
图解大数据 | 大数据分析挖掘-Spark初步
 Apache Spark是目前最主流和常用的分布式开源处理系统,支持跨多个工作负载重用代码—批处理、交互式查询、实时分析、机器学习和图形处理等。本节ShowMeAI给大家讲解它的相关知识。
Apache Spark是目前最主流和常用的分布式开源处理系统,支持跨多个工作负载重用代码—批处理、交互式查询、实时分析、机器学习和图形处理等。本节ShowMeAI给大家讲解它的相关知识。

作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/84
本文地址:https://www.showmeai.tech/article-detail/173
声明:版权所有,转载请联系平台与作者并注明出处
1.Spark是什么
学习或做大数据开发的同学,都听说或者使用过Spark,从这部分开始,ShowMeAI带大家一起来学习一下Spark相关的知识。
Apache Spark是一种用于大数据工作负载的分布式开源处理系统。它使用内存中缓存和优化的查询执行方式,可针对任何规模的数据进行快速分析查询。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量的廉价硬件之上,形成集群。
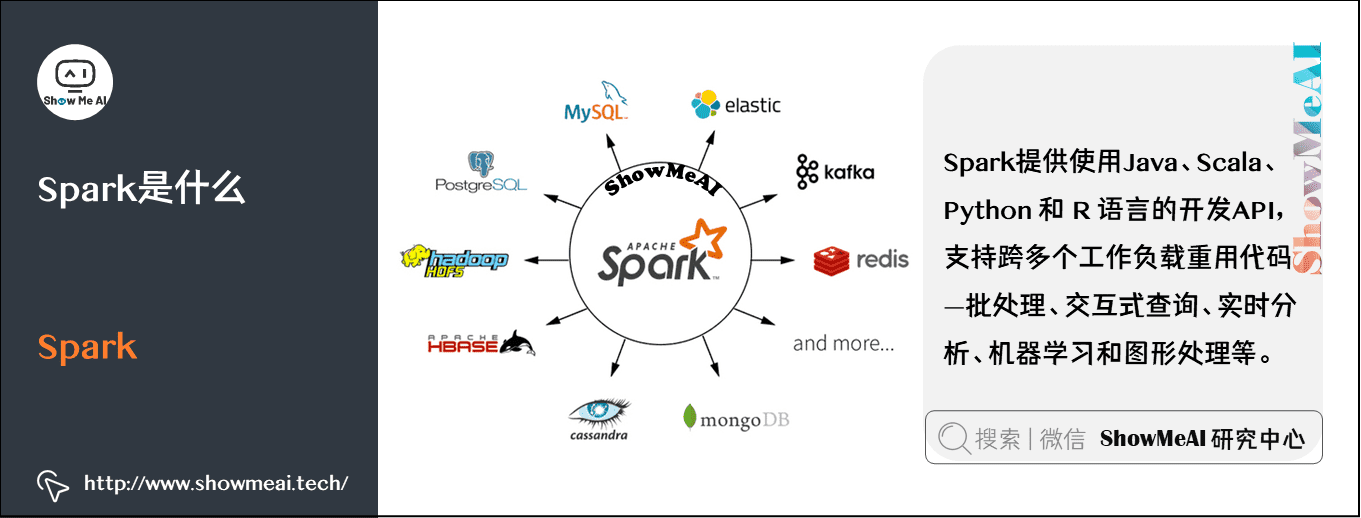
Spark提供使用Java、Scala、Python 和 R 语言的开发 API,支持跨多个工作负载重用代码—批处理、交互式查询、实时分析、机器学习和图形处理等。Apache Spark 已经成为最受欢迎的大数据分布式处理框架之一。
2.Spark的特点
Apache Spark是个开源和兼容Hadoop的集群计算平台。由加州大学伯克利分校的AMPLabs开发,作为Berkeley Data Analytics Stack(BDAS)的一部分,当下由大数据公司Databricks保驾护航,更是Apache旗下的顶级项目。
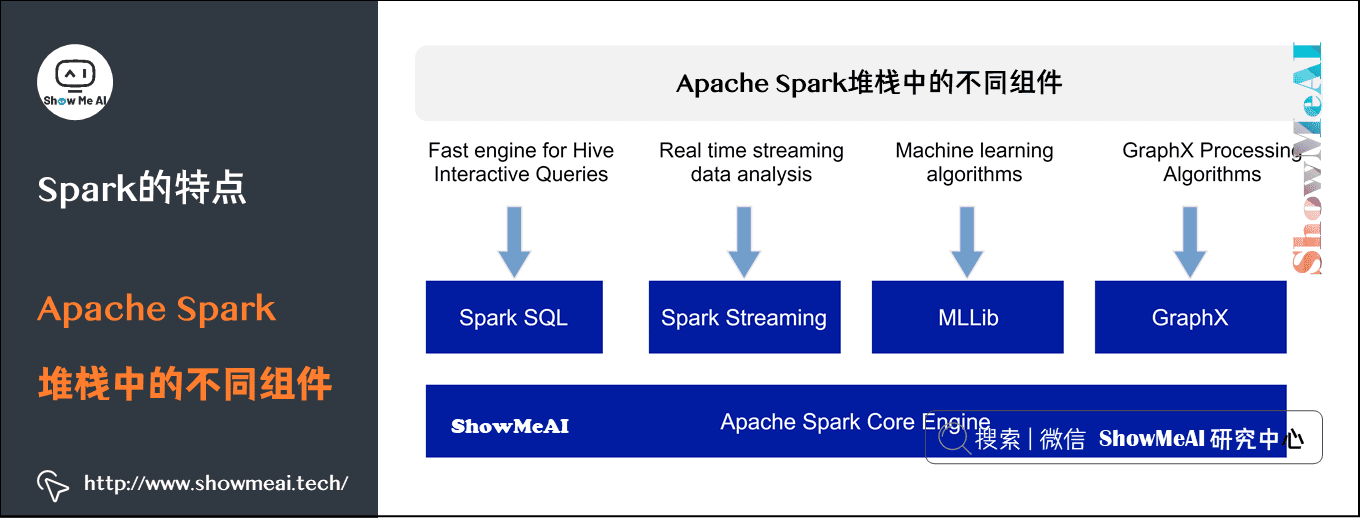
1)Apache Spark堆栈中的不同组件
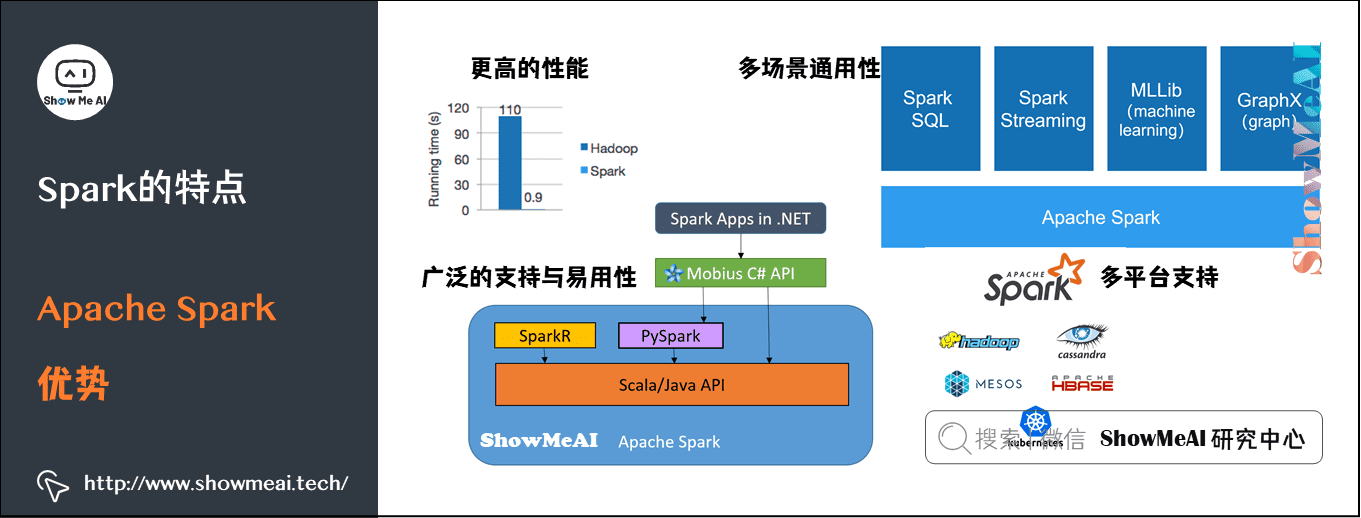
2)Apache Spark的优势
-
更高的性能:因为数据被加载到集群主机的分布式内存中。数据可以被快速的转换迭代,并缓存用以后续的频繁访问需求。在数据全部加载到内存的情况下,Spark有时能达到比Hadoop快100倍的数据处理速度,即使内存不够存放所有数据的情况也能快Hadoop 10倍。
-
广泛的支持与易用性:通过建立在Java、Scala、Python、SQL(应对交互式查询)的标准API以方便各行各业使用,同时还含有大量开箱即用的机器学习库。
-
多场景通用性:Spark集成了一系列的库,包括SQL和DataFrame帮助你快速完成数据处理;Mllib帮助你完成机器学习任务;Spark streaming做流式计算。
-
多平台支持:Spark可以跑在Hadoop、Apache Mesos、Kubernetes等之上,可以从HDFS、Alluxio、Apache Cassandra、Apache Hive以及其他的上百个数据源获取数据。
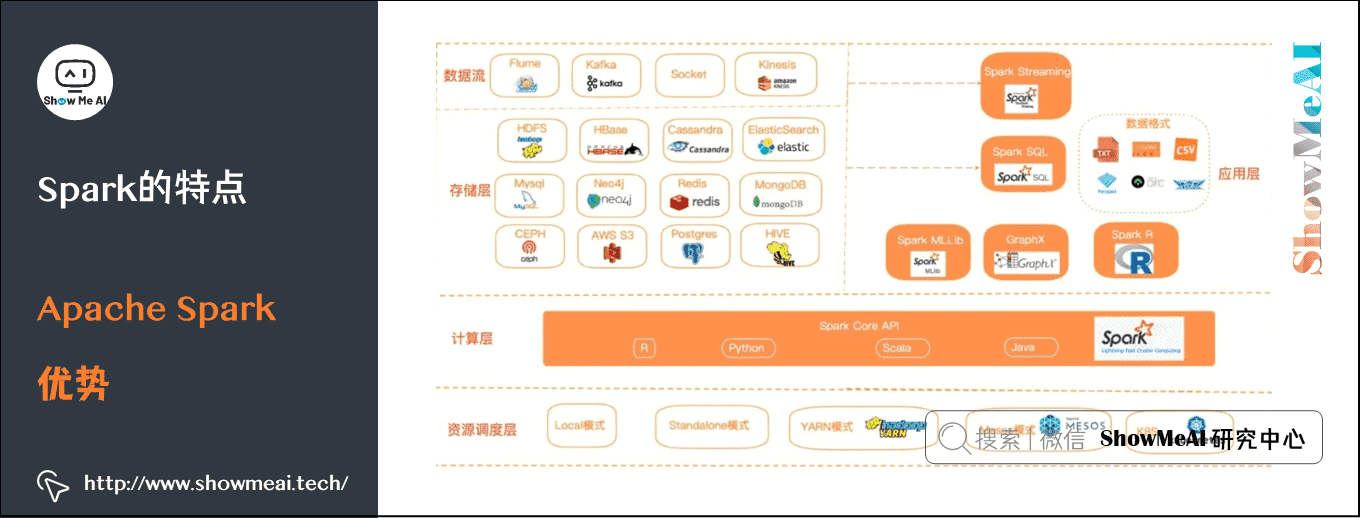
3.Spark作业与调度
Spark的核心是作业和任务调度系统,它可以保障各种任务高效完整地运行。
1)Spark作业和任务调度系统
Spark通过作业和任务调度系统,能够有效地进行调度完成各种任务,底层的巧妙设计是对任务划分DAG和容错,使得它对低层到顶层的各个模块之间的调用和处理显得游刃有余。

2)基本概念一览
| 概念 | 解释 |
|---|---|
| 作业(Job) | RDD中由行动操作所生成的一个或多个调度阶段。 |
| 调度阶段(Stage) | 每个Job作业会因为RDD之间的依赖关系拆分成多组任务集合,称为调度阶段,简称阶段,也叫做任务集(TaskSet)。调度阶段的划分是由DAGScheduler(DAG调度器)来划分的。调度阶段有Shuffle Map Stage和Result Stage两种。 |
| 任务(Task) | 分发到Executor上的工作任务,是Spark实际执行应用的最小单元。Task会对RDD的partition数据执行指定的算子操作,比如flatMap、map、reduce等算子操作,形成新RDD的partition。 |
| DAGScheduler(DAG调度器) | DAGScheduler是面向Stage(阶段)的任务调度器,负责接收Spark应用提交的作业,根据RDD的依赖关系划分调度阶段,并提交Stage(阶段)给TaskScheduler。 |
| TaskScheduler(任务调度器) | TaskScheduler是面向任务的调度器,它接收DAGScheduler提交过来的Stage(阶段),然后把任务分发到Worker节点运行,由Worker节点的Executor来运行该任务。 |
3)Spark作业和调度流程
Spark的作业调度主要是指基于RDD的一系列操作构成一个作业,然后在Executor中执行。这些操作算子主要分为转换操作和行动操作,对于转换操作的计算是lazy级别的,也就是延迟执行,只有出现了行动操作才触发作业的提交。
在Spark调度中最重要的是DAGScheduler和TaskScheduler两个调度器:其中DAGScheduler负责任务的逻辑调度,将Job作业拆分成不同阶段的具有依赖关系的任务集,而TaskScheduler则负责具体任务的调度执行。

4.RDD / DataFrame与Dataset
1)Spark API的历史
Apache Spark 中有RDD,DataFrame和Dataset三种不同数据API,发展如下:

RDD:
-
RDD是Spark最早提供的面向用户的主要API。
-
从根本上来说,一个RDD就是数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层API进行并行处理。
DataFrame:
-
与RDD相似,DataFrame也是数据的一个不可变分布式集合。
-
但与RDD不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样。
-
设计DataFrame的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。它提供了特定领域内专用的API来处理你的分布式数据,并让更多的人可以更方便地使用Spark,而不仅限于专业的数据工程师。
Dataset:
-
从Spark 2.0开始,Dataset开始具有两种不同类型的API特征:有明确类型的API和无类型的API。
-
从概念上来说,可以把DataFrame当作一些通用对象Dataset[Row]的集合的一个别名,而一行就是一个通用的无类型的JVM对象。
-
与之形成对比,Dataset就是一些有明确类型定义的JVM对象的集合,通过你在Scala中定义的Case Class或者Java中的Class来指定。
2)Spark API简介
在Spark 2.0中对Dataframe和Dataset进行了统一,如下图所示:
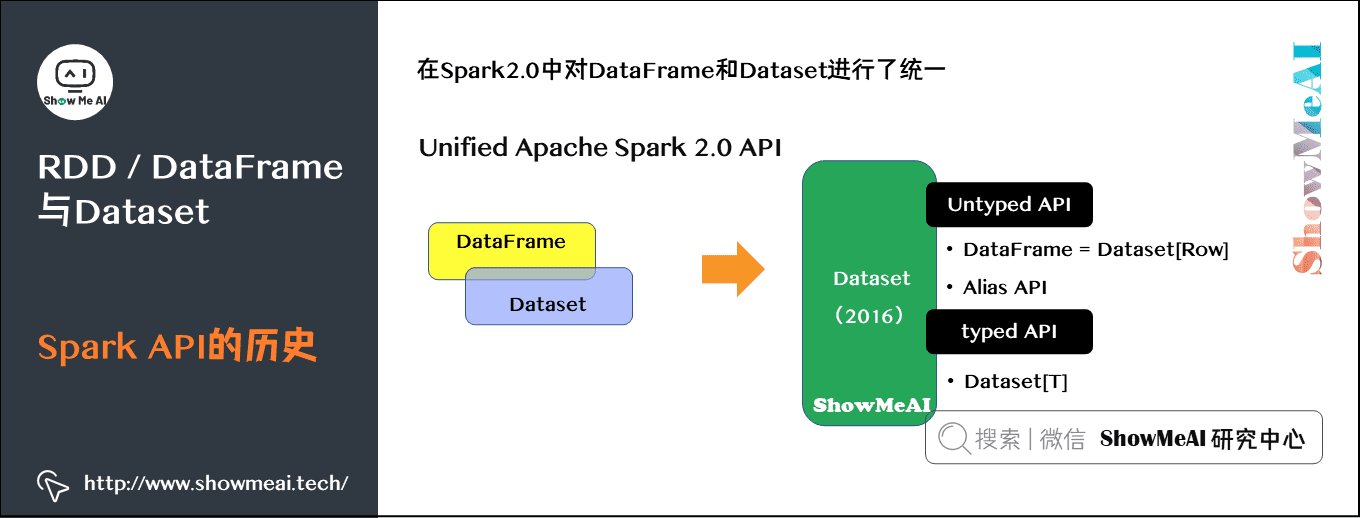
3)Spark的逻辑结构
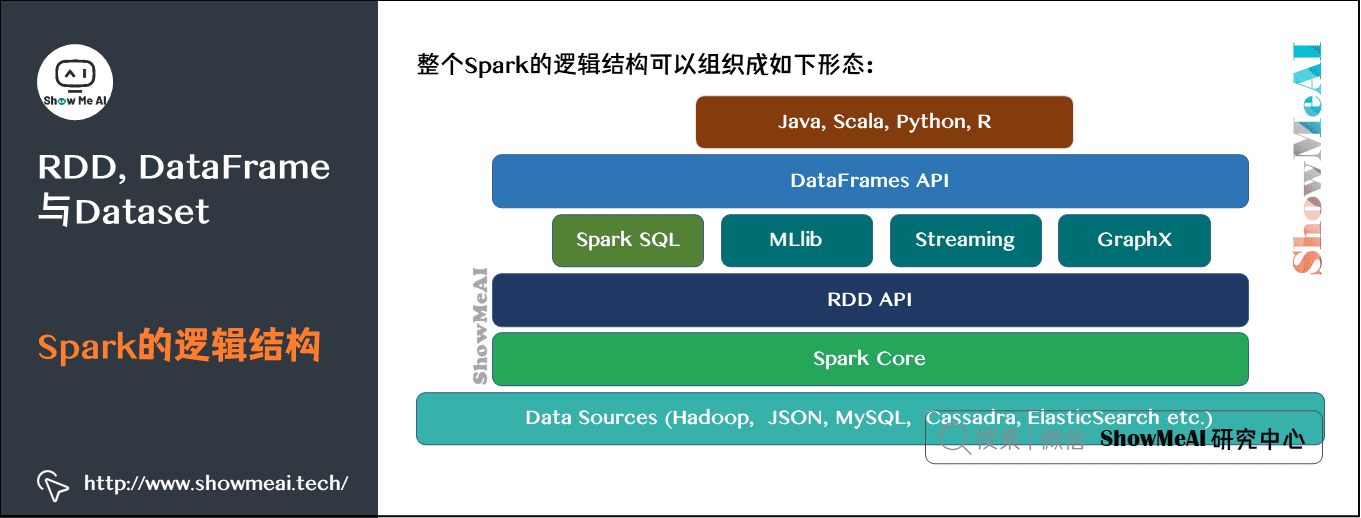
Spark的整体逻辑结构如下图所示,包含不同的层级及组成部分:
5.Spark2.0与SparkSession
1)SparkSession的引入
Spark2.0中引入了SparkSession的概念,它为用户提供了一个统一的切入点来使用Spark的各项功能,借助SparkSession,我们可以使用DataFrame和Dataset的各种API,应用Spark的难度也大大下降。
在Spark的早期版本,SparkContext是进入Spark的切入点,RDD数据基于其创建。但在流处理、SQL等场景下有其他的切入点,汇总如下:
- RDD,创建和操作使用SparkContext提供的API。
- 流处理,使用StreamingContext。
- SQL,使用sqlContext。
- Hive,使用HiveContext。

在Spark高版本中,DataSet和DataFrame提供的API逐渐成为新的标准API,需要一个切入点来构建它们。所以,Spark 2.0引入了一个新的切入点(entry point):SparkSession。
-
SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext)。
-
在SQLContext和HiveContext上可用的API,在SparkSession上同样可以使用。
-
SparkSession内部封装了SparkContext,计算实际上由SparkContext完成。
2)创建SparkSession

6.结构化流与连续性应用
1)Continuous Applications
Spark2.0中提出一个概念,Continuous Applications(连续应用程序)。
Spark Streaming等流式处理引擎,致力于流式数据的运算:比如通过map运行一个方法来改变流中的每一条记录,通过reduce可以基于时间做数据聚合。但是很少有只在流式数据上做运算的需求,流式处理往往是一个大型应用的一部分。
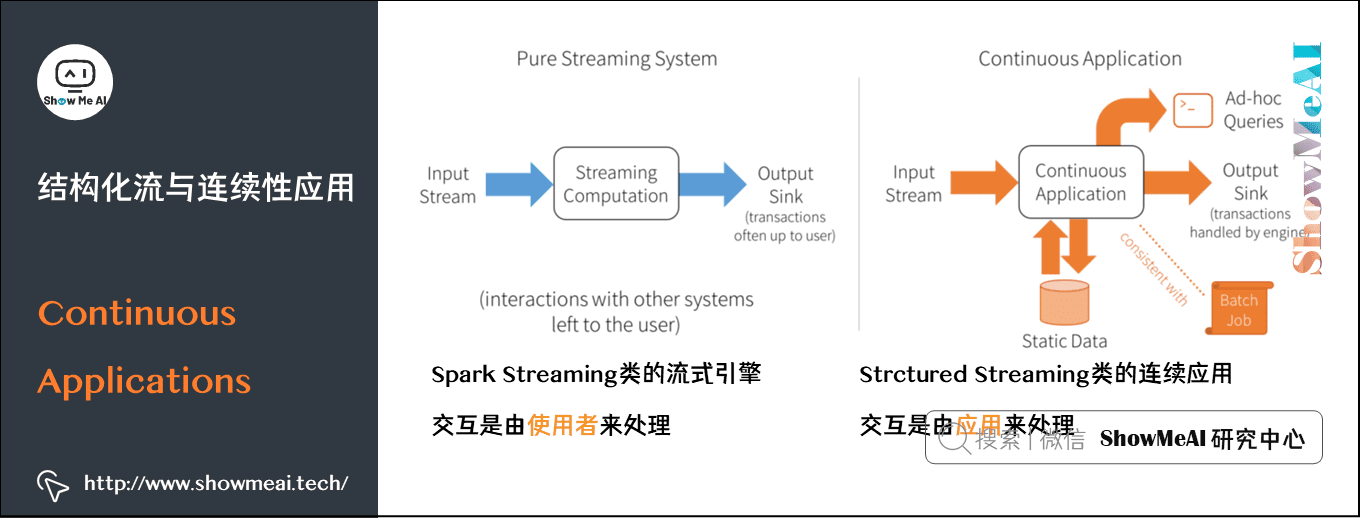
Continuous Applications提出后,实时运算作为一部分,不同系统间的交互等也可以由Structured Streaming来处理。
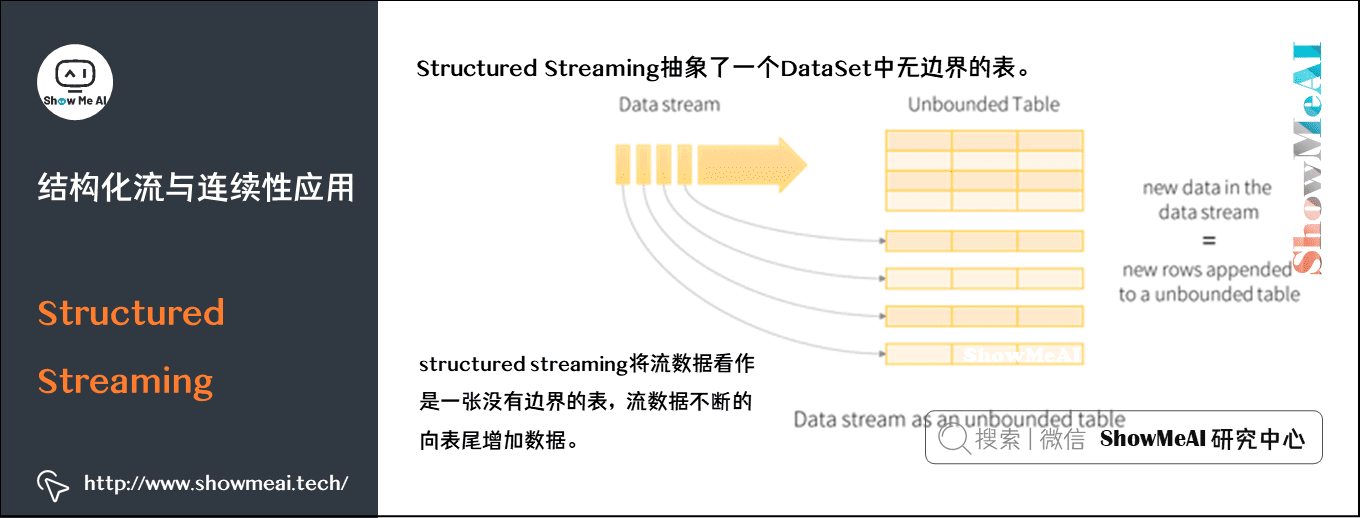
2)Structured Streaming
Structured Streaming是一个建立在Spark Sql引擎上的可扩展、高容错的流式处理引擎。它使得可以像对静态数据进行批量处理一样来处理流式数据。
7.参考资料
- 数据科学工具速查 | Spark使用指南(RDD版) https://www.showmeai.tech/article-detail/106
- 数据科学工具速查 | Spark使用指南(SQL版) https://www.showmeai.tech/article-detail/107
- 张安站著,《Spark技术内幕》,人民邮电机械工业出版社,2015
- Tomasz Drabas / Denny Lee 著,《Learning PySpark》,2017
- Spark基本概念快速入门, https://www.jianshu.com/p/e41b18a7e202
- Spark 编程指南, http://spark.apachecn.org/docs/cn/2-2).0/rdd-programming-guide.html
【大数据技术与处理】推荐阅读
- 图解大数据 | 大数据生态与应用导论
- 图解大数据 | 分布式平台Hadoop与Map-Reduce详解
- 图解大数据 | Hadoop系统搭建与环境配置@实操案例
- 图解大数据 | 应用Map-Reduce进行大数据统计@实操案例
- 图解大数据 | Hive搭建与应用@实操案例
- 图解大数据 | Hive与HBase详解@海量数据库查询
- 图解大数据 | 大数据分析挖掘框架@Spark初步
- 图解大数据 | 基于RDD大数据处理分析@Spark操作
- 图解大数据 | 基于Dataframe / SQL大数据处理分析@Spark操作
- 图解大数据 | 使用Spark分析新冠肺炎疫情数据@综合案例
- 图解大数据 | 使用Spark分析挖掘零售交易数据@综合案例
- 图解大数据 | 使用Spark分析挖掘音乐专辑数据@综合案例
- 图解大数据 | Spark Streaming @流式数据处理
- 图解大数据 | 工作流与特征工程@Spark机器学习
- 图解大数据 | 建模与超参调优@Spark机器学习
- 图解大数据 | GraphFrames @基于图的数据分析挖掘
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人