

深度学习教程 | 经典CNN网络实例详解
 本节展开介绍典型的CNN结构(LeNet-5、AlexNet、VGG),以及 ResNet(Residual Network,残差网络),Inception Neural Network,1x1卷积,迁移学习,数据扩增和手工工程与计算机现状等知识点
本节展开介绍典型的CNN结构(LeNet-5、AlexNet、VGG),以及 ResNet(Residual Network,残差网络),Inception Neural Network,1x1卷积,迁移学习,数据扩增和手工工程与计算机现状等知识点

- 作者:韩信子@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/35
- 本文地址:https://www.showmeai.tech/article-detail/222
- 声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容

本系列为吴恩达老师《深度学习专项课程(Deep Learning Specialization)》学习与总结整理所得,对应的课程视频可以在这里查看。
引言
在ShowMeAI前一篇文章 卷积神经网络解读 中我们对以下内容进行了介绍:
- 卷积计算、填充
- 卷积神经网络单层结构
- 池化层结构
- 卷积神经网络典型结构
- CNN特点与优势
本篇内容ShowMeAI展开介绍和总结几个有名的典型CNN案例。这些CNN是最典型和有效的结构,吴恩达老师希望通过对具体CNN模型案例的分析讲解,帮助我们理解CNN并训练实际的模型。

本篇涉及到的经典CNN模型包括:
- LeNet-5
- AlexNet
- VGG
- ResNet(Residual Network,残差网络)
- Inception Neural Network
1.经典卷积网络

1.1 LeNet-5
手写字体识别模型LeNet5由Yann LeCun教授于90年代提出来,是最早的卷积神经网络之一。它是第一个成功应用于数字识别问题的卷积神经网络。在MNIST数据中,它的准确率达到大约99.2%。
LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。
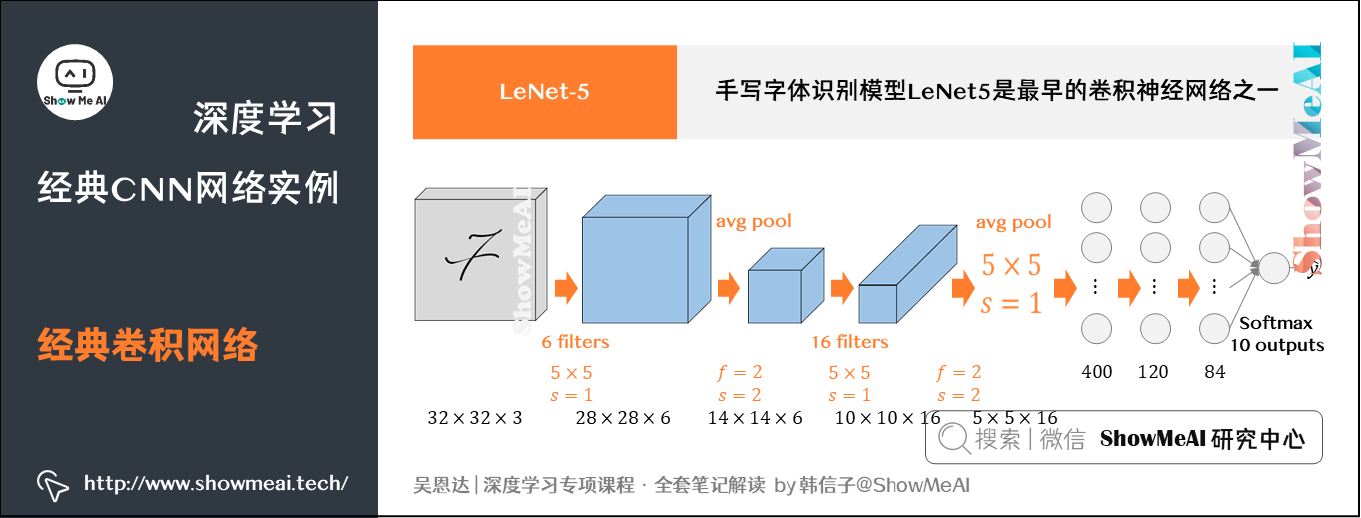
-
LeNet-5针对灰度图像而训练,因此输入图片维度为(注意其中通道数为1)。
-
该模型总共包含了约6万个参数,远少于标准神经网络所需。
-
典型的LeNet-5结构包含卷积层(CONV layer),池化层(POOL layer)和全连接层(FC layer),排列顺序一般为CONV layer POOL layer CONV layer POOL layer FC layer FC layer OUTPUT layer。一个或多个卷积层后面跟着一个池化层的模式至今仍十分常用。
-
当LeNet-5模型被提出时,其池化层使用的是平均池化,而且各层激活函数一般选用Sigmoid和tanh。现在我们更多的会使用最大池化并选用ReLU作为激活函数。
相关论文:LeCun et.al., 1998. Gradient-based learning applied to document recognition。吴恩达老师建议精读第二段,泛读第三段。
1.2 AlexNet
AlexNet由Alex Krizhevsky于2012年提出,夺得2012年ILSVRC比赛的冠军,top5预测的错误率为16.4%,远超第一名。
AlexNet采用8层的神经网络,5个卷积层和3个全连接层(3个卷积层后面加了最大池化层),包含6亿3000万个链接,6000万个参数和65万个神经元。具体的网络结构如下图:


模型结构解析:
- 卷积层 (最大)池化层 全连接层的结构。
- AlexNet模型与LeNet-5模型类似,但是更复杂,包含约6000万个参数。另外,AlexNet模型使用了ReLU函数。
- 当用于训练图像和数据集时,AlexNet能够处理非常相似的基本构造模块,这些模块往往包含大量的隐藏单元或数据。
相关论文:Krizhevsky et al.,2012. ImageNet classification with deep convolutional neural networks。这是一篇易于理解并且影响巨大的论文,计算机视觉群体自此开始重视深度学习。
1.3 VGG
VGG是Oxford的Visual Geometry Group的组提出的CNN神经网络。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。在提出后的几年内,大家广泛应用其作为典型CNN结构。
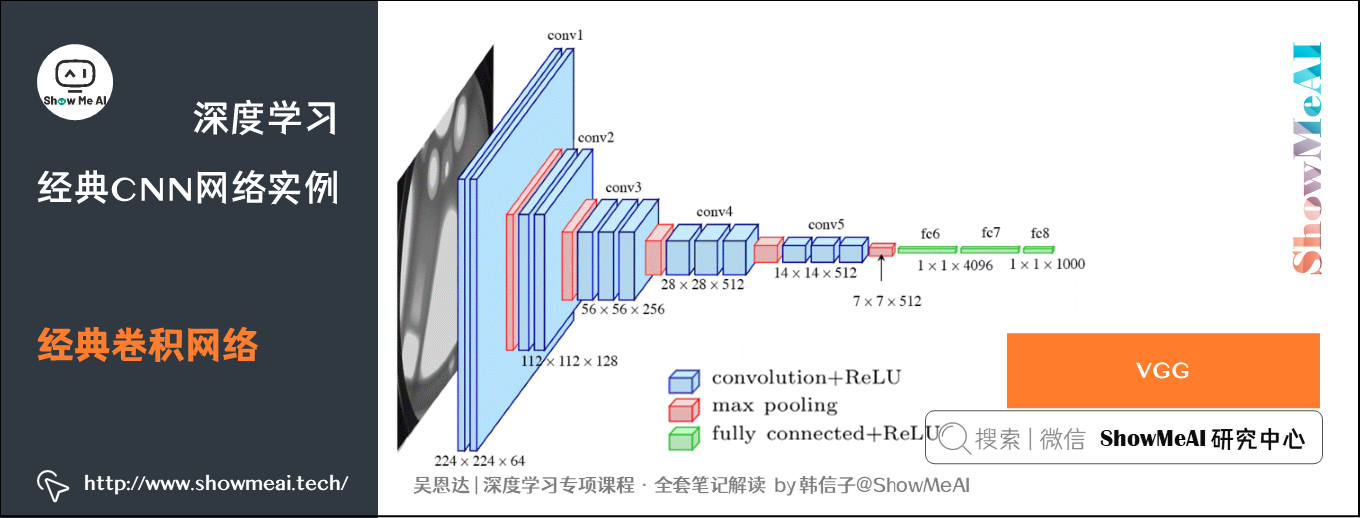

- VGG又称VGG-16网络,「16」指网络中包含16个卷积层和全连接层。
- 超参数较少,只需要专注于构建卷积层。
- 结构不复杂且规整,在每一组卷积层进行滤波器翻倍操作。
- VGG需要训练的特征数量巨大,包含多达约1.38亿个参数。
相关论文:Simonvan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition。
2.残差网络 ResNets

2.1 Residual Network结构
上面提到的VGG网络在当时已经是堆叠层次构建CNN比较极限的深度了,随着神经网络层数变多和网络变深,会带来严重的梯度消失和梯度爆炸问题(参考ShowMeAI文章 深度学习的实用层面 关于梯度消失和梯度爆炸的讲解),整个模型难以训练成功。
在网络结构层面,一种解决方法是人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为Residual Networks(ResNets)残差网络。

上图的结构被称为残差块(Residual block)。通过捷径(Short cut,或者称跳接/Skip connections)可以将添加到第二个ReLU过程中,直接建立与之间的隔层联系。表达式如下:
构建一个残差网络就是将许多残差块堆积在一起,形成一个深度网络。
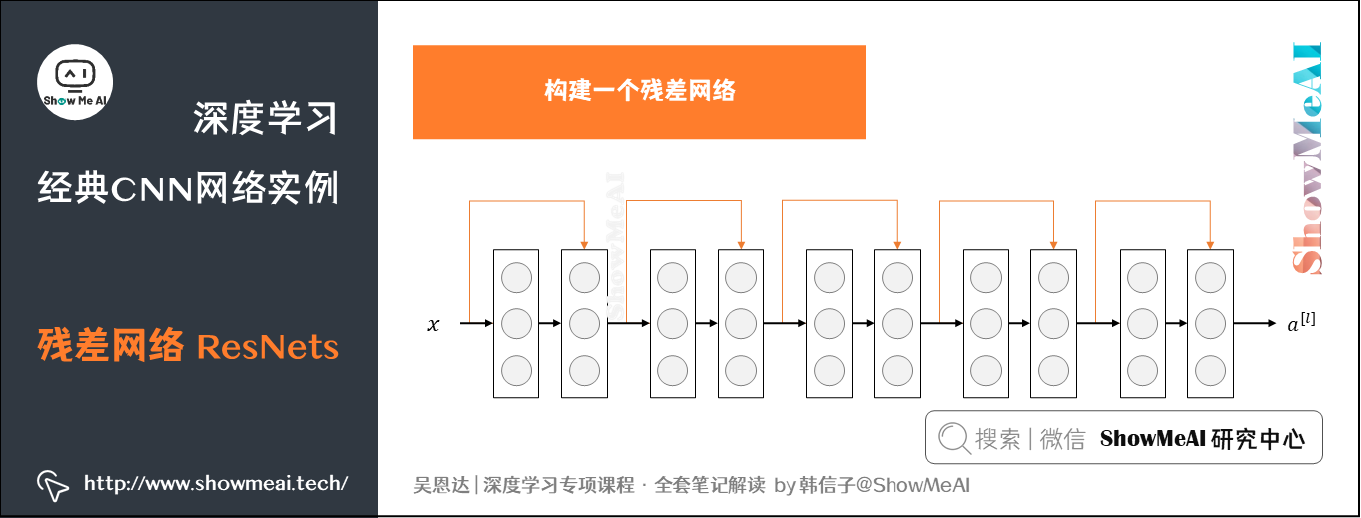
为了便于区分,在 ResNets 的论文 He et al., 2015. Deep residual networks for image recognition 中,非残差网络被称为普通直连网络(Plain Network)。将它变为残差网络的方法是加上所有的跳远连接。
理论上,随着网络深度的增加,模型学习能力变强,效果应该提升。但实际上,如下图所示,一个普通直连网络,随着神经网络层数增加,训练错误会先先减少后增多。但使用跳接的残差网络,随着网络变深,训练集误差持续呈现下降趋势。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aNBHgLIA-1649925808194)(http://image.showmeai.tech/deep_learning_tutorial/186.png)]
残差网络有助于解决梯度消失和梯度爆炸问题,使得在训练更深的网络的同时,又能保证良好的性能。
2.2 残差网络有效的原因

下面我们借助1个例子来解释为什么ResNets有效,为什么它能支撑训练更深的神经网络。
如图所示,假设输入经过很多层神经网络(上图的big NN)后输出,经过一个Residual block输出。的表达式如下:
输入经过Big NN后,若,,则有:

上述计算公式表明,即使发生了梯度消失,,也能直接建立与的线性关系(此时,就是identity function)。
直接连到,从效果来说,相当于直接忽略了之后的这两层神经层。很深的神经网络,由于许多Residual blocks的存在,弱化削减了某些神经层之间的联系,实现隔层线性传递,而不是一味追求非线性关系,模型本身也就能「容忍」更深层的神经网络了。而且从性能上来说,这两层额外的Residual blocks也不会降低Big NN的性能。
当然,没有发生梯度消失时,Residual blocks会忽略short cut,能训练得到跟Plain Network起到同样效果的非线性关系。
注意,如果Residual blocks中和的维度不同,通常可以引入矩阵,与相乘,使得的维度与一致。参数矩阵有来两种方法得到:
- ① 将作为学习参数,通过模型训练得到
- ② 固定值(类似单位矩阵),不需要训练,与的乘积仅仅使得截断或者补零
上述两种方法都可行。
下图所示的是CNN中ResNets的结构对比普通直连网络和VGG19:
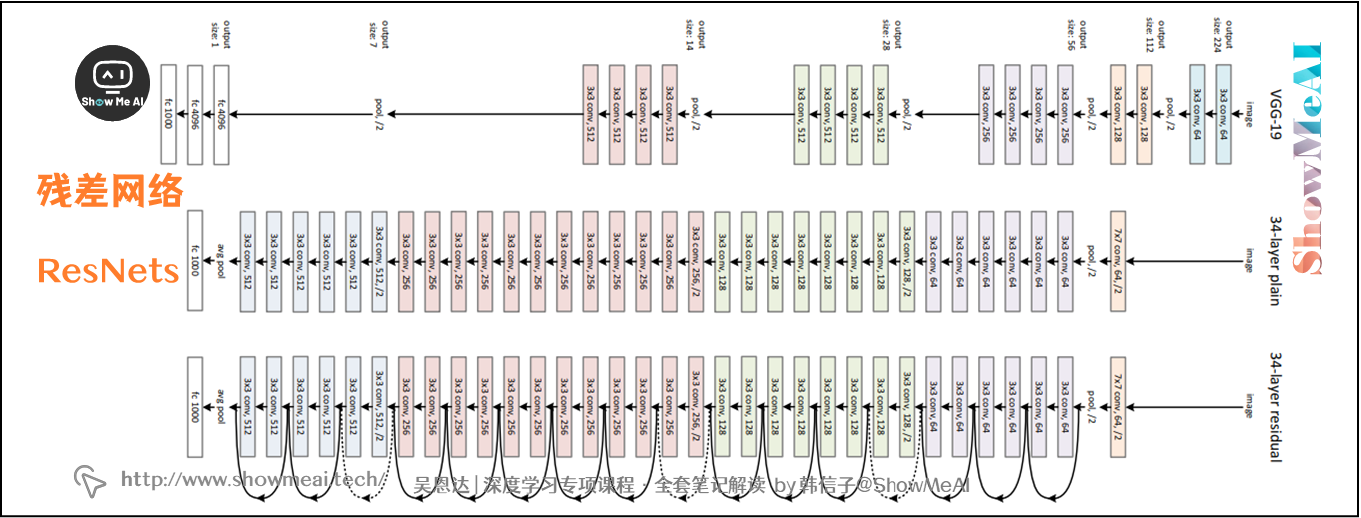
3.1x1卷积

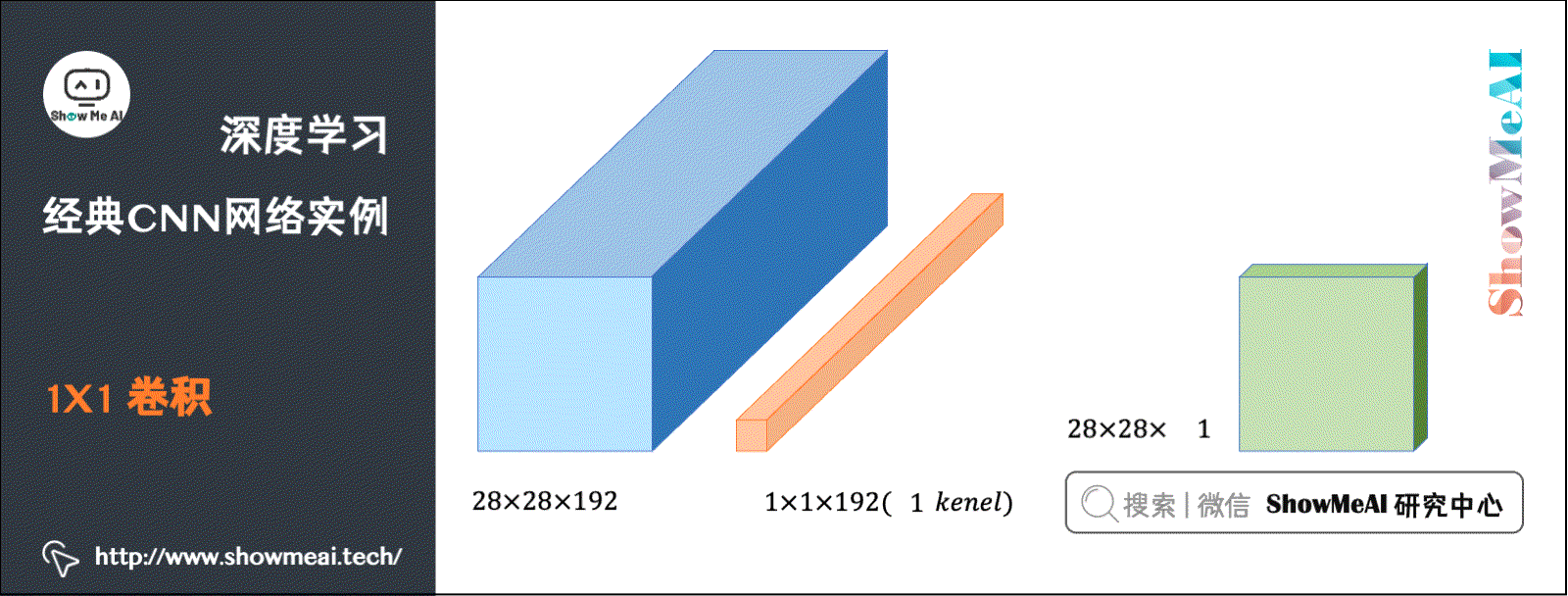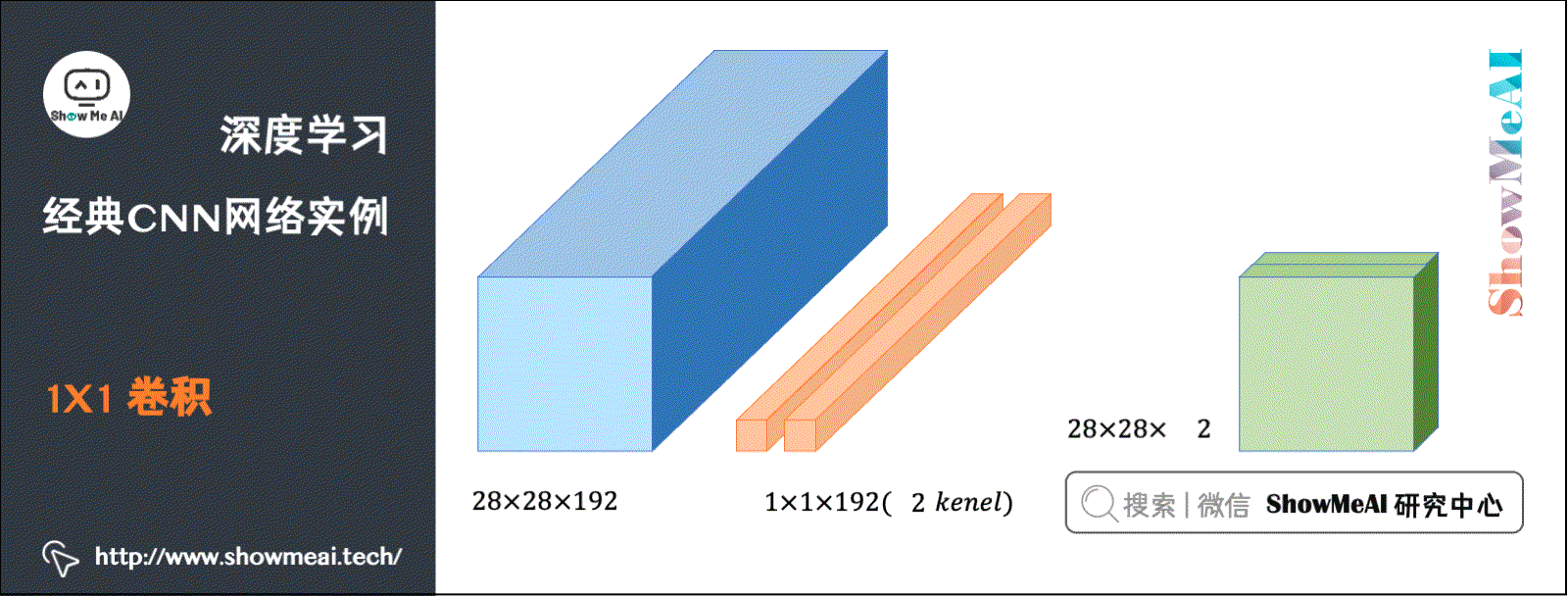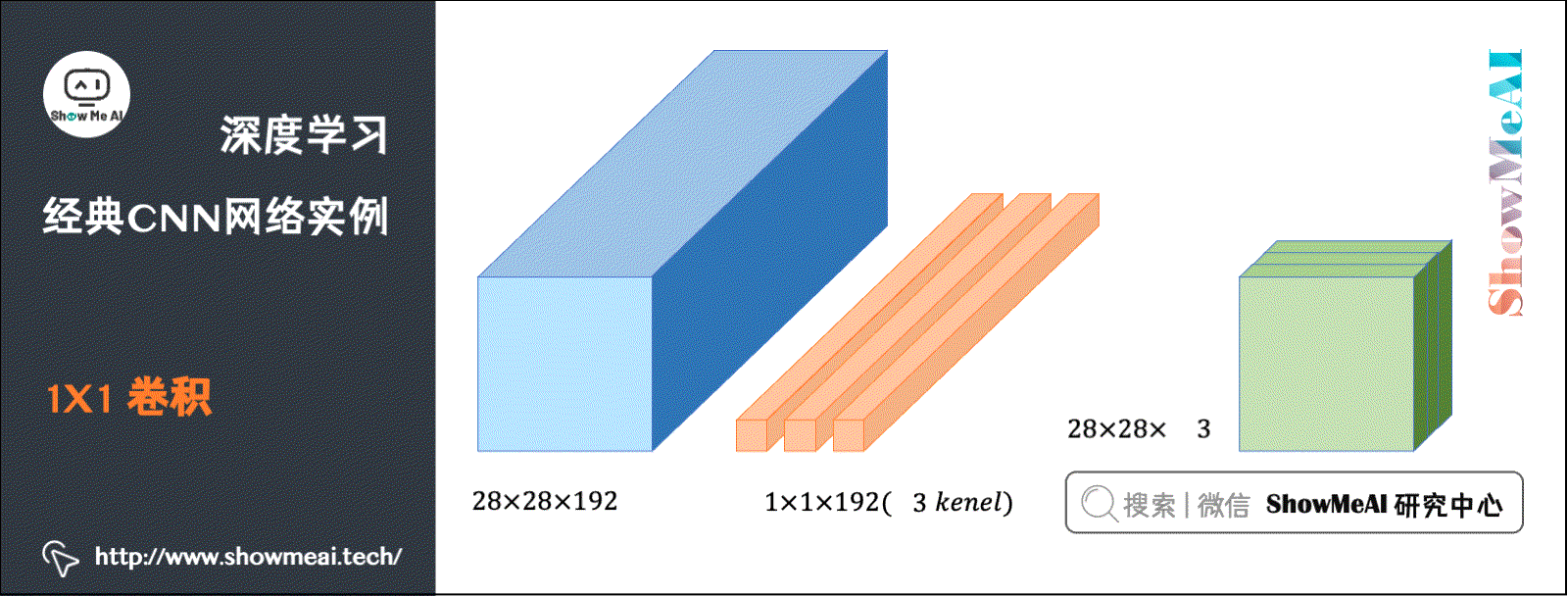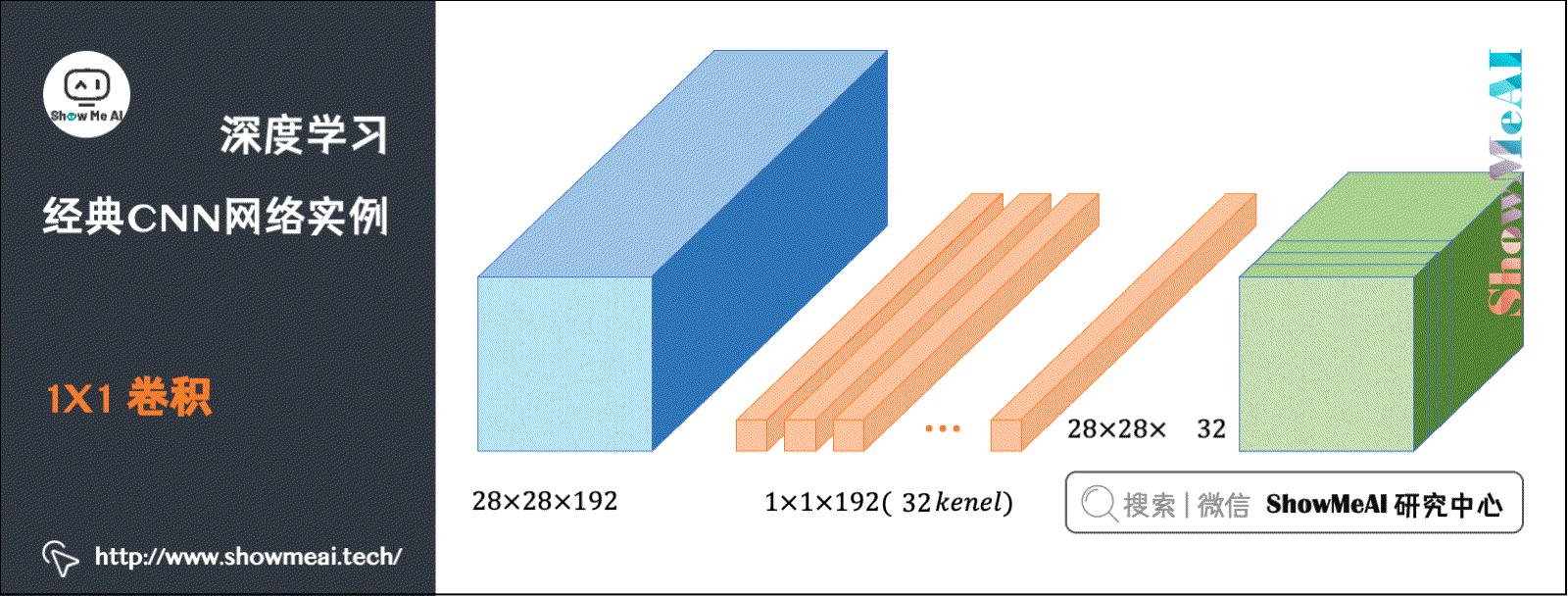
在CNN中有一种现在广泛使用的CNN结构:Convolution(卷积,也称Networks in Networks)。它指滤波器的尺寸为1。当通道数为1时,卷积意味着卷积操作等同于乘积操作。

而当通道数更多时,卷积的作用实际上类似全连接层的神经网络结构,从而对数据进行升降维度(取决于滤波器个数)。
池化能压缩数据的高度()及宽度(),而卷积能压缩数据的通道数()。在如下图所示的例子中,用32个大小为的滤波器进行卷积,就能使原先数据包含的192个通道压缩为32个。如下动图演示了卷积的计算:
4.Inception网络

下面介绍一下Inception网络,它是CNN分类器发展史上一个重要的里程碑。
在Google提出Inception之前,大部分流行CNN仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。
大家观察我们之前介绍到的CNN典型结构,都是只选择单一尺寸和类型的滤波器。而Inception网络的作用即是代替人工来确定卷积层中的滤波器尺寸与类型,或者确定是否需要创建卷积层或池化层。
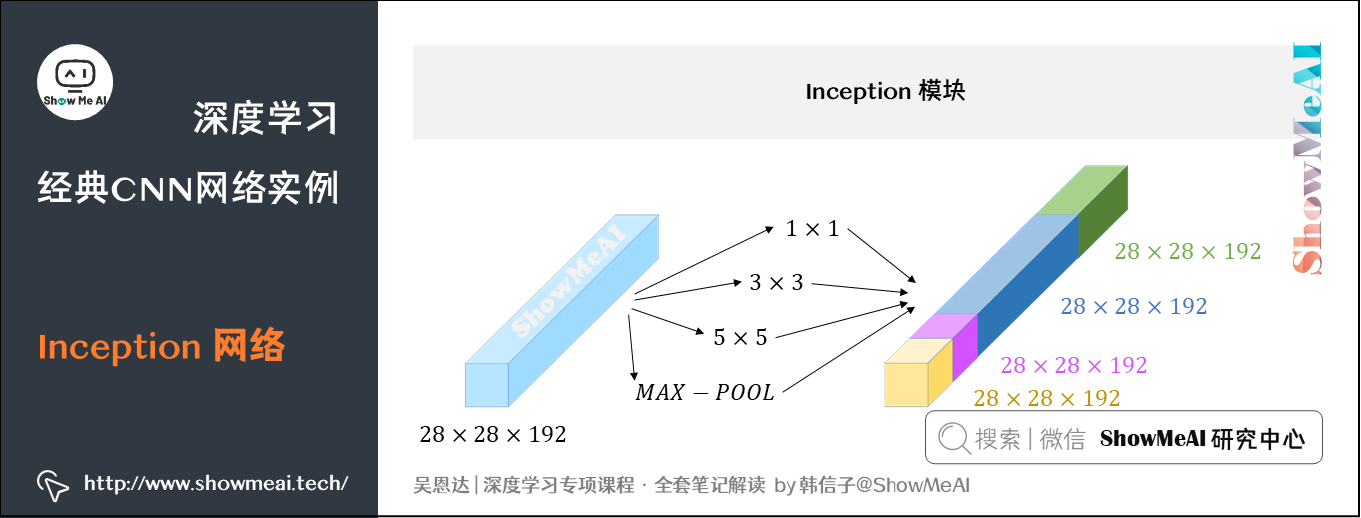
如上图所示,Inception网络选用不同尺寸的滤波器进行Same 卷积,并将卷积和池化得到的输出组合拼接起来,最终让网络自己去学习需要的参数和采用的滤波器组合。
4.1 计算成本问题
在提升性能的同时,Inception网络有着较大的计算成本。如下图的例子:

图中有个滤波器,每个滤波器的大小为。输出大小为,总共需要计算得到个结果数,对于每个数,要执行次乘法运算。加法运算次数与乘法运算次数近似相等。因此,这一层的计算量可以近似为亿。
Inception引入了卷积来减少计算量问题:

如上图所示,我们先使用卷积把输入数据从192个通道减少到16个通道,再对这个较小层运行卷积,得到最终输出。这种改进方式的计算量为千万,减少了约90%。
这里的的卷积层通常被称作瓶颈层(Bottleneck layer)。借助在网络中合理设计瓶颈层,可以在保持网络性能的前提下显著缩小计算规模。
4.2 完整的Inception网络

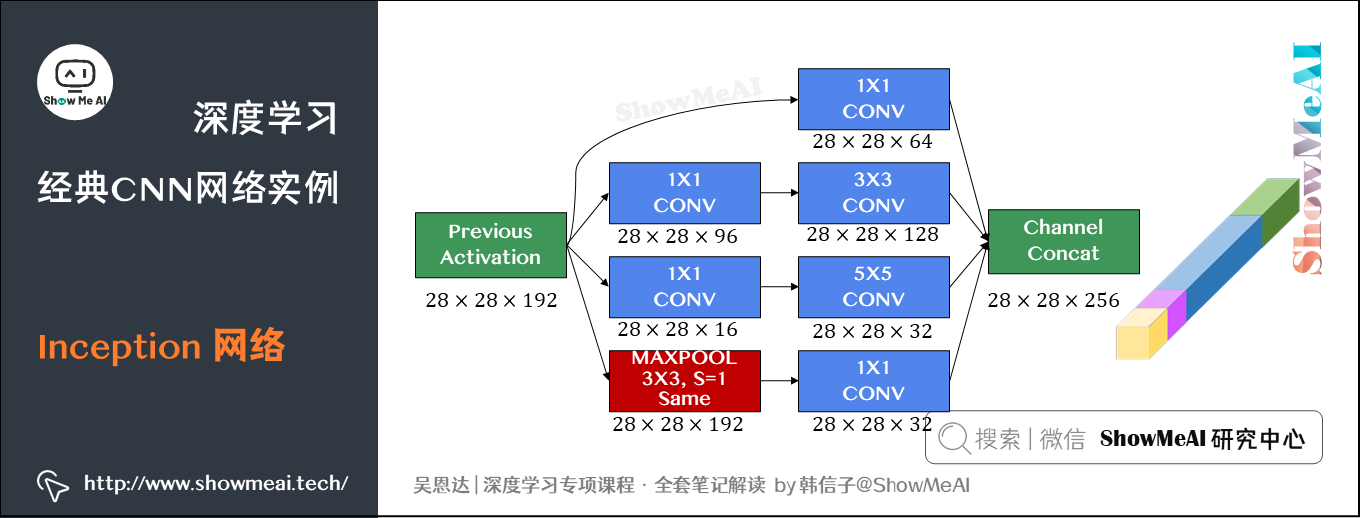
引入卷积后的Inception模块如上所示。注意,为了将所有的输出组合起来,红色的池化层使用Same类型的填充(padding)来池化使得输出的宽高不变,通道数也不变。
多个Inception模块组成一个完整的Inception网络(被称为GoogLeNet,以向LeNet致敬),如下图所示:
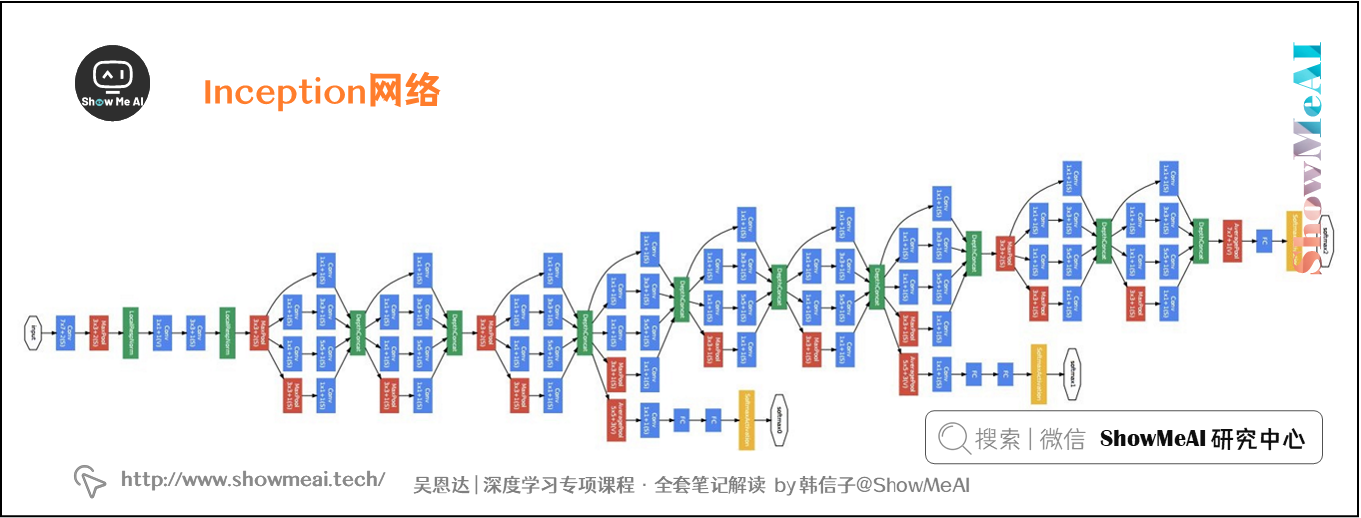
注意,在上图中,Inception网络除了有许多Inception模块(图上红框框出)之外,网络中间隐藏层也可以作为输出层Softmax(图中黑色圈圈出),有利于防止发生过拟合。
经过研究者们的不断发展,Inception模型的V2、V3、V4以及引入残差网络的版本被提出,这些变体都基于Inception V1版本的基础思想上。
5.使用开源的实现方案

很多神经网络结构复杂,且有很多细致的设计和调整,训练过程也包含非常多tricks,很难仅通过阅读论文来重现他人的成果。想要搭建一个同样的神经网络,查看开源的实现方案会快很多。
6.迁移学习

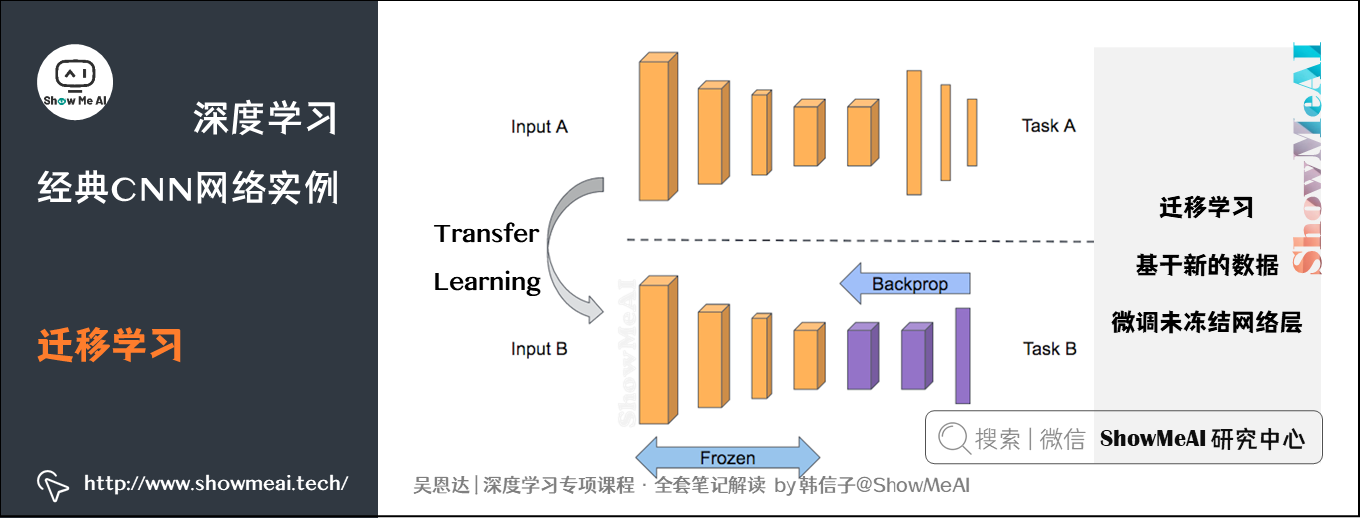
在ShowMeAI的前序文章 AI应用实践策略(下) 中我们提到过迁移学习。计算机视觉是一个经常用到迁移学习的领域。在搭建计算机视觉的应用时,相比于从头训练权重,下载别人已经训练好的网络结构的权重,用其做预训练模型,然后转换到自己感兴趣的任务上,有助于加速开发。
对于类似前面提到的VGG/ResNet/Inception等训练好的卷积神经网络,可以冻结住所有层,只训练针对当前任务添加的Softmax分类层参数即可。大多数深度学习框架都允许用户指定是否训练特定层的权重。
冻结的层由于不需要改变和训练,可以看作一个固定函数。可以将这个固定函数存入硬盘,以便后续使用,而不必每次再使用训练集进行训练了。
吴恩达老师指出,上述的做法适用于小数据集场景,如果你有一个更大的数据集,应该冻结更少的层,然后训练后面的层。越多的数据意味着冻结越少的层,训练更多的层。如果有一个极大的数据集,你可以将开源的网络和它的权重整个当作初始化(代替随机初始化),然后训练整个网络。
7.数据扩增

计算机视觉领域的应用都需要大量的数据。当数据不够时,数据扩增(Data Augmentation)可以帮助我们构建更多的数据样本。
常用的数据扩增包括镜像翻转、随机裁剪、色彩转换等。如下图为镜像和随机裁剪得到新的图片。

色彩转换是对图片的RGB通道数值进行随意增加或者减少,改变图片色调。另外,PCA颜色增强指更有针对性地对图片的RGB通道进行主成分分析(Principles Components Analysis,PCA),对主要的通道颜色进行增加或减少,可以采用高斯扰动做法来增加有效的样本数量。具体的PCA颜色增强做法可以查阅AlexNet的相关论文或者开源代码。
下图为使用color shifting色调转换进行data augmentation的示例。

在构建大型神经网络的时候,为了提升效率,我们可以使用两个或多个不同的线程并行来实现数据扩增和模型训练。
8.计算机视觉现状

深度学习需要大量数据,不同的神经网络模型所需的数据量是不同的。目标检测、图像识别、语音识别所需的数据量依次增加。一般来说,如果数据较少,那么就需要对已有数据做更多的手工工程(hand-engineering),比如上一节介绍的数据扩增操作。模型算法也需要特别设计,会相对要复杂一些。
如果数据很多,可以构建深层神经网络,不需要太多的手工工程,模型算法也就相对简单一些。
手工工程(Hand-engineering,又称hacks)指精心设计的特性、网络体系结构或是系统的其他组件。手工工程是一项非常重要也比较困难的工作。在数据量不多的情况下,手工工程是获得良好表现的最佳方式。正因为数据量不能满足需要,历史上计算机视觉领域更多地依赖于手工工程。近几年数据量急剧增加,因此手工工程量大幅减少。
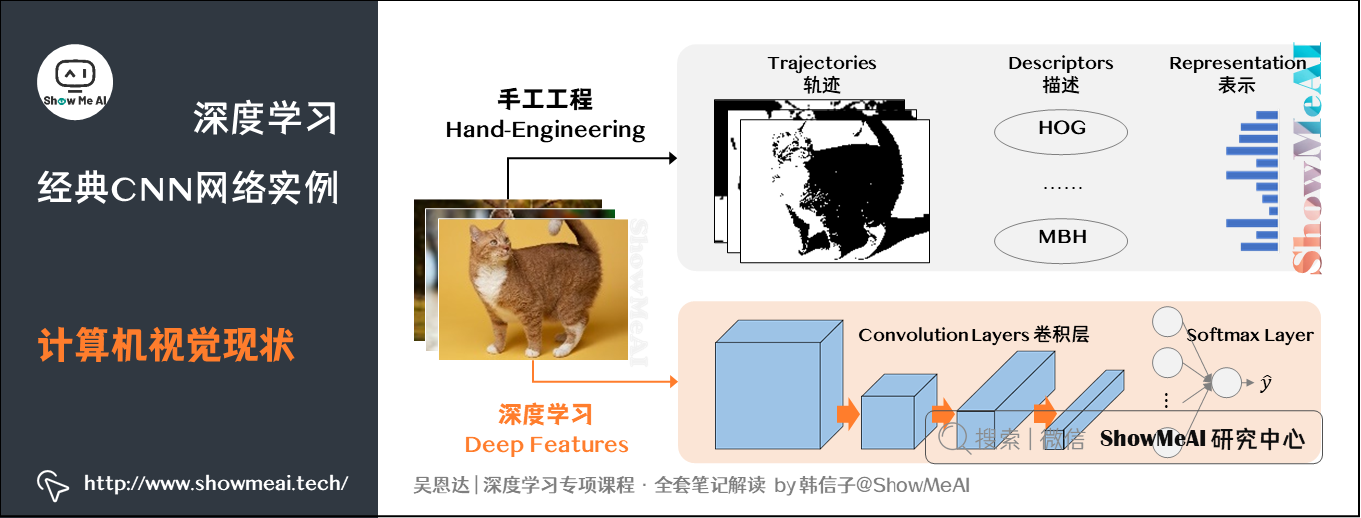
除此之外,在模型研究或者竞赛方面,有一些方法能够有助于提升神经网络模型的性能:
- 集成(Ensembling):独立地训练几个神经网络,并平均输出它们的输出。
- 测试阶段数据扩增(Multi-crop at test time):将数据扩增应用到测试集,对结果进行平均。
但是实际工业应用项目会考虑性能效率,上述技巧方法计算和内存成本较大,一般很少使用。
参考资料
- LeCun et.al., 1998. Gradient-based learning applied to document recognition
- Krizhevsky et al.,2012. ImageNet classification with deep convolutional neural networks
- Simonvan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition
- He et al., 2015. Deep residual networks for image recognition
- Szegedy et al., 2014, Going Deeper with Convolutions
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
推荐文章
- 深度学习教程 | 深度学习概论
- 深度学习教程 | 神经网络基础
- 深度学习教程 | 浅层神经网络
- 深度学习教程 | 深层神经网络
- 深度学习教程 | 深度学习的实用层面
- 深度学习教程 | 神经网络优化算法
- 深度学习教程 | 网络优化:超参数调优、正则化、批归一化和程序框架
- 深度学习教程 | AI应用实践策略(上)
- 深度学习教程 | AI应用实践策略(下)
- 深度学习教程 | 卷积神经网络解读
- 深度学习教程 | 经典CNN网络实例详解
- 深度学习教程 | CNN应用:目标检测
- 深度学习教程 | CNN应用:人脸识别和神经风格转换
- 深度学习教程 | 序列模型与RNN网络
- 深度学习教程 | 自然语言处理与词嵌入
- 深度学习教程 | Seq2seq序列模型和注意力机制



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix