
深度学习教程 | Seq2Seq序列模型和注意力机制
 本篇介绍自然语言处理中关于序列模型的高级知识,包括Sequence to sequence序列到序列模型和注意力机制。
本篇介绍自然语言处理中关于序列模型的高级知识,包括Sequence to sequence序列到序列模型和注意力机制。

- 作者:韩信子@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/35
- 本文地址:https://www.showmeai.tech/article-detail/227
- 声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容

本系列为吴恩达老师《深度学习专项课程(Deep Learning Specialization)》学习与总结整理所得,对应的课程视频可以在这里查看。
引言
在ShowMeAI前一篇文章 自然语言处理与词嵌入 中我们对以下内容进行了介绍:
- 词嵌入与迁移学习/类比推理
- 词嵌入学习方法
- 神经概率语言模型
- word2vec(skip-gram与CBOW)
- GloVe
- 情感分析
- 词嵌入消除偏见
本篇介绍自然语言处理中关于序列模型的高级知识,包括Sequence to sequence序列到序列模型和注意力机制。
1.Seq2Seq 模型
1.1 Seq2Seq结构

Seq2Seq(Sequence-to-Sequence)模型能够应用于机器翻译、语音识别等各种序列到序列的转换问题。一个 Seq2Seq 模型包含编码器(Encoder)和解码器(Decoder)两部分,它们通常是两个不同的 RNN。
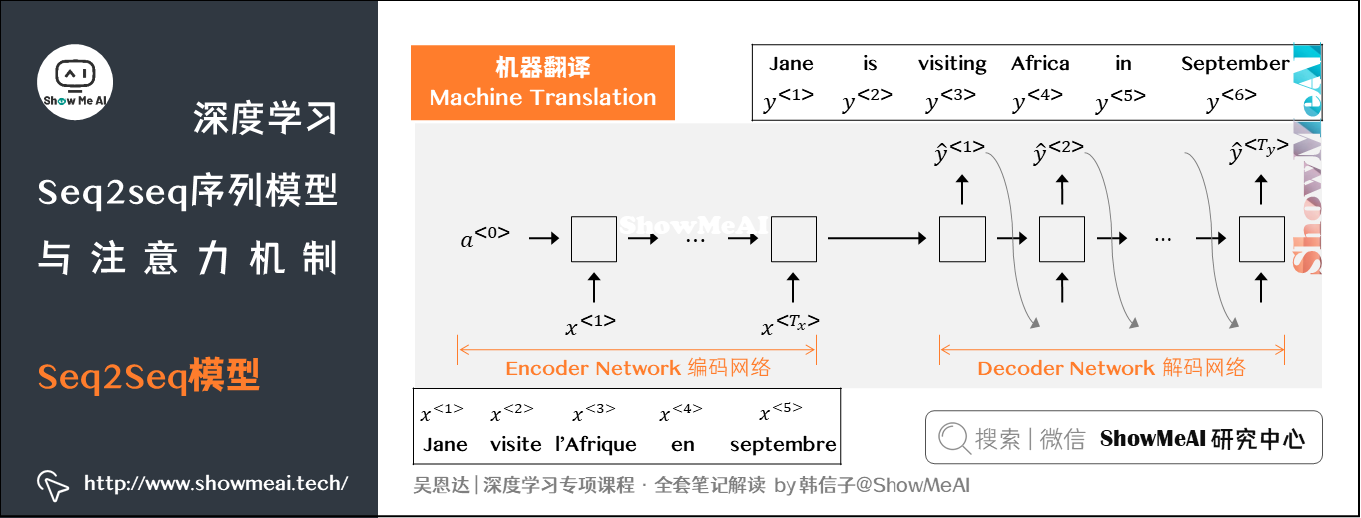
如图,为Seq2Seq模型典型的机器翻译应用,这个Seq2Seq网络中,包含编码网络(encoder network)和解码网络(decoder network)两个RNN模型子结构,其中encoder编码网络将输入语句编码为一个特征向量,传递给decoder解码网络,完成翻译输出。
提出 Seq2Seq 模型的相关论文:
Sutskever et al., 2014. Sequence to sequence learning with neural networks
1.2 Seq2Seq类似结构应用
这种编码器-解码器的结构也可以用于图像描述(Image captioning)任务。这个任务要根据给定的图像,「翻译」出对应的内容描述。

要完成上述任务,可以这么做:
① 第1步:将图片输入到CNN(例如预训练好的AlexNet/VGG/Inception),去掉最后的Bleu层,则倒数第2层这个全连接层的输出,就相当于图片的特征向量(编码向量),表征了图片特征信息。
② 第2步:将上述过程得到的图像信息表征向量输入至RNN,即decoder解码网络中,进行解码翻译输出。
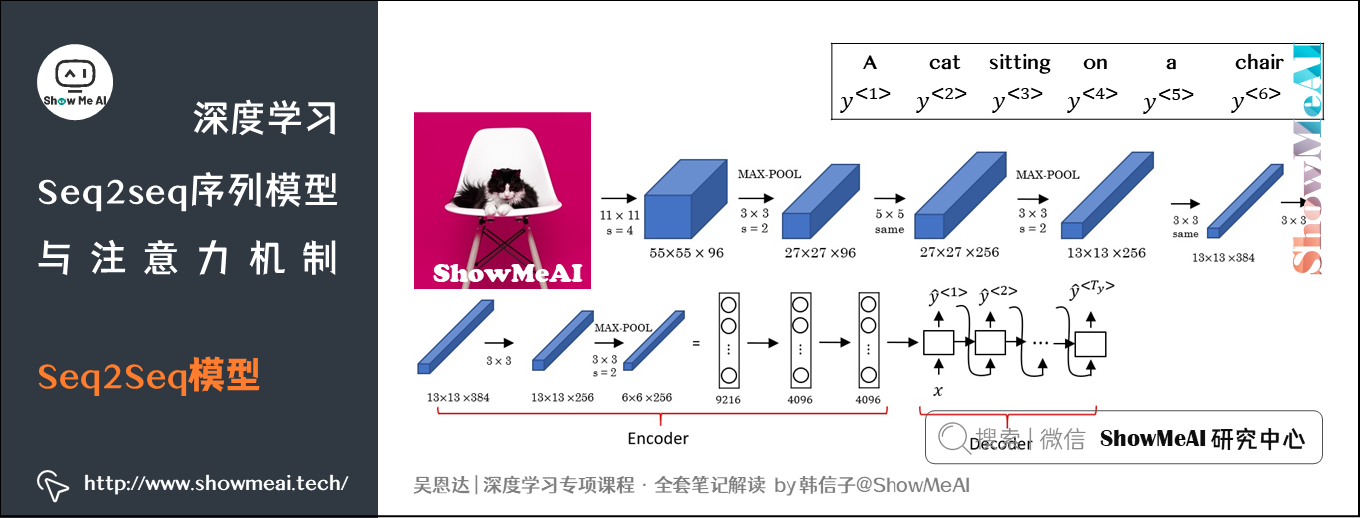
图像描述的相关论文:
Mao et. al., 2014. Deep captioning with multimodal recurrent neural networks
Vinyals et. al., 2014. Show and tell: Neural image caption generator
Karpathy and Fei Fei, 2015. Deep visual-semantic alignments for generating image descriptions
2.贪心搜索解码
2.1 机器翻译解码过程

上面提到的简单机器翻译模型与ShowMeAI前面文章 序列模型与RNN网络 提到的语言模型类似,只是用编码器的输出作为解码器第一个时间步的输入(而非0向量)。因此机器翻译的过程其实相当于建立一个条件语言模型。
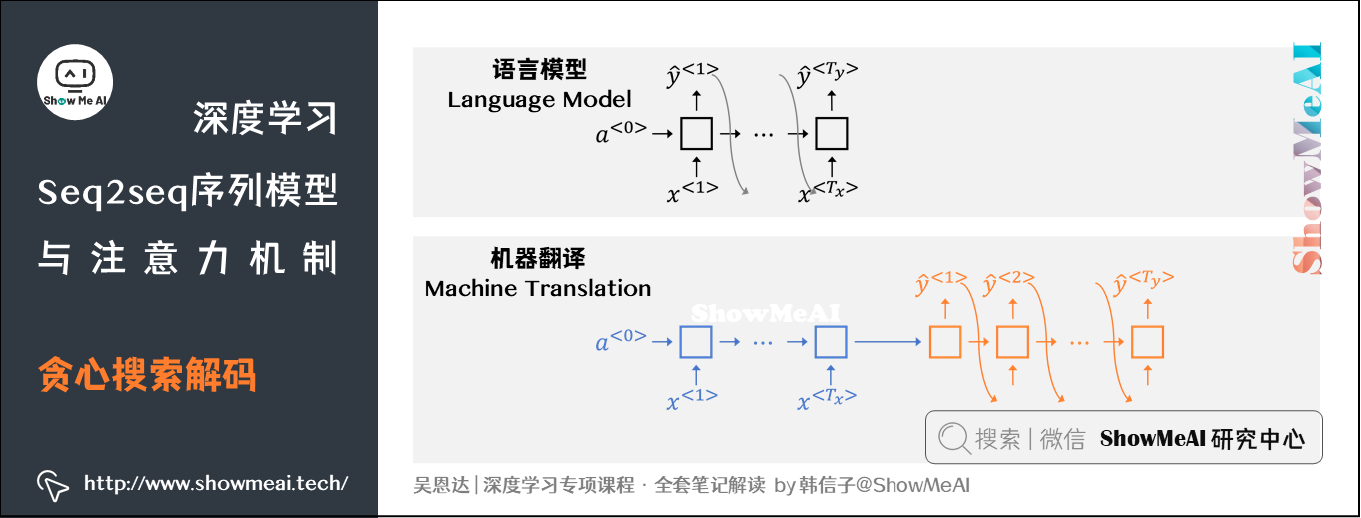
对应上图,是一个典型的机器翻译编码解码过程。解码器进行预测输出词的过程,结果可能有好有坏。我们希望找到能使条件概率最大化的翻译,即
\(arg \ max_{y^{\left \langle 1 \right \rangle}, \dots , y^{\left \langle T_y \right \rangle}}P(y^{\left \langle 1 \right \rangle}, \dots , y^{\left \langle T_y \right \rangle} \mid x)\)
2.2 贪心搜索
如下为吴恩达老师课程中的一个例子,翻译成英文有多个翻译候选:
Jane visite I'Afrique en septembre.
→ Jane is visiting Africa in September.
→ Jane is going to be visiting Africa in September.
→ In September, Jane will visit Africa.
→ Her African friend welcomed Jane in September.
最直接能想到的解决方法是贪婪搜索(greedy search):贪心搜索根据条件,解码器的每个时间步都选择概率最高的单词作为翻译输出。
例如,首先根据输入语句,找到第一个翻译的单词「Jane」,然后再找第二个单词「is」,再继续找第三个单词「visiting」,以此类推。
2.3 贪心搜索缺点
但上述贪心搜索方法存在一些缺点。
① 因为贪心搜索每次只选择概率最大的一个词,没有考虑该单词前后关系,概率选择上有可能会出错。
- 例如,上面翻译语句中,第三个单词「going」比「visiting」更常见,模型很可能会错误地选择了「going」,而错失最佳翻译语句。
② 贪心搜索总体运算成本也比较高,运算效率不高。
优化贪心搜索最常使用的算法是集束搜索(Beam Search)。
3.集束搜索解码
3.1 集束搜索方法

相比于贪心搜索每次都选择预测概率最大的词,集束搜索(Beam Search)会每次保留预测概率最大的\(B\)个单词(\(B\)表示取概率最大的词个数,为可调超参数)。
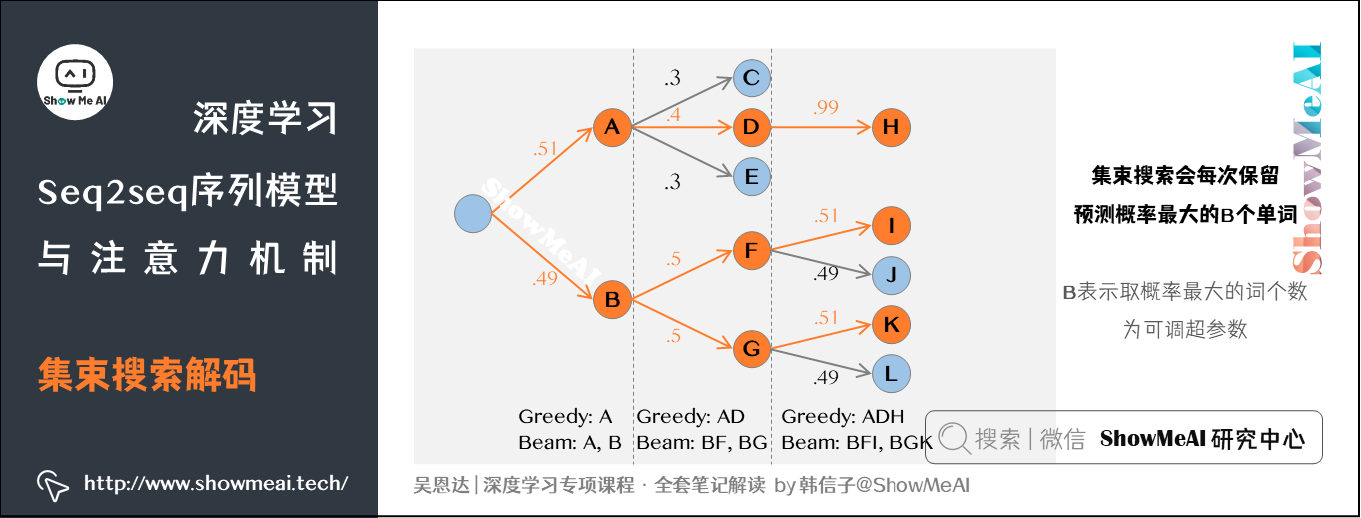
3.2 集束搜索示例
下面针对前一节的机器翻译例子,取\(B=3\)做一个展开讲解:
① 根据集束搜索,首先从词汇表中找出翻译的第1个单词概率最大的B个预测单词。对应到上例中是:in,jane,september。
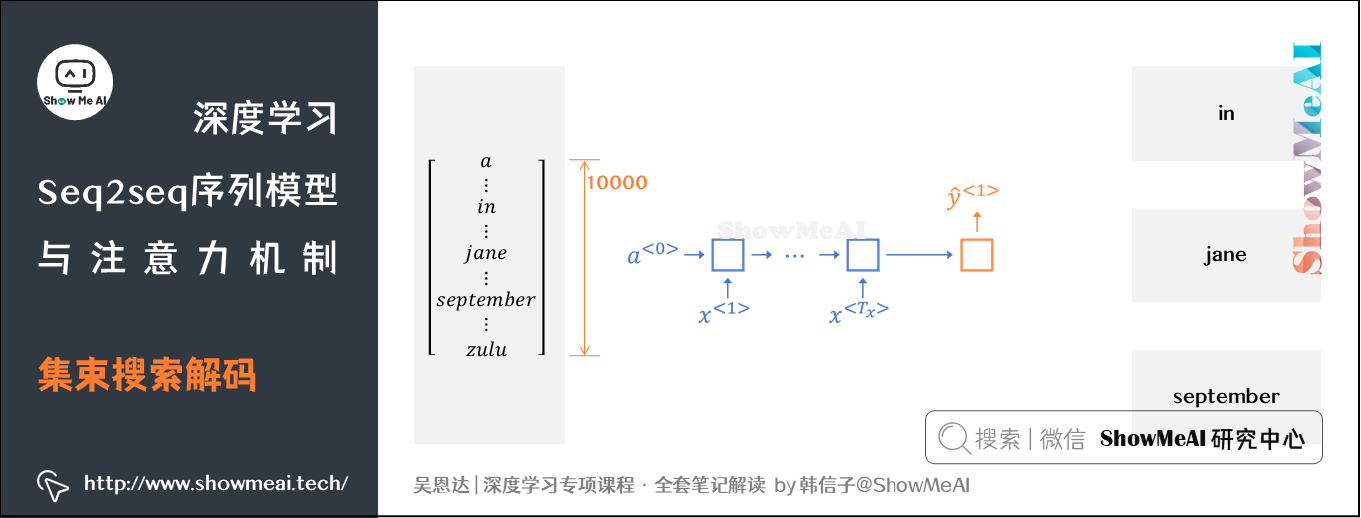
概率表示为:\(P(\hat {y}^{\left \langle 1 \right \rangle} \mid x)\)
② 再分别以in,jane,september为条件,计算每个词汇表单词作为预测第二个单词的概率。从中选择概率最大的3个作为第二个单词的预测值,得到:in september,jane is,jane visits。
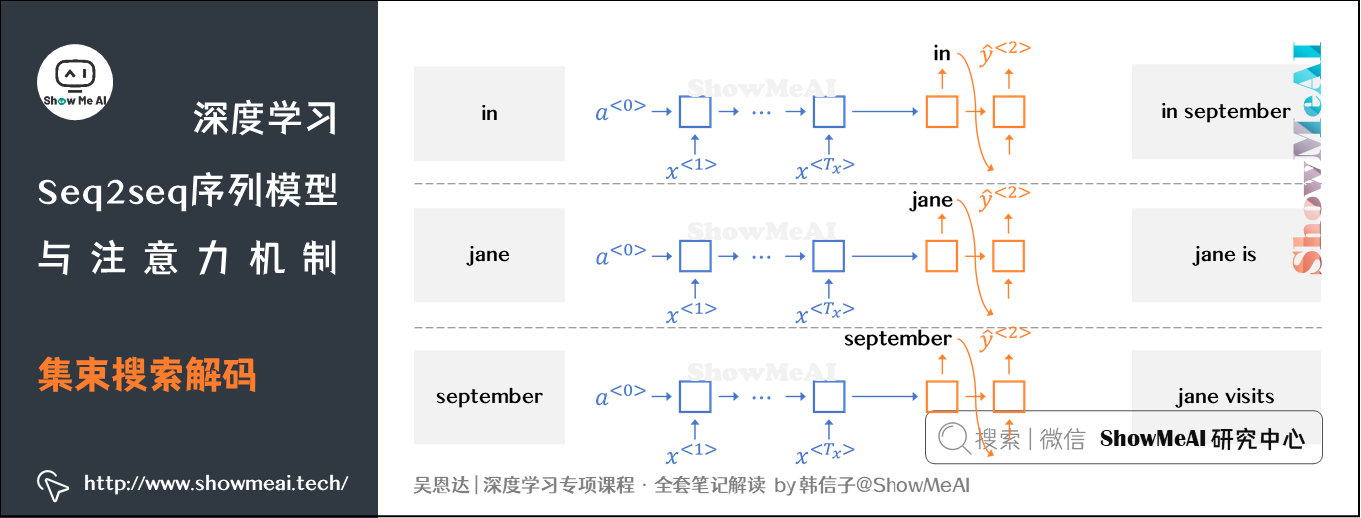
概率表示为:\(P(\hat {y}^{\left \langle 2 \right \rangle} \mid x,\hat {y}^{\left \langle 1 \right \rangle})\)。
到这时,得到的前两个单词的3种情况的概率为:
③ 用同样的方法预测第三个单词。
分别以in september,jane is,jane visits为条件,计算每个词汇表单词作为预测第三个单词的概率。从中选择概率最大的3个作为第三个单词的预测值,得到:in september jane,jane is visiting,jane visits africa。
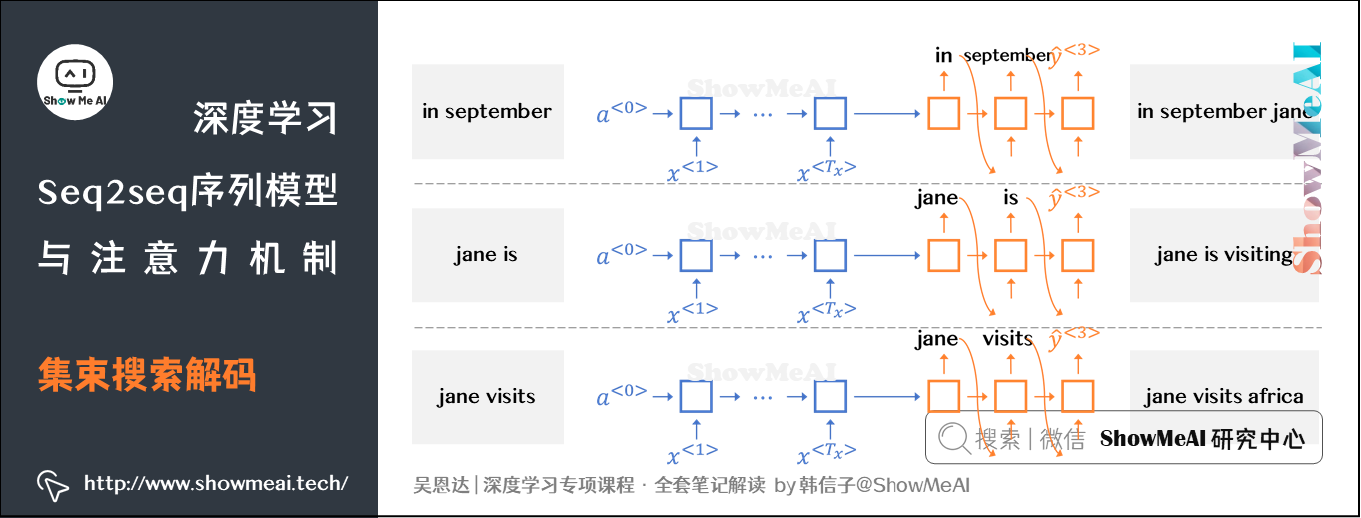
概率表示为:\(P(\hat {y}^{\left \langle 3 \right \rangle} \mid x,\hat {y}^{\left \langle 1 \right \rangle},\hat {y}^{\left \langle 2 \right \rangle})\)。
到这时,得到的前三个单词的3种情况的概率为:
④ 按照同样的方法以此类推,每次都取概率最大的三种预测。最后,选择概率最大的那一组作为最终的翻译语句。
Jane is visiting Africa in September.
特别的,如果参数\(B=1\),就等同于贪心搜索。实际应用中,根据效率要求、计算资源和准确度要求来设置\(B\)的取值。一般\(B\)越大,机器翻译越准确,但计算复杂度也会越高。
3.3 优化:长度标准化

长度标准化(Length Normalization)是对集束搜索算法的优化方式。我们观察公式
当很多个小于1的概率值相乘后,会造成数值下溢(Numerical Underflow),即得到的结果将会是一个电脑不能精确表示的极小浮点数。一种处理方法是取\(log\)值,并进行标准化:
公式中,\(T_y\)代表翻译结果的单词数量,\(\alpha\)是超参数归一化因子可调整(若\(\alpha=1\),则完全进行长度归一化;若\(\alpha=0\),则不进行长度归一化。一般令\(\alpha=0.7\))。标准化用于减少对输出长的结果的惩罚(因为翻译结果一般没有长度限制)。
前面也讨论到了:集束宽\(B\)的取值影响结果:
- 较大的\(B\)值意味着可能更好的结果和巨大的计算成本。
- 较小的\(B\)值代表较小的计算成本和可能表现较差的结果。
通常来说,\(B\)可以根据实际需求选取一个10以下的值。
与广度优先搜索和深度优先搜索等精确的查找算法相比,集束搜索算法运行速度更快,但是不能保证一定找到最准确的翻译结果。
3.4 误差分析

集束搜索是一种启发式搜索算法,有可能找不到最优的翻译结果。当Seq2Seq模型+集束搜索构建机器翻译等应用没有输出最佳结果时,我们可以通过误差分析来判断问题出现在RNN模型还是集束搜索算法中。
例如,对于下述两个由人工和算法得到的翻译结果:
\((y^\ast)\) Human:\ Jane\ visits\ Africa\ in\ September.\
\((\hat{y})\) Algorithm:\ Jane\ visited\ Africa\ last\ September.\
这个例子中,我们发现翻译结果的前三个单词差异不大,以其作为解码器前三个时间步的输入,得到第四个时间步的条件概率\(P(y^\ast \mid x)\)和\(P(\hat{y} \mid x)\),比较其大小,我们有如下的结论:
- 如果\(P(y^\ast \mid x) > P(\hat {y} \mid x)\),说明是集束搜索算法出现错误,没有选择到概率最大的词;
- 如果\(P(y^\ast \mid x) \le P(\hat {y} \mid x)\),说明是RNN模型的效果不佳,预测的第四个词为「in」的概率小于「last」。
我们可以构建表格对错误的case进行汇总分析,综合判断错误出现在RNN模型还是集束搜索算法中。

如果错误出现在集束搜索算法中,可以考虑增大集束宽\(B\);否则,需要进一步分析,看是需要正则化、更多数据或是尝试一个不同的网络结构。
4.Bleu 得分

4.1 Bleu计算方式
上述我们一直以机器翻译为例给大家做讲解,下面我们介绍一下机器翻译的评估方法,我们会用Bleu(Bilingual Evaluation Understudy)得分评估机器翻译的质量,核心思想是「机器翻译的结果越接近于人工翻译,则评分越高」。
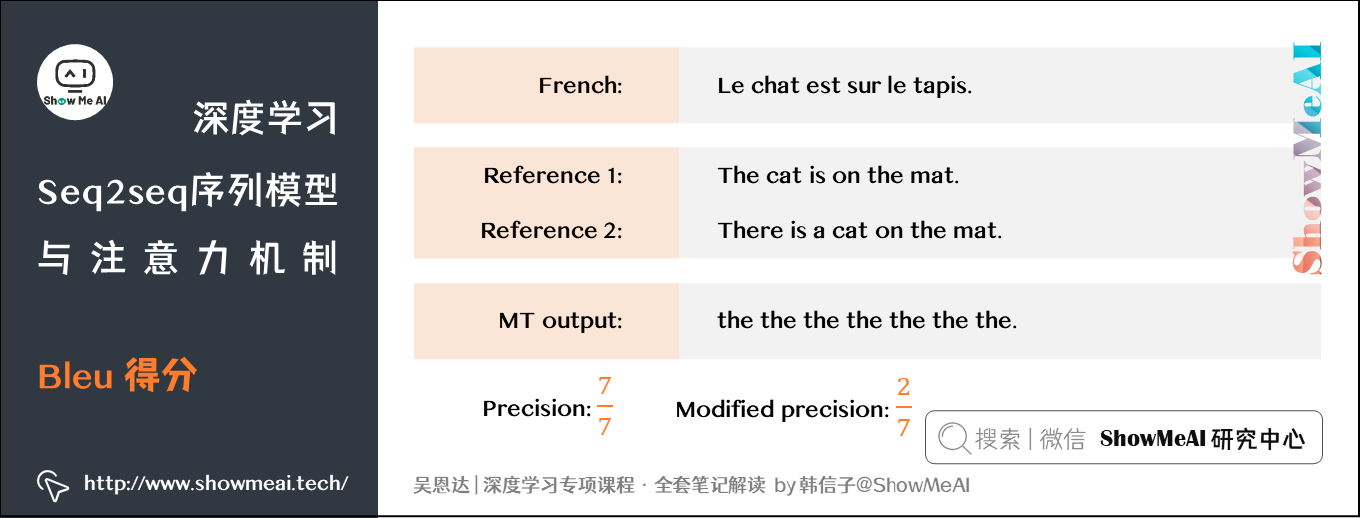
原始的Bleu计算方法将机器翻译结果中每个单词在人工翻译中出现的次数作为分子,机器翻译结果总词数作为分母,计算得到,但这种简单粗暴的方式容易出现错误。例如,机器翻译结果全部选定高频出现,又恰好在人工翻译结果中的词(比如上图的the),则按照上述方法得到的Bleu为1,显然有误。
改进的计算方法是将每个单词在人工翻译结果中出现的次数作为分子,在机器翻译结果中出现的次数作为分母。
4.2 从unigram到n-gram
上述统计,以单个词为单位的集合称为unigram(一元组)。我们可以以两两连续的词为单位统计,叫做bigram(二元组):对每个二元组,可以统计其在机器翻译结果(\(count\))和人工翻译结果(\(count_{clip}\))出现的次数,计算Bleu得分。
同样的方式,还可以统计以\(n\)个单词为单位的集合,称为n-gram(多元组),基于n-gram的Blue得分计算公式为:
对$ N \(个\)p_n$进行几何加权平均得到:
4.3 长度惩罚
Bleu存在的1个问题是:当机器翻译结果比较短时,比较容易能得到更大的精确度分值(容易理解,因为输出的大部分词可能都出现在人工翻译结果中)。
对长度问题的改进方法之一,是设置一个最佳匹配长度(Best Match Length),若机器翻译的结果短于该最佳匹配长度,则需要接受简短惩罚(Brevity Penalty,BP):
优化调整过后的Bleu得分为:
相关论文:Papineni et. al., 2002. A method for automatic evaluation of machine translation
5.注意力模型
5.1 注意力机制

回到机器翻译问题,有时候翻译的句子很长,如果对整个语句输入RNN的编码网络和解码网络进行翻译,效果会不佳。具体表现是Bleu score会随着单词数目增加而逐渐降低,如下图所示。
一种处理长句的方法是将长语句分段,每次只对其一部分进行翻译。人工翻译也是采用这样的方法,高效准确。
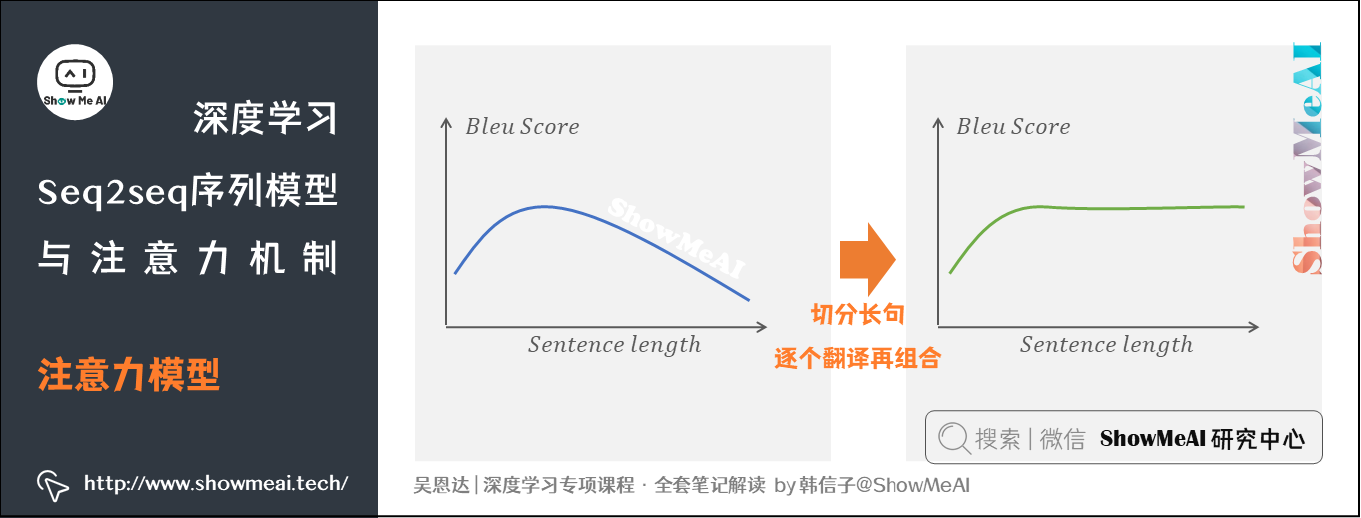
这种「局部聚焦」的思想,对应到深度学习中非常重要的注意力机制(attention mechanism)。对应的模型叫做注意力模型(attention model)。
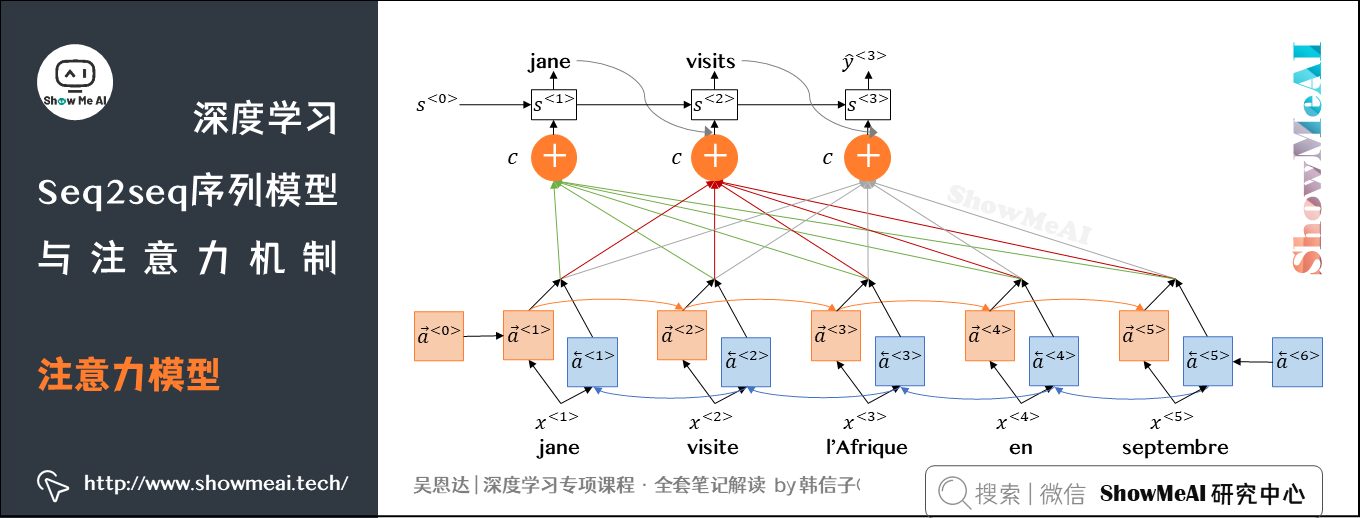
5.2 注意力模型(Attention Model)

下图为注意力模型的一个示例。模型的底层是一个双向循环神经网络(BRNN),「双向」是指的每个时间步的激活都包含前向传播和反向传播产生的激活结果:
\(a^{\langle t\prime \rangle} = ({\overrightarrow a}^{\langle t\prime \rangle}, {\overleftarrow a}^{\langle t\prime \rangle})\)
模型的顶层是一个「多对多」结构的循环神经网络,我们以第\(t\)个时间步为例,它的输入包含:
① 同级网络前一个时间步的激活\(s^{\left \langle t-1 \right \rangle}\)、输出\(y^{\left \langle t-1 \right \rangle}\)
② 底层BRNN网络多个时间步的激活 \(c\),其中\(c\)计算方式如下(注意分辨\(\alpha\)和\(a\)):\(c^{\left \langle t \right \rangle} = \sum_{\left \langle t \prime \right \rangle}\alpha^{ \left \langle t,t\prime \right \rangle }a^{\left \langle t \prime \right \rangle}\)
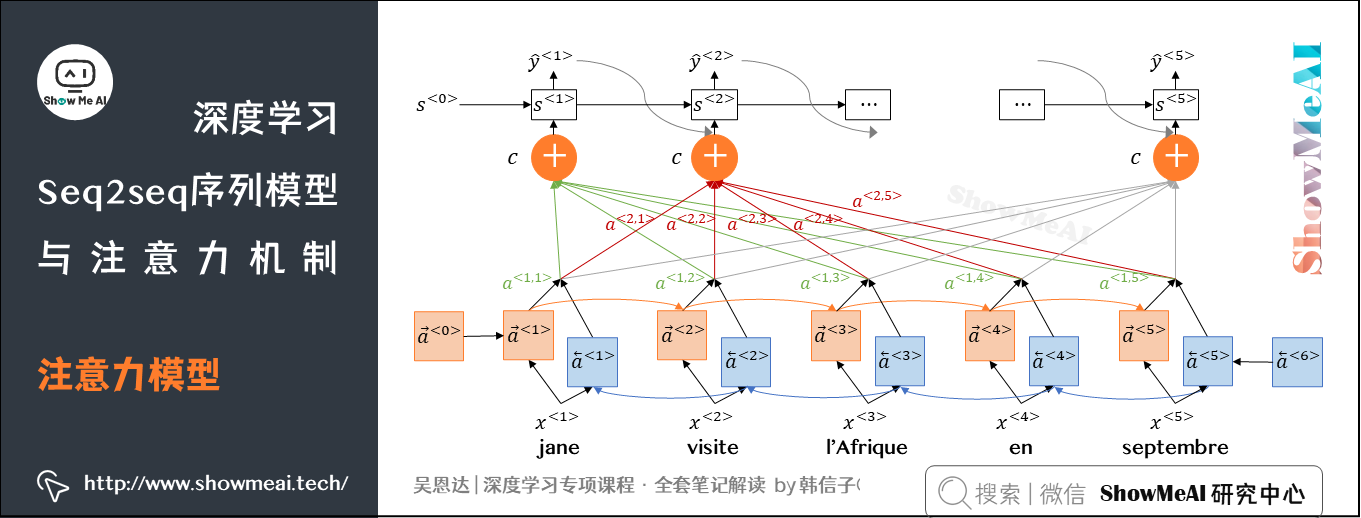
我们对上面的公式展开讲解:
① 参数\(\alpha^{\left \langle t,t\prime \right \rangle}\)代表着\(y^{\left \langle t \right \rangle}\)对\(a^{\left \langle t \prime \right \rangle}\)的「注意力」,总和为\(1\)(体现分配到不同部分的注意力比重):
- \(\alpha^{\left \langle t,t\prime \right \rangle}\)的计算是使用Bleu得到的,即:\(\alpha^{\left \langle t,t\prime \right \rangle} = \frac{exp(e^{\left \langle t,t\prime \right \rangle})}{\sum^{T_x}_{\left \langle t \prime =1 \right \rangle}exp(e^{\left \langle t,t\prime \right \rangle})}\),所以也一定能保证总和为1。
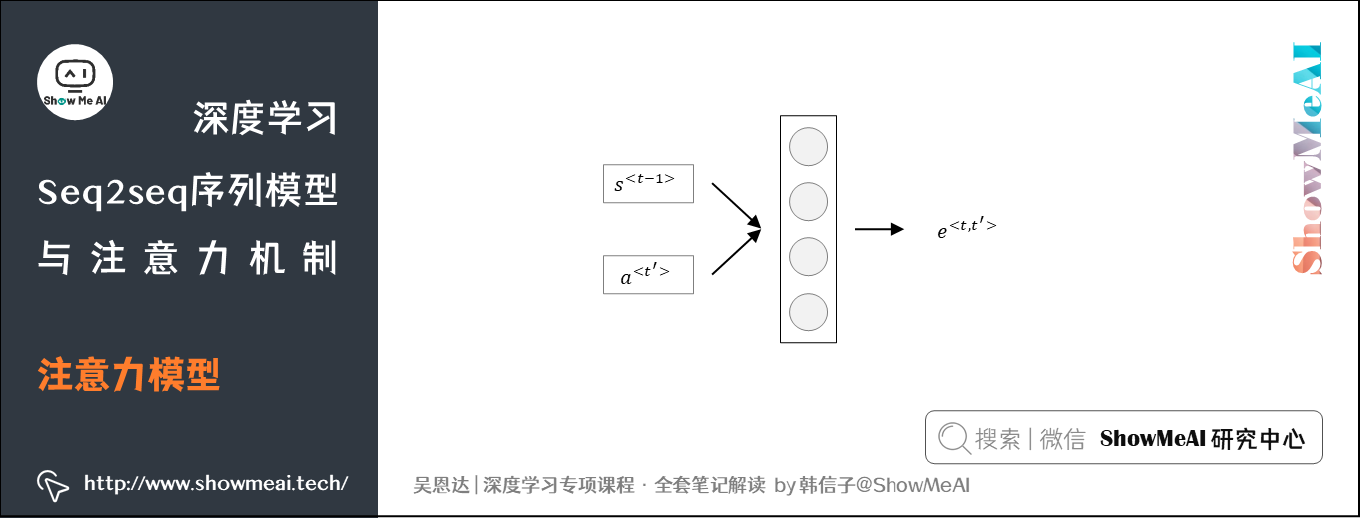
② 上式中的\(e^{\left \langle t,t\prime \right \rangle}\)是通过神经网络学习得到的。假设输入为\(s^{\left \langle t-1 \right \rangle}\)和\(a^{\left \langle t,t\prime \right \rangle}\),则可以通过下图这样一个简单的神经网络计算得到:
注意力模型在其他领域,例如图像捕捉方面也有应用。它的一个缺点是时间复杂度较高。
Attention model能有效处理很多机器翻译问题,例如下面的时间格式归一化:
July 20th 1969 → 1969-07-20
23 April, 1564 → 1564-04-23
下图将注意力权重可视化:
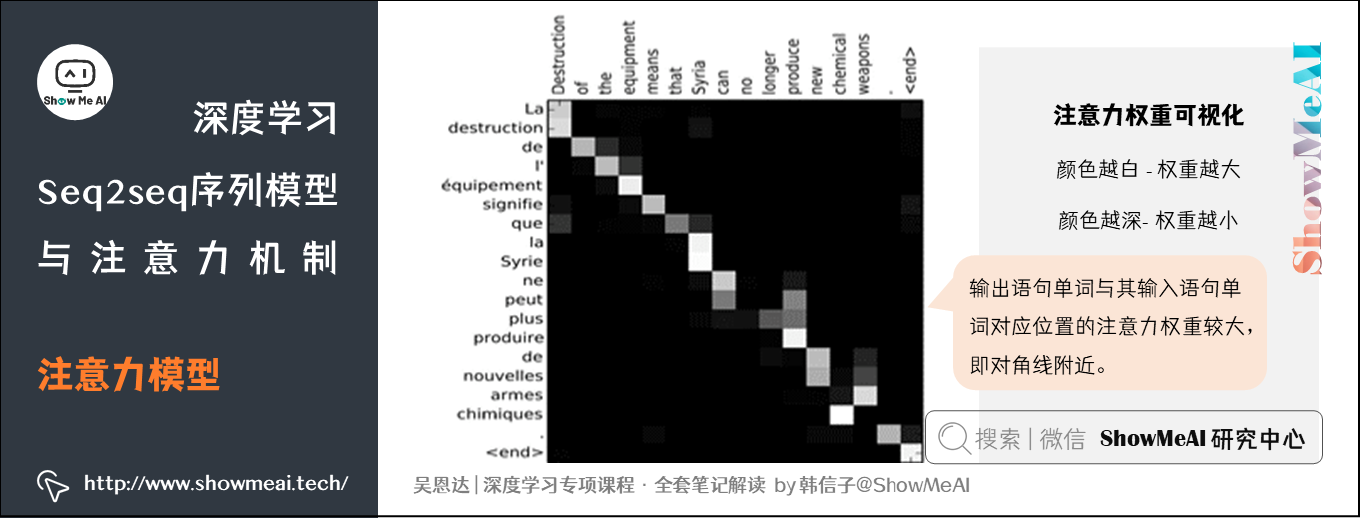
上图中,颜色越白表示注意力权重越大,颜色越深表示权重越小。可见,输出语句单词与其输入语句单词对应位置的注意力权重较大,即对角线附近。
相关论文:
Bahdanau et. al., 2014. Neural machine translation by jointly learning to align and translate
Xu et. al., 2015. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention:将注意力模型应用到图像标注中
6.语音识别

语音识别是另外一个非常典型的NLP序列问题,在语音识别任务中,输入是一段音频片段,输出是文本。我们有时会把信号转化为频域信号,也就是声谱图(spectrogram),再借助于RNN模型进行识别。
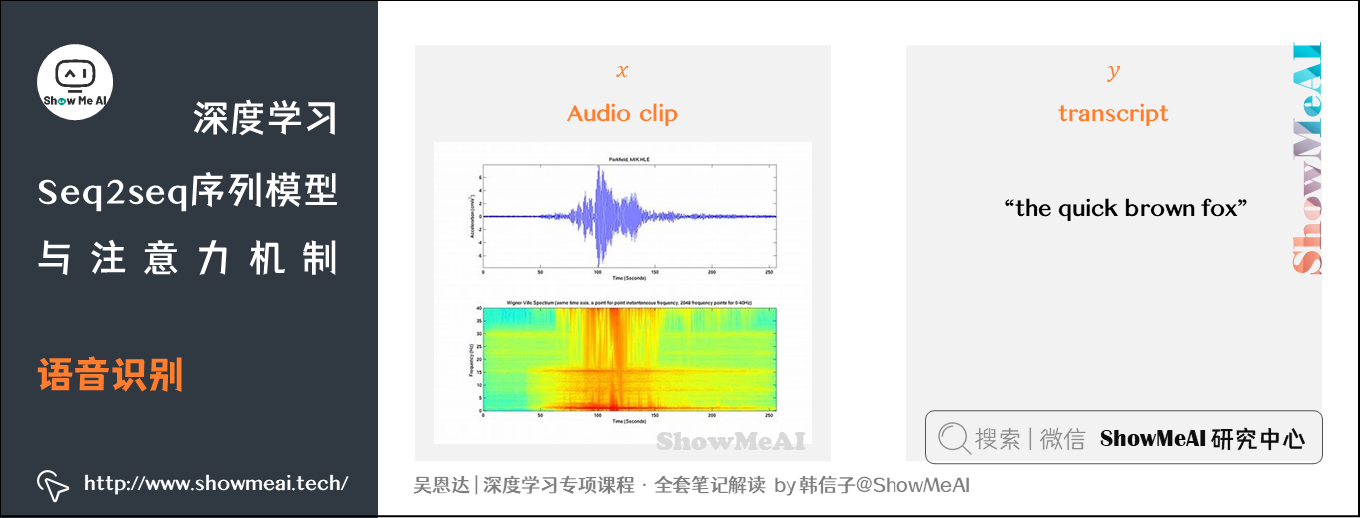
以前的语音识别系统通过语言学家人工设计的音素(Phonemes)来构建,音素指的是一种语言中能区别两个词的最小语音单位。现在的端到端系统中,用深度学习就可以实现输入音频,直接输出文本。
要使用深度学习训练可靠的语音识别系统,要依赖海量的数据。在语音识别的学术研究中,要用到长度超过3000小时的音频数据;如果是商用系统,那么超过一万小时是最基本的要求。
语音识别系统可以用注意力模型来构建,一个简单的图例如下:
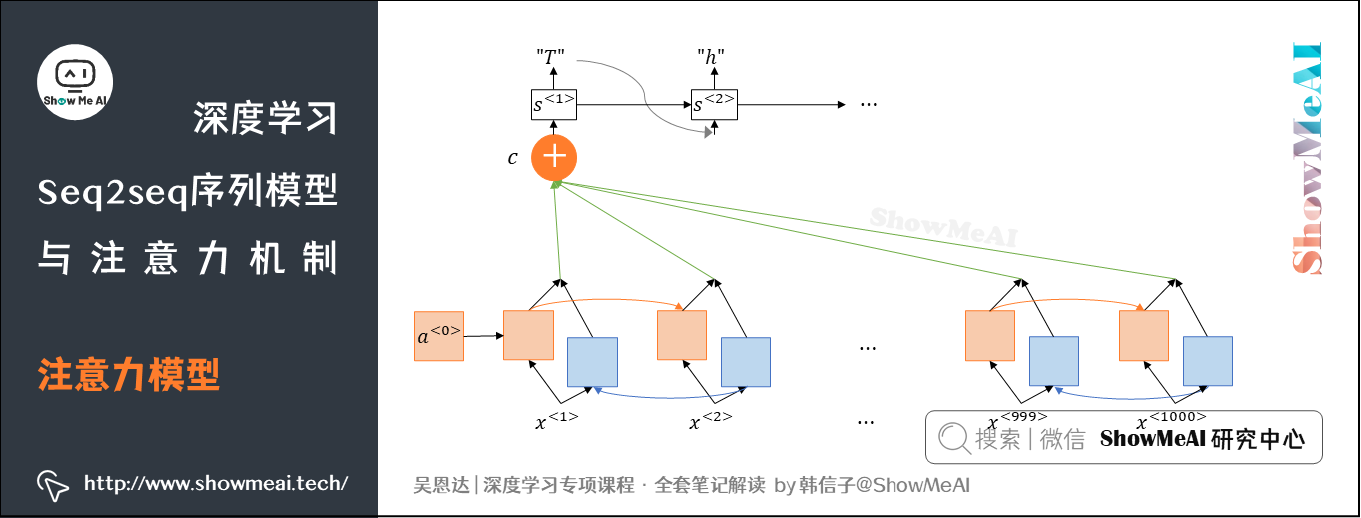
假如上例中,语音识别的输入为10s语音信号序列,采样率为100Hz,则语音长度为1000。而翻译的语句通常很短,例如「the quick brown fox」,包含19个字符。我们会发现\(T_x\)与\(T_y\)差别很大。为了让\(T_x=T_y\),可以对输出做一些处理,比如对相应字符重复,比如加入一些空白(blank),如下:
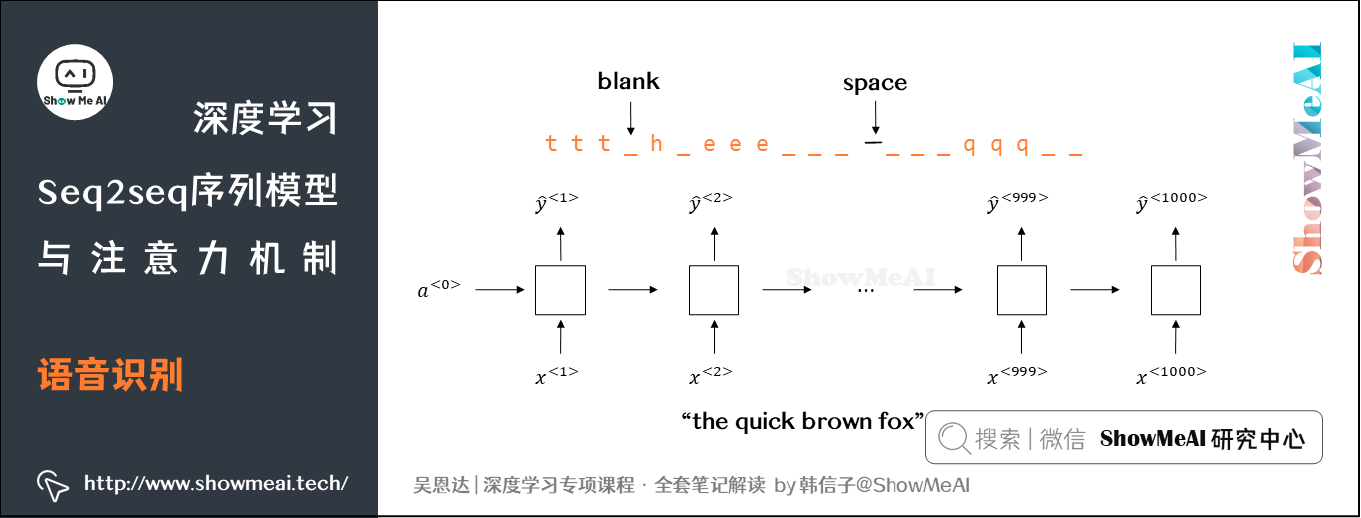
上式中,下划线 _ 表示空白,\(\sqcup\) 表示两个单词之间的空字符。这种写法的一个基本准则是没有被空白符 _ 分割的重复字符将被折叠到一起,即表示一个字符。
通过加入了重复字符和空白符、空字符,可以让输出长度也达到1000,即\(T_x=T_y\)。这种模型被称为CTC(Connectionist temporal classification):
7.触发词检测

触发词检测(Trigger Word Detection)常用于各种智能设备,通过约定的触发词可以语音唤醒设备。例如Amazon Echo的触发词是「Alexa」,小米音箱的触发词是「小爱同学」,百度DuerOS的触发词是「小度你好」,Apple Siri的触发词是「Hey Siri」。

我们可以使用RNN模型来构建触发词检测系统。如下图的输入语音中包含一些触发词。RNN检测到触发字后输出1,非触发字输出0。这样训练的RNN模型就能实现触发字检测。
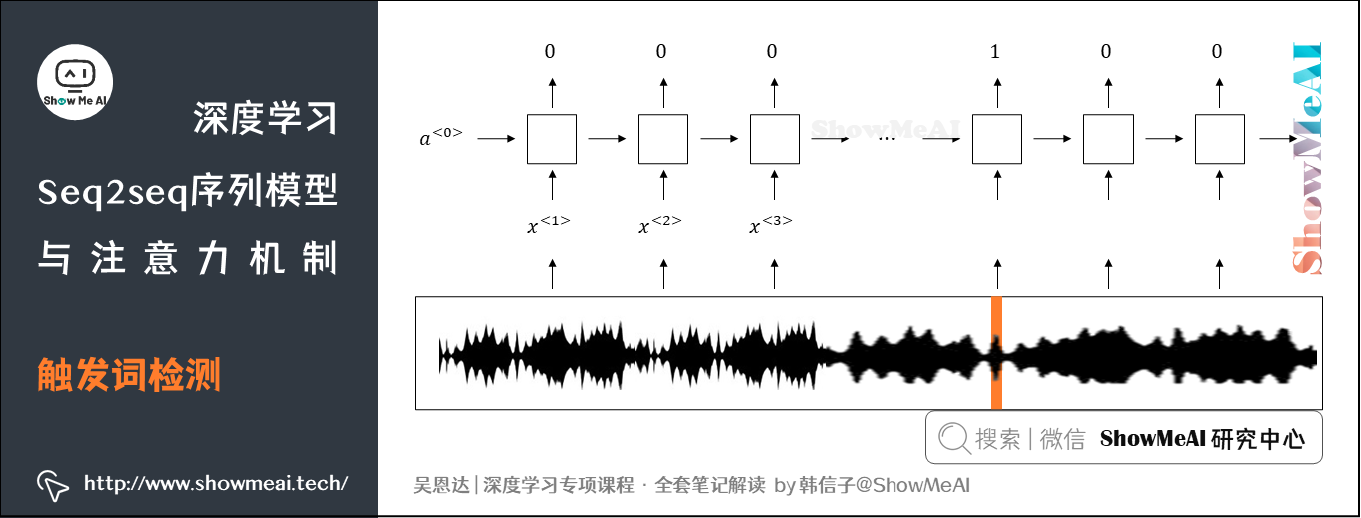
上述模型的缺点是,训练样本语音大部分片段都是非触发词,只有少数的触发词部分,即正负样本分布不均。
一种解决办法如下图所示,对触发词附近的数据处理,将附近的RNN输出都调整为1。这样简单粗暴处理后,相当于增加了正样本。
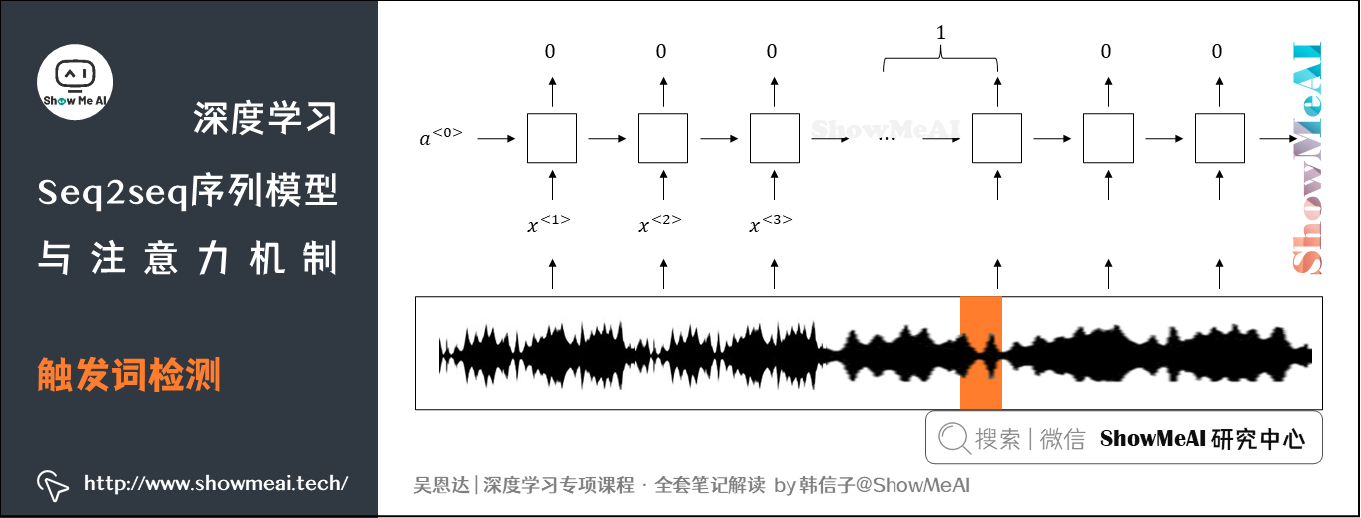
参考资料
- Sutskever et al., 2014. Sequence to sequence learning with neural networks
- Cho et al., 2014. Learning phrase representaions using RNN encoder-decoder for statistical machine translation
- Mao et. al., 2014. Deep captioning with multimodal recurrent neural networks
- Vinyals et. al., 2014. Show and tell: Neural image caption generator
- Karpathy and Fei Fei, 2015. Deep visual-semantic alignments for generating image descriptions
- Papineni et. al., 2002. A method for automatic evaluation of machine translation
- Bahdanau et. al., 2014. Neural machine translation by jointly learning to align and translate
- Xu et. al., 2015. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- Graves et al., 2006. Connectionist Temporal Classification: Labeling unsegmented sequence data with recurrent neural networks
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
推荐文章
- 深度学习教程 | 深度学习概论
- 深度学习教程 | 神经网络基础
- 深度学习教程 | 浅层神经网络
- 深度学习教程 | 深层神经网络
- 深度学习教程 | 深度学习的实用层面
- 深度学习教程 | 神经网络优化算法
- 深度学习教程 | 网络优化:超参数调优、正则化、批归一化和程序框架
- 深度学习教程 | AI应用实践策略(上)
- 深度学习教程 | AI应用实践策略(下)
- 深度学习教程 | 卷积神经网络解读
- 深度学习教程 | 经典CNN网络实例详解
- 深度学习教程 | CNN应用:目标检测
- 深度学习教程 | CNN应用:人脸识别和神经风格转换
- 深度学习教程 | 序列模型与RNN网络
- 深度学习教程 | 自然语言处理与词嵌入
- 深度学习教程 | Seq2seq序列模型和注意力机制

