
深度学习教程 | 浅层神经网络
 本文从浅层神经网络入手,讲解神经网络的基本结构(输入层,隐藏层和输出层),浅层神经网络前向传播和反向传播过程,神经网络参数的梯度下降优化,不同的激活函数的优缺点及非线性的原因
本文从浅层神经网络入手,讲解神经网络的基本结构(输入层,隐藏层和输出层),浅层神经网络前向传播和反向传播过程,神经网络参数的梯度下降优化,不同的激活函数的优缺点及非线性的原因

- 作者:韩信子@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/35
- 本文地址:https://www.showmeai.tech/article-detail/214
- 声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容

本系列为吴恩达老师《深度学习专项课程(Deep Learning Specialization)》学习与总结整理所得,对应的课程视频可以在这里查看。
引言
在ShowMeAI前一篇文章 神经网络基础 中我们对以下内容进行了介绍:
- 二分类问题、逻辑回归模型及损失函数。
- 梯度下降算法。
- 计算图与正向传播及反向传播。
- 向量化方式并行计算与提效。
本篇内容我们将从浅层神经网络入手,逐步拓展到真正的神经网络模型知识学习。
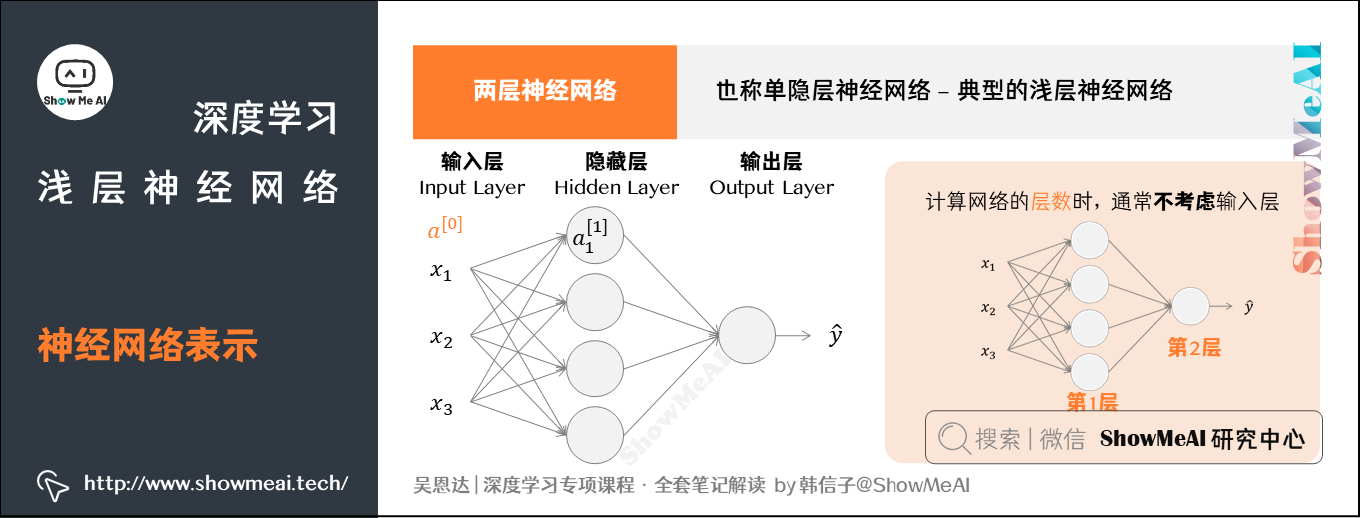
1.神经网络表示

图示为两层神经网络,也可以称作单隐层神经网络(a single hidden layer neural network)。这就是典型的浅层(shallow)神经网络,结构上,从左到右,可以分成三层:
- 输入层(input layer):竖向堆叠起来的输入特征向量。
- 隐藏层(hidden layer):抽象的非线性的中间层。
- 输出层(output layer):输出预测值。
注意:当我们计算网络的层数时,通常不考虑输入层。因此图中隐藏层是第一层,输出层是第二层。
有一些约定俗成的符号表示,如下:
- 输入层的激活值为,隐藏层产生的激活值,记作。
- 隐藏层的第一个单元(或者说节点)就记作,输出层同理。
- 隐藏层和输出层都是带有参数和的,它们都使用上标[1]来表示是和第一个隐藏层有关,或者上标[2]来表示是和输出层有关。
2.计算神经网络的输出
2.1 两层神经网络

接下来我们开始详细推导神经网络的计算过程。
我们依旧来看看我们熟悉的逻辑回归,我们用其构建两层神经网络。逻辑回归的前向传播计算可以分解成计算和的两部分。
如果我们基于逻辑回归构建两层神经网络,前向计算从前往后要做2次计算:
- 从输入层到隐藏层,对应一次逻辑回归运算。
- 从隐藏层到输出层,对应一次逻辑回归运算。
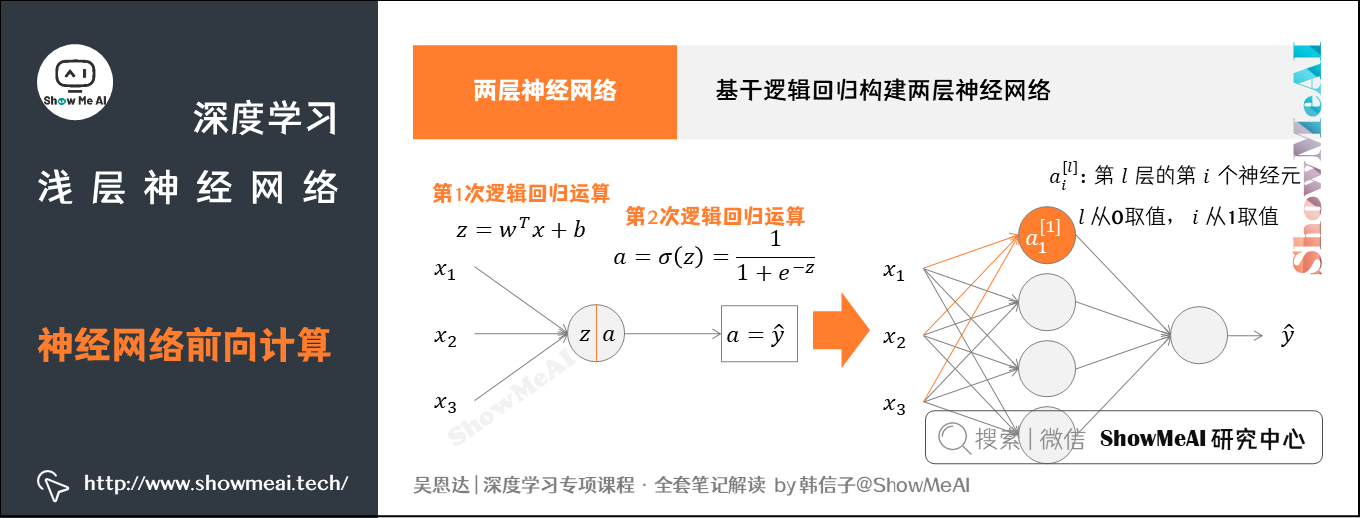
在每层计算中,我们注意对应的上标和下标:
- 我们记上标方括号表示layer,记下标表示第几个神经元。例如,表示第层的第个神经元。
- 注意,从开始,从开始。
2.2 单个样本计算方式
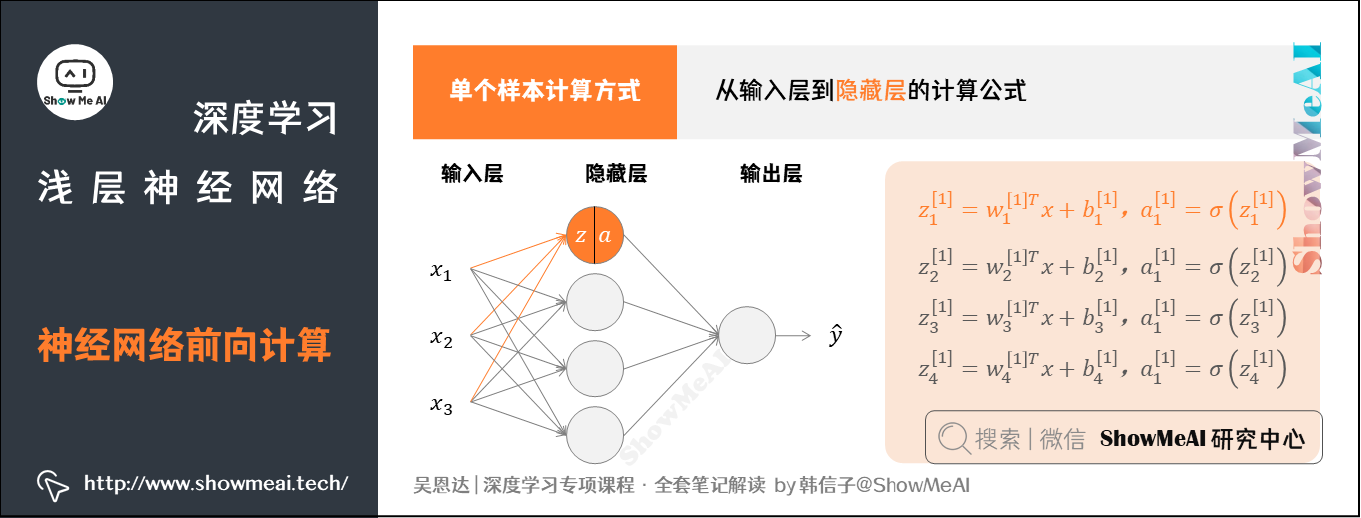
我们将输入层到隐藏层的计算公式列出来:
后续从隐藏层到输出层的计算公式为:
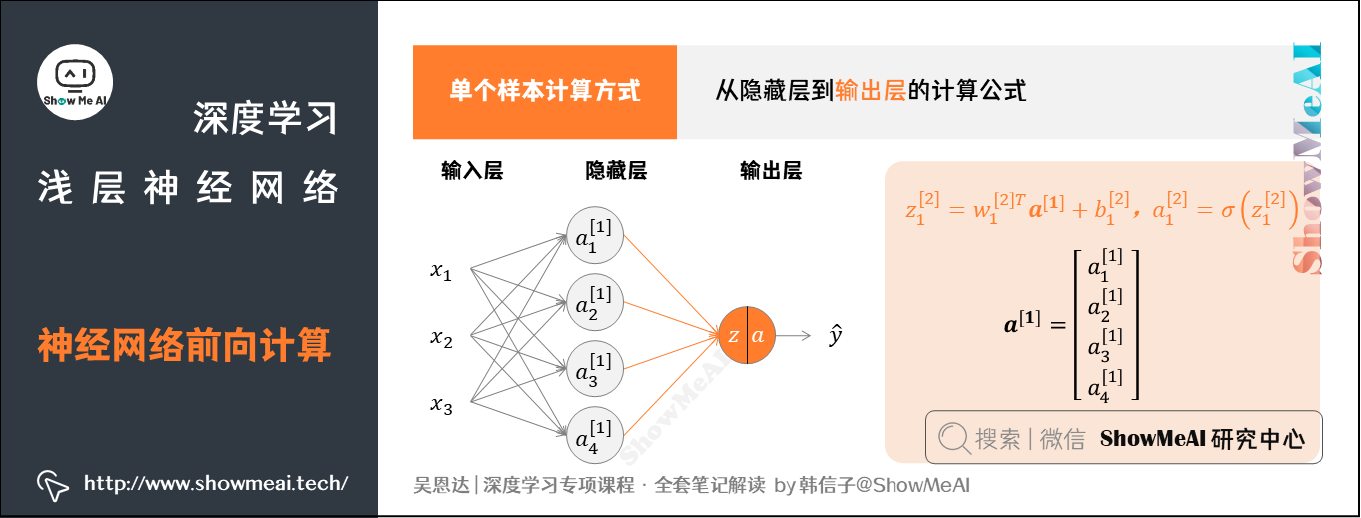
上述每个节点的计算都对应着一次逻辑运算的过程,分别由计算和两部分组成。
2.3 向量化计算

我们引入向量化思想提升计算效率,将上述表达式转换成矩阵运算的形式,如下所示:
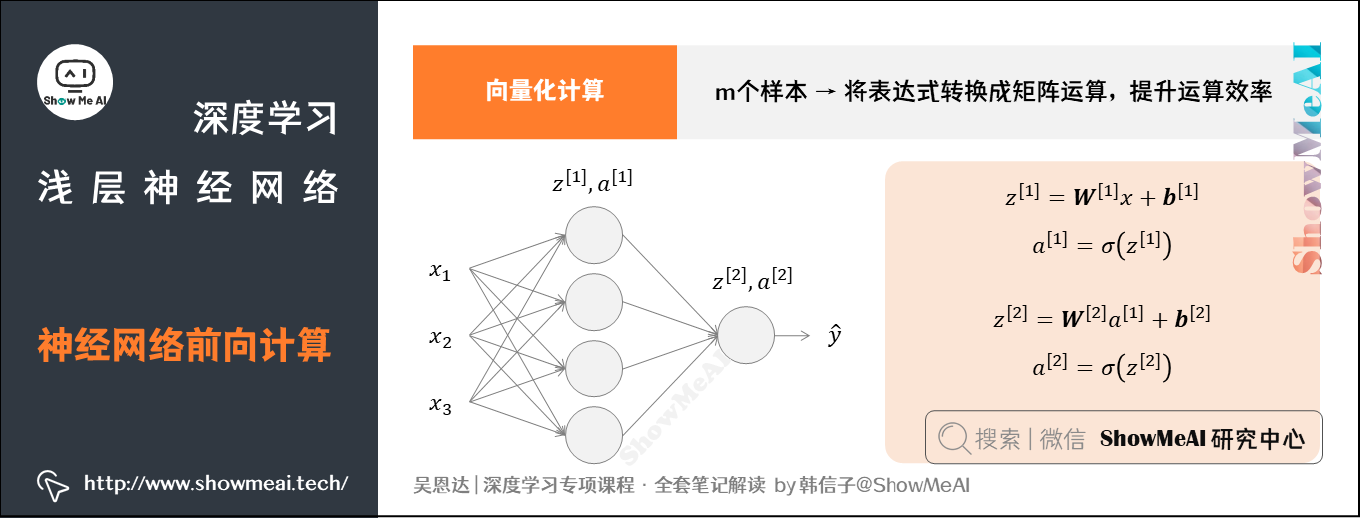
我们这里特别注意一下数据维度:
- 的维度是
- 的维度是
- 的维度是
- 的维度是
2.4 数据集向量化计算

上面部分提到的是单个样本的神经网络正向传播矩阵运算过程。对于个训练样本,我们也可以使用向量化矩阵运算的形式来提升计算效率。形式上,它和单个样本的矩阵运算十分相似,比较简单。我们记输入矩阵的维度为,则有:

上述公式中,的维度是,4是隐藏层神经元的个数;的维度与相同;和的维度均为。
我们可以这样理解上述的矩阵:行表示神经元个数,列表示样本数目。
3.激活函数

3.1 不同的激活函数与选择
在神经网络中,隐藏层和输出层都需要激活函数(activation function),前面的例子中我们都默认使用Sigmoid函数作为激活函数。实际我们有不同的激活函数可以选择,而且它们有各自的优点:
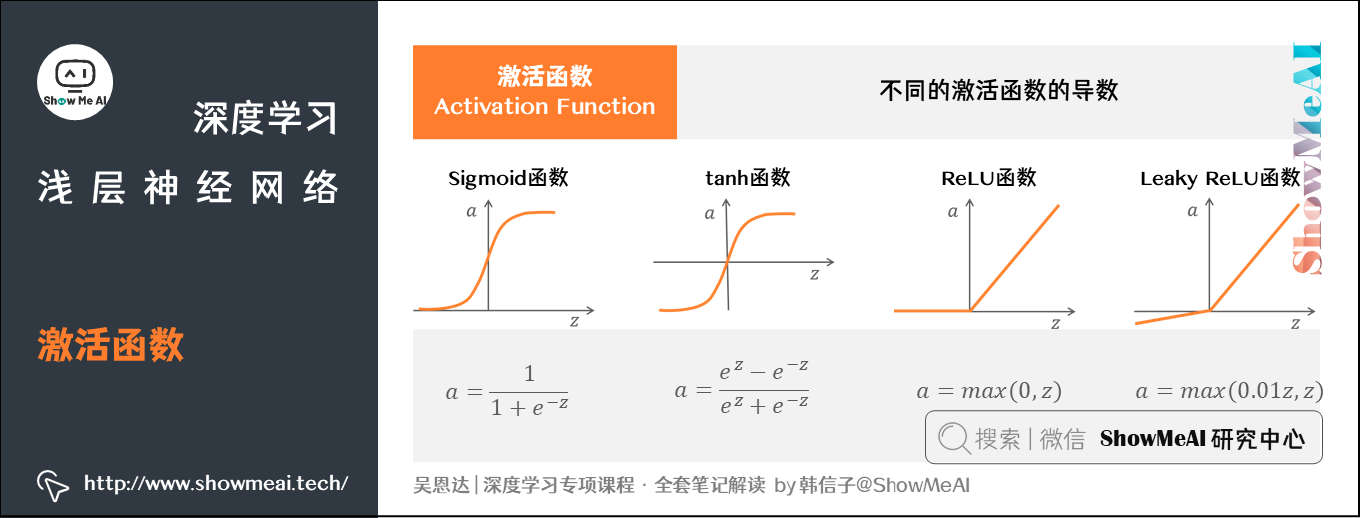
(1) tanh 函数
the hyperbolic tangent function,双曲正切函数
优点:函数输出介于,激活函数的平均值就更接近0,有类似数据中心化的效果。效果几乎总比Sigmoid函数好(二元分类的输出层我们还是会用Sigmoid,因为我们希望输出的结果介于)。
缺点:当趋紧无穷大(或无穷小),导数的梯度(即函数的斜率)就趋紧于0,这使得梯度算法的速度大大减缓。这一点和Sigmoid一样。
(2) ReLU函数
the rectified linear unit,修正线性单元
优点:当时,梯度始终为1,从而提高神经网络基于梯度算法的运算速度,收敛速度远大于Sigmoid和tanh。
缺点:当时,梯度一直为0,但是实际的运用中,该缺陷的影响不是很大。
(3) Leaky ReLU
带泄漏的ReLU
优点:Leaky ReLU保证在的时候,梯度仍然不为0。
理论上来说,Leaky ReLU有ReLU的所有优点,但在实际操作中没有证明总是好于ReLU,因此不常用。
总结
在选择激活函数的时候,如果在不知道该选什么的时候就选择ReLU。当然也没有固定答案,要依据实际问题在交叉验证集合中进行验证分析。注意,我们可以在不同层选用不同的激活函数。
3.2 使用非线性激活函数的原因

使用线性激活函数和不使用激活函数、无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,就成了最原始的感知器了。我们以2层神经网络做一个简单推导,如下:
假设所有的激活函数都是线性的,为了更简单一点,我们直接令激活函数,即。那么,浅层神经网络的各层输出为:
我们对上述公式中展开计算,得:
上述推导后,我们可以发现仍是输入变量的线性组合!后续堆叠更多的层次,也可以依次类推,这表明,使用神经网络,如果不使用激活函数或使用线性激活函数,与直接使用线性模型的效果并没有什么两样!因此,隐藏层的激活函数必须要是非线性的。
不过,在部分场景下,比如是回归预测问题而不是分类问题,输出值为连续值,输出层的激活函数可以使用线性函数。如果输出恒为正值,则也可以使用ReLU激活函数,这些具体情况具体分析。
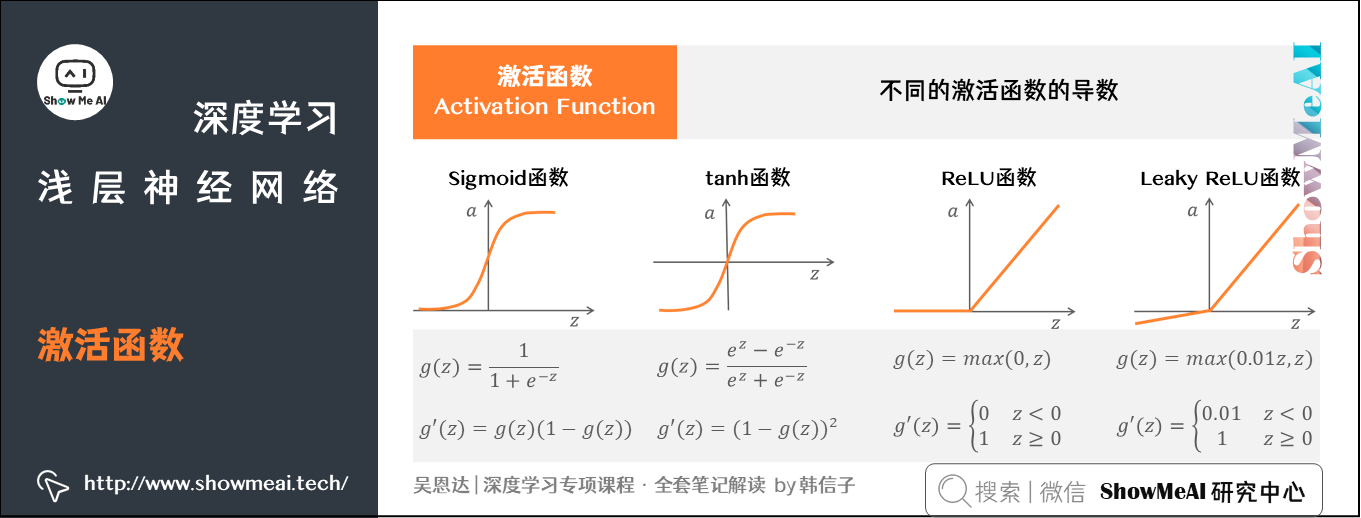
3.3 激活函数的导数

我们来看一下不同激活函数的导数,这将在我们反向传播中频繁用到。
4.神经网络的梯度下降法

下面我们来一起看看,神经网络中的梯度计算。
我们依旧以浅层神经网络为例,它包含的参数为,,,。
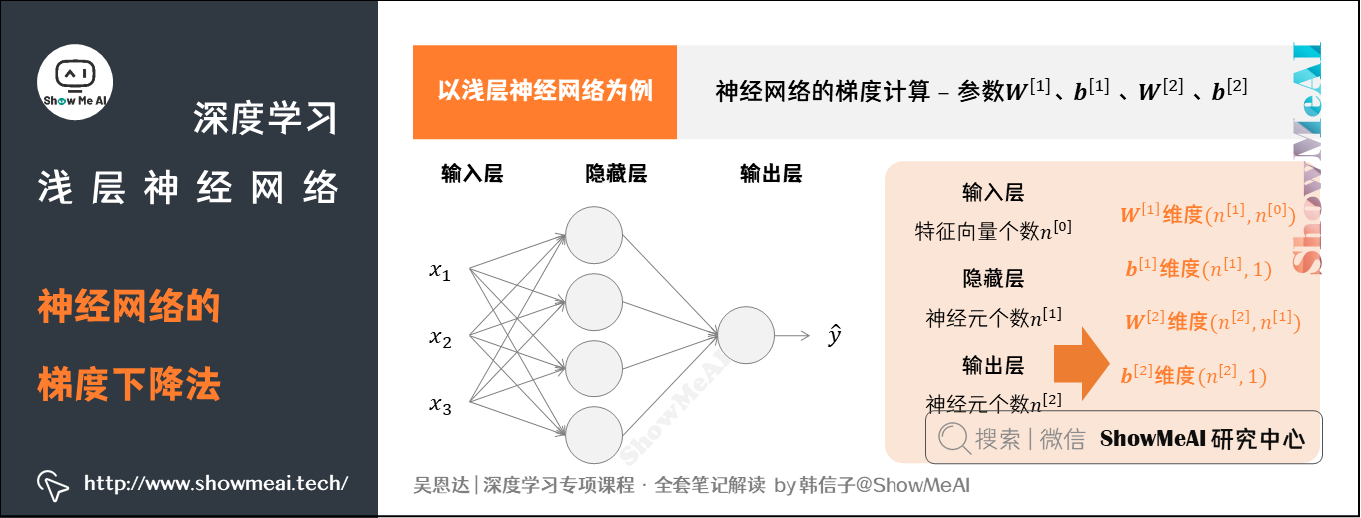
令输入层的特征向量个数,隐藏层神经元个数为,输出层神经元个数为。则:
- 的维度为
- 的维度为
- 的维度为
- 的维度为
4.1 神经网络中的梯度下降
上述神经网络的前向传播过程,对应的公式如下图左侧。反向传播过程,我们会进行梯度计算,我们先列出Cost Function对各个参数的梯度,如下图右侧公式。

其中,np.sum使用到python中的numpy工具库,想了解更多的同学可以查看ShowMeAI的 图解数据分析 系列中的numpy教程,也可以通过ShowMeAI制作的numpy速查手册 快速了解其使用方法)
4.2 反向传播(拓展补充)

我们使用上篇内容 神经网络基础 中的计算图方式来推导神经网络反向传播。回忆我们前面提到的逻辑回归,推导前向传播和反向传播的计算图如下图所示:

因为多了隐藏层,神经网络的计算图要比逻辑回归的复杂一些,如下图所示。
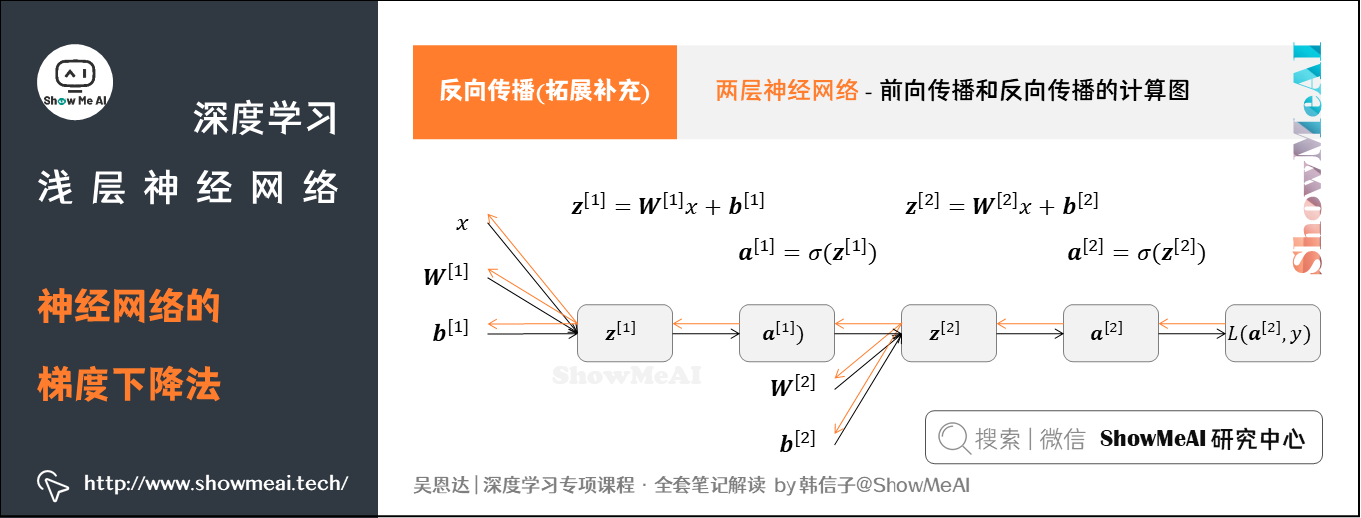
综上,对于浅层神经网络(包含一个隐藏层)而言,「单个样本」和「m个训练样本」的反向传播过程分别对应如下的6个表达式(都是向量化矩阵形式):

5.随机初始化

5.1 全零初始化权重问题
我们在很多机器学习模型中,会初始化权重为0。但在神经网络模型中,参数权重是不能全部初始化为零的,它会带来对称性问题(symmetry breaking problem),下面是分析过程。
假设一个浅层神经网络包含两个输入,隐藏层包含两个神经元。
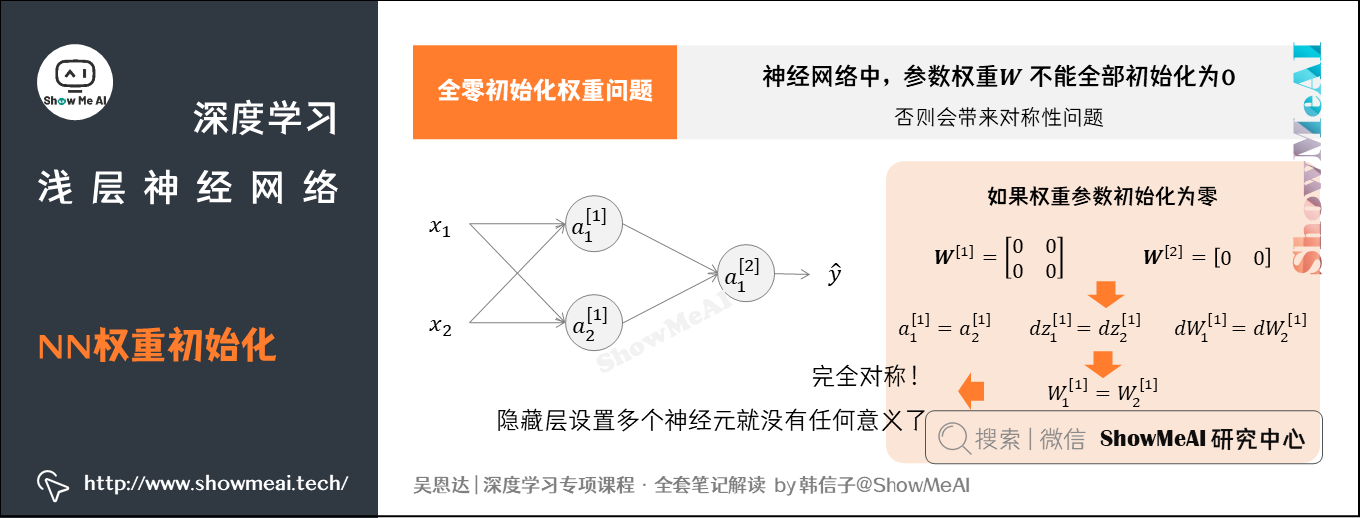
如果权重和都初始化为零,这样使得隐藏层第一个神经元的输出等于第二个神经元的输出,即。容易得到,以及。
我们发现:隐藏层两个神经元对应的权重行向量和每次迭代更新都会得到完全相同的结果,始终等于,完全对称!这样隐藏层设置多个神经元就没有任何意义了。
当然,因为中间层每次只会有1个偏置项参数,它可以全部初始化为零,并不会影响神经网络训练效果。
5.2 解决方法
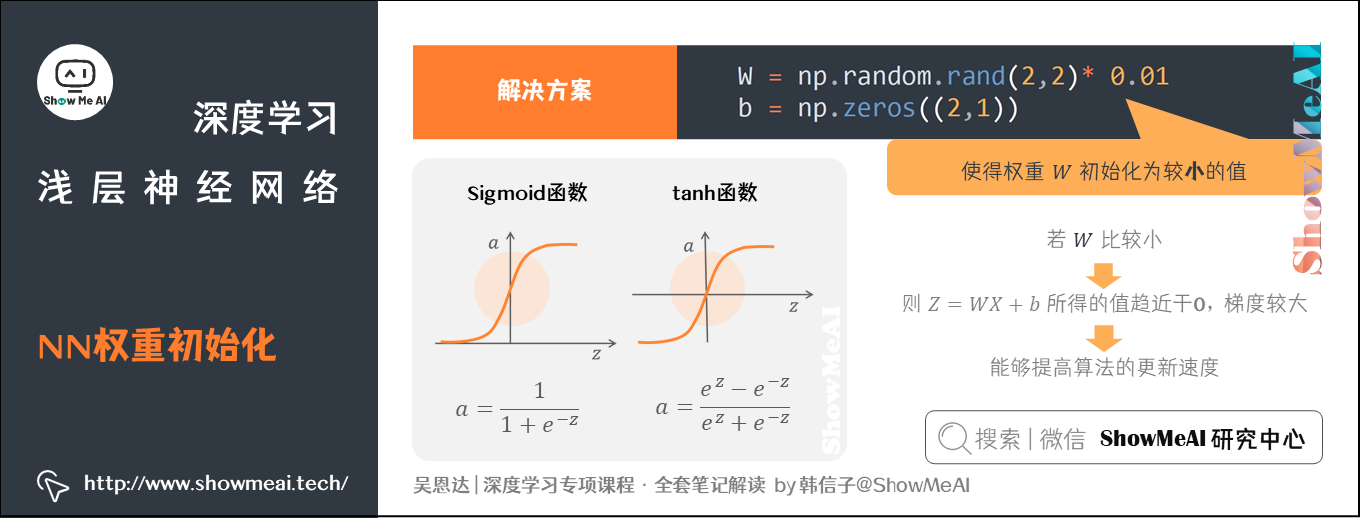
上述提到的权重W全部初始化为零带来的问题就是symmetry breaking problem(对称性)。解决方法也很简单:在初始化的时候,参数要进行随机初始化,不可以设置为0。而因为不存在对称性的问题,可以设置为 0。
以 2 个输入,2 个隐藏神经元为例:
W = np.random.rand(2,2)* 0.01 b = np.zeros((2,1))
这里将 的值乘以 0.01(或者其他的常数值)的原因是为了使得权重 初始化为较小的值,这是因为使用 Sigmoid 函数或者 tanh 函数作为激活函数时:
- 若 比较小,则 所得的值趋近于 0,梯度较大,能够提高算法的更新速度。
- 若 设置的太大,得到的梯度较小,训练过程因此会变得很慢。
ReLU 和 Leaky ReLU 作为激活函数时不存在这种问题,因为在大于 0 的时候,梯度均为 1。如果输出层是Sigmoid函数,则对应的权重最好初始化到比较小的值。
参考资料
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
推荐文章
- 深度学习教程 | 深度学习概论
- 深度学习教程 | 神经网络基础
- 深度学习教程 | 浅层神经网络
- 深度学习教程 | 深层神经网络
- 深度学习教程 | 深度学习的实用层面
- 深度学习教程 | 神经网络优化算法
- 深度学习教程 | 网络优化:超参数调优、正则化、批归一化和程序框架
- 深度学习教程 | AI应用实践策略(上)
- 深度学习教程 | AI应用实践策略(下)
- 深度学习教程 | 卷积神经网络解读
- 深度学习教程 | 经典CNN网络实例详解
- 深度学习教程 | CNN应用:目标检测
- 深度学习教程 | CNN应用:人脸识别和神经风格转换
- 深度学习教程 | 序列模型与RNN网络
- 深度学习教程 | 自然语言处理与词嵌入
- 深度学习教程 | Seq2seq序列模型和注意力机制



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律