
斯坦福NLP课程 | 第14讲 - Transformers自注意力与生成模型
 NLP课程第14讲介绍了Attention注意力机制、文本生成、自相似度、相对自注意力、图片与音乐生成、迁移学习等。
NLP课程第14讲介绍了Attention注意力机制、文本生成、自相似度、相对自注意力、图片与音乐生成、迁移学习等。

- 作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/36
- 本文地址:https://www.showmeai.tech/article-detail/251
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

ShowMeAI为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》课程的全部课件,做了中文翻译和注释,并制作成了GIF动图!视频和课件等资料的获取方式见文末。
引言

学习变长数据的表示

- 学习变长数据的表示,这是序列学习的基本组件
- 序列学习包括 NMT,text summarization,QA,···
1.循环神经网络(RNN)

- 通常使用 RNN 学习变长的表示
- RNN 本身适合句子和像素序列
- LSTMs, GRUs 和其变体在循环模型中占主导地位
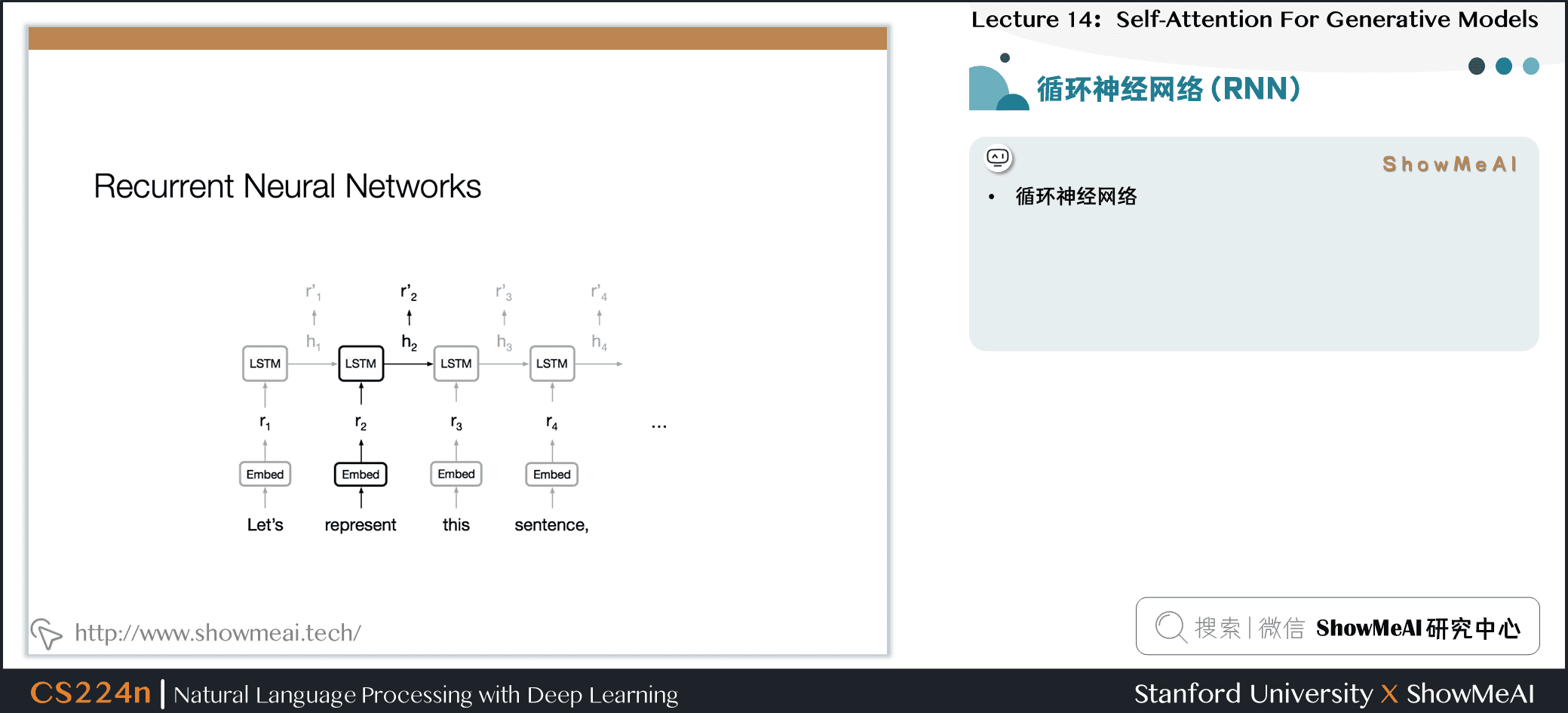

- 但是序列计算抑制了并行化
- 没有对长期和短期依赖关系进行显式建模
- 我们想要对层次结构建模
- RNNs(顺序对齐的状态)看起来很浪费!
2.卷积神经网络(CNN)
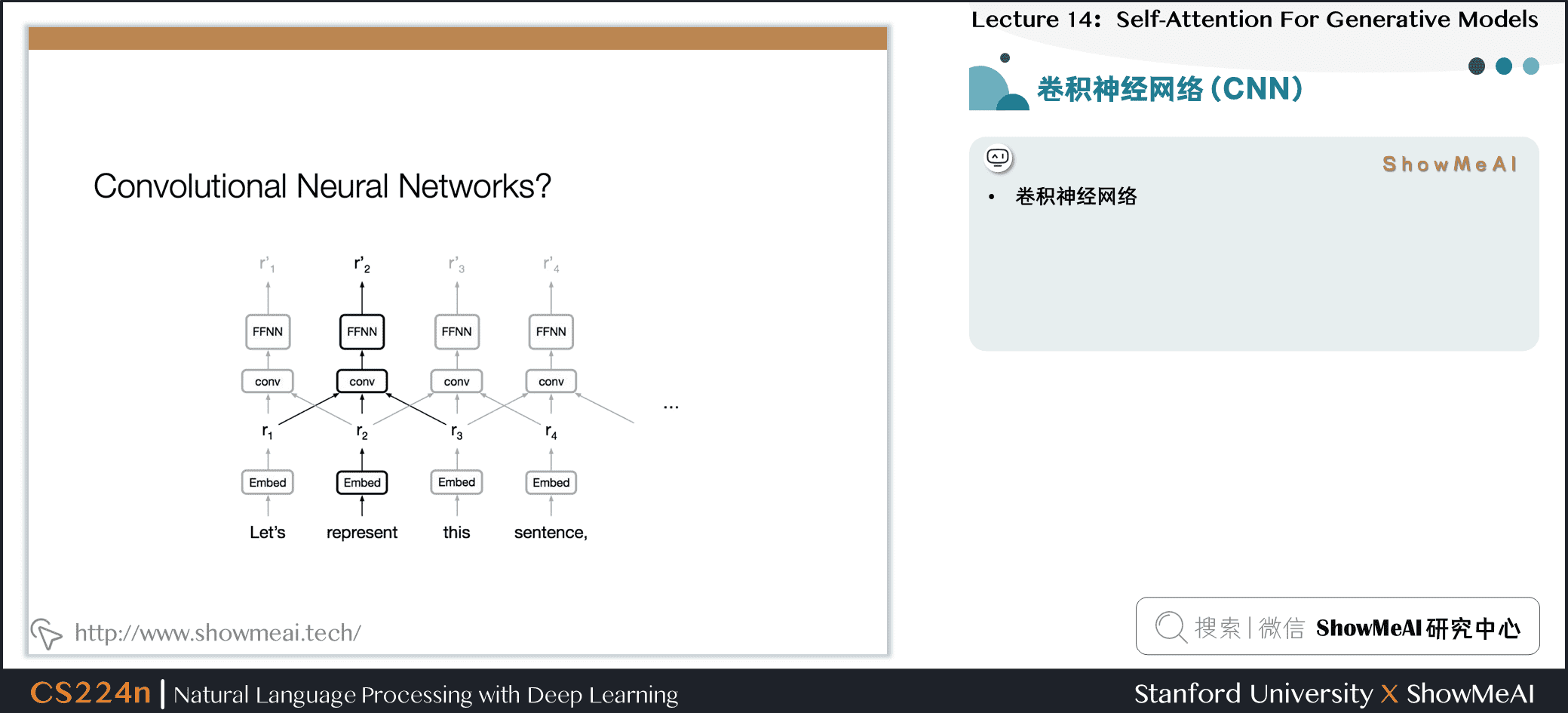
- 并行化(每层)很简单
- 利用局部依赖
- 不同位置的交互距离是线性或是对数的
- 远程依赖需要多层
3.Attention 注意力
- NMT 中,编码器和解码器之间的 Attention 是至关重要的
- 为什么不把注意力用于表示呢?
3.1 自注意力
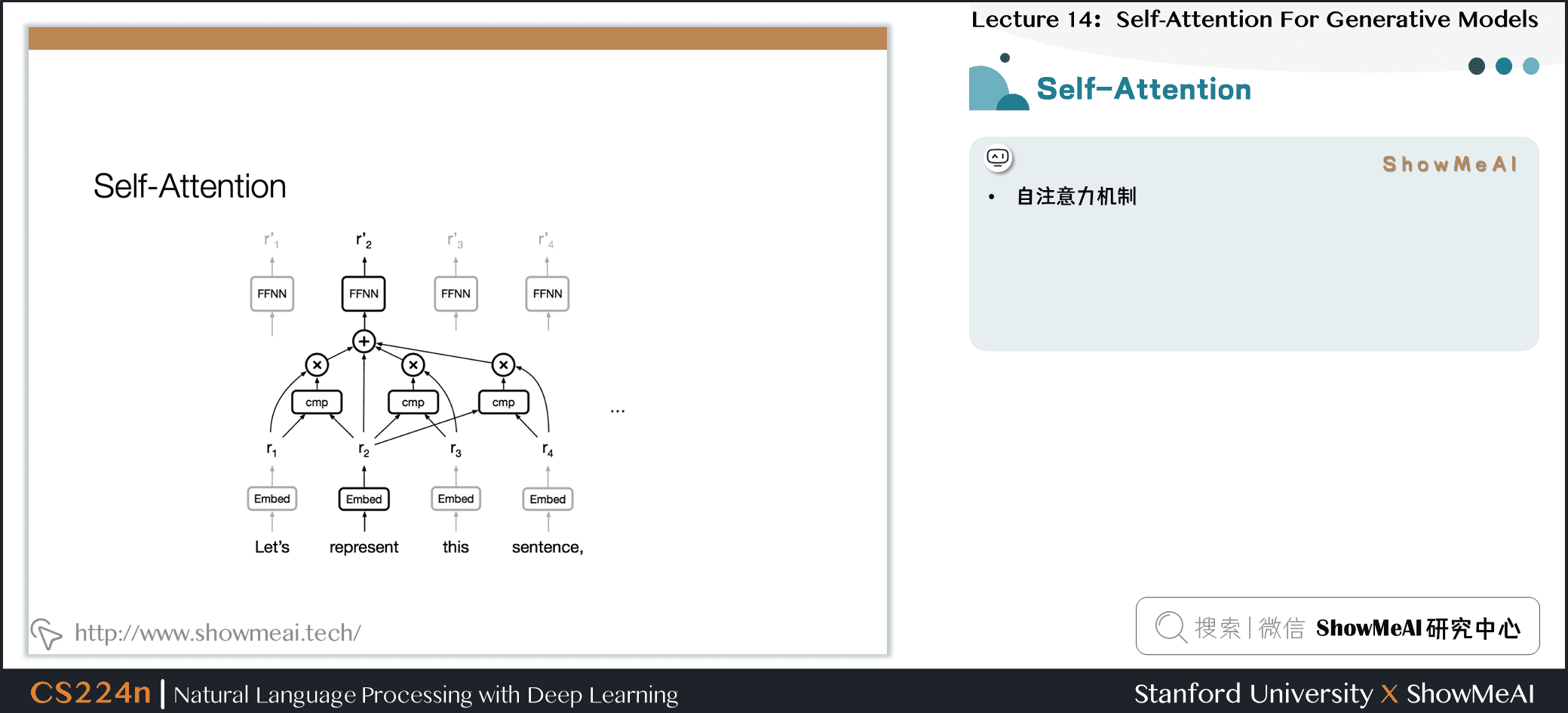
- 自注意力机制
4.文本生成

4.1 自注意力
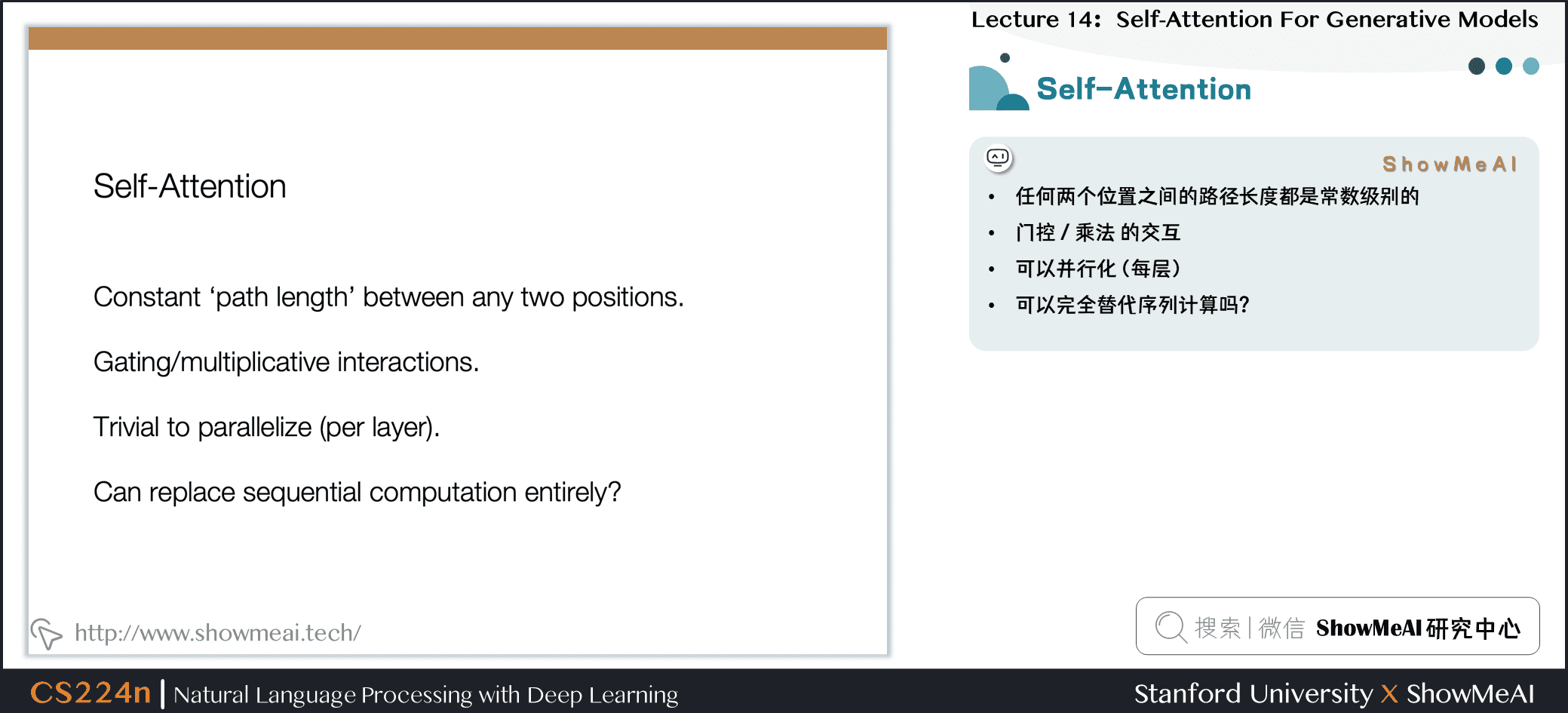
- 任何两个位置之间的路径长度都是常数级别的
- 门控 / 乘法 的交互
- 可以并行化(每层)
- 可以完全替代序列计算吗?
4.2 既有成果
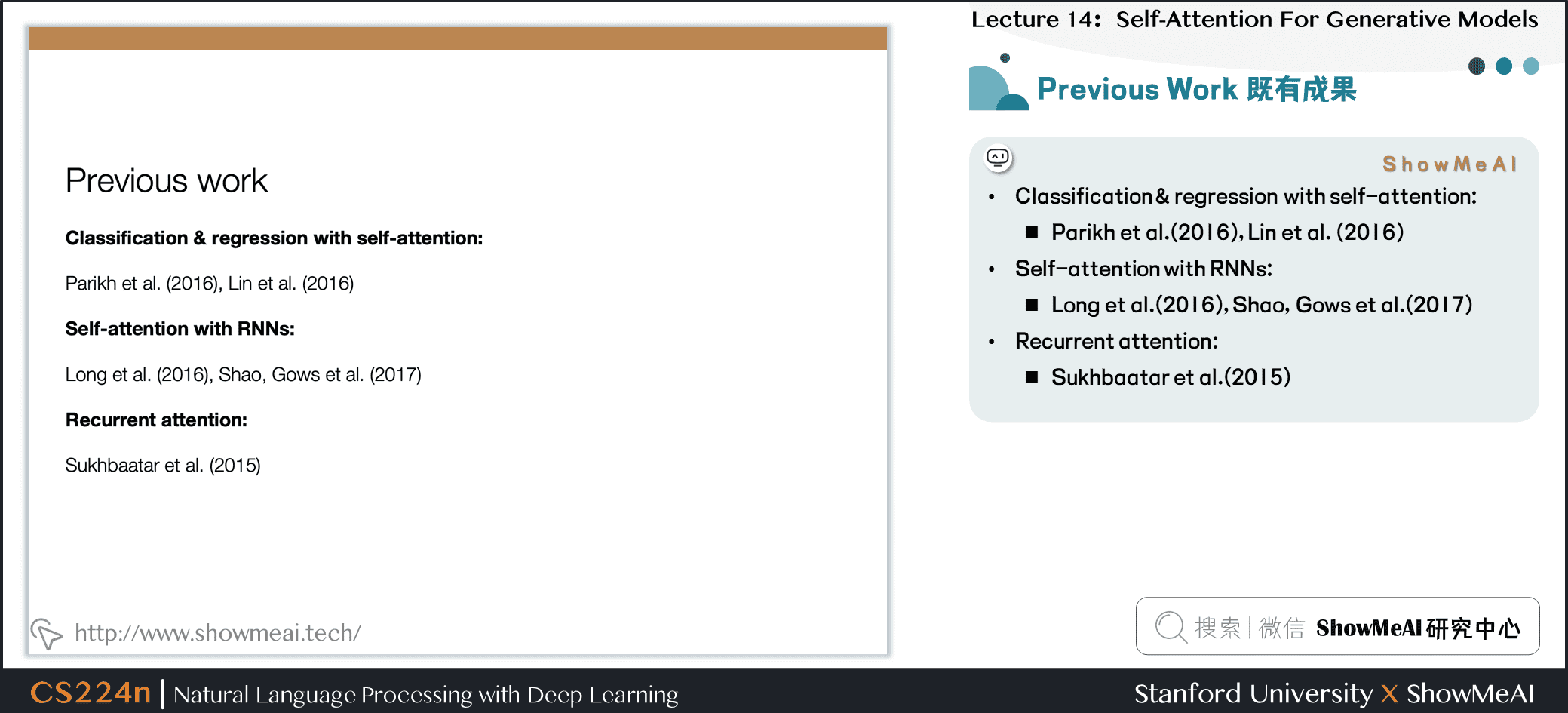
- Classification & regression with self-attention:
- Parikh et al.(2016), Lin et al. (2016)
- Self-attention with RNNs:
- Long et al.(2016), Shao, Gows et al.(2017)
- Recurrent attention:
- Sukhbaatar et al.(2015)
4.3 Transformer
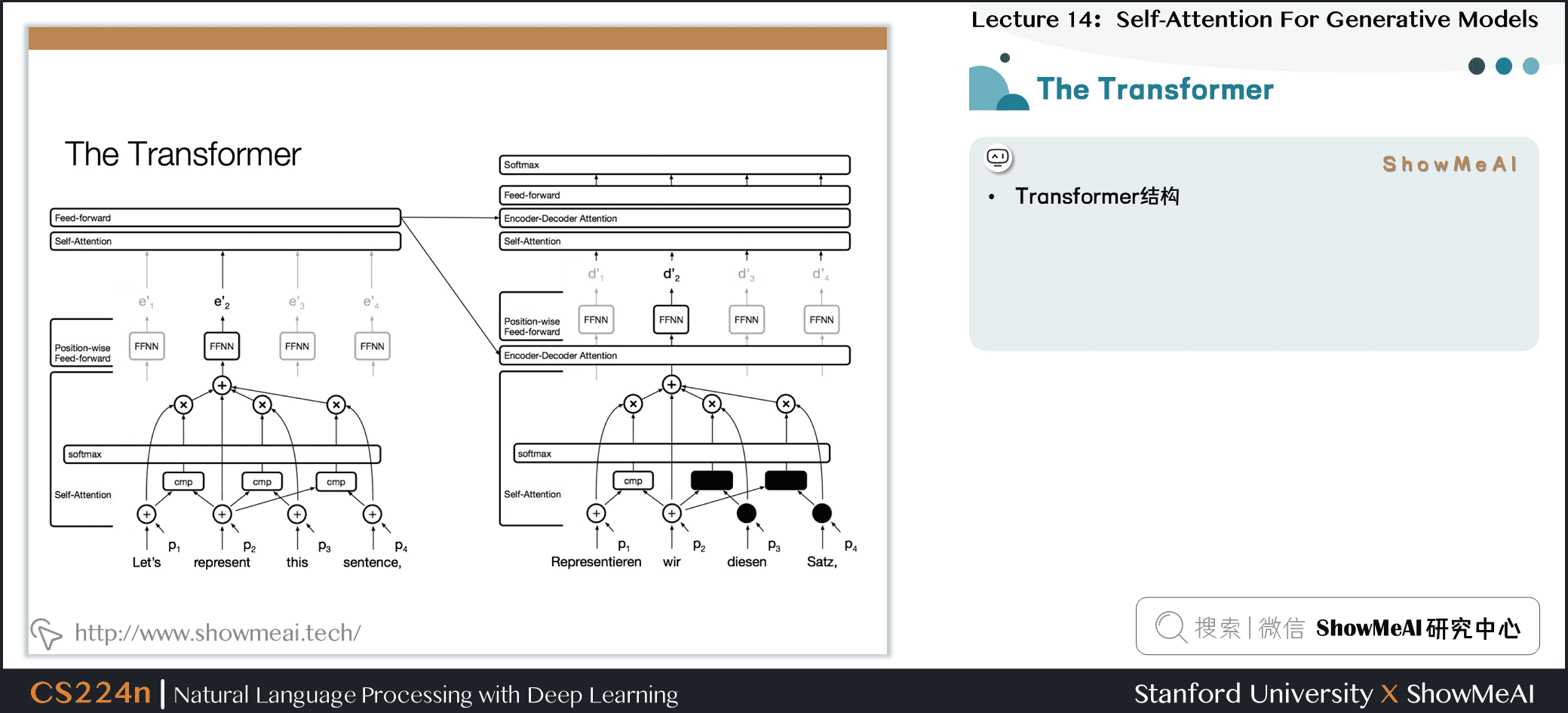
- Transformer结构
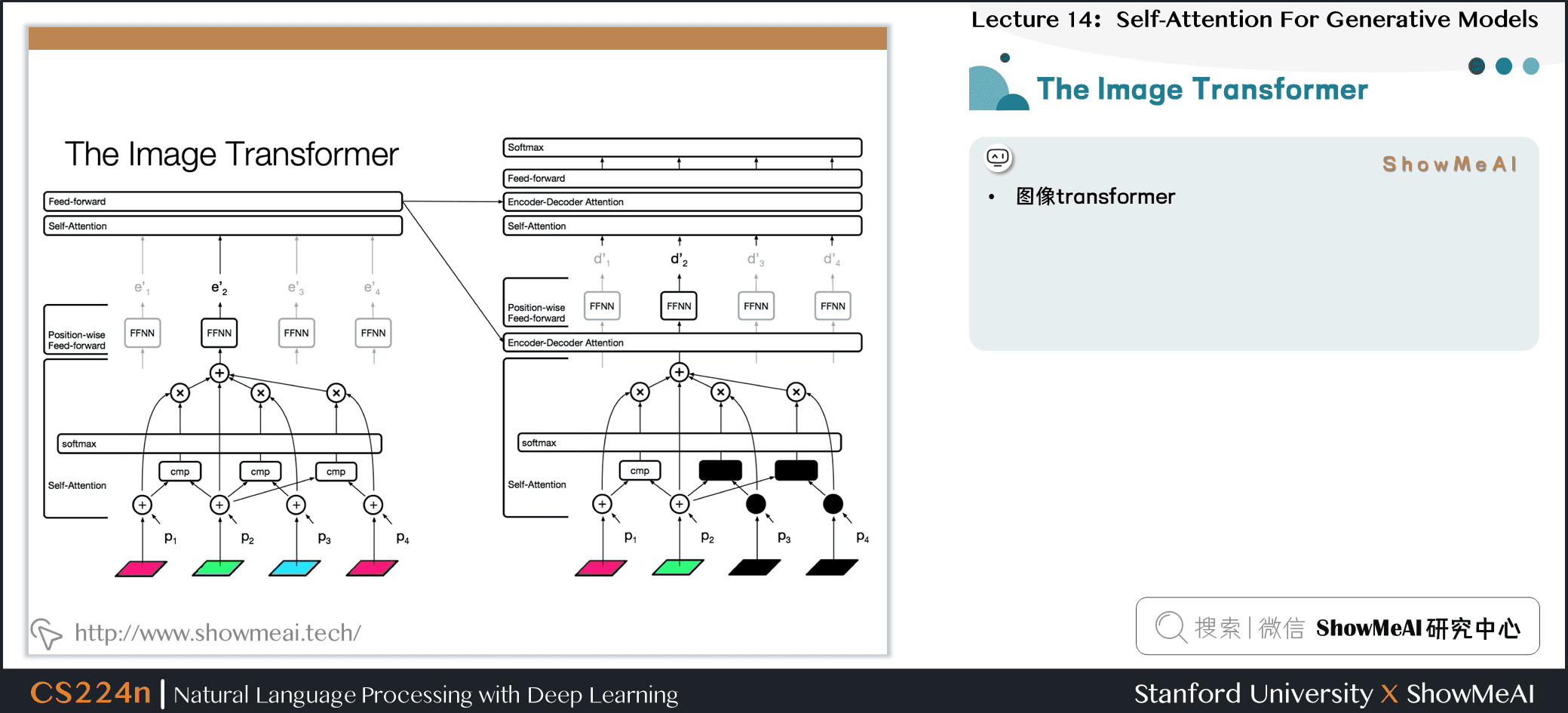
4.4 编码器与解码器的自注意力
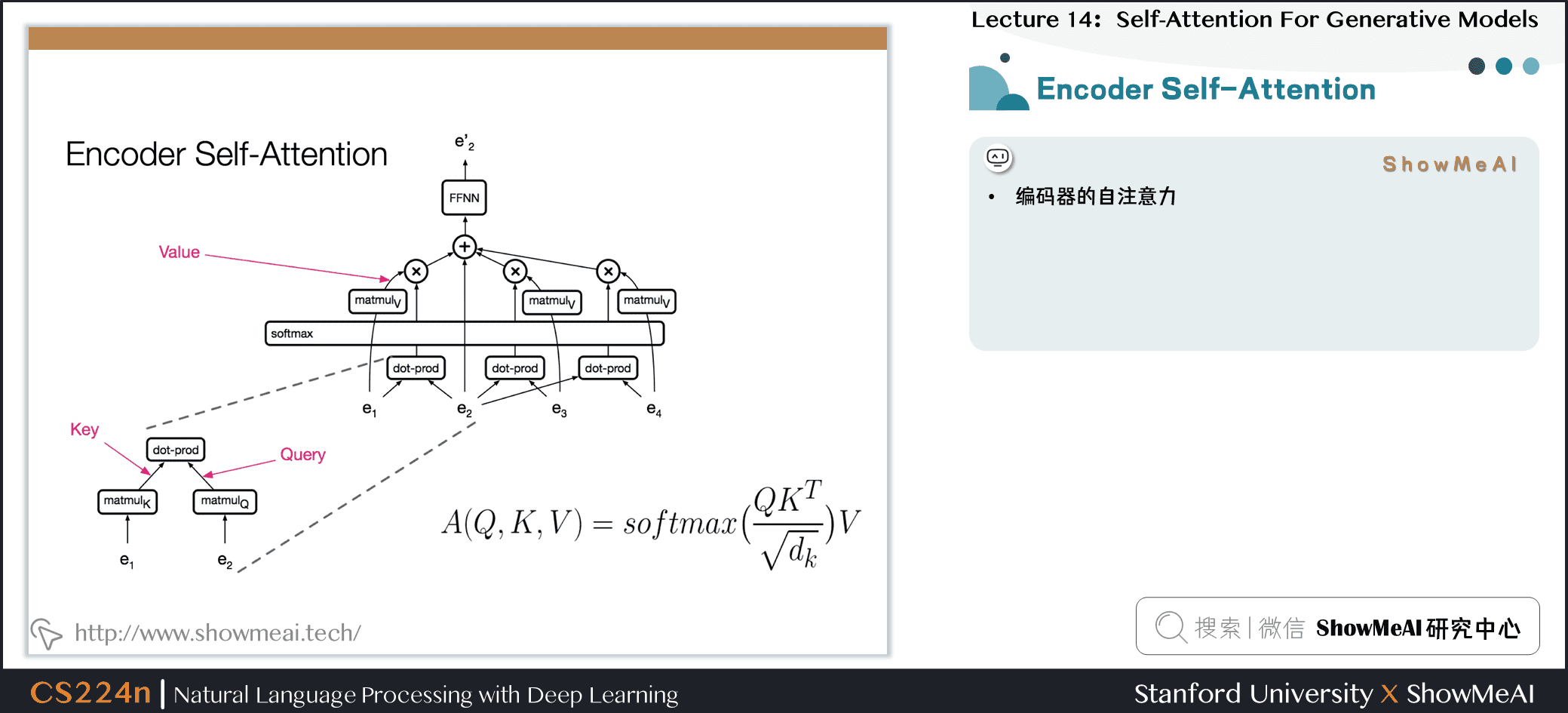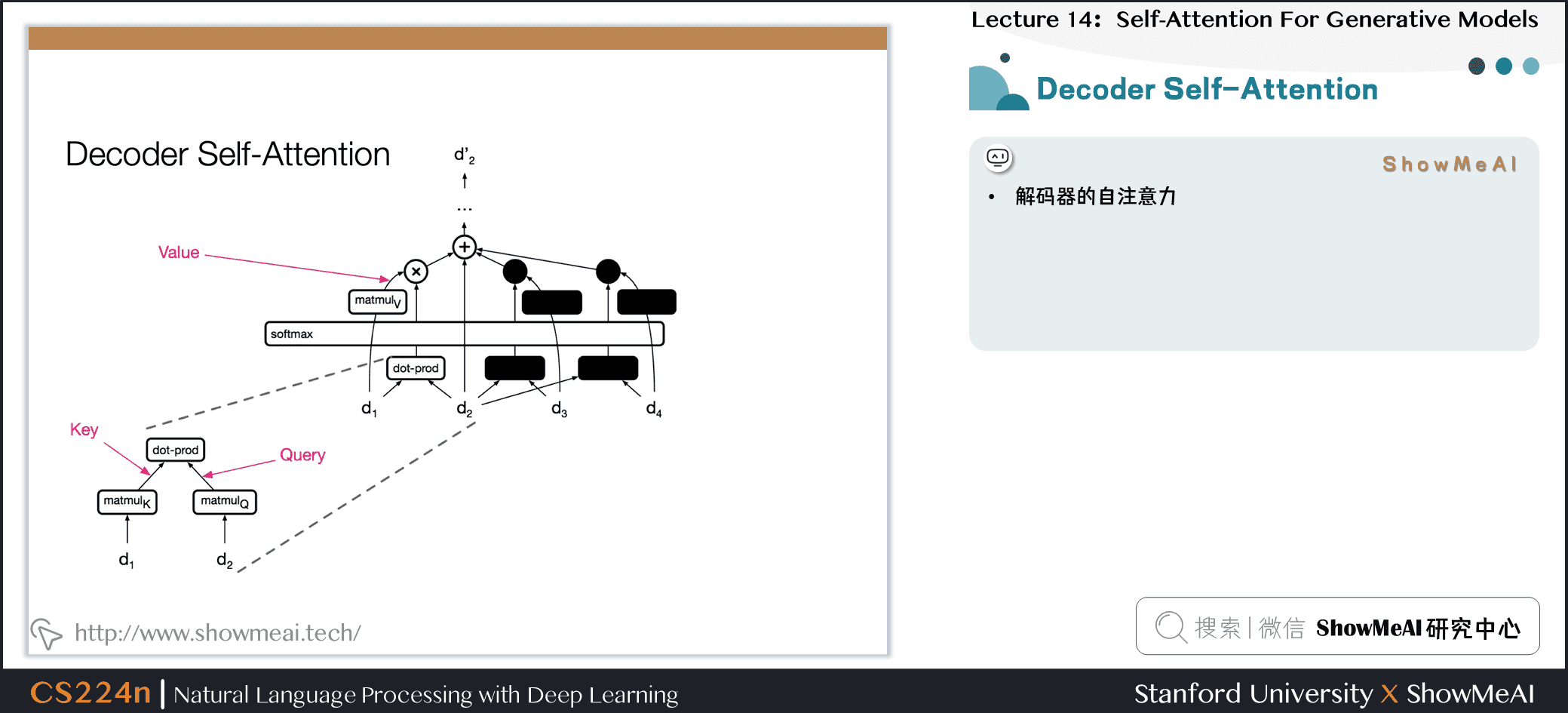
- 编码器的自注意力
- 解码器的自注意力
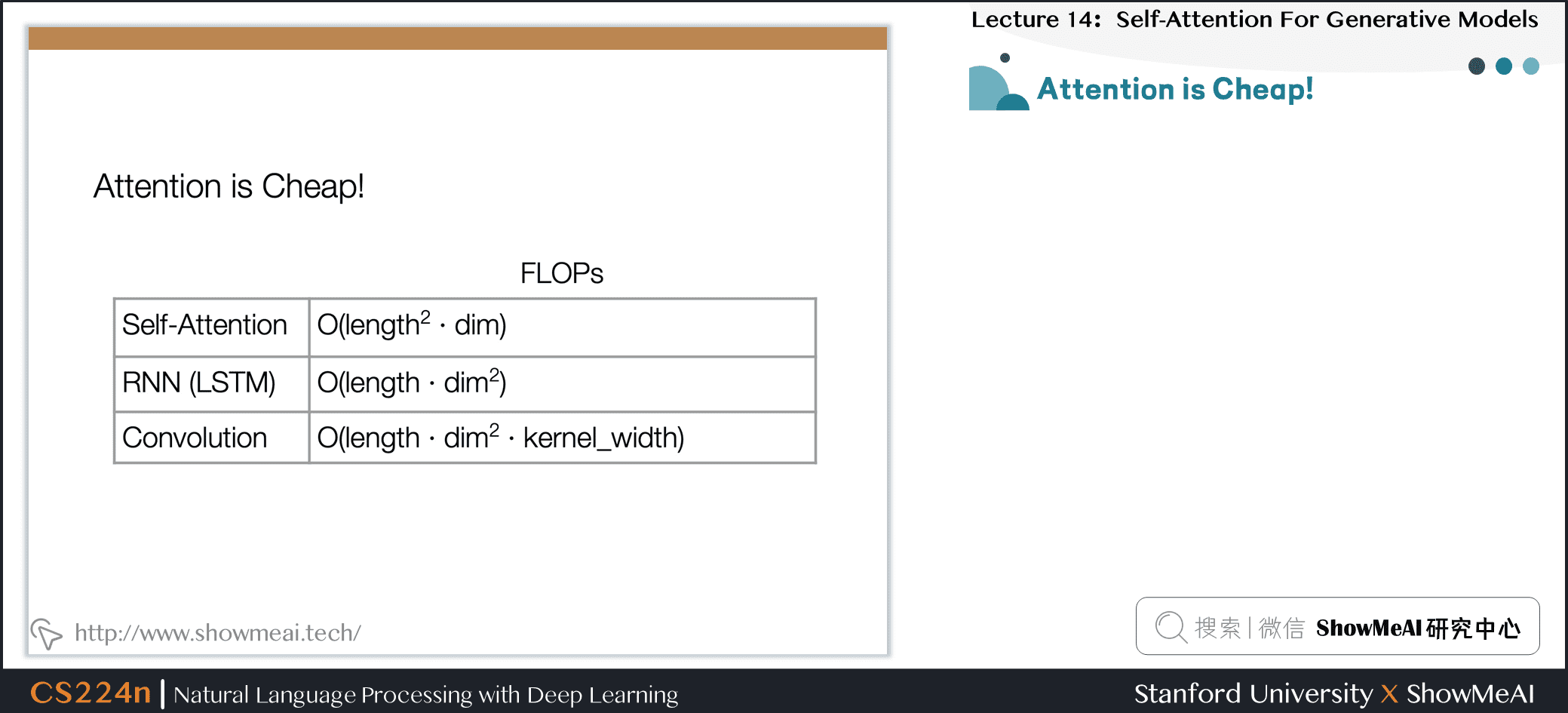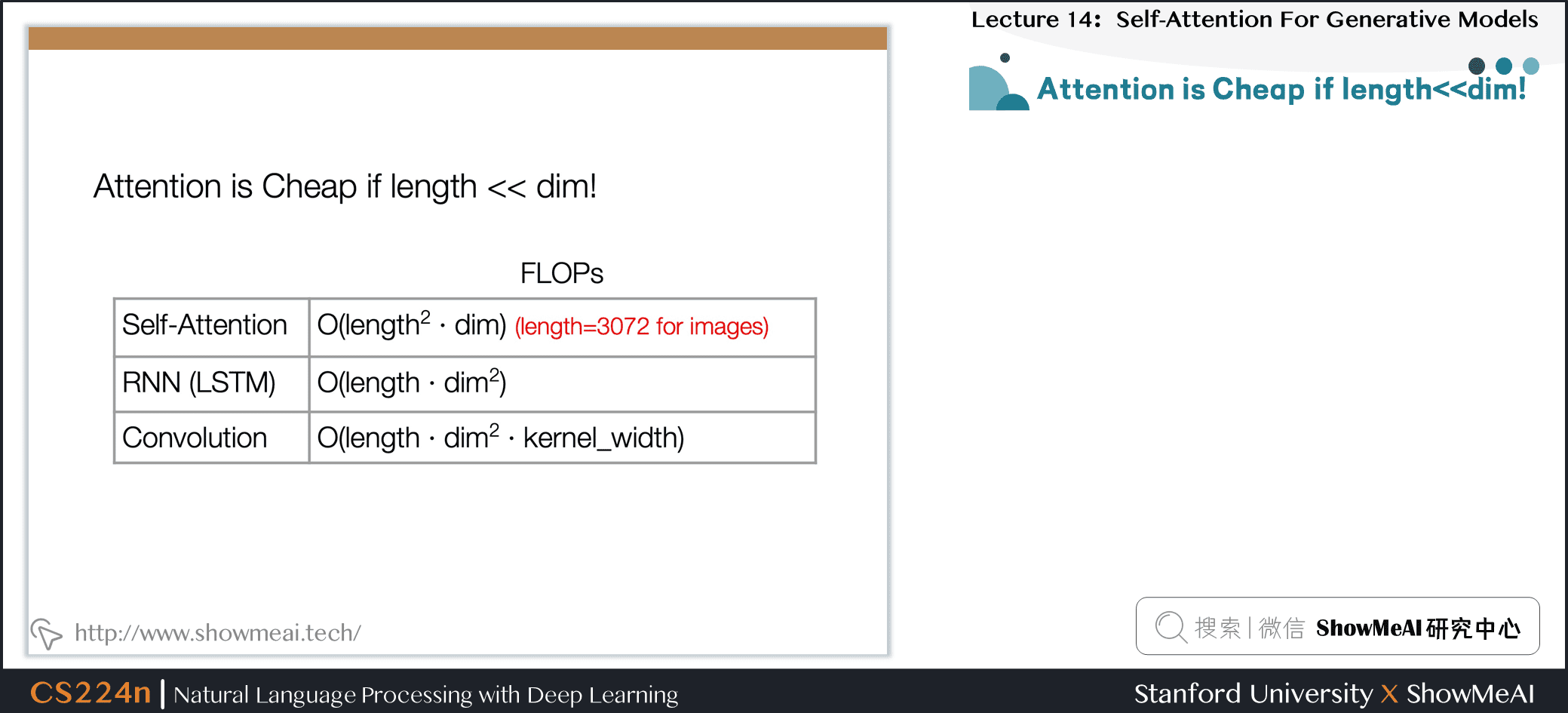
4.5 Attention is Cheap!
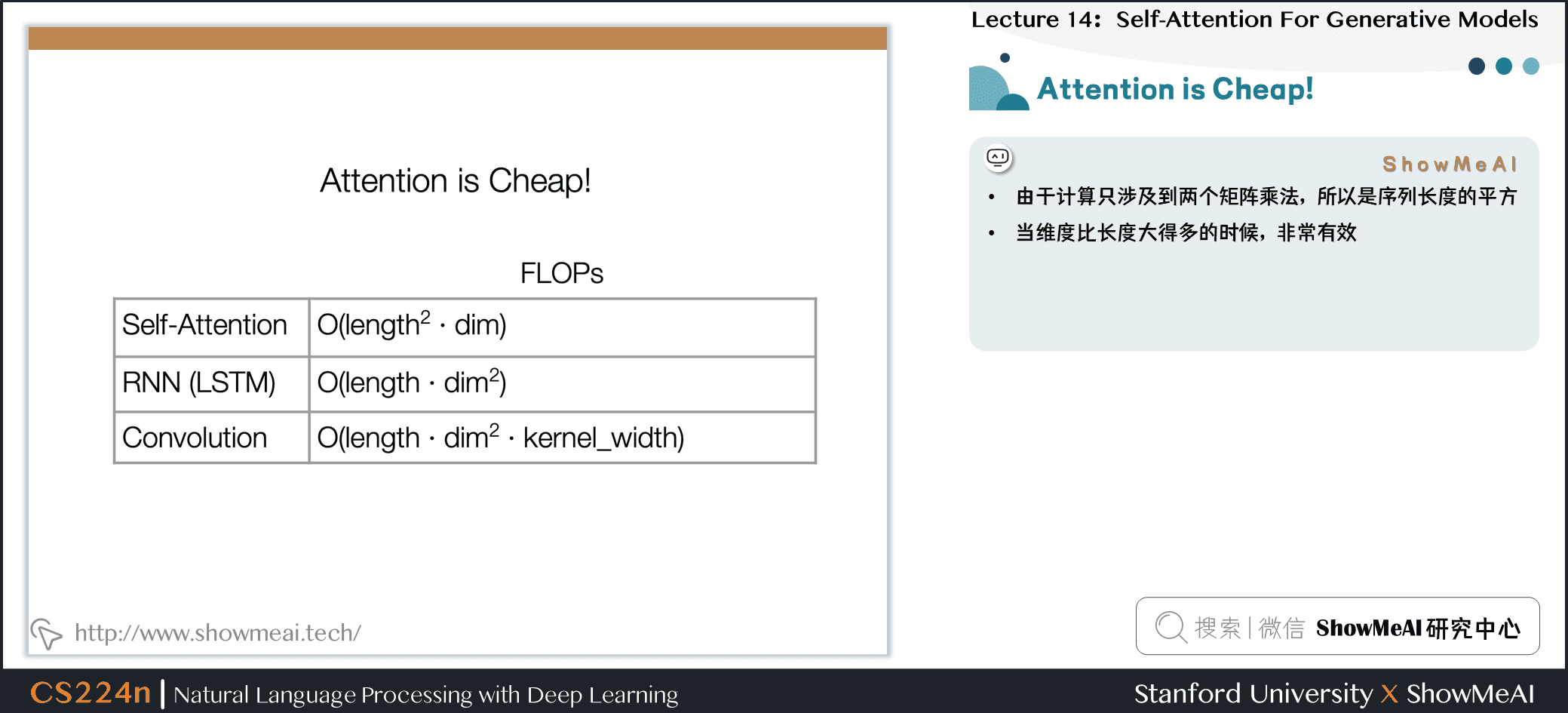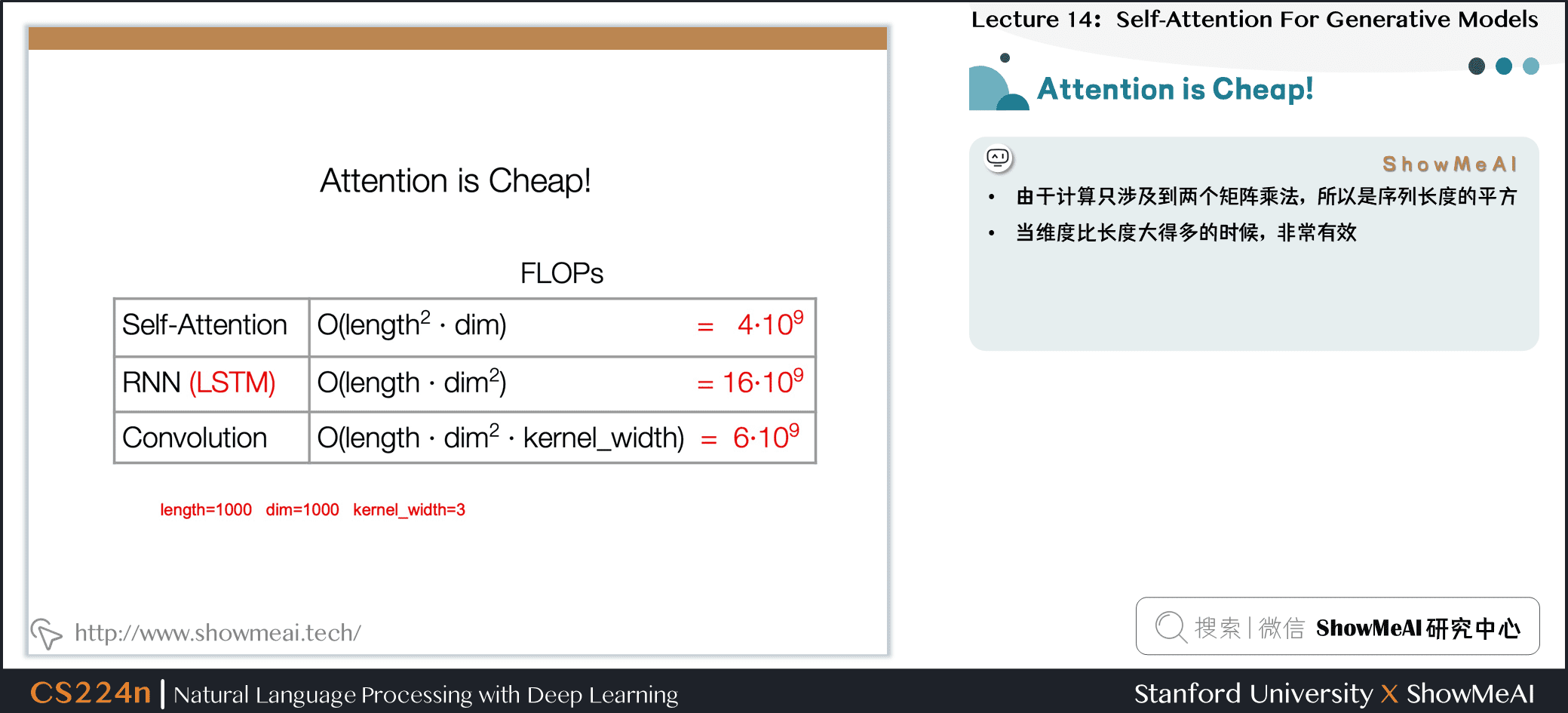
- 由于计算只涉及到两个矩阵乘法,所以是序列长度的平方
- 当维度比长度大得多的时候,非常有效
4.6 注意力:加权平均
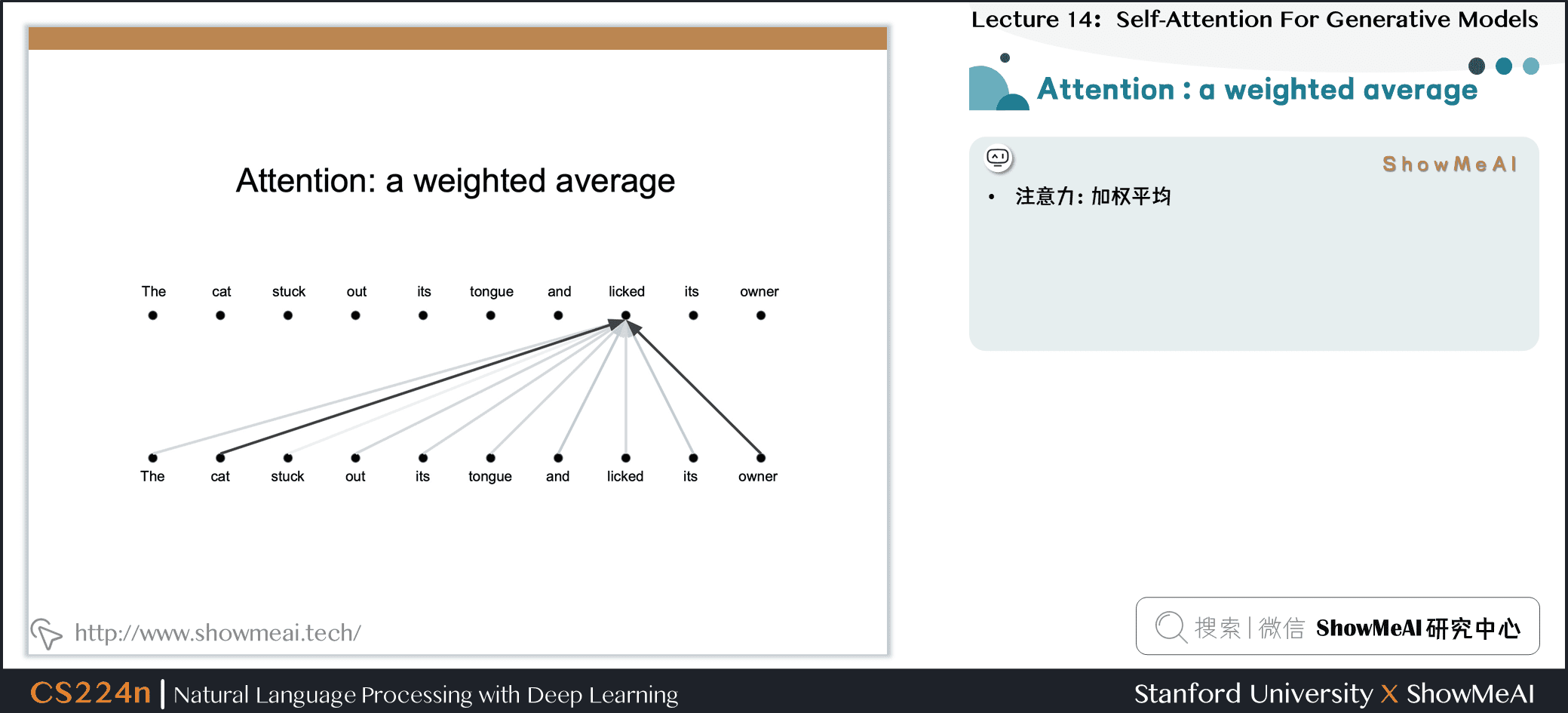
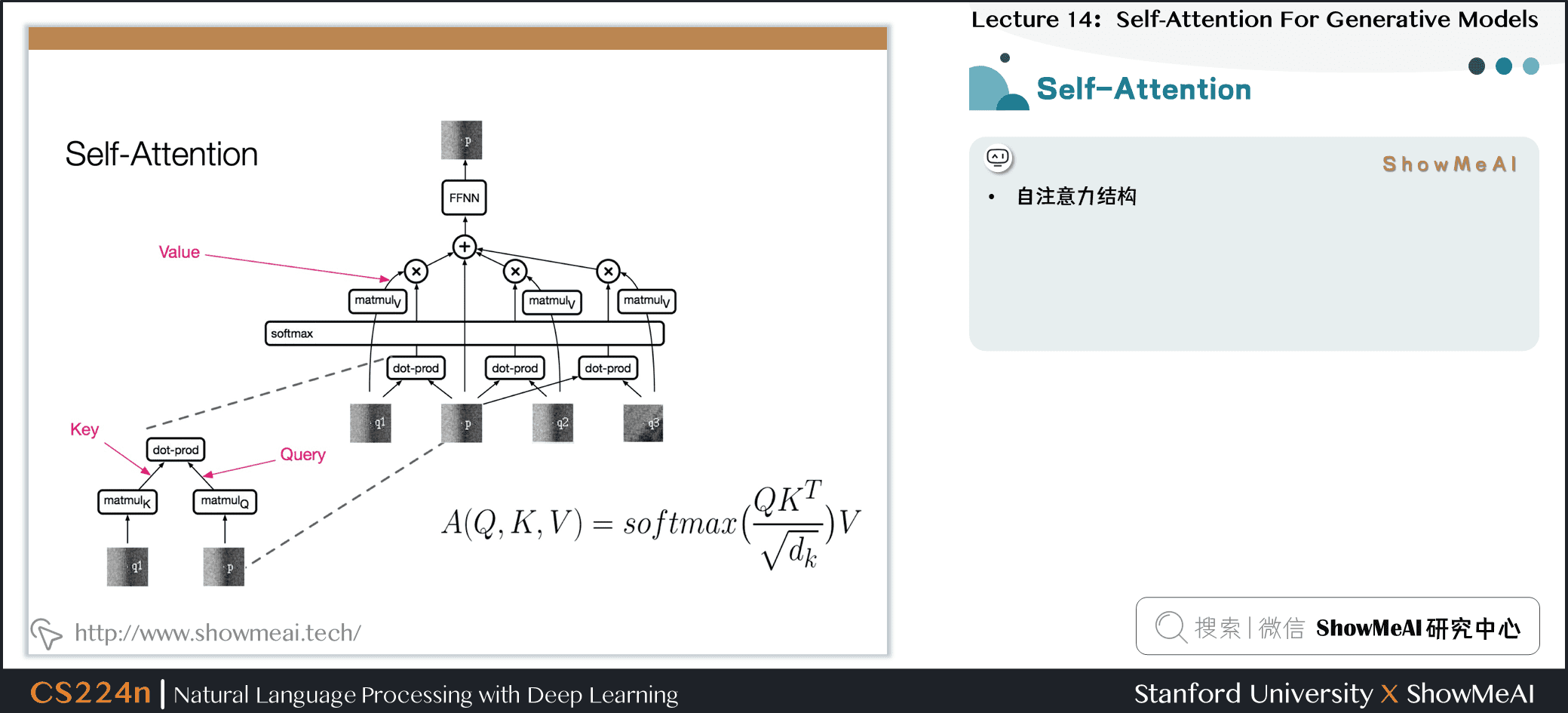
4.7 自注意力

- 上例中,我们想要知道谁对谁做了什么,通过卷积中的多个卷积核的不同的线性操作,我们可以分别获取到 who, did what, to whom 的信息。
- 但是对于 Attention 而言,如果只有一个Attention layer,那么对于一句话里的每个词都是同样的线性变换,不能够做到在不同的位置提取不同的信息
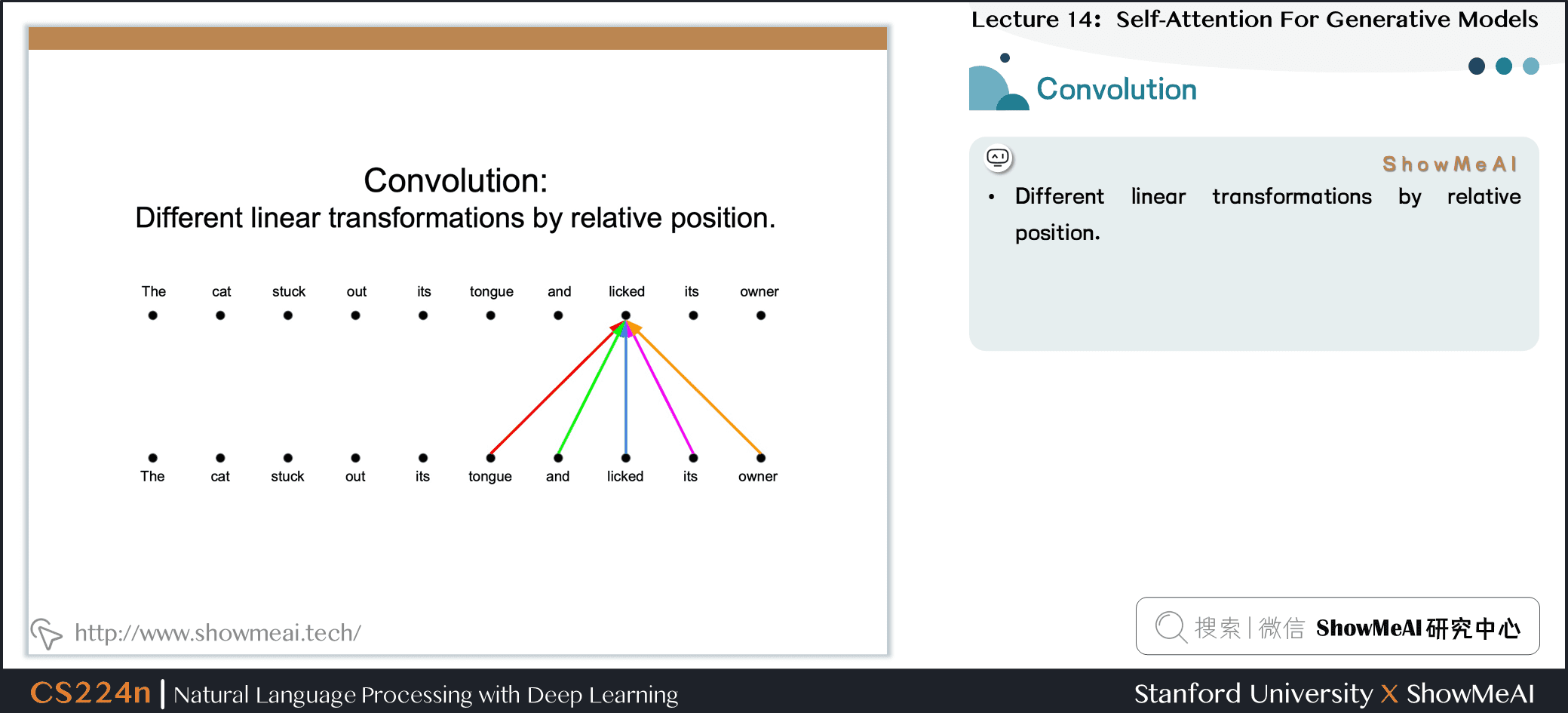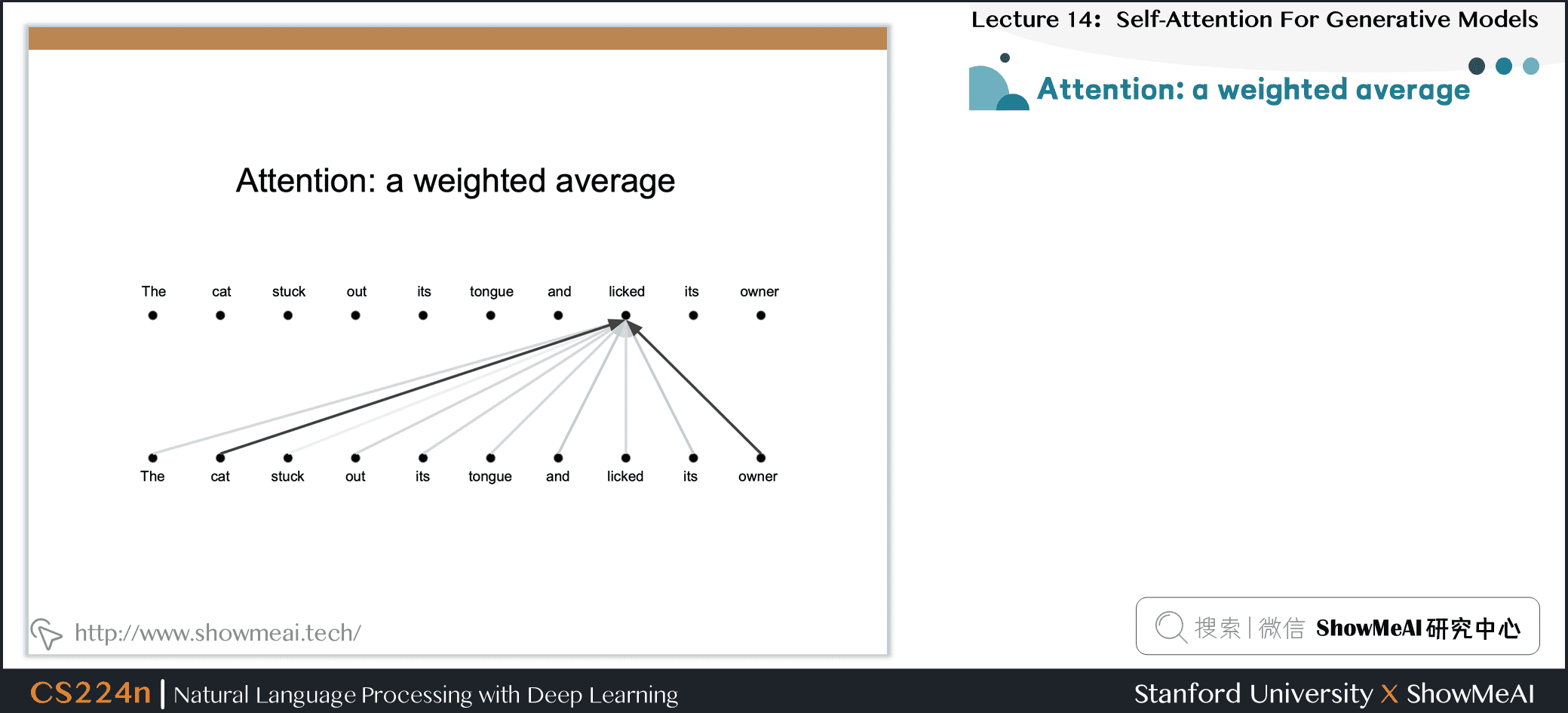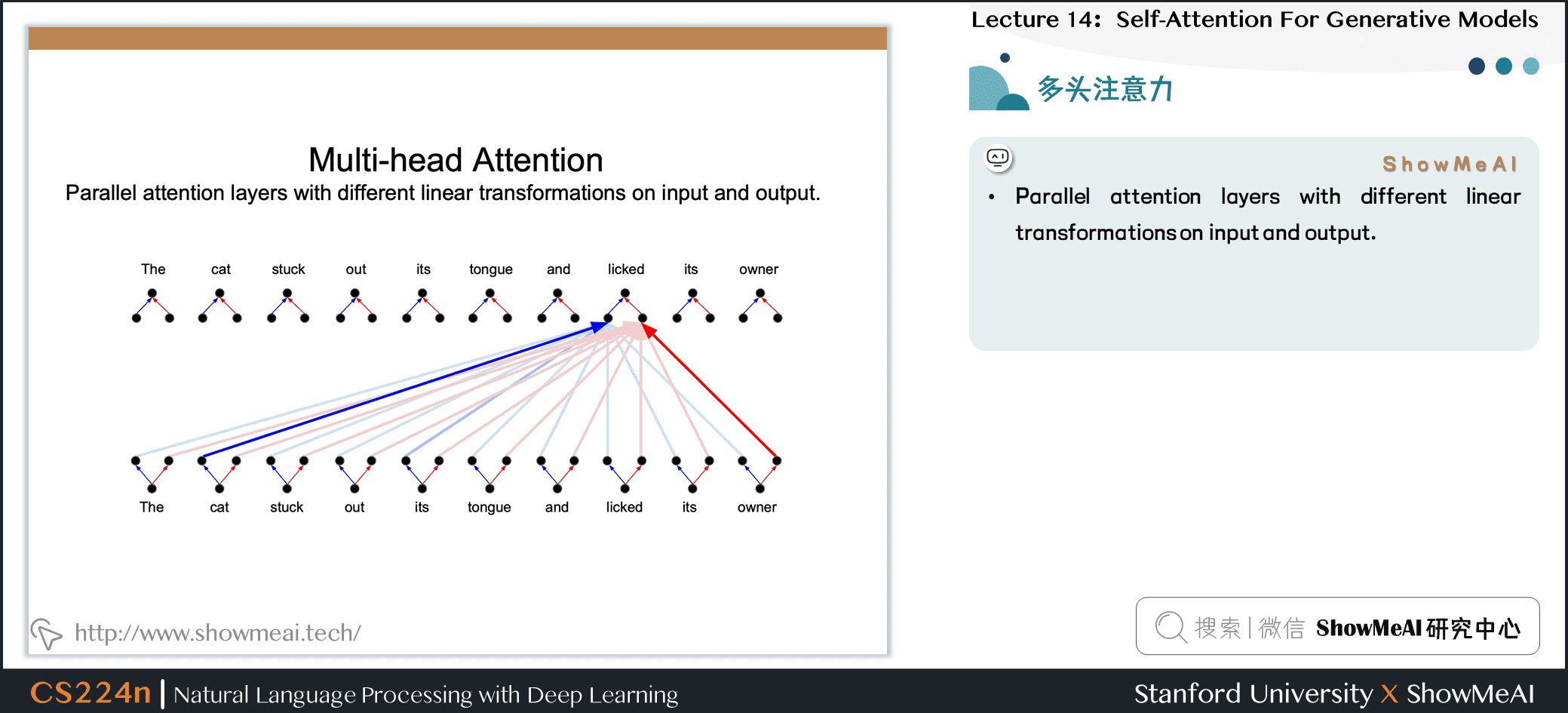
- Who,Did What,To Whom,分别拥有注意力头
- 将注意力层视为特征探测器
- 可以并行完成
- 为了效率,减少注意力头的维度,并行操作这些注意力层,弥补了计算差距
4.8 卷积和多头注意力
- Different linear transformations by relative position.
- Parallel attention layers with different linear transformations on input and output.
5.Results

5.1 机器翻译: WMT-2014 BLEU
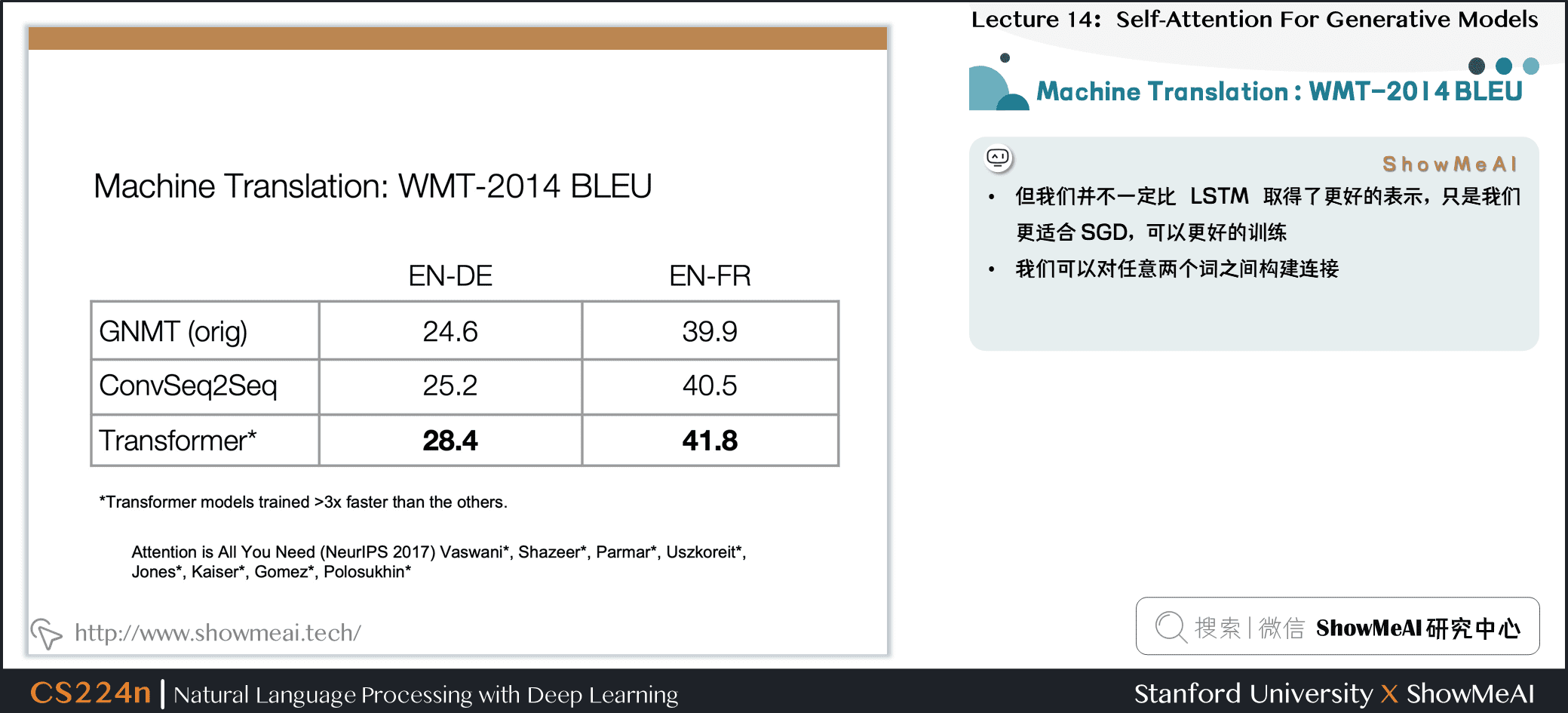
- 但我们并不一定比 LSTM 取得了更好的表示,只是我们更适合 SGD,可以更好的训练
- 我们可以对任意两个词之间构建连接
6.框架
6.1 残差连接的必要性
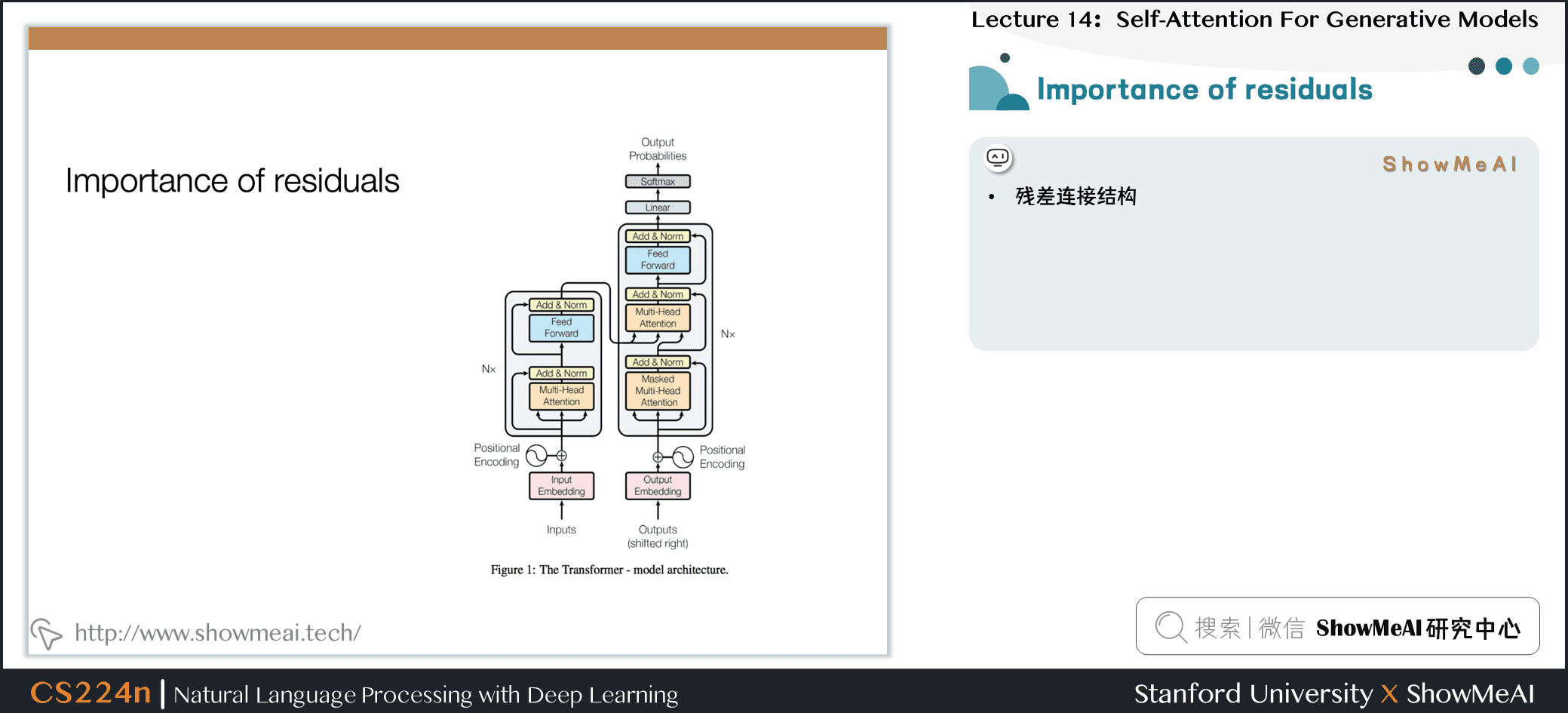

- 残差连接结构
- 位置信息最初添加在了模型的输入处,通过残差连接将位置信息传递到每一层,可以不需要再每一层都添加位置信息
6.2 训练细节

- ADAM 优化器,同时使用了学习率预热 (warmup + exponential decay)
- 每一层在添加残差之前都会使用dropout
- Layer-norm/层归一化
- 有些实验中使用了Attention dropout
- Checkpoint-averaging 检查点平均处理
- Label smoothing 标签平滑
- Auto-regressive decoding with beam search and length biasing 使用集束搜索和length biasing的自回归解码
- ……
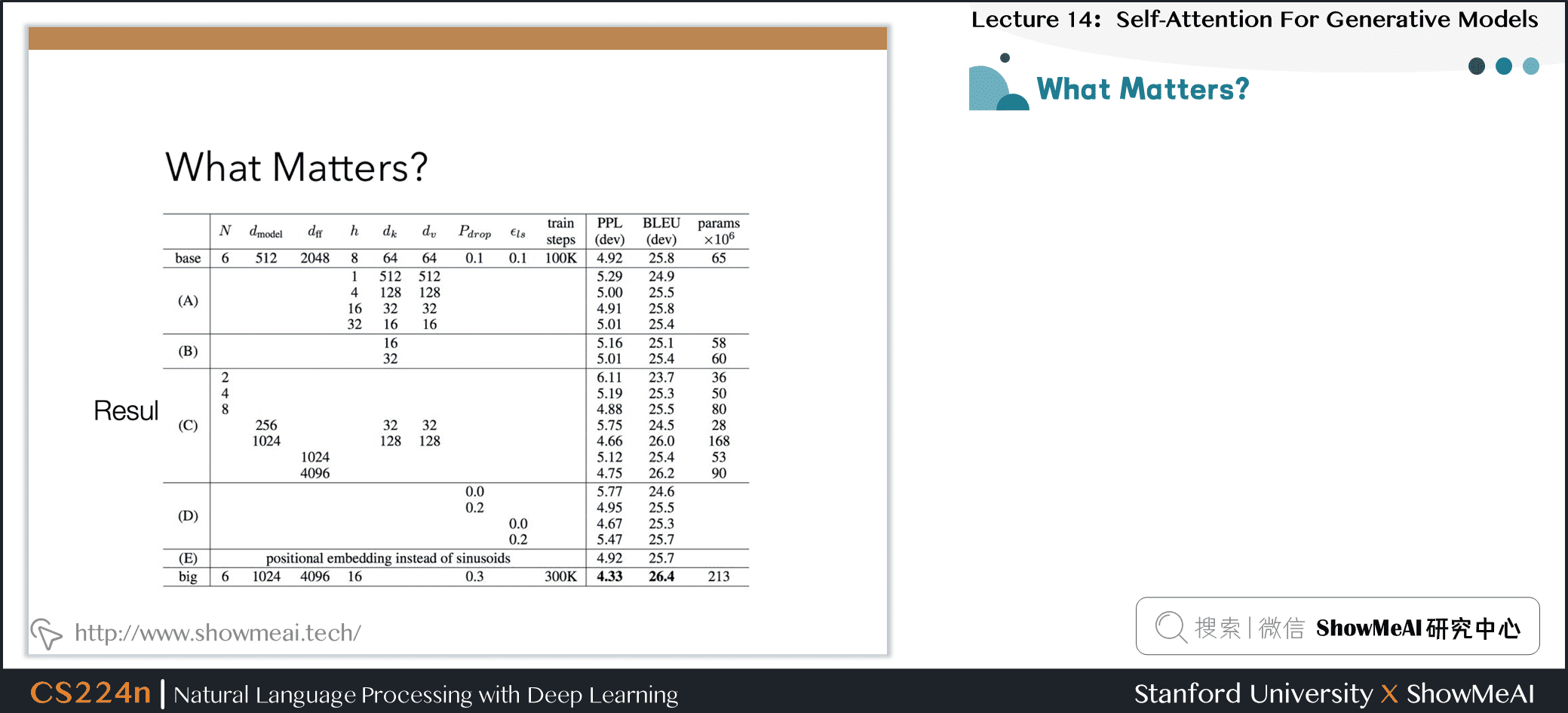
6.3 What Matters?
6.4 Generating Wikipedia by Summarizing Long Sequences

7.自相似度,图片与音乐生成

7.1 自相似度,图片与音乐生成

7.2 基于概率分布的图像生成

- 模拟像素的联合分布
- 把它变成一个序列建模问题
- 分配概率允许度量泛化
- RNNs和CNNs是最先进的(PixelRNN, PixelCNN)
- incorporating gating CNNs 现在在效果上与 RNNs 相近
- 由于并行化,CNN 要快得多

- 图像的长期依赖关系很重要(例如对称性)
- 可能随着图像大小的增加而变得越来越重要
- 使用CNNs建模长期依赖关系需要两者之一
- 多层可能使训练更加困难
- 大卷积核参数/计算成本相应变大
7.3 自相似性的研究
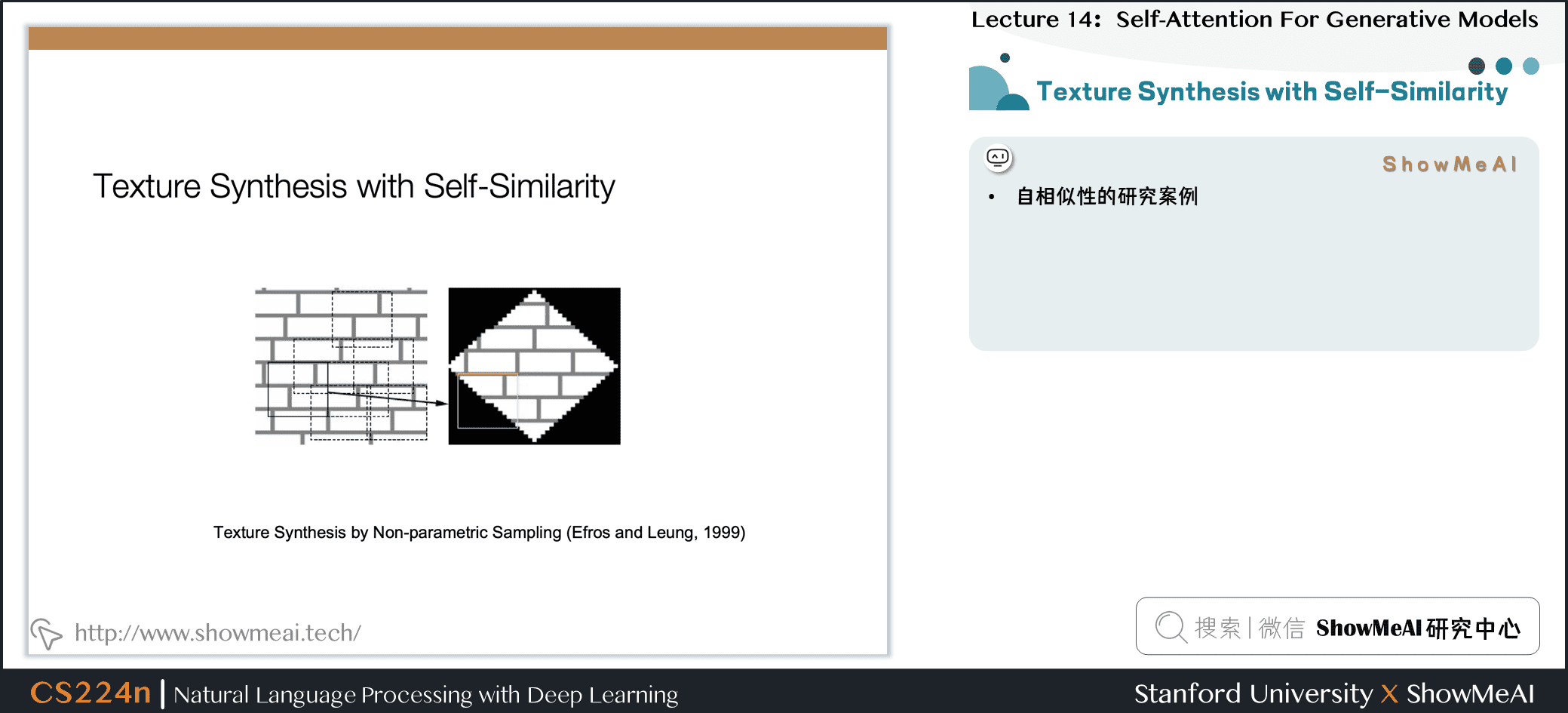
- 自相似性的研究案例
7.4 非局部均值
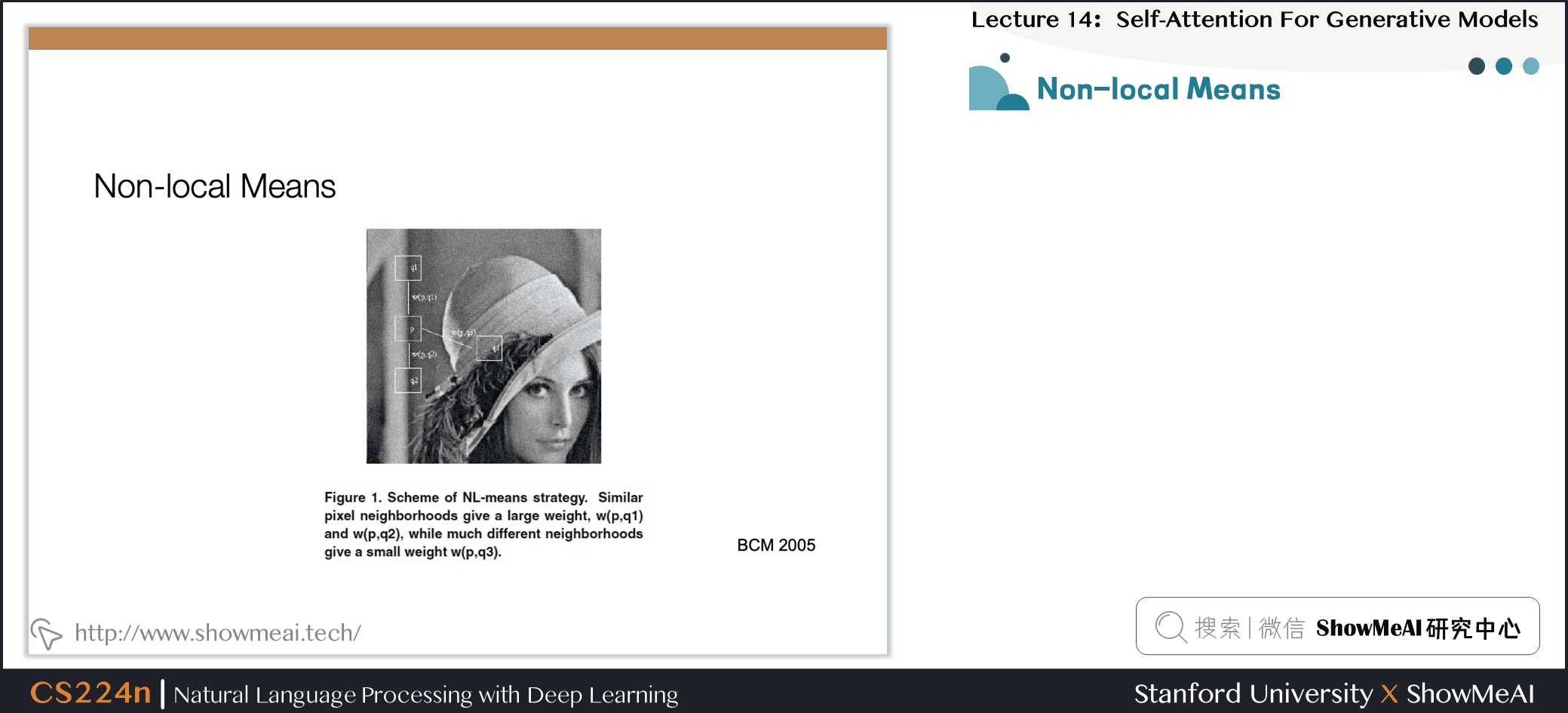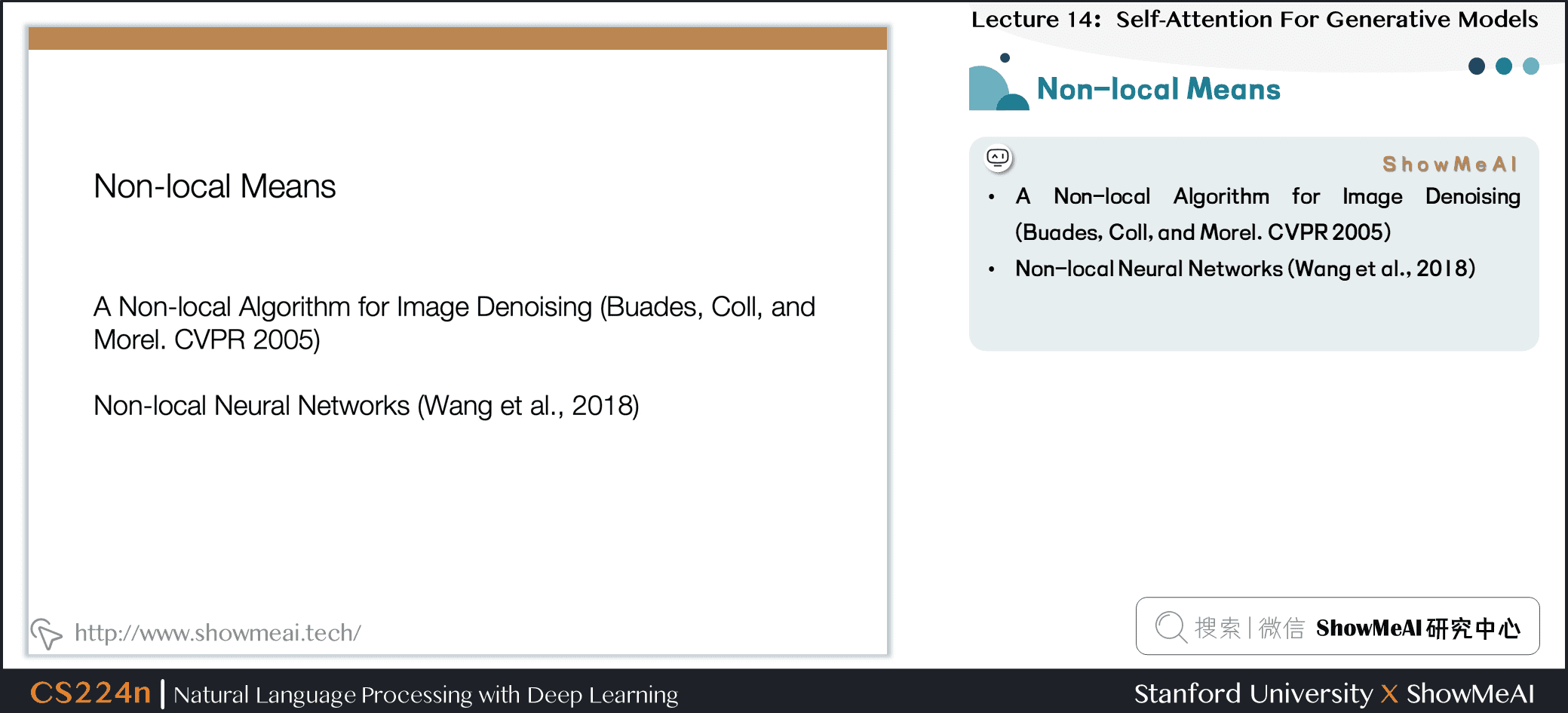
- A Non-local Algorithm for Image Denoising (Buades, Coll, and Morel. CVPR 2005)
- Non-local Neural Networks (Wang et al., 2018)
7.5 既有工作
- Self-attention:
- Parikh et al. (2016), Lin et al. (2016), Vaswani et al. (2017)
- Autoregressive Image Generation:
- A Oord et al. (2016), Salimans et al. (2017)
7.6 自注意力
7.7 图像 Transformer
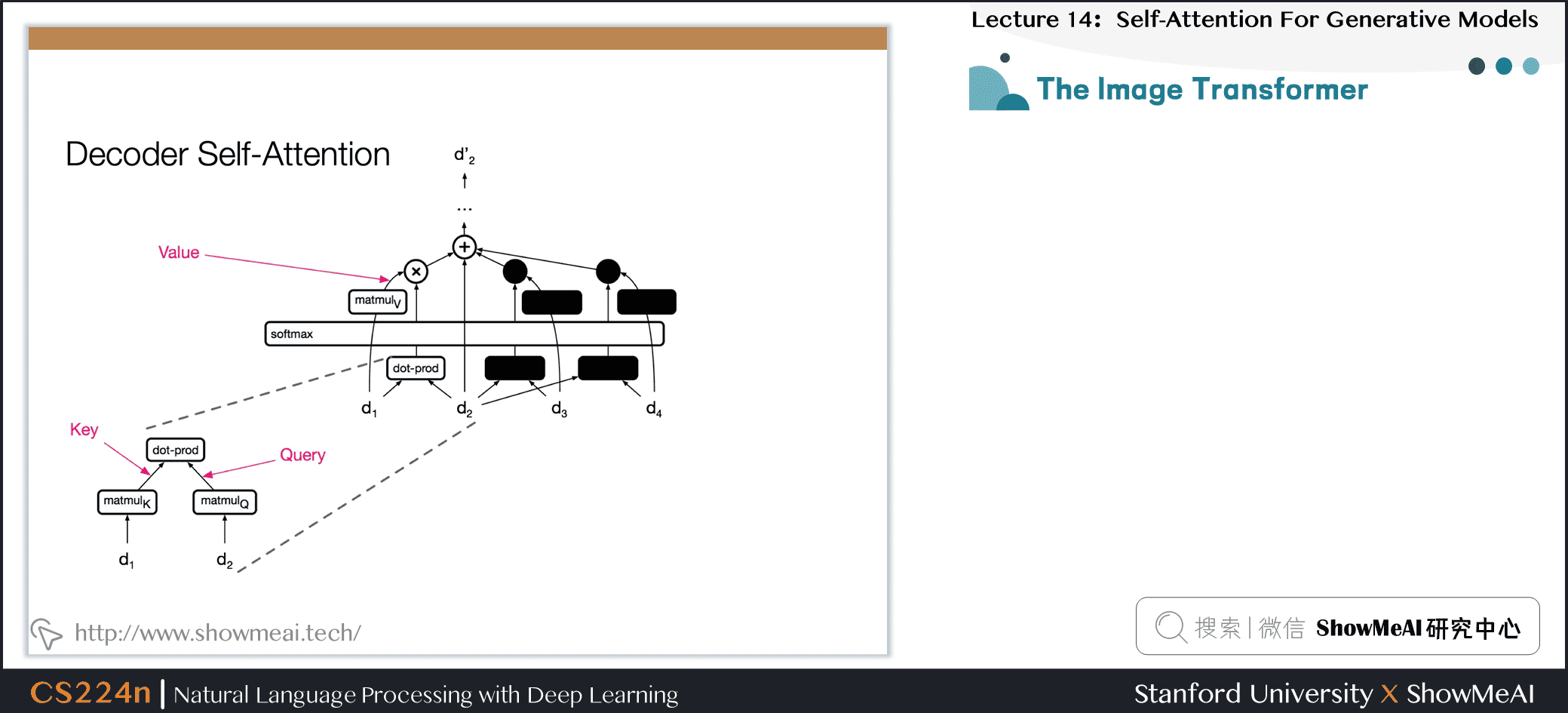
7.8 Attention is Cheap if length<<dim!
7.9 Combining Locality with Self-Attention

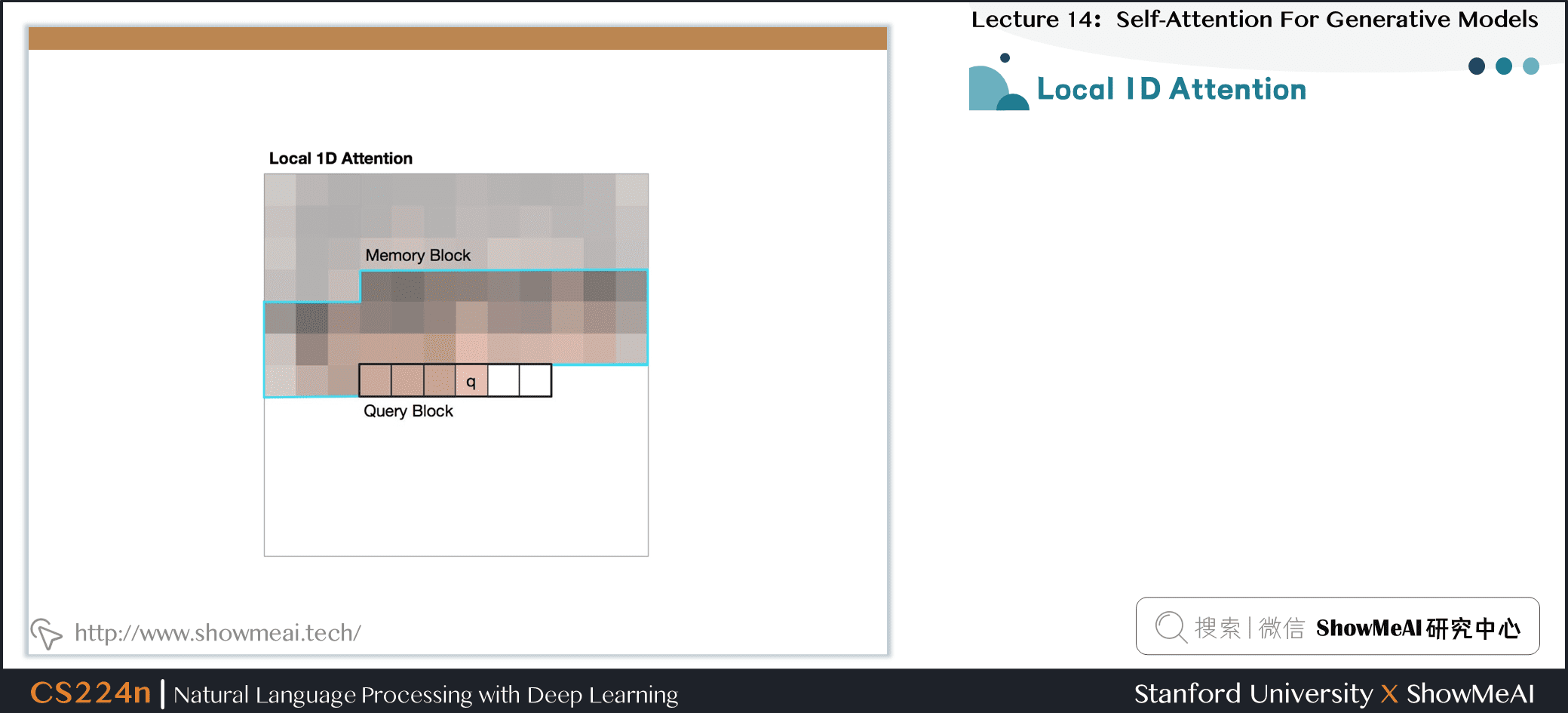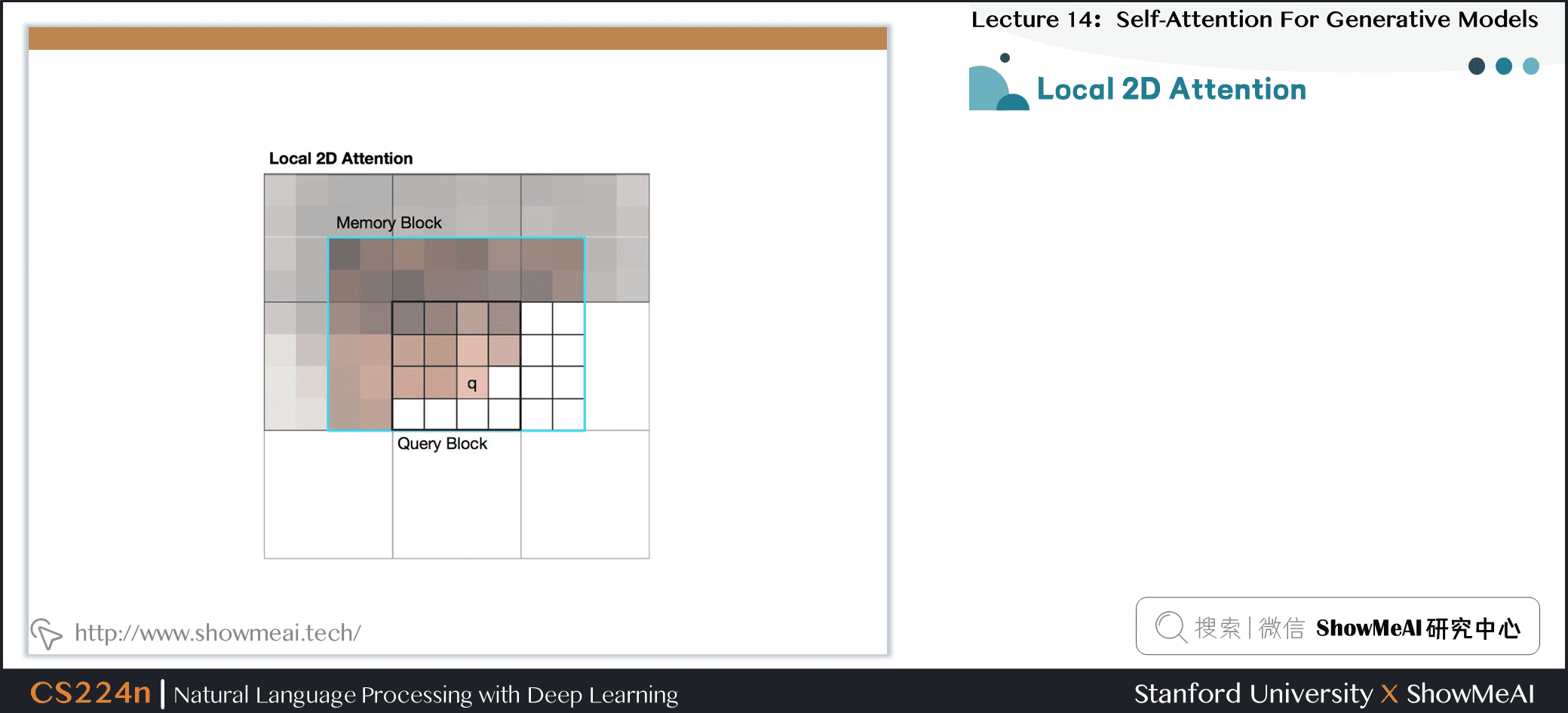
- 将注意力窗口限制为局部范围
- 由于空间局部性,这在图像中是很好的假设
7.10 局部1维和2维注意力
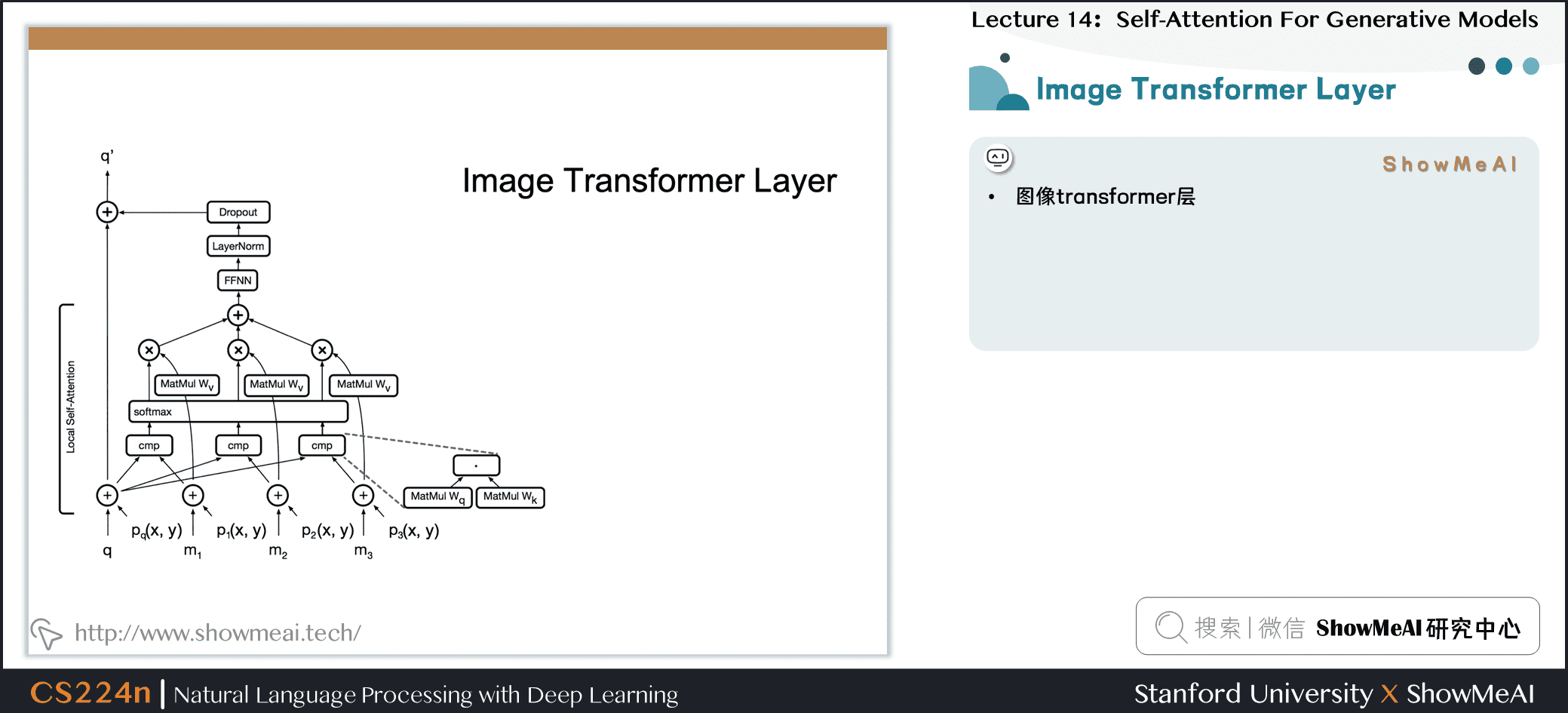
7.11 图像Transformer层
7.12 Task
7.13 Results
- lmage Transformer
- Parmar , Vaswani",Uszkoreit, Kaiser, Shazeer,Ku, and Tran.ICML 2018
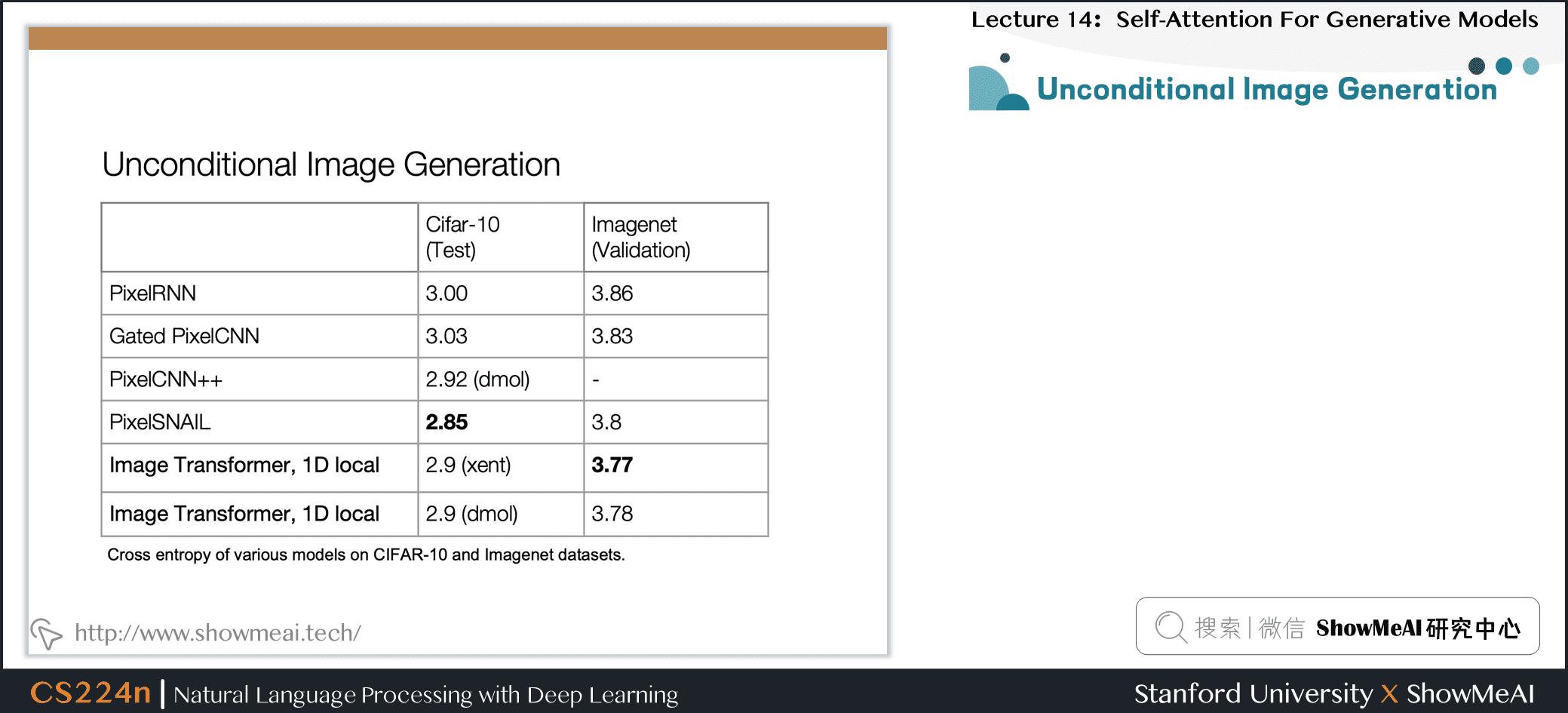
7.14 无约束图像生成
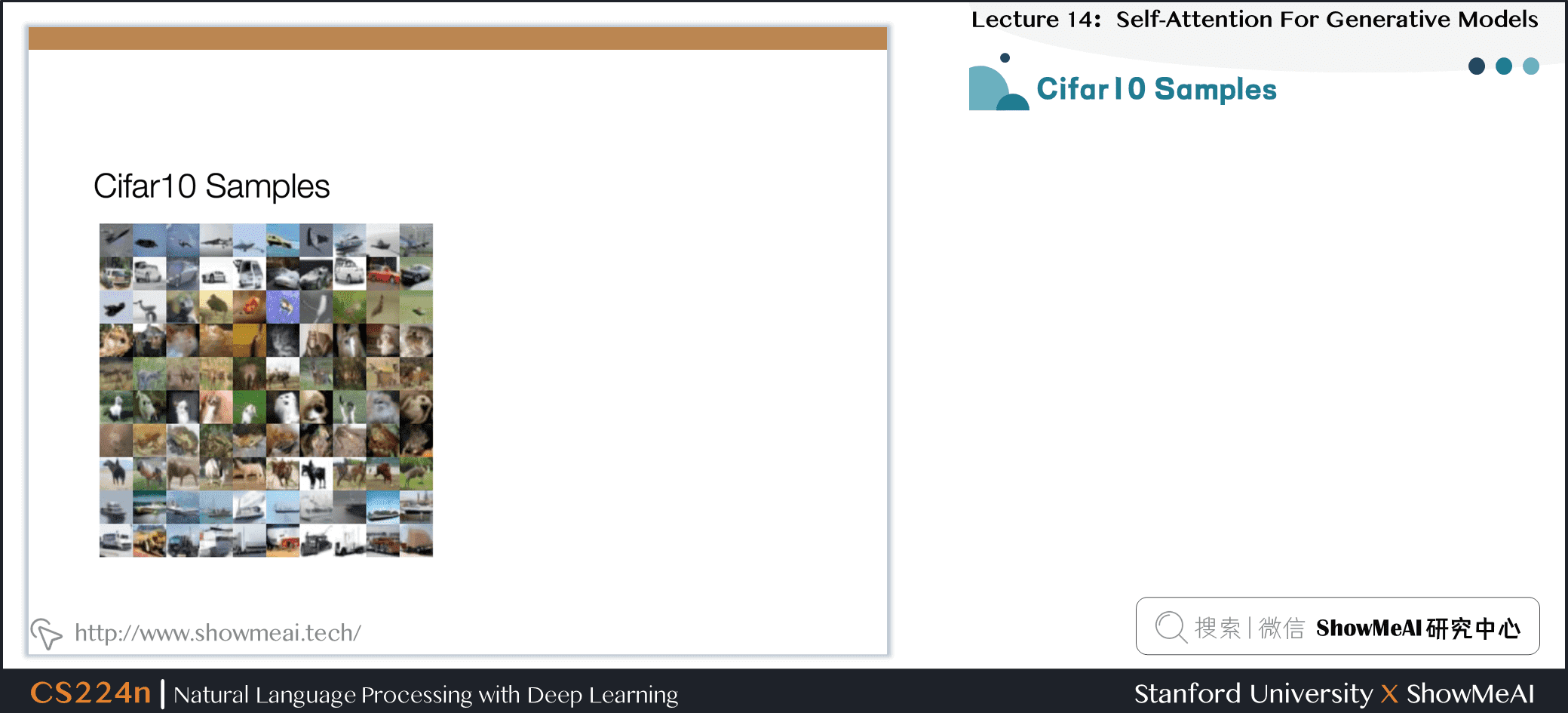
7.15 Cifar10样本
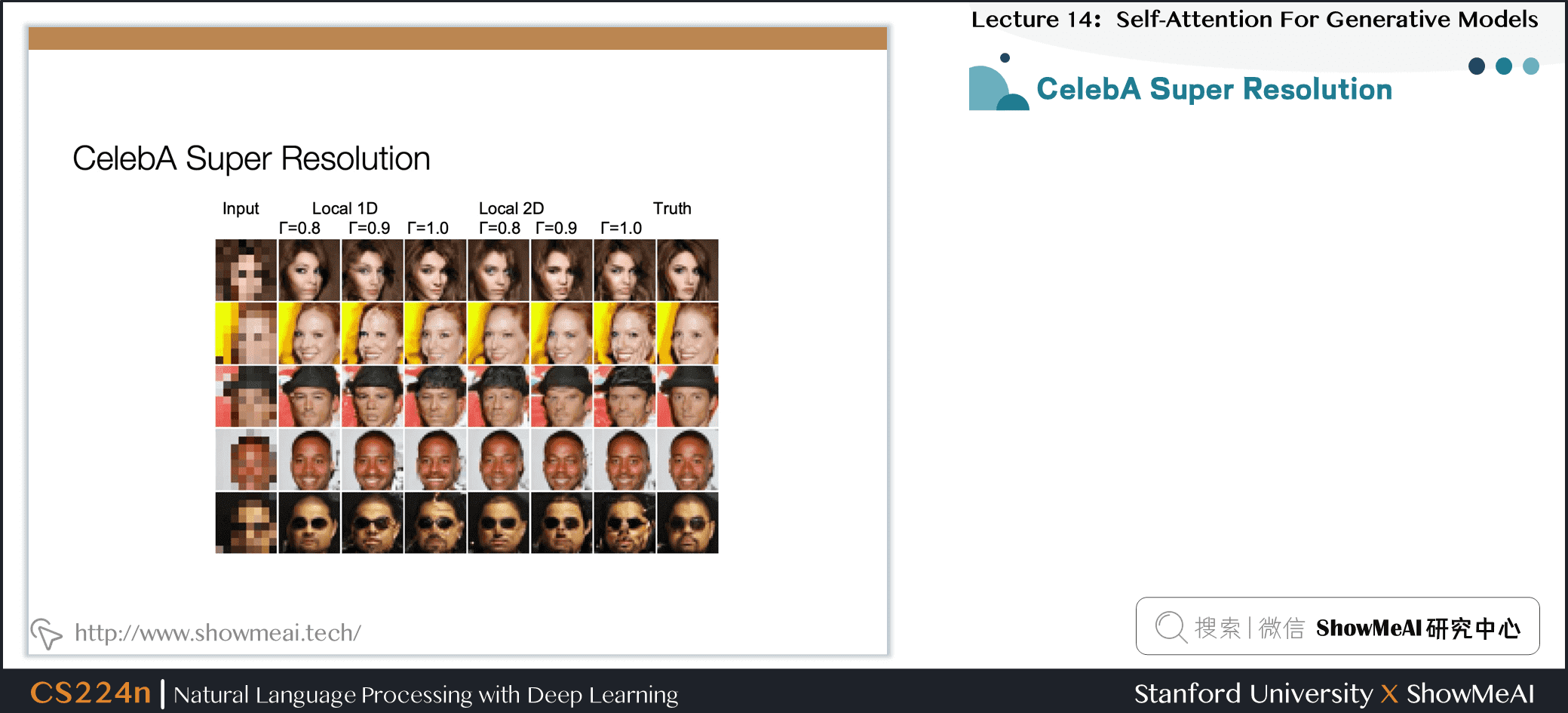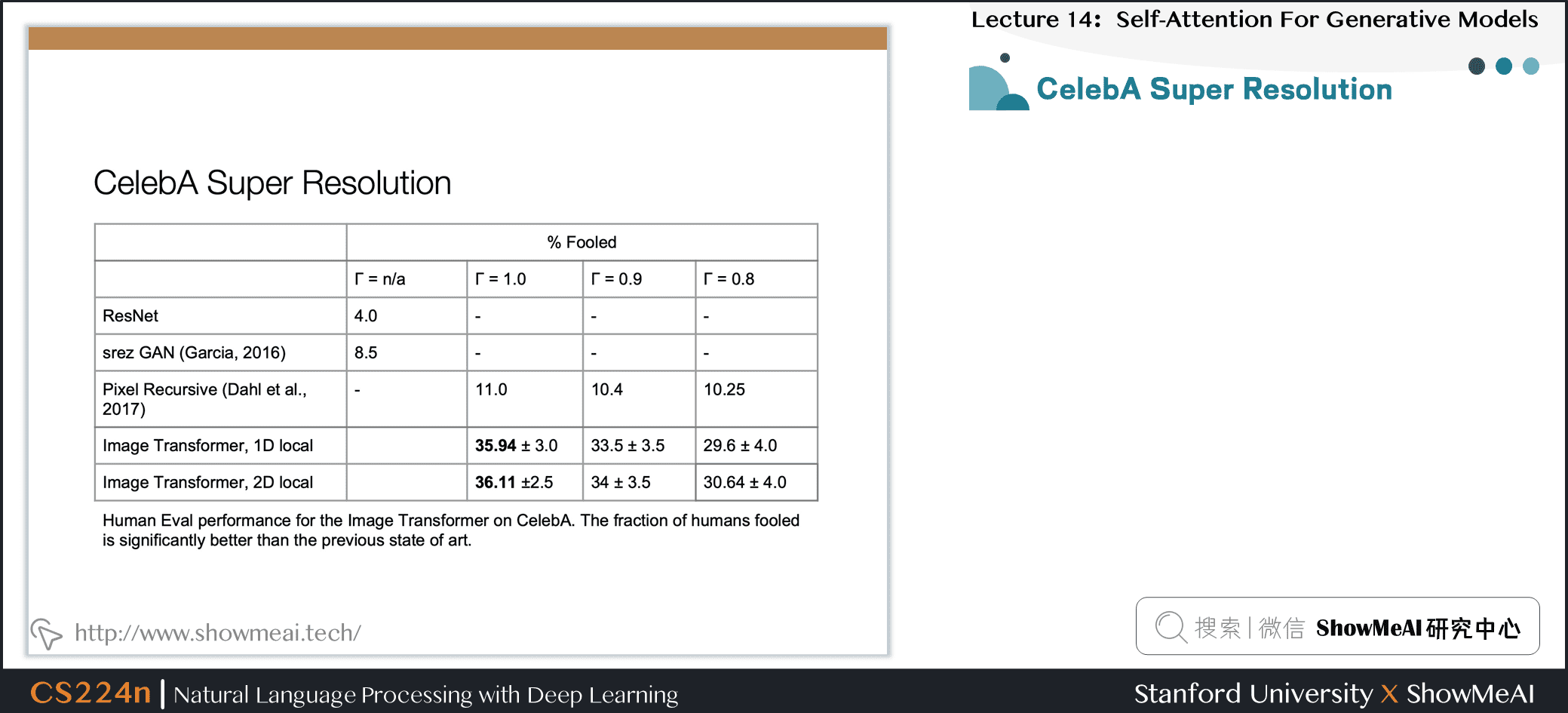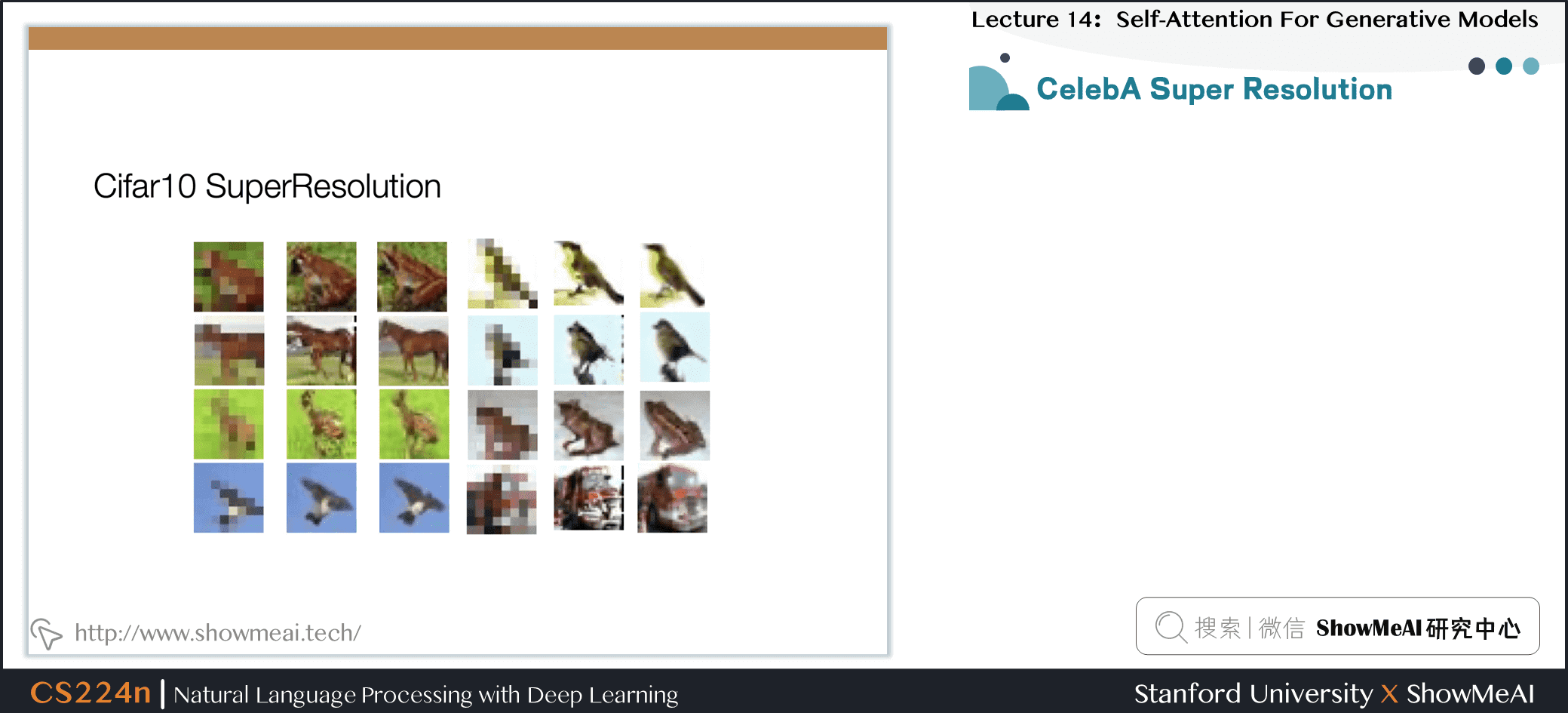
7.16 CelebA超分辨率重建
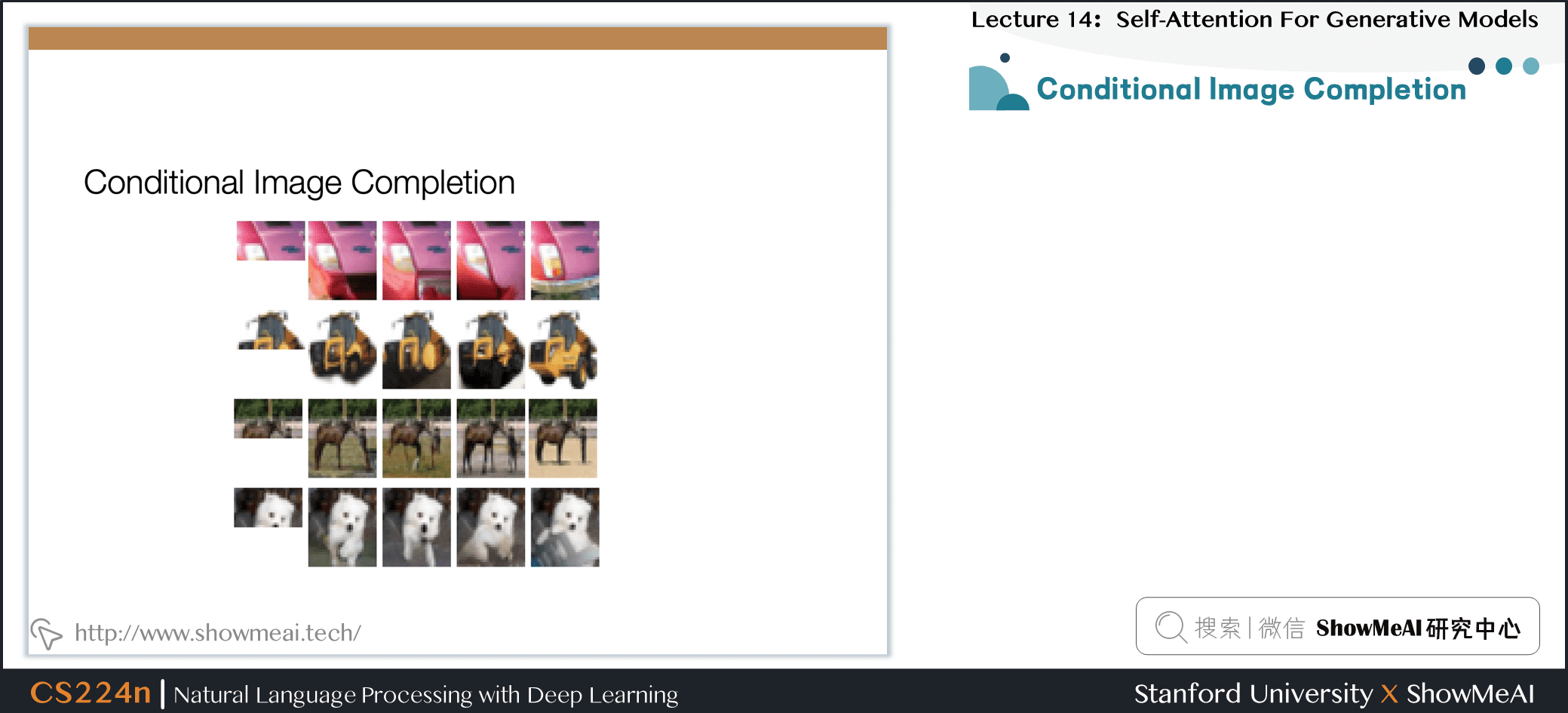
7.17 条件图片生成
8.相对自注意力音乐生成

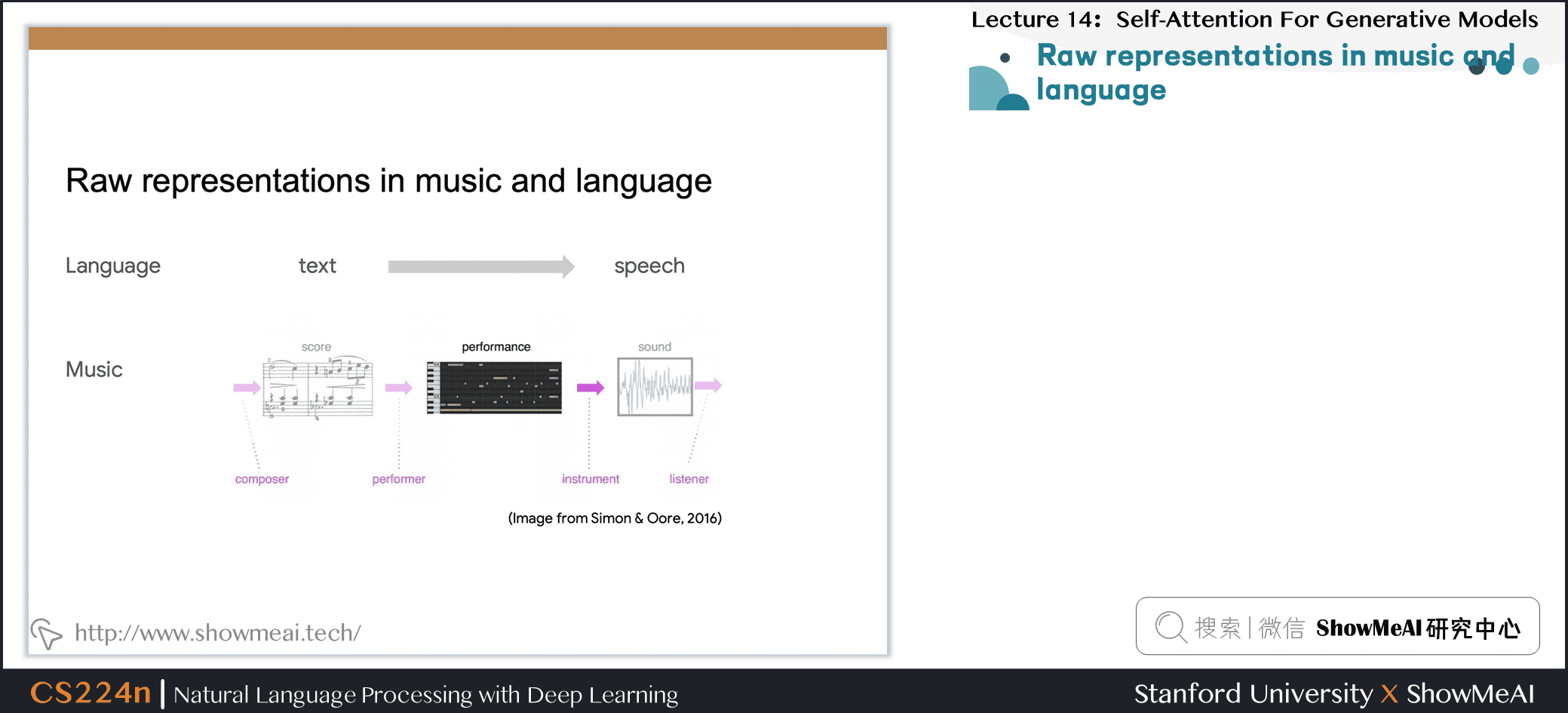
8.1 音乐和语言的原始表征
8.2 音乐语言模型

- 传统的 RNN 模型需要将长序列嵌入到固定长度的向量中
8.3 Continuations to given initial motif

8.4 音乐自相似度
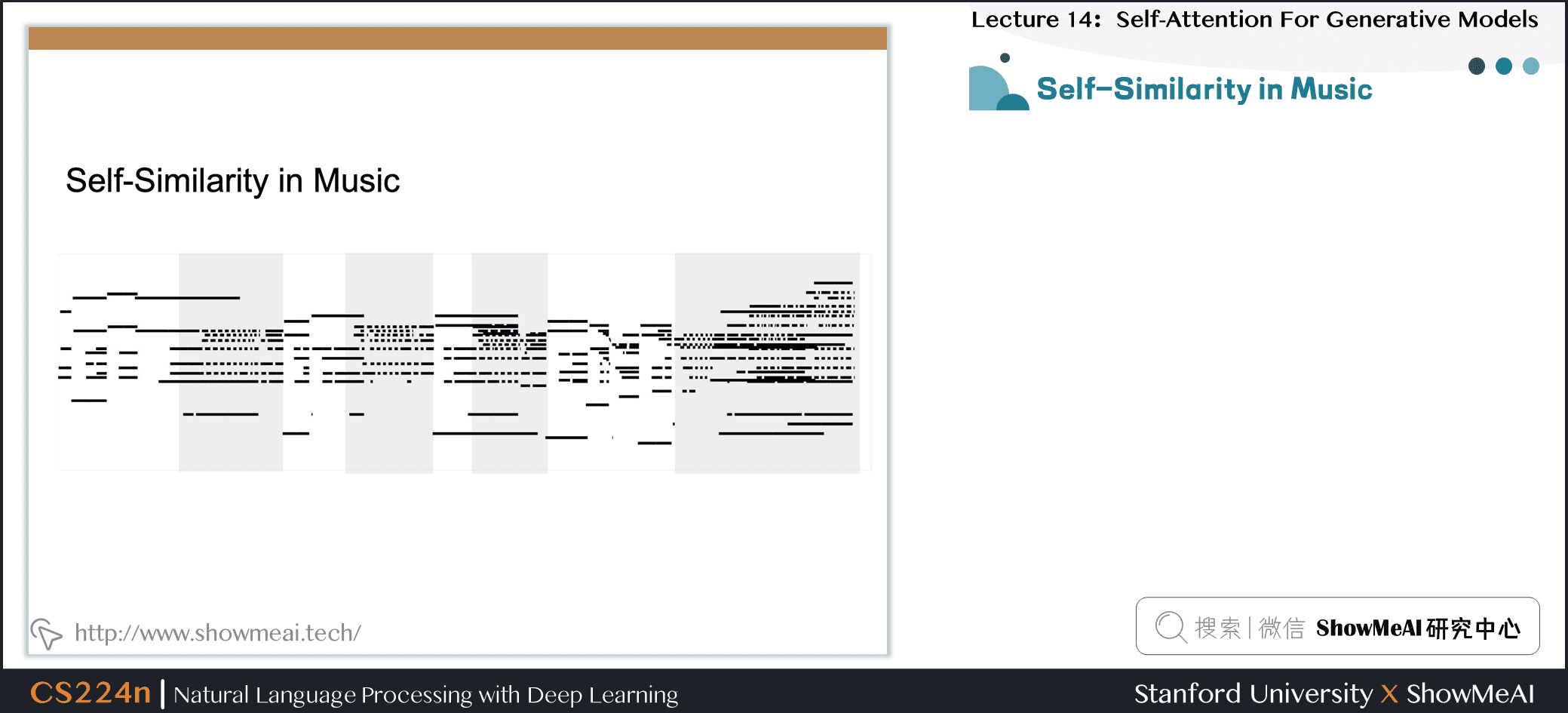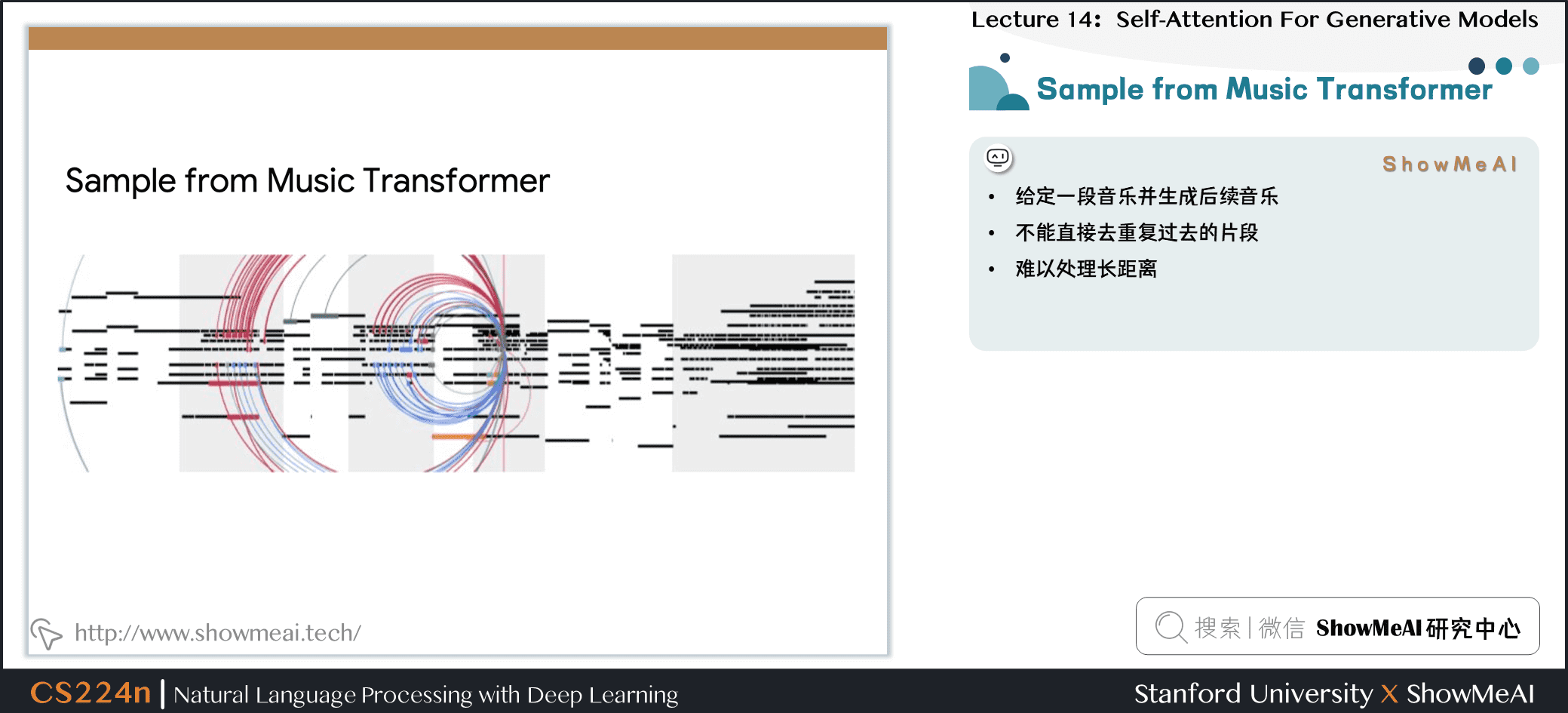
- 给定一段音乐并生成后续音乐
- 不能直接去重复过去的片段
- 难以处理长距离
8.5 注意力:加权平均

- 移动的固定过滤器捕获相对距离
- Music Transformer 使用平移不变性来携带超过其训练长度的关系信息,进行传递
- Different linear transformations by relative position.
8.6 近观相对注意力
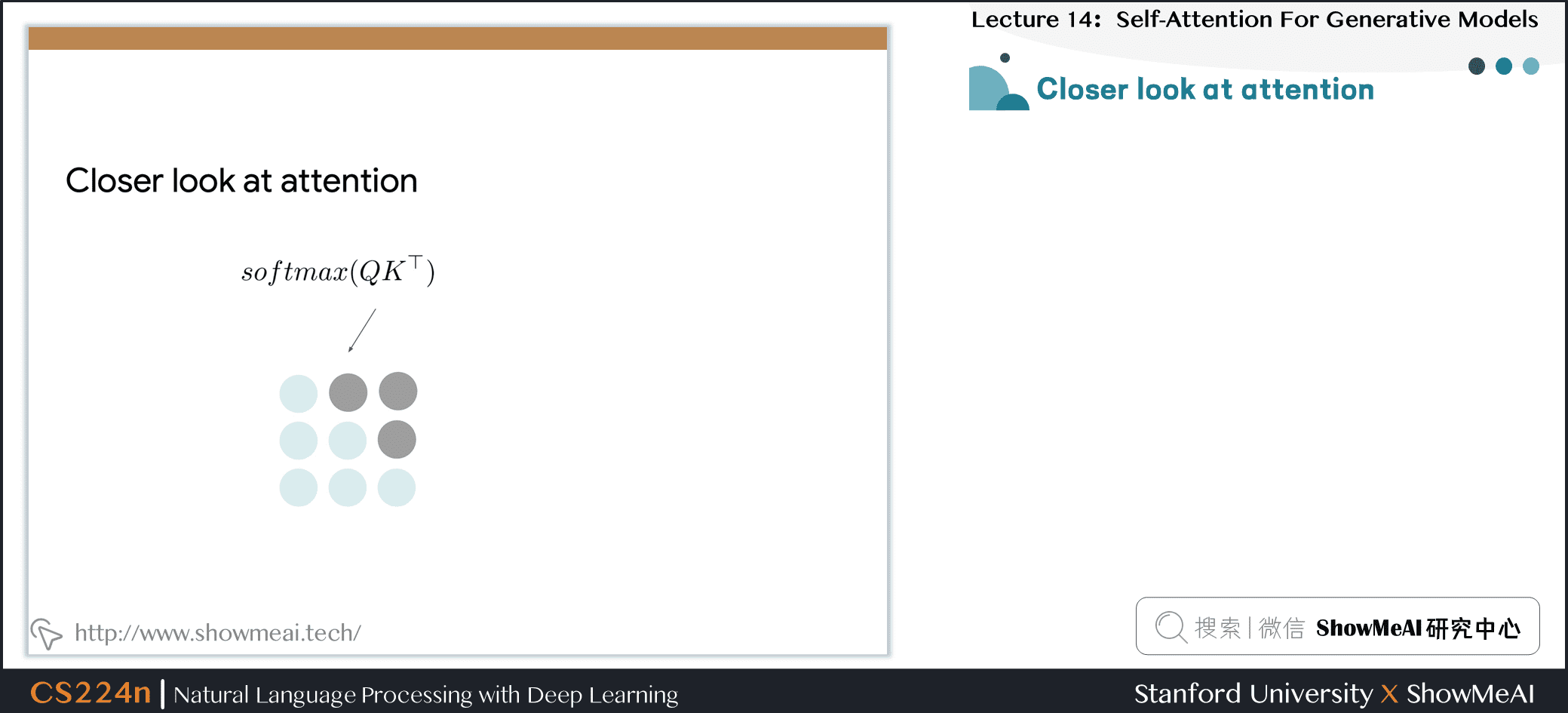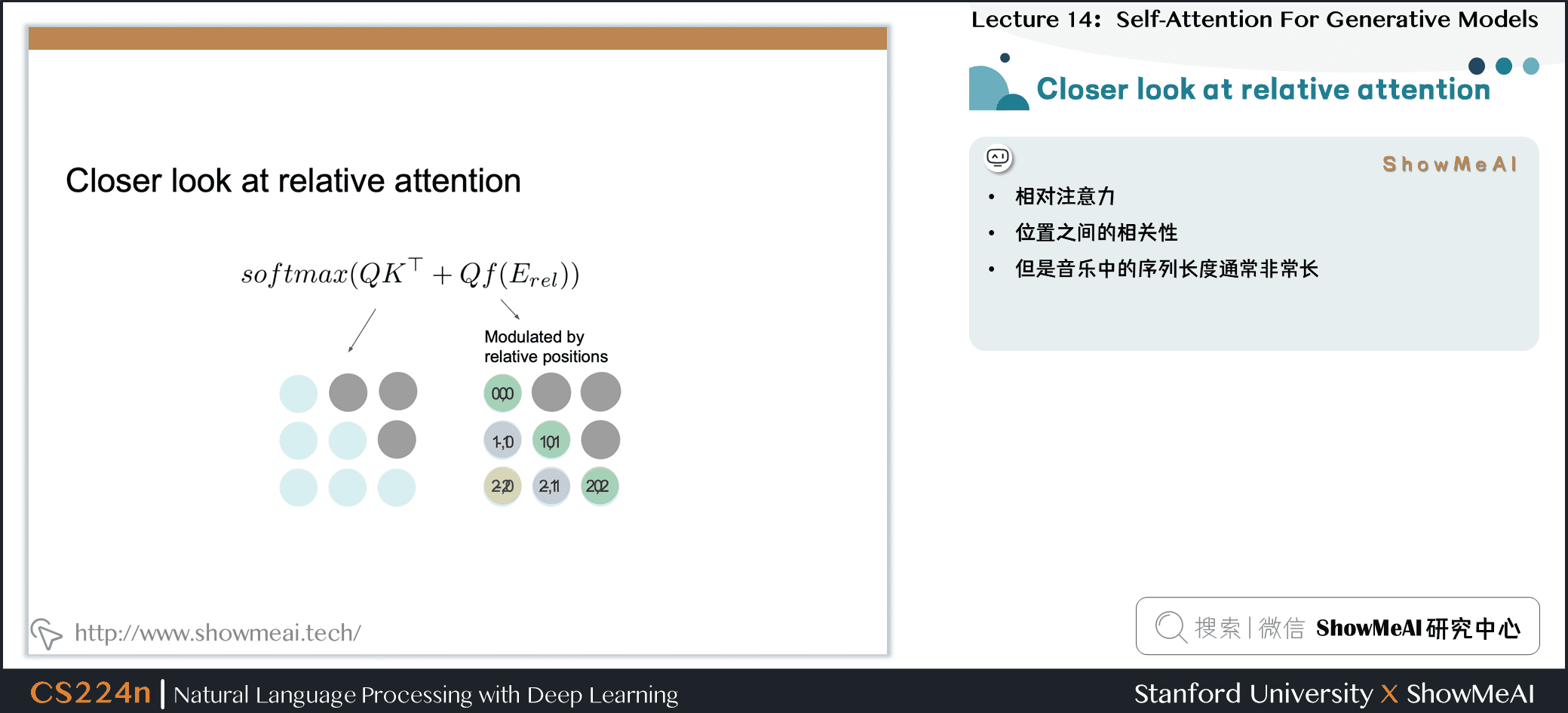
- 相对注意力
- 位置之间的相关性
- 但是音乐中的序列长度通常非常长
8.7 机器翻译
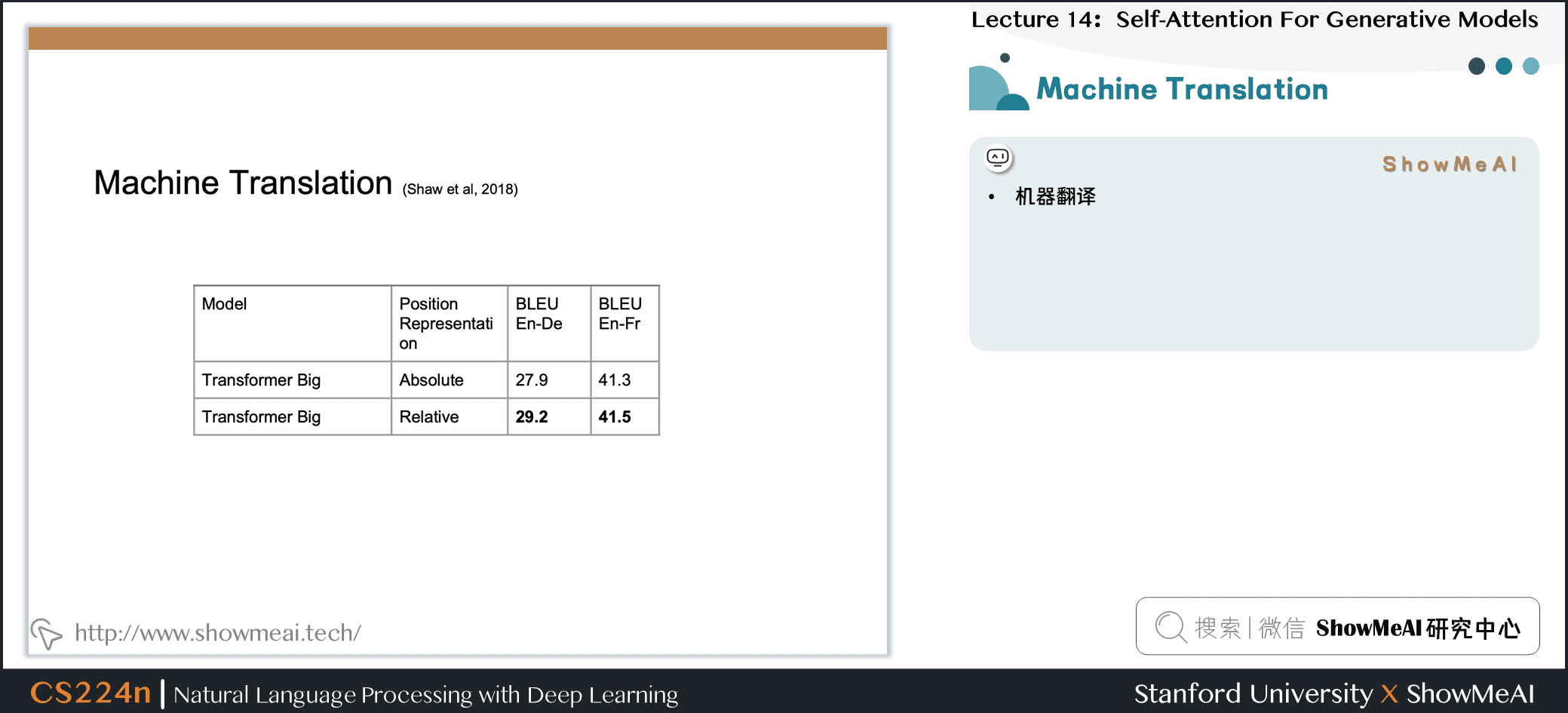
8.8 既有成果

8.9 Our formulation
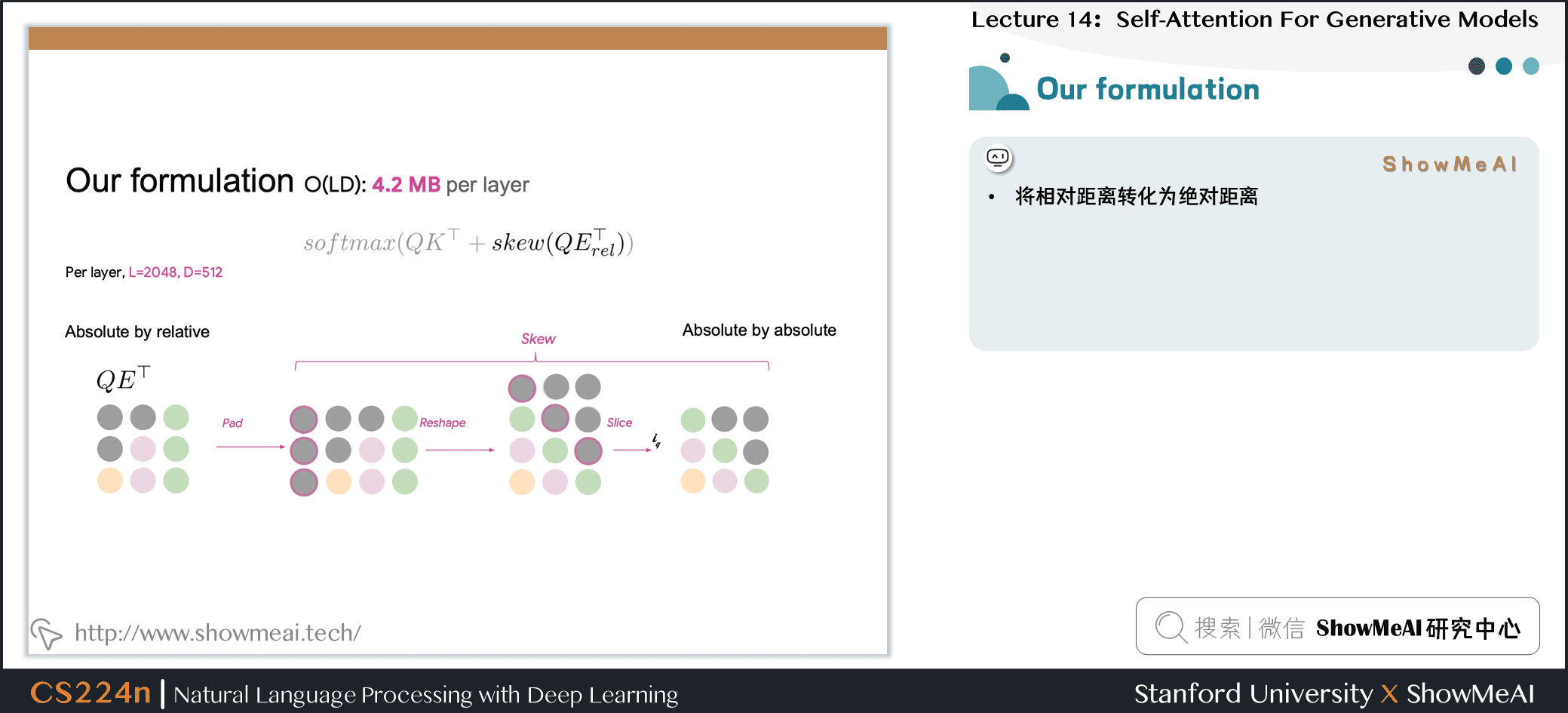
- 将相对距离转化为绝对距离
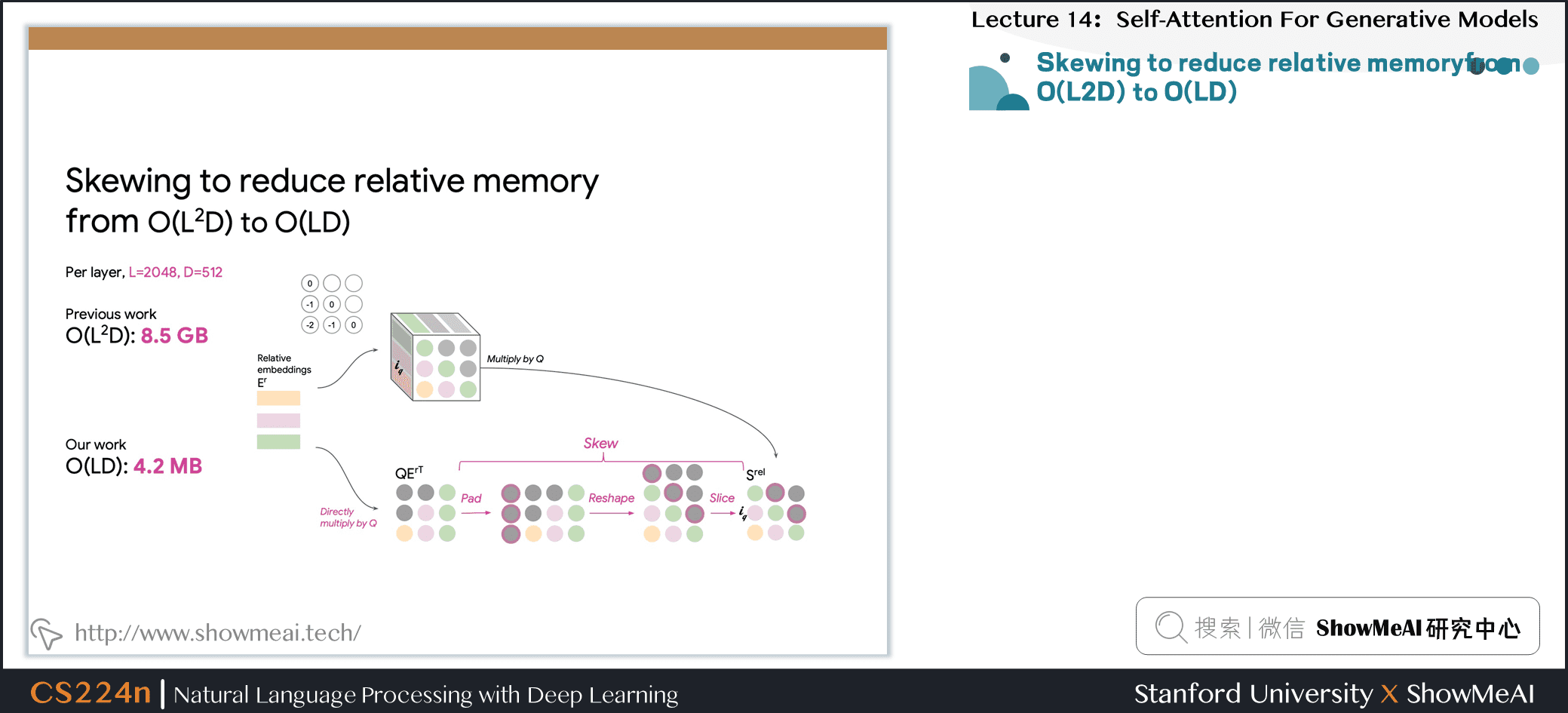
8.10 Goal of skewing procedure

8.11 Skewing to reduce relative memoryfrom O(L2D) to O(LD)
8.12 AJazz sample from Music Transformer
8.13 Convolutions and Translational Equivariance

8.14 Relative Attention And Graphs
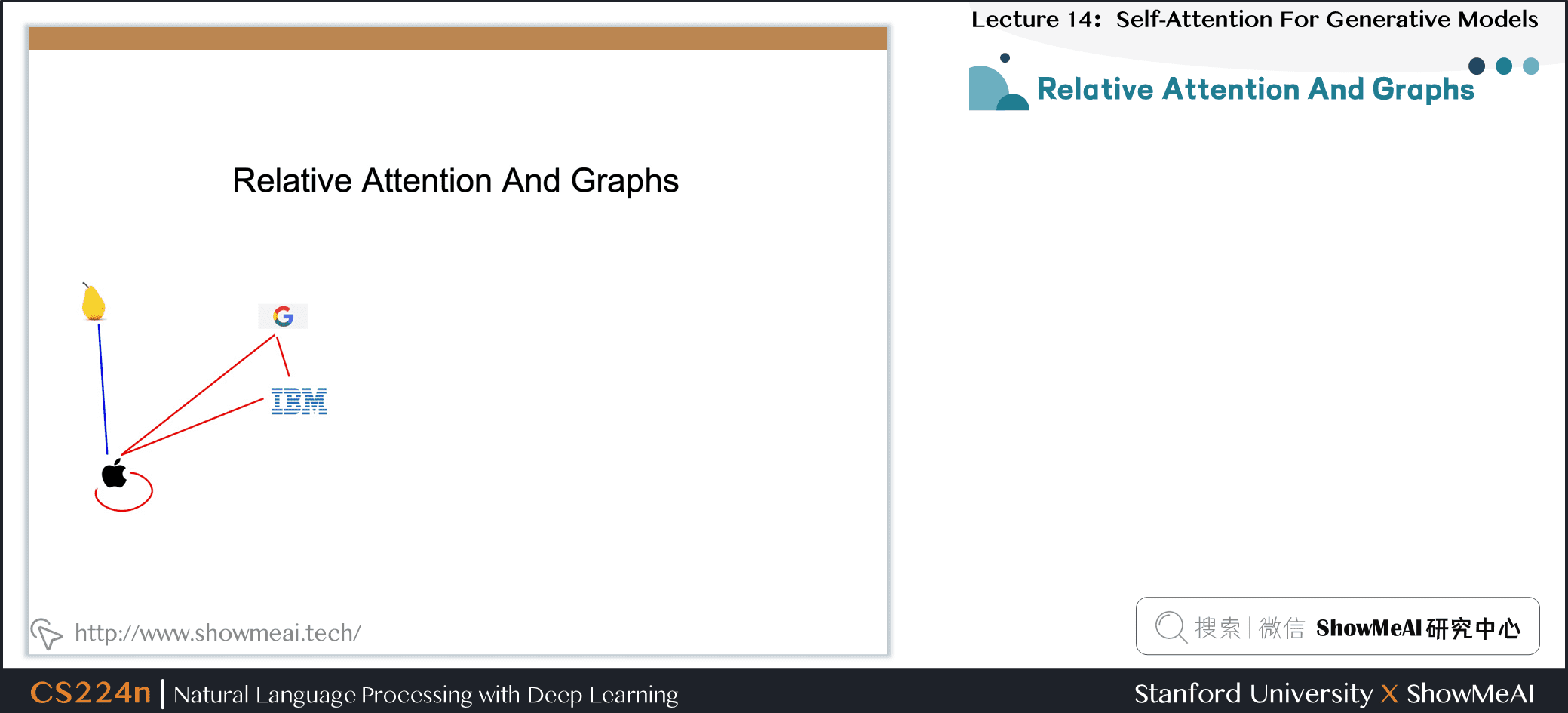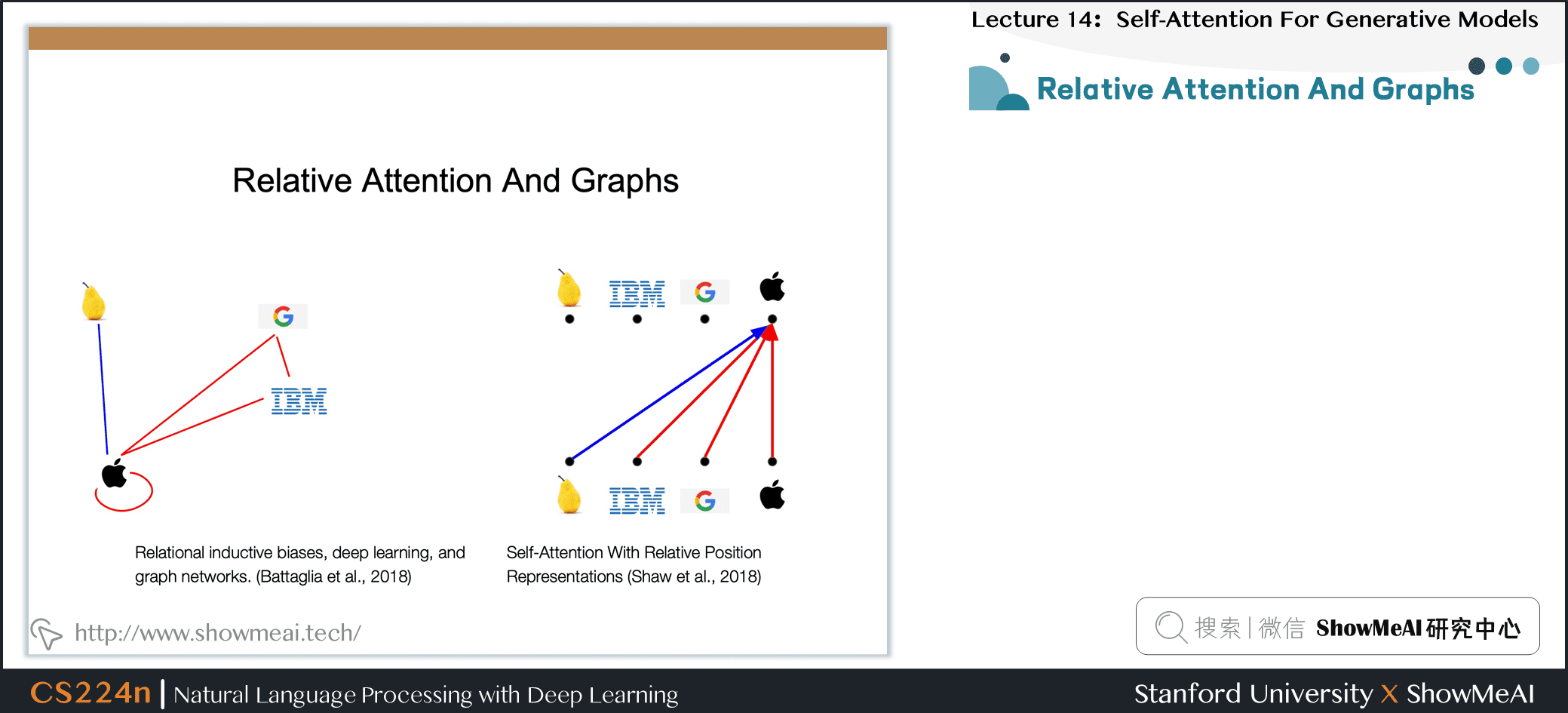
8.15 Message Passing Neural Networks

8.16 多塔结构

8.17 图工具库
8.18 自注意力

- 任意两个位置之间的路径长度是常数级的
- 没有边界的内存
- 易于并行化
- 对自相似性进行建模
- 相对注意力提供了表达时间、equivariance,可以自然延伸至图表
8.19 热门研究领域
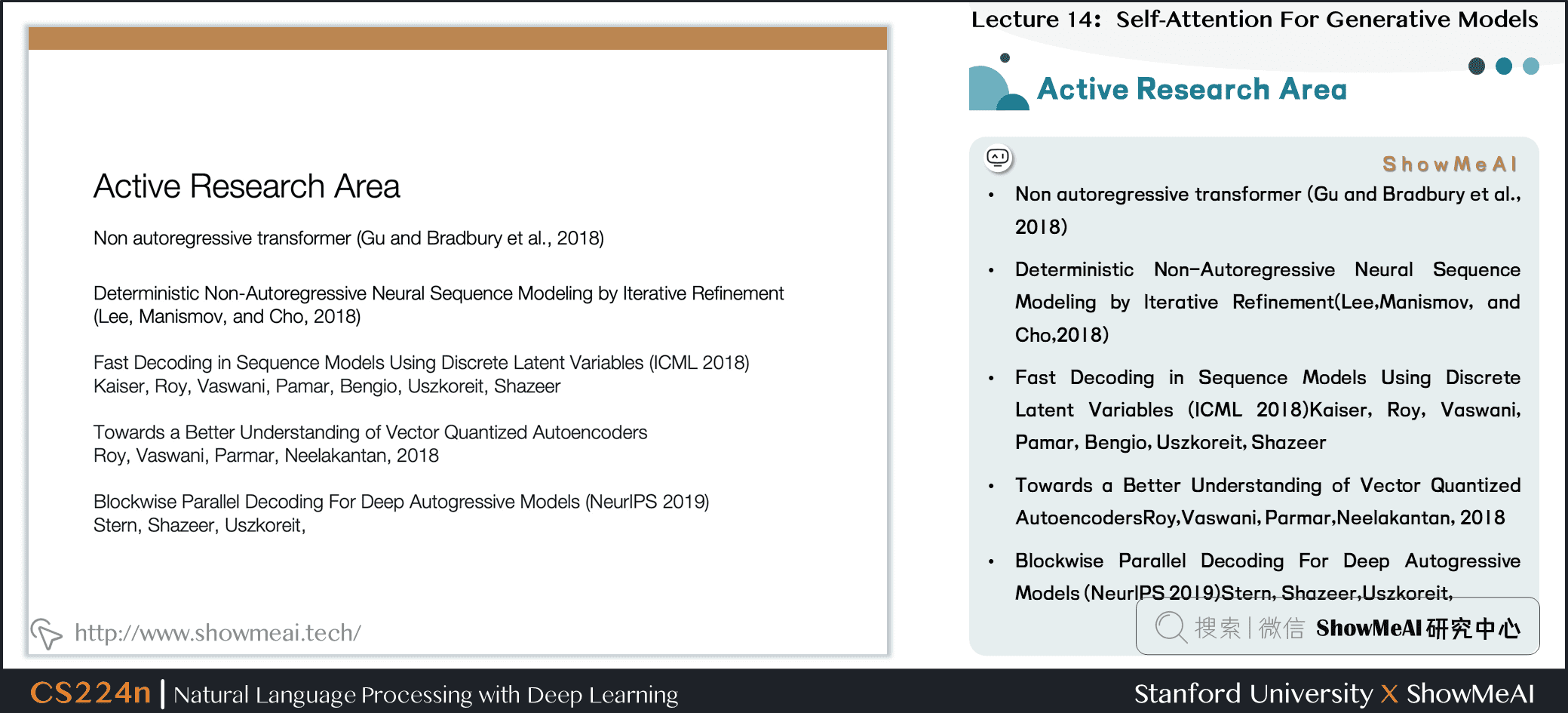
- Non autoregressive transformer (Gu and Bradbury et al., 2018)
- Deterministic Non-Autoregressive Neural Sequence Modeling by lterative Refinement(Lee,Manismov, and Cho,2018)
- Fast Decoding in Sequence Models Using Discrete Latent Variables (ICML 2018)Kaiser, Roy, Vaswani, Pamar, Bengio, Uszkoreit, Shazeer
- Towards a Better Understanding of Vector Quantized AutoencodersRoy,Vaswani, Parmar,Neelakantan, 2018
- Blockwise Parallel Decoding For Deep Autogressive Models (NeurlPS 2019)Stern, Shazeer,Uszkoreit,
9.迁移学习

10.优化&大模型

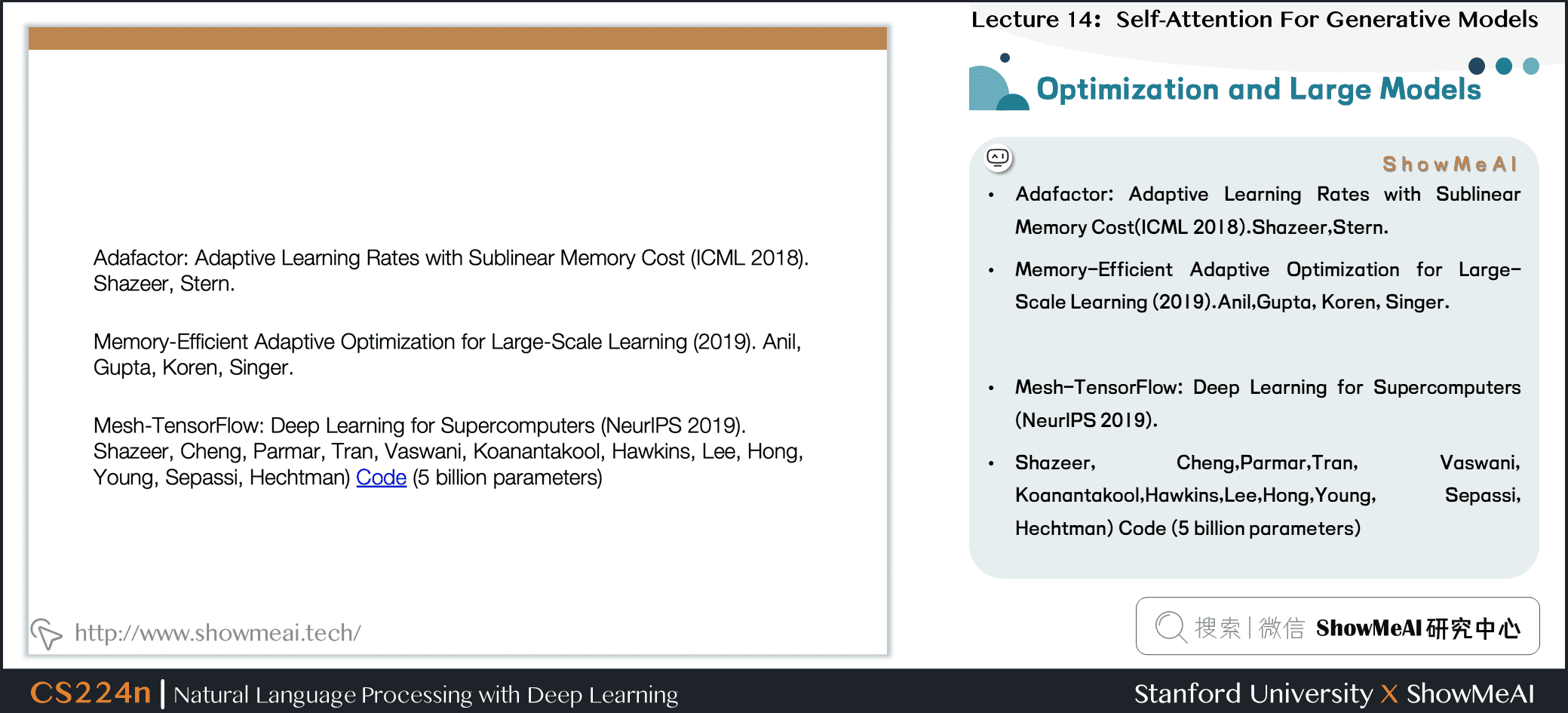
- Adafactor: Adaptive Learning Rates with Sublinear Memory Cost(ICML 2018).Shazeer,Stern.
- Memory-Efficient Adaptive Optimization for Large-Scale Learning (2019).Anil,Gupta, Koren, Singer.
- Mesh-TensorFlow: Deep Learning for Supercomputers (NeurlPS 2019).
- Shazeer, Cheng,Parmar,Tran, Vaswani, Koanantakool,Hawkins,Lee,Hong,Young, Sepassi, Hechtman) Code (5 billion parameters)
11.自注意力其他研究与应用

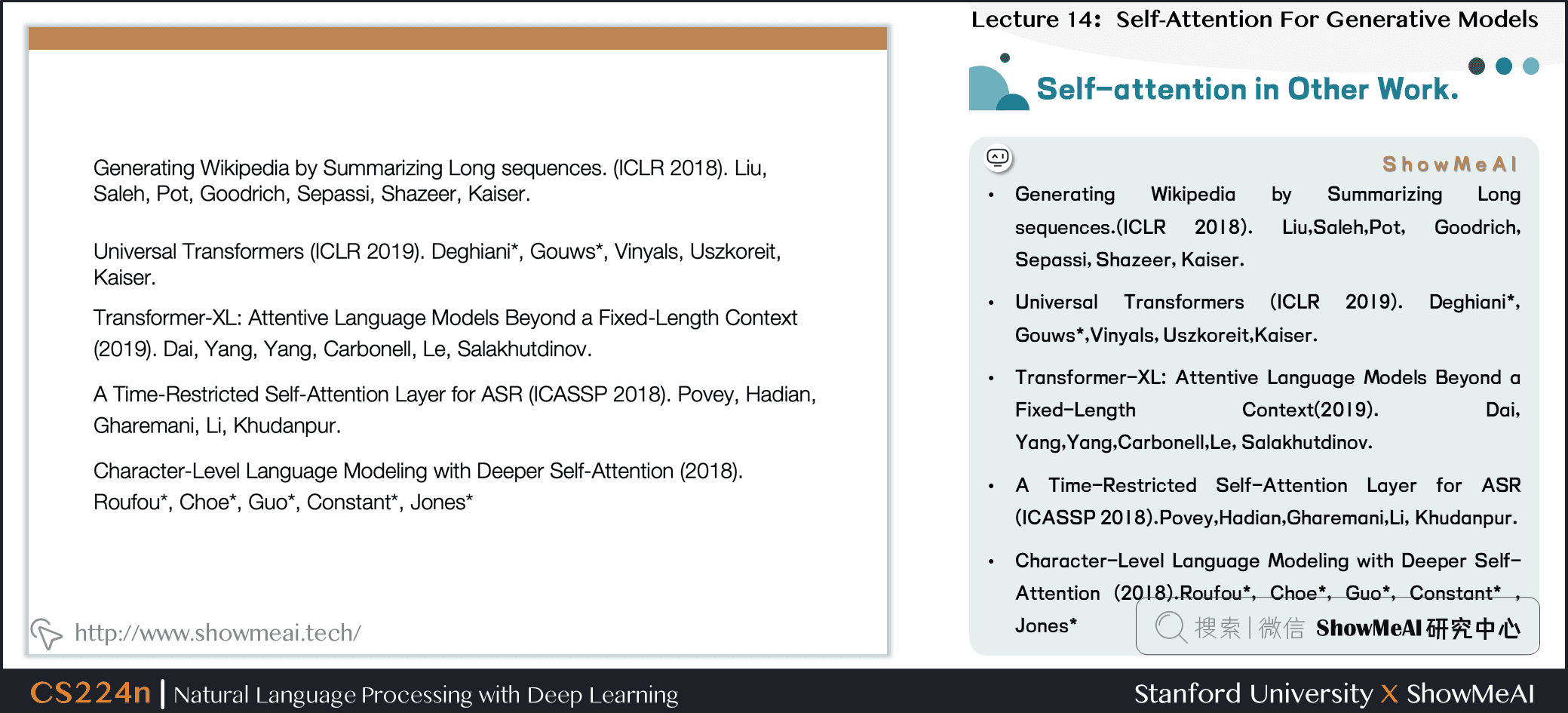
- Generating Wikipedia by Summarizing Long sequences.(ICLR 2018). Liu,Saleh,Pot, Goodrich, Sepassi, Shazeer, Kaiser.
- Universal Transformers (ICLR 2019). Deghiani, Gouws,Vinyals, Uszkoreit,Kaiser.
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(2019). Dai, Yang,Yang,Carbonell,Le, Salakhutdinov.
- A Time-Restricted Self-Attention Layer for ASR (ICASSP 2018).Povey,Hadian,Gharemani,Li, Khudanpur.
- Character-Level Language Modeling with Deeper Self-Attention (2018).Roufou, Choe, Guo, Constant , Jones*
12.未来的工作研究方向

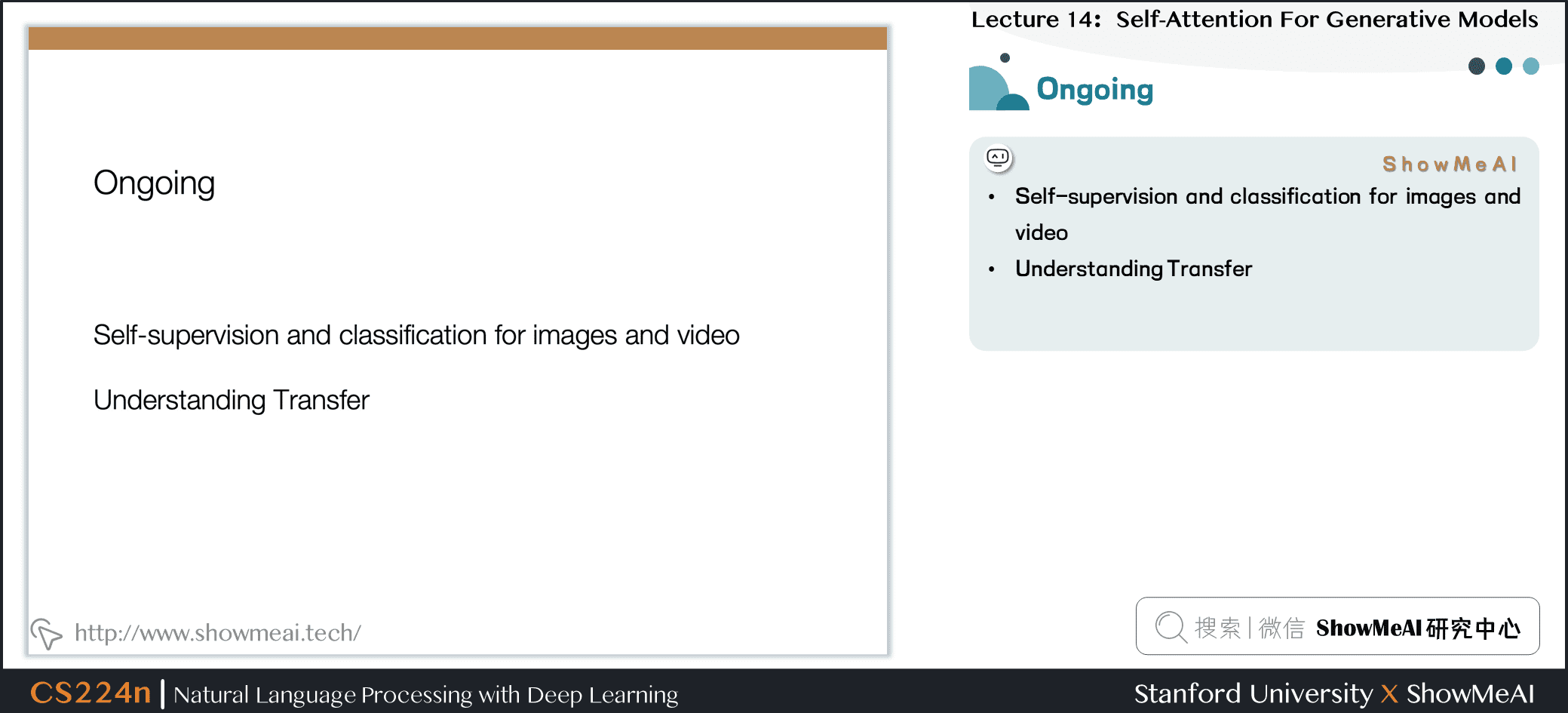
- Self-supervision and classification for images and video
- Understanding Transfer
13.视频教程
可以点击 B站 查看视频的【双语字幕】版本
14.参考资料
- 本讲带学的在线阅翻页版本
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
- Stanford官网 | CS224n: Natural Language Processing with Deep Learning
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
NLP系列教程文章
- NLP教程(1)- 词向量、SVD分解与Word2vec
- NLP教程(2)- GloVe及词向量的训练与评估
- NLP教程(3)- 神经网络与反向传播
- NLP教程(4)- 句法分析与依存解析
- NLP教程(5)- 语言模型、RNN、GRU与LSTM
- NLP教程(6)- 神经机器翻译、seq2seq与注意力机制
- NLP教程(7)- 问答系统
- NLP教程(8)- NLP中的卷积神经网络
- NLP教程(9)- 句法分析与树形递归神经网络
斯坦福 CS224n 课程带学详解
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
- 斯坦福NLP课程 | 第3讲 - 神经网络知识回顾
- 斯坦福NLP课程 | 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP课程 | 第5讲 - 句法分析与依存解析
- 斯坦福NLP课程 | 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP课程 | 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP课程 | 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP课程 | 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP课程 | 第10讲 - NLP中的问答系统
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP课程 | 第12讲 - 子词模型
- 斯坦福NLP课程 | 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP课程 | 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
- 斯坦福NLP课程 | 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP课程 | 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP课程 | 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP课程 | 第19讲 - AI安全偏见与公平
- 斯坦福NLP课程 | 第20讲 - NLP与深度学习的未来


