
斯坦福NLP课程 | 第2讲 - 词向量进阶
 NLP课程第2讲内容覆盖ord2vec与词向量、算法优化基础、计数与共现矩阵、GloVe模型、词向量评估、word senses等。
NLP课程第2讲内容覆盖ord2vec与词向量、算法优化基础、计数与共现矩阵、GloVe模型、词向量评估、word senses等。

- 作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/36
- 本文地址:https://www.showmeai.tech/article-detail/233
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

ShowMeAI为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》课程的全部课件,做了中文翻译和注释,并制作成了GIF动图!

本讲内容的深度总结教程可以在这里 查看。视频和课件等资料的获取方式见文末。
引言
CS224n是顶级院校斯坦福出品的深度学习与自然语言处理方向专业课程。核心内容覆盖RNN、LSTM、CNN、transformer、bert、问答、摘要、文本生成、语言模型、阅读理解等前沿内容。
本篇是ShowMeAI对第2课的内容梳理,内容覆盖词嵌入/词向量,word vectors和word senses。

本篇内容覆盖
- word2vec与词向量回顾
- 算法优化基础
- 计数与共现矩阵
- GloVe模型
- 词向量评估
- word senses

1.word2vec与词向量回顾
1.1 复习:word2vec的主要思想
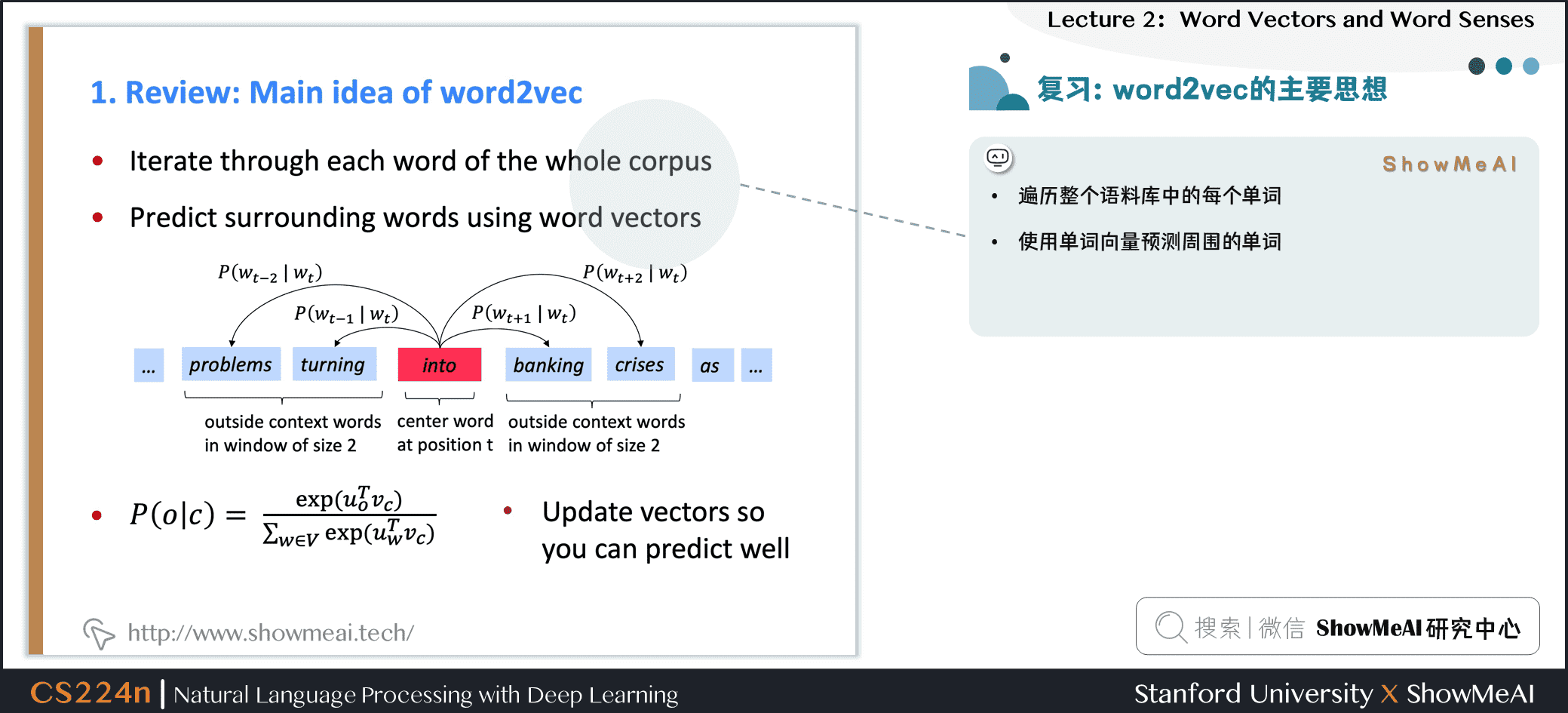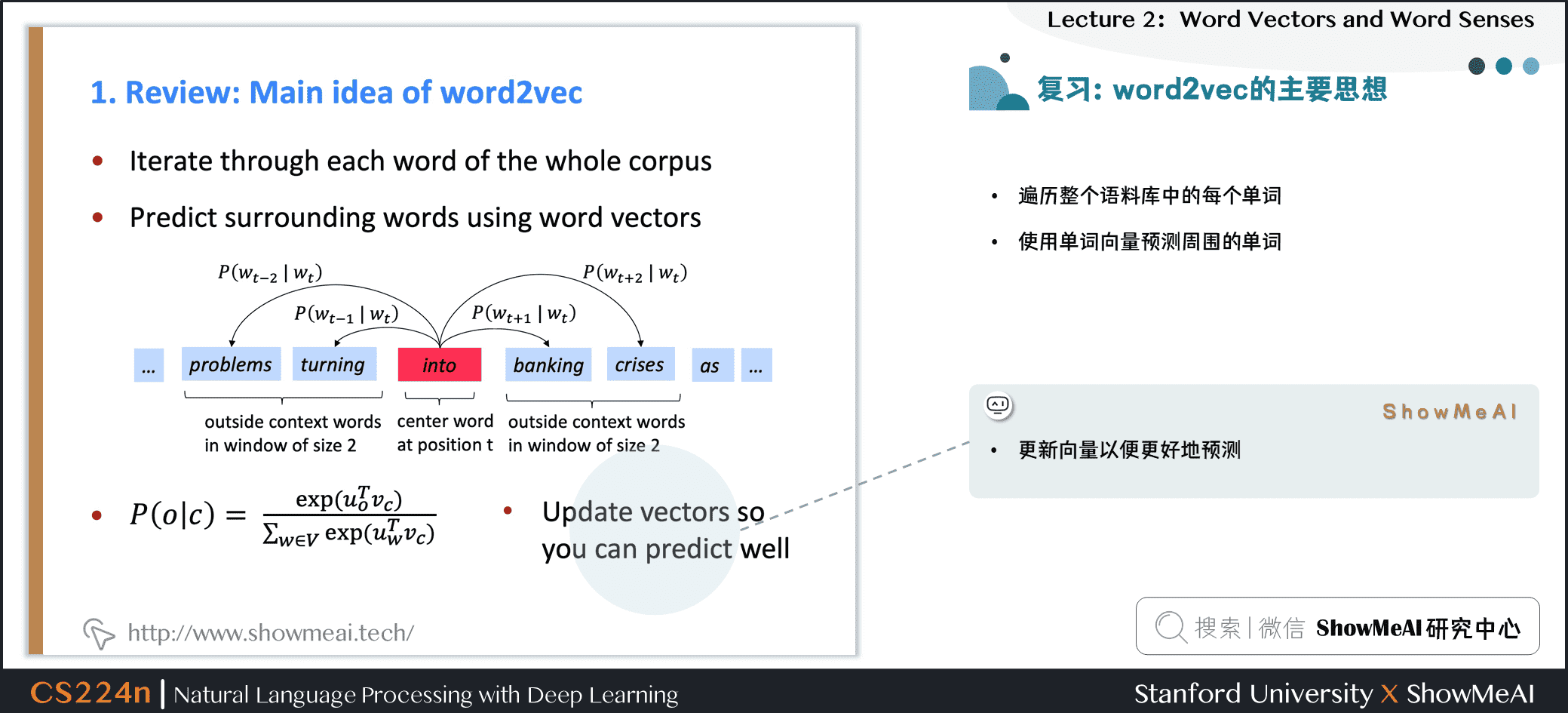
我们来回顾一下ShowMeAI上一篇 1.NLP介绍与词向量初步 提到的word2vec模型核心知识
- 模型会遍历整个语料库中的每个单词
- 使用中心单词向量预测周围的单词(Skip-Gram)
- 更新向量(参数)以便更好地预测上下文
1.2 Word2vec参数和计算
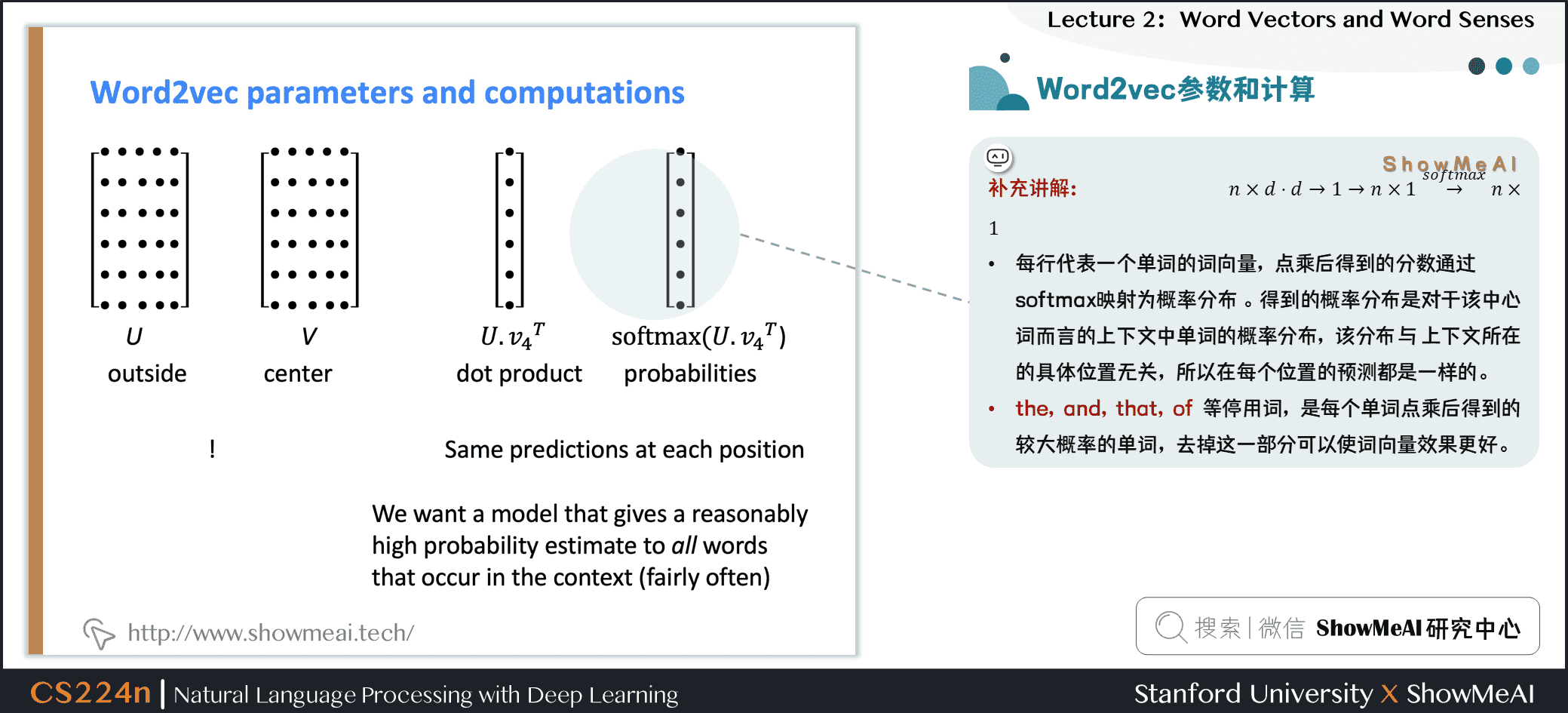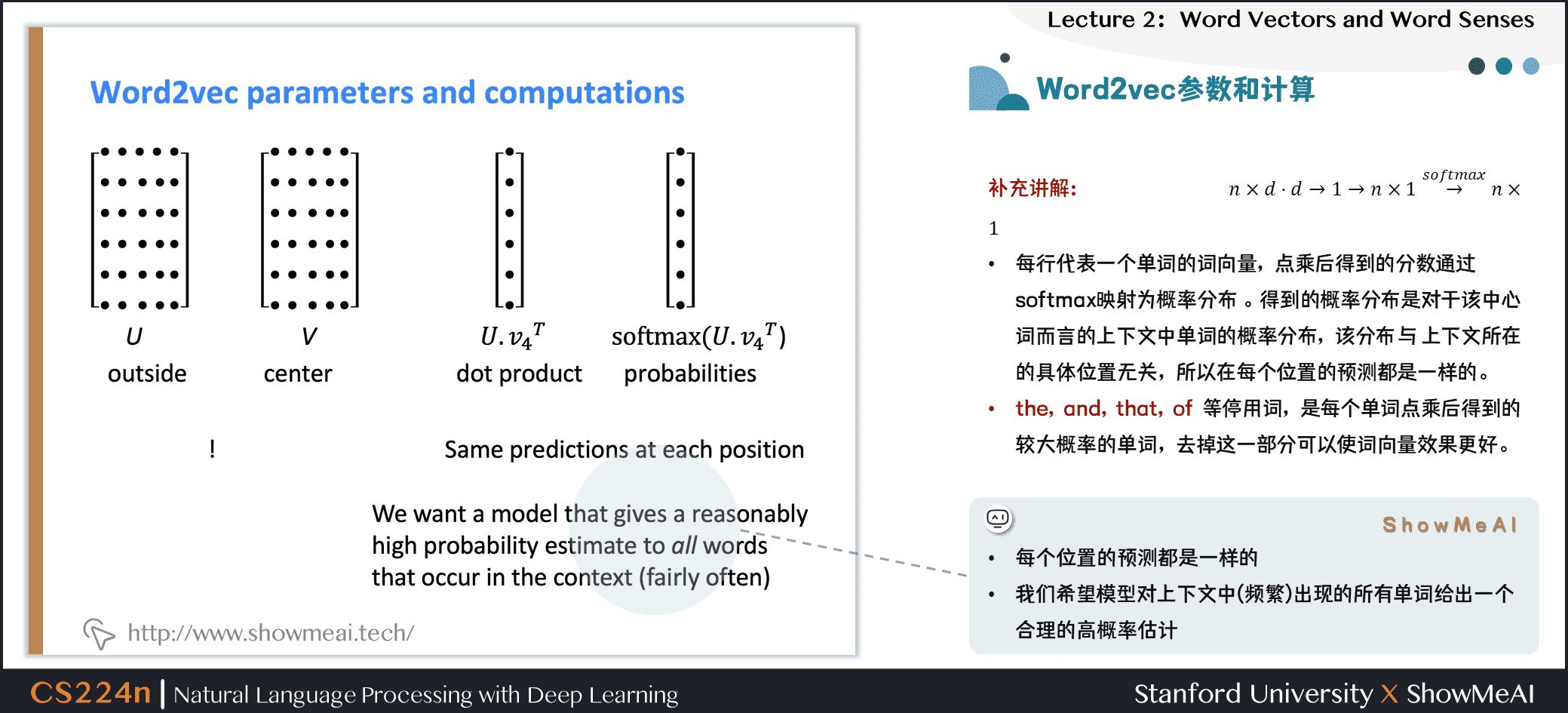
我们对word2vec的参数和训练细节等做一个补充讲解:
- \(U\) 、 \(V\) 矩阵,每行代表一个单词的词向量,点乘后得到的分数通过softmax映射为概率分布。得到的概率分布是对于该中心词而言的上下文中单词的概率分布,该分布与上下文所在的具体位置无关,所以在每个位置的预测都是一样的。
- the、and、that、of等停用词,是每个单词点乘后得到的较大概率的单词,去掉这一部分可以使词向量效果更好。
1.3 word2vec训练得到的词向量分布体现语义相似度
经过word2vec最大化目标函数后,通过可视化可以发现,相似的词汇在词向量空间里是比较接近的。

1.4 优化算法:梯度下降
ShowMeAI在上一篇 1.NLP介绍与词向量初步 讲解了需要最小化的代价函数 \(J(\theta)\) ,我们使用梯度下降算法最小化 \(J(\theta)\)

遵循梯度下降的一般思路,我们计算 \(J(\theta)\) 对于参数 \(\theta\) 的梯度,然后朝着负梯度的方向迈进一小步,并不断重复这个过程,如图所示。
注意:我们实际的目标函数可能不是下图这样的凸函数
2.算法优化基础
2.1 梯度下降算法

- 更新参数的公式(矩阵化写法)
-
\(\alpha\) :步长,也叫学习率
-
更新参数的公式(单个参数更新)
2.2 词向量随机梯度下降法
梯度下降会一次性使用所有数据样本进行参数更新,对应到我们当前的词向量建模问题,就是 \(J(\theta)\) 的计算需要基于语料库所有的样本(窗口),数据规模非常大
- 计算非常耗资源
- 计算时间太长

处理方式是把优化算法调整为「随机梯度下降算法」,即在单个样本里计算和更新参数,并遍历所有样本。
但基于单个样本更新会表现为参数震荡很厉害,收敛过程并不平稳,所以很多时候我们会改为使用mini-batch gradient descent(具体可以参考ShowMeAI的深度学习教程中文章神经网络优化算法)
- Mini-batch具有以下优点:通过batch平均,减少梯度估计的噪音;在GPU上并行化运算,加快运算速度。
2.3 词向量建模中的随机梯度下降
-
应用随机梯度下降,在每个窗口计算和更新参数,遍历所有样本
-
在每个窗口内,我们最多只有 \(2m+1\) 个词,因此 \(\nabla_{\theta} J_t(\theta)\) 是非常稀疏的

上面提到的稀疏性问题,一种解决方式是我们只更新实际出现的向量
-
需要稀疏矩阵更新操作来只更新矩阵 \(U\) 和 \(V\) 中的特定行
-
需要保留单词向量的哈希/散列
如果有数百万个单词向量,并且进行分布式计算,我们无需再传输巨大的更新信息(数据传输有成本)

2.4 Word2vec的更多细节

word2vec有两个模型变体:
- 1.Skip-grams (SG):输入中心词并预测上下文中的单词
- 2.Continuous Bag of Words (CBOW):输入上下文中的单词并预测中心词
之前一直使用naive的softmax(简单但代价很高的训练方法),其实可以使用负采样方法加快训练速率
2.5 负例采样的skip-gram模型(作业2)
这个部分大家也可以参考ShowMeAI的深度学习教程中文章自然语言处理与词嵌入

softmax中用于归一化的分母的计算代价太高
- 我们将在作业2中实现使用 negative sampling/负例采样方法的 skip-gram 模型。
- 使用一个 true pair (中心词及其上下文窗口中的词)与几个 noise pair (中心词与随机词搭配) 形成的样本,训练二元逻辑回归。

原文中的(最大化)目标函数是 \(J(\theta)=\frac{1}{T} \sum_{t=1}^{T} J_{t}(\theta)\)
- 左侧为sigmoid函数(大家会在后续的内容里经常见到它)
- 我们要最大化2个词共现的概率

本课以及作业中的目标函数是
- 我们取 \(k\) 个负例采样
- 最大化窗口中包围「中心词」的这些词语出现的概率,而最小化其他没有出现的随机词的概率
\(P(w)=U(w)^{3 / 4} / Z\)
- 我们用左侧的公式进行抽样,其中 \(U(w)\) 是 unigram 分布
- 通过 3/4 次方,相对减少常见单词的频率,增大稀有词的概率
- \(Z\) 用于生成概率分布
3.计数与共现矩阵
3.1 共现矩阵与词向量构建
在自然语言处理里另外一个构建词向量的思路是借助于共现矩阵(我们设其为 \(X\) ),我们有两种方式,可以基于窗口(window)或者全文档(full document)统计:

- Window :与word2vec类似,在每个单词周围都使用Window,包括语法(POS)和语义信息
- Word-document 共现矩阵的基本假设是在同一篇文章中出现的单词更有可能相互关联。假设单词 \(i\) 出现在文章 \(j\) 中,则矩阵元素 \(X_{ij}\) 加一,当我们处理完数据库中的所有文章后,就得到了矩阵 \(X\) ,其大小为 \(|V|\times M\) ,其中 \(|V|\) 为词汇量,而 \(M\) 为文章数。这一构建单词文章co-occurrence matrix的方法也是经典的Latent Semantic Analysis所采用的【语义分析】。
3.2 基于窗口的共现矩阵示例
利用某个定长窗口(通常取5-10)中单词与单词同时出现的次数,来产生基于窗口的共现矩阵。

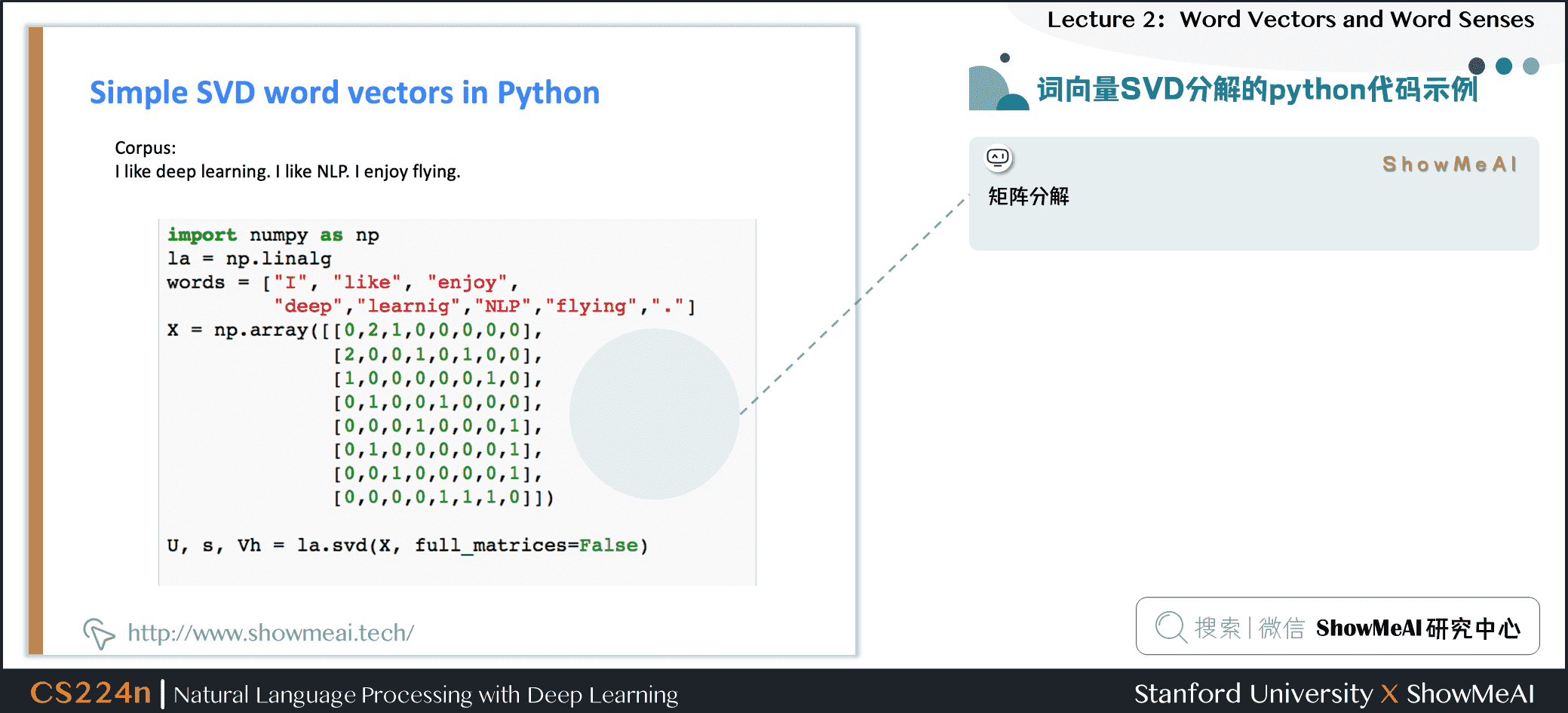
下面以窗口长度为1来举例,假设我们的数据包含以下几个句子:
- I like deep learning.
- I like NLP.
- I enjoy flying.
我们可以得到如下的词词共现矩阵(word-word co-occurrence matrix)

3.3 基于直接的共现矩阵构建词向量的问题
直接基于共现矩阵构建词向量,会有一些明显的问题,如下:

- 使用共现次数衡量单词的相似性,但是会随着词汇量的增加而增大矩阵的大小。
- 需要很多空间来存储这一高维矩阵。
- 后续的分类模型也会由于矩阵的稀疏性而存在稀疏性问题,使得效果不佳。
3.4 解决方案:低维向量

针对上述问题,我们的一个处理方式是降维,获得低维稠密向量。
- 通常降维到(25-1000)维,和word2vec类似
如何降维呢?
3.5 方法1:对X进行降维(作业1)
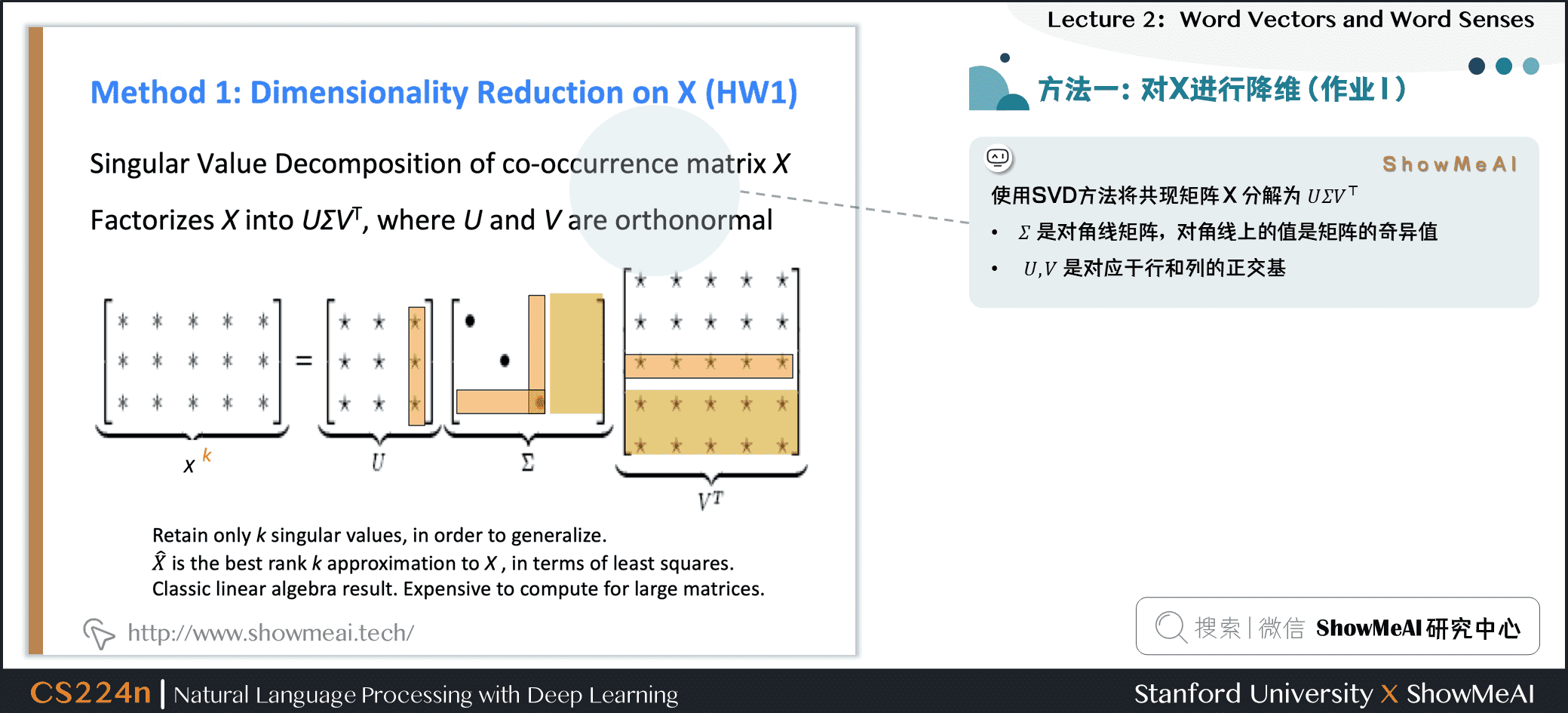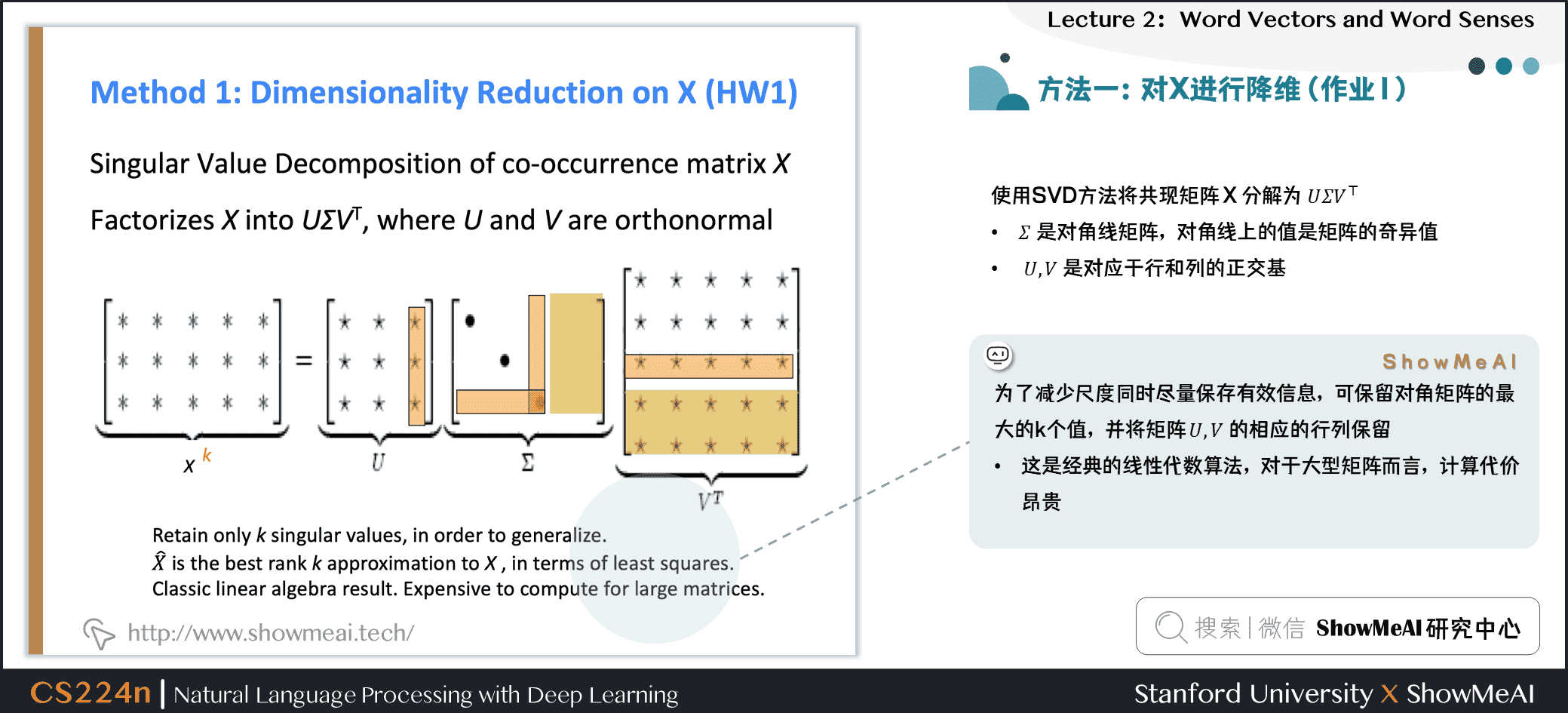
可以使用SVD方法将共现矩阵 \(X\) 分解为 \(U \Sigma V^T\) ,其中:
- \(\Sigma\) 是对角线矩阵,对角线上的值是矩阵的奇异值
- \(U\) , \(V\) 是对应于行和列的正交基
为了减少尺度同时尽量保存有效信息,可保留对角矩阵的最大的 \(k\) 个值,并将矩阵 \(U\) , \(V\) 的相应的行列保留。
- 这是经典的线性代数算法,对于大型矩阵而言,计算代价昂贵。
3.6 词向量SVD分解的python代码示例
python矩阵分解示例如下
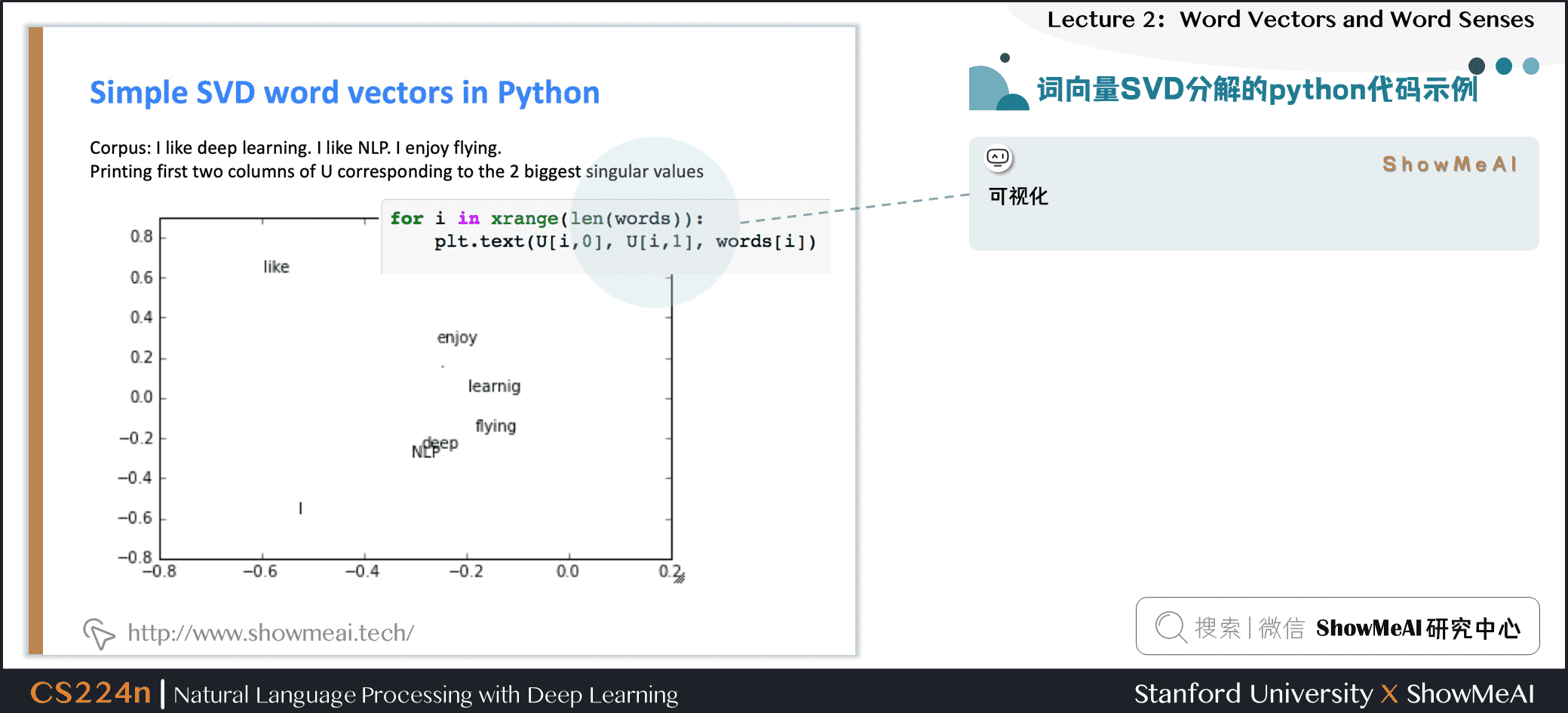
降维词向量可视化
3.7 #论文讲解#
Hacks to X (several used in Rohde et al. 2005)

按比例调整 counts 会很有效
- 对高频词进行缩放(语法有太多的影响)
- 使用log进行缩放
- \(min(X, t), t \approx 100\)
- 直接全部忽视
- 在基于window的计数中,提高更加接近的单词的计数
- 使用Person相关系数
3.8 词向量分布探究
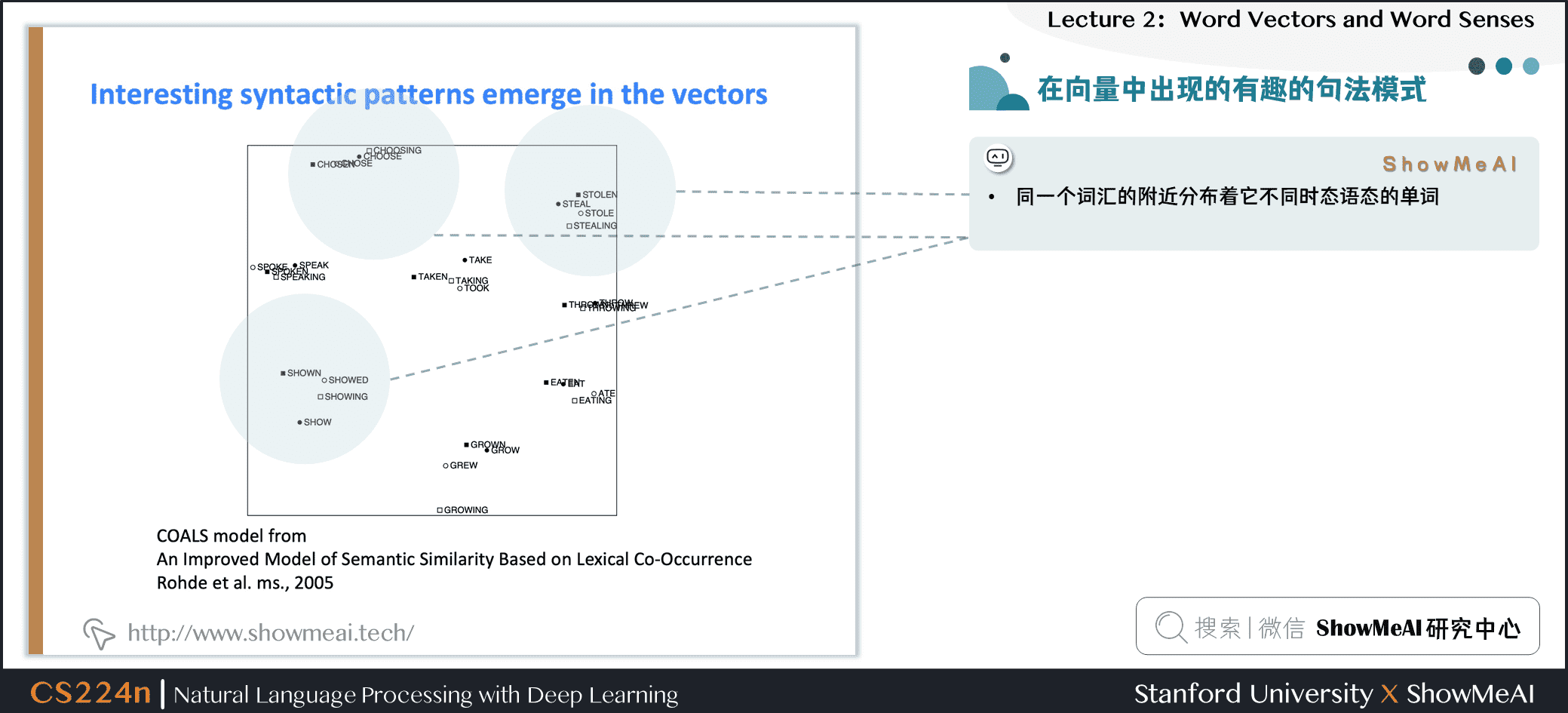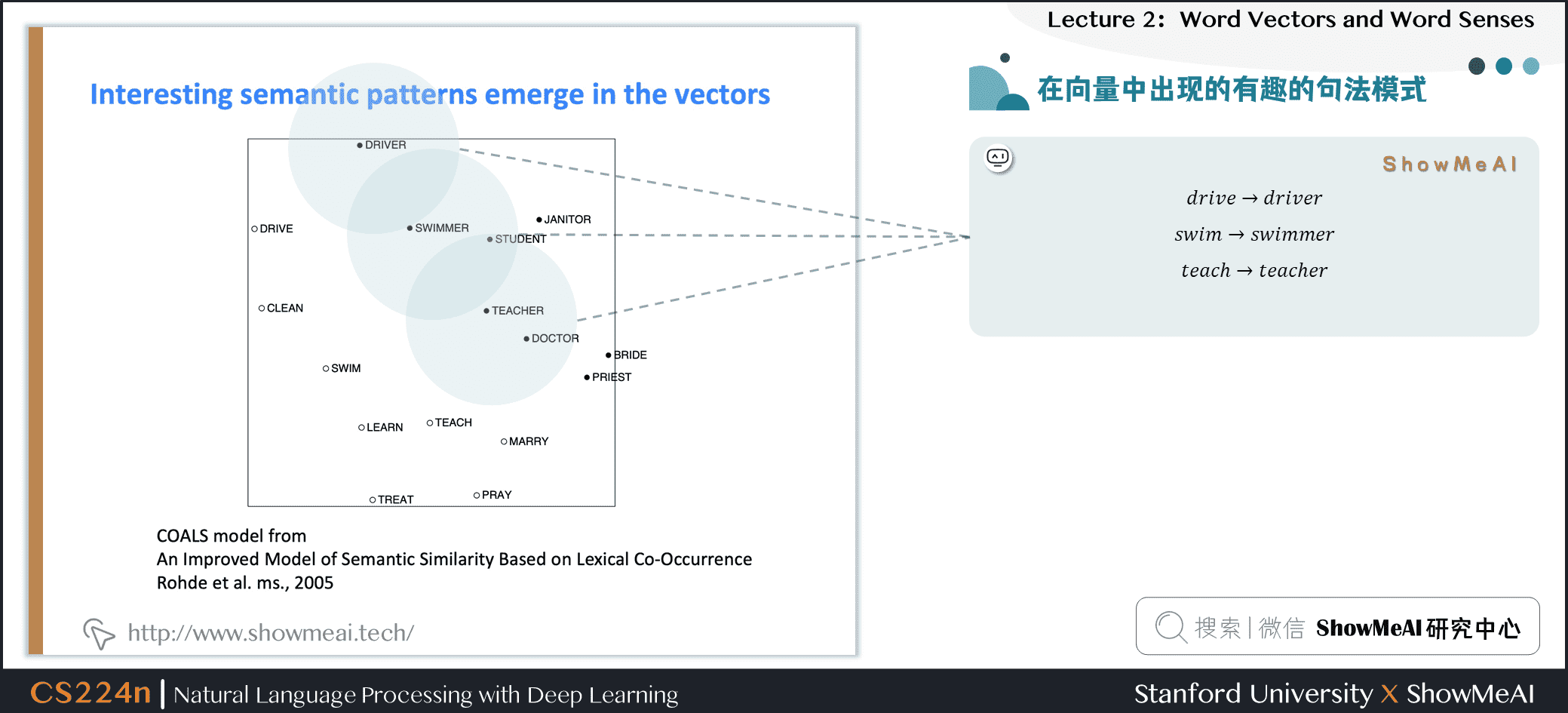
如果对词向量进行空间分布,会发现同一个词汇的附近分布着它不同时态语态的单词:
- \(drive \to driver\)
- \(swim \to swimmer\)
- \(teach \to teacher\)
在向量中出现的有趣的句法模式:语义向量基本上是线性组件,虽然有一些摆动,但是基本是存在动词和动词实施者的方向。
3.9 基于计数 VS. 基于预估
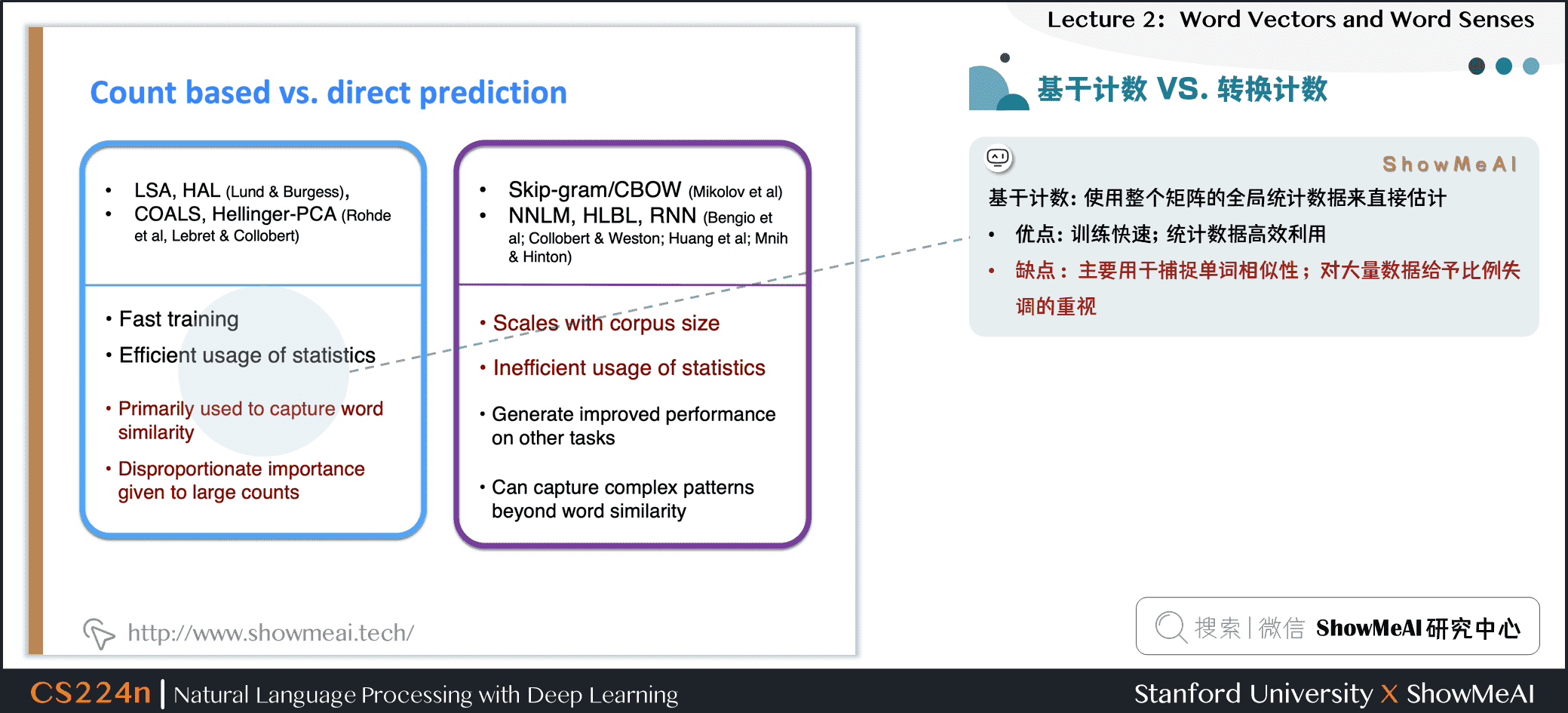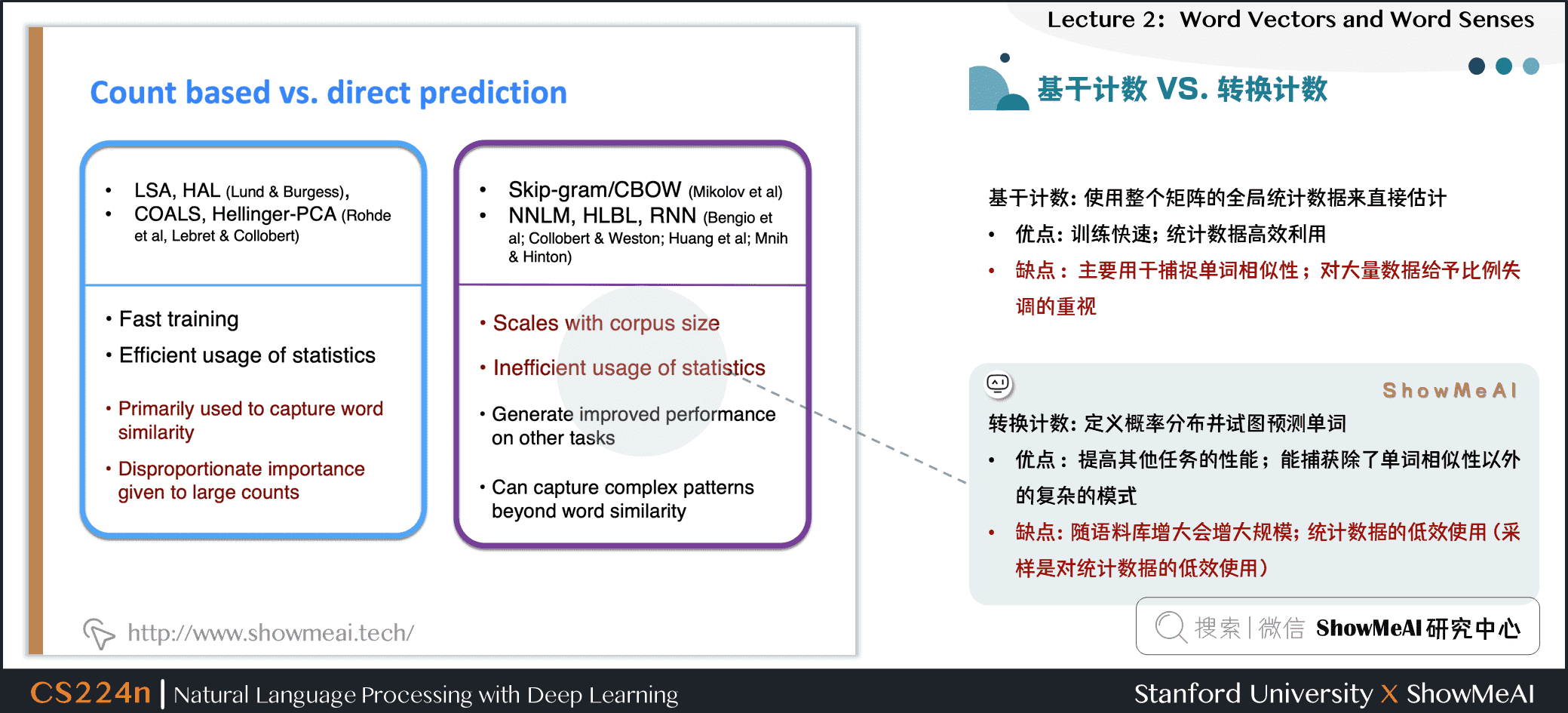
我们来总结一下基于共现矩阵计数和基于预估模型两种得到词向量的方式
基于计数:使用整个矩阵的全局统计数据来直接估计
- 优点:训练快速;统计数据高效利用
- 缺点:主要用于捕捉单词相似性;对大量数据给予比例失调的重视
基于预估模型:定义概率分布并试图预测单词
- 优点:提高其他任务的性能;能捕获除了单词相似性以外的复杂的模式
- 缺点:随语料库增大会增大规模;统计数据的低效使用(采样是对统计数据的低效使用)
4.GloVe模型
4.1 #论文讲解#
1)Encoding meaning in vector differences
将两个流派的想法结合起来,在神经网络中使用计数矩阵。关于Glove的理论分析需要阅读原文,也可以阅读 NLP教程(2) | GloVe及词向量的训练与评估。

GloVe模型关键思想:共现概率的比值可以对meaning component进行编码。将两个流派的想法结合起来,在神经网络中使用计数矩阵。
补充讲解:
重点不是单一的概率大小,重点是他们之间的比值,其中蕴含着重要的信息成分。
-
例如我们想区分热力学上两种不同状态ice冰与蒸汽steam,它们之间的关系可通过与不同的单词 \(x\) 的共现概率的比值来描述
-
例如对于solid固态,虽然 \(P(solid \mid ice)\) 与 \(P(solid \mid steam)\) 本身很小,不能透露有效的信息,但是它们的比值 \(\frac{P(solid \mid ice)}{P(solid \mid steam)}\) 却较大,因为solid更常用来描述ice的状态而不是steam的状态,所以在ice的上下文中出现几率较大
-
对于gas则恰恰相反,而对于water这种描述ice与steam均可或者fashion这种与两者都没什么联系的单词,则比值接近于 \(1\) 。所以相较于单纯的共现概率,实际上共现概率的相对比值更有意义

问题:
我们如何在词向量空间中以线性含义成分的形式捕获共现概率的比值?
解决方案:
- log-bilinear 模型:
- 向量差异:
2)Combining the best of both worlds GloVe [Pennington et al., EMNLP 2014]
![#论文讲解# Combining the best of both worlds GloVe [Pennington et al., EMNLP 2014]](https://img-blog.csdnimg.cn/img_convert/58fdeebb15c21077c18aecb8942f8d76.gif)
补充讲解
- 如果使向量点积等于共现概率的对数,那么向量差异变成了共现概率的比率
- 使用平方误差促使点积尽可能得接近共现概率的对数
- 使用 \(f(x)\) 对常见单词进行限制
优点
- 训练快速
- 可以扩展到大型语料库
- 即使是小语料库和小向量,性能也很好
4.2 GloVe的一些结果展示

上图是一个GloVe词向量示例,我们通过GloVe得到的词向量,我们可以找到frog(青蛙)最接近的一些词汇,可以看出它们本身是很类似的动物。
5.词向量评估
5.1 如何评估词向量?

我们如何评估词向量呢,有内在和外在两种方式:
-
内在评估方式
- 对特定/中间子任务进行评估
- 计算速度快
- 有助于理解这个系统
- 不清楚是否真的有用,除非与实际任务建立了相关性
-
外部任务方式
- 对真实任务(如下游NLP任务)的评估
- 计算精确度可能需要很长时间
- 不清楚子系统问题所在,是交互还是其他子系统问题
- 如果用另一个子系统替换一个子系统可以提高精确度
5.2 内在词向量评估
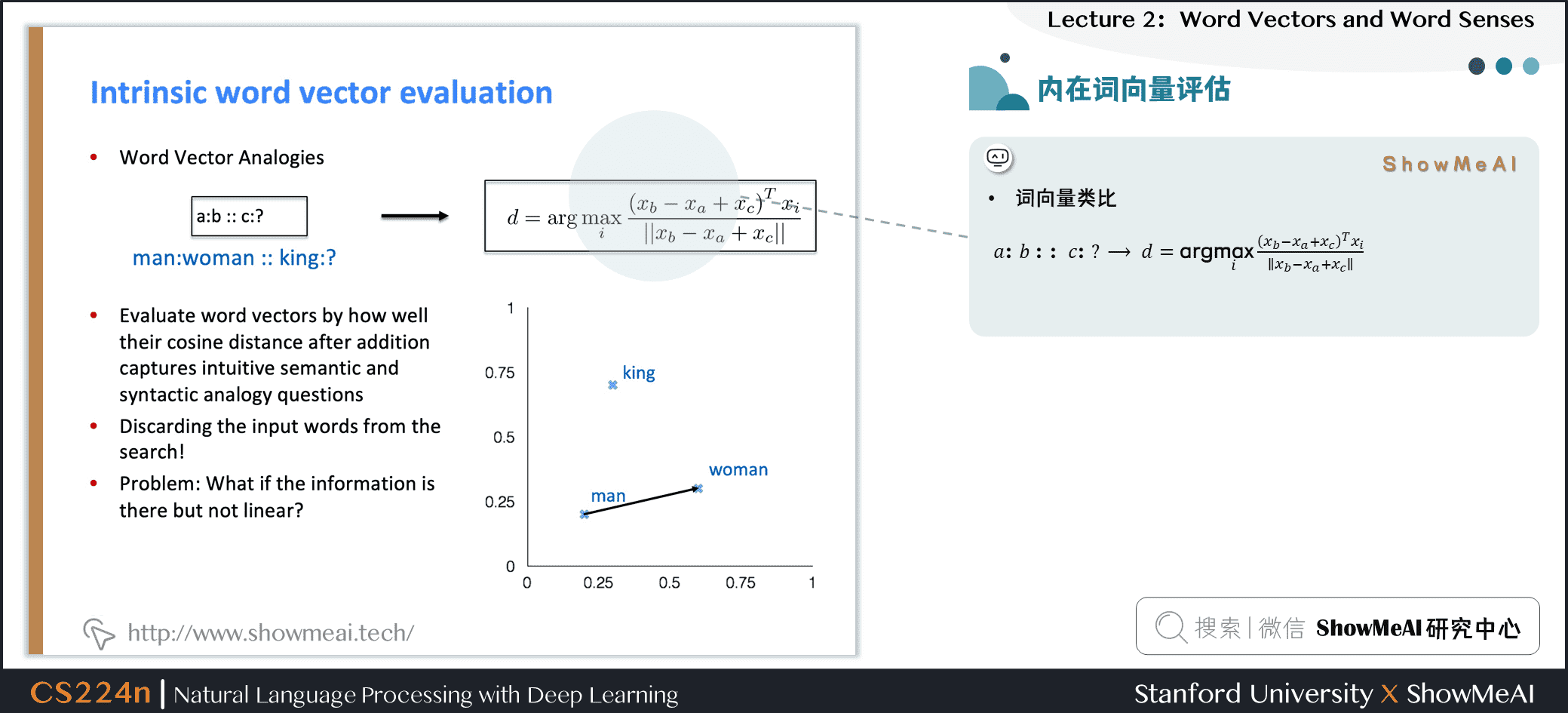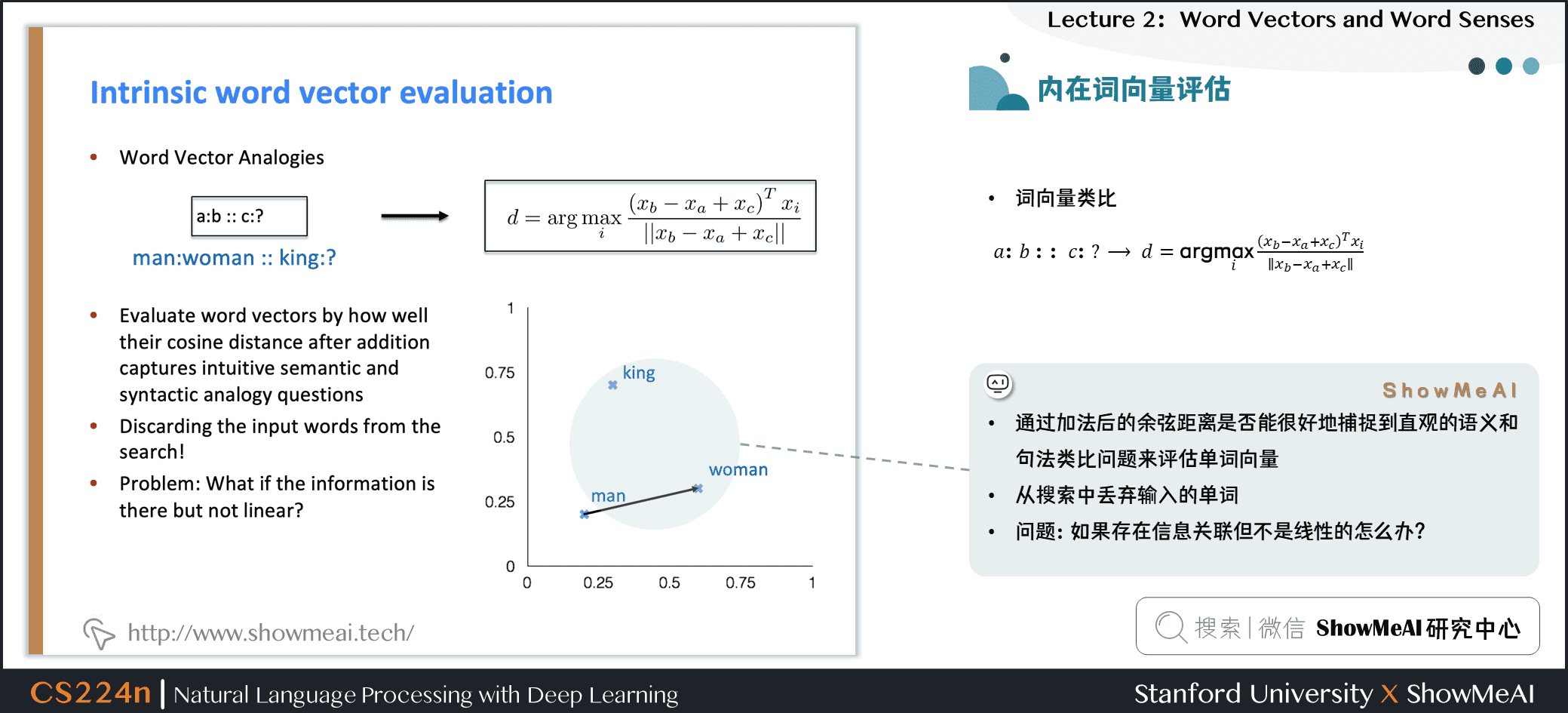
一种内在词向量评估方式是「词向量类比」:对于具备某种关系的词对a,b,在给定词c的情况下,找到具备类似关系的词d
- 通过加法后的余弦距离是否能很好地捕捉到直观的语义和句法类比问题来评估单词向量
- 从搜索中丢弃输入的单词
- 问题:如果有信息但不是线性的怎么办?
5.3 Glove可视化效果
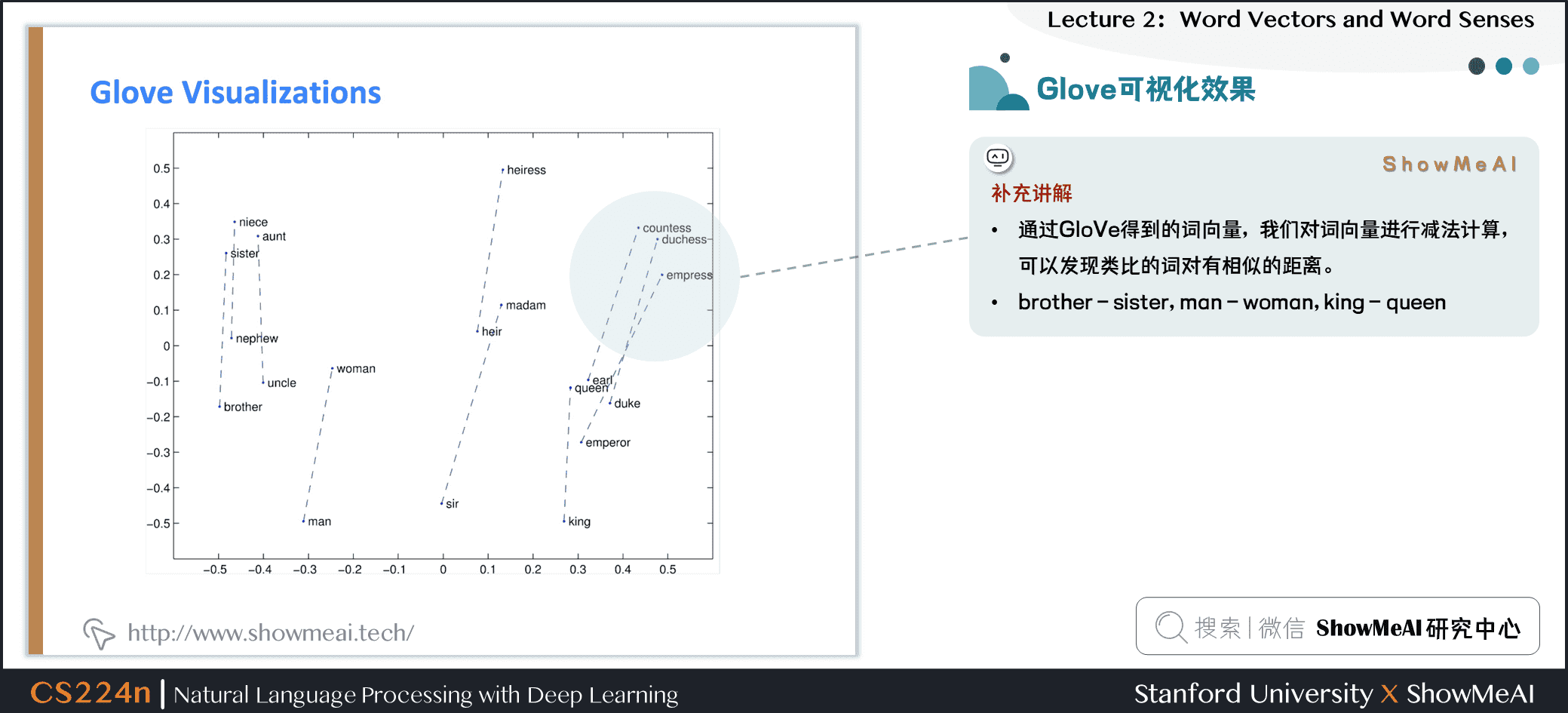
上述为GloVe得到的词向量空间分布,我们对词向量进行减法计算,可以发现类比的词对有相似的距离。
brother – sister, man – woman, king - queen
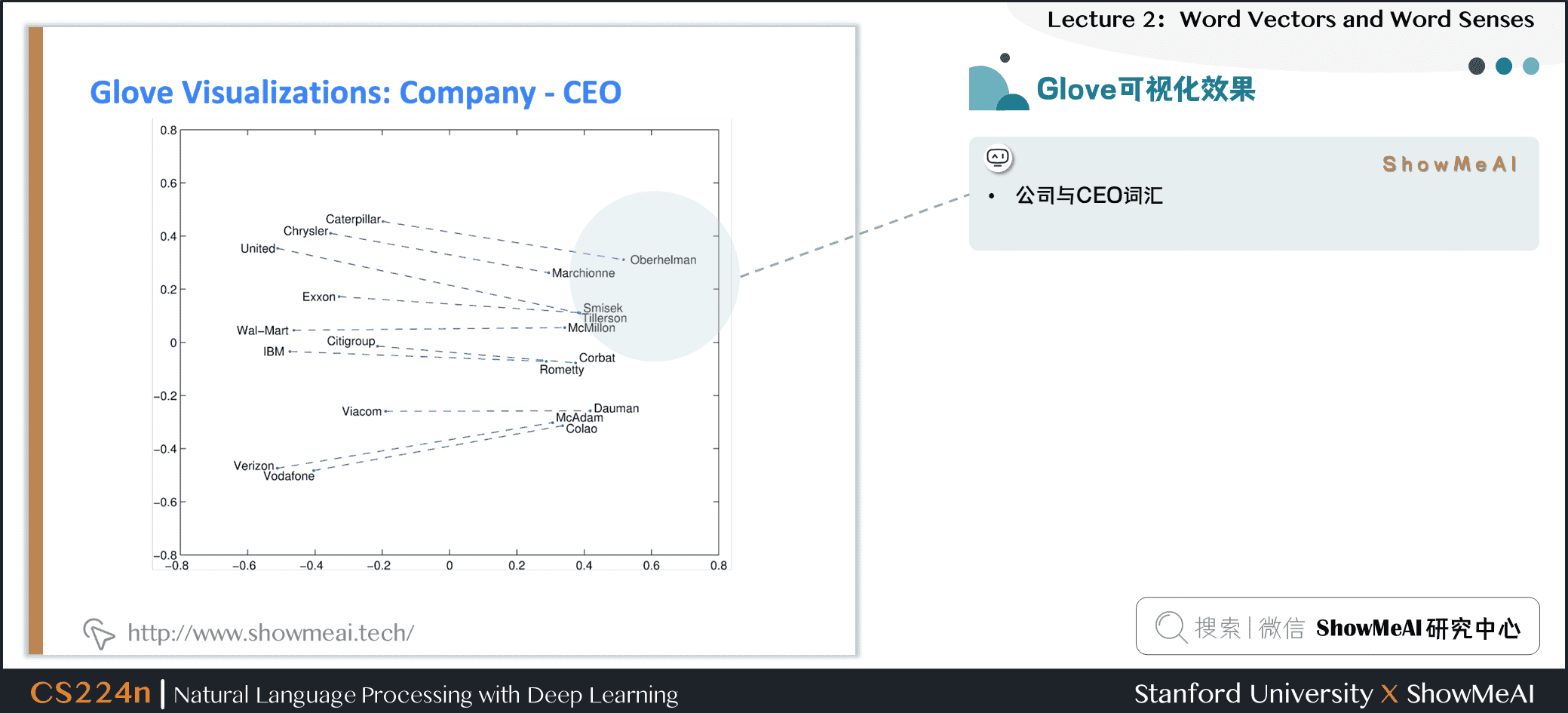
下图为“公司与CEO词汇”分布
下图为“词汇比较级与最高级”分布
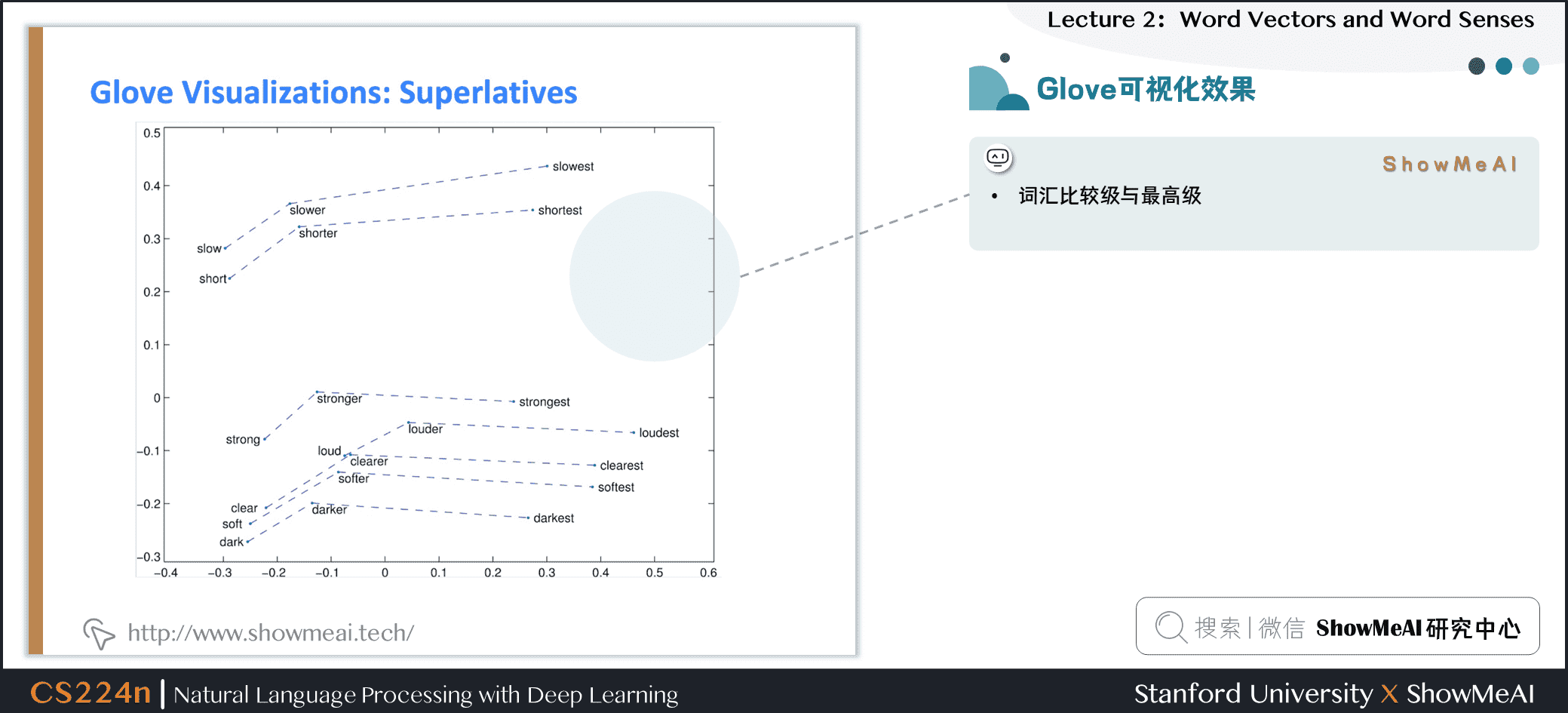
5.4 内在词向量评估的细节


5.5 类比任务评估与超参数
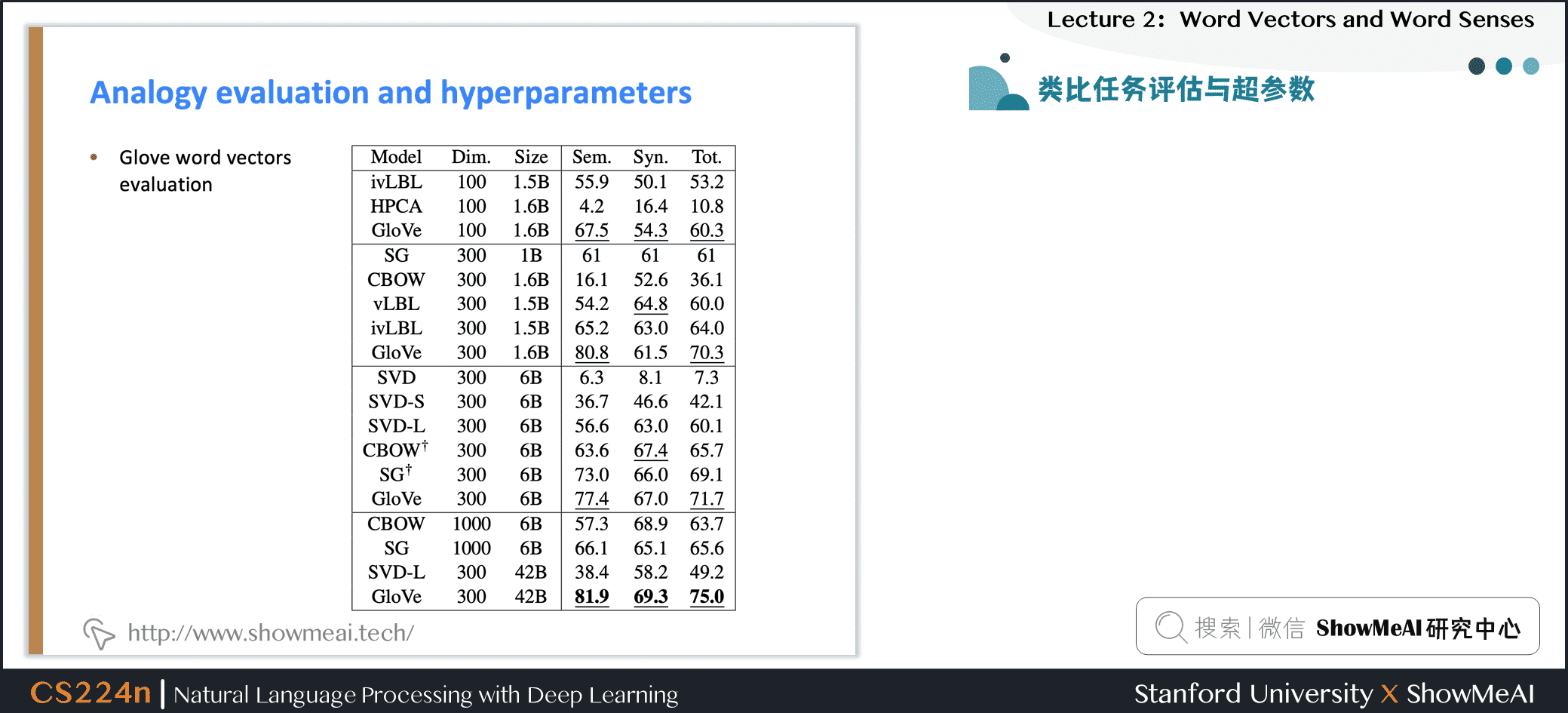
下图是对于类比评估和超参数的一些实验和经验
- 300是一个很好的词向量维度
- 不对称上下文(只使用单侧的单词)不是很好,不过这点在下游任务中不一定完全正确
- window size 设为 8 对 Glove向量来说比较好

补充分析
- window size设为2的时候实际上有效的,并且对于句法分析是更好的,因为句法效果非常局部
5.6 #论文讲解#
1)On the Dimensionality of Word Embedding

利用矩阵摄动理论,揭示了词嵌入维数选择的基本的偏差与方法的权衡
补充说明:当持续增大词向量维度的时候,词向量的效果不会一直变差并且会保持平稳。
5.7 类比任务评估与超参数
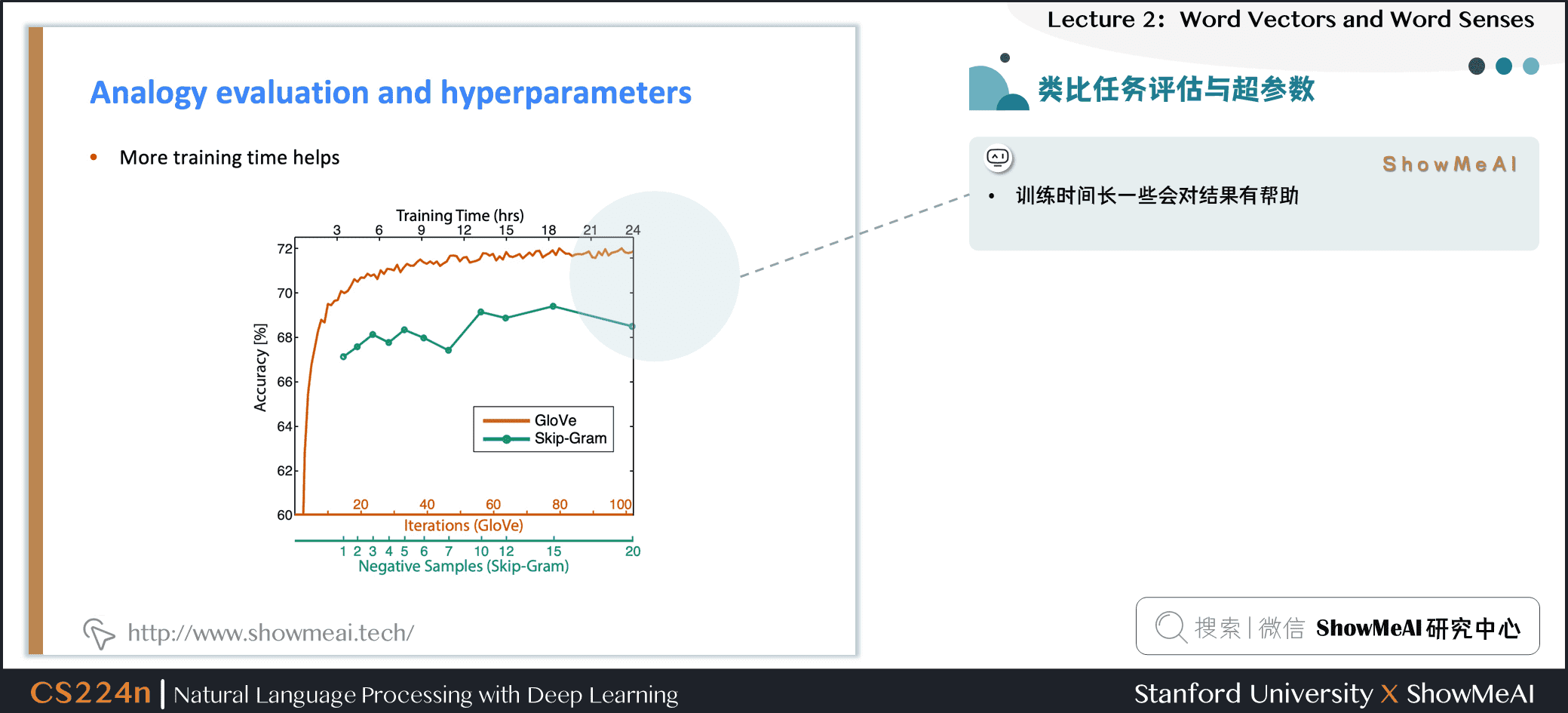
- 训练时间长一些会对结果有帮助
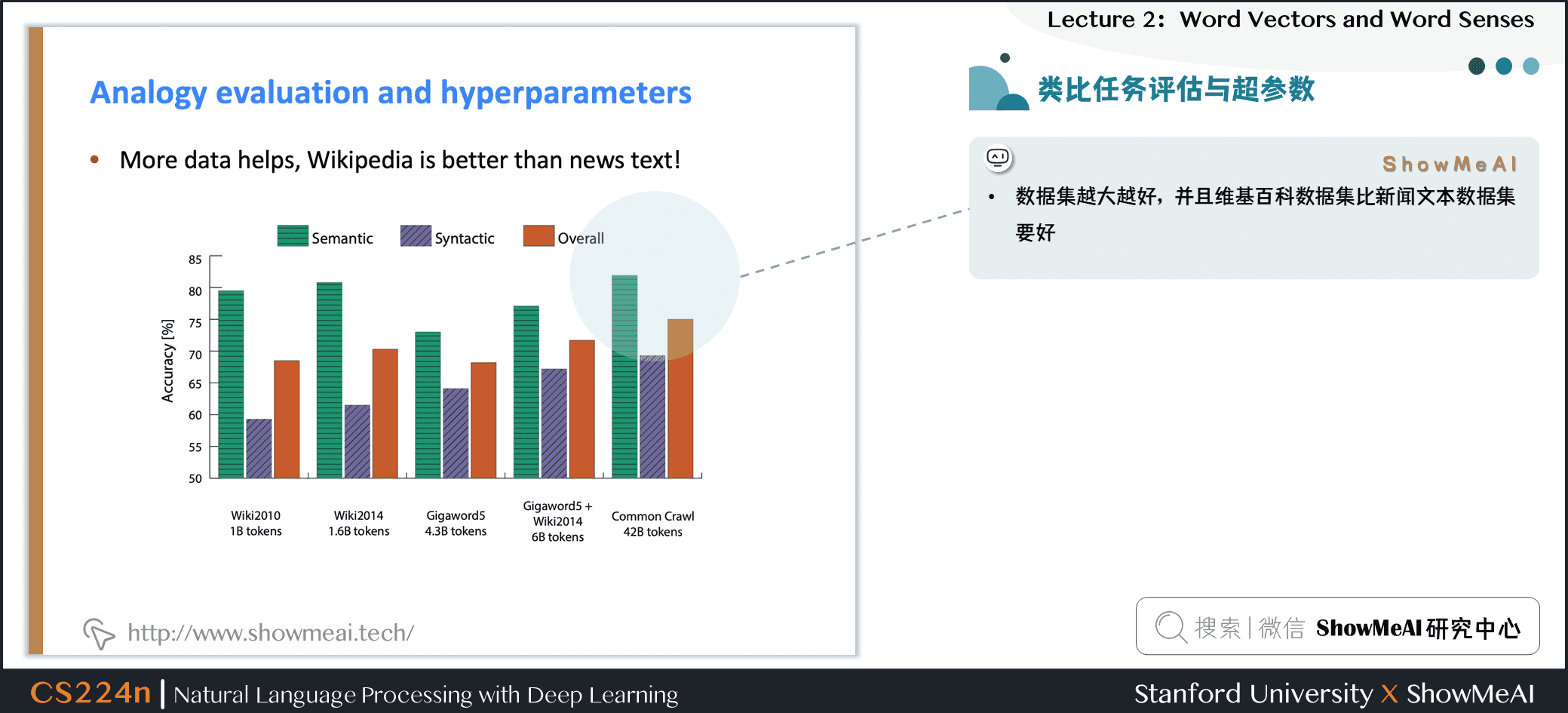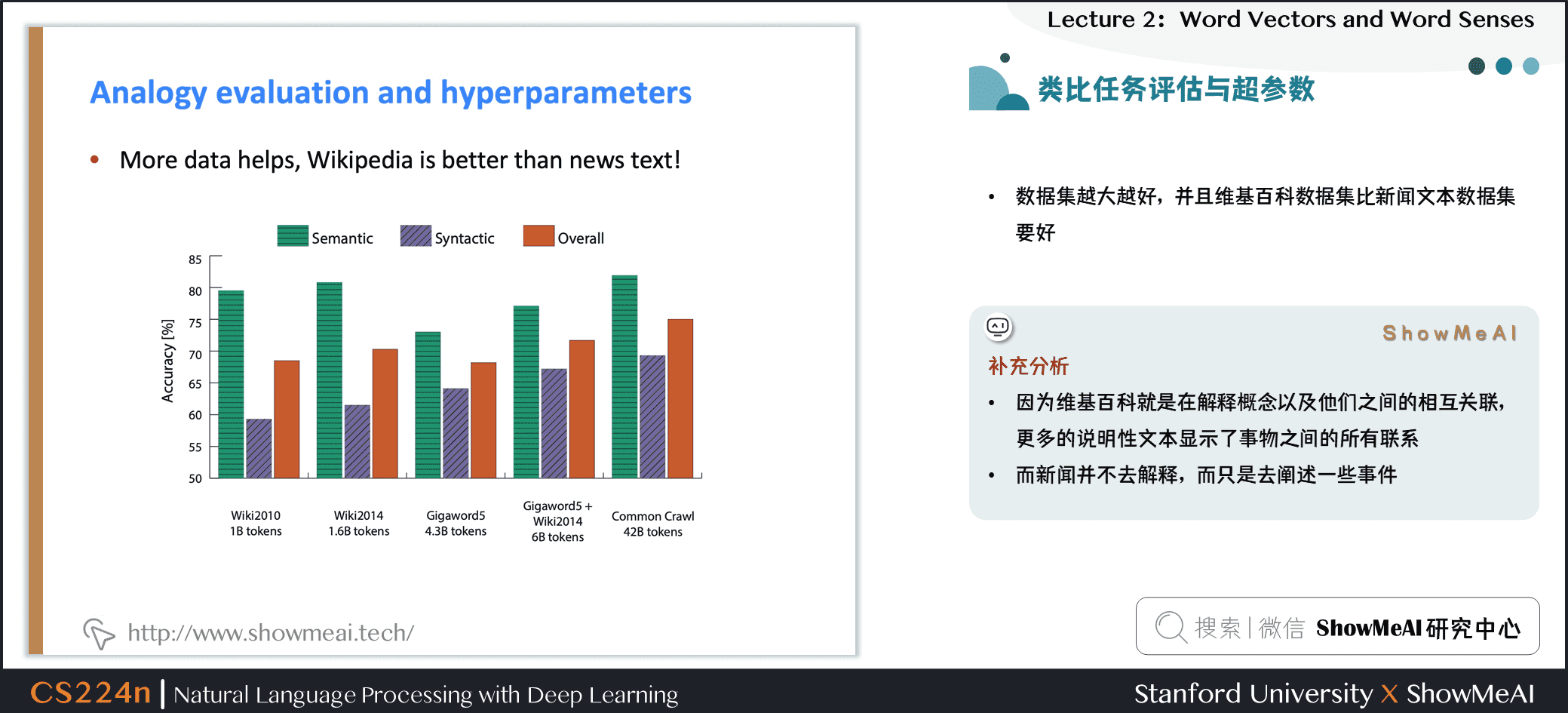
- 数据集越大越好,并且维基百科数据集比新闻文本数据集要好
补充分析
- 因为维基百科就是在解释概念以及他们之间的相互关联,更多的说明性文本显示了事物之间的所有联系
- 而新闻并不去解释,而只是去阐述一些事件
5.8 另一个内在词向量评估

- 使用 cosine similarity 衡量词向量之间的相似程度
- 并与人类评估比照
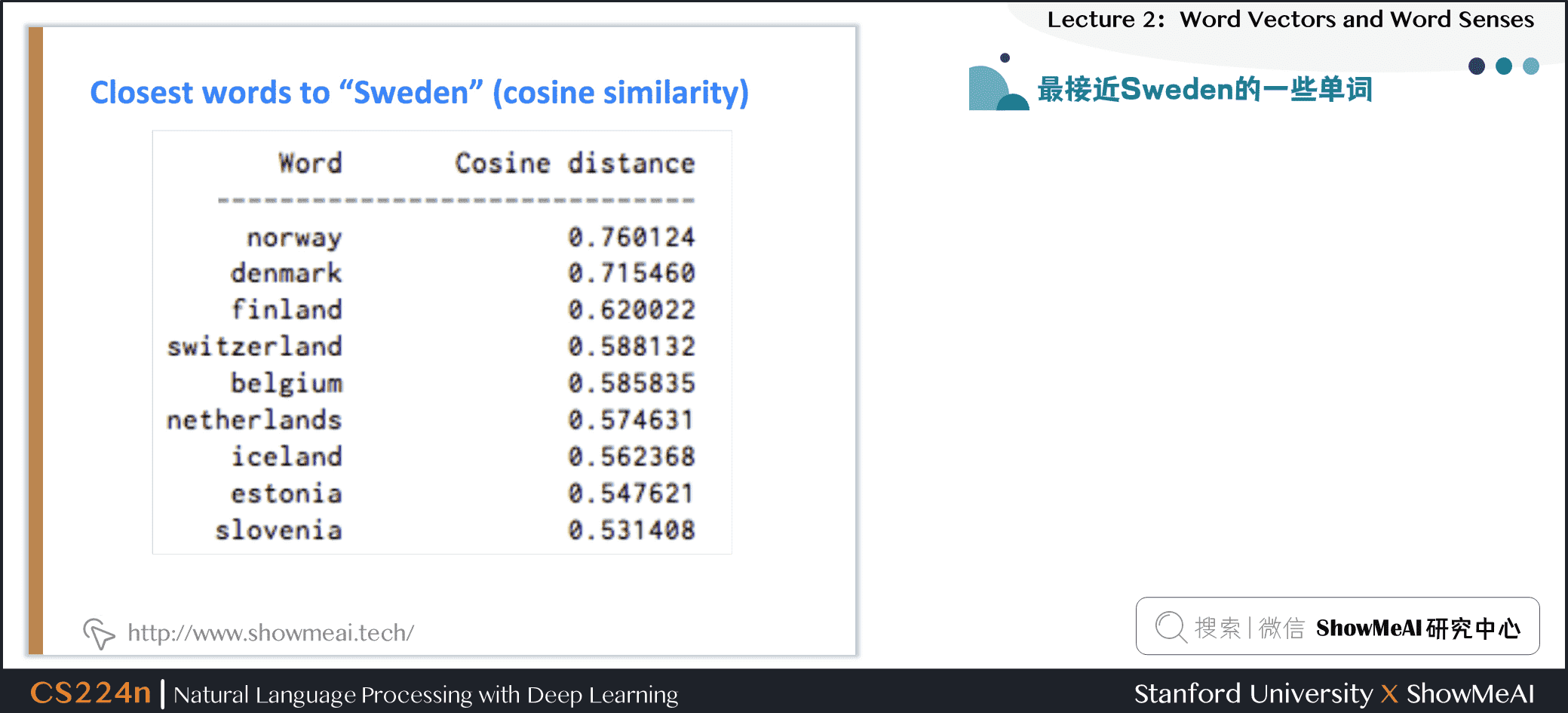
5.9 最接近Sweden的一些单词
5.10 相关性评估
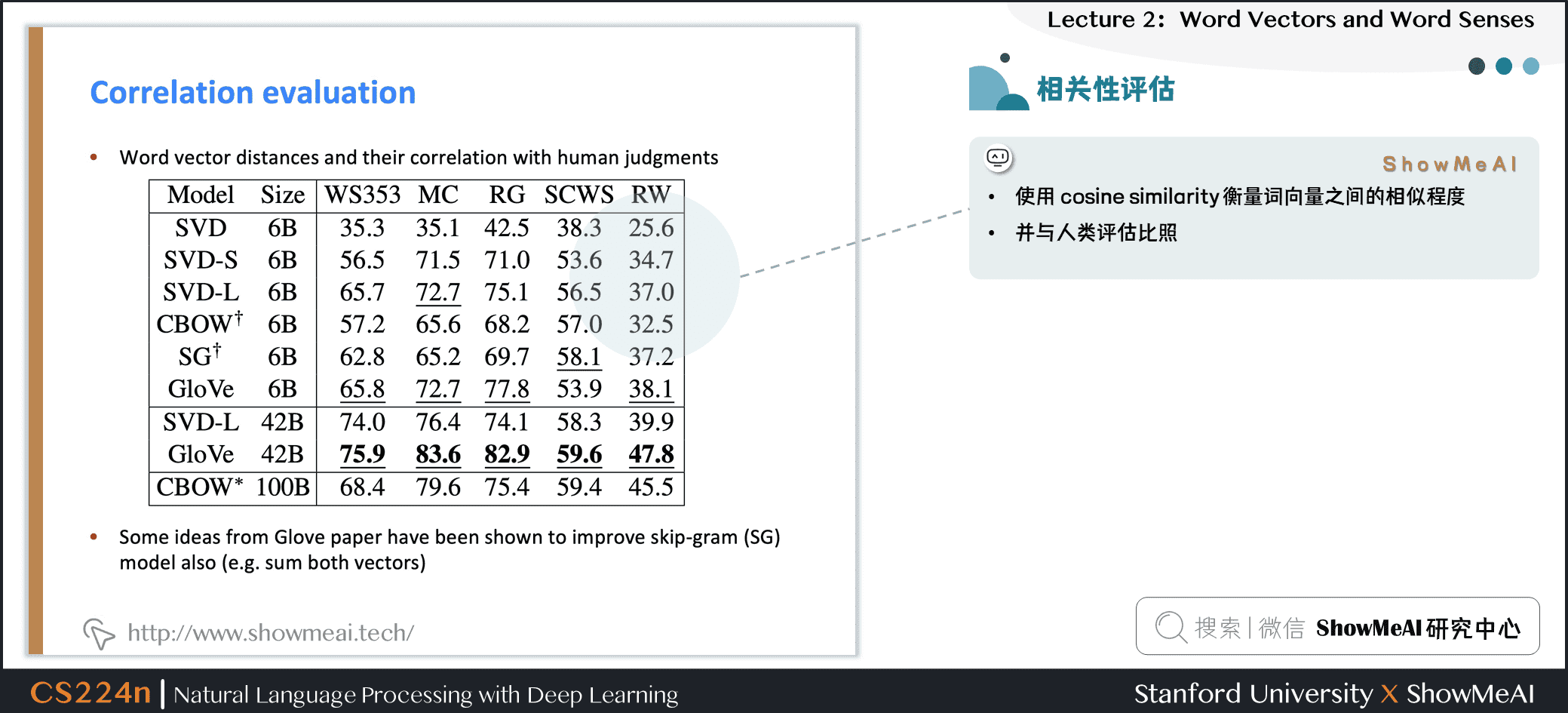
- 使用 cosine similarity 衡量词向量之间的相似程度
- 并与人类评估比照
6.word senses
6.1 词义与词义歧义

大多数单词都是多义的
- 特别是常见单词
- 特别是存在已久的单词
例如:pike
那么,词向量是总体捕捉了所有这些信息,还是杂乱在一起了呢?
6.2 pike的不同含义示例
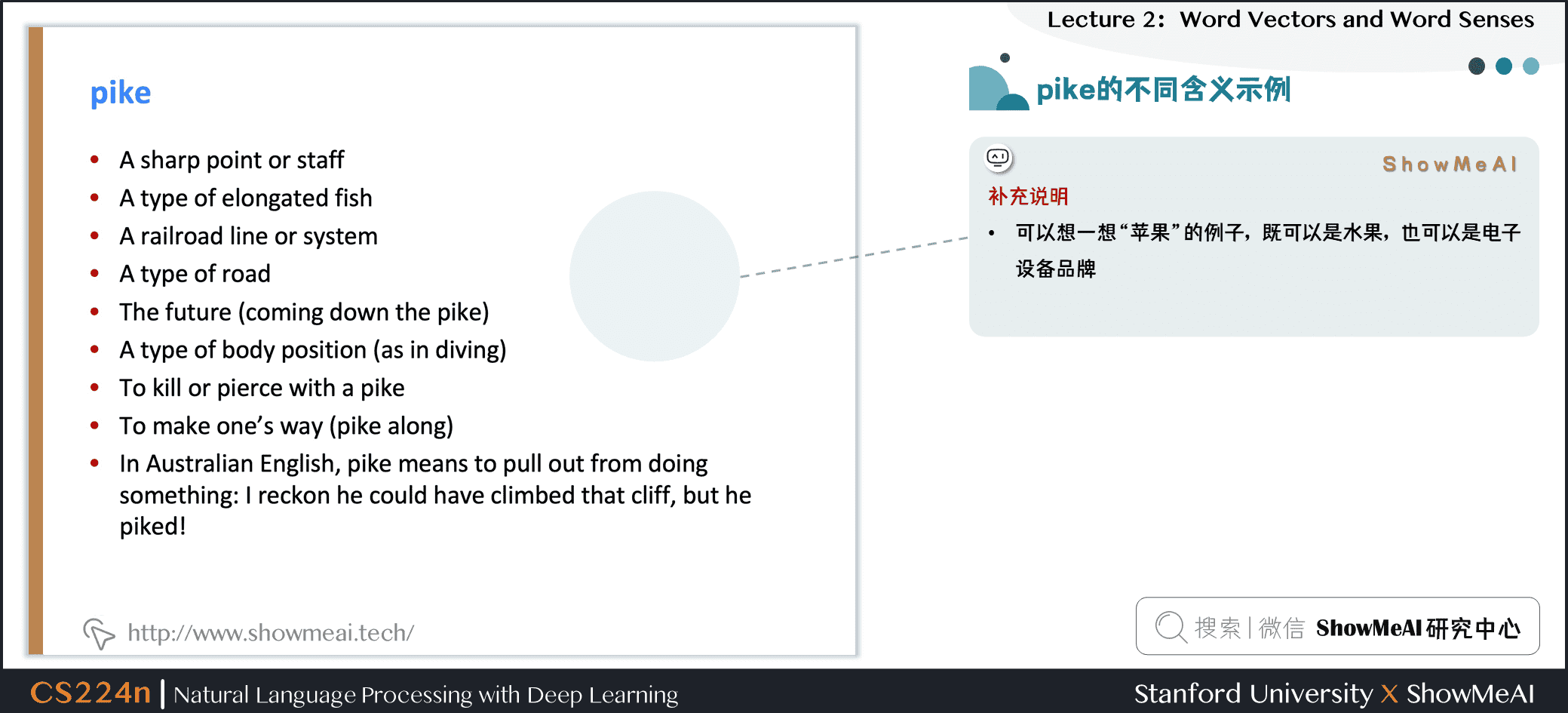
补充说明:可以想一想“苹果”的例子,既可以是水果,也可以是电子设备品牌。
6.3 #论文讲解#
1)Improving Word Representations Via Global Context And Multiple Word Prototypes (Huang et al. 2012)

将常用词的所有上下文进行聚类,通过该词得到一些清晰的簇,从而将这个常用词分解为多个单词,例如 \(bank_1\) 、 \(bank_2\) 、 \(bank_3\) 。
补充说明:虽然这很粗糙,并且有时sensors之间的划分也不是很明确,甚至相互重叠。
2)Linear Algebraic Structure of Word Senses, with Applications to Polysemy
- 单词在标准单词嵌入(如word2vec)中的不同含义以线性叠加(加权和)的形式存在
- 其中, \(\alpha_1=\frac{f_1}{f_1+f_2+f_3}\)

令人惊讶的结果:
- 只是加权平均值就已经可以获得很好的效果
- 由于从稀疏编码中得到的概念,你实际上可以将感官分离出来(前提是它们相对比较常见)
补充讲解:可以理解为由于单词存在于高维的向量空间之中,不同的纬度所包含的含义是不同的,所以加权平均值并不会损害单词在不同含义所属的纬度上存储的信息。
6.4 外向词向量评估

- 单词向量的外部评估:词向量可以应用于NLP的很多下游任务
- 一个例子是在命名实体识别任务中,寻找人名、机构名、地理位置名,词向量非常有帮助
7.视频教程
可以点击 B站 查看视频的【双语字幕】版本
8.参考资料
- 本讲带学的在线阅翻页本
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
- Stanford官网 | CS224n: Natural Language Processing with Deep Learning
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
自然语言处理 (NLP) 教程
- NLP教程(1)- 词向量、SVD分解与Word2vec
- NLP教程(2)- GloVe及词向量的训练与评估
- NLP教程(3)- 神经网络与反向传播
- NLP教程(4)- 句法分析与依存解析
- NLP教程(5)- 语言模型、RNN、GRU与LSTM
- NLP教程(6)- 神经机器翻译、seq2seq与注意力机制
- NLP教程(7)- 问答系统
- NLP教程(8)- NLP中的卷积神经网络
- NLP教程(9)- 句法分析与树形递归神经网络
斯坦福 CS224n 课程带学详解
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
- 斯坦福NLP课程 | 第3讲 - 神经网络知识回顾
- 斯坦福NLP课程 | 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP课程 | 第5讲 - 句法分析与依存解析
- 斯坦福NLP课程 | 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP课程 | 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP课程 | 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP课程 | 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP课程 | 第10讲 - NLP中的问答系统
- 斯坦福NLP课程 | 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP课程 | 第12讲 - 子词模型
- 斯坦福NLP课程 | 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP课程 | 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
- 斯坦福NLP课程 | 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP课程 | 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP课程 | 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP课程 | 第19讲 - AI安全偏见与公平
- 斯坦福NLP课程 | 第20讲 - NLP与深度学习的未来


