
斯坦福NLP课程 | 第12讲 - NLP子词模型
 NLP课程第12讲介绍了语法学 (linguistics) 基础知识、基于字符粒度的模型、子词模型 (Subword-models)、混合字符与词粒度的模型、fastText模型等。
NLP课程第12讲介绍了语法学 (linguistics) 基础知识、基于字符粒度的模型、子词模型 (Subword-models)、混合字符与词粒度的模型、fastText模型等。

- 作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/36
- 本文地址:https://www.showmeai.tech/article-detail/249
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

ShowMeAI为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》课程的全部课件,做了中文翻译和注释,并制作成了GIF动图!视频和课件等资料的获取方式见文末。
引言

授课计划

- A tiny bit of linguistics / 语法学基础知识
- Purely character-level models / 基于字符粒度的模型
- Subword-models: Byte Pair Encoding and friends / 子词模型
- Hybrid character and word level models / 混合字符与词粒度的模型
- fastText / fastText模型
1.语法学基础知识
1.1 人类语言的声音:语音学和语音体系

- 语音学 (honetics) 是音流无争议的
物理学
- 语音体系 (Phonology) 假定了一组或多组独特的、分类的单元:音素 (phoneme) 或者是独特的特征
- 这也许是一种普遍的类型学,但却是一种特殊的语言实现
- 分类感知的最佳例子就是语音体系
- 音位差异缩小
- 音素之间的放大
1.2 词法:词类

- 传统上,词素 (morphemes) 是最小的语义单位
\[\left[\left[\text {un}\left[[\text { fortun }(\mathrm{e})]_{\text { Root }} \text { ate }\right]_{\text { STEM }}\right]_{\text { STEM }} \text {ly}\right]_{\text { WORD }}
\]
- 深度学习:形态学研究较少;递归神经网络的一种尝试是 (Luong, Socher, & Manning 2013)
- 处理更大词汇量的一种可能方法:大多数看不见的单词是新的形态(或数字)
- 声音本身在语言中没有意义
- parts of words 是音素的下一级的形态学,是具有意义的最低级别
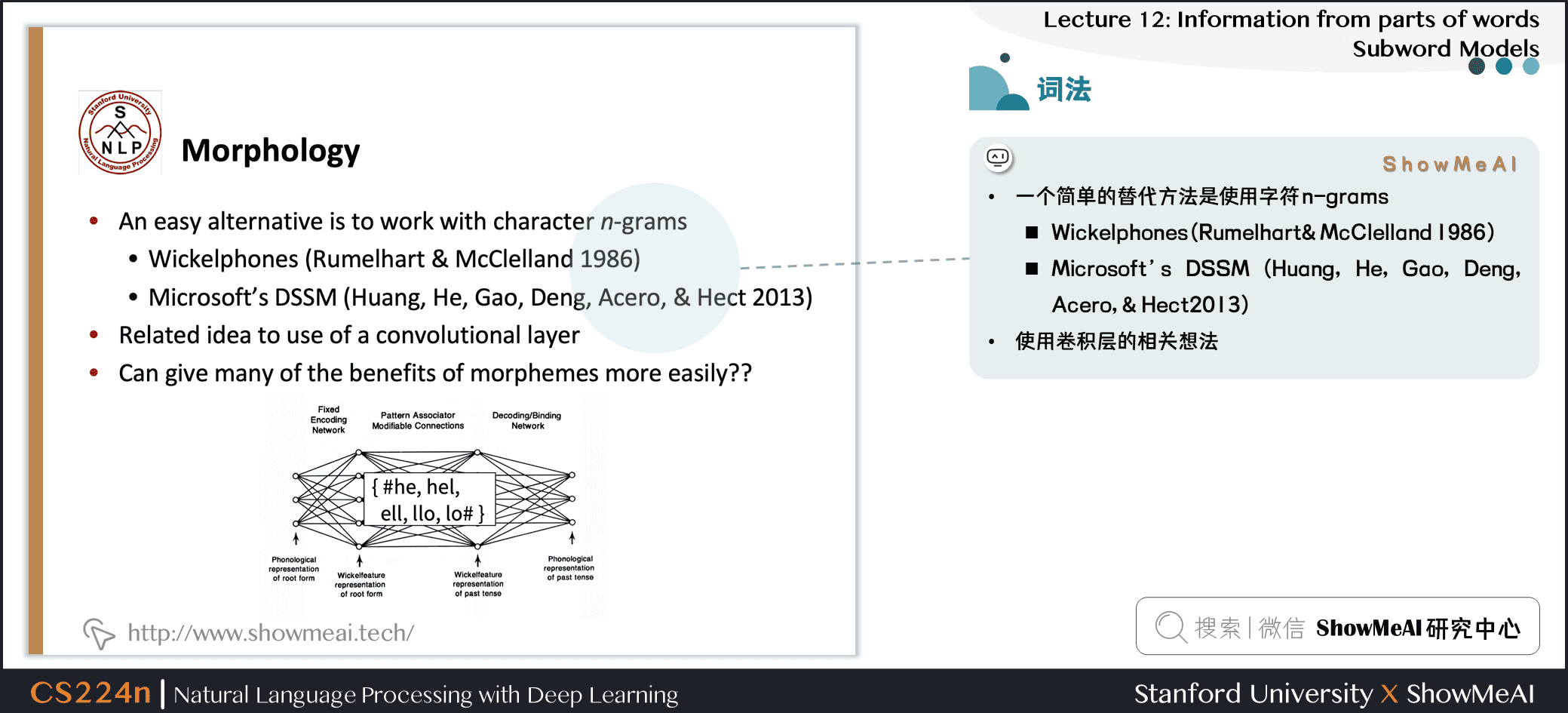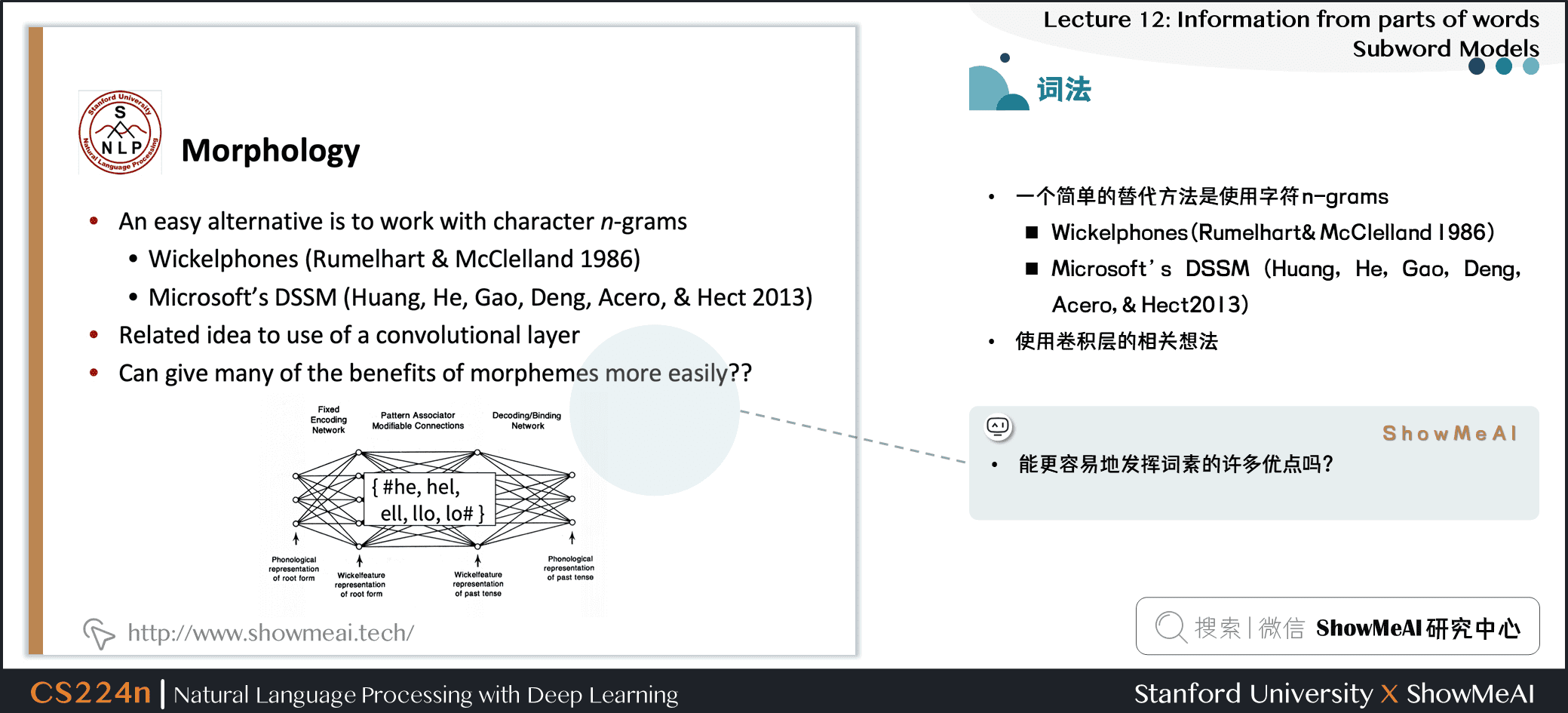
- 一个简单的替代方法是使用字符 n-grams
- Wickelphones (Rumelhart & McClelland 1986)
- Microsoft’s DSSM (Huang, He, Gao, Deng, Acero, & Hect2013)
- 使用卷积层的相关想法
- 能更容易地发挥词素的许多优点吗?
1.3 书写系统中的单词
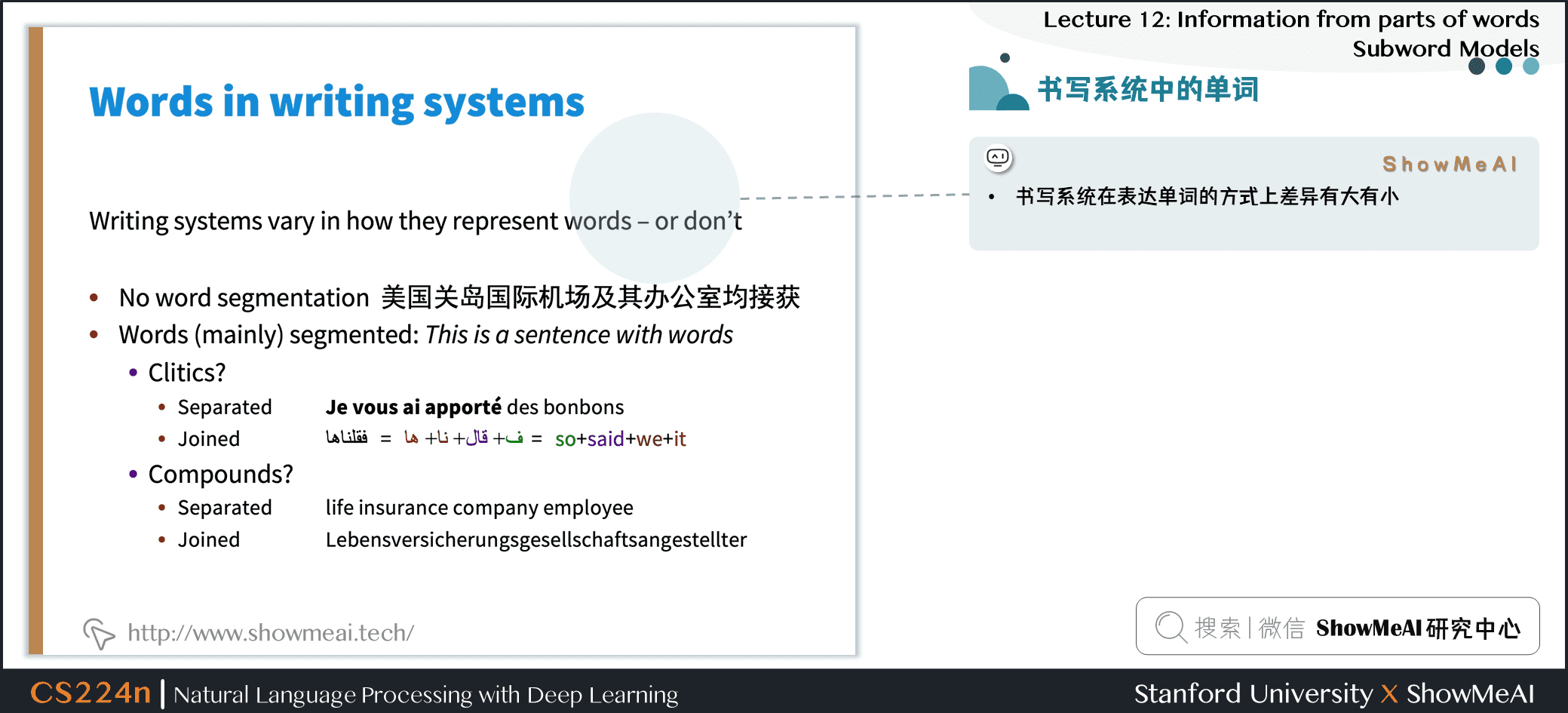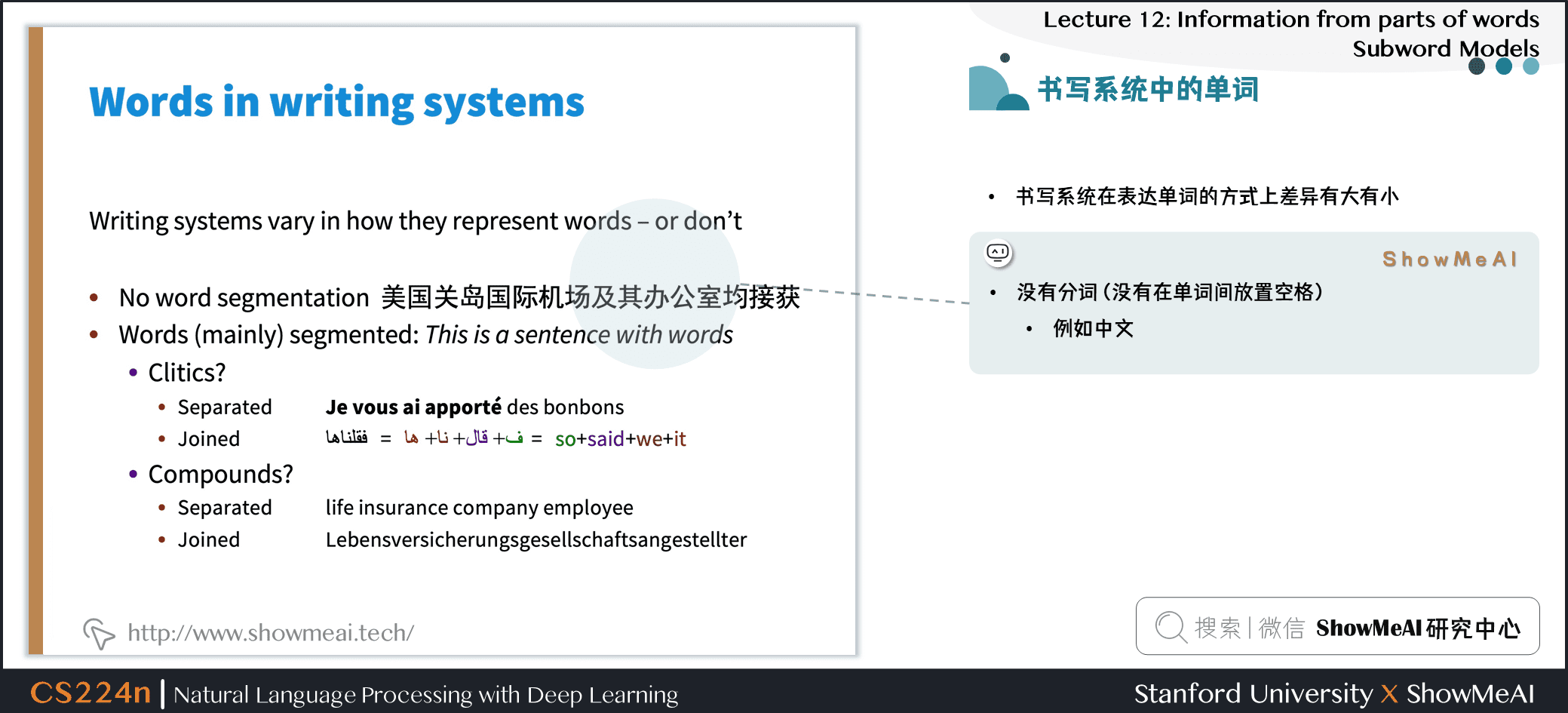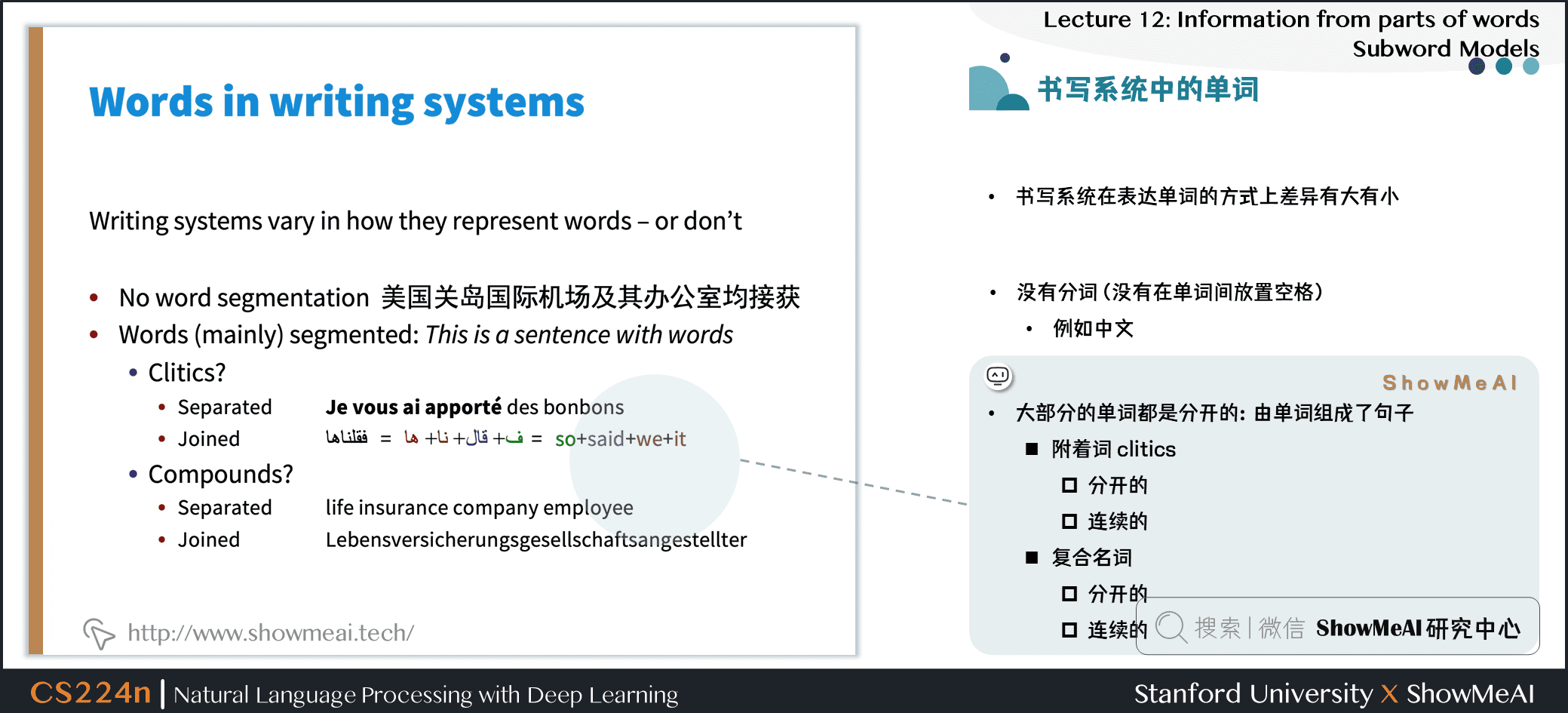
- 书写系统在表达单词的方式上差异有大有小
- 没有分词 (没有在单词间放置空格)
- 例如中文
- 大部分的单词都是分开的:由单词组成了句子
- 附着词
- 分开的
- 连续的
- 复合名词
- 分开的
- 连续的
- 附着词
1.4 比单词粒度更细的模型

- 需要处理数量很大的开放词汇:巨大的、无限的单词空间
- 丰富的形态
- 音译 (特别是名字,在翻译中基本上是音译)
- 非正式的拼写
1.5 字符级模型
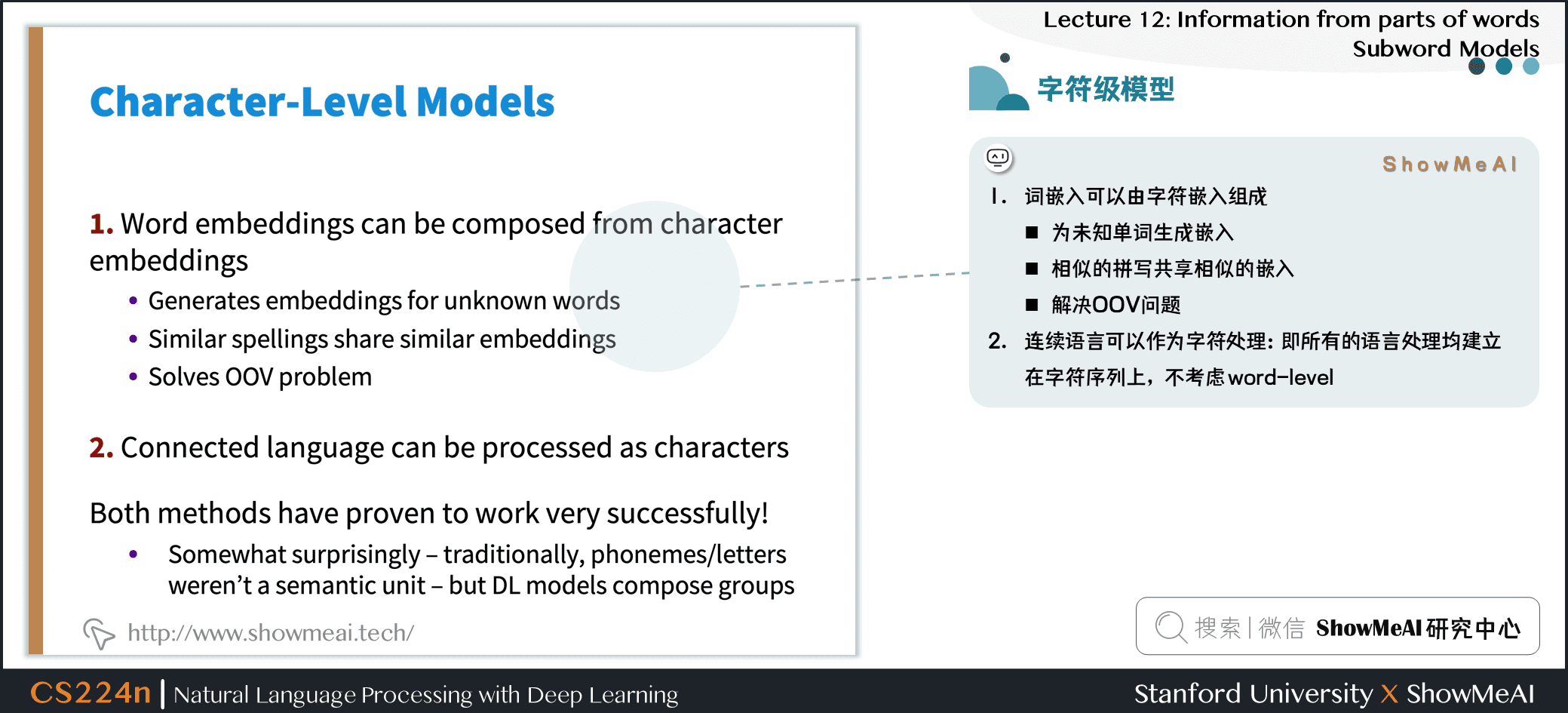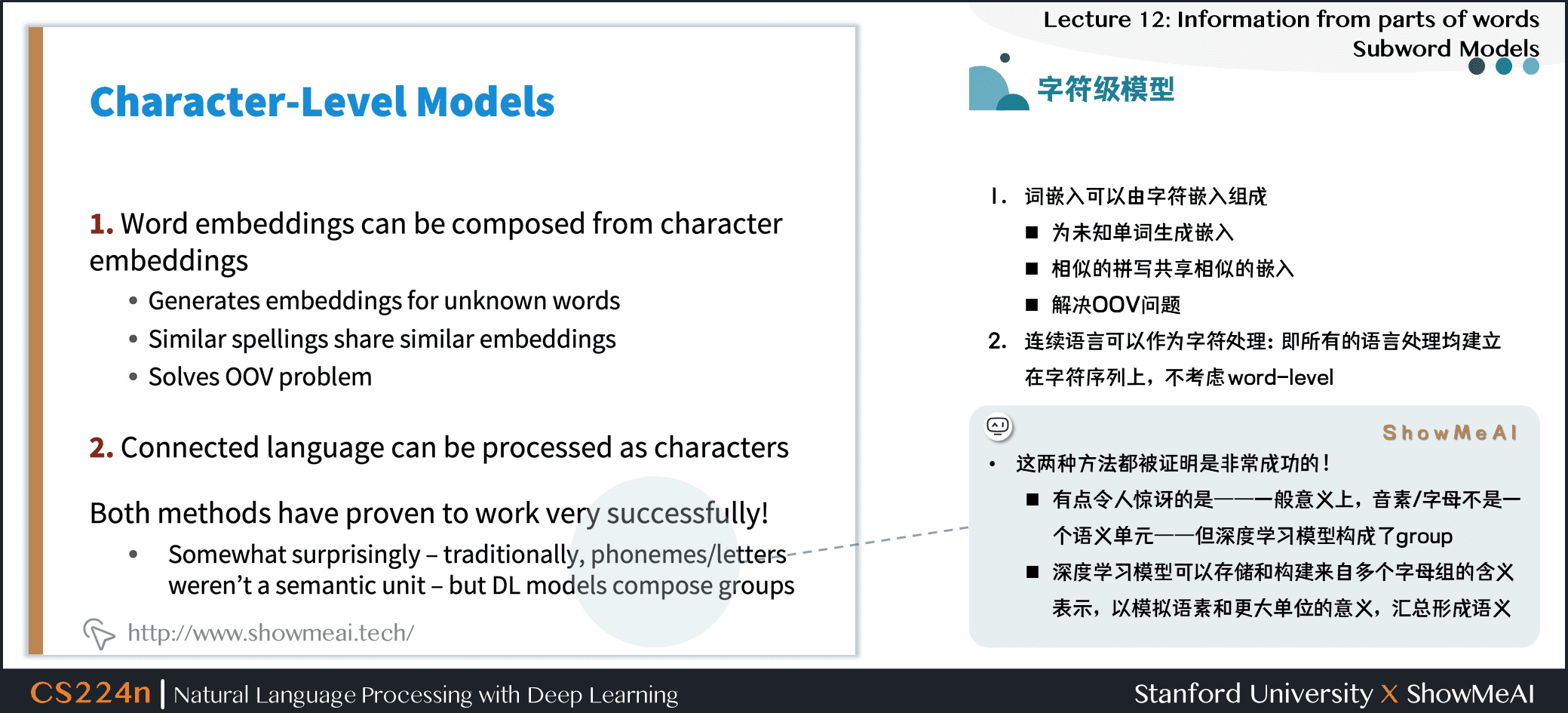
-
① 词嵌入可以由字符嵌入组成
- 为未知单词生成嵌入
- 相似的拼写共享相似的嵌入
- 解决OOV问题
-
② 连续语言可以作为字符处理:即所有的语言处理均建立在字符序列上,不考虑 word-level
- 这两种方法都被证明是非常成功的!
- 有点令人惊讶的是:一般意义上,音素/字母不是一个语义单元:但深度学习模型构成了group
- 深度学习模型可以存储和构建来自多个字母组的含义表示,以模拟语素和更大单位的意义,汇总形成语义
1.6 单词之下:书写系统

- 大多数深度学习NLP的工作,都是从语言的书面形式开始的:这是一种容易处理的、现成的数据
- 但是人类语言书写系统不是一回事!各种语言的字符是不同的!
2.基于字符粒度的模型
2.1 纯字符级模型

- 上节课,我们看到了一个很好的用于句子分类的纯字符级模型的例子
- 非常深的卷积网络用于文本分类
- Conneau, Schwenk, Lecun, Barrault.EACL 2017
- 强大的结果通过深度卷积堆叠
2.2 字符级别输入输出的机器翻译系统
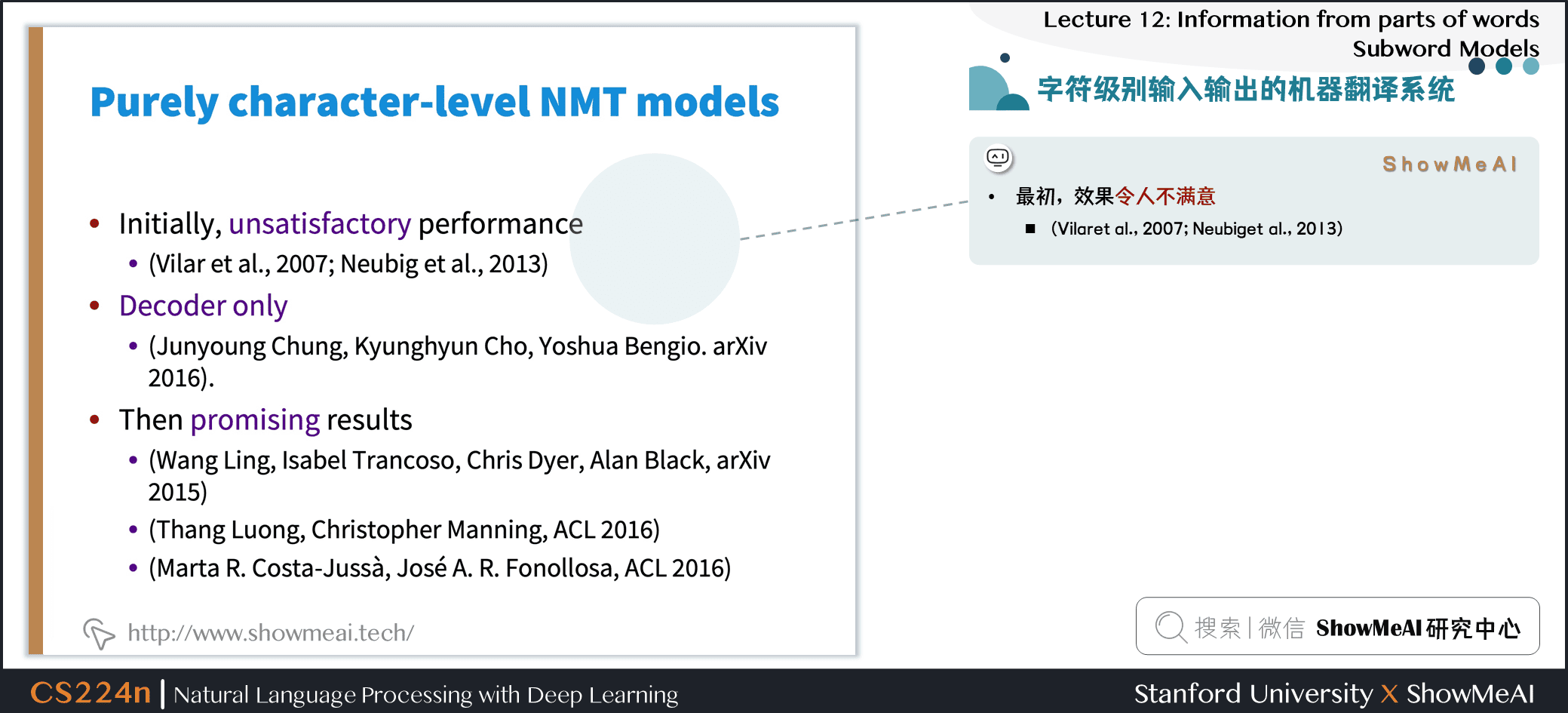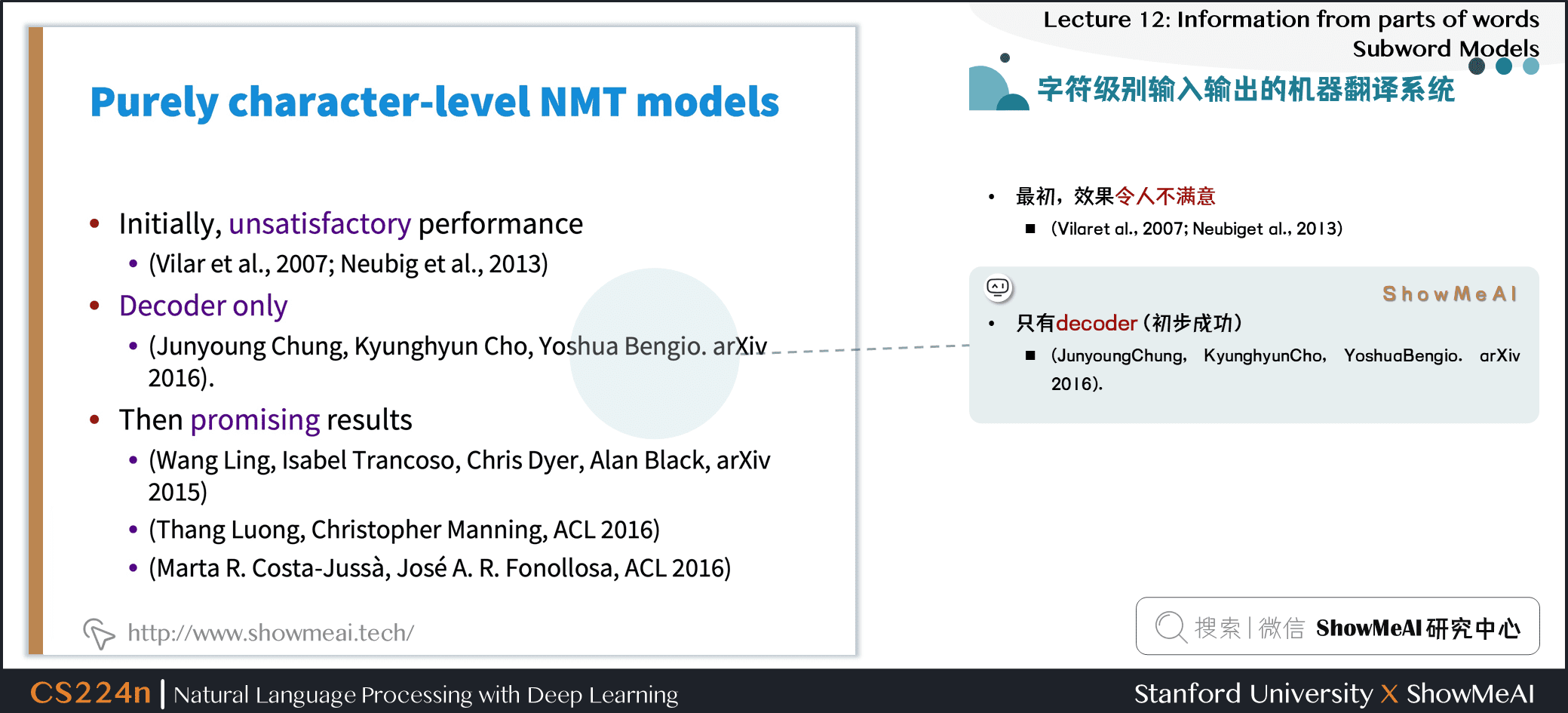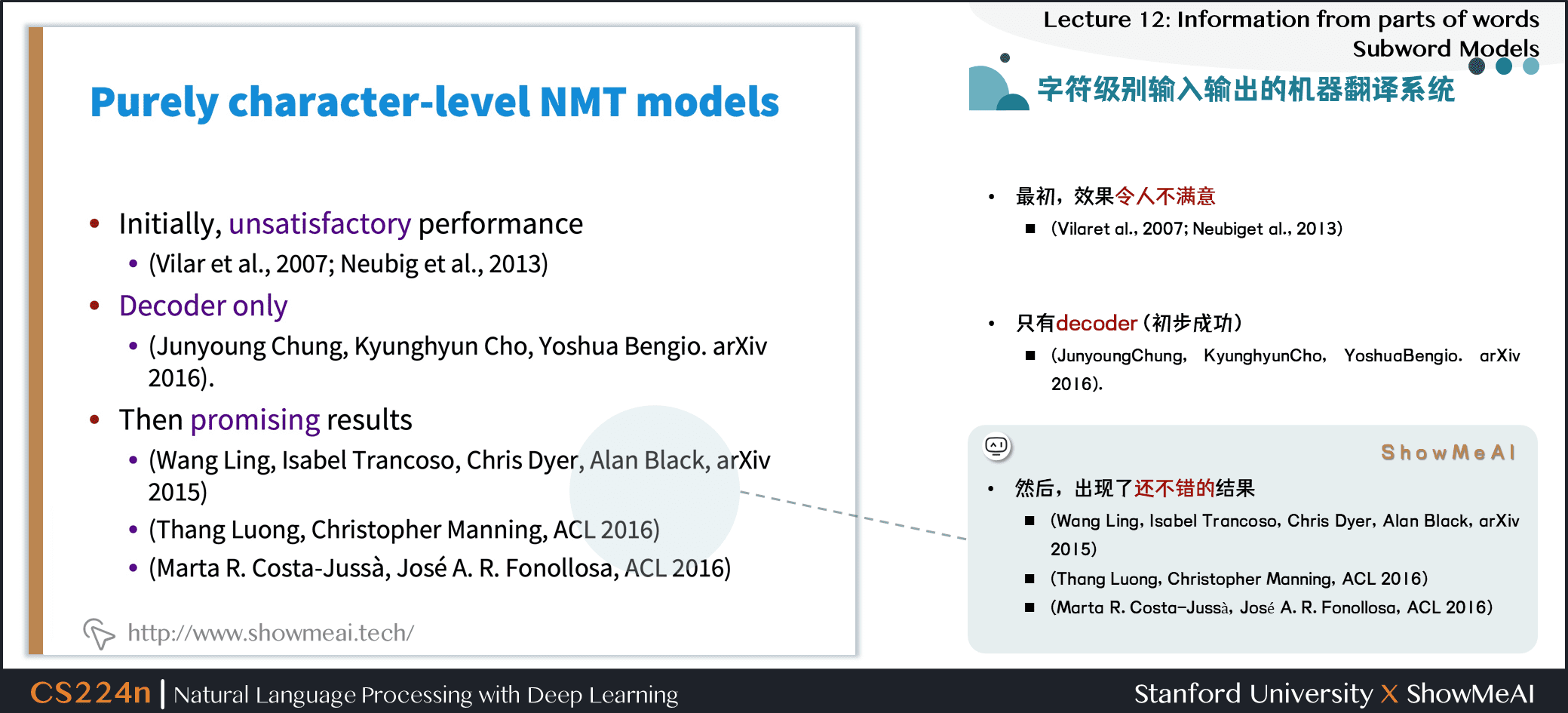
- 最初,效果令人不满意
- (Vilaret al., 2007; Neubiget al., 2013)
- 只有decoder (初步成功)
- (JunyoungChung, KyunghyunCho, YoshuaBengio. arXiv 2016).
- 然后,出现了还不错的结果
- (Wang Ling, Isabel Trancoso, Chris Dyer, Alan Black, arXiv 2015)
- (Thang Luong, Christopher Manning, ACL 2016)
- (Marta R. Costa-Jussà, José A. R. Fonollosa, ACL 2016)
2.3 English-Czech WMT 2015 Results


- Luong 和 Manning 测试了一个纯字符级 seq2seq (LSTM) NMT 系统作为基线
- 它在单词级基线上运行得很好
- 对于 UNK,是用 single word translation 或者 copy stuff from the source
- 字符级的 model 效果更好了,但是太慢了
- 但是运行需要3周的时间来训练,运行时没那么快
- 如果放进了 LSTM 中,序列长度变为以前的数倍 (大约七倍)
2.4 无显式分割的完全字符级神经机器翻译

- Jason Lee, KyunghyunCho, Thomas Hoffmann. 2017.
- 编码器如下
- 解码器是一个字符级的 GRU
2.5 #论文解读# Stronger character results with depth in LSTM seq2seq model

- Revisiting Character-Based Neural Machine Translation with Capacity and Compression. 2018. Cherry, Foster, Bapna, Firat, Macherey, Google AI
- 在 LSTM-seq2seq 模型中,随着深度的增加,特征越强
- 在捷克语这样的复杂语言中,字符级模型的效果提升较为明显,但是在英语和法语等语言中则收效甚微。
- 模型较小时,word-level 更佳
- 模型较大时,character-level 更佳
3.子词模型
3.1 子词模式:两种趋势

- 与 word 级模型相同的架构
- 但是使用更小的单元:
word pieces - [Sennrich, Haddow, Birch, ACL’16a], [Chung, Cho, Bengio, ACL’16].
- 但是使用更小的单元:
- 混合架构
- 主模型使用单词,其他使用字符级
- [Costa-Jussà& Fonollosa, ACL’16], [Luong & Manning, ACL’16].
3.2 字节对编码/BPE

- 最初的压缩算法
- 最频繁的字节 → 一个新的字节。
- 用字符 ngram 替换字节(实际上,有些人已经用字节做了一些有趣的事情)
- Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural Machine Translation of Rare Words with SubwordUnits. ACL 2016.

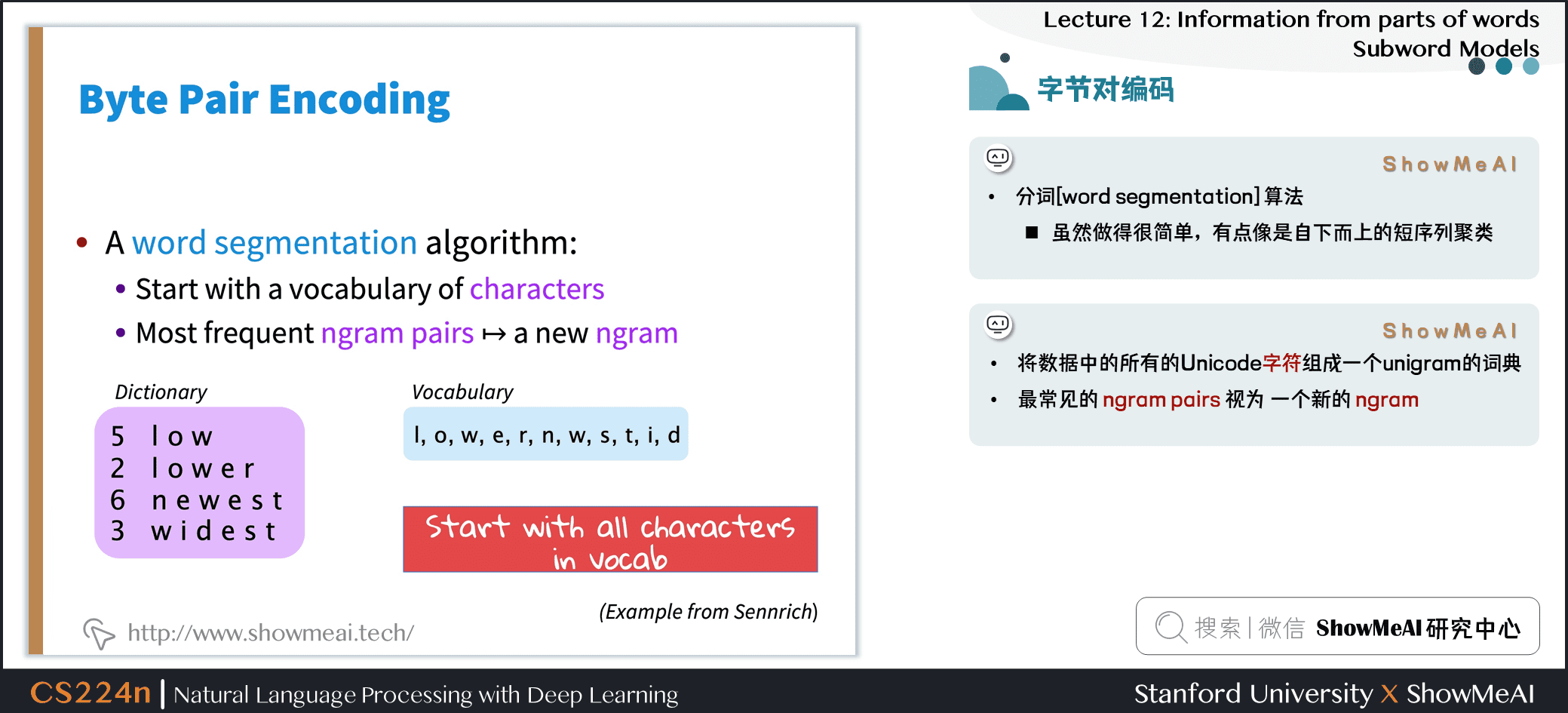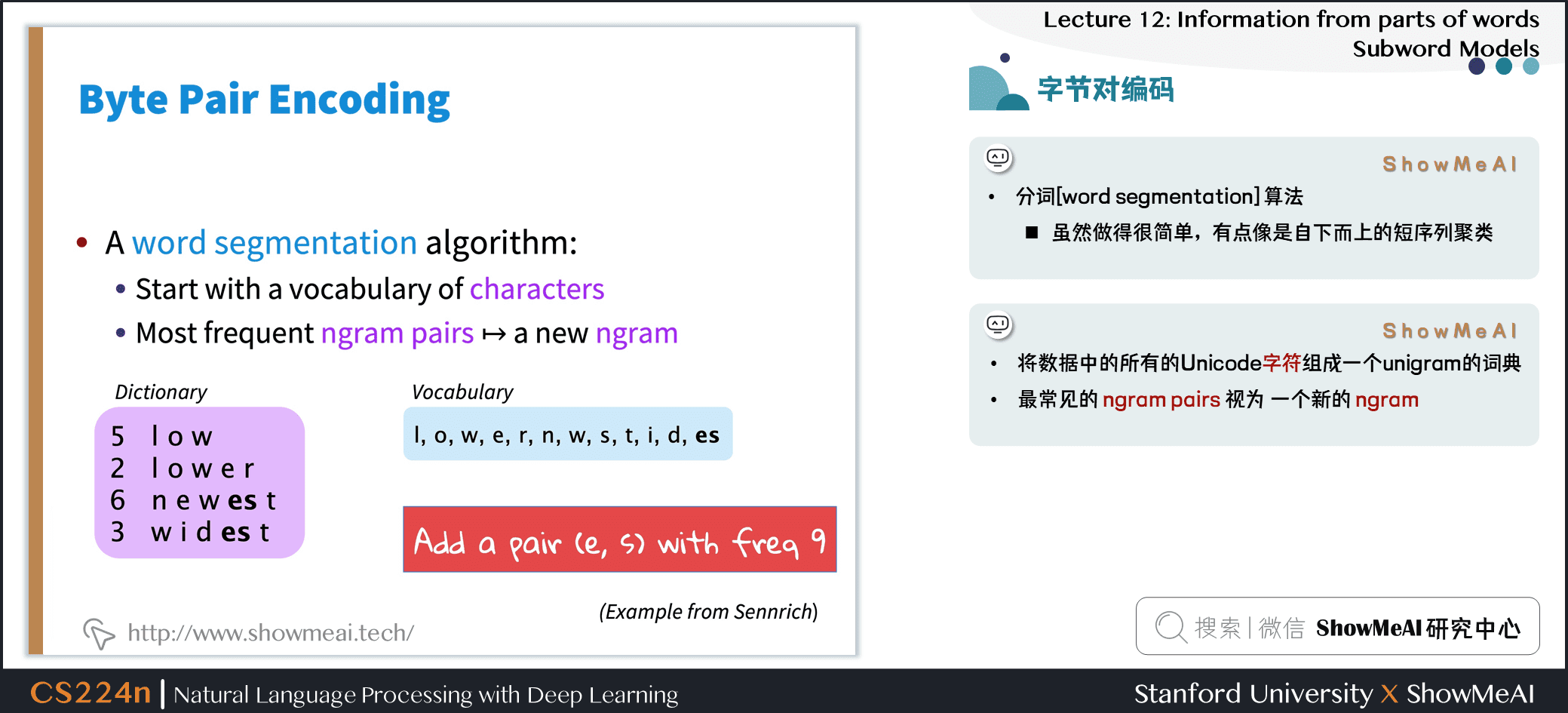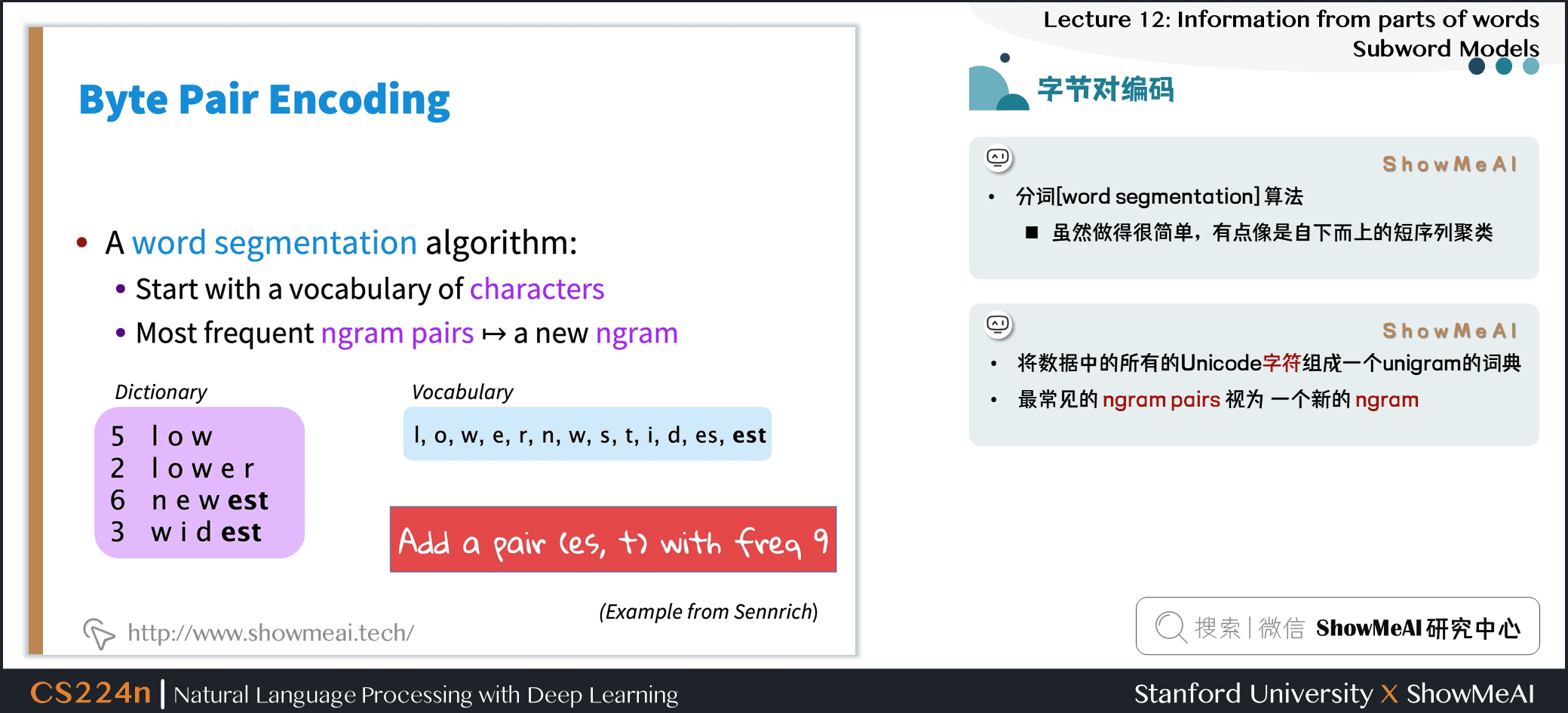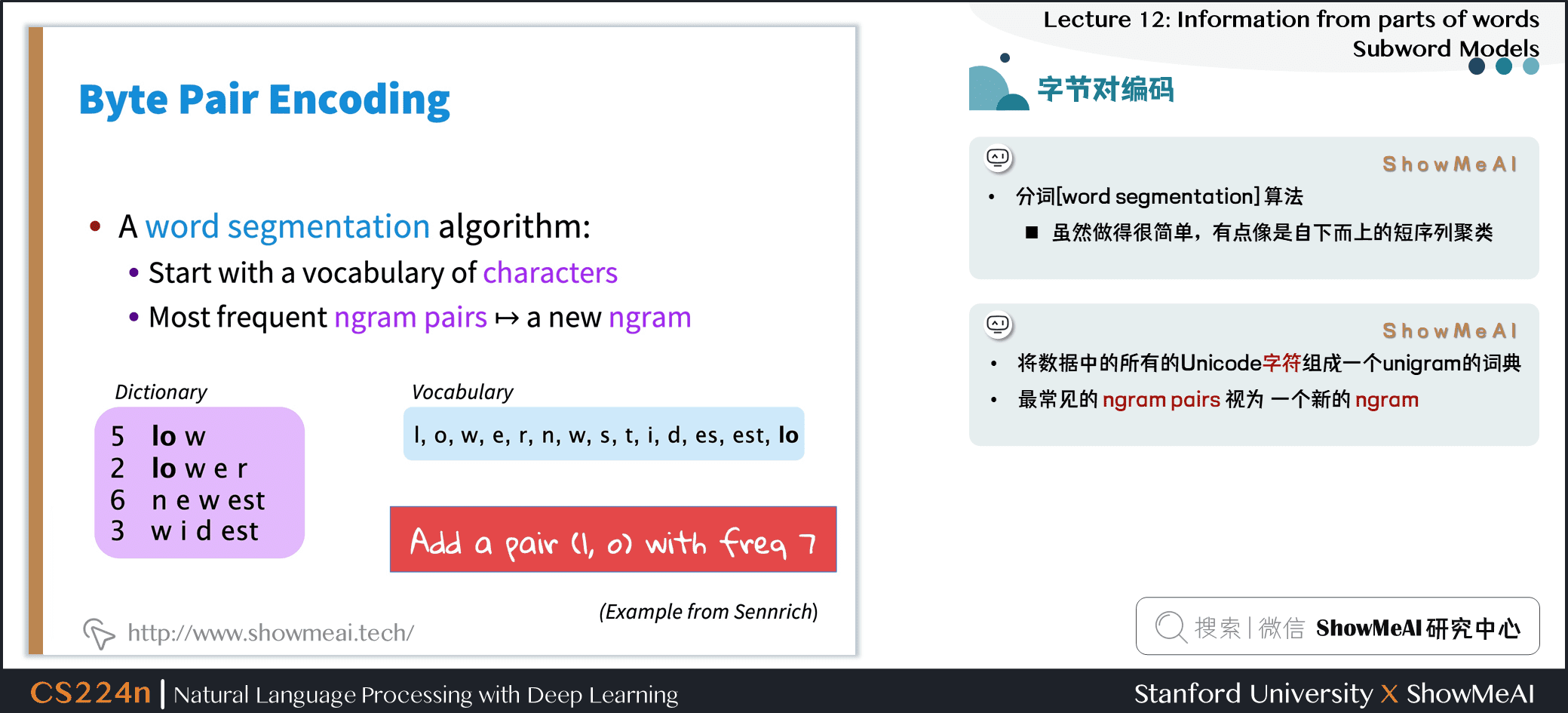
- 分词 (word segmentation) 算法
- 虽然做得很简单,有点像是自下而上的短序列聚类
- 将数据中的所有的 Unicode 字符组成一个 unigram 的词典
- 最常见的 ngram pairs 视为 一个新的 ngram
- BPE 并未深度学习的有关算法,但已成为标准且成功表示 pieces of words 的方法,可以获得一个有限的词典与无限且有效的词汇表。

- 有一个目标词汇量,当你达到它的时候就停止
- 做确定性的最长分词分割
- 分割只在某些先前标记器 (通常MT使用的 Moses tokenizer) 标识的单词中进行
- 自动为系统添加词汇
- 不再是基于传统方式的 strongly
word
- 不再是基于传统方式的 strongly
- 2016年WMT排名第一!仍然广泛应用于2018年WMT
- https://github.com/rsennrich/nematus
3.3 Wordpiece / Sentencepiece模型
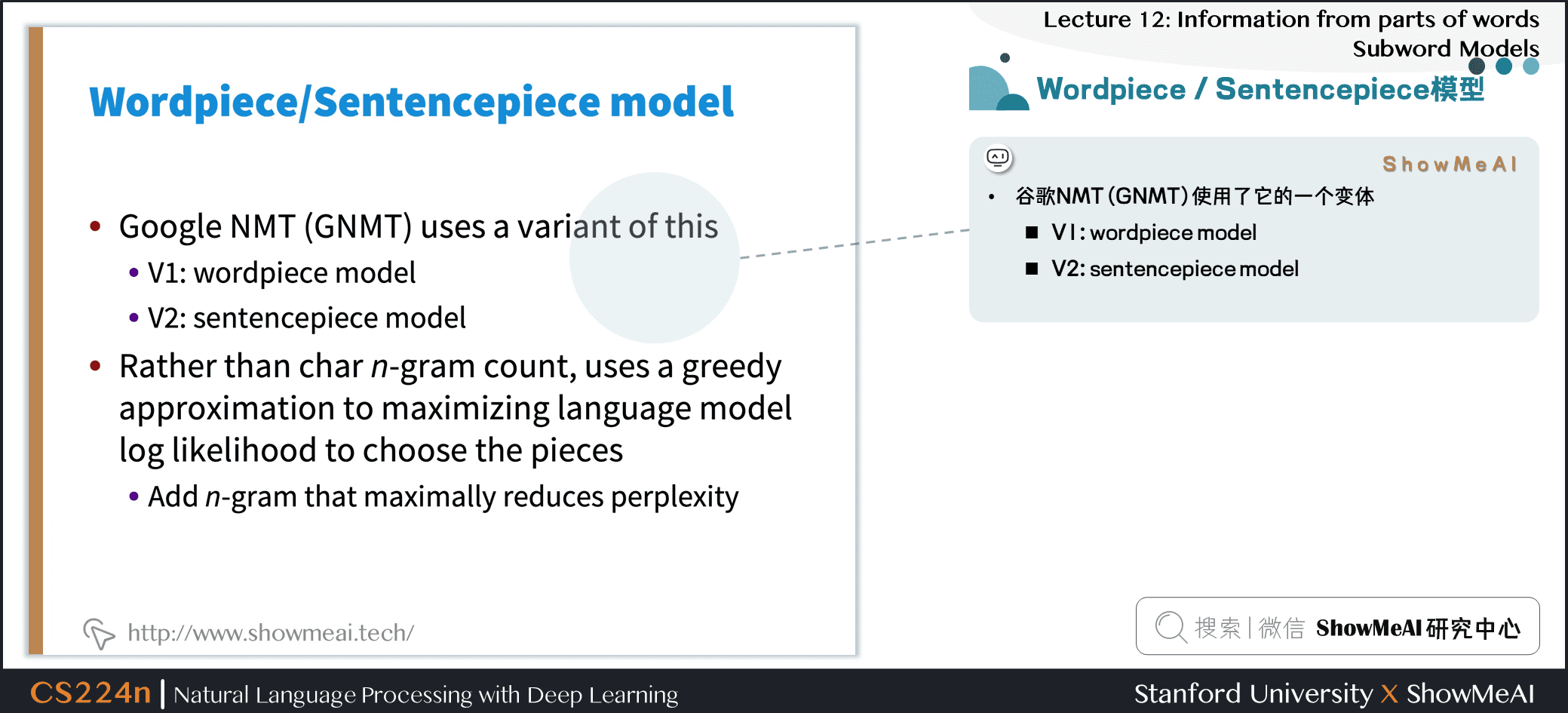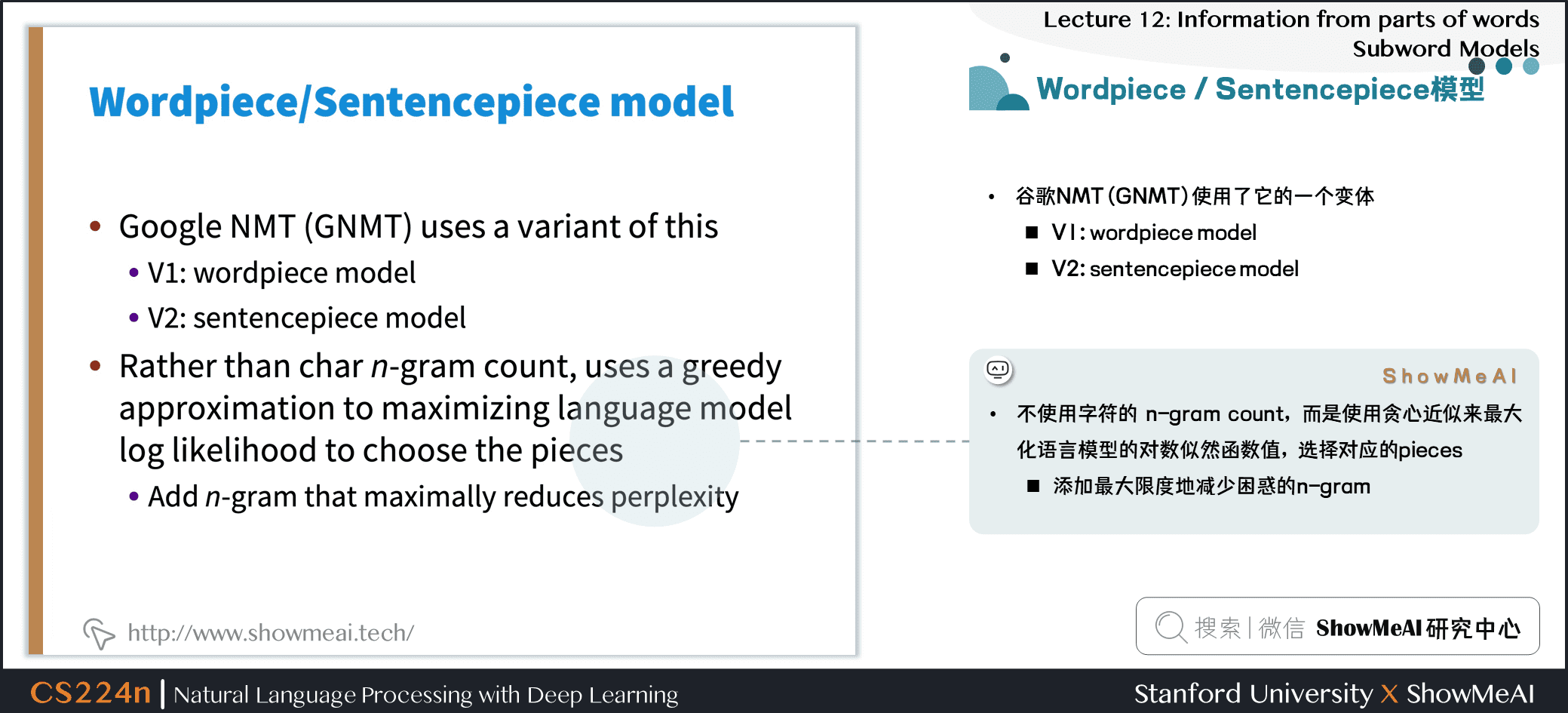
- 谷歌 NMT (GNMT) 使用了它的一个变体
- V1: wordpiece model
- V2: sentencepiece model
- 不使用字符的 n-gram count,而是使用贪心近似来最大化语言模型的对数似然函数值,选择对应的 pieces
- 添加最大限度地减少困惑的 n-gram

- Wordpiece模型标记内部单词
- Sentencepiece模型使用原始文本
- 空格被保留为特殊标记(_),并正常分组
- 可以通过将片段连接起来并将它们重新编码到空格中,从而在末尾将内容反转

- BERT 使用了 wordpiece 模型的一个变体
- (相对) 在词汇表中的常用词
- at, fairfax, 1910s
- 其他单词由wordpieces组成
- hypatia = h ##yp ##ati ##a
- (相对) 在词汇表中的常用词
- 如果你在一个基于单词的模型中使用 BERT,你必须处理这个
3.4 字符级构建单词级
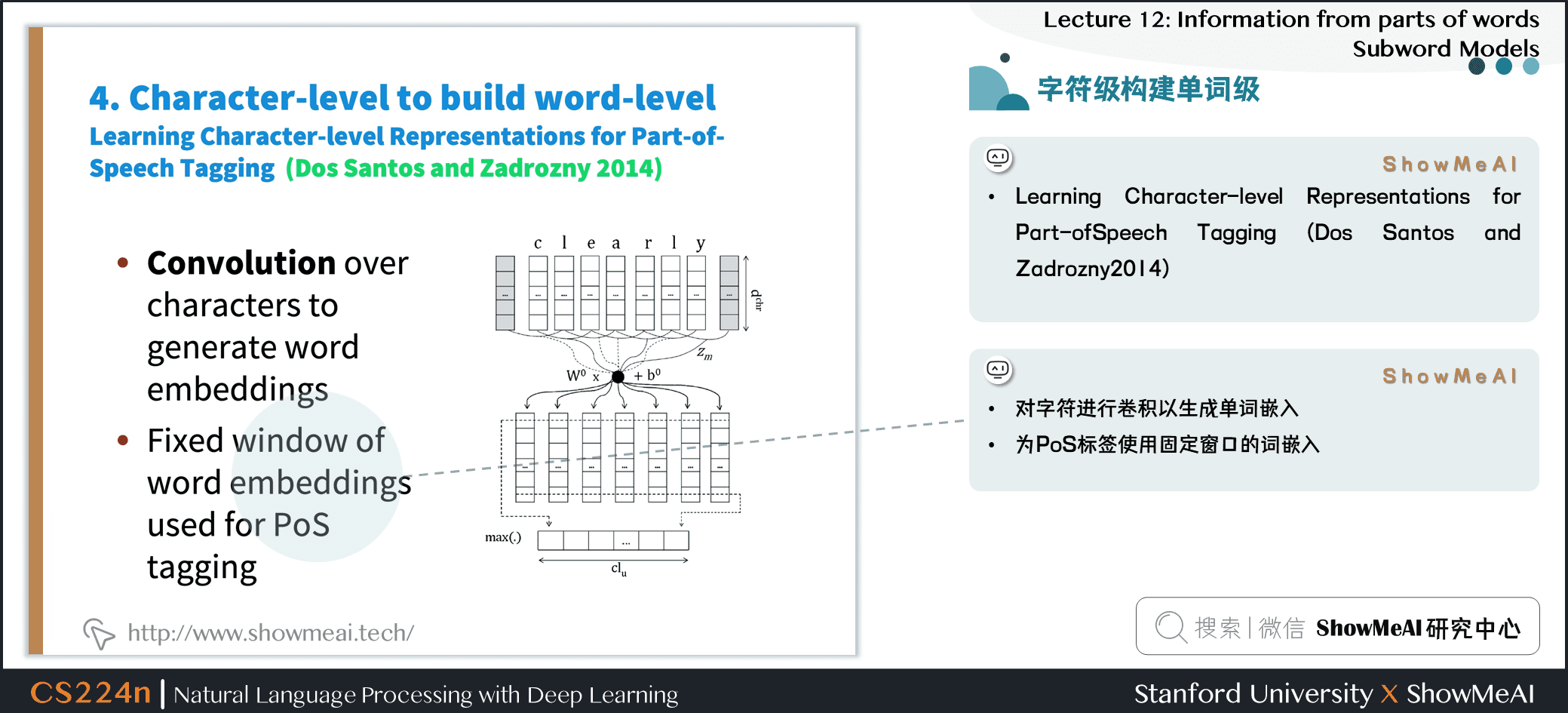
- Learning Character-level Representations for Part-ofSpeech Tagging (Dos Santos and Zadrozny 2014)
- 对字符进行卷积以生成单词嵌入
- 为 PoS 标签使用固定窗口的词嵌入
3.5 基于字符的LSTM构建单词表示

- Bi-LSTM构建单词表示
3.6 #论文解读# Character-Aware Neural Language Models

- 一个更复杂/精密的方法
- 动机
- 派生一个强大的、健壮的语言模型,该模型在多种语言中都有效
- 编码子单词关联性:eventful, eventfully, uneventful…
- 解决现有模型的罕见字问题
- 用更少的参数获得可比较的表达性
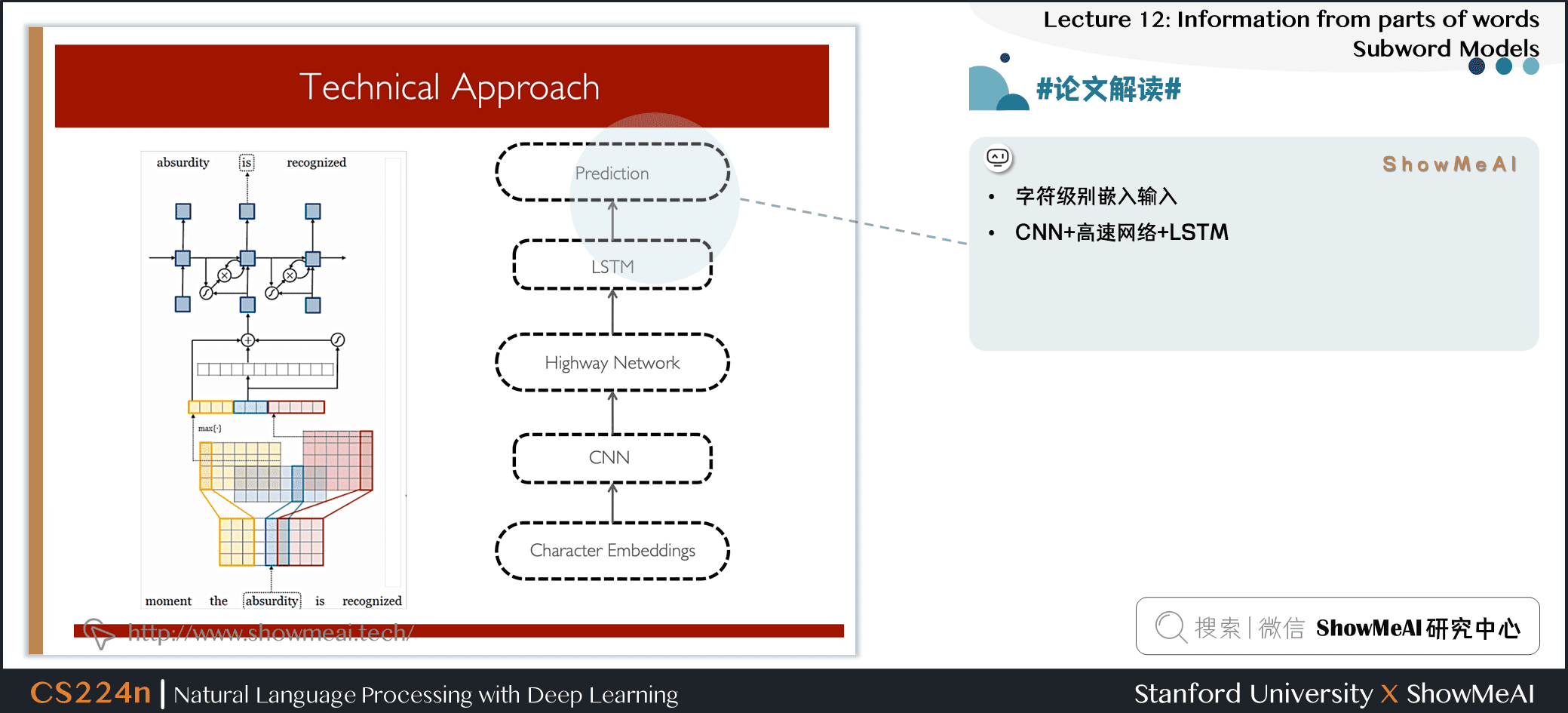
- 字符级别嵌入输入
- CNN+高速网络+LSTM
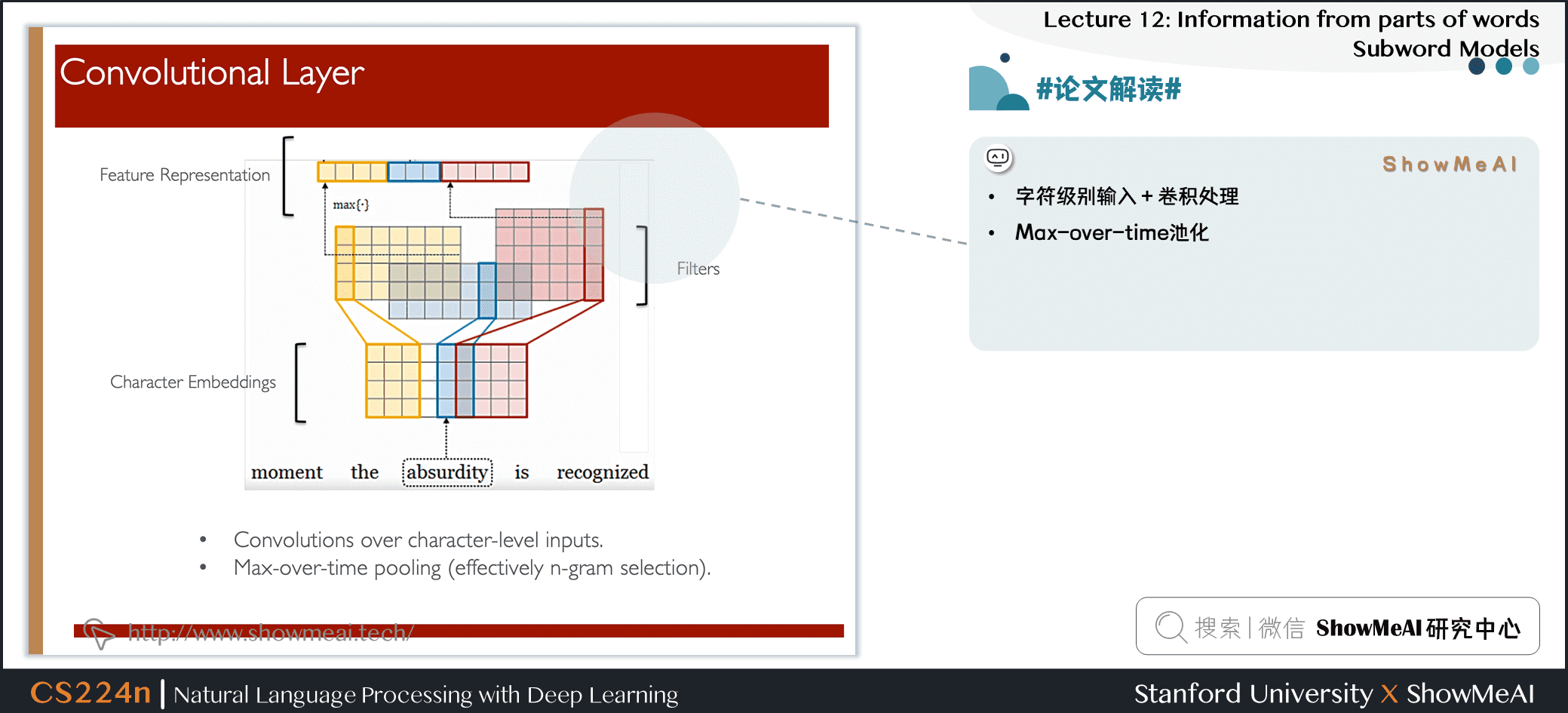
- 字符级别输入 + 卷积处理
- Max-over-time池化
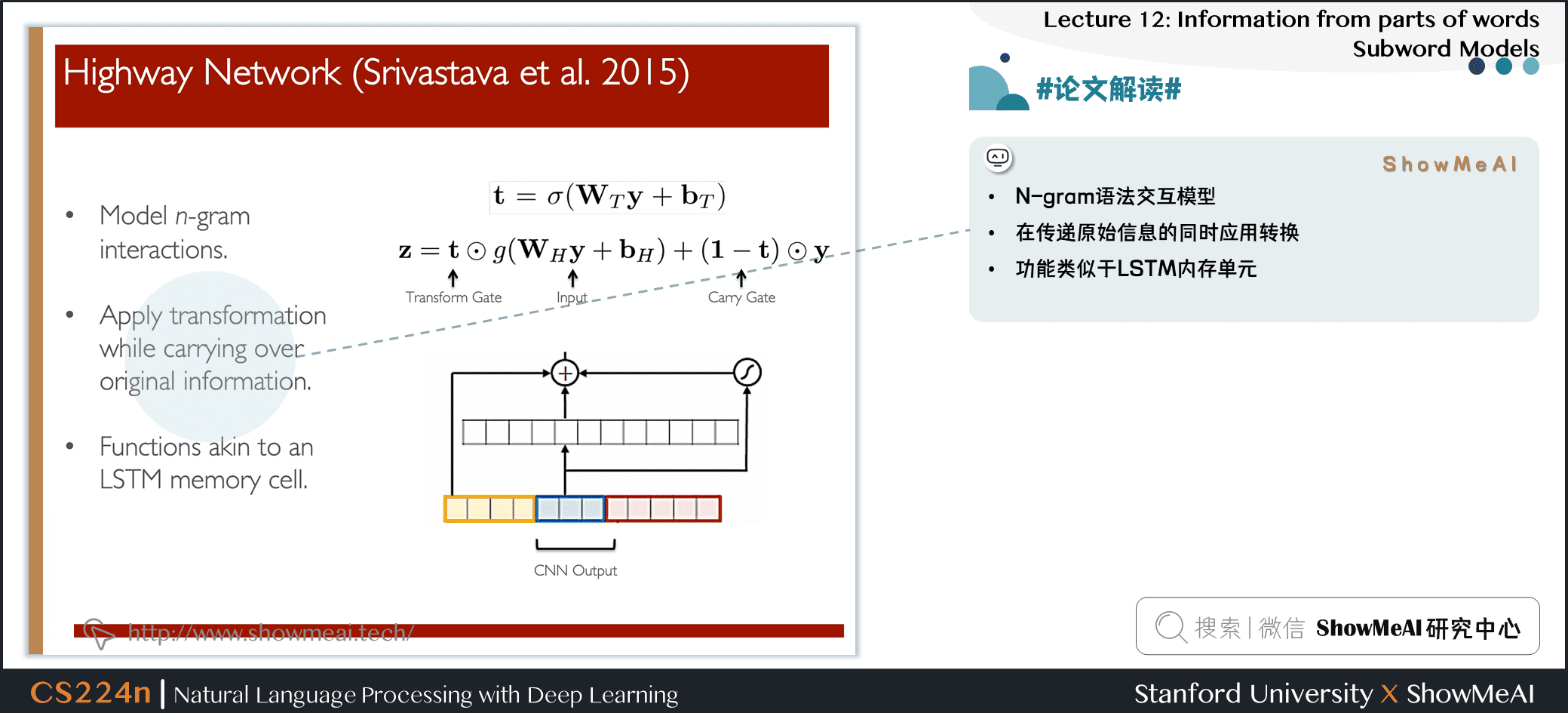
- N-gram 语法交互模型
- 在传递原始信息的同时应用转换
- 功能类似于 LSTM 内存单元
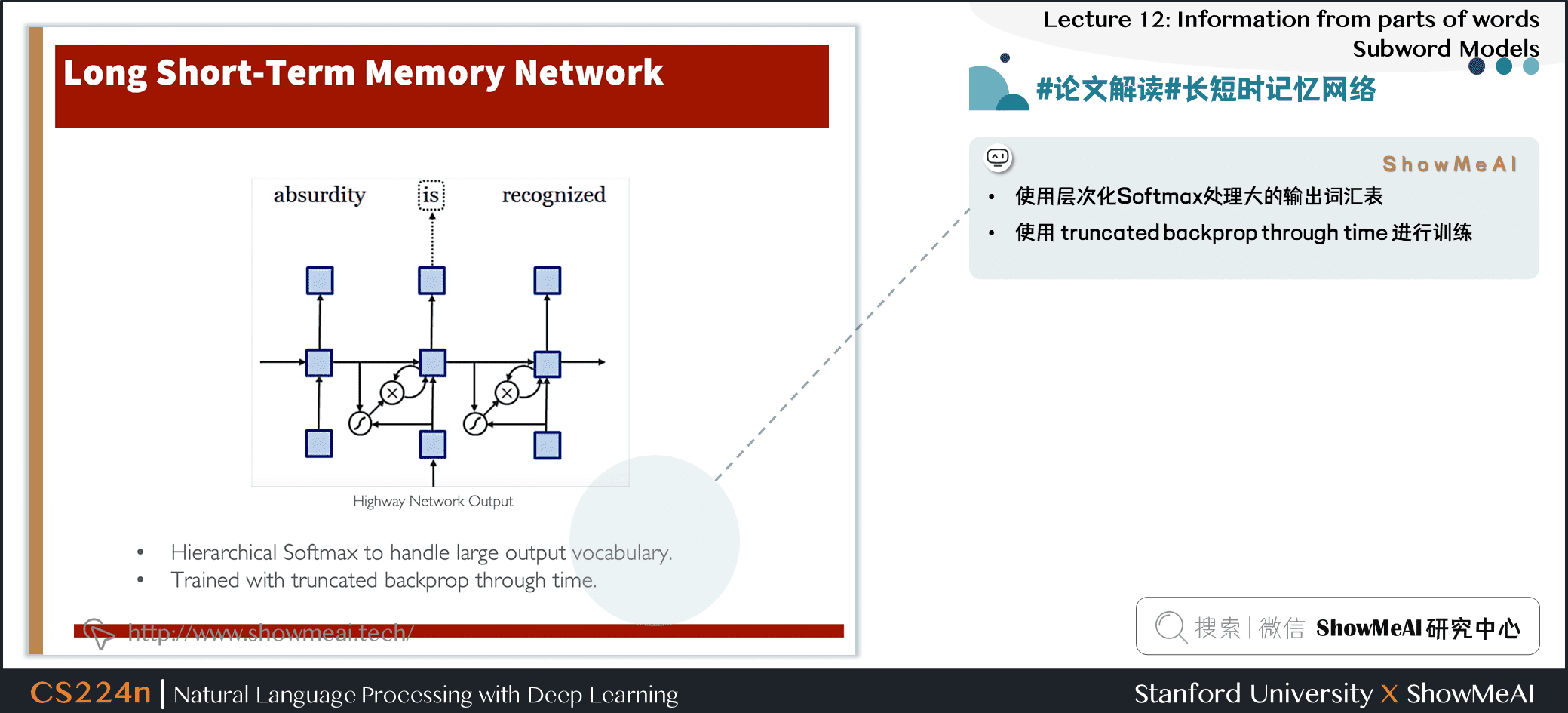
- 使用层次化 Softmax 处理大的输出词汇表
- 使用 truncated backprop through time 进行训练
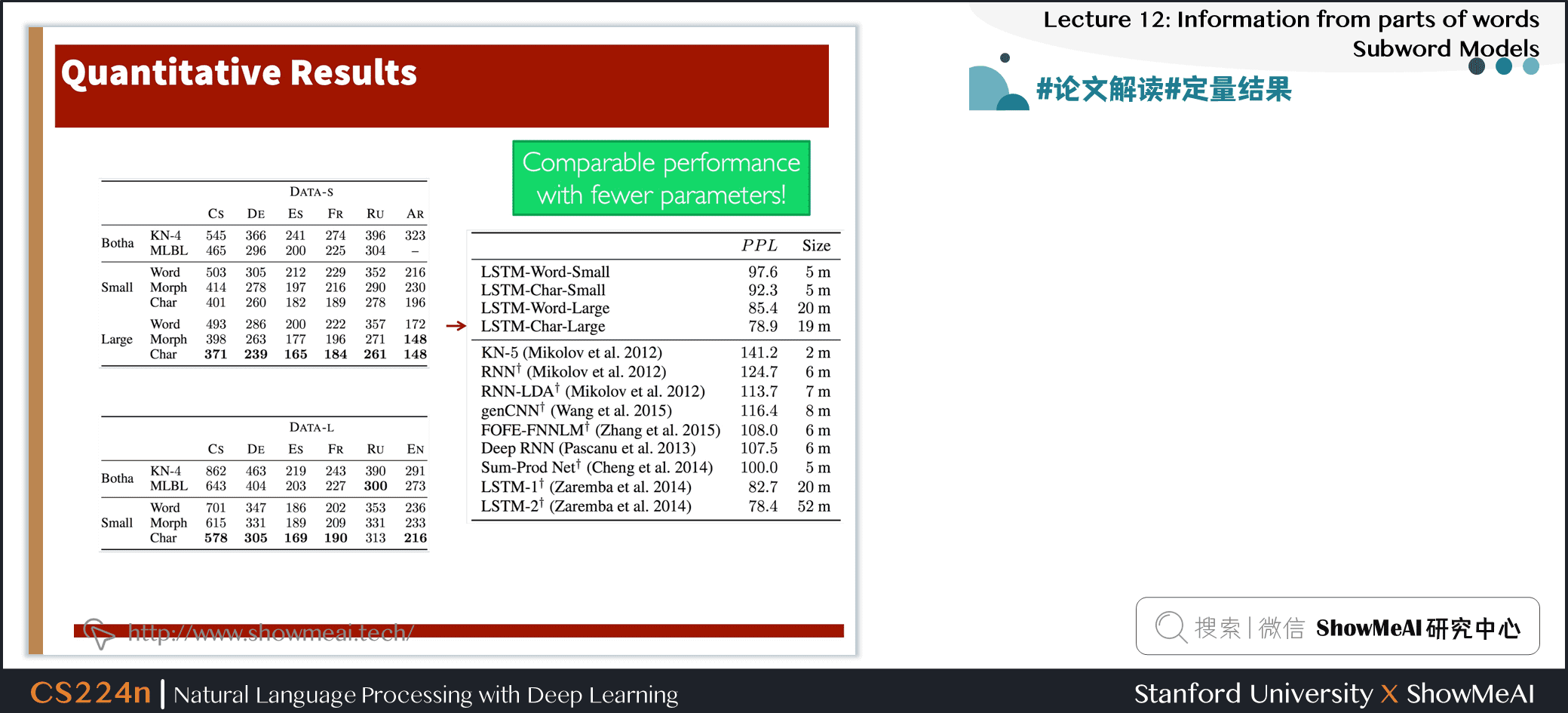
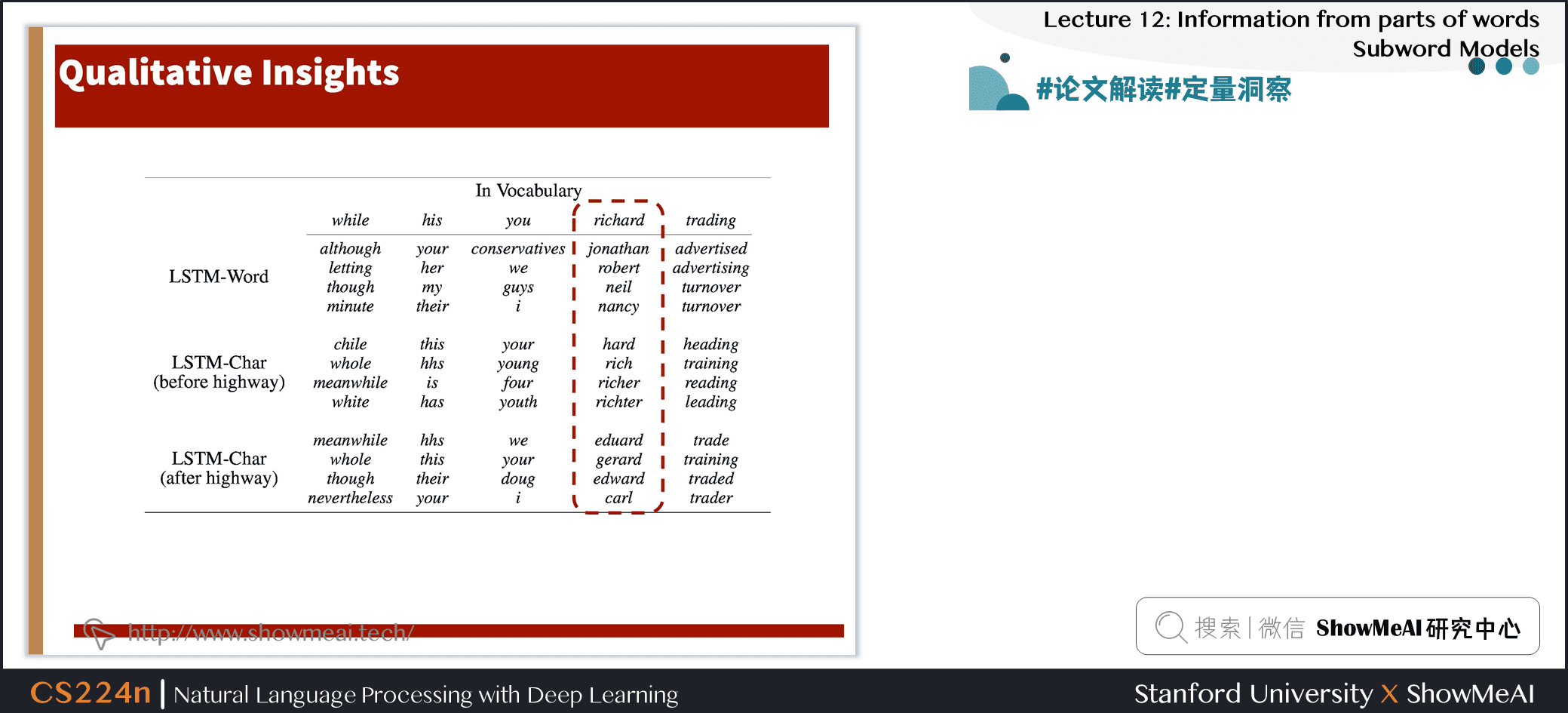
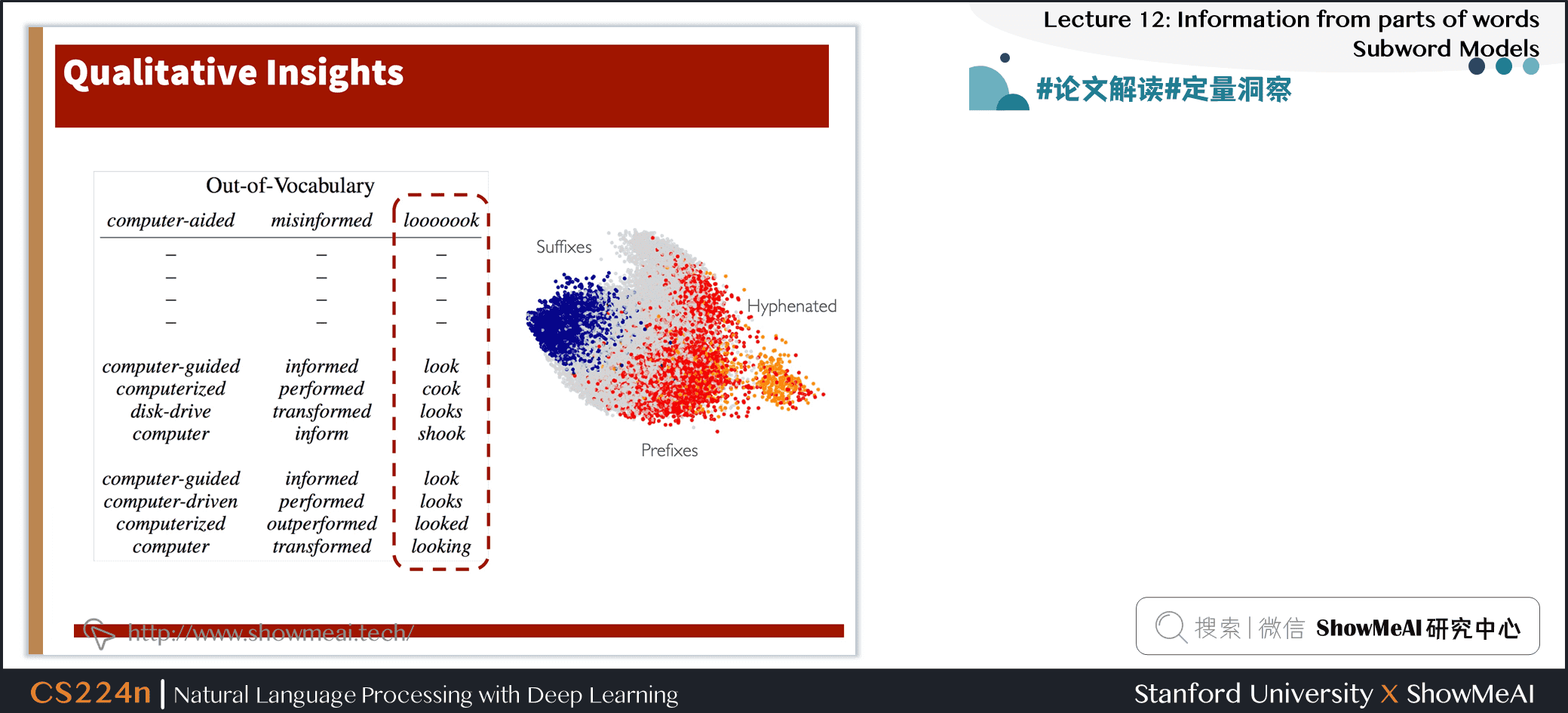

- 本文对使用词嵌入作为神经语言建模输入的必要性提出了质疑
- 字符级的 CNNs + Highway Network 可以提取丰富的语义和结构信息
- 关键思想:您可以构建
building blocks来获得细致入微且功能强大的模型!
4.混合字符与词粒度的模型
4.1 混合NMT

- 混合高效结构
- 翻译大部分是单词级别的
- 只在需要的时候进入字符级别
- 使用一个复制机制,试图填充罕见的单词,产生了超过 2个点的 BLEU 的改进
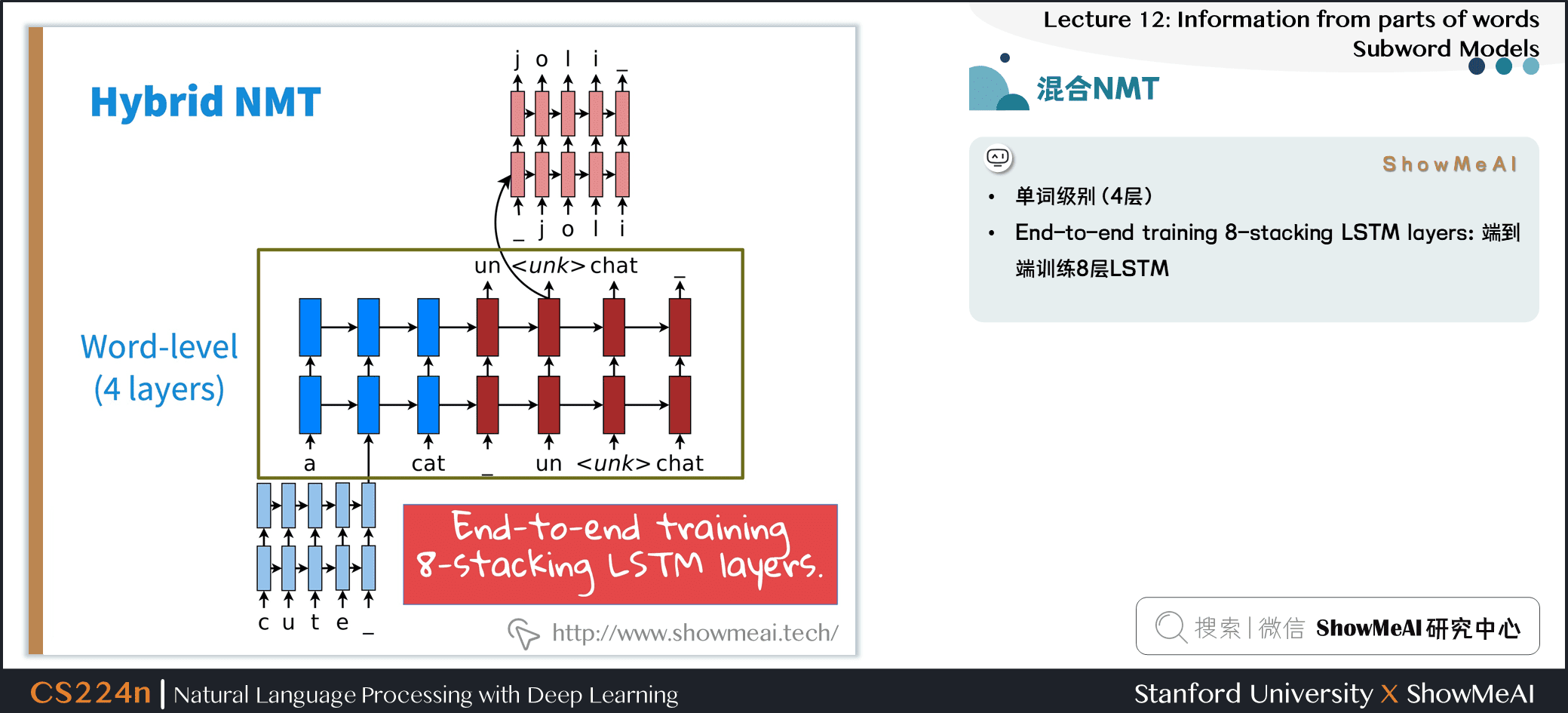
- 单词级别 (4层)
- End-to-end training 8-stacking LSTM layers:端到端训练 8 层 LSTM
4.2 二级解码
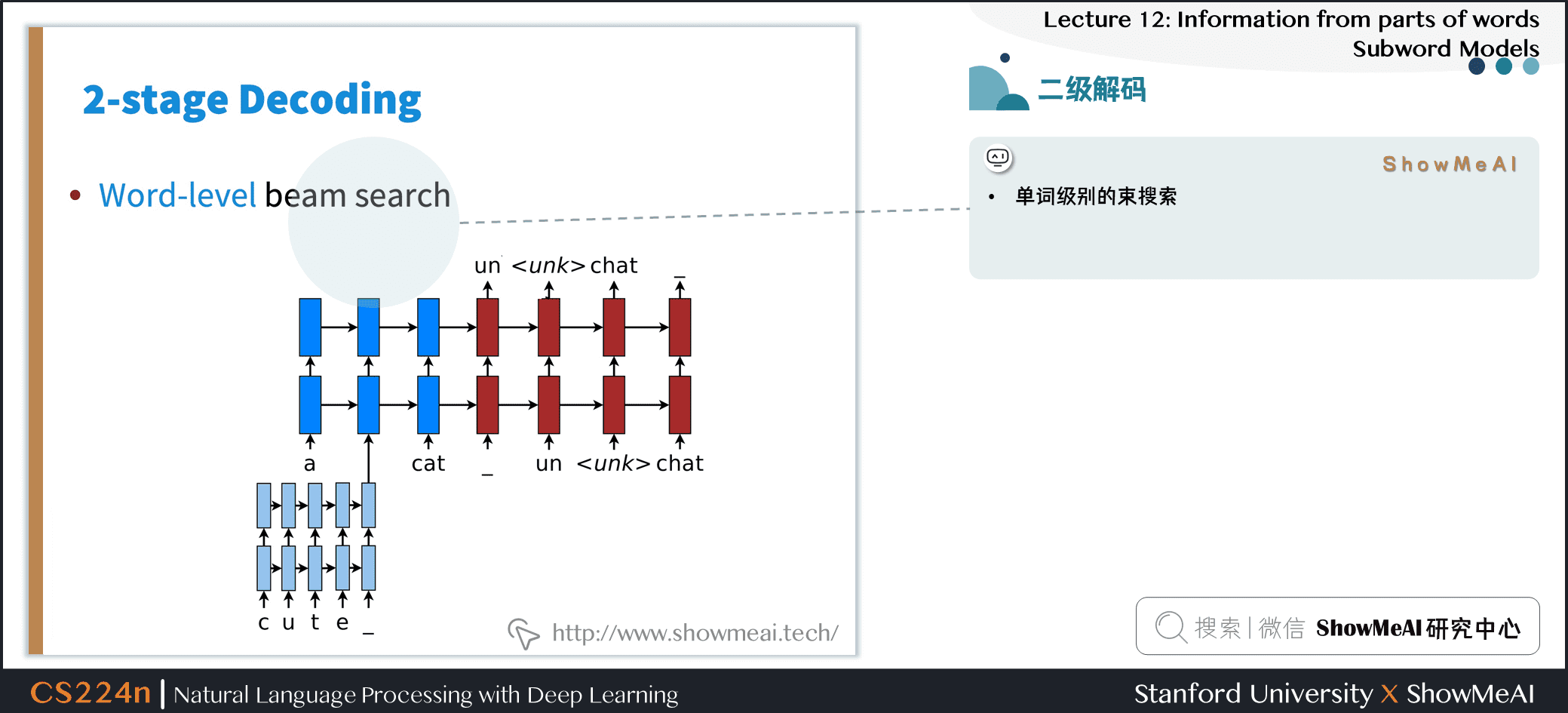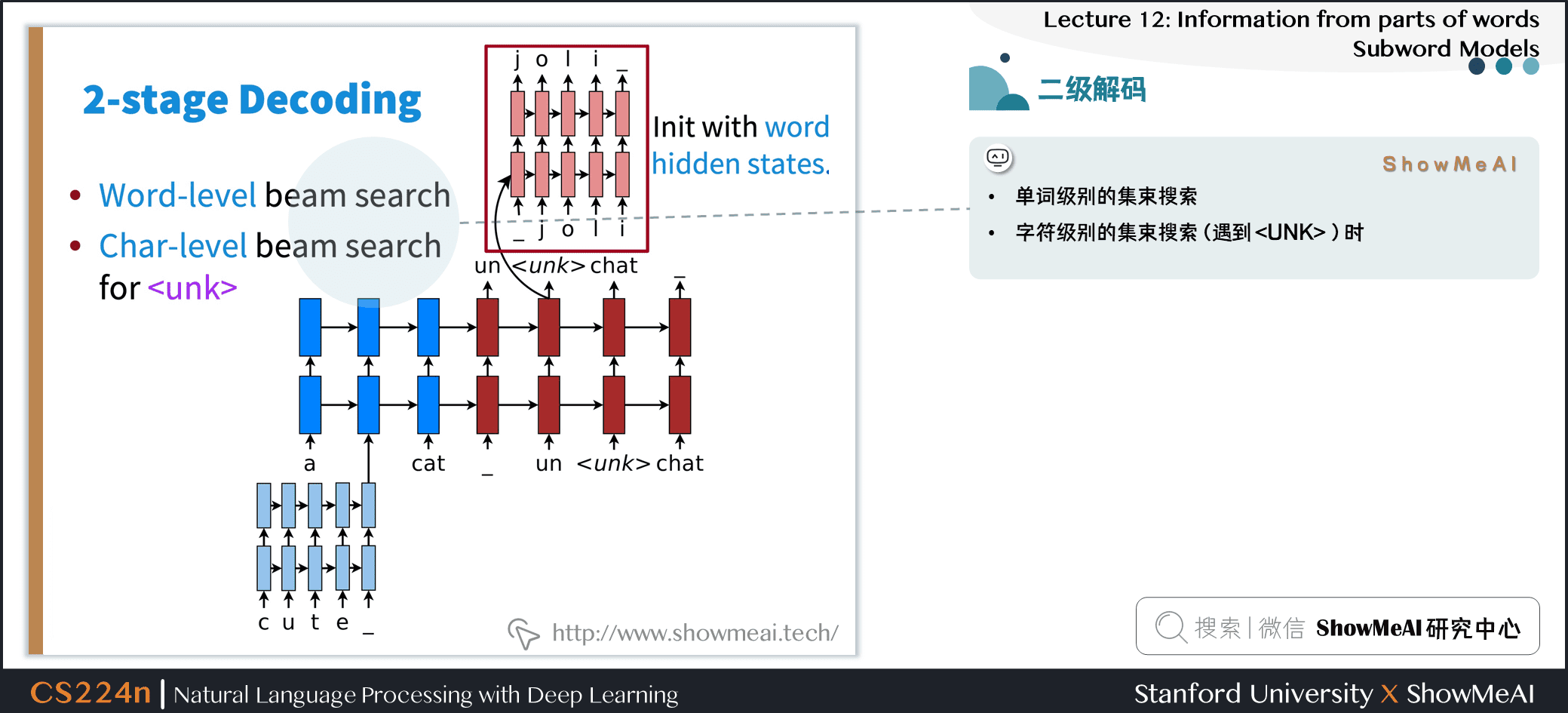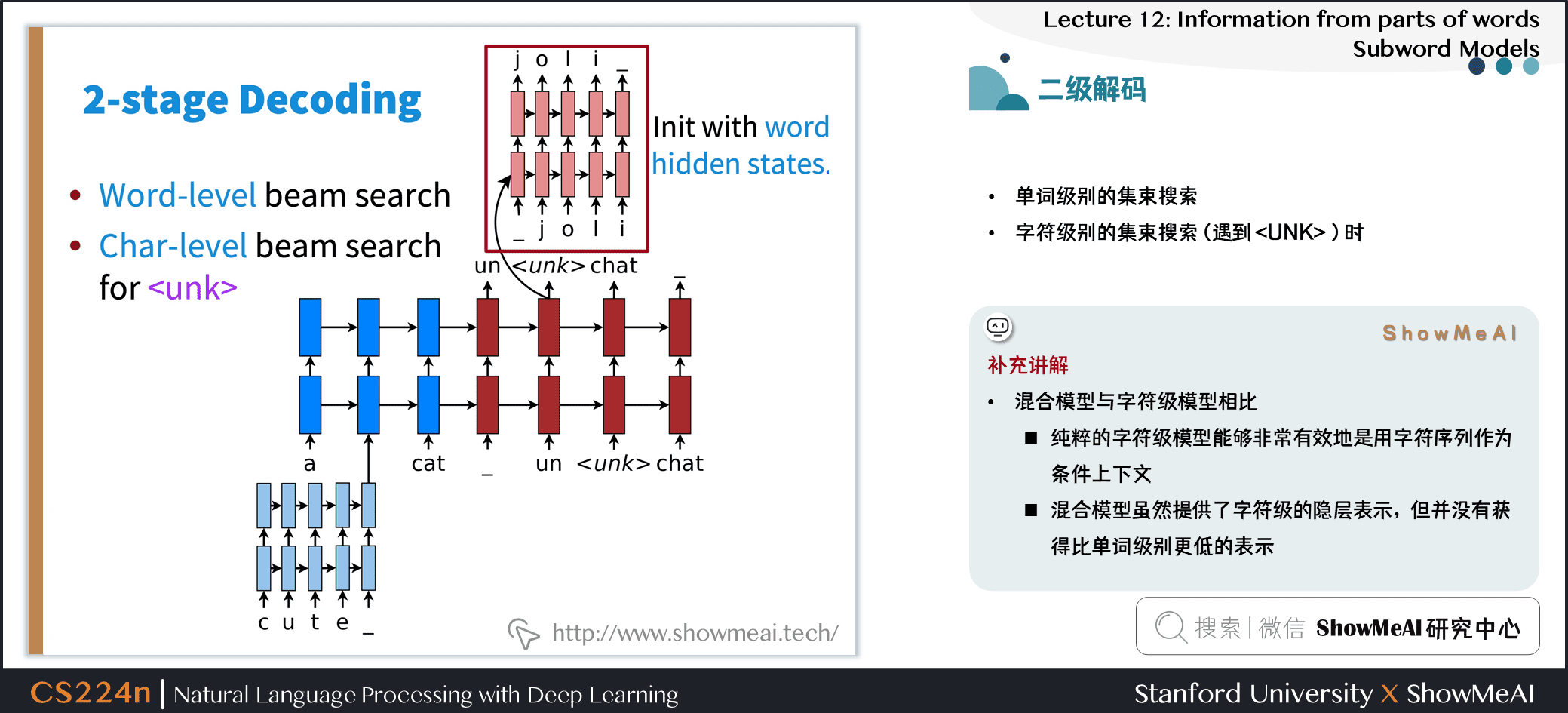
- 单词级别的集束搜索
- 字符级别的集束搜索 (遇到
) 时
补充讲解
- 混合模型与字符级模型相比
- 纯粹的字符级模型能够非常有效地使用字符序列作为条件上下文
- 混合模型虽然提供了字符级的隐层表示,但并没有获得比单词级别更低的表示
4.3 English - Czech Results

- 使用WMT’15数据进行训练 (12M句子对)
- 新闻测试2015
- 30倍数据
- 3个系统
- 大型词汇+复制机制
- 达到先进的效果!
4.4 Sample English-czech translations
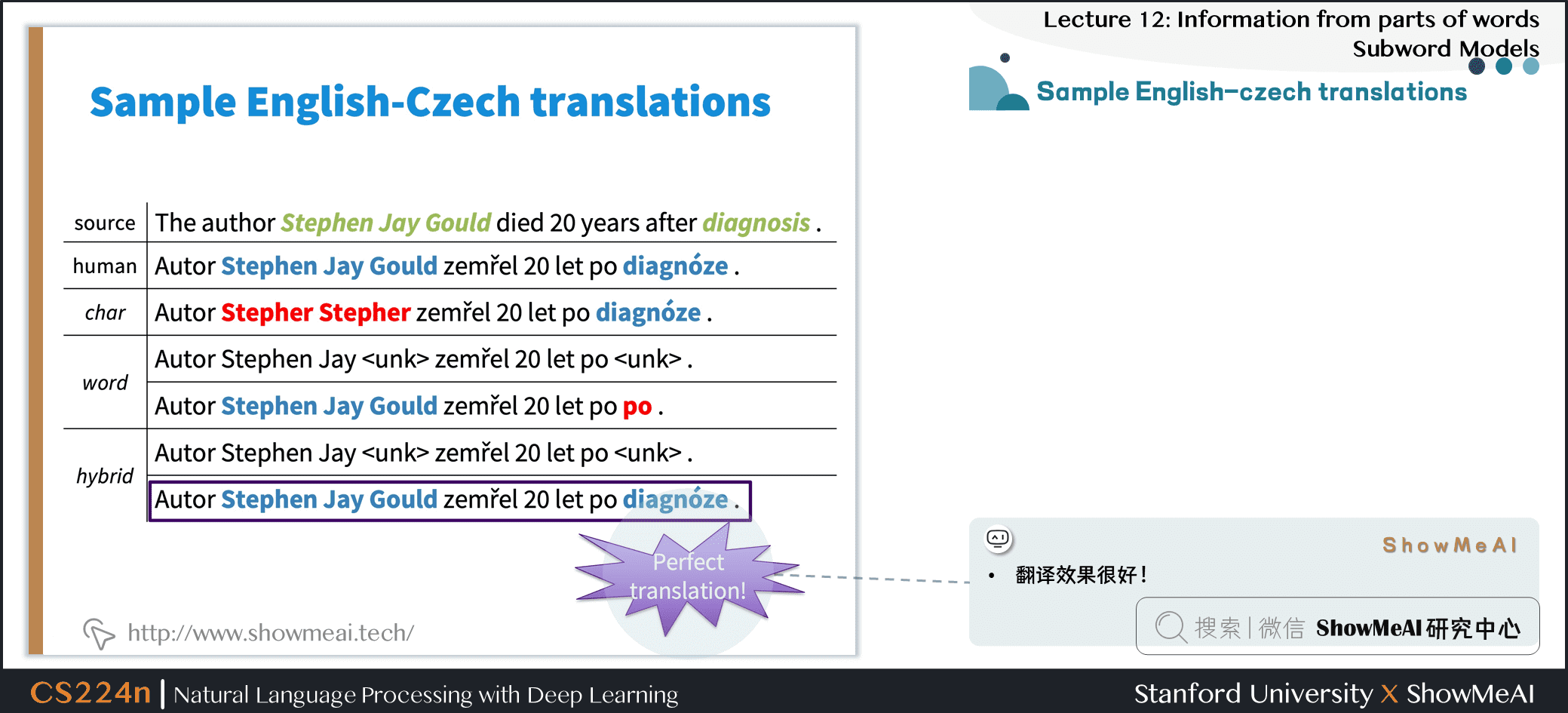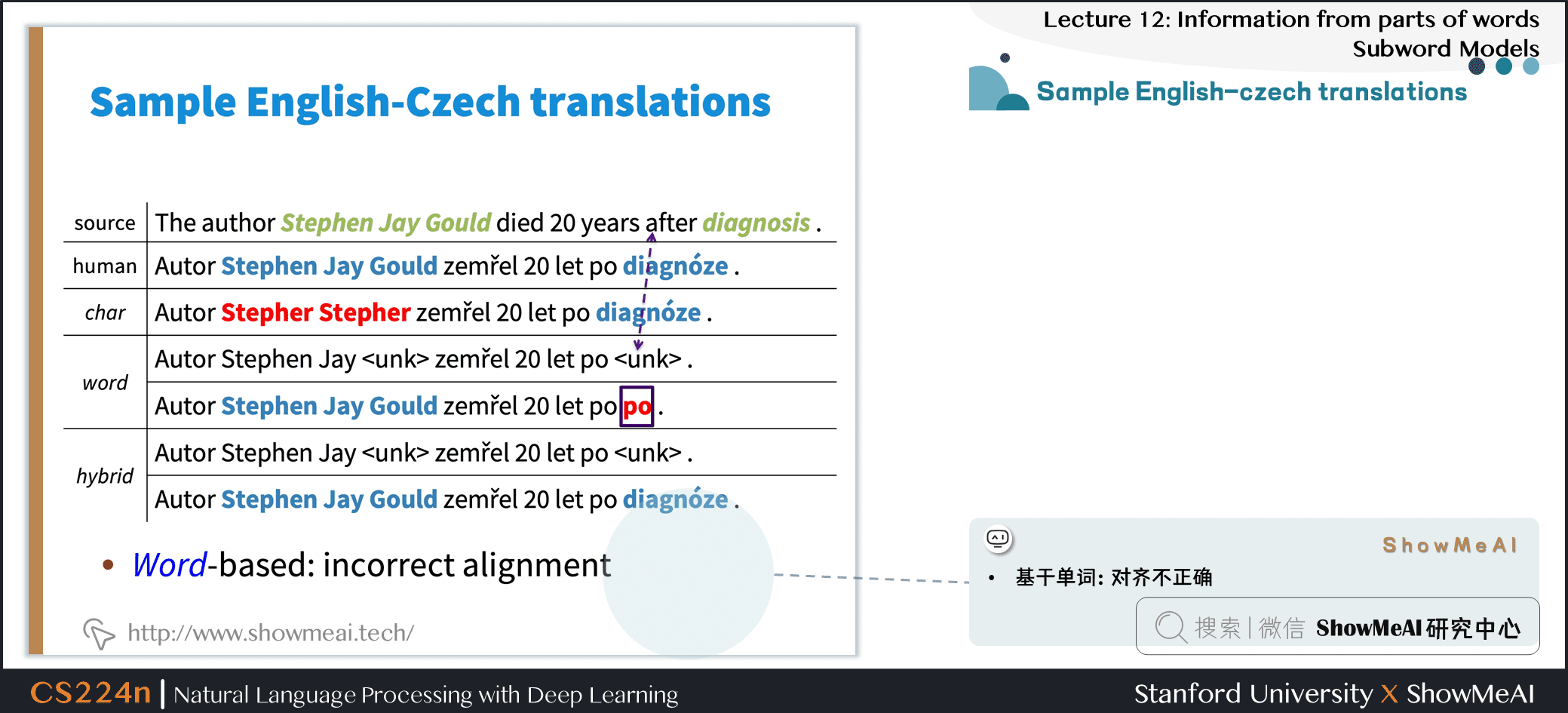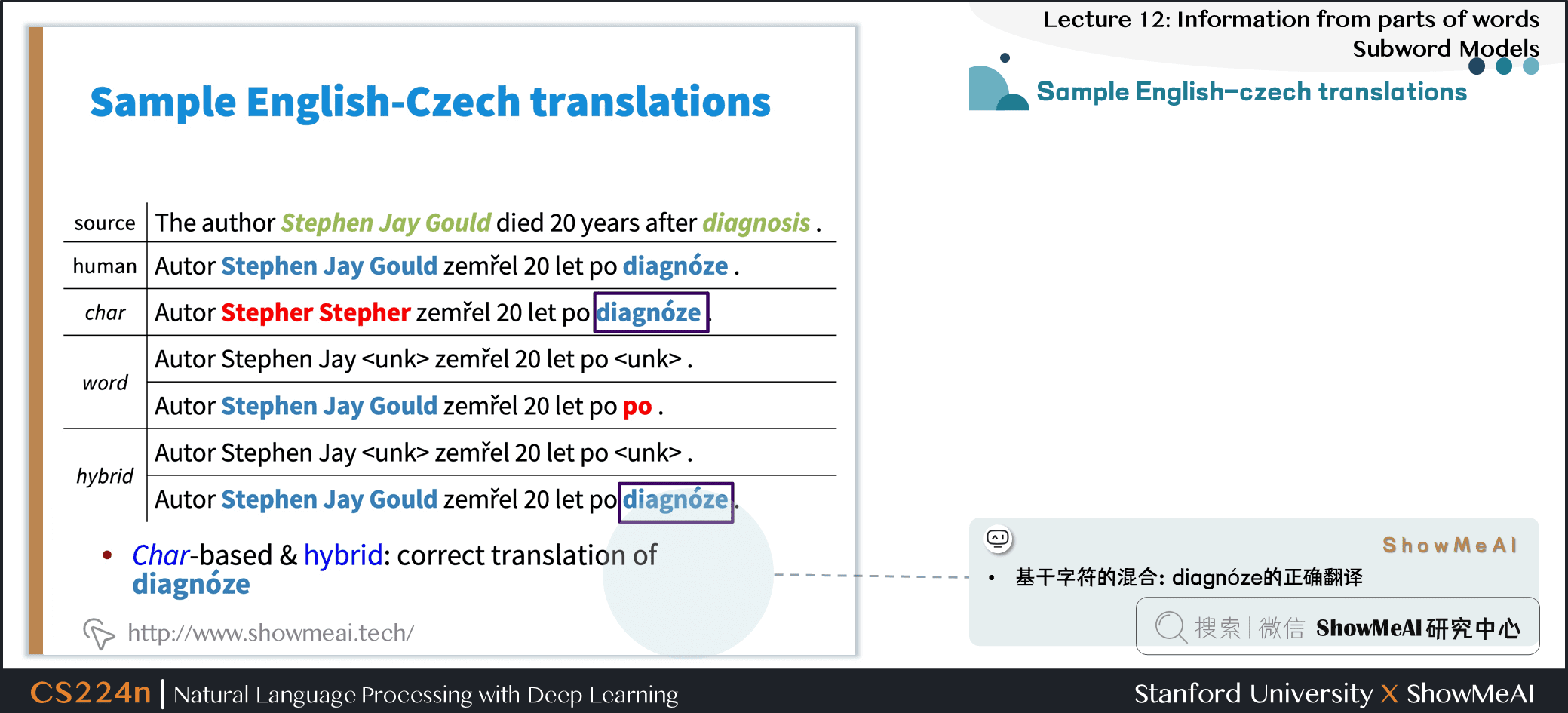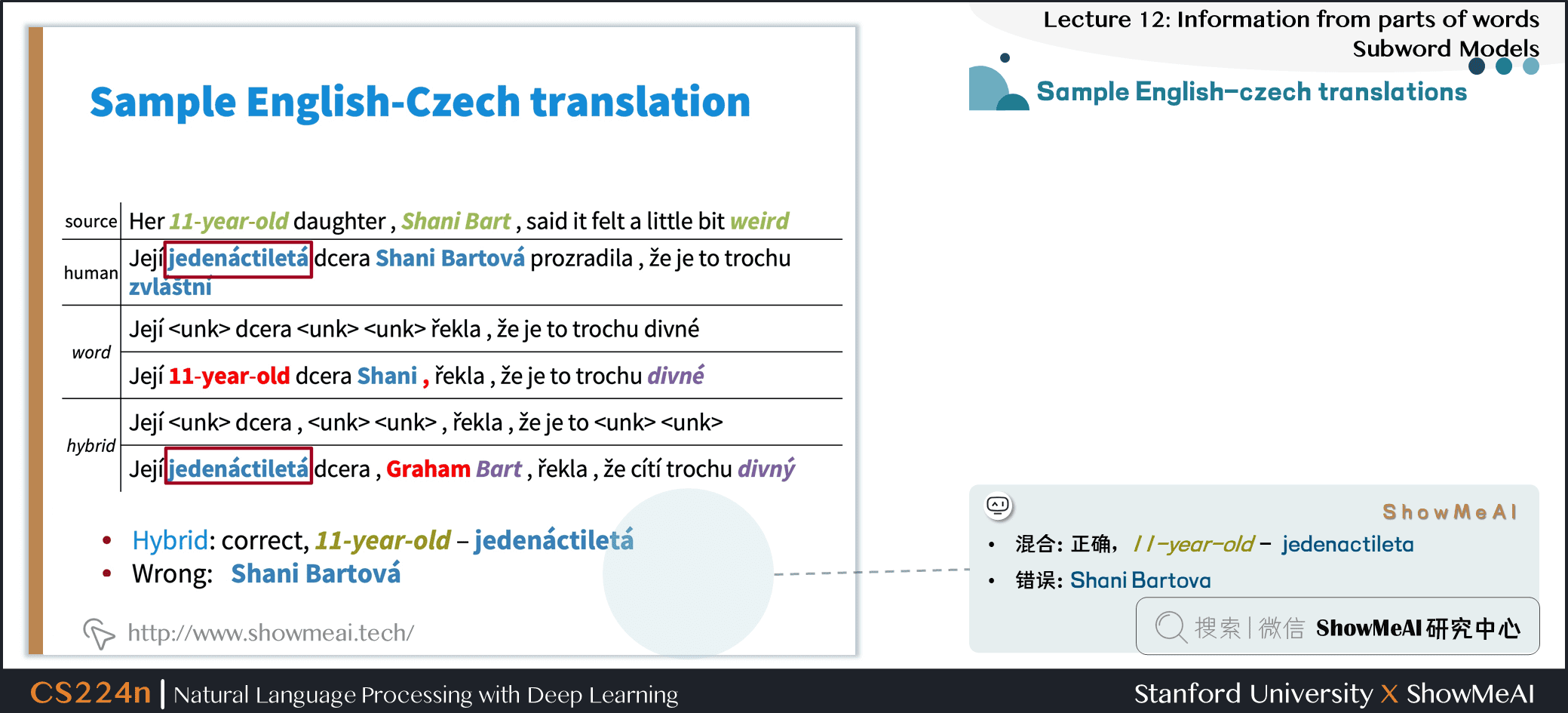
- 翻译效果很好!
- 基于字符:错误的名称翻译
- 基于单词:对齐不正确
- 基于字符的混合:diagnóze的正确翻译
- 基于单词:特征复制失败
- 混合:正确,11-year-old-jedenactileta
- 错误:Shani Bartova
4.5 单词嵌入中的字符应用
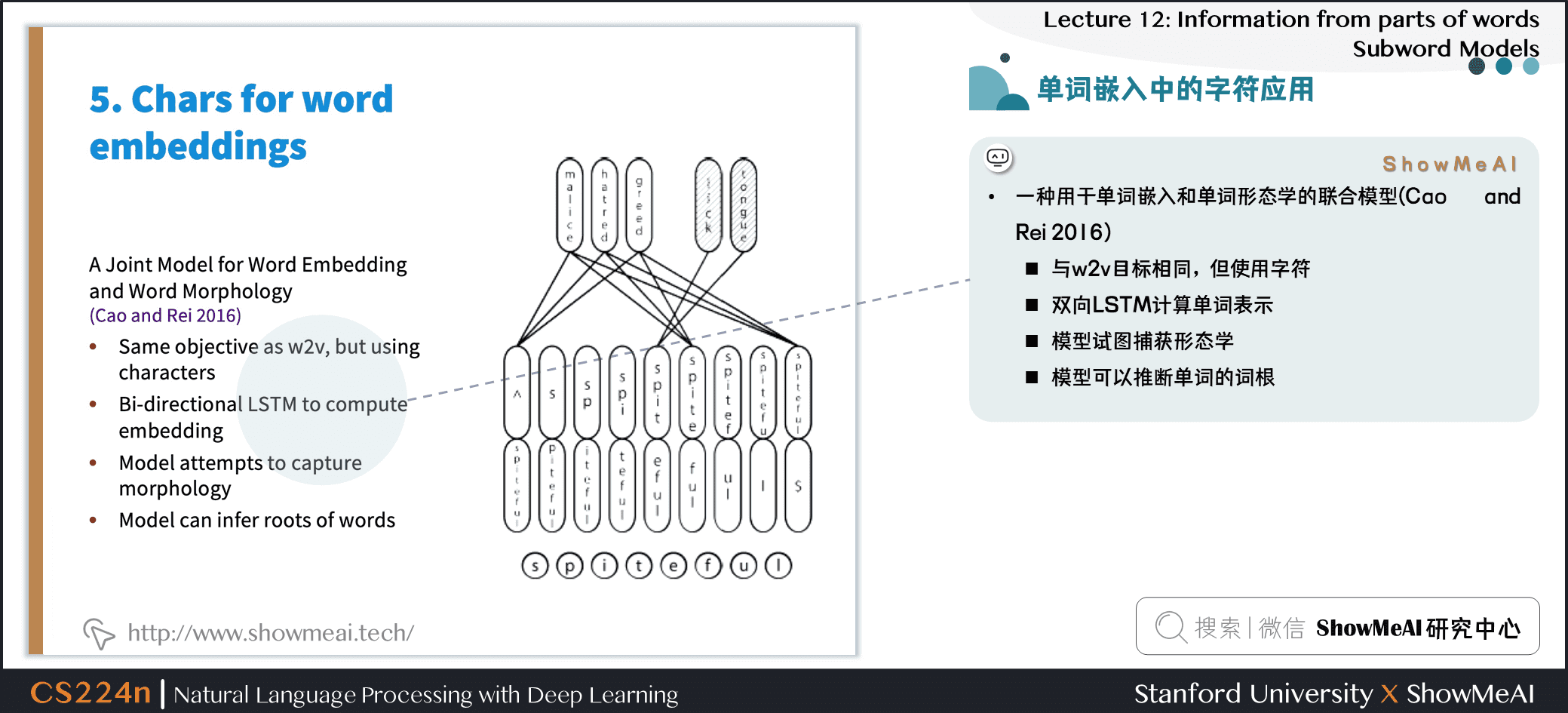
- 一种用于单词嵌入和单词形态学的联合模型(Cao and Rei 2016)
- 与 w2v 目标相同,但使用字符
- 双向 LSTM 计算单词表示
- 模型试图捕获形态学
- 模型可以推断单词的词根
5.fastText模型

- 用子单词信息丰富单词向量
Bojanowski, Grave, Joulinand Mikolov. FAIR. 2016.
- 目标:下一代高效的类似于 word2vecd 的单词表示库,但更适合于具有大量形态学的罕见单词和语言
- 带有字符 n-grams 的 w2v 的 skip-gram 模型的扩展

- 将单词表示为用边界符号和整词扩充的字符 n-grams
\[where =,where =<wh,whe,her,ere,re>,<where>
\]
- 注意 \(<her>\)、\(<her\)是不同于 \(her\)的
- 前缀、后缀和整个单词都是特殊的
- 将 word 表示为这些表示的和。上下文单词得分为
\[S(w, c)=\sum g \in G(w) \mathbf{Z}_{g}^{\mathrm{T}} \mathbf{V}_{C}
\]
- 细节:与其共享所有 n-grams 的表示,不如使用
hashing trick来拥有固定数量的向量
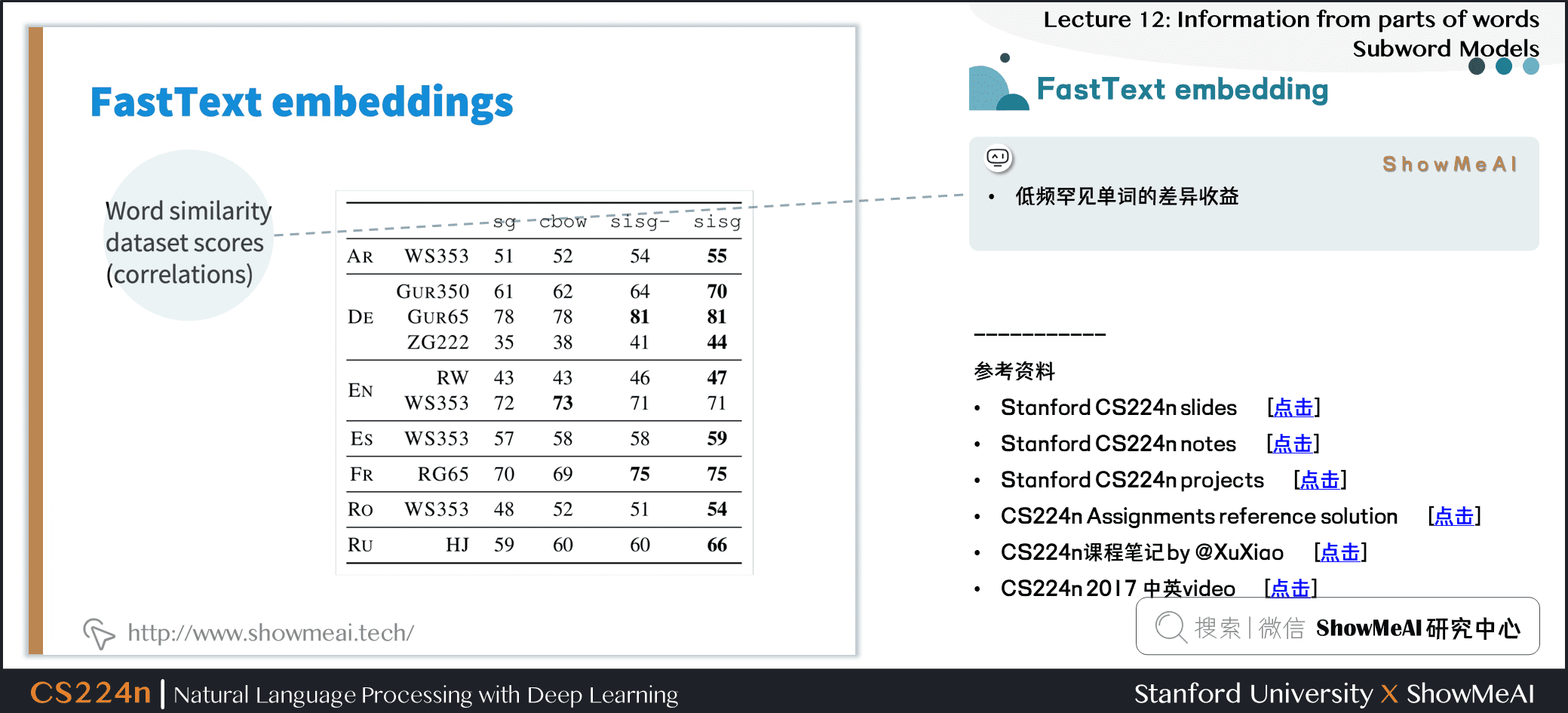
- 低频罕见单词的差异收益

Suggested Readings
6.视频教程
可以点击 B站 查看视频的【双语字幕】版本
7.参考资料
- 本讲带学的在线阅翻页本
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
- Stanford官网 | CS224n: Natural Language Processing with Deep Learning
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
NLP系列教程文章
- NLP教程(1)- 词向量、SVD分解与Word2vec
- NLP教程(2)- GloVe及词向量的训练与评估
- NLP教程(3)- 神经网络与反向传播
- NLP教程(4)- 句法分析与依存解析
- NLP教程(5)- 语言模型、RNN、GRU与LSTM
- NLP教程(6)- 神经机器翻译、seq2seq与注意力机制
- NLP教程(7)- 问答系统
- NLP教程(8)- NLP中的卷积神经网络
- NLP教程(9)- 句法分析与树形递归神经网络
斯坦福 CS224n 课程带学详解
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
- 斯坦福NLP课程 | 第3讲 - 神经网络知识回顾
- 斯坦福NLP课程 | 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP课程 | 第5讲 - 句法分析与依存解析
- 斯坦福NLP课程 | 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP课程 | 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP课程 | 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP课程 | 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP课程 | 第10讲 - NLP中的问答系统
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP课程 | 第12讲 - 子词模型
- 斯坦福NLP课程 | 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP课程 | 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
- 斯坦福NLP课程 | 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP课程 | 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP课程 | 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP课程 | 第19讲 - AI安全偏见与公平
- 斯坦福NLP课程 | 第20讲 - NLP与深度学习的未来


