
图解大数据 | 实操案例-MapReduce大数据统计
 Hadoop使用一套Map-Reduce的计算框架,解决了大数据处理的难题。本教程ShowMeAI通过几个实例和代码,详细给大家讲解Hadoop使用Map-Reduce进行数据统计的方法。
Hadoop使用一套Map-Reduce的计算框架,解决了大数据处理的难题。本教程ShowMeAI通过几个实例和代码,详细给大家讲解Hadoop使用Map-Reduce进行数据统计的方法。

作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/84
本文地址:https://www.showmeai.tech/article-detail/170
声明:版权所有,转载请联系平台与作者并注明出处
1.引言
本教程ShowMeAI详细给大家讲解Hadoop使用Map-Reduce进行数据统计的方法,关于Hadoop与map-reduce的基础知识,大家可以回顾ShowMeAI的基础知识讲解篇分布式平台Hadoop与Map-reduce详解。
尽管大部分人使用Hadoop都是用java完成,但是Hadoop程序可以用python、C++、ruby等完成。本示例教大家用python完成MapReduce实例统计输入文件的单词的词频。
- 输入:文本文件
- 输出:单词和词频信息,用
\t隔开
2.Python实现 MapReduce 代码
使用python完成MapReduce需要利用Hadoop流的API,通过STDIN(标准输入)、STDOUT(标准输出)在Map函数和Reduce函数之间传递数据。
我们会利用Python的sys.stdin读取输入数据,并把我们的输出传送给 sys.stdout。Hadoop流将会完成其他的工作。
一个抽象的Hadoop大数据处理流程如下图所示:
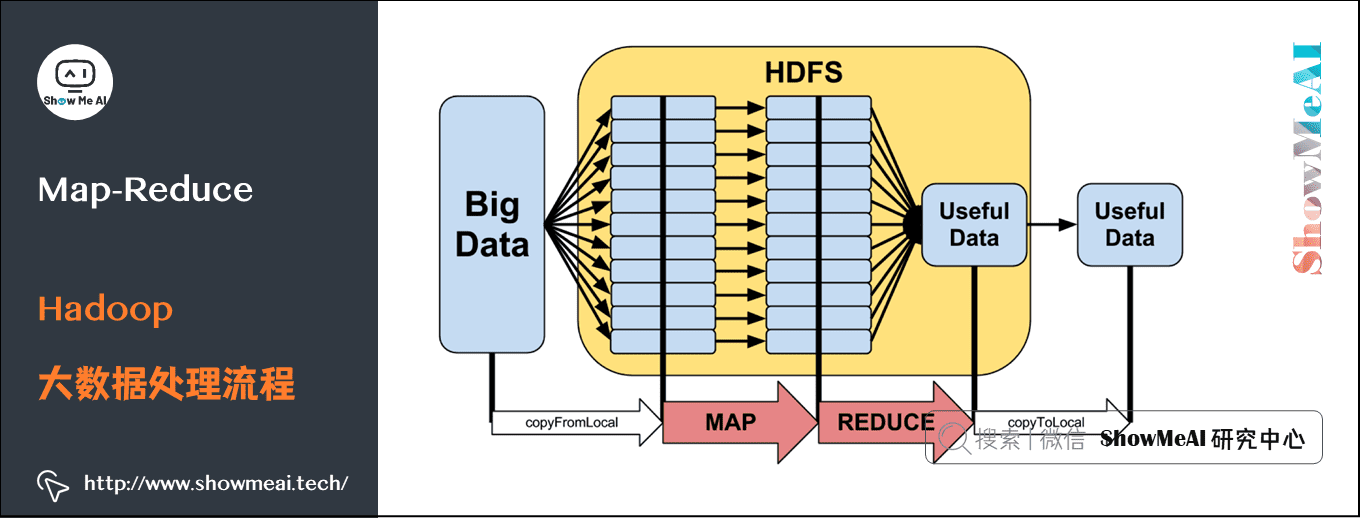
对于本文提到的任务,我们做一个更详细的拆解,整个Hadoop Map-Reduce过程如下图所示:
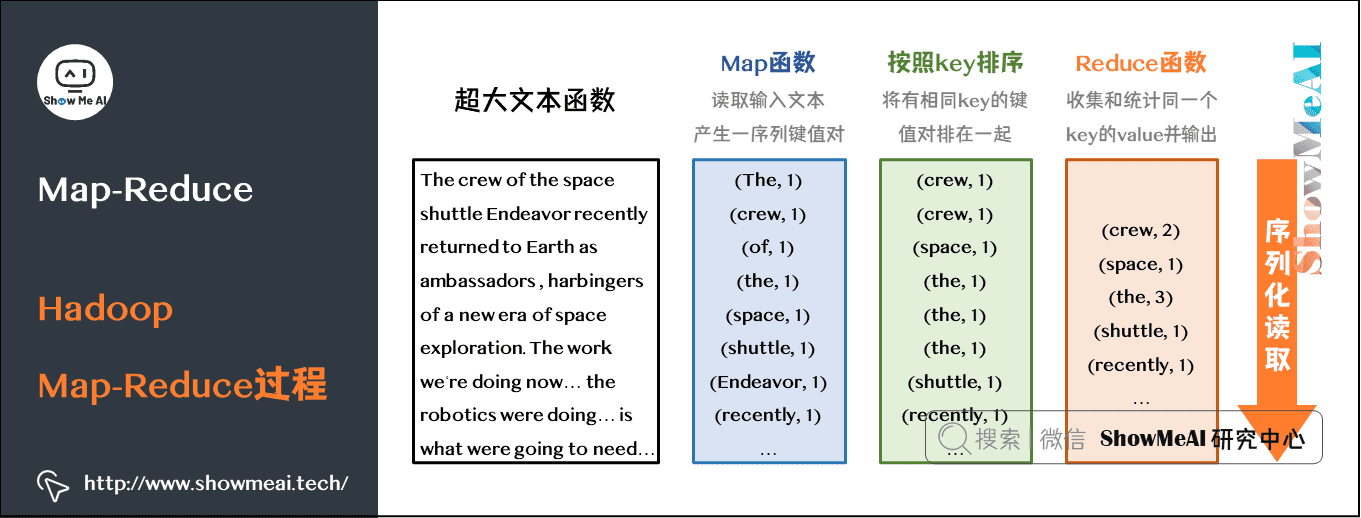
从上图,我们可以看到,我们在当前任务中,需要核心通过代码完成的步骤是:
- Map:产生词与次数标记键值对
- Reduce:聚合同一个词(key)的值,完成统计
下面我们来看看,通过python如何完成这里的 Map 和 Reduce 阶段。
2.1 Map阶段:mapper.py
在这里,我们假设map阶段使用到的python脚本存放地址为 ShowMeAI/hadoop/code/mapper.py
#!/usr/bin/env python import sys for line in sys.stdin: line = line.strip() words = line.split() for word in words: print "%s\t%s" % (word, 1)
解释一下上述代码:
- 文件从STDIN读取文件。
- 把单词切开,并把单词和词频输出STDOUT。
- Map脚本不会计算单词的总数,而是直接输出 1(Reduce阶段会完成统计工作)。
为了使脚本可执行,增加 mapper.py 的可执行权限:
chmod +x ShowMeAI/hadoop/code/mapper.py
2.2 Reduce阶段:reducer.py
在这里,我们假设reduce阶段使用到的python脚本存放地址为 ShowMeAI/hadoop/code/reducer.py :
#!/usr/bin/env python from operator import itemgetter import sys current_word = None current_count = 0 word = None for line in sys.stdin: line = line.strip() word, count = line.split('\t', 1) try: count = int(count) except ValueError: #count如果不是数字的话,直接忽略掉 continue if current_word == word: current_count += count else: if current_word: print "%s\t%s" % (current_word, current_count) current_count = count current_word = word if word == current_word: #不要忘记最后的输出 print "%s\t%s" % (current_word, current_count)
文件会读取 mapper.py 的结果作为 reducer.py 的输入,并统计每个单词出现的总的次数,把最终的结果输出到STDOUT。
为了是脚本可执行,增加 reducer.py 的可执行权限
chmod +x ShowMeAI/hadoop/code/reducer.py
3.本地测试MapReduce流程
通常我们在把数据处理流程提交到集群进行运行之前,会本地做一个简单测试,我们会借助linux的管道命令 (cat data | map | sort | reduce) 对数据流进行串接,验证我们写的 mapper.py 和 reducer.py脚本功能是否正常。这种测试方式,能保证输出的最终结果是我们期望的。
测试的命令如下:
cd ShowMeAI/hadoop/code/ echo "foo foo quux labs foo bar quux" | python mapper.py echo ``"foo foo quux labs foo bar quux"` `| python mapper.py | sort -k1, 1 | python reducer.py
其中的sort过程主要是完成以key为基准的排序,方便reduce阶段进行聚合统计。
4.Hadoop集群运行python代码
4.1 数据准备
我们对以下三个文件进行词频统计,先根据下述路径下载:
- Plain Text UTF-8 http://www.gutenberg.org/ebooks/4300.txt.utf-8
- Plain Text UTF-8 http://www.gutenberg.org/ebooks/5000.txt.utf-8
- Plain Text UTF-8 http://www.gutenberg.org/ebooks/20417.txt.utf-8
将文件放置到 ShowMeAI/hadoop/datas/ 目录下。
4.2 执行程序
把本地的数据文件拷贝到分布式文件系统HDFS中。
bin/hadoop dfs -copyFromLocal ShowMeAI/hadoop/datas hdfs_in
查看:
bin/hadoop dfs -ls
查看具体的文件:
bin/hadoop dfs -ls /user/showmeai/hdfs_in
执行MapReduce job:
bin/hadoop jar contrib/streaming/hadoop-*streaming*.jar \ -file ShowMeAI/hadoop/code/mapper.py -mapper ShowMeAI/hadoop/code/mapper.py \ -file ShowMeAI/hadoop/code/reducer.py -reducer ShowMeAI/hadoop/code/reducer.py \ -input /user/showmeai/hdfs_in/- -output /user/showmeai/hdfs_out
实例输出:
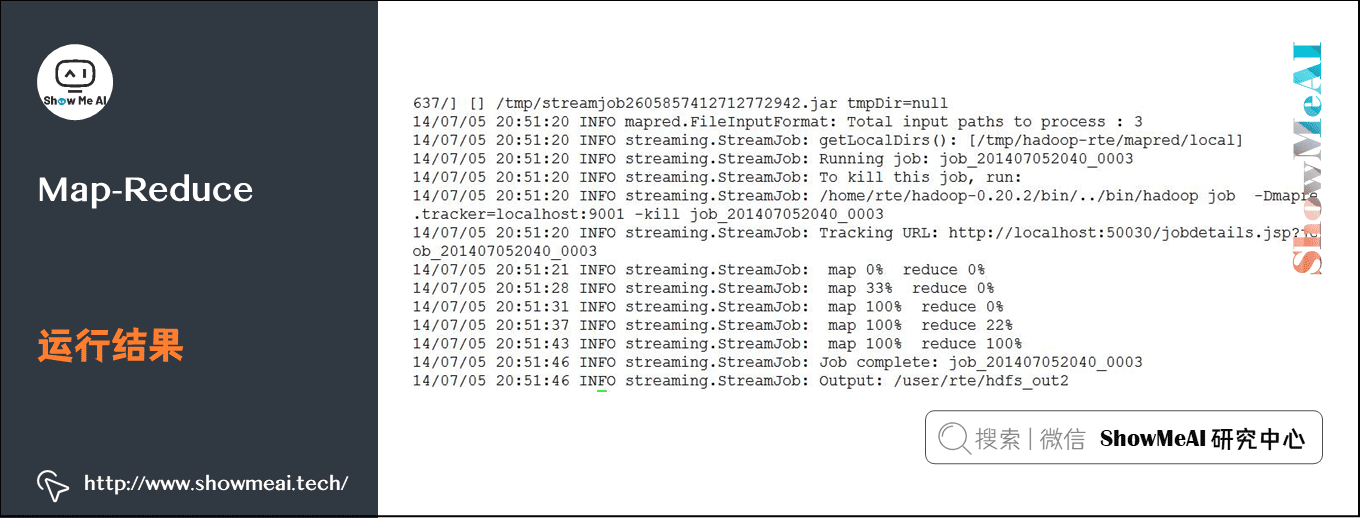
查看输出结果是否在目标目录 /user/showmeai/hdfs_out:
bin/hadoop dfs -ls /user/showmeai/hdfs_out
查看结果:
bin/hadoop dfs -cat /user/showmeai/hdfs_out2/part-00000
输出:

5.Mapper 和 Reducer代码优化
5.1 python中的迭代器和生成器
我们这里对Map-Reduce的代码优化主要基于迭代器和生成器,对这个部分不熟悉的同学可以参考ShowMeAI的python部分内容 → 《图解python | 迭代器与生成器》 。
5.2 优化Mapper 和 Reducer代码
mapper.py #!/usr/bin/env python import sys def read_input(file): for line in file: yield line.split() def main(separator='\t'): data = read_input(sys.stdin) for words in data: for word in words: print "%s%s%d" % (word, separator, 1) if __name__ == "__main__": main() reducer.py #!/usr/bin/env python from operator import itemgetter from itertools import groupby import sys def read_mapper_output(file, separator = '\t'): for line in file: yield line.rstrip().split(separator, 1) def main(separator = '\t'): data = read_mapper_output(sys.stdin, separator = separator) for current_word, group in groupby(data, itemgetter(0)): try: total_count = sum(int(count) for current_word, count in group) print "%s%s%d" % (current_word, separator, total_count) except valueError: pass if __name__ == "__main__": main()
我们对代码中的groupby做一个简单代码功能演示讲解,如下:
from itertools import groupby from operator import itemgetter things = [('2009-09-02', 11), ('2009-09-02', 3), ('2009-09-03', 10), ('2009-09-03', 4), ('2009-09-03', 22), ('2009-09-06', 33)] sss = groupby(things, itemgetter(0)) for key, items in sss: print key for subitem in items: print subitem print '-' * 20
结果:
2009-09-02 ('2009-09-02', 11) ('2009-09-02', 3) -------------------- 2009-09-03 ('2009-09-03', 10) ('2009-09-03', 4) ('2009-09-03', 22) -------------------- 2009-09-06 ('2009-09-06', 33) --------------------
代码中:
groupby(things, itemgetter(0))以第0列为排序目标groupby(things, itemgetter(1))以第1列为排序目标groupby(things)以整行为排序目标
6.参考资料
-
python中的split函数中的参数问题 http://segmentfault.com/q/1010000000311861
-
Writing an Hadoop MapReduce Program in Python http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/
-
shell的sort命令的-k参数 http://blog.chinaunix.net/uid-25513153-id-200481.html
【大数据技术与处理】推荐阅读
- 图解大数据 | 大数据生态与应用导论
- 图解大数据 | 分布式平台Hadoop与Map-Reduce详解
- 图解大数据 | Hadoop系统搭建与环境配置@实操案例
- 图解大数据 | 应用Map-Reduce进行大数据统计@实操案例
- 图解大数据 | Hive搭建与应用@实操案例
- 图解大数据 | Hive与HBase详解@海量数据库查询
- 图解大数据 | 大数据分析挖掘框架@Spark初步
- 图解大数据 | 基于RDD大数据处理分析@Spark操作
- 图解大数据 | 基于Dataframe / SQL大数据处理分析@Spark操作
- 图解大数据 | 使用Spark分析新冠肺炎疫情数据@综合案例
- 图解大数据 | 使用Spark分析挖掘零售交易数据@综合案例
- 图解大数据 | 使用Spark分析挖掘音乐专辑数据@综合案例
- 图解大数据 | Spark Streaming @流式数据处理
- 图解大数据 | 工作流与特征工程@Spark机器学习
- 图解大数据 | 建模与超参调优@Spark机器学习
- 图解大数据 | GraphFrames @基于图的数据分析挖掘
ShowMeAI系列教程推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人