

图解机器学习 | 逻辑回归算法详解
 逻辑回归简单有效且可解释性强,是机器学习领域最常见的模型之一。本文讲解逻辑回归算法的核心思想,并讲解sigmoid函数、梯度下降、解决过拟合、线性/非线性切分等重要知识点。
逻辑回归简单有效且可解释性强,是机器学习领域最常见的模型之一。本文讲解逻辑回归算法的核心思想,并讲解sigmoid函数、梯度下降、解决过拟合、线性/非线性切分等重要知识点。

作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/34
本文地址:https://www.showmeai.tech/article-detail/188
声明:版权所有,转载请联系平台与作者并注明出处
引言
本篇内容我们给大家介绍机器学习领域最常见的模型之一:逻辑回归。它也是目前工业界解决问题最广泛作为baseline的解决方案。逻辑回归之所以被广泛应用,因为其简单有效且可解释性强。
本文的结构如下:
-
第1部分:回顾机器学习与分类问题。回顾机器学习中最重要的问题之一分类问题,不同的分类问题及数学抽象。
-
第2部分:逻辑回归核心思想。介绍线性回归问题及逻辑回归解决方式,讲解逻辑回归核心思想。
-
第3部分:Sigmoid函数与分类器决策边界。介绍逻辑回归模型中最重要的Sigmoid变换函数,以及不同分类器得到的决策边界。
-
第4部分:模型优化使用的梯度下降算法。介绍模型参数学习过程中最常使用到的优化算法:梯度下降。
-
第5部分:模型过拟合问题与正则化。介绍模型状态分析及过拟合问题,以及缓解过拟合问题可以使用的正则化手段。
-
第6部分:特征变换与非线性切分。介绍由线性分类器到非线性分类场景,对特征可以进行的变换如构建多项式特征,使得分类器得到分线性切分能力。
(本篇逻辑回归算法的部分内容涉及到机器学习基础知识,没有先序知识储备的宝宝可以查看ShowMeAI的文章 图解机器学习 | 机器学习基础知识)。
1.机器学习与分类问题
1)分类问题
分类问题是机器学习非常重要的一个组成部分,它的目标是根据已知样本的某些特征,判断一个样本属于哪个类别。分类问题可以细分如下:
-
二分类问题:表示分类任务中有两个类别新的样本属于哪种已知的样本类。
-
多类分类(Multiclass Classification)问题:表示分类任务中有多类别。
-
多标签分类(Multilabel Classification)问题:给每个样本一系列的目标标签。

2)分类问题的数学抽象
从算法的角度解决一个分类问题,我们的训练数据会被映射成n维空间的样本点(这里的n就是特征维度),我们需要做的事情是对n维样本空间的点进行类别区分,某些点会归属到某个类别。
下图所示的是二维平面中的两类样本点,我们的模型(分类器)在学习一种区分不同类别的方法,比如这里是使用一条直线去对2类不同的样本点进行切分。

常见的分类问题应用场景很多,我们选择几个进行举例说明:
-
垃圾邮件识别:可以作为二分类问题,将邮件分为你「垃圾邮件」或者「正常邮件」。
-
图像内容识别:因为图像的内容种类不止一个,图像内容可能是猫、狗、人等等,因此是多类分类问题。
-
文本情感分析:既可以作为二分类问题,将情感分为褒贬两种,还可以作为多类分类问题,将情感种类扩展,比如分为:十分消极、消极、积极、十分积极等。
2.逻辑回归算法核心思想
下面介绍本次要讲解的算法——逻辑回归(Logistic Regression)。逻辑回归是线性回归的一种扩展,用来处理分类问题。
1)线性回归与分类
分类问题和回归问题有一定的相似性,都是通过对数据集的学习来对未知结果进行预测,区别在于输出值不同。
-
分类问题的输出值是离散值(如垃圾邮件和正常邮件)。
-
回归问题的输出值是连续值(例如房子的价格)。
既然分类问题和回归问题有一定的相似性,那么我们能不能在回归的基础上进行分类呢?
可以想到的一种尝试思路是,先用线性拟合,然后对线性拟合的预测结果值进行量化,即将连续值量化为离散值——即使用『线性回归+阈值』解决分类问题。
我们来看一个例子。假如现在有一个关于肿瘤大小的数据集,需要根据肿瘤的大小来判定是良性(用数字0表示)还是恶性(用数字1表示),这是一个很典型的二分类问题。

如上图,目前这个简单的场景我们得到1个直观的判定:肿瘤的大小大于5,即为恶性肿瘤(输出为1);肿瘤的大小等于5,即为良性肿瘤(输出为0)。
下面我们尝试之前提到的思路,使用一元线性函数去进行拟合数据,函数体现在图片中就是这条黑色直线。

这样分类问题就可以转化为:对于这个线性拟合的假设函数,给定一个肿瘤的大小,只要将其带入假设函数,并将其输出值和0.5进行比较:
-
如果线性回归值大于0.5,就输出1(恶性肿瘤)。
-
如果线性回归值小于0.5,就输出0(良性肿瘤)。

上图的数据集中的分类问题被完美解决。但如果将数据集更改一下,如图所示,如果我们还是以0.5为判定阈值,那么就会把肿瘤大小为6的情况进行误判为良好。
所以,单纯地通过将线性拟合的输出值与某一个阈值进行比较,这种方法用于分类非常不稳定。
2)逻辑回归核心思想
因为「线性回归+阈值」的方式很难得到鲁棒性好的分类器,我们对其进行拓展得到鲁棒性更好的逻辑回归(Logistic Regression,有些地方也叫做「对数几率回归」)。逻辑回归将数据拟合到一个logit函数中,从而完成对事件发生概率的预测。
如果线性回归的结果输出是一个连续值,而值的范围是无法限定的,这种情况下我们无法得到稳定的判定阈值。那是否可以把这个结果映射到一个固定大小的区间内(比如0到1),进而判断呢。
当然可以,这就是逻辑回归做的事情,而其中用于对连续值压缩变换的函数叫做Sigmoid函数(也称Logistic函数,S函数)。

Sigmoid数学表达式为
可以看到S函数的输出值在0到1之间。
3.Sigmoid函数与决策边界
刚才大家见到了Sigmoid函数,下面我们来讲讲它和线性拟合的结合,如何能够完成分类问题,并且得到清晰可解释的分类器判定「决策边界」。
1)分类与决策边界
决策边界就是分类器对于样本进行区分的边界,主要有线性决策边界(linear decision boundaries)和非线性决策边界(non-linear decision boundaries),如下图所示。

2)线性决策边界生成
那么,逻辑回归是怎么得到决策边界的呢,它与Sigmoid函数又有什么关系呢?
如下图中的例子:
如果我们用函数g表示Sigmoid函数,逻辑回归的输出结果由假设函数得到。
对于图中的例子,我们暂时取参数分别为-3、1和1,那么对于图上的两类样本点,我们代入一些坐标到,会得到什么结果值呢。

-
对于直线上方的点(例如),代入,得到大于0的取值,经过Sigmoid映射后得到的是大于0.5的取值。
-
对于直线下方的点(例如),代入,得到小于0的取值,经过Sigmoid映射后得到的是小于0.5的取值。
如果我们以0.5为判定边界,则线性拟合的直线变换成了一条决策边界(这里是线性决策边界)。
3)非线性决策边界生成
其实,我们不仅仅可以得到线性决策边界,当更复杂的时候,我们甚至可以得到对样本非线性切分的非线性决策边界(这里的非线性指的是无法通过直线或者超平面把不同类别的样本很好地切分开)。
如下图中另外一个例子:如果我们用函数g表示Sigmoid函数,逻辑回归的输出结果由假设函数得到。
对于图中的例子,我们暂时取参数分别为-1、0、0、1和1,那么对于图上的两类样本点,我们代入一些坐标到
,会得到什么结果值呢。

-
对于圆外部的点(例如),代入,得到大于0的取值,经过Sigmoid映射后得到的是大于0.5的取值。
-
对于圆内部的点(例如),代入,得到小于0的取值,经过Sigmoid映射后得到的是小于0.5的取值。
如果我们以0.5为判定边界,则线性拟合的圆曲线变换成了一条决策边界(这里是非线性决策边界)。
4.梯度下降与优化
1)损失函数
前一部分的例子中,我们手动取了一些参数θ的取值,最后得到了决策边界。但大家显然可以看到,取不同的参数时,可以得到不同的决策边界。
哪一条决策边界是最好的呢?我们需要定义一个能量化衡量模型好坏的函数——损失函数(有时候也叫做「目标函数」或者「代价函数」)。我们的目标是使得损失函数最小化。
我们如何衡量预测值和标准答案之间的差异呢,最简单直接的方式是数学中的均方误差。它的计算方式很简单,对于所有的样本点,预测值与标准答案作差后平方,求均值即可,这个取值越小代表差异度越小。
均方误差对应的损失函数:均方误差损失(MSE)在回归问题损失定义与优化中广泛应用,但是在逻辑回归问题中不太适用。sigmoid函数的变换使得我们最终得到损失函数曲线如下图所示,是非常不光滑凹凸不平的,这种数学上叫做非凸的损失函数(关于损失函数与凸优化更多知识可以参考ShowMeAI的文章 图解AI数学基础 | 微积分与最优化),我们要找到最优参数(使得函数取值最小的参数)是很困难的。

解释:在逻辑回归模型场景下,使用MSE得到的损失函数是非凸的,数学特性不太好,我们希望损失函数如下的凸函数。凸优化问题中,局部最优解同时也是全局最优解,这一特性使得凸优化问题在一定意义上更易于解决,而一般的非凸最优化问题相比之下更难解决。
我们更希望我们的损失函数如下图所示,是凸函数,我们在数学上有很好优化方法可以对其进行优化。

在逻辑回归模型场景下,我们会改用对数损失函数(二元交叉熵损失),这个损失函数同样能很好地衡量参数好坏,又能保证凸函数的特性。对数损失函数的公式如下:
其中表示样本取值,在其为正样本时取值为1,负样本时取值为0,我们分这两种情况来看看:

-:当一个样本为负样本时,若的结果接近1(即预测为正样本),那么的值很大,那么得到的惩罚就大。
-:当一个样本为正样本时,若的结果接近0(即预测为负样本),那么的值很大,那么得到的惩罚就大。
2)梯度下降
损失函数可以用于衡量模型参数好坏,但我们还需要一些优化方法找到最佳的参数(使得当前的损失函数值最小)。最常见的算法之一是「梯度下降法」,逐步迭代减小损失函数(在凸函数场景下非常容易使用)。如同下山,找准方向(斜率),每次迈进一小步,直至山底。

梯度下降(Gradient Descent)法,是一个一阶最优化算法,通常也称为最速下降法。要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。

上图中,α称为学习率(learning rate),直观的意义是,在函数向极小值方向前进时每步所走的步长。太大一般会错过极小值,太小会导致迭代次数过多。

(关于损失函数与凸优化更多知识可以参考ShowMeAI的文章 图解AI数学基础 | 微积分与最优化https://www.showmeai.tech/article-detail/165,关于监督学习的更多总结可以查看ShowMeAI总结的速查表手册 AI知识技能速查 | 机器学习-监督学习)
5.正则化与缓解过拟合
1)过拟合现象
在训练数据不够多,或者模型复杂又过度训练时,模型会陷入过拟合(Overfitting)状态。如下图所示,得到的不同拟合曲线(决策边界)代表不同的模型状态:
-
拟合曲线1能够将部分样本正确分类,但是仍有较大量的样本未能正确分类,分类精度低,是「欠拟合」状态。
-
拟合曲线2能够将大部分样本正确分类,并且有足够的泛化能力,是较优的拟合曲线。
-
拟合曲线3能够很好的将当前样本区分开来,但是当新来一个样本时,有很大的可能不能将其正确区分,原因是该决策边界太努力地学习当前的样本点,甚至把它们直接「记」下来了。

拟合曲线中的「抖动」,表示拟合曲线不规则、不光滑(上图中的拟合曲线3),对数据的学习程度深,过拟合了。
2)正则化处理
过拟合的一种处理方式是正则化,我们通过对损失函数添加正则化项,可以约束参数的搜索空间,从而保证拟合的决策边界并不会抖动非常厉害。如下图为对数损失函数中加入正则化项(这里是一个L2正则化项)
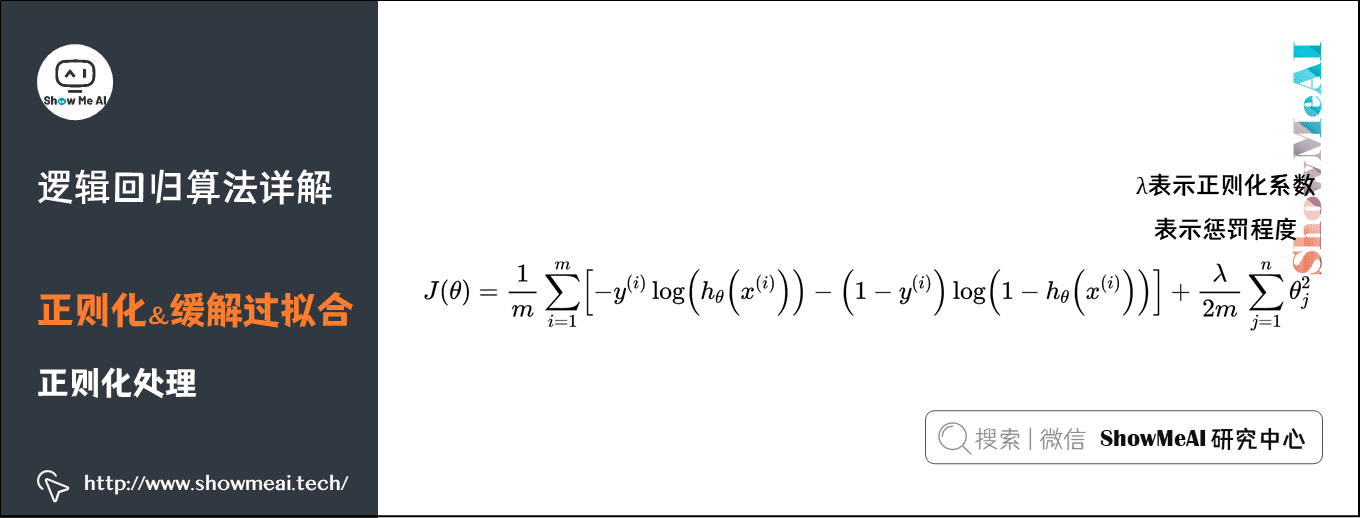
其中表示正则化系数,表示惩罚程度,的值越大,为使的值小,则参数的绝对值就得越小,通常对应于越光滑的函数,也就是更加简单的函数,因此不易发生过拟合的问题。我们依然可以采用梯度下降对加正则化项的损失函数进行优化。
6.特征变换与非线性表达
1)多项式特征
对于输入的特征,如果我们直接进行线性拟合再给到Sigmoid函数,得到的是线性决策边界。但添加多项式特征,可以对样本点进行多项式回归拟合,也能在后续得到更好的非线性决策边界。

多项式回归,回归函数是回归变量多项式。多项式回归模型是线性回归模型的一种,此时回归函数关于回归系数是线性的。
在实际应用中,通过增加一些输入数据的非线性特征来增加模型的复杂度通常是有效的。一个简单通用的办法是使用多项式特征,这可以获得特征的更高维度和互相间关系的项,进而获得更好的实验结果。
2)非线性切分
如下图所示,在逻辑回归中,拟合得到的决策边界,可以通过添加多项式特征,调整为非线性决策边界,具备非线性切分能力。
-中是参数,当时,此时得到的是线性决策边界;
-时,使用了多项式特征,得到的是非线性决策边界。

目的是低维线性不可分的数据转化到高维时,会变成线性可分。得到在高维空间下的线性分割参数映射回低维空间,形式上表现为低维的非线性切分。
更多监督学习的算法模型总结可以查看ShowMeAI的文章 AI知识技能速查 | 机器学习-监督学习。
视频教程
可以点击 B站 查看视频的【双语字幕】版本
【双语字幕+资料下载】MIT 6.036 | 机器学习导论(2020·完整版)
机器学习【算法】系列教程
- 图解机器学习 | 机器学习基础知识
- 图解机器学习 | 模型评估方法与准则
- 图解机器学习 | KNN算法及其应用
- 图解机器学习 | 逻辑回归算法详解
- 图解机器学习 | 朴素贝叶斯算法详解
- 图解机器学习 | 决策树模型详解
- 图解机器学习 | 随机森林分类模型详解
- 图解机器学习 | 回归树模型详解
- 图解机器学习 | GBDT模型详解
- 图解机器学习 | XGBoost模型最全解析
- 图解机器学习 | LightGBM模型详解
- 图解机器学习 | 支持向量机模型详解
- 图解机器学习 | 聚类算法详解
- 图解机器学习 | PCA降维算法详解
机器学习【实战】系列教程
- 机器学习实战 | Python机器学习算法应用实践
- 机器学习实战 | SKLearn入门与简单应用案例
- 机器学习实战 | SKLearn最全应用指南
- 机器学习实战 | XGBoost建模应用详解
- 机器学习实战 | LightGBM建模应用详解
- 机器学习实战 | Python机器学习综合项目-电商销量预估
- 机器学习实战 | Python机器学习综合项目-电商销量预估<进阶方案>
- 机器学习实战 | 机器学习特征工程最全解读
- 机器学习实战 | 自动化特征工程工具Featuretools应用
- 机器学习实战 | AutoML自动化机器学习建模
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?