
机器学习实战 | SKLearn入门与简单应用案例
 本篇内容介绍了SKLearn的核心板块,并通过SKLearn自带的数据集,讲解一个典型应用案例。
本篇内容介绍了SKLearn的核心板块,并通过SKLearn自带的数据集,讲解一个典型应用案例。

作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/41
本文地址:https://www.showmeai.tech/article-detail/202
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
引言
在前面的机器学习案例中,我们使用了Python机器学习工具库Scikit-Learn,它建立在NumPy、SciPy、Pandas和Matplotlib之上,也是最常用的Python机器学习工具库之一,里面的API的设计非常好,所有对象的接口简单,很适合新手上路。ShowMeAI在本篇内容中对Scikit-Learn做一个介绍。

1.SKLearn是什么
Scikit-Learn也简称SKLearn,是一个基于Python语言的机器学习工具,它对常用的机器学习方法进行了封装,例如,分类、回归、聚类、降维、模型评估、数据预处理等,我们只需调用对应的接口即可。
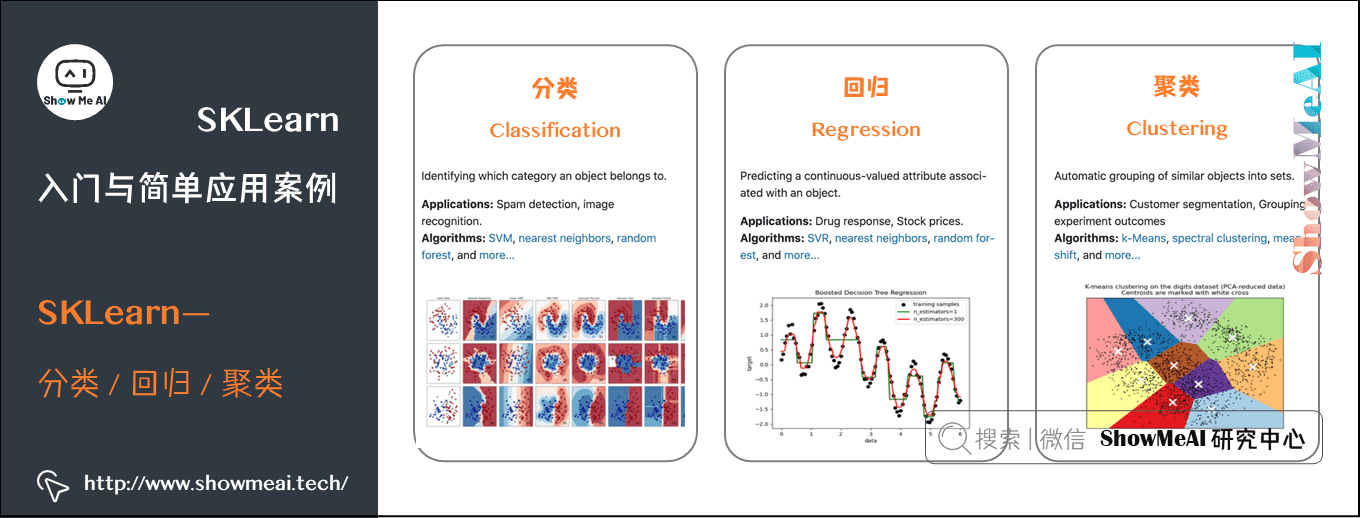

在SKLearn的官网上,写着以下四点介绍:
- 一个简单高效的数据挖掘和数据分析工具。
- 构建在NumPy,SciPy和matplotlib上。
- 可供大家在各种环境中重复使用。
- 开源,可商业使用–BSD许可证。
SKLearn官网:https://scikit-learn.org/stable/
SKLearn的快速使用方法也推荐大家查看ShowMeAI的文章和速查手册 AI建模工具速查|Scikit-learn使用指南
2.安装SKLearn
安装SKLearn非常简单,命令行窗口中输入命令:
pip install scikit-learn
我们也可以使用清华镜像源安装,通常速度会更快一些:
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
3.SKLearn常用接口
对于机器学习整个流程中涉及到的常用操作,SKLearn中几乎都有现成的接口可以直接调用,而且不管使用什么处理器或者模型,它的接口一致度都非常高。
3.1 数据集导入
更多数据集请参考SKLearn官网:https://scikit-learn.org/stable/modules/classes.html?highlight=dataset#module-sklearn.datasets

#鸢尾花数据集 from sklearn.datasets import load_iris #乳腺癌数据集 from sklearn.datasets import load_breast_cancer #波士顿房价数据集 from sklearn.datasets import load_boston
3.2 数据预处理
官网链接:https://scikit-learn.org/stable/modules/classes.html#module-sklearn.preprocessing

#拆分数据集 from sklearn.model_selection import train_test_split #数据缩放 from sklearn.preprocessing import MinMaxScaler
3.3 特征抽取
官网链接:https://scikit-learn.org/stable/modules/classes.html#module-sklearn.feature_extraction
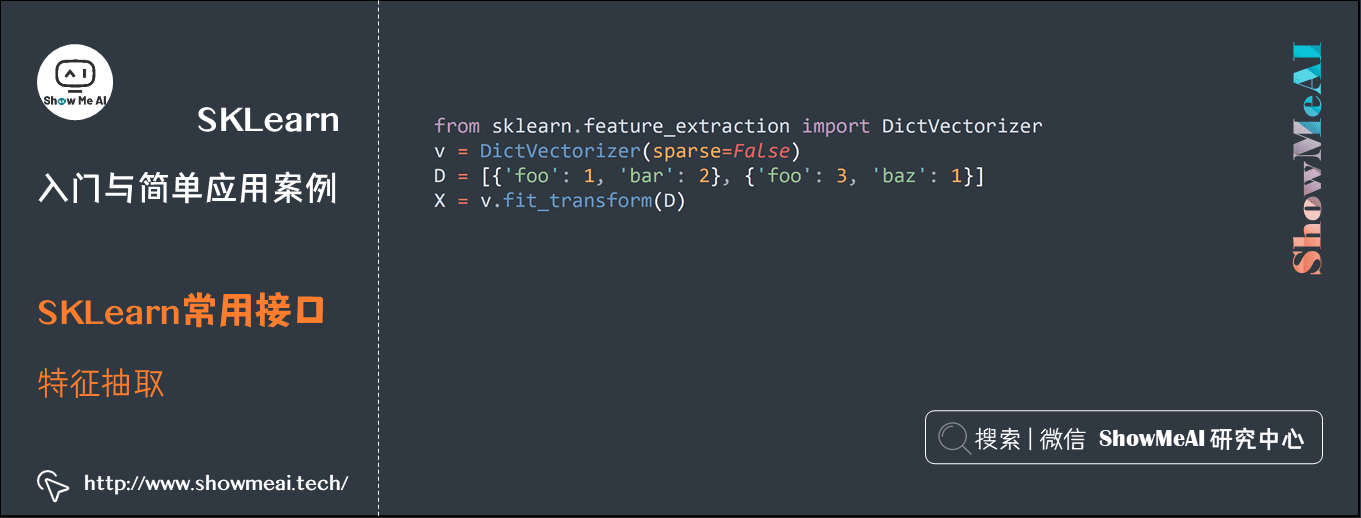
from sklearn.feature_extraction import DictVectorizer v = DictVectorizer(sparse=False) D = [{'foo': 1, 'bar': 2}, {'foo': 3, 'baz': 1}] X = v.fit_transform(D)
3.4 特征选择
官网链接:https://scikit-learn.org/stable/modules/classes.html#module-sklearn.feature_selection
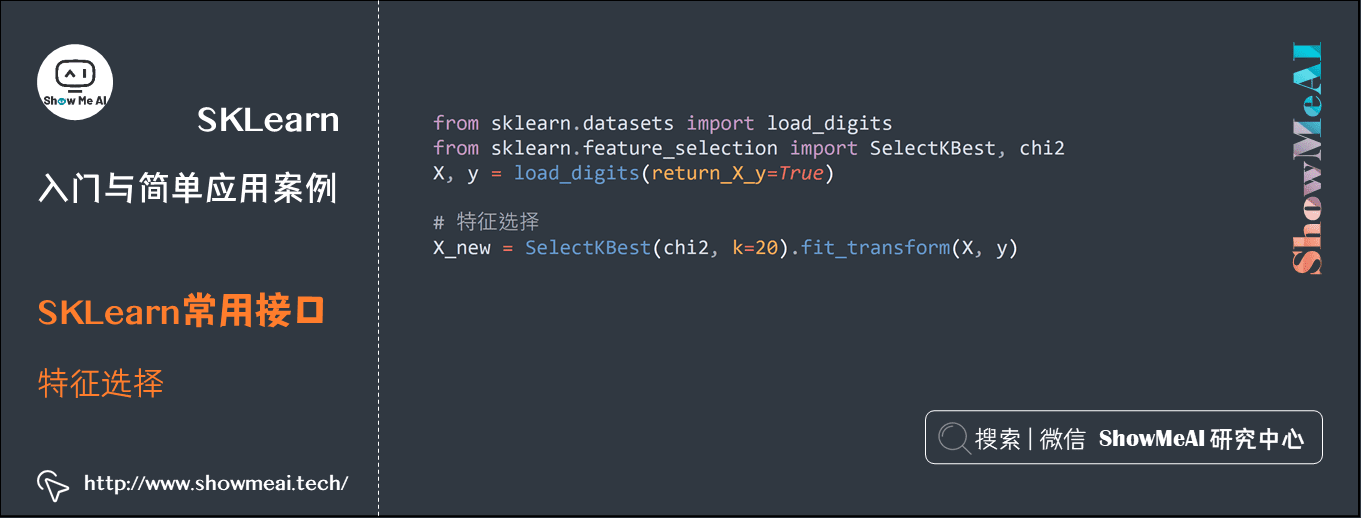
from sklearn.datasets import load_digits from sklearn.feature_selection import SelectKBest, chi2 X, y = load_digits(return_X_y=True) # 特征选择 X_new = SelectKBest(chi2, k=20).fit_transform(X, y)
3.5 常用模型
官网链接:https://scikit-learn.org/stable/modules/classes.html

#KNN模型 from sklearn.neighbors import KNeighborsClassifier #决策树 from sklearn.tree import DecisionTreeClassifier #支持向量机 from sklearn.svm import SVC #随机森林 from sklearn.ensemble import RandomForestClassifier
3.6 建模拟合与预测

#拟合训练集 knn.fit(X_train,y_train) #预测 y_pred=knn.predict(X_test)
3.7 模型评估
官网链接:https://scikit-learn.org/stable/modules/classes.html#sklearn-metrics-metrics
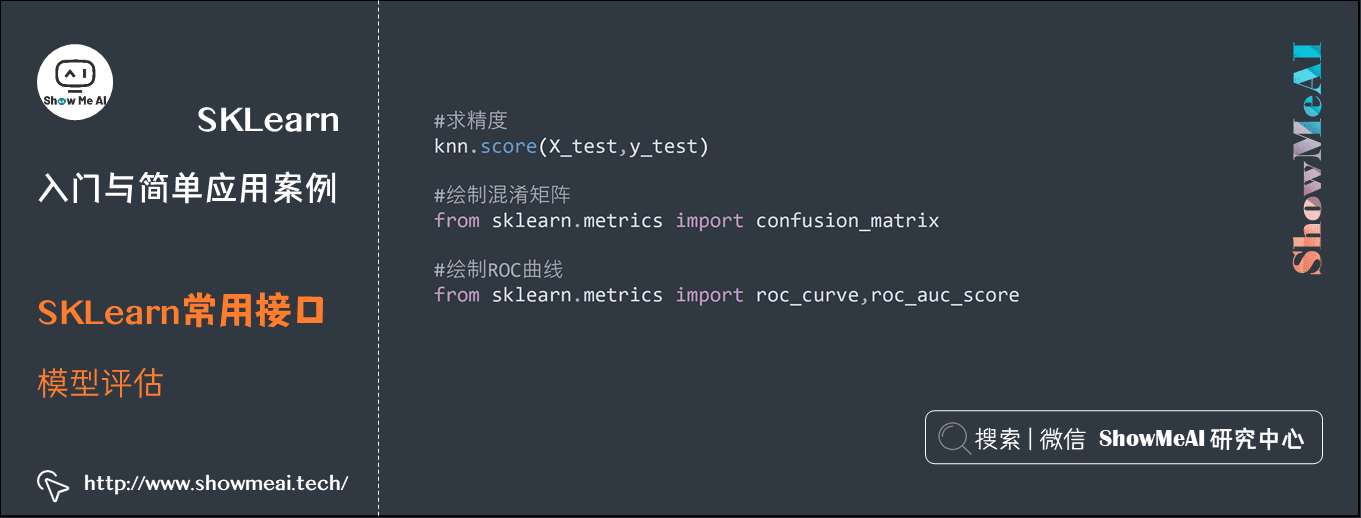
#求精度 knn.score(X_test,y_test) #绘制混淆矩阵 from sklearn.metrics import confusion_matrix #绘制ROC曲线 from sklearn.metrics import roc_curve,roc_auc_score
3.8 典型的建模流程示例
典型的一个机器学习建模应用流程遵循【数据准备】【数据预处理】【特征工程】【建模与评估】【模型优化】这样的一些流程环节。
# 加载数据 import numpy as np import urllib # 下载数据集 url = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data" raw_data = urllib.urlopen(url) # 加载CSV文件 dataset = np.loadtxt(raw_data, delimiter=",") # 区分特征和标签 X = dataset[:,0:7] y = dataset[:,8] # 数据归一化 from sklearn import preprocessing # 幅度缩放 scaled_X = preprocessing.scale(X) # 归一化 normalized_X = preprocessing.normalize(X) # 标准化 standardized_X = preprocessing.scale(X) # 特征选择 from sklearn import metrics from sklearn.ensemble import ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) # 特征重要度 print(model.feature_importances_) # 建模与评估 from sklearn import metrics from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X, y) print('MODEL') print(model) # 预测 expected = y predicted = model.predict(X) # 输出评估结果 print('RESULT') print(metrics.classification_report(expected, predicted)) print('CONFUSION MATRIX') print(metrics.confusion_matrix(expected, predicted)) # 超参数调优 from sklearn.model_selection import GridSearchCV param_grid = {'penalty' : ['l1', 'l2', 'elasticnet'], 'C': [0.1, 1, 10]} grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5)
参考资料
机器学习【算法】系列教程
- 图解机器学习 | 机器学习基础知识
- 图解机器学习 | 模型评估方法与准则
- 图解机器学习 | KNN算法及其应用
- 图解机器学习 | 逻辑回归算法详解
- 图解机器学习 | 朴素贝叶斯算法详解
- 图解机器学习 | 决策树模型详解
- 图解机器学习 | 随机森林分类模型详解
- 图解机器学习 | 回归树模型详解
- 图解机器学习 | GBDT模型详解
- 图解机器学习 | XGBoost模型最全解析
- 图解机器学习 | LightGBM模型详解
- 图解机器学习 | 支持向量机模型详解
- 图解机器学习 | 聚类算法详解
- 图解机器学习 | PCA降维算法详解
机器学习【实战】系列教程
- 机器学习实战 | Python机器学习算法应用实践
- 机器学习实战 | SKLearn入门与简单应用案例
- 机器学习实战 | SKLearn最全应用指南
- 机器学习实战 | XGBoost建模应用详解
- 机器学习实战 | LightGBM建模应用详解
- 机器学习实战 | Python机器学习综合项目-电商销量预估
- 机器学习实战 | Python机器学习综合项目-电商销量预估<进阶方案>
- 机器学习实战 | 机器学习特征工程最全解读
- 机器学习实战 | 自动化特征工程工具Featuretools应用
- 机器学习实战 | AutoML自动化机器学习建模
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人