💡 作者:韩信子@ShowMeAI
📘 大数据技术 ◉ 技能提升系列:https://www.showmeai.tech/tutorials/84
📘 行业名企应用系列:https://www.showmeai.tech/tutorials/63
📘 本文地址:https://www.showmeai.tech/article-detail/296
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容
💡 背景
Sparkify 是一个音乐流媒体平台,用户可以获取部分免费音乐资源,也有不少用户开启了会员订阅计划(参考QQ音乐),在Sparkify中享受优质音乐内容。
用户可以随时对自己的会员订阅计划降级甚至取消,而当下极其内卷和竞争激烈的大环境下,获取新客的成本非常高,因此维护现有用户并确保他们长期会员订阅至关重要。同时因为我们有很多用户在平台的历史使用记录,基于这些数据支撑去挖掘客户倾向,定制合理的业务策略,也更加有保障和数据支撑。
但现在稍大一些的互联网公司,数据动辄成百上千万,我们要在这么巨大的数据规模下完成挖掘与建模,又要借助各种处理海量数据的大数据平台。在本文中ShowMeAI将结合 Sparkify 的业务场景和海量数据,讲解基于 Spark 的客户流失建模预测案例。
本文涉及到大数据处理分析及机器学习建模相关内容,ShowMeAI为这些内容制作了详细的教程与工具速查手册,大家可以通过如下内容展开学习或者回顾相关知识。
💡 数据
本文用到的 Sparkify 数据有3个大小的数据规格,大家可以根据自己的计算资源情况,选择合适的大小,本文代码都兼容和匹配,对应的数据大家可以通过ShowMeAI的百度网盘地址获取。
🏆 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [9] Spark 海量数据上的用户留存分析挖掘与建模 『sparkify 用户流失数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
- mini_sparkify_event_data.json: 最小的数据子集 (125 MB)
- medium-sparkify-event-data.json: 中型大小数据子集 (237 MB)
- sparkify_event_data.json: 全量数据 (12 GB)
💡 探索性数据分析(EDA)
在进行建模之前,我们首先要深入了解我们的数据,这可以帮助我们更有针对性地构建特征和选择模型。也就是ShowMeAI之前提到过的「探索性数据分析(EDA)」的过程。
① 导入工具库
| |
| import pandas as pd |
| import numpy as np |
| import seaborn as sns |
| import matplotlib.pyplot as plt |
| import requests |
| from datetime import datetime |
| |
| from pyspark.sql import SparkSession |
| from pyspark.sql import Window, Row |
| import pyspark.sql.functions as F |
| from pyspark.sql.types import IntegerType, StringType, FloatType |
② 初步数据探索
Sparkify 数据集中,每一个用户的行为都被记录成了一条带有时间戳的操作记录,包括用户注销、播放歌曲、点赞歌曲和降级订阅计划等。
| |
| spark_session = SparkSession.builder \ |
| .master("local") \ |
| .appName("sparkify") \ |
| .getOrCreate() |
| |
| |
| src = "data/mini_sparkify_event_data.json" |
| df = spark_session.read.json(src) |
| |
| df.createOrReplaceTempView("sparkify_table") |
| df.persist() |
| |
| |
| df . limit(5) . toPandas() |
用全量数据集(12GB)做EDA可能会消耗大量的资源且很慢,所以这个过程我们选择小子集(128MB)来完成,如果采样方式合理,小子集上的数据分布能很大程度体现全量数据上的分布特性。
对于中小数据集上的EDA大家可以参考ShowMeAI分享过的自动化数据分析工具,可以更快捷地获取一些数据信息与分析结论。
📌 基础数据维度信息
| |
| print(f'数据集有 {len(df.columns)} 列') |
| print(f'数据集有 {df.count()} 行') |
结果显示有 18 列 和 286500 行。
实际这份小子集中只有 225 个唯一用户 ID,这意味着平均每个客户与平台有 286500/225≈1200 多个交互操作。
📌 字段信息
我们通过上述命令查看数据字段信息,输出结果如下,包含字段名和类型等:
| |-- artist: string (nullable = true) |
| |-- auth: string (nullable = true) |
| |-- firstName: string (nullable = true) |
| |-- gender: string (nullable = true) |
| |-- itemInSession: long (nullable = true) |
| |-- lastName: string (nullable = true) |
| |-- length: double (nullable = true) |
| |-- level: string (nullable = true) |
| |-- location: string (nullable = true) |
| |-- method: string (nullable = true) |
| |-- page: string (nullable = true) |
| |-- registration: long (nullable = true) |
| |-- sessionId: long (nullable = true) |
| |-- song: string (nullable = true) |
| |-- status: long (nullable = true) |
| |-- ts: long (nullable = true) |
| |-- userAgent: string (nullable = true) |
| |-- userId: string (nullable = true) |
我们获取的一些初步信息如下:
- 字符串类型的字段包括
song, artist, gender和 level
- 一些时间和ID类的字段特征
ts(时间戳),registration(时间戳),page 和 userId 。
- 可能作用不太大的一些字段
firstName , lastName , method , status , userAgent和 auth等(等待进一步挖掘)
📌 时间跨度信息
| |
| df = df . sort('ts', ascending= False) |
| |
| df . select(F . max(df . ts), F . min(df . ts)) . show() |
| |
| |
| print("Min date =", datetime.fromtimestamp(1538352117000 / 1000)) |
| print("Max date =", datetime.fromtimestamp(1543799476000 / 1000)) |
| |
| df.select(F.min(df.registration)).show() |
| print("Min register =", datetime.fromtimestamp(1521380675000 / 1000)) |
📌 字段分布
| |
| cols = df.columns |
| n_unique = [] |
| |
| for col in cols: |
| n_unique.append(df.select(col).distinct().count()) |
| |
| pd.DataFrame(data={'col':cols, 'n_unique':n_unique}).sort_values('n_unique', ascending=False) |
结果如下,ID类的属性有最多的取值,其他的字段属性相对集中。
📌 类别型取值分布
我们来看看上面分析的尾部,分布比较集中的类别型字段的取值有哪些。
| |
| df . select(['method']) . distinct() . show() |
| |
| df.select(['level']).distinct().show() |
| |
| df . select(['status']) . distinct() . show() |
| |
| df.select(['gender']).distinct().show() |
| |
| df . select(['auth']) . distinct() . show() |
我们再看看取值中等和较多的字段
| |
| df . select(['page']) . distinct() . show() |
| |
| df.select(['userAgent']).distinct().show() |
| |
| df.select(['artist']).distinct().show() |
| |
| df.select(['song']).distinct().show() |
③ 缺失值分析
我们首先剔除掉userId为空的数据记录,总共删除了 8,346 行。
| no_userId = df . where(df . userId == "") |
| no_userId . count() |
| no_userId . limit(10) . toPandas() |
| |
| df = df . where(df . userId != "") |
| df . createOrReplaceTempView("sparkify_table") |
我们再统计一下其他字段的缺失状况
| |
| general_string_type = ['auth', 'firstName', 'gender', 'lastName', 'level', 'location', 'method', 'page', 'userAgent', 'userId'] |
| for col in general_string_type: |
| null_vals = df.select(col).where(df[col].isNull()).count() |
| print(f'{col}: {null_vals}') |
| |
| |
| numerical_cols = ['itemInSession', 'length', 'registration', 'sessionId', 'status', 'ts'] |
| for col in numerical_cols: |
| null_vals = df.select(col).where(df[col] == np.nan).count() |
| print(f'{col}: {null_vals}') |
| |
| |
| |
| |
| def make_missing_bool_index(c): |
| ''' |
| Generates boolean index to check missing value/NULL values |
| @param c (string) - string of column of dataframe |
| returns boolean index created |
| ''' |
| |
| |
| |
| |
| bool_index = (F.col(c) == "") | \ |
| F.col(c).isNull() | \ |
| F.isnan(c) |
| return bool_index |
| |
| missing_count = [F.count(F.when(make_missing_bool_index(c), c)).alias(c) |
| for c in df.columns] |
| |
| df.select(missing_count).toPandas() |
④ EDA洞察&结论
由于我们的数据是基于各种有时间戳的交易来组织的,以事件为基础(基于 "页 "列),我们需要执行额外的特征工程来定制我们的数据以适应我们的机器学习模型。
📌 目标&问题
📌 重要字段列
ts - 时间戳,在以下场景有用
- 订阅与取消之间的时间点信息
- 构建「听歌的平均时间」特征
- 构建「听歌之间的时间间隔」特征
- 基于时间戳构建数据样本,比如选定用户流失前的3个月或6个月
registration - 时间戳 - 用于识别交易的范围page - 用户正在参与的事件
- 本身并无用处
- 需要进一步特征工程,从页面类型中提取信息,或结合时间戳等信息
userId
📌 配合特征工程有用的字段列
song - 歌名,可用于构建类似下述的特征:
artist- 歌手,可用于构建类似下述的特征:
- 因为是明文的歌名,我们甚至可以通过外部API补充信息构建特征:
gender - 性别
level - 等级
location - 地区
📌 无用字段列(我们会直接删除)
firstName和lastName - 名字一般在模型中很难直接给到信息。method - 仅仅有PUT或GET取值,是网络请求类型,作用不大。status- 仅仅是API响应,例如200/404,作用不大。userAgent--指定用户使用的浏览器类型
- 有可能不同浏览器代表的用户群体有差别,这个可以进一步调研
auth - 登入登出等信息,作用不大
💡 数据处理
① 定义流失
我们的 page功能有 22 个独特的标签,代表用户点击或访问的页面,结合上面的数据分析大家可以看到页面包括关于、登录、注册等。
可以帮助我们定义流失的页面是 Cancellation Confirmation,表示 免费 和 付费 用户均存在流媒体平台。
| |
| is_churn = F.udf(lambda x: 1 if x == 'Cancellation Confirmation' else 0, IntegerType()) |
| df = df.withColumn("churn", is_churn(df.page)) |
| df.createOrReplaceTempView("sparkify_table") |
| |
| user_window = Window \ |
| .partitionBy('userId') \ |
| .orderBy(F.desc('ts')) \ |
| .rangeBetween(Window.unboundedPreceding, 0) |
| |
| |
| |
| tmp_row = spark_local.sparkContext.parallelize(Row(second_row)).toDF(schema=df.schema) |
| df.where(df.userId == 100001).union(tmp_row).withColumn('pre_churn', F.sum('churn').over(user_window)).limit(5).toPandas() |
| |
| df = df.withColumn('preChurn', F.sum('churn').over(user_window)) |
| df.createOrReplaceTempView("sparkify_table") |
对用户流失情况做简单分析
| spark_local.sql(''' |
| SELECT SUM(churn) |
| FROM sparkify_table |
| GROUP BY userId |
| ''').toPandas().value_counts() |
在我们采样出来的小数据集中:有225 个用户, 23%(52 个用户)流失 。
② 特征工程
关于特征工程可以参考ShowMeAI的以下文章详解
本文中所使用到的特征工程如下:
- ① 歌曲和歌手相关:
uniqueSongs, uniqueArtists, uniqueSongArtist.
- ② 用户服务时长:
dayServiceLen(注册到上次与网站互动之间的天数)
- ③ 用户行为统计:
countListen(收听次数), countSession(session数量), lengthListen(听的总时长)
- ④ 使用②和③的组合
lengthListenPerDay, countListenPerDay, sessionPerDay等
- ⑤ 针对一些统计值(
countListen , countSession, 和 lengthListen等)计算的差异度。
📌 清理数据
| |
| def clean_data(df): |
| ''' |
| Cleans raw dataframe to: |
| i. sort values |
| ii. remove null userId rows |
| @param df: raw spark dataframe |
| returns updated spark dataframe |
| ''' |
| |
| df = df.sort('ts', ascending=False) |
| |
| df = df.where(df.userId != "") |
| return df |
📌 定义用户流失标签
| |
| def define_churn(df): |
| ''' |
| Define churn |
| @param df - spark dataframe |
| returns updated spark dataframe |
| ''' |
| |
| is_churn = F.udf(lambda x: 1 if x == 'Cancellation Confirmation' else 0, IntegerType()) |
| df = df.withColumn("churn", is_churn(df.page)) |
| return df |
📌 清理脏数据
有一部分用户在流失之后,还有一些数据信息,这可能是时间戳的问题,我们把这部分数据清理掉
| |
| def remove_post_churn_rows(df, spark, sql_table): |
| ''' |
| Remove post-churn rows |
| @param df - spark dataframe |
| @param spark - SparkSession instance |
| @param sql_table - string representing name of sql table |
| returns updated spark dataframe |
| ''' |
| |
| user_window = Window \ |
| .partitionBy('userId') \ |
| .orderBy(F.desc('ts')) \ |
| .rangeBetween(Window.unboundedPreceding, 0) |
| df = df.withColumn('preChurn', F.sum('churn').over(user_window)) |
| |
| |
| churn_df = spark.sql(f''' |
| SELECT |
| userId AS tmpId, |
| MAX(churn) AS tmpChurn |
| FROM {sql_table} |
| GROUP BY userId |
| ''') |
| df = df.join(churn_df, df.userId == churn_df.tmpId, "left") |
| |
| df = df.where(~((df.preChurn == 0) & (df.tmpChurn == 1))) |
| |
| df = df.drop('tmpId', 'tmpChurn') |
| return df |
📌 时间特征
| def prelim_feature_eng(df): |
| ''' |
| Feature engineer columns: |
| i timeSinceRegister |
| ii. columns representing time scope of entry |
| @param df: raw spark dataframe |
| returns updated spark dataframe |
| ''' |
| |
| time_since_register = F.col('ts') - F.col('registration') |
| df = df.withColumn("timeSinceRegister", time_since_register) |
| |
| |
| mth_3 = 60 * 60 * 24 * 90 |
| mth_6 = 60 * 60 * 24 * 180 |
| mth_12 = 60 * 60 * 24 * 365 |
| mth_3_f = F.udf(lambda x : 1 if x / 1000 <= mth_3 else 0, IntegerType()) |
| mth_6_f = F.udf(lambda x : 1 if x / 1000 <= mth_6 else 0, IntegerType()) |
| mth_12_f = F.udf(lambda x : 1 if x / 1000 <= mth_12 else 0, IntegerType()) |
| df = df.withColumn("month3", mth_3_f(df.timeSinceRegister))\ |
| .withColumn("month6", mth_6_f(df.timeSinceRegister))\ |
| .withColumn("month12", mth_12_f(df.timeSinceRegister)) |
| return df |
📌 统计&组合特征
| def melt_data(df, spark, sql_table): |
| ''' |
| Melts data to show entries on a user basis for the following columns: |
| - userId |
| - gender |
| - level |
| - location |
| - uniqueSongs |
| - uniqueArtists |
| - dayServiceLen |
| - countListen1H, |
| - countSession1H, |
| - lengthListen1H, |
| - countListen2H, |
| - countSession2H, |
| - lengthListen2H |
| - churn |
| @param df - spark dataframe |
| @param spark - SparkSession instance |
| @param sql_table - string representing name of sql table |
| returns updated spark datafraem |
| ''' |
| melt1 = spark.sql(f''' |
| SELECT userId, |
| MIN(gender) AS gender, |
| MIN(level) AS level, |
| MAX(location) AS location, |
| COUNT(DISTINCT(song)) AS uniqueSongs, |
| COUNT(DISTINCT(artist)) AS uniqueArtists, |
| COUNT(DISTINCT(song, artist)) AS uniqueSongArtist, |
| MAX(Churn) AS churn |
| FROM {sql_table} |
| GROUP BY userId |
| ''') |
| melt2 = spark.sql(f''' |
| WITH sparkify_table_upt AS ( |
| SELECT * FROM {sql_table} |
| WHERE page = "NextSong" |
| ), |
| msServiceTable AS ( |
| SELECT userId, |
| MAX(ts) - MIN(ts) AS msServiceLen, |
| MIN(ts) + (MAX(ts) - MIN(ts)) / 2 AS midTs |
| FROM sparkify_table_upt |
| GROUP BY userId |
| ), |
| earlyHalfTable AS ( |
| SELECT a.userId, |
| COUNT(1) AS countListen1H, |
| COUNT(DISTINCT(a.sessionId)) AS countSession1H, |
| SUM(a.length) AS lengthListen1H |
| FROM sparkify_table_upt AS a |
| LEFT JOIN msServiceTable AS b ON b.userId = a.userId |
| WHERE a.ts < b.midTs |
| GROUP BY a.userId |
| ), |
| lateHalfTable AS ( |
| SELECT a.userId, |
| COUNT(1) AS countListen2H, |
| COUNT(DISTINCT(a.sessionId)) AS countSession2H, |
| SUM(a.length) AS lengthListen2H |
| FROM sparkify_table_upt AS a |
| LEFT JOIN msServiceTable AS b ON b.userId = a.userId |
| WHERE a.ts >= b.midTs |
| GROUP BY a.userId |
| ), |
| concatTable AS ( |
| SELECT m.userId AS tmpUserId, |
| milisecToDay(msServiceLen) AS dayServiceLen, |
| countListen1H + countListen2H AS countListen, |
| countSession1H + countSession2H AS countSession, |
| lengthListen1H + lengthListen2H AS lengthListen, |
| countListen2H - countListen1H AS countListenDiff, |
| countSession2H - countSession1H AS countSessionDiff, |
| lengthListen2H - lengthListen1H AS lengthListenDiff |
| FROM msServiceTable as m |
| LEFT JOIN earlyHalfTable as e ON e.userId = m.userId |
| LEFT JOIN lateHalfTable AS l ON l.userId = m.userId |
| ) |
| SELECT *, |
| lengthListen / dayServiceLen AS lengthListenPerDay, |
| countListen / dayServiceLen AS countListenPerDay, |
| countSession / dayServiceLen AS sessionPerDay, |
| lengthListen / countListen AS lengthPerListen, |
| lengthListen / countSession AS lengthPerSession |
| FROM concatTable |
| |
| ''') |
| melt_concat = melt1.join(melt2, melt1.userId == melt2.tmpUserId, "Left") |
| melt_concat = melt_concat.drop('tmpUserId') |
| return melt_concat |
📌 位置信息
| def location_feature_eng(df, census): |
| ''' |
| Create 2 new columns from location -> Region and Division |
| @param df: raw spark dataframe |
| @param census: csv file containing location mapping based on state code |
| returns updated spark dataframe |
| ''' |
| |
| map_region = F.udf(lambda x: census.loc[census['State Code'] == x[-2:], 'Region'].iloc[0], StringType()) |
| map_division = F.udf(lambda x: census.loc[census['State Code'] == x[-2:], 'Division'].iloc[0], StringType()) |
| |
| df = df.withColumn("region", map_region(df.location))\ |
| .withColumn("division", map_division(df.location)) |
| return df |
📌 组织数据&特征流水线
| |
| df_train = spark_session.read.json(src) |
| |
| df_train = df_train.drop('firstName', 'lastName', 'method', 'status', 'userAgent', 'auth') |
| |
| df_train = clean_data(df_train) |
| df_train = define_churn(df_train) |
| df_train.createOrReplaceTempView("table") |
| |
| df_train = remove_post_churn_rows(df_train, spark_local, "table") |
| |
| df_train = prelim_feature_eng(df_train) |
| |
| df_train.createOrReplaceTempView("table") |
| |
| df_melt = melt_data(df_train, spark_local, "table") |
| df_melt = location_feature_eng(df_melt, census) |
📌 查看数据特征
| pd_melt = df_melt . toPandas() |
| pd_melt . describe() |
💡 进一步数据探索
① 流失率
| predictor = pd_melt['churn'].value_counts() |
| |
| print(predictor) |
| |
| plt.title('Churn distribution') |
| predictor.plot.pie(autopct='%.0f%%') |
| plt.show() |
② 数值vs类别型特征
| label = 'churn' |
| categorical = ['gender', 'level' , 'location', 'region', 'division'] |
| numerical = ['uniqueSongs', 'uniqueArtists', 'uniqueSongArtist', 'dayServiceLen', \ |
| 'countListen', 'countSession', 'lengthListen', 'countListenDiff', 'countSessionDiff',\ |
| 'lengthListenDiff', 'lengthListenPerDay', 'countListenPerDay',\ |
| 'sessionPerDay', 'lengthPerListen', 'lengthPerSession'] |
| |
| plt.title('Distribution of numerical/categorical features') |
| plt.pie([len(categorical), len(numerical)], labels=['categorical', 'numerical'], autopct='%.0f%%') |
| plt.show() |
在我们所有的特征中,25% 是类别型的。
③ 数值型特征分布
📌 数值特征&流失分布
| def plot_distribution(df, hue, filter_col=None, bins='auto'): |
| ''' |
| Plots distribution of numerical columns |
| By default, exclude object, datetime, timedelta and bool types and only consider numerical columns |
| @param df (DataFrame) - dataset |
| @param hue (str) - column of dataset to apply hue (useful for classification) |
| @param filter_col (array) - optional argument, features to be included in plot |
| @param bins (int) - defaults to auto for seaborn, sets number of bins of histograms |
| ''' |
| if filter_col == None: |
| filter_col = df.select_dtypes(exclude=['object', 'datetime', 'timedelta', 'bool']).columns |
| num_cols = len(list(filter_col)) |
| width = 3 |
| height = num_cols // width if num_cols % width == 0 else num_cols // width + 1 |
| plt.figure(figsize=(18, height * 3)) |
| for i, col in zip(range(num_cols), filter_col): |
| plt.subplot(height, width, i + 1) |
| plt.xlabel(col) |
| plt.ylabel('Count') |
| plt.title(f'Distribution of {col}') |
| sns.histplot(df, x=col, hue=hue, element="step", stat="count", common_norm=False, bins=bins) |
| plt.tight_layout() |
| plt.show() |
| |
| |
| plot_distribution(pd_melt, 'churn', filter_col=numerical) |
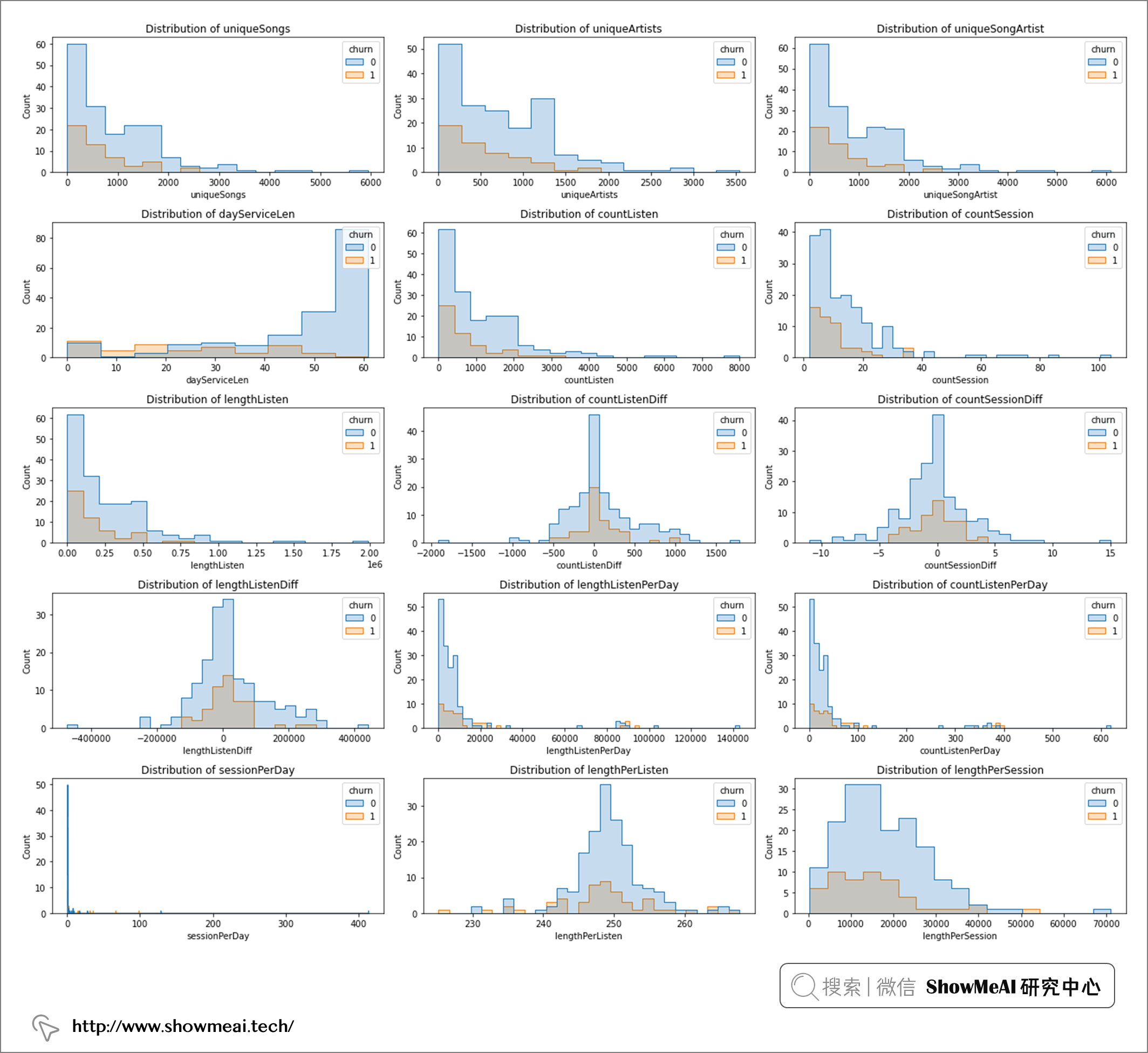
我们的数值型特征上可以看出:
- 流失与非流失用户都有右偏倾向的分布
dayServiceLen字段有最明显的流失客户和非流失客户分布差异。
📌 数值型特征相关度
| |
| numerical_churn = numerical + ['churn'] |
| |
| corr_data = pd_melt[numerical_churn].corr() |
| |
| |
| plt.figure(figsize=(16,16)) |
| plt.title('Heat map of correlation for all variables') |
| matrix = np.triu(corr_data) |
| sns.heatmap(corr_data, cmap='Blues', annot=True, mask=matrix) |
| plt.show() |
- 我们从热力图上没有看到有数值型特征与流失标签列有明显的高相关性。
- 有几组特征,uniqueArtists、uniqueSongArtist、countListen、countSession和lengthListen,它们之间有非常高的相关性。如果大家使用线性模型,可以考虑做特征选择,我们后续使用非线性模型的话,可以考虑保留。
④ 类别型特征的分布
| def plot_cat_distribution(data, colname): |
| ''' |
| Plots barplot for categorical columns and piechart showing proportions of churned vs non-churned customers |
| @param - data (panas dataframe) |
| @param - colname (str) - column of dataframe referenced |
| ''' |
| |
| plt.figure(figsize=(15,5)) |
| ax1 = plt.subplot(1, 3, 1) |
| tmp = data.copy() |
| tmp['count'] = 1 |
| x = tmp.groupby([colname, 'churn']).count().reset_index()[[colname, 'churn','count']] |
| |
| x = x.pivot(index='churn', columns=colname).transpose().reset_index().drop('level_0', axis=1) |
| x = x.fillna(0) |
| |
| plt.title(f'Distribution of {colname}') |
| plt.ylabel('Count') |
| x.plot.bar(x=colname, stacked=True, ax=ax1, color=['green', 'lightgreen']) |
| |
| ax2 = plt.subplot(1, 3, 2) |
| plt.title(f'Proportion of {colname} for churned customers') |
| plt.pie(x['Yes'], labels=x[colname], autopct='%.0f%%') |
| |
| plt.subplot(1, 3, 3) |
| plt.title(f'Proportion of {colname} for non-churned customers') |
| plt.pie(x['No'], labels=x[colname], autopct='%.0f%%') |
| |
| plt.tight_layout() |
| plt.show() |
| |
| x.index.rename('index', inplace=True) |
| print(x) |
| tmp_sum = x[['No','Yes']].sum(axis=1) |
| x['No'] = x['No'] / tmp_sum |
| x['Yes'] = x['Yes'] / tmp_sum |
| print(x) |
| print(tmp_sum / tmp_sum.sum()) |
| |
| |
| tmp_pd_melt = pd_melt.copy() |
| tmp_pd_melt['churn'] = tmp_pd_melt['churn'].apply(lambda x: 'Yes' if x == 1 else 'No') |
📌 性别&流失分布
| plot_cat_distribution(tmp_pd_melt, 'gender') |
流失客户的男性比例更高。
📌 等级&流失分布
| plot_cat_distribution(tmp_pd_melt, 'level') |
免费和付费客户的流失比例几乎没有差异(差2%),虽然图上表明付费客户流失的可能性稍小一点,但这个特征在建模过程中可能作用不大。
📌 地区&流失分布
| plot_cat_distribution(tmp_pd_melt, 'region') |
图上可以看出地区有一些差异,南部地区的流失要严重一些,相比之下北部地区的流失用户少一些。
可以进一步对地区细化和绘图
| plot_cat_distribution(tmp_pd_melt, 'division') |
📌 类别型特征取值数量分布
| def cardinality_plot(df, filter_col=None): |
| ''' |
| Input list of categorical variables to filter |
| Default is None where it would only consider columns which have type 'Object' |
| @param df (DataFrame) - dataset |
| @param filter_col (array) - optional argument to specify columns we want to filter |
| ''' |
| if filter_col == None: |
| filter_col = df.select_dtypes(include='object').columns |
| num_unique = [] |
| for col in filter_col: |
| num_unique.append(len(df[col].unique())) |
| plt.bar(list(filter_col), num_unique) |
| plt.title('Number of unique categorical variables') |
| plt.xlabel('Column name') |
| plt.ylabel('Num unique') |
| plt.xticks(rotation=90) |
| plt.yticks([0, 1, 2, 3, 4]) |
| plt.show() |
| return pd.Series(num_unique, index=filter_col).sort_values(ascending=False) |
| |
| cardinality_plot(pd_melt, categorical) |
直接看最喜欢的location,取值数量有点太多了,我们可以考虑用粗粒度的地理位置信息,可能区分能力会强一些。
下述部分,我们会使用spark进行特征工程&大数据建模与调优,相关内容可以阅读ShowMeAI的以下文章,我们对它的用法做了详细的讲解
💡 建模优化
我们先对数值型特征做一点小小的数据变换(这里用到的是log变换),这样我们的原始数值型特征分布可以得到一定程度的校正。
| def log_transform(df, columns): |
| ''' |
| Log trasform columns in dataframe |
| @df - spark dataframe |
| @columns - array of string of column names to be log transformed |
| returns updated spark dataframe |
| ''' |
| log_transform_func = F.udf(lambda x: np.log10(x + 1), FloatType()) |
| for col in columns: |
| df = df.withColumn(col, log_transform_func(df[col])) |
| return df |
| |
| |
| df_melt = log_transform(df_melt, numerical) |
① 数据切分
接下来我们把数据集拆分为 60:20:20 的3部分,分别用于训练、验证和测试。
| df_melt_copy = df_melt . withColumn("label", df_melt . churn) |
| rest, test = df_melt_copy.randomSplit([0.8, 0.2], seed=42) |
| train, val = rest.randomSplit([0.75, 0.25], seed=42) |
② 建模流水线
| |
| from pyspark.ml import Pipeline |
| from pyspark.ml.feature import VectorAssembler, StandardScaler, MinMaxScaler, OneHotEncoder, StringIndexer |
| from pyspark.ml.classification import LogisticRegression, RandomForestClassifier, GBTClassifier |
| from pyspark.ml.tuning import CrossValidator, ParamGridBuilder |
| |
| from sklearn.metrics import accuracy_score, f1_score, precision_score, recall_score, roc_auc_score |
| from sklearn.metrics import roc_curve, precision_recall_curve, confusion_matrix, ConfusionMatrixDisplay |
| |
| import re |
| |
| |
| numerical_assembler = VectorAssembler(inputCols=numerical, outputCol="numericalFeatures") |
| standardise = StandardScaler(inputCol="numericalFeatures", outputCol="standardNumFeatures", withStd=True, withMean=True) |
| minmax = MinMaxScaler(inputCol="standardNumFeatures", outputCol="minmaxNumFeatures") |
| |
| |
| inputCols = ['gender', 'level', 'region', 'division'] |
| outputColsIndexer = [x + 'SI' for x in inputCols] |
| indexer = StringIndexer(inputCols = inputCols, outputCols=outputColsIndexer) |
| outputColsOH = [x + 'OH' for x in inputCols] |
| onehot = OneHotEncoder(inputCols=outputColsIndexer, outputCols=outputColsOH) |
| categorical_assembler = VectorAssembler(inputCols=outputColsOH, outputCol="categoricalFeatures") |
| |
| |
| total_assembler = VectorAssembler(inputCols=['minmaxNumFeatures', 'categoricalFeatures'], outputCol='features') |
| pipeline = Pipeline(stages=[numerical_assembler, standardise, minmax, indexer, onehot, categorical_assembler, total_assembler]) |
| |
| pipeline . fit(train) . transform(train) . head() |
得到如下结果
| Row(userId='10', gender='M', level='paid', location='Laurel, MS', uniqueSongs=629, uniqueArtists=565, uniqueSongArtist=633, churn=0, dayServiceLen=42.43672561645508, countListen=673, countSession=6, lengthListen=166866.37250999993, countListenDiff=-203, countSessionDiff=2, lengthListenDiff=-48180.54478999992, lengthListenPerDay=3932.121766842835, countListenPerDay=15.858904998528928, sessionPerDay=0.14138696878331883, lengthPerListen=247.94408991084686, lengthPerSession=27811.062084999987, region='South', division='East South Central', label=0, numericalFeatures=DenseVector([629.0, 565.0, 633.0, 42.4367, 673.0, 6.0, 166866.3725, -203.0, 2.0, -48180.5448, 3932.1218, 15.8589, 0.1414, 247.9441, 27811.0621]), standardNumFeatures=DenseVector([-0.3973, -0.331, -0.3968, -0.016, -0.3968, -0.6026, -0.3993, -0.6779, 0.6836, -0.6549, -0.3678, -0.3625, -0.1256, -0.1374, 1.1354]), minmaxNumFeatures=DenseVector([0.1053, 0.1587, 0.1034, 0.6957, 0.0838, 0.0392, 0.0835, 0.5701, 0.5, 0.5692, 0.0264, 0.0245, 0.0002, 0.5344, 0.56]), genderSI=0.0, levelSI=1.0, regionSI=0.0, divisionSI=4.0, genderOH=SparseVector(1, {0: 1.0}), levelOH=SparseVector(1, {}), regionOH=SparseVector(3, {0: 1.0}), divisionOH=SparseVector(8, {4: 1.0}), categoricalFeatures=SparseVector(13, {0: 1.0, 2: 1.0, 9: 1.0}), features=DenseVector([0.1053, 0.1587, 0.1034, 0.6957, 0.0838, 0.0392, 0.0835, 0.5701, 0.5, 0.5692, 0.0264, 0.0245, 0.0002, 0.5344, 0.56, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0])) |
③ 初步建模&评估
我们先定义一个模型评估函数,因为是类别非均衡场景,我们这里覆盖比较多的评估准则,包括常用的precision、recall以及排序准则auc等。
| |
| def evaluate_model(y_trueTrain, y_predTrain, y_trueTest, y_predTest, y_testProba): |
| ''' |
| Wrapper function for evaluating classification results |
| ''' |
| train_acc = accuracy_score(y_trueTrain, y_predTrain) |
| test_acc = accuracy_score(y_trueTest, y_predTest) |
| fscore = f1_score(y_trueTest, y_predTest, zero_division=0) |
| precision = precision_score(y_trueTest, y_predTest, zero_division=0) |
| recall = recall_score(y_trueTest, y_predTest, zero_division=0) |
| |
| try: |
| roc_auc = roc_auc_score(y_trueTest, y_testProba) |
| except: |
| roc_auc = 0 |
| return { |
| 'train_acc': train_acc, |
| 'test_acc' : test_acc, |
| 'fscore': fscore, |
| 'precision': precision, |
| 'recall': recall, |
| 'roc_auc': roc_auc |
| } |
📌 逻辑回归
| |
| lr = LogisticRegression(maxIter=10, regParam=0.0, elasticNetParam=0) |
| pipeline_lr = Pipeline(stages=[numerical_assembler, standardise, minmax, indexer, onehot, categorical_assembler, total_assembler, lr]) |
| |
| |
| lrModel = pipeline_lr.fit(train) |
| lr_res_test = lrModel.transform(val).select('label', 'prediction', 'probability').toPandas() |
| lr_res_train = lrModel.transform(train).select('label', 'prediction', 'probability').toPandas() |
| |
| |
| lr_results = evaluate_model(lr_res_train['label'],lr_res_train['prediction'],lr_res_test['label'],lr_res_test['prediction'], lr_res_test['probability'].apply(lambda x: x[1])) |
| lr_results |
结果如下
| {'train_acc': 0.8456375838926175, |
| 'test_acc': 0.8780487804878049, |
| 'fscore': 0.7368421052631579, |
| 'precision': 0.5833333333333334, |
| 'recall': 1.0, |
| 'roc_auc': 0.9579831932773109} |
📌 梯度提升树GBT
| |
| gbt = GBTClassifier() |
| pipeline_gbt = Pipeline(stages=[numerical_assembler, standardise, minmax, indexer, onehot, categorical_assembler, total_assembler, gbt]) |
| |
| |
| gbtModel = pipeline_gbt.fit(train) |
| gbt_res_test = gbtModel.transform(val).select('label', 'prediction', 'probability').toPandas() |
| gbt_res_train = gbtModel.transform(train).select('label', 'prediction', 'probability').toPandas() |
| |
| |
| gbt_results = evaluate_model(gbt_res_train['label'],gbt_res_train['prediction'],gbt_res_test['label'],gbt_res_test['prediction'],\ |
| gbt_res_test['probability'].apply(lambda x: x[1])) |
| gbt_results |
结果如下
| {'train_acc': 1.0, |
| 'test_acc': 0.8048780487804879, |
| 'fscore': 0.6, |
| 'precision': 0.46153846153846156, |
| 'recall': 0.8571428571428571, |
| 'roc_auc': 0.8193277310924371} |
📌 随机森林
| |
| rf = RandomForestClassifier() |
| pipeline_rf = Pipeline(stages=[numerical_assembler, standardise, minmax, indexer, onehot, categorical_assembler, total_assembler, rf]) |
| |
| |
| rfModel = pipeline_rf.fit(train) |
| rf_res_test = rfModel.transform(val).select('label', 'prediction', 'probability').toPandas() |
| rf_res_train = rfModel.transform(train).select('label', 'prediction', 'probability').toPandas() |
| |
| |
| rf_results = evaluate_model(rf_res_train['label'],rf_res_train['prediction'],rf_res_test['label'],rf_res_test['prediction'], rf_res_test['probability'].apply(lambda x: x[1])) |
| rf_results |
结果如下
| {'train_acc': 0.959731543624161, |
| 'test_acc': 0.8780487804878049, |
| 'fscore': 0.6666666666666666, |
| 'precision': 0.625, |
| 'recall': 0.7142857142857143, |
| 'roc_auc': 0.9243697478991597} |
📌 综合对比
| cv_results = pd.DataFrame(columns=['accuracy_train','accuracy_cv','fscore_cv','precision_cv','recall_cv', 'roc_auc_cv']) |
| cv_results.loc['LogisticRegression'] = lr_results.values() |
| cv_results.loc['GradientBoostingTree'] = gbt_results.values() |
| cv_results.loc['RandomForest'] = rf_results.values() |
| |
| cv_results.style.apply(lambda x: ["background: lightgreen" if abs(v) == max(x) else "" for v in x], axis = 0) |
综合对比结果如下:
我们在上述建模与评估过程中,综合对比了训练集和验证集的结果。关于评估准则:
- accuracy通常不是衡量类别非均衡场景下的分类好指标。 极端的情况下,仅预测我们所有的客户“不流失”就达到 77% 的accuracy。
- recall衡量我们的正样本中有多少被模型预估为正样本,即
TP / (TP + FN),我们上述建模过程中,LogisticRegression正确识别所有会流失的客户。
- recall还需要结合precision一起看,例如,上述
LogisticRegression预估的流失客户中,只有 58% 真正流失了。 (这意味着如果我们要开展营销活动来解决客户流失问题,有42% (1 - 0.58) 的成本会浪费在未流失客户身上)。
- 可以使用 fscore 指标来综合考虑recall和precision。
- ROC_AUC 衡量我们的真阳性与假阳性率。 我们的 AUC 越高,模型在区分正类和负类方面的性能就越好。
上述指标中,我们优先关注ROC_AUC,其次是 fscore,我们上述指标中LogisticRegression效果良好,下面我们基于它进一步调优。
④ 超参数调优
📌 交叉验证
我们上面的建模只是敲定了一组超参数,超参数会影响模型的最终效果,我们可以使用spark的CrossValidator进行超参数调优,选出最优的超参数。
| paramGrid = ParamGridBuilder() \ |
| .addGrid(lr.regParam,[0.0, 0.1]) \ |
| .addGrid(lr.maxIter,[50, 100]) \ |
| .build() |
| |
| crossval = CrossValidator(estimator=pipeline_lr, |
| estimatorParamMaps=paramGrid, |
| evaluator=MulticlassClassificationEvaluator(), |
| numFolds=3) |
| |
| |
| cvModel = crossval . fit(rest) |
| cvModel . avgMetrics |
输出结果如下
| [0.8011084544393228, |
| 0.8222872837788751, |
| 0.7284659848286738, |
| 0.7284659848286738] |
我们对测试集做评估
| |
| cv_res_test = cvModel.transform(test).select('label', 'prediction', 'probability').toPandas() |
| cv_res_train = cvModel.transform(rest).select('label', 'prediction', 'probability').toPandas() |
| cv_metrics = evaluate_model(cv_res_train['label'],cv_res_train['prediction'],cv_res_test['label'],cv_res_test['prediction'], cv_res_test['probability'].apply(lambda x: x[1])) |
| |
| cv_metrics |
| {'train_acc': 0.8894736842105263, |
| 'test_acc': 0.8571428571428571, |
| 'fscore': 0.7368421052631577, |
| 'precision': 0.7, |
| 'recall': 0.7777777777777778, |
| 'roc_auc': 0.858974358974359} |
📌 最优超参数
| cvModel . getEstimatorParamMaps()[np . argmax(cvModel . avgMetrics)] |
| |
| {Param(parent='LogisticRegression_e765de70ec6a', name='regParam', doc='regularization parameter (>= 0).'): 0.0, |
| Param(parent='LogisticRegression_e765de70ec6a', name='maxIter', doc='max number of iterations (>= 0).'): 100} |
💡 结果评估
我们的 ROC_AUC 从 95.7 下降到 85.9。 这并不奇怪,因为我怀疑 95.7 的结果是由于过度拟合造成的。
| {'train_acc': 0.8894736842105263, |
| 'test_acc': 0.8571428571428571, |
| 'fscore': 0.7368421052631577, |
| 'precision': 0.7, |
| 'recall': 0.7777777777777778, |
| 'roc_auc': 0.858974358974359} |
最好的参数是 regParam为 0 和 maxIter100 个。
① 混淆矩阵
我们定一个函数来绘制一下混淆矩阵(即对正负样本和预估结果划分4个象限进行评估)。
| def plot_confusion_matrix(y_true, y_pred, title): |
| ''' |
| Plots confusion matrix |
| @param y_true - array of actual labels |
| @param y_pred - array of predictions |
| @title title - string of title |
| ''' |
| conf_matrix = confusion_matrix(y_true, y_pred) |
| matrix_display = ConfusionMatrixDisplay(confusion_matrix=conf_matrix, display_labels=["No Churn", "Churn"]) |
| matrix_display.plot(cmap='Greens') |
| |
| matrix_display.ax_.set_title(title) |
| plt.grid(False) |
| plt.show() |
| |
| |
| tn = conf_matrix[0][0] |
| tp = conf_matrix[1][1] |
| fn = conf_matrix[1][0] |
| fp = conf_matrix[0][1] |
| print(f'True Positive Rate/Recall/Sensitivity: {round(tp/(tp+fn), 6)}') |
| |
| print(f'False Positive Rate/(1 - Specificity): {round(fp/(tn+fp), 6)}') |
| print(f'Precision : {round(tp/(tp+fp), 6)}') |
| |
| |
| plot_confusion_matrix(cv_res_test['label'], cv_res_test['prediction'], "Confusion matrix at 50% threshold (default)") |
查看下面的混淆矩阵,用0.5的默认概率阈值能够正确预测 77.78% 的流失客户 (7/(7+2)),也具有 70% 的不错的precision (7/(7+3))
② ROC_AUC 曲线
| |
| test_proba = cv_res_test['probability'] . apply(lambda x: x[1]) |
| |
| |
| |
| fpr, tpr, _ = roc_curve(cv_res_test['label'], test_proba) |
| |
| |
| plt.figure(figsize=(10,8)) |
| plt.title('ROC AUC Curve for customer churn') |
| plt.xlabel('False Positive Rate (FPR)') |
| plt.ylabel('True Postive Rate (FPR) / Recall') |
| plt.plot(fpr, tpr, marker='.', label='LR') |
| plt.plot([0, 1], [0, 1]) |
| plt.show() |
下面的 ROC AUC 曲线清楚地显示了召回率(真阳性率)和假阳性率之间的权衡。
③ PR 曲线
| lr_precision, lr_recall, _ = precision_recall_curve(cv_res_test['label'], test_proba) |
| |
| plt.figure(figsize=(10,8)) |
| plt.title('Recall/Precision curve') |
| plt.xlabel('Recall') |
| plt.ylabel('Precision') |
| plt.plot(lr_recall, lr_precision, marker='.', label='LR') |
| plt.axhline(y=cv_metrics['precision'], color='r') |
| plt.axvline(x=cv_metrics['recall'], color='r') |
| plt.show() |
下面的召回/精度图中的交点代表了我们调整后的LogisticRegression模型的召回-精度。默认的50%的决策阈值得出了77.8%/70%的召回率-精确度的权衡。
通过调整我们的决策阈值,我们可以定制我们想要的召回/精确率。
💡 总结&业务思考
我们可以调整我们的决策(概率)阈值,以获得一个最满意的召回率或精确度。比如在我们的场景下,使用了0.72的阈值取代默认的0.5,结果是在召回率没有下降的基础上,提升了精度。
现实中,召回率和精确度之间肯定会有权衡,特别是当我们在比较大的数据集上建模应用时。
| def classify_custom_threshold(y_true, y_pred_proba, threshold=0.5): |
| ''' |
| Identifies custom threshold and plots confusion matrix |
| @y_true - array of actual labels |
| @y_pred_proba - array of probabilities of predictions |
| @threshold - decision threshold which is defaulted to 50% |
| ''' |
| y_pred = y_pred_proba >= threshold |
| plot_confusion_matrix(y_true, y_pred, f'Confusion matrix at {round(threshold * 100, 1)}% decision threshold') |
| |
| classify_custom_threshold(cv_res_test['label'], test_proba, 0.72) |
我们还需要与业务管理人员积极沟通,了解他们更有倾向性的指标(更看重precision还是recall):
- 优先考虑recall意味着我们能判断出大部分实际流失的客户,但这可能会降低精度,就像我们之前提到的,这可能会导致成本增加。
- 我们当前的结果已经很不错了,如果业务负责人想追求更高的召回率,并愿意为此花费一些成本,我们可以降低决策(概率)门槛。
举例来说,在我们当前的例子中,如果我们将决策判定概率从0.5降低到0.25,可以把召回率提升到88.9%,但随之发生变化的是精度降低到47%。
| lr_precision, lr_recall, _ = precision_recall_curve(cv_res_test['label'], test_proba) |
| |
| plt.figure(figsize=(10,8)) |
| plt.title('Recall/Precision curve') |
| plt.xlabel('Recall') |
| plt.ylabel('Precision') |
| plt.plot(lr_recall, lr_precision, marker='.', label='LR') |
| plt.axhline(y=cv_metrics['precision'], color='r', alpha=0.3) |
| plt.axvline(x=cv_metrics['recall'], color='r', alpha=0.3) |
| plt.axhline(y=0.470588, color='r') |
| plt.axvline(x=0.888889, color='r') |
| plt.show() |
| |
| classify_custom_threshold(cv_res_test['label'], test_proba, 0.25) |
参考资料


 如何在海量用户中精准预测哪些客户即将流失?本文结合音乐流媒体平台 Sparkify 数据,详细讲解一个客户流失建模预测案例的全流程:探索性数据分析 EDA、数据处理、进一步数据探索、建模优化、结果评估。【代码与数据集亲测可运行】
如何在海量用户中精准预测哪些客户即将流失?本文结合音乐流媒体平台 Sparkify 数据,详细讲解一个客户流失建模预测案例的全流程:探索性数据分析 EDA、数据处理、进一步数据探索、建模优化、结果评估。【代码与数据集亲测可运行】


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人