和排序,所以我们的检索过程可以如下简单实现:
def search(query, N):
# Input: 检索文本串query, 返回结果条数N
# Output: 所有文档中最相关的N条结果索引
inferred_vector = model.infer_vector(query.split(' '))
return model.dv.most_similar(inferred_vector, topn=N)
# 根据索引映射回原来的文档内容
[documents.data[idx[0]] for idx in search('car hunter', 5)]
参考资料
- 📘 深度学习教程:吴恩达专项课程 · 全套笔记解读:https://www.showmeai.tech/tutorials/35
- 📘 深度学习教程 | 自然语言处理与词嵌入:https://www.showmeai.tech/article-detail/226
- 📘 NLP教程 | 斯坦福CS224n · 课程带学与全套笔记解读:https://www.showmeai.tech/tutorials/36
- 📘 NLP教程(1) - 词向量、SVD分解与Word2Vec:https://www.showmeai.tech/article-detail/230
- 📘 NLP教程(2) - GloVe及词向量的训练与评估:https://www.showmeai.tech/article-detail/232

 浙公网安备 33010602011771号
浙公网安备 33010602011771号