斯坦福NLP课程 | 第17讲 - 多任务学习(以问答系统为例)
 NLP课程第17讲介绍了问答系统(QA)、多任务学习、自然语言处理的十项全能(decaNLP)、多任务问答系统(MQAN)等。
NLP课程第17讲介绍了问答系统(QA)、多任务学习、自然语言处理的十项全能(decaNLP)、多任务问答系统(MQAN)等。

- 作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/36
- 本文地址:https://www.showmeai.tech/article-detail/254
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

ShowMeAI为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》课程的全部课件,做了中文翻译和注释,并制作成了GIF动图!视频和课件等资料的获取方式见文末。
1.问答系统与多任务学习
2.NLP与AI的下一步

3.单任务的弊端

- 鉴于\(\{dataset,task,model,metric\}\),近年来性能得到了很大改善
- 只要 \(|\text{dataset}| > 1000 \times C\),我们就可以得到当前的最优结果 (\(C\)是输出类别的个数)
- 对于更一般的 Al,我们需要在单个模型中继续学习
- 模型通常从随机开始,仅部分预训练
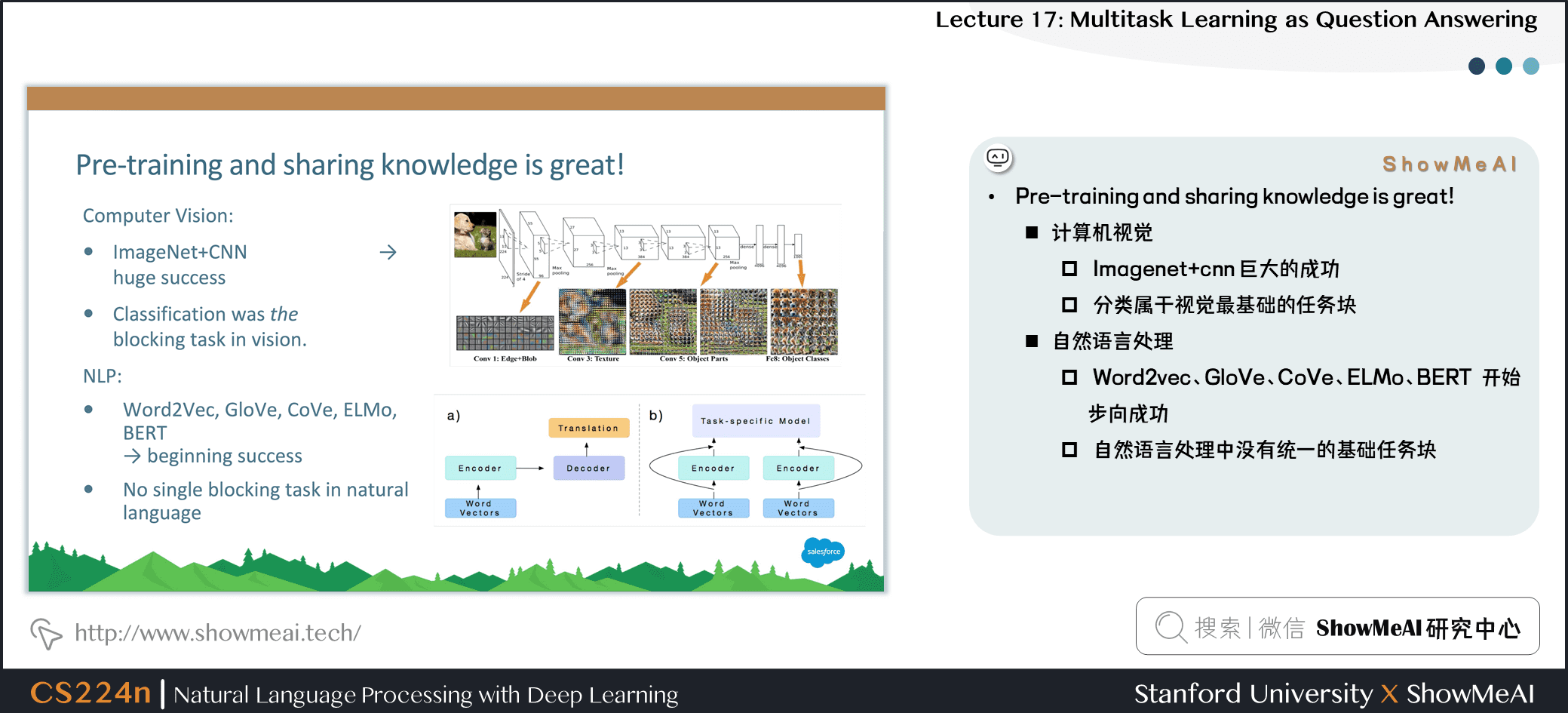
4.预训练与信息共享帮助很大
-
计算机视觉
- Imagenet+cnn 巨大的成功
- 分类属于视觉最基础的任务块
-
自然语言处理
- Word2vec、GloVe、CoVe、ELMo、BERT 开始步向成功
- 自然语言处理中没有统一的基础任务块
5.为什么NLP中共享权重相对较少

- NLP 需要多种推理:逻辑,语言,情感,视觉,++
- 需要短期和长期记忆
- NLP 被分为中间任务和单独任务以取得进展
- 在每个社区中追逐基准
- 一个无人监督的任务可以解决所有问题吗?不可以
- 语言显然需要监督
6.为什么NLP也需要1个统一多任务模型

- 多任务学习是一般 NLP 系统的阻碍
- 统一模型可以决定如何转移知识(领域适应,权重分享,转移和零射击学习)
- 统一的多任务模型可以
- 更容易适应新任务
- 简化部署到生产的时间
- 降低标准,让更多人解决新任务
- 潜在地转向持续学习
7.如何在1个框架中承载多个NLP任务

- 序列标记
- 命名实体识别,aspect specific sentiment
- 文字分类
- 对话状态跟踪,情绪分类
- Seq2seq
- 机器翻译,总结,问答
8.NLP中的超级任务

- 语言模型
- 问答
- 对话
9.自然语言处理十项全能 (decaNLP)

- 把 10 项不同的任务都写成了 QA 的形式,进行训练与测试
10.问答多任务学习

- Meta-Supervised learning 元监督学习 :
From {x,y} to {x,t,y}(t is the task) - 使用问题 \(q\) 作为任务 \(t\) 的自然描述,以使模型使用语言信息来连接任务
- \(y\) 是 \(q\) 的答案,\(x\) 是回答 \(q\) 所必需的上下文
11.为decaNLP设计模型

- 需求:
- 没有任务特定的模块或参数,因为我们假设任务ID是未提供的
- 必须能够在内部进行调整以执行不同的任务
- 应该为看不见的任务留下零射击推断的可能性
12.decaNLP的1个多任务问答神经网络模型方案

- 以一段上下文开始
- 问一个问题
- 一次生成答案的一个单词,通过
- 指向上下文
- 指向问题
- 或者从额外的词汇表中选择一个单词
- 每个输出单词的指针切换都在这三个选项中切换
13.多任务问答网络 (MQAN)
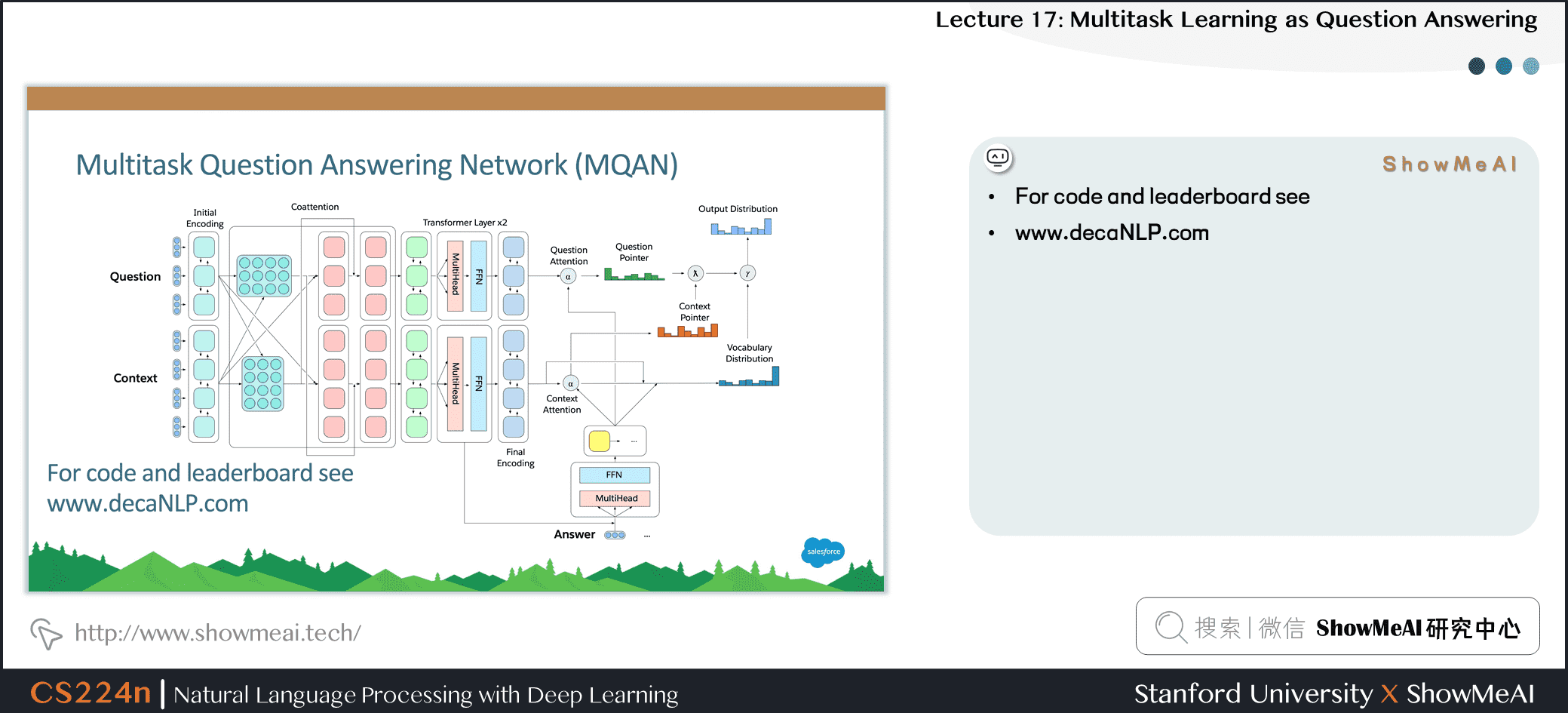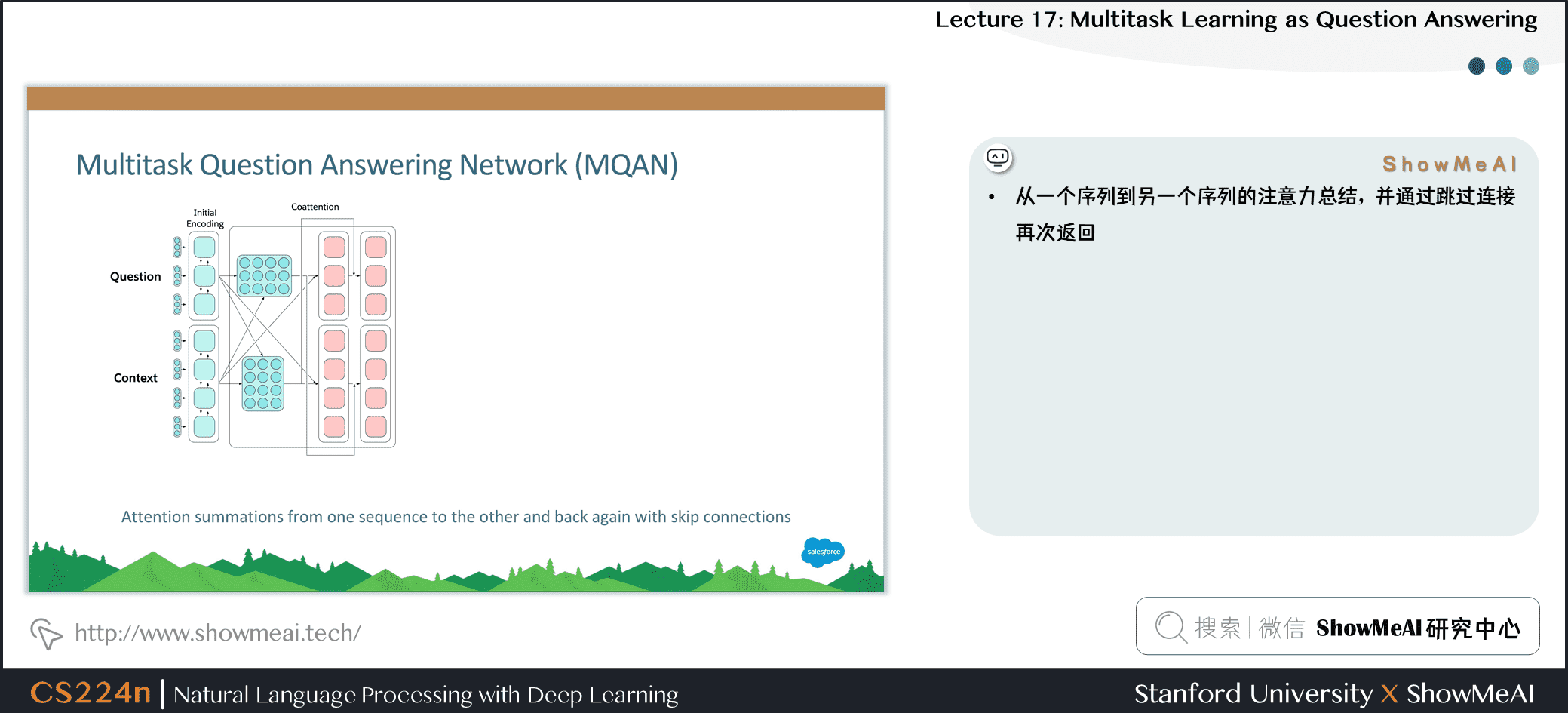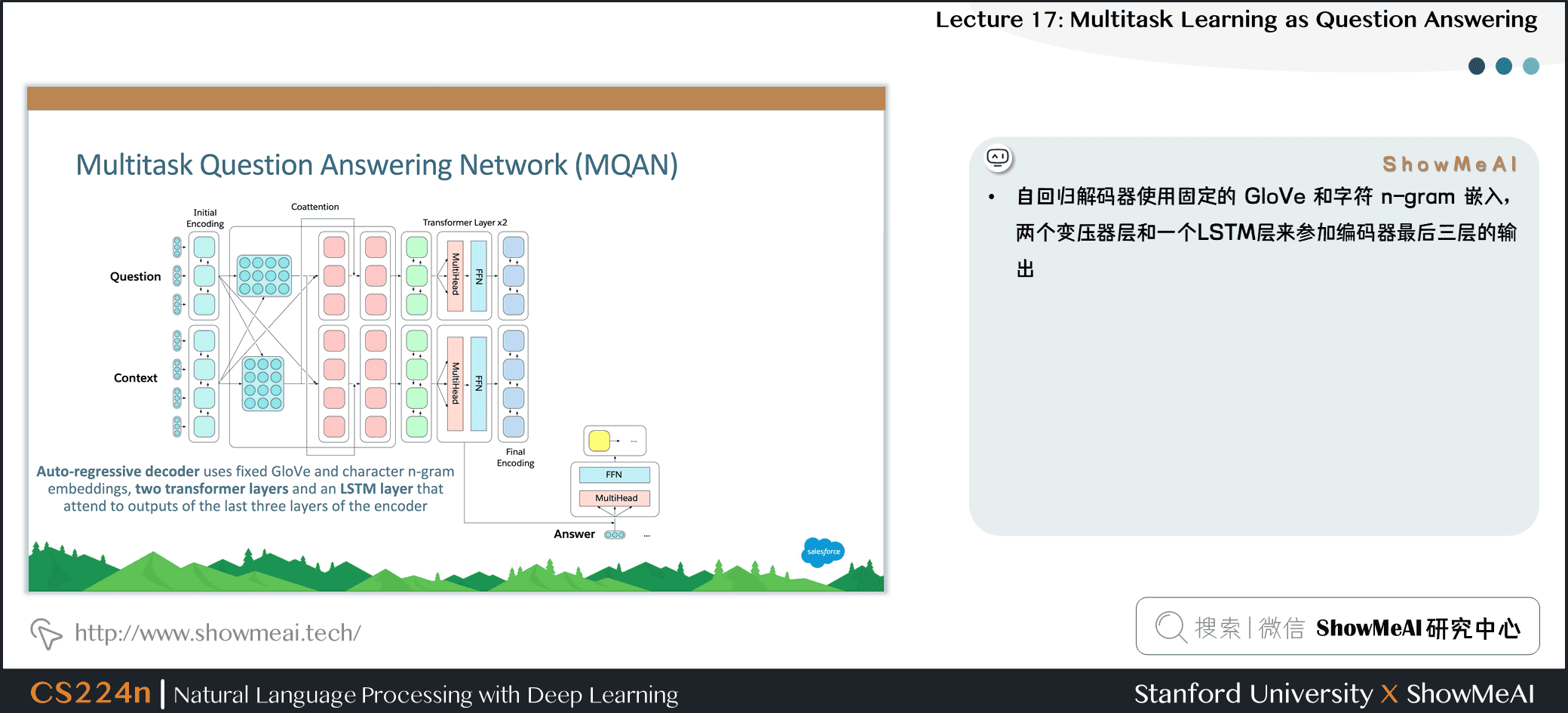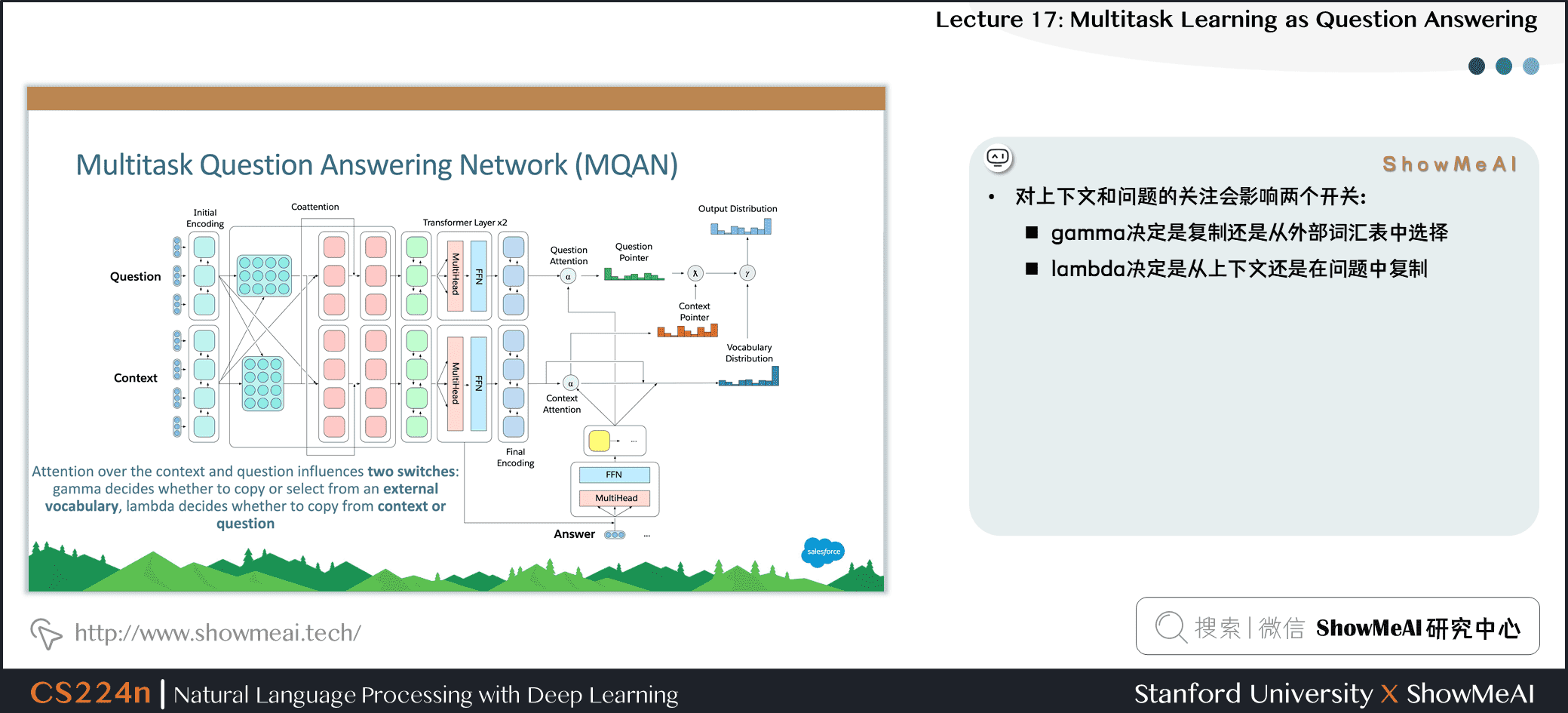
- 固定的 GloVe 词嵌入 + 字符级的 n-gram 嵌入→ Linear → Shared BiLSTM with skip connection
- 从一个序列到另一个序列的注意力总结,并通过跳过连接再次返回
- 分离BiLSTM以减少维数,两个变压器层,另一个BiLSTM
- 自回归解码器使用固定的 GloVe 和字符 n-gram 嵌入,两个变压器层和一个LSTM层来参加编码器最后三层的输出
- LSTM解码器状态用于计算上下文与问题中的被用作指针注意力分布问题
- 对上下文和问题的关注会影响两个开关:
- gamma 决定是复制还是从外部词汇表中选择
- lambda 决定是从上下文还是在问题中复制
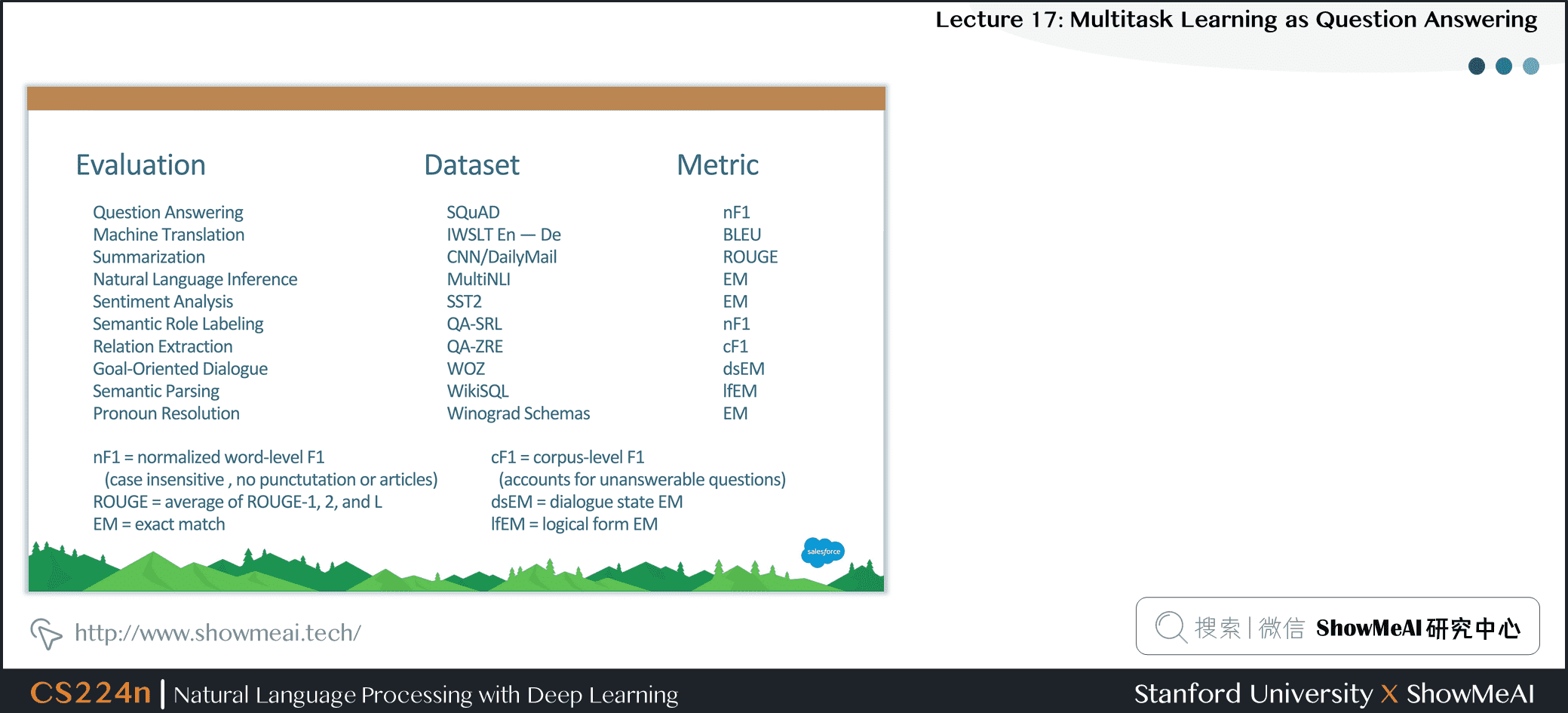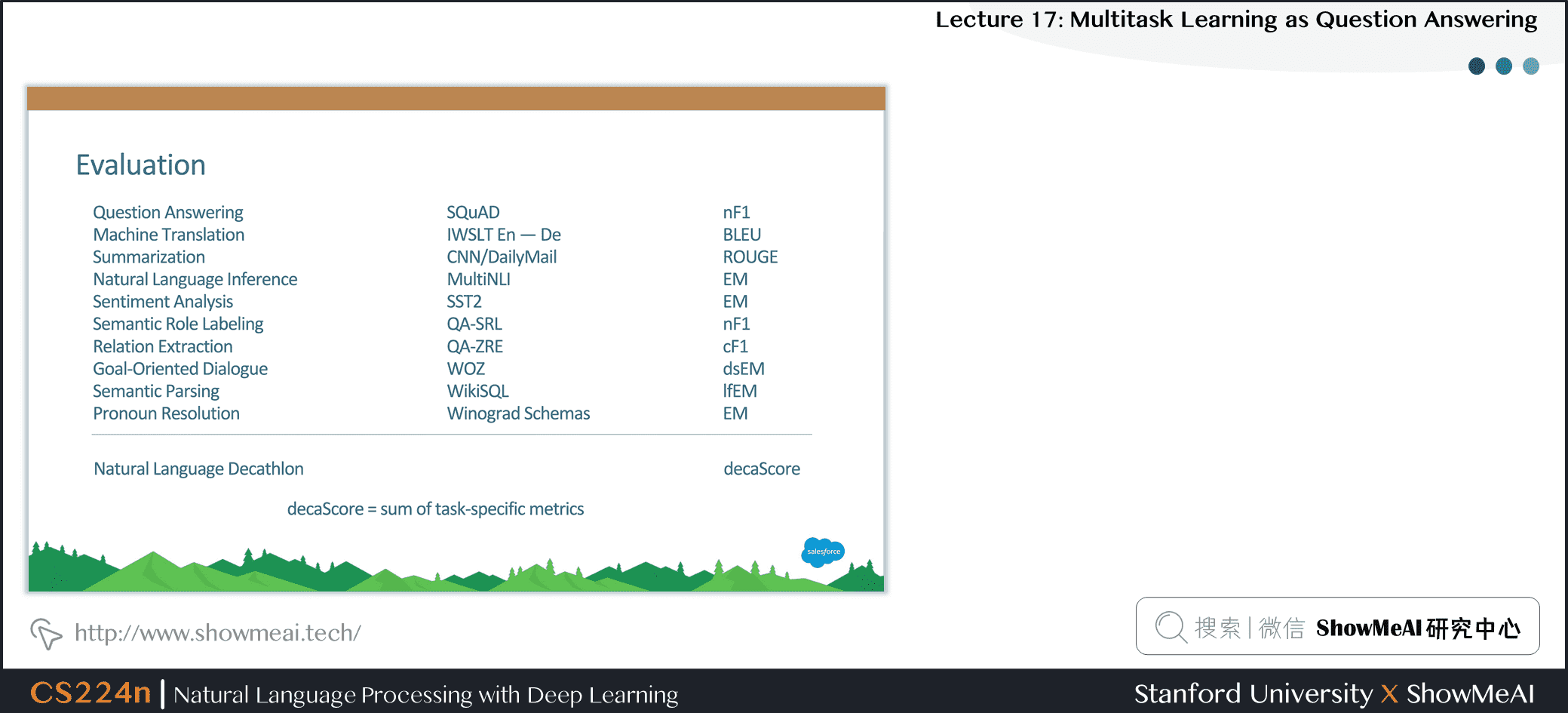
14.评估
15.单任务效果vs多任务效果

- S2S 是 seq2seq
- +SelfAtt = plus self attention
- +CoAtt = plus coattention
- +QPtr = plus question pointer == MQAN
- Transformer 层在单任务和多任务设置中有收益
- QA和SRL有很强的关联性
- 指向问题至关重要
- 多任务处理有助于实现零射击
- 组合的单任务模型和单个多任务模型之间存在差距
16.训练策略:全联合

- Training Strategies: Fully Joint
- 简单的全联合训练策略
- 困难:在单任务设置中收敛多少次迭代
- 带红色的任务:预训练阶段包含的任务
17.单任务vs多任务

- QA 的 Anti-curriculum 反课程预训练改进了完全联合培训
- 但MT仍然很糟糕
18.近期研究与实验

- Closing the Gap: Some Recent Experiments
19.单任务vs多任务

20.MQAN细节

- Where MQAN Points
- 答案从上下文或问题中正确的复制
- 没有混淆模型应该执行哪个任务或使用哪个输出空间
21.decaNLP预训练提升最后效果
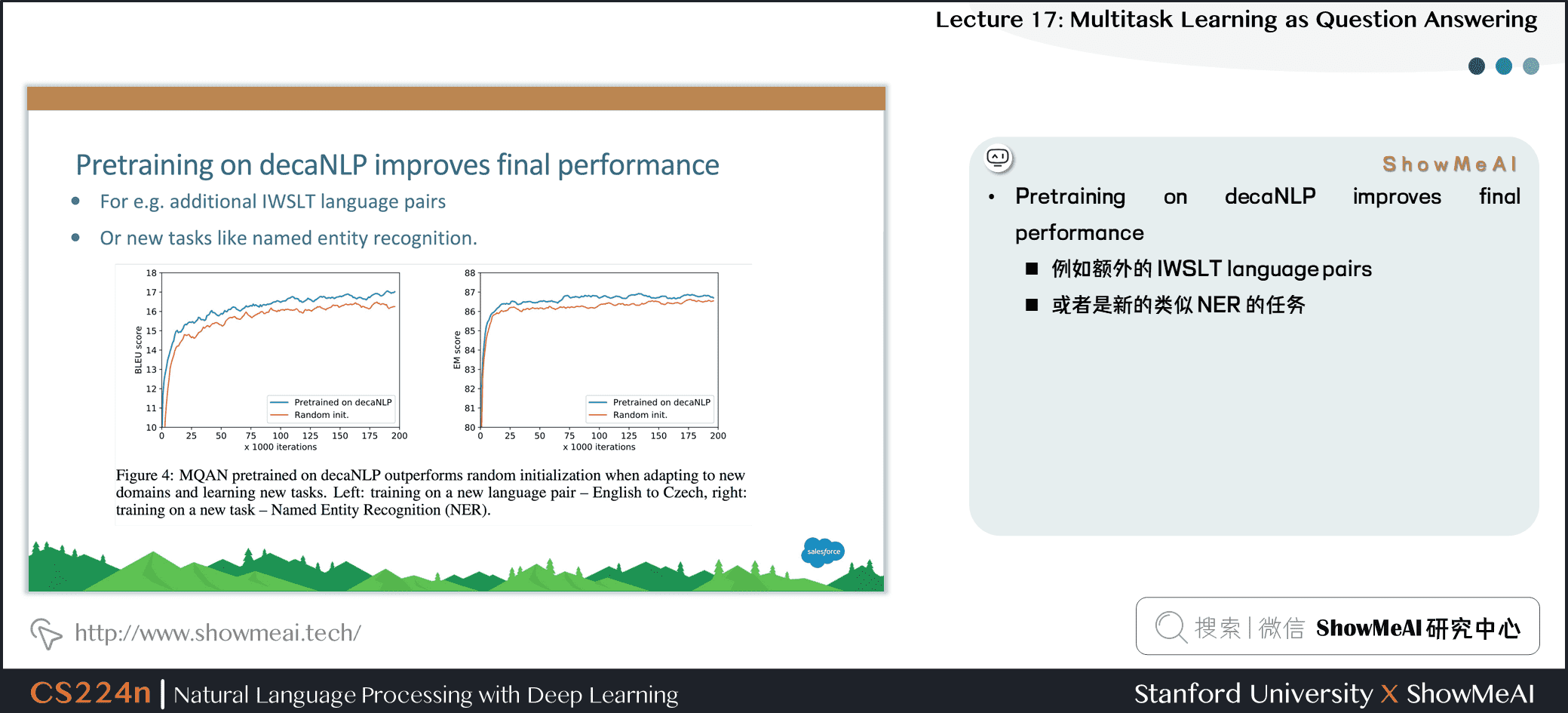
- Pretraining on decaNLP improves final performance
- 例如额外的 IWSLT language pairs
- 或者是新的类似 NER 的任务
22.预训练MQAN的零次学习任务域自适应

- Zero-Shot Domain Adaptation of pretrained MQAN:
- 在 Amazon and Yelp reviews 上获得了 80% 的 精确率
- 在 SNLI 上获得了 62% (参数微调的版本获得了 87% 的精确率,比使用随机初始化的高 2%)
23.零次学习(Zero-Shot)分类

- Zero-Shot Classification
- 问题指针使得我们可以处理问题的改变(例如,将标签转换为满意/支持和消极/悲伤/不支持)而无需任何额外的微调
- 使模型无需训练即可响应新任务
24.decaNLP:通用NLP任务效果基准

- decaNLP: A Benchmark for Generalized NLP
- 为多个NLP任务训练单问题回答模型
- 解决方案
- 更一般的语言理解
- 多任务学习
- 领域适应
- 迁移学习
- 权重分享,预训练,微调(对于NLP的ImageNet-CNN?)
- 零射击学习
25.相关研究与工作

26.NLP的下一步

27.视频教程
可以点击 B站 查看视频的【双语字幕】版本
[video(video-pX2WT17D-1652089964477)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=376755412&page=17)(image-https://img-blog.csdnimg.cn/img_convert/1a2cbea52bb63801e623a42862764eb1.png)(title-【双语字幕+资料下载】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲))]
28.参考资料
- 本讲带学的在线阅翻页本
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
- Stanford官网 | CS224n: Natural Language Processing with Deep Learning
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
NLP系列教程文章
- NLP教程(1)- 词向量、SVD分解与Word2vec
- NLP教程(2)- GloVe及词向量的训练与评估
- NLP教程(3)- 神经网络与反向传播
- NLP教程(4)- 句法分析与依存解析
- NLP教程(5)- 语言模型、RNN、GRU与LSTM
- NLP教程(6)- 神经机器翻译、seq2seq与注意力机制
- NLP教程(7)- 问答系统
- NLP教程(8)- NLP中的卷积神经网络
- NLP教程(9)- 句法分析与树形递归神经网络
斯坦福 CS224n 课程带学详解
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
- 斯坦福NLP课程 | 第3讲 - 神经网络知识回顾
- 斯坦福NLP课程 | 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP课程 | 第5讲 - 句法分析与依存解析
- 斯坦福NLP课程 | 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP课程 | 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP课程 | 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP课程 | 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP课程 | 第10讲 - NLP中的问答系统
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP课程 | 第12讲 - 子词模型
- 斯坦福NLP课程 | 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP课程 | 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
- 斯坦福NLP课程 | 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP课程 | 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP课程 | 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP课程 | 第19讲 - AI安全偏见与公平
- 斯坦福NLP课程 | 第20讲 - NLP与深度学习的未来


 浙公网安备 33010602011771号
浙公网安备 33010602011771号