
图解大数据 | Spark机器学习(上)-工作流与特征工程
 本文介绍Spark中用于大数据机器学习的板块MLlib/ML,讲解机器学习工作流(Pipeline)及其构建方式,并详解讲解基于DataFrame的Spark ML特征工程,包括二值化、定边界离散化、标准化、特征抽取等。
本文介绍Spark中用于大数据机器学习的板块MLlib/ML,讲解机器学习工作流(Pipeline)及其构建方式,并详解讲解基于DataFrame的Spark ML特征工程,包括二值化、定边界离散化、标准化、特征抽取等。

作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/84
本文地址:https://www.showmeai.tech/article-detail/180
声明:版权所有,转载请联系平台与作者并注明出处
1.Spark机器学习工作流
1)Spark mllib 与ml
Spark中同样有用于大数据机器学习的板块MLlib/ML,可以支持对海量数据进行建模与应用。

2)机器学习工作流(Pipeline)
一个典型的机器学习过程,从数据收集开始,要经历多个步骤,才能得到需要的输出。是一个包含多个步骤的流水线式工作:
- 源数据ETL(抽取、转化、加载)
- 数据预处理
- 指标提取
- 模型训练与交叉验证
- 新数据预测
MLlib 已足够简单易用,但在一些情况下使用 MLlib 将会让程序结构复杂,难以理解和实现。
- 目标数据集结构复杂需要多次处理。
- 对新数据进行预测的时候,需要结合多个已经训练好的单个模型进行综合预测 Spark 1.2 版本之后引入的 ML Pipeline,可以用于构建复杂机器学习工作流应用。
以下是几个重要概念的解释:
(1)DataFrame
使用Spark SQL中的 DataFrame 作为数据集,可以容纳各种数据类型。较之 RDD,DataFrame 包含了 schema 信息,更类似传统数据库中的二维表格。
它被 ML Pipeline 用来存储源数据,例如DataFrame 中的列可以是存储的文本、特征向量、真实标签和预测的标签等。
(2)Transformer(转换器)
是一种可以将一个DataFrame 转换为另一个DataFrame 的算法。比如,一个模型就是一个 Transformer,它可以把一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。
技术上,Transformer实现了一个方法transform(),通过附加一个或多个列将一个 DataFrame 转换为另一个DataFrame。
(3)Estimator(估计器/评估器)
是学习算法或在训练数据上的训练方法的概念抽象。在 Pipeline 里通常是被用来操作 DataFrame 数据,并生产一个 Transformer。从技术上讲,Estimator 实现了一个方法fit(),它接受一个DataFrame 并产生一个Transformer转换器。
(4)Parameter
Parameter 被用来设置 Transformer 或者 Estimator 的参数。现在,所有 Transformer(转换器)和Estimator(估计器)可共享用于指定参数的公共API。ParamMap是一组(参数,值)对。
(5)PipeLine(工作流/管道)
工作流将多个工作流阶段( Transformer转换器和Estimator估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
3)构建一个Pipeline工作流
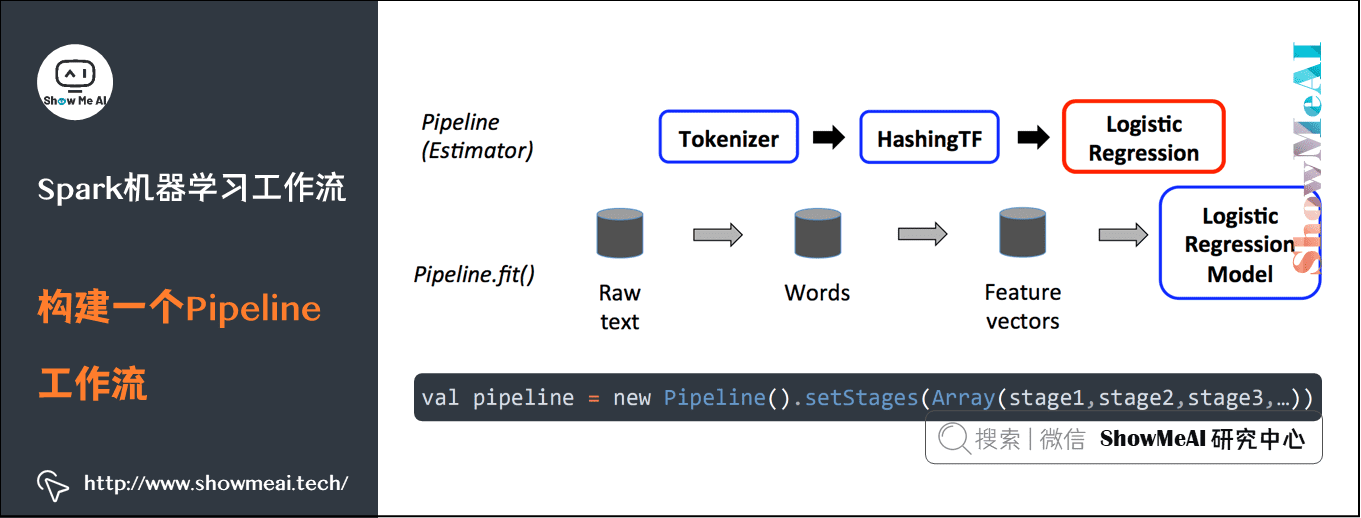
val pipeline = new Pipeline().setStages(Array(stage1,stage2,stage3,…))
① 首先需要定义 Pipeline 中的各个PipelineStage(工作流阶段)。
- 包括Transformer转换器 和Estimator评估器。
- 比如指标提取 和 转换模型训练。
- 有了这些处理特定问题的Transformer转换器和 Estimator评估器,就可以按照具体的处理逻辑,有序地组织PipelineStages,并创建一个Pipeline。
② 然后,可以把训练数据集作为入参,并调用 Pipelin 实例的 fit 方法,开始以流的方式来处理源训练数据。
- 这个调用会返回一个 PipelineModel 类实例,进而被用来预测测试数据的标签
③ 工作流的各个阶段按顺序运行,输入的DataFrame在它通过每个阶段时被转换。
- 对于 Transformer转换器阶段,在DataFrame上调用
transform()方法。 - 对于Estimator估计器阶段,调用fit()方法来生成一个转换器(它成为PipelineModel的一部分或拟合的Pipeline),并且在DataFrame上调用该转换器的
transform()方法。
4)构建Pipeline示例
- 获取数据集与代码 → ShowMeAI的官方GitHub https://github.com/ShowMeAI-Hub/awesome-AI-cheatsheets
- 运行代码段与学习 → 在线编程环境 http://blog.showmeai.tech/python3-compiler
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer # Prepare training documents from a list of (id, text, label) tuples. training = spark.createDataFrame([ (0, "a b c d e spark", 1.0), (1, "b d", 0.0), (2, "spark f g h", 1.0), (3, "hadoop mapreduce", 0.0) ], ["id", "text", "label"]) # Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr. tokenizer = Tokenizer(inputCol="text", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.001) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr]) # Fit the pipeline to training documents. model = pipeline.fit(training) # Prepare test documents, which are unlabeled (id, text) tuples. test = spark.createDataFrame([ (4, "spark i j k"), (5, "l m n"), (6, "spark hadoop spark"), (7, "apache hadoop") ], ["id", "text"]) # Make predictions on test documents and print columns of interest. prediction = model.transform(test) selected = prediction.select("id", "text", "probability", "prediction") for row in selected.collect(): rid, text, prob, prediction = row # type: ignore print( "(%d, %s) --> prob=%s, prediction=%f" % ( rid, text, str(prob), prediction # type: ignore ) )
2.基于DataFrame的Spark ML特征工程
- 获取数据集与代码 → ShowMeAI的官方GitHub https://github.com/ShowMeAI-Hub/awesome-AI-cheatsheets
- 运行代码段与学习 → 在线编程环境 http://blog.showmeai.tech/python3-compiler
1)特征工程
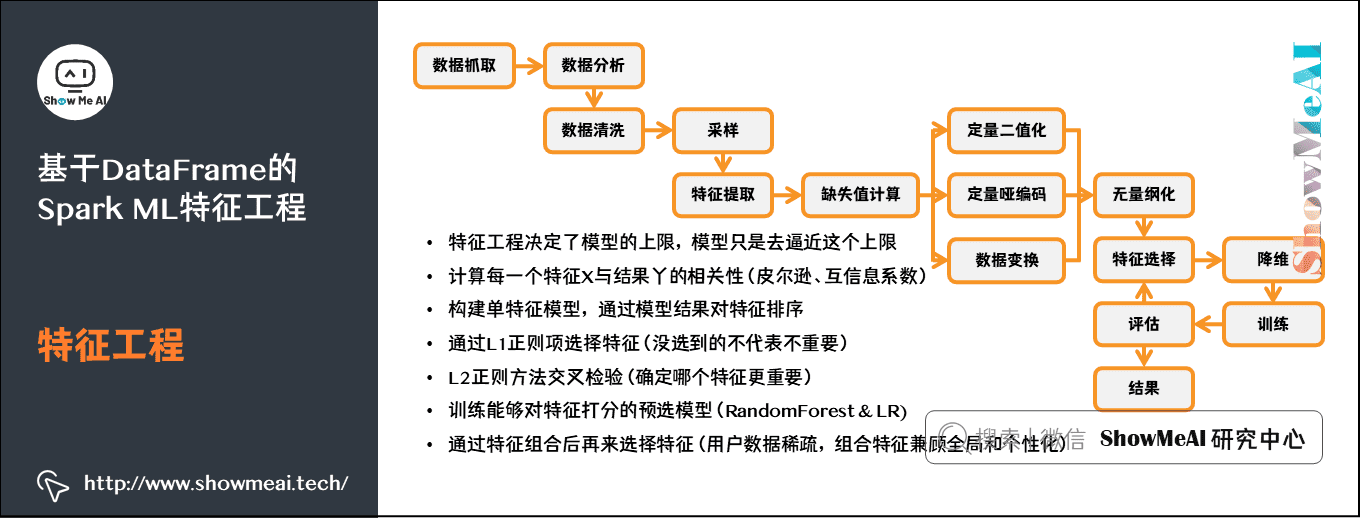
2)二值化
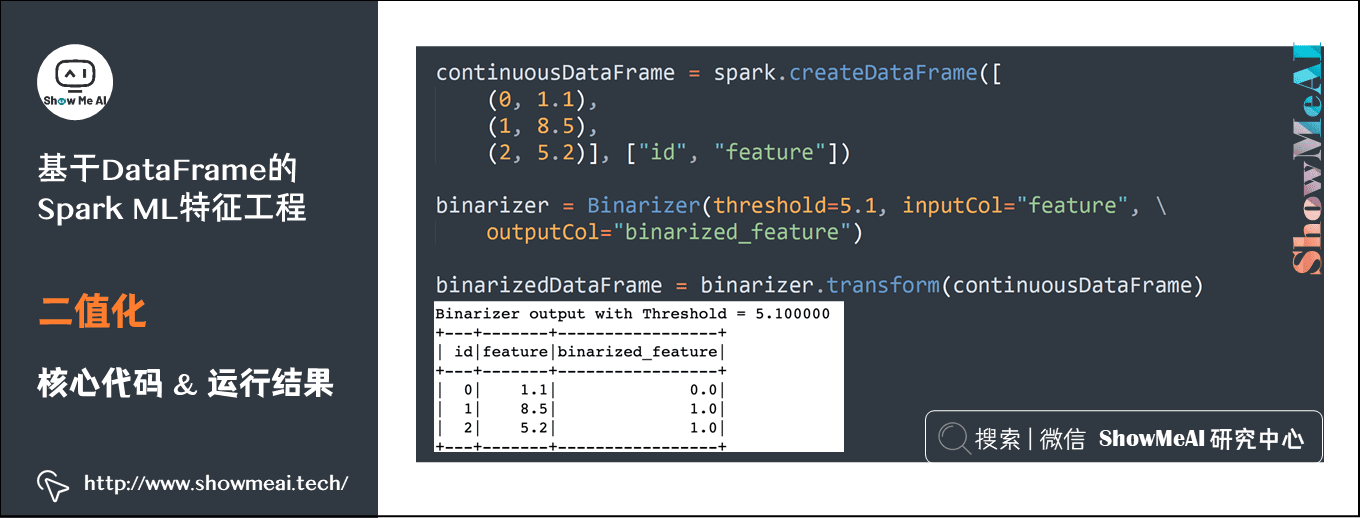
continuousDataFrame = spark.createDataFrame([(0, 1.1),(1, 8.5),(2, 5.2)], ["id", "feature"]) binarizer = Binarizer(threshold=5.1, inputCol="feature", outputCol="binarized_feature") binarizedDataFrame = binarizer.transform(continuousDataFrame)
3)定边界离散化

splits = [-float("inf"), -0.5, 0.0, 0.5, float("inf")] data = [(-999.9,),(-0.5,),(-0.3,),(0.0,),(0.2,),(999.9,)] dataFrame = spark.createDataFrame(data, ["features"]) bucketizer = Bucketizer(splits=splits, inputCol="features", outputCol="bucketedFeatures") # 按照给定的边界进行分桶 bucketedData = bucketizer.transform(dataFrame)
4)按照分位数离散化
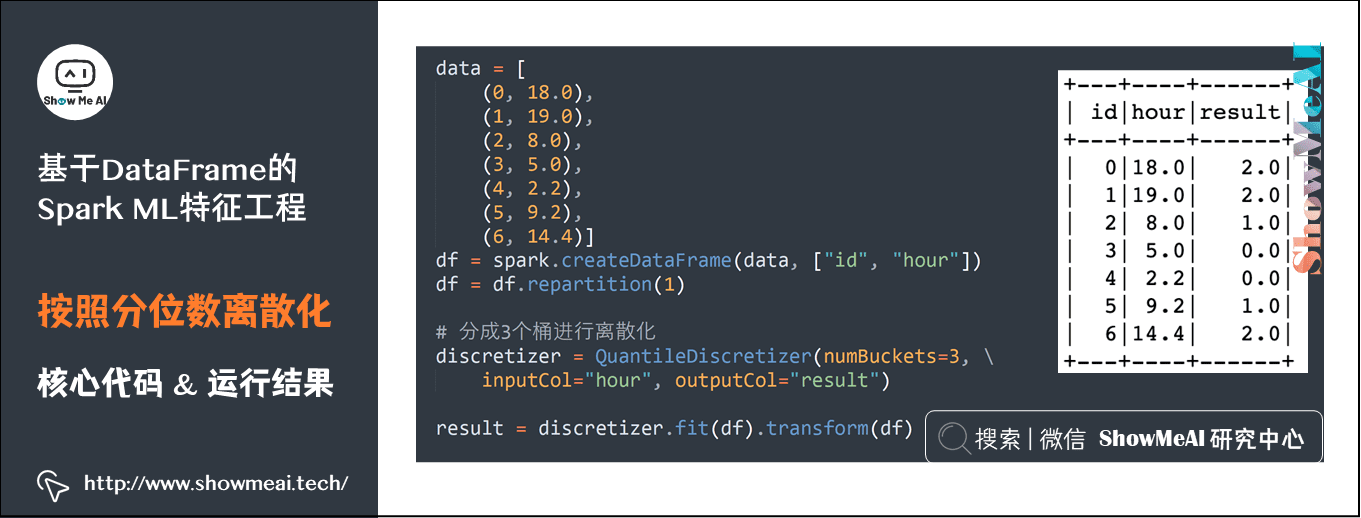
data = [(0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2), (5, 9.2), (6, 14.4)] df = spark.createDataFrame(data, ["id", "hour"]) df = df.repartition(1) # 分成3个桶进行离散化 discretizer = QuantileDiscretizer(numBuckets=3, inputCol="hour", outputCol="result") result = discretizer.fit(df).transform(df)
5)连续值幅度缩放
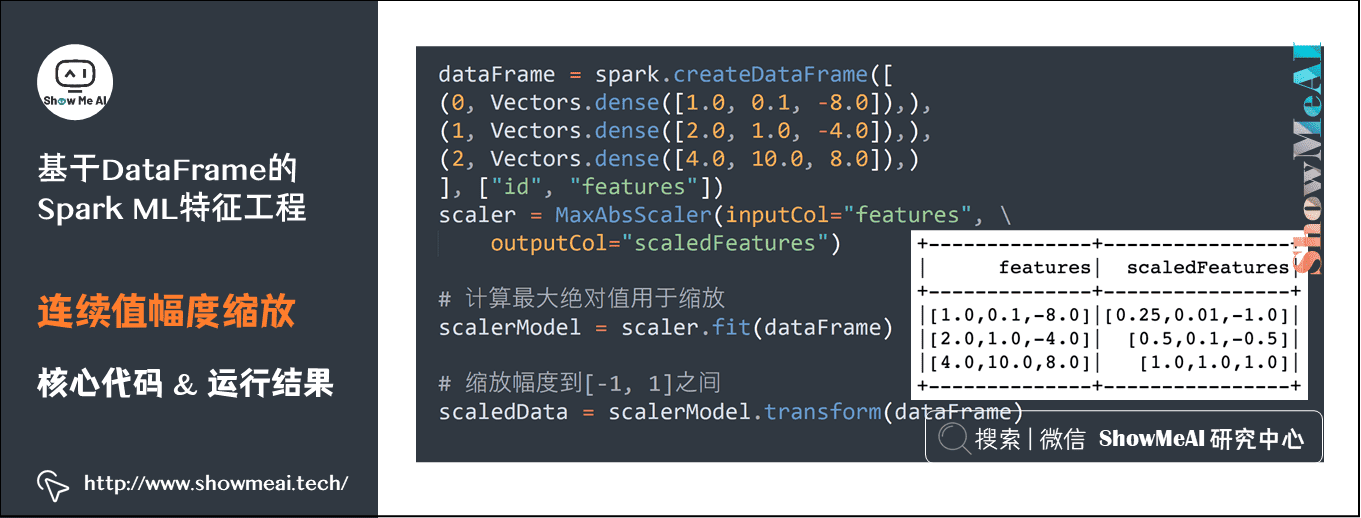
dataFrame = spark.createDataFrame([ (0, Vectors.dense([1.0, 0.1, -8.0]),), (1, Vectors.dense([2.0, 1.0, -4.0]),), (2, Vectors.dense([4.0, 10.0, 8.0]),) ], ["id", "features"]) scaler = MaxAbsScaler(inputCol="features", outputCol="scaledFeatures") # 计算最大绝对值用于缩放 scalerModel = scaler.fit(dataFrame) # 缩放幅度到[-1, 1]之间 scaledData = scalerModel.transform(dataFrame)
6)标准化
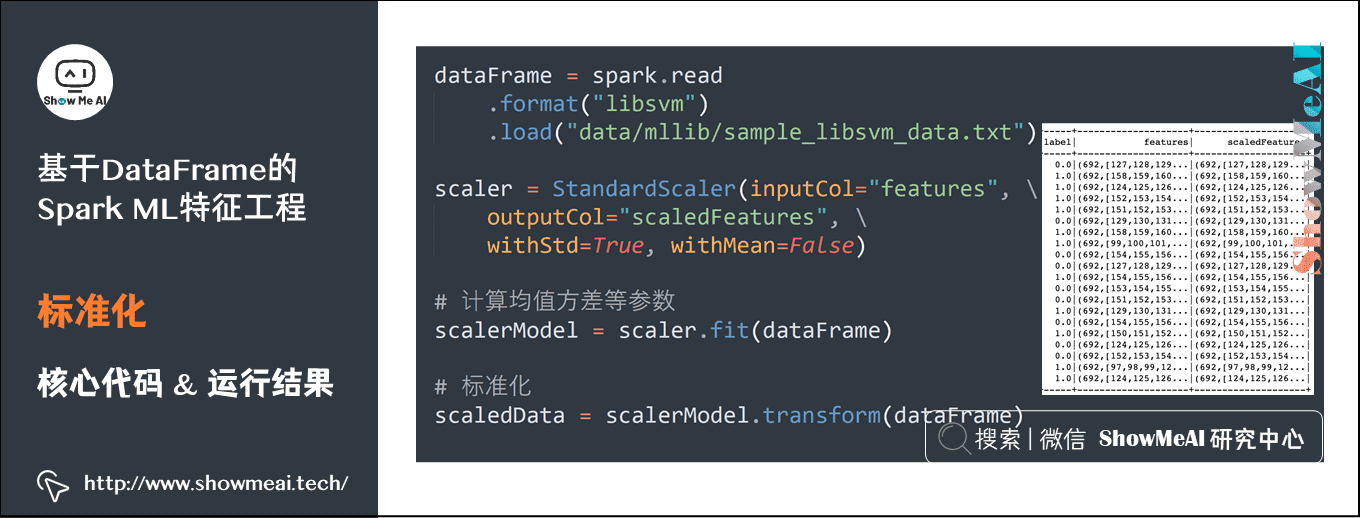
dataFrame = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt") scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures", withStd=True, withMean=False) # 计算均值方差等参数 scalerModel = scaler.fit(dataFrame) # 标准化 scaledData = scalerModel.transform(dataFrame)
7)添加多项式特征
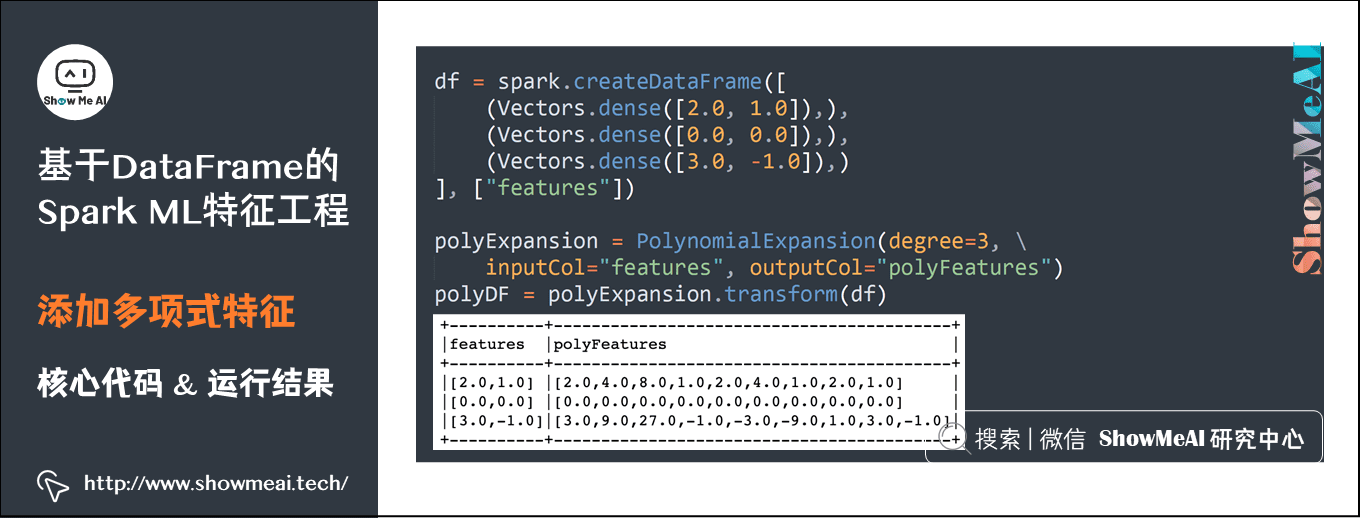
df = spark.createDataFrame([(Vectors.dense([2.0, 1.0]),), (Vectors.dense([0.0, 0.0]),), (Vectors.dense([3.0, -1.0]),)], ["features"]) polyExpansion = PolynomialExpansion(degree=3, inputCol="features", outputCol="polyFeatures") polyDF = polyExpansion.transform(df)
8)类别型独热向量编码

df = spark.createDataFrame([ (0,"a"), (1,"b"), (2,"c"), (3,"a"), (4,"a"), (5,"c")], ["id","category"]) stringIndexer = StringIndexer(inputCol="category", outputCol="categoryIndex") model = stringIndexer.fit(df) indexed = model.transform(df) encoder = OneHotEncoder(inputCol="categoryIndex", outputCol="categoryVec") encoded = encoder.transform(indexed)
9)文本型特征抽取

df = spark.createDataFrame([(0, "a b c".split(" ")), (1, "a b b c a".split(" "))], ["id", "words"]) cv = CountVectorizer(inputCol="words", outputCol="features", vocabSize=3, minDF=2.0) model = cv.fit(df) result = model.transform(df)
10)文本型特征抽取
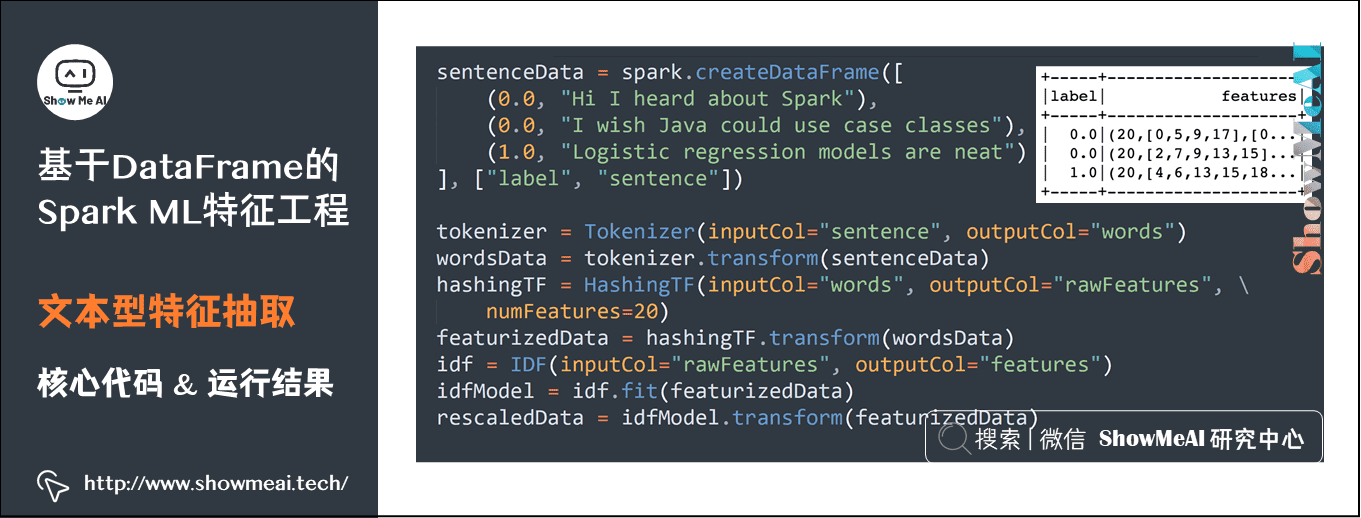
sentenceData = spark.createDataFrame([ (0.0, "Hi I heard about Spark"), (0.0, "I wish Java could use case classes"), (1.0, "Logistic regression models are neat") ], ["label", "sentence"]) tokenizer = Tokenizer(inputCol="sentence", outputCol="words") wordsData = tokenizer.transform(sentenceData) hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20) featurizedData = hashingTF.transform(wordsData) idf = IDF(inputCol="rawFeatures", outputCol="features") idfModel = idf.fit(featurizedData) rescaledData = idfModel.transform(featurizedData)
3.参考资料
- 数据科学工具速查 | Spark使用指南(RDD版) https://www.showmeai.tech/article-detail/106
- 数据科学工具速查 | Spark使用指南(SQL版) https://www.showmeai.tech/article-detail/107
- 黄美灵,Spark MLlib机器学习:算法、源码及实战详解, 电子工业出版社,2016
- 使用 ML Pipeline 构建机器学习工作流https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice5/index.html
- Spark官方文档:机器学习库 (MLlib) 指南,http://spark.apachecn.org/docs/cn/2.2.0/ml-guide.html
【大数据技术与处理】推荐阅读
- 图解大数据 | 大数据生态与应用导论
- 图解大数据 | 分布式平台Hadoop与Map-Reduce详解
- 图解大数据 | Hadoop系统搭建与环境配置@实操案例
- 图解大数据 | 应用Map-Reduce进行大数据统计@实操案例
- 图解大数据 | Hive搭建与应用@实操案例
- 图解大数据 | Hive与HBase详解@海量数据库查询
- 图解大数据 | 大数据分析挖掘框架@Spark初步
- 图解大数据 | 基于RDD大数据处理分析@Spark操作
- 图解大数据 | 基于Dataframe / SQL大数据处理分析@Spark操作
- 图解大数据 | 使用Spark分析新冠肺炎疫情数据@综合案例
- 图解大数据 | 使用Spark分析挖掘零售交易数据@综合案例
- 图解大数据 | 使用Spark分析挖掘音乐专辑数据@综合案例
- 图解大数据 | Spark Streaming @流式数据处理
- 图解大数据 | 工作流与特征工程@Spark机器学习
- 图解大数据 | 建模与超参调优@Spark机器学习
- 图解大数据 | GraphFrames @基于图的数据分析挖掘
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人