
作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/41
本文地址:https://www.showmeai.tech/article-detail/210
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
1.AutoML与自动化机器学习
在前序系列文章中大家跟着ShowMeAI一起学习了如何构建机器学习应用。我们构建一个机器学习模型解决方案baseline很容易,但模型选择和泛化性能优化是一项艰巨的任务。选择合适的模型并是一个需要高计算成本、时间和精力的过程。
针对上述问题就提出了AutoML,AutoML(Automated machine learning)是自动化构建端到端机器学习流程,解决实际场景问题的过程。
在本篇内容中我们将介绍到微软开发的高效轻量级自动化机器学习框架FLAML(A Fast and Lightweight AutoML Library)。
2.FLAML介绍
2.1 FLAML特点
官方网站对FLAML的特点总结如下:
- 对于分类和回归等常见的机器学习任务,FLAML可以在消耗尽量少的资源前提下,快速找到高质量模型。它支持经典机器学习模型和深度神经网络。
- 它很容易定制或扩展。用户可以有很灵活的调整与定制模式:
- 最小定制(设定计算资源限制)
- 中等定制(例如设定scikit-learn学习器、搜索空间和度量标准)
- 完全定制(自定义训练和评估代码)。
- 它支持快速且低消耗的自动调优,能够处理大型搜索空间。 FLAML 由 Microsoft Research 发明的新的高效益超参数优化和学习器选择方法支撑。
2.2 安装方法
我们可以通过pip轻松安装上FLAML
有一些可选的安装选项,如下:
(1) Notebook示例支持
如果大家要跑官方的 notebook代码示例,安装时添加[notebook]选项:
| pip install flaml[notebook] |
(2) 更多模型学习器支持
- 如果我们希望flaml支持catboost模型,安装时添加[catboost]选项
| pip install flaml[catboost] |
- 如果我们希望flaml支持vowpal wabbit ,安装时添加[vw]选项
- 如果我们希望flaml支持时间序列预估器prophet和statsmodels,安装时可以添加[forecast]
| pip install flaml[forecast] |
(3) 分布式调优支持
| pip install flaml[blendsearch] |
3.FLAML使用示例
3.1 全自动模式
下面我们用一个场景数据案例(二分类)来演示FLAML工具库的全自动模式。(大家可以在jupyter notebook中运行下列的代码,关于IDE与环境配置大家可以参考ShowMeAI文章 图解python | 安装与环境设置)。
| !pip install flaml[notebook] |
(1) 加载数据和预处理
我们从 OpenML 下载航空公司数据集 Airlines dataset。 这个数据集的建模任务是在给定预定起飞信息的情况下预测给定航班是否会延误。
| from flaml.data import load_openml_dataset |
| X_train, X_test, y_train, y_test = load_openml_dataset(dataset_id=1169, data_dir='./') |
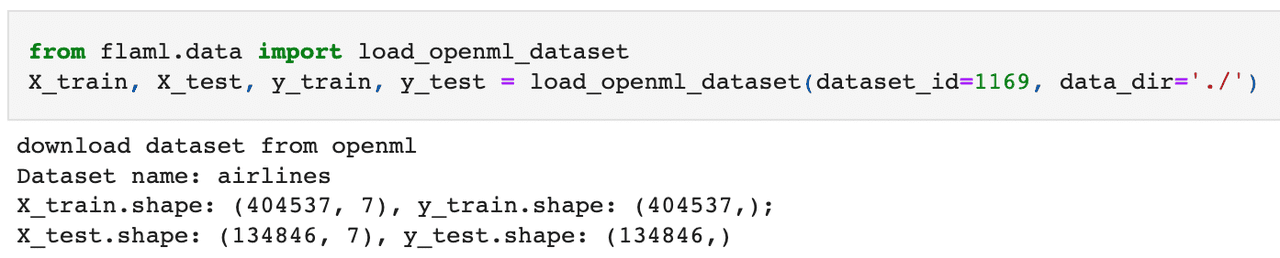
从运行结果可以看到训练集测试集及标签的维度信息。
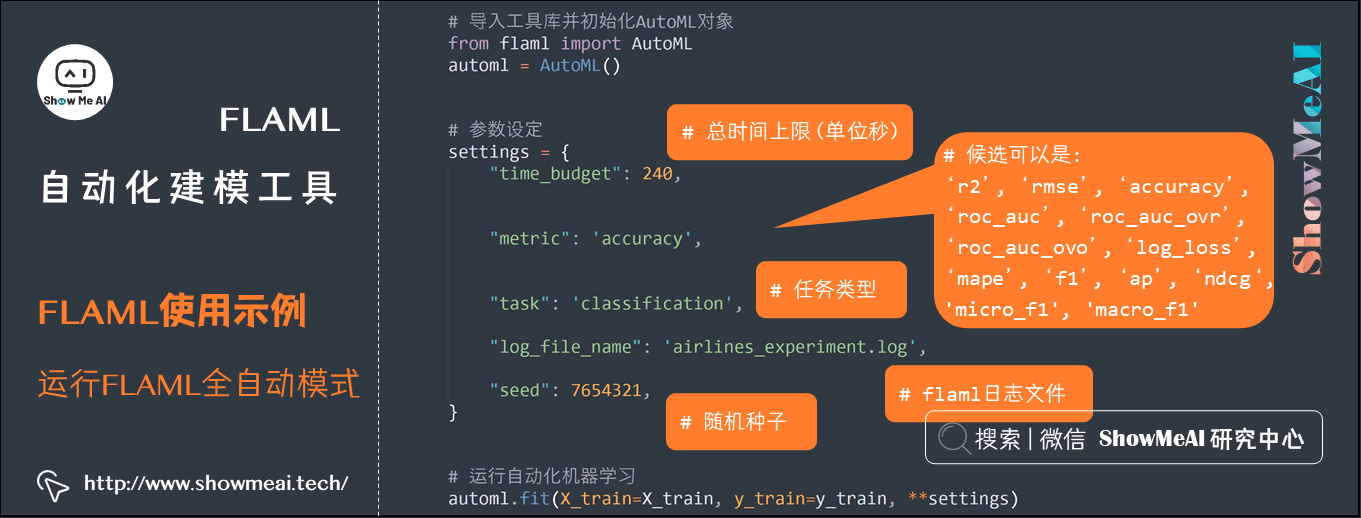
(2) 运行 FLAML全自动模式
下面我们直接运行 FLAML automl 全自动模式,实际在运行配置中,我们可以指定 任务类型、时间预算、误差度量、学习者列表、是否下采样、重采样策略类型等。 如果不作任何设定的话,所有这些参数都会使用默认值(例如,默认分类器是 [lgbm, xgboost, xgb_limitdepth, catboost, rf, extra_tree, lrl1])。
| |
| from flaml import AutoML |
| automl = AutoML() |
| |
| settings = { |
| "time_budget": 240, |
| "metric": 'accuracy', |
| "task": 'classification', |
| "log_file_name": 'airlines_experiment.log', |
| "seed": 7654321, |
| } |
| |
| automl.fit(X_train=X_train, y_train=y_train, **settings) |
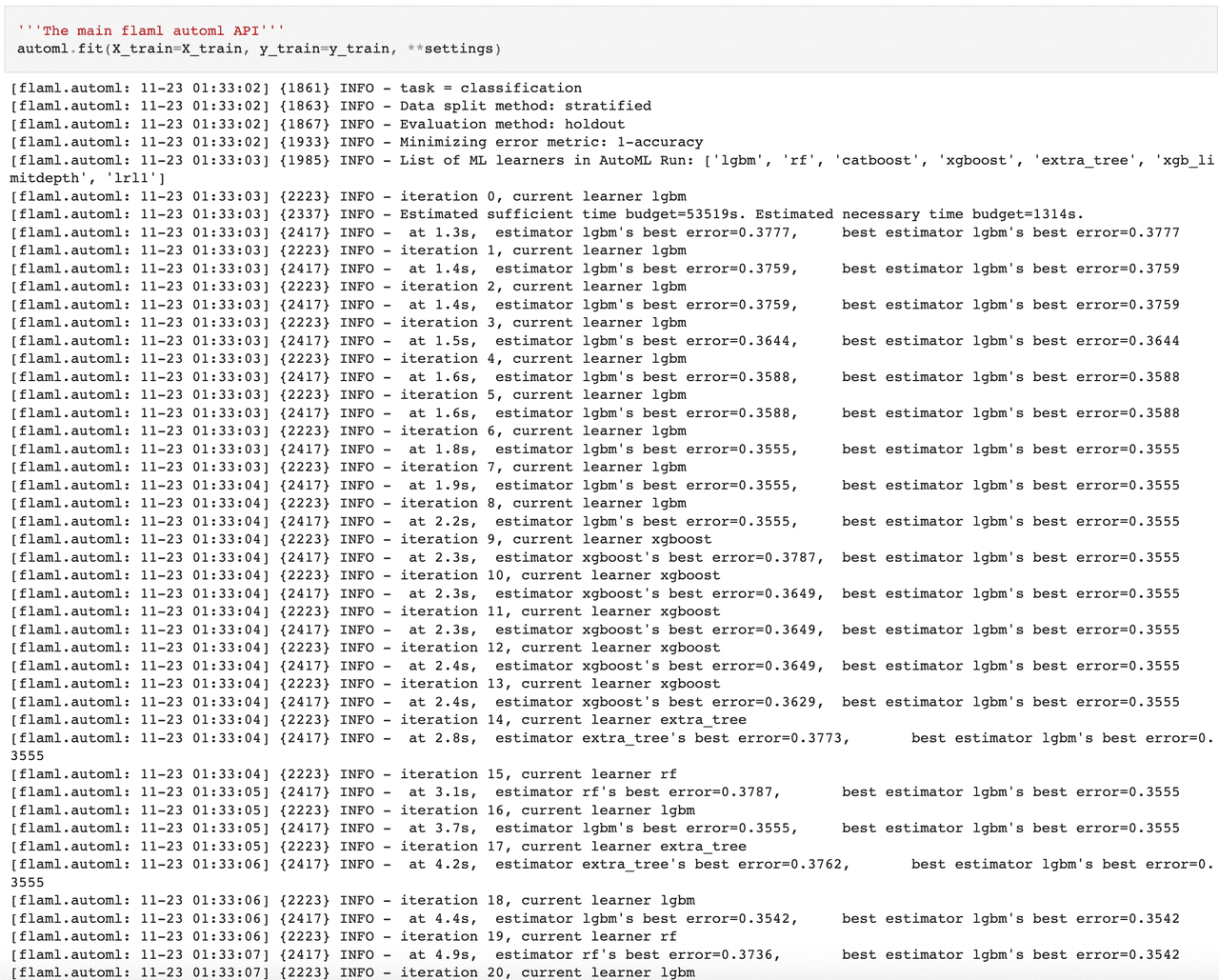
从上述运行结果可以看出,自动机器学习过程,对[lgbm, xgboost, xgb_limitdepth, catboost, rf, extra_tree, lrl1]这些候选模型进行了实验,并运行出了对应的结果。
(3) 最优模型与评估结果
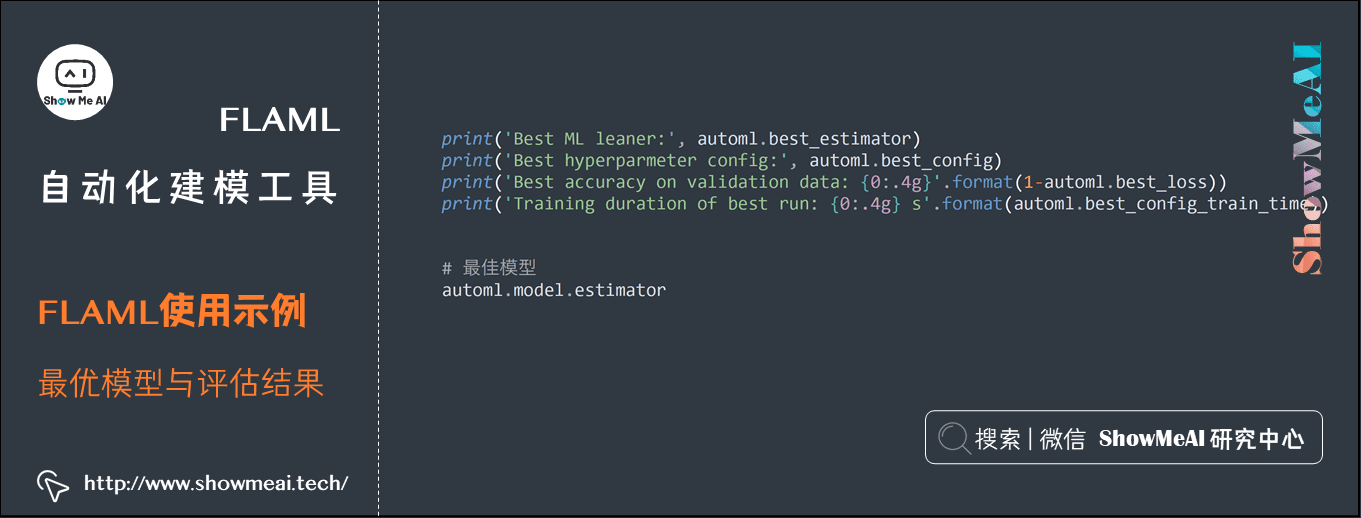
| print('Best ML leaner:', automl.best_estimator) |
| print('Best hyperparmeter config:', automl.best_config) |
| print('Best accuracy on validation data: {0:.4g}'.format(1-automl.best_loss)) |
| print('Training duration of best run: {0:.4g} s'.format(automl.best_config_train_time)) |
运行结果如下
| Best ML leaner: lgbm |
| Best hyperparmeter config: {'n_estimators': 1071, 'num_leaves': 25, 'min_child_samples': 36, 'learning_rate': 0.10320258241974468, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.0009765625, 'reg_lambda': 0.08547376339713011, 'FLAML_sample_size': 364083} |
| Best accuracy on validation data: 0.6696 |
| Training duration of best run: 9.274 s |
可以通过运行完毕的automl对象属性,取出对应的「最优模型」、「最佳模型配置」、「评估准则结果」等信息。在这里最优的模型是1071颗树构建而成的一个LightGBM模型。
更进一步,我们可以通过下面的代码,取出最优模型,并用它对测试集进行预测。
运行结果如下
| LGBMClassifier(learning_rate=0.10320258241974468, max_bin=1023, |
| min_child_samples=36, n_estimators=1071, num_leaves=25, |
| reg_alpha=0.0009765625, reg_lambda=0.08547376339713011, |
| verbose=-1) |
(4) 模型存储与加载
| |
| import pickle |
| with open('automl.pkl', 'wb') as f: |
| pickle.dump(automl, f, pickle.HIGHEST_PROTOCOL) |
| |
| |
| with open('automl.pkl', 'rb') as f: |
| automl = pickle.load(f) |
| |
| y_pred = automl.predict(X_test) |
| print('Predicted labels', y_pred) |
| print('True labels', y_test) |
| y_pred_proba = automl.predict_proba(X_test)[:,1] |
运行结果如下:
| Predicted labels ['1' '0' '1' ... '1' '0' '0'] |
| True labels 118331 0 |
| 328182 0 |
| 335454 0 |
| 520591 1 |
| 344651 0 |
| .. |
| 367080 0 |
| 203510 1 |
| 254894 0 |
| 296512 1 |
| 362444 0 |
| Name: Delay, Length: 134846, dtype: category |
| Categories (2, object): ['0' < '1'] |
可以看到,automl得到的最佳模型,对测试集预估的方式,和自己建模得到的模型是一样的。
| |
| from flaml.ml import sklearn_metric_loss_score |
| print('accuracy', '=', 1 - sklearn_metric_loss_score('accuracy', y_pred, y_test)) |
| print('roc_auc', '=', 1 - sklearn_metric_loss_score('roc_auc', y_pred_proba, y_test)) |
| print('log_loss', '=', sklearn_metric_loss_score('log_loss', y_pred_proba, y_test)) |
评估结果如下:
| accuracy = 0.6720332824110467 |
| roc_auc = 0.7253276908529442 |
| log_loss = 0.6034449031876942 |
(5) 查看日志历史详情
我们可以通过如下代码,查看automl对各个模型实验的结果详细数据。
| from flaml.data import get_output_from_log |
| time_history, best_valid_loss_history, valid_loss_history, config_history, metric_history = \ |
| get_output_from_log(filename=settings['log_file_name'], time_budget=240) |
| for config in config_history: |
| print(config) |
结果如下
| {'Current Learner': 'lgbm', 'Current Sample': 10000, 'Current Hyper-parameters': {'n_estimators': 4, 'num_leaves': 4, 'min_child_samples': 20, 'learning_rate': 0.09999999999999995, 'log_max_bin': 8, 'colsample_bytree': 1.0, 'reg_alpha': 0.0009765625, 'reg_lambda': 1.0, 'FLAML_sample_size': 10000}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 4, 'num_leaves': 4, 'min_child_samples': 20, 'learning_rate': 0.09999999999999995, 'log_max_bin': 8, 'colsample_bytree': 1.0, 'reg_alpha': 0.0009765625, 'reg_lambda': 1.0, 'FLAML_sample_size': 10000}} |
| {'Current Learner': 'lgbm', 'Current Sample': 10000, 'Current Hyper-parameters': {'n_estimators': 4, 'num_leaves': 14, 'min_child_samples': 15, 'learning_rate': 0.22841390623808822, 'log_max_bin': 9, 'colsample_bytree': 1.0, 'reg_alpha': 0.0014700173967242716, 'reg_lambda': 7.624911621832711, 'FLAML_sample_size': 10000}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 4, 'num_leaves': 14, 'min_child_samples': 15, 'learning_rate': 0.22841390623808822, 'log_max_bin': 9, 'colsample_bytree': 1.0, 'reg_alpha': 0.0014700173967242716, 'reg_lambda': 7.624911621832711, 'FLAML_sample_size': 10000}} |
| {'Current Learner': 'lgbm', 'Current Sample': 10000, 'Current Hyper-parameters': {'n_estimators': 4, 'num_leaves': 25, 'min_child_samples': 12, 'learning_rate': 0.5082200481556802, 'log_max_bin': 8, 'colsample_bytree': 0.9696263001275751, 'reg_alpha': 0.0028107036379524425, 'reg_lambda': 3.716898117989413, 'FLAML_sample_size': 10000}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 4, 'num_leaves': 25, 'min_child_samples': 12, 'learning_rate': 0.5082200481556802, 'log_max_bin': 8, 'colsample_bytree': 0.9696263001275751, 'reg_alpha': 0.0028107036379524425, 'reg_lambda': 3.716898117989413, 'FLAML_sample_size': 10000}} |
| {'Current Learner': 'lgbm', 'Current Sample': 10000, 'Current Hyper-parameters': {'n_estimators': 23, 'num_leaves': 14, 'min_child_samples': 15, 'learning_rate': 0.22841390623808822, 'log_max_bin': 9, 'colsample_bytree': 1.0, 'reg_alpha': 0.0014700173967242718, 'reg_lambda': 7.624911621832699, 'FLAML_sample_size': 10000}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 23, 'num_leaves': 14, 'min_child_samples': 15, 'learning_rate': 0.22841390623808822, 'log_max_bin': 9, 'colsample_bytree': 1.0, 'reg_alpha': 0.0014700173967242718, 'reg_lambda': 7.624911621832699, 'FLAML_sample_size': 10000}} |
| {'Current Learner': 'lgbm', 'Current Sample': 10000, 'Current Hyper-parameters': {'n_estimators': 101, 'num_leaves': 12, 'min_child_samples': 24, 'learning_rate': 0.07647794276357095, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.001749539645587163, 'reg_lambda': 4.373760956394571, 'FLAML_sample_size': 10000}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 101, 'num_leaves': 12, 'min_child_samples': 24, 'learning_rate': 0.07647794276357095, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.001749539645587163, 'reg_lambda': 4.373760956394571, 'FLAML_sample_size': 10000}} |
| {'Current Learner': 'lgbm', 'Current Sample': 40000, 'Current Hyper-parameters': {'n_estimators': 101, 'num_leaves': 12, 'min_child_samples': 24, 'learning_rate': 0.07647794276357095, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.001749539645587163, 'reg_lambda': 4.373760956394571, 'FLAML_sample_size': 40000}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 101, 'num_leaves': 12, 'min_child_samples': 24, 'learning_rate': 0.07647794276357095, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.001749539645587163, 'reg_lambda': 4.373760956394571, 'FLAML_sample_size': 40000}} |
| {'Current Learner': 'lgbm', 'Current Sample': 40000, 'Current Hyper-parameters': {'n_estimators': 361, 'num_leaves': 11, 'min_child_samples': 32, 'learning_rate': 0.13528717598813866, 'log_max_bin': 9, 'colsample_bytree': 0.9851977789068981, 'reg_alpha': 0.0038372002422749616, 'reg_lambda': 0.25113531892556773, 'FLAML_sample_size': 40000}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 361, 'num_leaves': 11, 'min_child_samples': 32, 'learning_rate': 0.13528717598813866, 'log_max_bin': 9, 'colsample_bytree': 0.9851977789068981, 'reg_alpha': 0.0038372002422749616, 'reg_lambda': 0.25113531892556773, 'FLAML_sample_size': 40000}} |
| {'Current Learner': 'lgbm', 'Current Sample': 364083, 'Current Hyper-parameters': {'n_estimators': 361, 'num_leaves': 11, 'min_child_samples': 32, 'learning_rate': 0.13528717598813866, 'log_max_bin': 9, 'colsample_bytree': 0.9851977789068981, 'reg_alpha': 0.0038372002422749616, 'reg_lambda': 0.25113531892556773, 'FLAML_sample_size': 364083}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 361, 'num_leaves': 11, 'min_child_samples': 32, 'learning_rate': 0.13528717598813866, 'log_max_bin': 9, 'colsample_bytree': 0.9851977789068981, 'reg_alpha': 0.0038372002422749616, 'reg_lambda': 0.25113531892556773, 'FLAML_sample_size': 364083}} |
| {'Current Learner': 'lgbm', 'Current Sample': 364083, 'Current Hyper-parameters': {'n_estimators': 547, 'num_leaves': 46, 'min_child_samples': 60, 'learning_rate': 0.281323306091088, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.001643352694266288, 'reg_lambda': 0.14719738747481906, 'FLAML_sample_size': 364083}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 547, 'num_leaves': 46, 'min_child_samples': 60, 'learning_rate': 0.281323306091088, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.001643352694266288, 'reg_lambda': 0.14719738747481906, 'FLAML_sample_size': 364083}} |
| {'Current Learner': 'lgbm', 'Current Sample': 364083, 'Current Hyper-parameters': {'n_estimators': 1071, 'num_leaves': 25, 'min_child_samples': 36, 'learning_rate': 0.10320258241974468, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.0009765625, 'reg_lambda': 0.08547376339713011, 'FLAML_sample_size': 364083}, 'Best Learner': 'lgbm', 'Best Hyper-parameters': {'n_estimators': 1071, 'num_leaves': 25, 'min_child_samples': 36, 'learning_rate': 0.10320258241974468, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.0009765625, 'reg_lambda': 0.08547376339713011, 'FLAML_sample_size': 364083}} |
我们可以绘制出验证集的学习曲线,如下:
| import matplotlib.pyplot as plt |
| import numpy as np |
| plt.title('Learning Curve') |
| plt.xlabel('Wall Clock Time (s)') |
| plt.ylabel('Validation Accuracy') |
| plt.scatter(time_history, 1 - np.array(valid_loss_history)) |
| plt.step(time_history, 1 - np.array(best_valid_loss_history), where='post') |
| plt.show() |
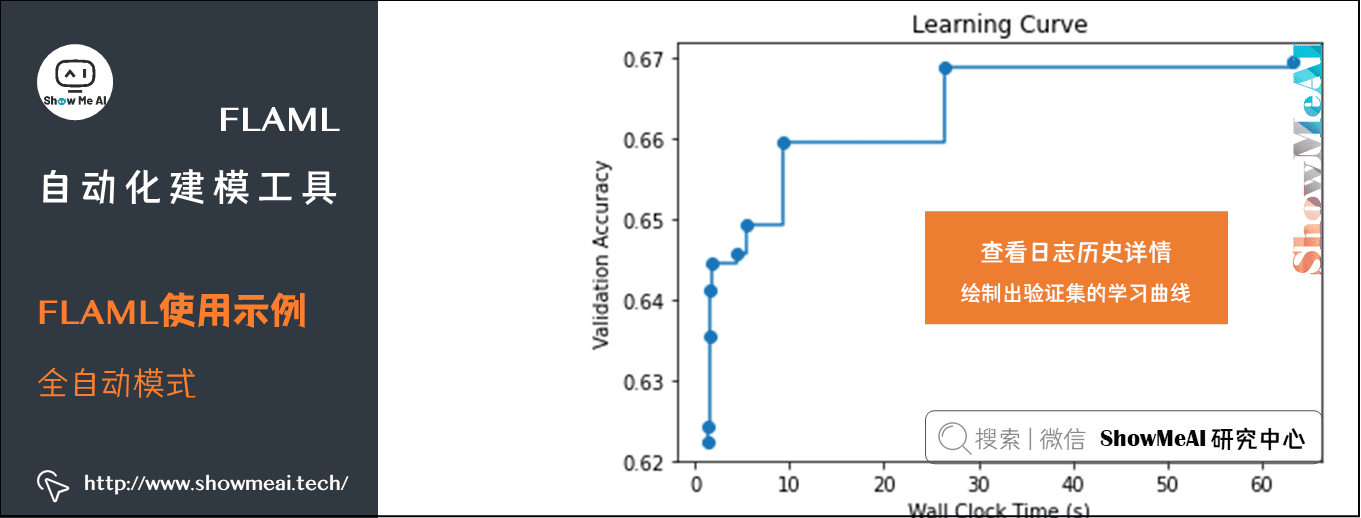
(6) 对比默认XGBoost/LightGBM实验结果
我们来对比一下全部使用默认参数的XGBoost模型在本数据集上的效果,代码如下
| from xgboost import XGBClassifier |
| from lightgbm import LGBMClassifier |
| |
| |
| xgb = XGBClassifier() |
| cat_columns = X_train.select_dtypes(include=['category']).columns |
| X = X_train.copy() |
| X[cat_columns] = X[cat_columns].apply(lambda x: x.cat.codes) |
| xgb.fit(X, y_train) |
| |
| lgbm = LGBMClassifier() |
| lgbm.fit(X_train, y_train) |
| |
| |
| X = X_test.copy() |
| X[cat_columns] = X[cat_columns].apply(lambda x: x.cat.codes) |
| y_pred_xgb = xgb.predict(X) |
| |
| y_pred_lgbm = lgbm.predict(X_test) |
| |
| |
| print('默认参数 xgboost accuracy', '=', 1 - sklearn_metric_loss_score('accuracy', y_pred_xgb, y_test)) |
| print('默认参数 lgbm accuracy', '=', 1 - sklearn_metric_loss_score('accuracy', y_pred_lgbm, y_test)) |
| print('flaml (4min) accuracy', '=', 1 - sklearn_metric_loss_score('accuracy', y_pred, y_test)) |
最终结果如下:
| 默认参数 xgboost accuracy = 0.6676060098186078 |
| 默认参数 lgbm accuracy = 0.6602346380315323 |
| flaml (4min) accuracy = 0.6720332824110467 |
从对比结果中可以看出,flaml自动机器学习调优的最佳模型,效果优于默认参数的XGBoost和LightGBM建模结果。
3.2 自定义学习器
除了完全自动化模式使用FLAML工具库,我们还可以对它的一些组件进行自定义,实现自定义调优。比如我们可以对「模型」「参数搜索空间」「候选学习器」「模型优化指标」等进行设置。
(1) 自定义模型
正则化贪心森林 (RGF) 是一种机器学习方法,目前未包含在 FLAML 中。 RGF 有许多调整参数,其中最关键的是:[max_leaf, n_iter, n_tree_search, opt_interval, min_samples_leaf]。 要运行自定义/新学习器,用户需要提供以下信息:
- 自定义/新学习器的实现
- 超参数名称和类型的列表
- 超参数的粗略范围(即上限/下限)
在下面的示例代码中,RGF 信息被包装在一个名为 MyRegularizedGreedyForest 的 python 类中。
| from flaml.model import SKLearnEstimator |
| from flaml import tune |
| from flaml.data import CLASSIFICATION |
| |
| class MyRegularizedGreedyForest(SKLearnEstimator): |
| def __init__(self, task='binary', **config): |
| '''Constructor |
| |
| Args: |
| task: A string of the task type, one of |
| 'binary', 'multi', 'regression' |
| config: A dictionary containing the hyperparameter names |
| and 'n_jobs' as keys. n_jobs is the number of parallel threads. |
| ''' |
| |
| super().__init__(task, **config) |
| |
| '''task=binary or multi for classification task''' |
| if task in CLASSIFICATION: |
| from rgf.sklearn import RGFClassifier |
| |
| self.estimator_class = RGFClassifier |
| else: |
| from rgf.sklearn import RGFRegressor |
| |
| self.estimator_class = RGFRegressor |
| |
| @classmethod |
| def search_space(cls, data_size, task): |
| '''[required method] search space |
| Returns: |
| A dictionary of the search space. |
| Each key is the name of a hyperparameter, and value is a dict with |
| its domain (required) and low_cost_init_value, init_value, |
| cat_hp_cost (if applicable). |
| e.g., |
| {'domain': tune.randint(lower=1, upper=10), 'init_value': 1}. |
| ''' |
| space = { |
| 'max_leaf': {'domain': tune.lograndint(lower=4, upper=data_size[0]), 'init_value': 4, 'low_cost_init_value': 4}, |
| 'n_iter': {'domain': tune.lograndint(lower=1, upper=data_size[0]), 'init_value': 1, 'low_cost_init_value': 1}, |
| 'n_tree_search': {'domain': tune.lograndint(lower=1, upper=32768), 'init_value': 1, 'low_cost_init_value': 1}, |
| 'opt_interval': {'domain': tune.lograndint(lower=1, upper=10000), 'init_value': 100}, |
| 'learning_rate': {'domain': tune.loguniform(lower=0.01, upper=20.0)}, |
| 'min_samples_leaf': {'domain': tune.lograndint(lower=1, upper=20), 'init_value': 20}, |
| } |
| return space |
| |
| @classmethod |
| def size(cls, config): |
| '''[optional method] memory size of the estimator in bytes |
| |
| Args: |
| config - the dict of the hyperparameter config |
| Returns: |
| A float of the memory size required by the estimator to train the |
| given config |
| ''' |
| max_leaves = int(round(config['max_leaf'])) |
| n_estimators = int(round(config['n_iter'])) |
| return (max_leaves * 3 + (max_leaves - 1) * 4 + 1.0) * n_estimators * 8 |
| |
| @classmethod |
| def cost_relative2lgbm(cls): |
| '''[optional method] relative cost compared to lightgbm |
| ''' |
| return 1.0 |
(2) 运行FLAML自定义模型automl
将RGF添加到学习器列表后,我们通过调整RGF的超参数以及默认学习器来运行automl。
| automl = AutoML() |
| automl.add_learner(learner_name='RGF', learner_class=MyRegularizedGreedyForest) |
| |
| settings = { |
| "time_budget": 10, |
| "metric": 'accuracy', |
| "estimator_list": ['RGF', 'lgbm', 'rf', 'xgboost'], |
| "task": 'classification', |
| "log_file_name": 'airlines_experiment_custom_learner.log', |
| "log_training_metric": True, |
| } |
| automl.fit(X_train = X_train, y_train = y_train, **settings) |
(3) 自定义优化指标
我们可以为模型自定义优化指标。 下面的示例代码中,我们合并训练损失和验证损失作为自定义优化指标,并对其进行优化,希望损失最小化。
| def custom_metric(X_val, y_val, estimator, labels, X_train, y_train, |
| weight_val=None, weight_train=None, config=None, |
| groups_val=None, groups_train=None): |
| from sklearn.metrics import log_loss |
| import time |
| start = time.time() |
| y_pred = estimator.predict_proba(X_val) |
| pred_time = (time.time() - start) / len(X_val) |
| val_loss = log_loss(y_val, y_pred, labels=labels, |
| sample_weight=weight_val) |
| y_pred = estimator.predict_proba(X_train) |
| train_loss = log_loss(y_train, y_pred, labels=labels, |
| sample_weight=weight_train) |
| alpha = 0.5 |
| return val_loss * (1 + alpha) - alpha * train_loss, { |
| "val_loss": val_loss, "train_loss": train_loss, "pred_time": pred_time |
| } |
| |
| |
| |
| automl = AutoML() |
| settings = { |
| "time_budget": 10, |
| "metric": custom_metric, |
| "task": 'classification', |
| "log_file_name": 'airlines_experiment_custom_metric.log', |
| } |
| automl.fit(X_train = X_train, y_train = y_train, **settings) |
3.3 sklearn流水线调优
FLAML可以配合sklearn pipeline进行模型自动化调优,我们这里依旧以航空公司数据集 Airlines dataset 案例为场景,对其用法做一个讲解。
(1) 加载数据集
| |
| from flaml.data import load_openml_dataset |
| X_train, X_test, y_train, y_test = load_openml_dataset( |
| dataset_id=1169, data_dir='./', random_state=1234, dataset_format='array') |
(2) 构建建模流水线
| import sklearn |
| from sklearn import set_config |
| from sklearn.pipeline import Pipeline |
| from sklearn.impute import SimpleImputer |
| from sklearn.preprocessing import StandardScaler |
| from flaml import AutoML |
| set_config(display='diagram') |
| imputer = SimpleImputer() |
| standardizer = StandardScaler() |
| automl = AutoML() |
| automl_pipeline = Pipeline([ |
| ("imputuer",imputer), |
| ("standardizer", standardizer), |
| ("automl", automl) |
| ]) |
| automl_pipeline |
输出结果如下
| Pipeline(steps=[('imputuer', SimpleImputer()), |
| ('standardizer', StandardScaler()), |
| ('automl', )]) |
| SimpleImputerSimpleImputer() |
| StandardScalerStandardScaler() |
| AutoML |
(3) 参数设定与automl拟合
| |
| settings = { |
| "time_budget": 60, |
| "metric": 'accuracy', |
| "task": 'classification', |
| "estimator_list":['xgboost','catboost','lgbm'], |
| "log_file_name": 'airlines_experiment.log', |
| } |
| |
| |
| automl_pipeline.fit(X_train, y_train, |
| automl__time_budget=settings['time_budget'], |
| automl__metric=settings['metric'], |
| automl__estimator_list=settings['estimator_list'], |
| automl__log_training_metric=True) |
(4) 取出最优模型
| |
| automl = automl_pipeline.steps[2][1] |
| |
| print('Best ML leaner:', automl.best_estimator) |
| print('Best hyperparmeter config:', automl.best_config) |
| print('Best accuracy on validation data: {0:.4g}'.format(1-automl.best_loss)) |
| print('Training duration of best run: {0:.4g} s'.format(automl.best_config_train_time)) |
| automl.model |
运行结果如下:
| Best ML leaner: xgboost |
| Best hyperparmeter config: {'n_estimators': 63, 'max_leaves': 1797, 'min_child_weight': 0.07275175679381725, 'learning_rate': 0.06234183309508761, 'subsample': 0.9814772488195874, 'colsample_bylevel': 0.810466508891351, 'colsample_bytree': 0.8005378817953572, 'reg_alpha': 0.5768305704485758, 'reg_lambda': 6.867180836557797, 'FLAML_sample_size': 364083} |
| Best accuracy on validation data: 0.6721 |
| Training duration of best run: 15.45 s |
| <flaml.model.XGBoostSklearnEstimator at 0x7f03a5eada00> |
(5) 测试集评估与模型存储
| import pickle |
| with open('automl.pkl', 'wb') as f: |
| pickle.dump(automl, f, pickle.HIGHEST_PROTOCOL) |
| |
| y_pred = automl_pipeline.predict(X_test) |
| print('Predicted labels', y_pred) |
| print('True labels', y_test) |
| y_pred_proba = automl_pipeline.predict_proba(X_test)[:,1] |
| print('Predicted probas ',y_pred_proba[:5]) |
运行结果如下
| Predicted labels [0 1 1 ... 0 1 0] |
| True labels [0 0 0 ... 1 0 1] |
| Predicted probas [0.3764987 0.6126277 0.699604 0.27359942 0.25294745] |
3.4 XGBoost自动调优
这里我们简单给大家讲一下如何使用FLAML调优最常见的模型之一XGBoost。
(1) 工具库导入与基本设定
| |
| from flaml import AutoML |
| automl = AutoML() |
| |
| settings = { |
| "time_budget": 120, |
| "metric": 'r2', |
| "estimator_list": ['xgboost'], |
| "task": 'regression', |
| "log_file_name": 'houses_experiment.log', |
| } |
(2) 自动化机器学习拟合
| automl.fit(X_train=X_train, y_train=y_train, **settings) |
(3) 最优模型与评估
我们可以输出最优模型配置及详细信息
| |
| print('Best hyperparmeter config:', automl.best_config) |
| print('Best r2 on validation data: {0:.4g}'.format(1 - automl.best_loss)) |
| print('Training duration of best run: {0:.4g} s'.format(automl.best_config_train_time)) |
运行结果:
| Best hyperparmeter config: {'n_estimators': 776, 'max_leaves': 160, 'min_child_weight': 32.57408640781376, 'learning_rate': 0.034786853332414935, 'subsample': 0.9152991332236934, 'colsample_bylevel': 0.5656764254642628, 'colsample_bytree': 0.7313266091895249, 'reg_alpha': 0.005771390107656191, 'reg_lambda': 1.49126672786588} |
| Best r2 on validation data: 0.834 |
| Training duration of best run: 9.471 s |
我们可以取出最优模型
结果如下:
| XGBRegressor(base_score=0.5, booster='gbtree', |
| colsample_bylevel=0.5656764254642628, colsample_bynode=1, |
| colsample_bytree=0.7313266091895249, gamma=0, gpu_id=-1, |
| grow_policy='lossguide', importance_type='gain', |
| interaction_constraints='', learning_rate=0.034786853332414935, |
| max_delta_step=0, max_depth=0, max_leaves=160, |
| min_child_weight=32.57408640781376, missing=nan, |
| monotone_constraints='()', n_estimators=776, n_jobs=-1, |
| num_parallel_tree=1, random_state=0, |
| reg_alpha=0.005771390107656191, reg_lambda=1.49126672786588, |
| scale_pos_weight=1, subsample=0.9152991332236934, |
| tree_method='hist', use_label_encoder=False, validate_parameters=1, |
| verbosity=0) |
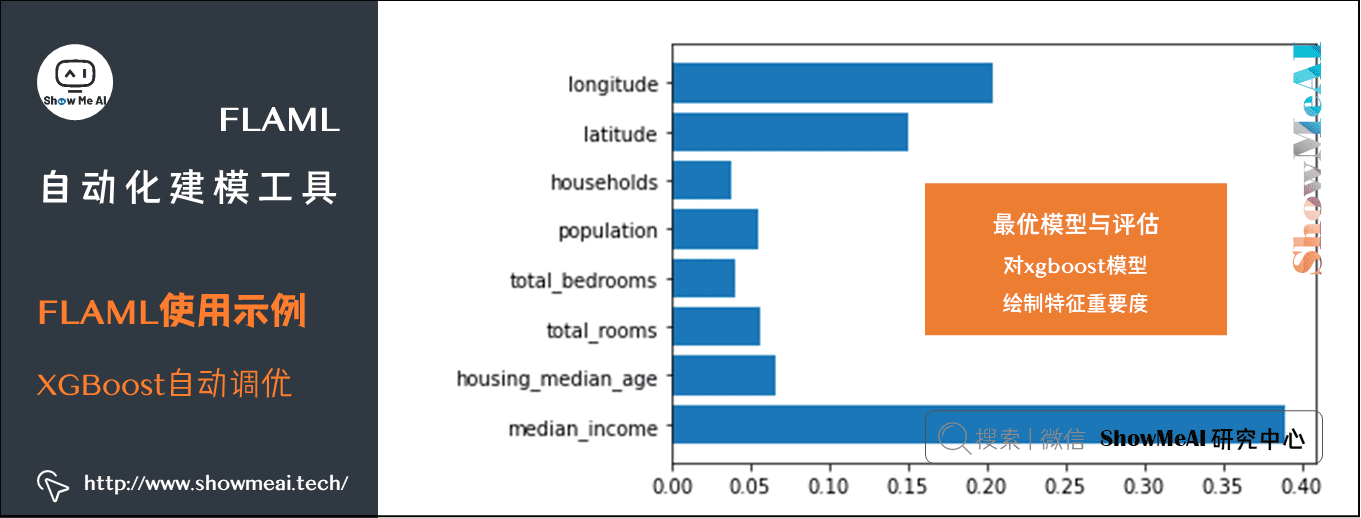
同样可以对XGBoost模型绘制特征重要度
| import matplotlib.pyplot as plt |
| plt.barh(X_train.columns, automl.model.estimator.feature_importances_) |
(4) 模型存储
| import pickle |
| with open('automl.pkl', 'wb') as f: |
| pickle.dump(automl, f, pickle.HIGHEST_PROTOCOL) |
(5) 测试集预估及模型评估
| |
| y_pred = automl.predict(X_test) |
| print('Predicted labels', y_pred) |
| print('True labels', y_test) |
| |
| |
| from flaml.ml import sklearn_metric_loss_score |
| print('r2', '=', 1 - sklearn_metric_loss_score('r2', y_pred, y_test)) |
| print('mse', '=', sklearn_metric_loss_score('mse', y_pred, y_test)) |
| print('mae', '=', sklearn_metric_loss_score('mae', y_pred, y_test)) |
3.5 LightGBM自动调优
LightGBM调优的过程和XGBoost非常类似,仅仅在参数配置的部分指定模型需要做一点调整,其他部分是一致的,如下:
| |
| from flaml import AutoML |
| automl = AutoML() |
| |
| |
| settings = { |
| "time_budget": 240, |
| "metric": 'r2', |
| "estimator_list": ['lgbm'], |
| "task": 'regression', |
| "log_file_name": 'houses_experiment.log', |
| "seed": 7654321, |
| } |
| |
| |
| automl.fit(X_train=X_train, y_train=y_train, **settings) |
参考资料
机器学习【算法】系列教程
机器学习【实战】系列教程
ShowMeAI系列教程推荐


 本篇介绍工具库FLAML。FLAML 由 Microsoft Research 开发,适用于AutoML自动化机器学习建模,构建端到端机器学习流程、解决实际场景问题。
本篇介绍工具库FLAML。FLAML 由 Microsoft Research 开发,适用于AutoML自动化机器学习建模,构建端到端机器学习流程、解决实际场景问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人