
图解大数据 | Spark GraphFrames-基于图的数据分析挖掘
 GraphFrames库构建在DataFrame之上,具备DataFrame强大的性能,也提供了统一的图处理API。本文讲解GraphFrames的构建使用,包括query与数据分析、图中点与边的计算、图入度与出度的应用等。
GraphFrames库构建在DataFrame之上,具备DataFrame强大的性能,也提供了统一的图处理API。本文讲解GraphFrames的构建使用,包括query与数据分析、图中点与边的计算、图入度与出度的应用等。

作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/84
本文地址:https://www.showmeai.tech/article-detail/182
声明:版权所有,转载请联系平台与作者并注明出处
1.GraphFrames介绍
由Databricks、UC Berkeley以及MIT联合为Apache Spark开发了一款图处理类库,名为GraphFrames。该类库构建在DataFrame之上,既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。
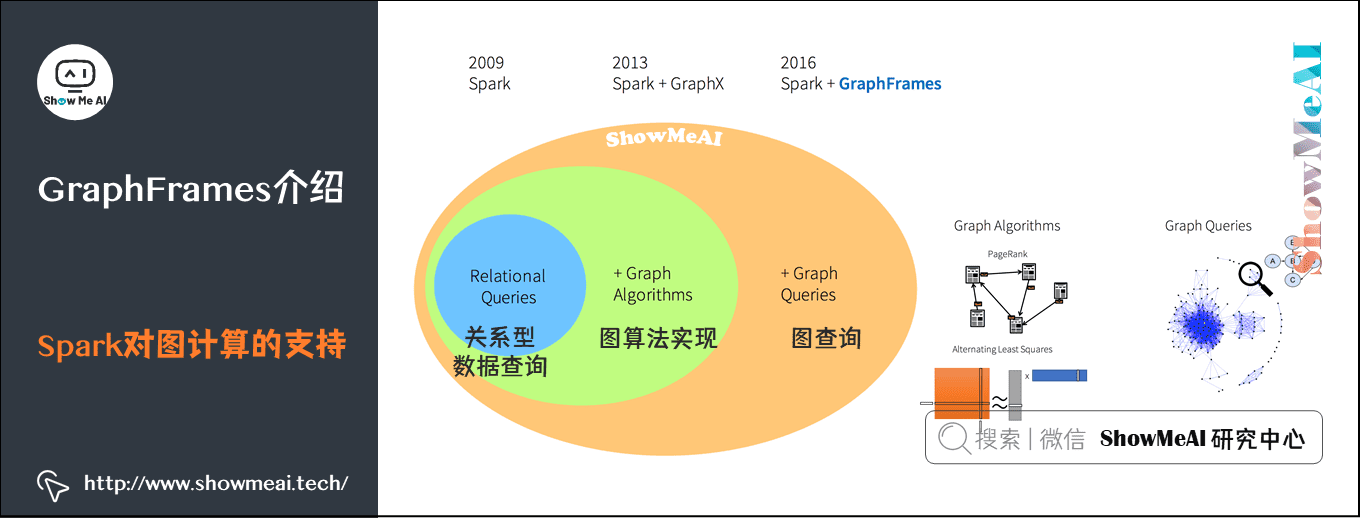
1) Spark对图计算的支持
Spark从最开始的关系型数据查询,到图算法实现,到GraphFrames库可以完成图查询。
2) GraphFrames的优势
GraphFrames是类似于Spark的GraphX库,支持图处理。但GraphFrames建立在Spark DataFrame之上,具有以下重要的优势:
-
支持Scala,Java 和Python AP:GraphFrames提供统一的三种编程语言APIs,而GraphX的所有算法支持Python和Java。
-
方便、简单的图查询:GraphFrames允许用户使用Spark SQL和DataFrame的API查询。
-
支持导出和导入图:GraphFrames支持DataFrame数据源,使得可以读取和写入多种格式的图,比如Parquet、JSON和CSV格式。
2.构建GraphFrames
- 获取数据集与代码 → ShowMeAI的官方GitHub https://github.com/ShowMeAI-Hub/awesome-AI-cheatsheets
- 运行代码段与学习 → 在线编程环境 http://blog.showmeai.tech/python3-compiler
以航班分析为例,我们需要构建GraphFrames:
- ① 先把数据读取成DataFrame。
- ② 再通过DataFrame查询,构建出点和边。
- ③ 再通过点和边构建GraphFrames。

# Create Vertices (airports) and Edges (flights)
tripVertices=airports.withColumnRenamed("IATA","id").distinct()
tripEdges=departureDelays
.select("tripid","delay","src","dst","city_dst","state_dst")
# This GraphFrame builds upon the vertices and edges based on our trips (flights)
tripGraph=GraphFrame(tripVertices, tripEdges)
3.简单query与数据分析
1) 查询机场个数和行程个数

# 查询机场个数和行程个数(查询节点和边的个数)
print("Airports:", tripGraph.vertices.count())
print("Trips:", tripGraph.edges.count())
2) 查询最长的航班延迟

# 查询最长延误时间(通过分组统计完成)
longestDelay = tripGraph.edges.groupby().max("delay")
3) 晚点与准点航班分析

# 晚点与准点航班分析(通过数据选择与过滤,进行边的分析)
print "On-time / Early Flights: %d" % tripGraph.edges.filter("delay <= 0").count()
print "Delayed Flights: %d" % tripGraph.edges.filter("delay > 0").count()
4)从旧金山出发的飞机中延迟最严重的航班

# 从旧金山出发的飞机中延迟最严重的航班(数据选择+边分析+分组统计)
tripGraph.edges.filter(“src = ‘SFO’ and delay > 0”).groupBy(“src”, “dst”).avg(“delay”).sort(desc(“avg(delay)”))
4.图中点与边相关计算
- 获取数据集与代码 → ShowMeAI的官方GitHub https://github.com/ShowMeAI-Hub/awesome-AI-cheatsheets
- 运行代码段与学习 → 在线编程环境 http://blog.showmeai.tech/python3-compiler
1) 图中度的分析
在航班案例中:入度:抵达本机场的航班数量;出度:从本机场出发的航班数量;度:连接数量。
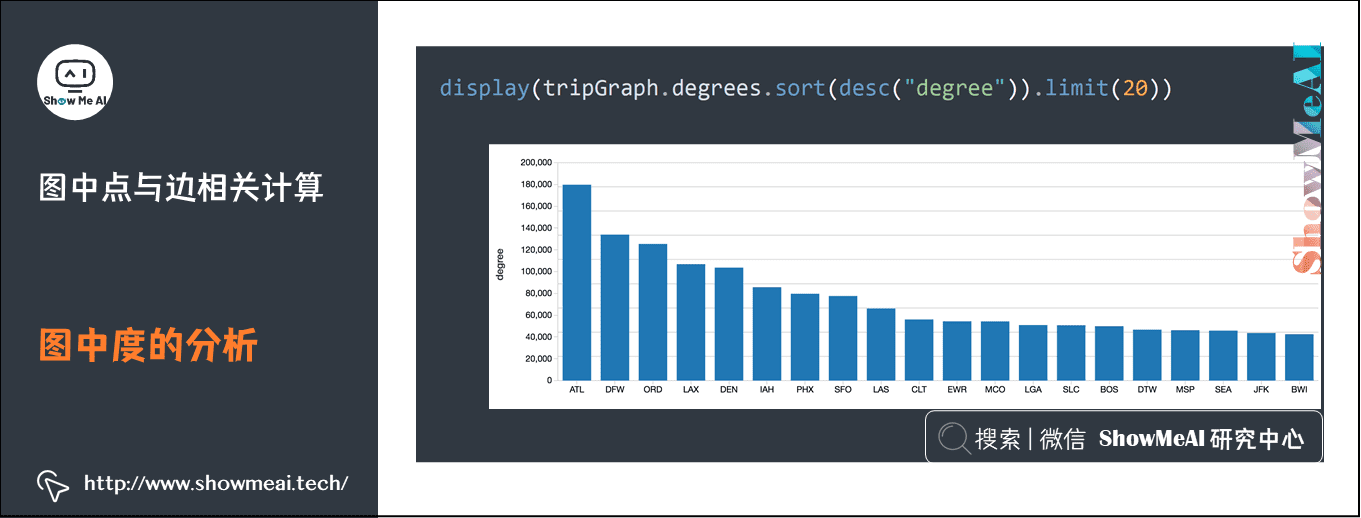
display(tripGraph.degrees.sort(desc("degree")).limit(20))
2) 图中边的分析
边的分析,通常是对成对的数据进行统计分析的
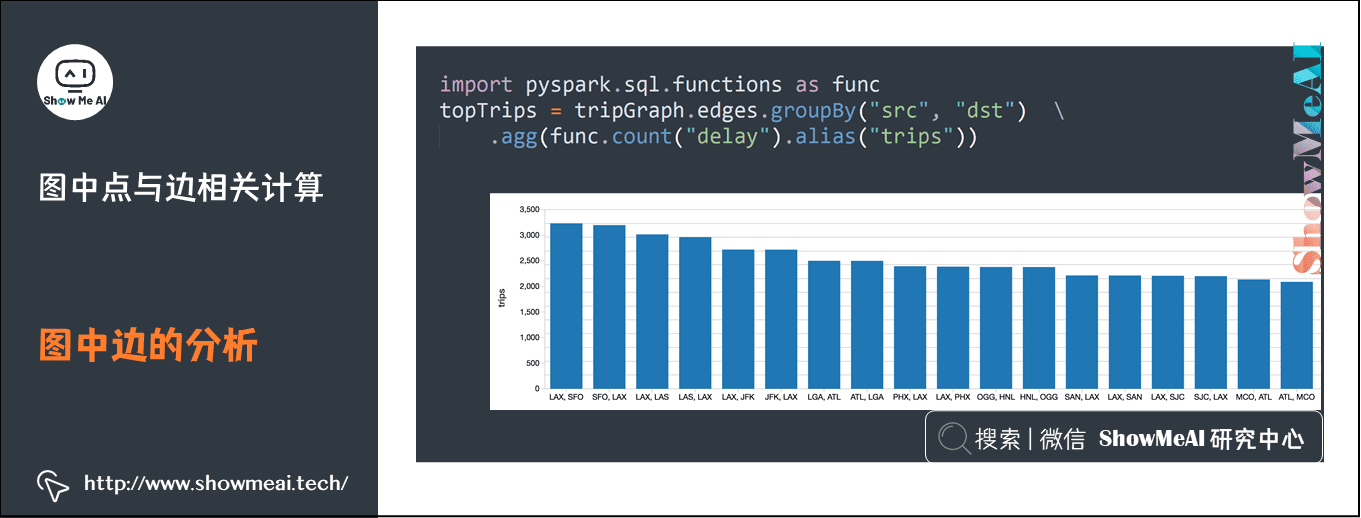
import pyspark.sql.functions as func
topTrips = tripGraph.edges.groupBy("src", "dst").agg(func.count("delay").alias("trips"))
5.图入度与出度相关应用
- 获取数据集与代码 → ShowMeAI的官方GitHub https://github.com/ShowMeAI-Hub/awesome-AI-cheatsheets
- 运行代码段与学习 → 在线编程环境 http://blog.showmeai.tech/python3-compiler
1) 入度出度对图进一步分析
通过入度和出度分析中转站:入度/出度≈1,中转站;入度/出度>1,出发站;入度/出度<1,抵达站。
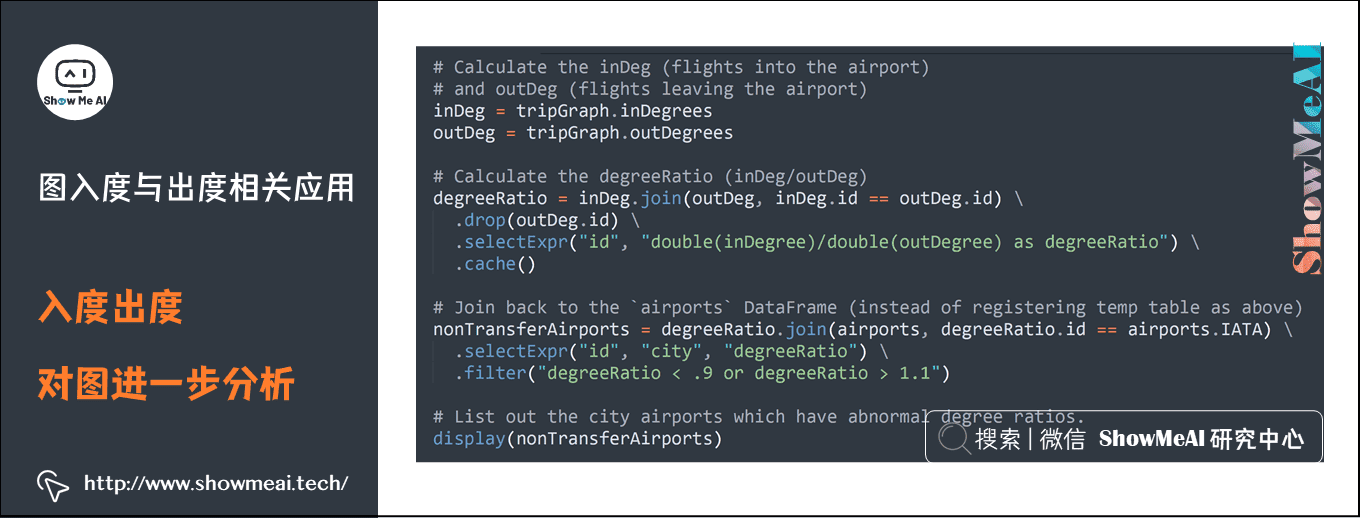

# Calculate the inDeg (flights into the airport) and outDeg (flights leaving the airport)
inDeg = tripGraph.inDegrees
outDeg = tripGraph.outDegrees
# Calculate the degreeRatio (inDeg/outDeg)
degreeRatio = inDeg.join(outDeg, inDeg.id == outDeg.id).drop(outDeg.id).selectExpr("id", "double(inDegree)/double(outDegree) as degreeRatio").cache()
# Join back to the `airports` DataFrame (instead of registering temp table as above)
nonTransferAirports = degreeRatio.join(airports, degreeRatio.id == airports.IATA) \
.selectExpr("id", "city", "degreeRatio").filter("degreeRatio < .9 or degreeRatio > 1.1")
# List out the city airports which have abnormal degree ratios.
display(nonTransferAirports)

# Join back to the `airports` DataFrame (instead of registering temp table as above)
transferAirports = degreeRatio.join(airports, degreeRatio.id == airports.IATA) \
.selectExpr("id", "city", "degreeRatio").filter("degreeRatio between 0.9 and 1.1")
# List out the top 10 transfer city airports
display(transferAirports.orderBy("degreeRatio").limit(10))
2) 广度优先搜索
通过广度优先搜索,可以对图中的两个点进行关联查询:比如我们查询从旧金山到布法罗,中间有一次中转的航班。


# Example 1: Direct Seattle to San Francisco
filteredPaths = tripGraph.bfs(fromExpr = "id = 'SEA'", toExpr = "id = 'SFO'", maxPathLength = 1)
display(filteredPaths)
# Example 2: Direct San Francisco and Buffalo
filteredPaths = tripGraph.bfs(fromExpr = "id = 'SFO'", toExpr = "id = 'BUF'", maxPathLength = 1)
display(filteredPaths)
# Example 2a: Flying from San Francisco to Buffalo
filteredPaths = tripGraph.bfs(fromExpr = "id = 'SFO'", toExpr = "id = 'BUF'", maxPathLength = 2)
display(filteredPaths)
6.Pagerank算法与相关应用
可以通过pagerank算法进行机场排序:每个机场都会作为始发站和终点站很多次,可以通过pagerank算法对其重要度进行排序。
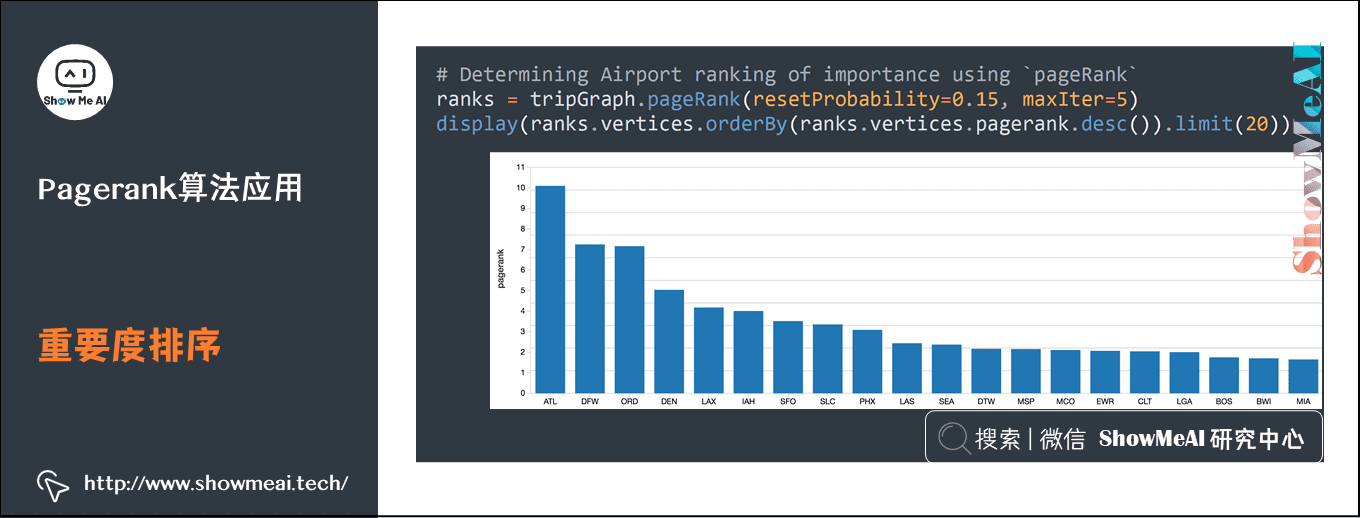
# Determining Airport ranking of importance using `pageRank`
ranks = tripGraph.pageRank(resetProbability=0.15, maxIter=5)
display(ranks.vertices.orderBy(ranks.vertices.pagerank.desc()).limit(20))
7.参考资料
- 数据科学工具速查 | Spark使用指南(RDD版) https://www.showmeai.tech/article-detail/106
- 数据科学工具速查 | Spark使用指南(SQL版) https://www.showmeai.tech/article-detail/107
- SparkGraphx官方文档,http://spark.apachecn.org/docs/cn/2.2.0/graphx-programming-guide.html
- pregel 与 spark graphX 的 pregel api:https://blog.csdn.net/u013468917/article/details/51199808
- 浅谈GraphX:https://blog.csdn.net/shangwen_/article/details/38645601
- SparkGraphX介绍:https://blog.csdn.net/oanqoanq/article/details/79559223
【大数据技术与处理】推荐阅读
- 图解大数据 | 大数据生态与应用导论
- 图解大数据 | 分布式平台Hadoop与Map-Reduce详解
- 图解大数据 | Hadoop系统搭建与环境配置@实操案例
- 图解大数据 | 应用Map-Reduce进行大数据统计@实操案例
- 图解大数据 | Hive搭建与应用@实操案例
- 图解大数据 | Hive与HBase详解@海量数据库查询
- 图解大数据 | 大数据分析挖掘框架@Spark初步
- 图解大数据 | 基于RDD大数据处理分析@Spark操作
- 图解大数据 | 基于Dataframe / SQL大数据处理分析@Spark操作
- 图解大数据 | 使用Spark分析新冠肺炎疫情数据@综合案例
- 图解大数据 | 使用Spark分析挖掘零售交易数据@综合案例
- 图解大数据 | 使用Spark分析挖掘音乐专辑数据@综合案例
- 图解大数据 | Spark Streaming @流式数据处理
- 图解大数据 | 工作流与特征工程@Spark机器学习
- 图解大数据 | 建模与超参调优@Spark机器学习
- 图解大数据 | GraphFrames @基于图的数据分析挖掘
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读


 浙公网安备 33010602011771号
浙公网安备 33010602011771号