Python数据分析 | Pandas数据变换高级函数
 本篇为『图解Pandas数据变换高级函数』,讲解3个函数是map、apply和applymap,更高效地完成数据处理过程中对DataFrame进行逐行、逐列和逐元素的操作。
本篇为『图解Pandas数据变换高级函数』,讲解3个函数是map、apply和applymap,更高效地完成数据处理过程中对DataFrame进行逐行、逐列和逐元素的操作。

作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/33
本文地址:https://www.showmeai.tech/article-detail/147
声明:版权所有,转载请联系平台与作者并注明出处

当我们提到python数据分析的时候,大部分情况下都会使用Pandas进行操作。pandas整个系列覆盖以下内容:
本篇为『图解Pandas数据变换高级函数』。
一、Pandas的数据变换高级函数
在数据处理过程中,经常需要对DataFrame进行逐行、逐列和逐元素的操作(例如,机器学习中的特征工程阶段)。Pandas中有非常高效简易的内置函数可以完成,最核心的3个函数是map、apply和applymap。下面我们以图解的方式介绍这3个方法的应用方法。
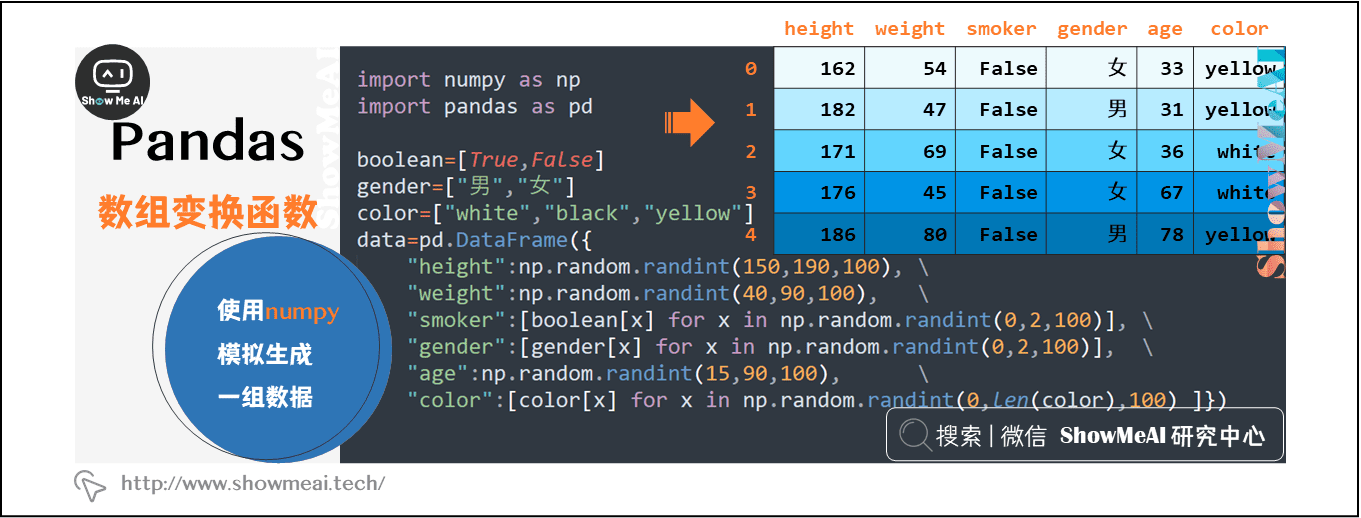
首先,通过numpy模拟生成一组数据。数据集如下所示,各列分别代表身高(height)、体重(weight)、是否吸烟(smoker)、性别(gender)、年龄(age)和肤色(color)。
import numpy as np
import pandas as pd
boolean=[True,False]
gender=["男","女"]
color=["white","black","yellow"]
data=pd.DataFrame({
"height":np.random.randint(150,190,100),
"weight":np.random.randint(40,90,100),
"smoker":[boolean[x] for x in np.random.randint(0,2,100)],
"gender":[gender[x] for x in np.random.randint(0,2,100)],
"age":np.random.randint(15,90,100),
"color":[color[x] for x in np.random.randint(0,len(color),100) ]
}
)
二、Series数据处理
2.1 map方法
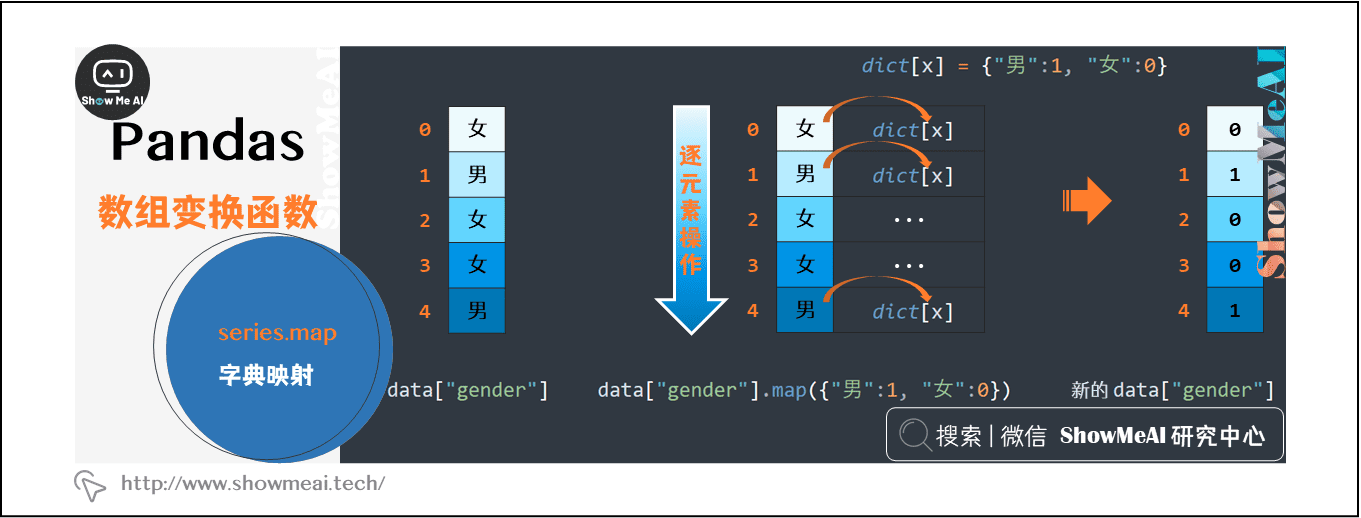
当我们需要把series数据逐元素做同一个变换操作时,我们不会使用for循环(效率很低),我们会使用Series.map()来完成,通过简单的一行代码即可完成变换处理。例如,我们把数据集中gender列的男替换为1,女替换为0。
下面我们通过图解的方式,拆解map的操作过程:
(1)使用字典映射的map原理
#①使用字典进行映射
data["gender"] = data["gender"].map({"男":1, "女":0})
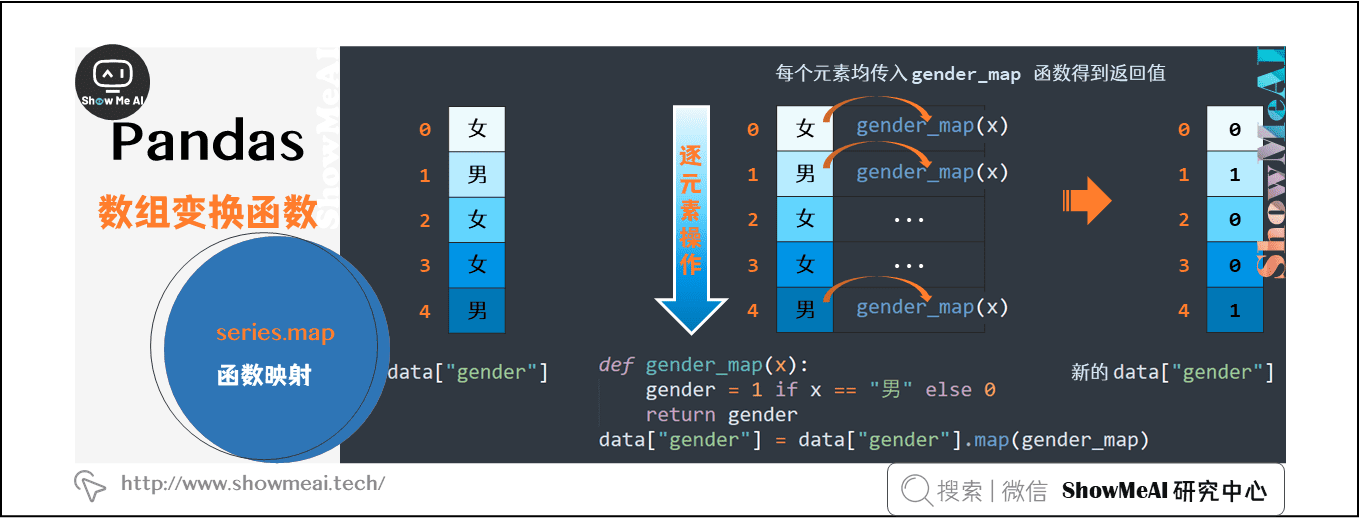
(2)使用函数映射的map原理
#②使用函数
def gender_map(x):
gender = 1 if x == "男" else 0
return gender
#注意这里传入的是函数名,不带括号
data["gender"] = data["gender"].map(gender_map)
如上面例子所示,使用map时,我们可以通过字典或者函数进行映射处理。对于这两种方式,map都是把对应的数据逐个当作参数传入到字典或函数中,进行映射得到结果。
2.2 apply方法
当我们需要完成复杂的数据映射操作处理时,我们会使用到Series对象的apply方法,它和map方法类似,但能够传入功能更为复杂的函数。
我们通过一个例子来理解一下。例如,我们要对年龄age列进行调整(加上或减去一个值),这个加上或减去的值我们希望通过传入。此时,多了1个参数bias,用map方法是操作不了的(传入map的函数只能接收一个参数),apply方法则可以解决这个问题。
def apply_age(x,bias):
return x+bias
#以元组的方式传入额外的参数
data["age"] = data["age"].apply(apply_age,args=(-3,))

可以看到age列都减了3,这是个非常简单的例子,apply在复杂场景下有着更灵活的作用。
总结一下,对于Series而言,map可以完成大部分数据的统一映射处理,而apply方法适合对数据做复杂灵活的函数映射操作。
三、DataFrame数据处理
3.1 apply方法
DataFrame借助apply方法,可以接收各种各样的函数(Python内置的或自定义的)对数据进行处理,非常灵活便捷。
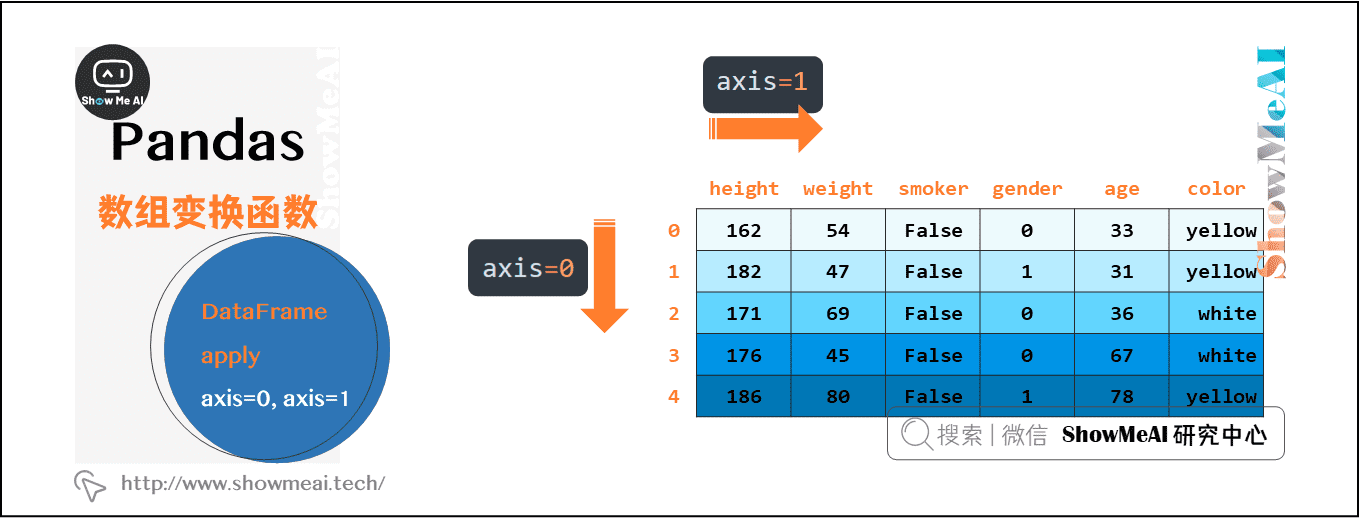
掌握DataFrame的apply方法需要先了解一下axis的概念,在DataFrame对象的大多数方法中,都会有axis这个参数,它控制了你指定的操作是沿着0轴还是1轴进行。axis=0代表操作对列columns进行,axis=1代表操作对行row进行,如下图所示。
我们来通过例子理解一下这个方法的使用。例如,我们对data中的数值列分别进行取对数和求和的操作。这时使用apply进行相应的操作,两行代码可以很轻松地解决。
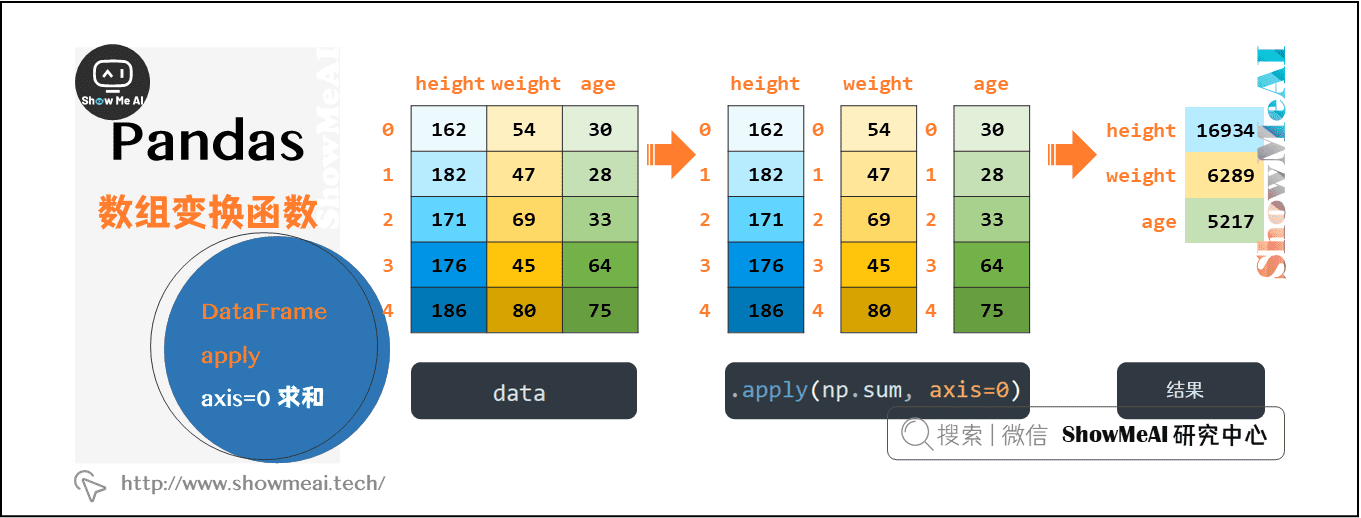
(1)按列求和的实现过程
因为是对列进行操作,所以需要指定axis=0。本次实现的底层,apply到底做了什么呢?我们来通过图解的方式理解一下:
# 沿着0轴求和
data[["height","weight","age"]].apply(np.sum, axis=0)
(2)按列取对数的实现过程
因为是对列进行操作,所以需要指定axis=0。本次实现的底层,apply到底做了什么呢?我们来通过图解的方式理解一下:
# 沿着0轴求和
data[["height","weight","age"]].apply(np.sum, axis=0)
# 沿着0轴取对数
data[["height","weight","age"]].apply(np.log, axis=0)
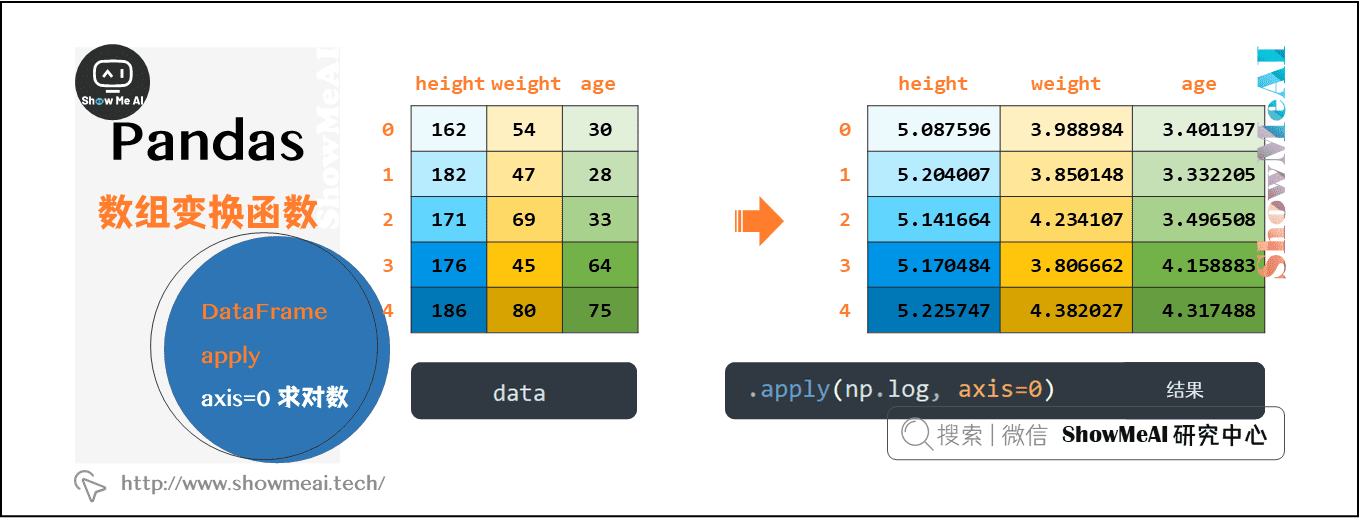
当沿着轴0(axis=0)进行操作时,会将各列(columns)默认以Series的形式作为参数,传入到你指定的操作函数中,操作后合并并返回相应的结果。
(3)按行计算BMI指数
那我们实际应用过程中有没有(axis=1)的情况呢?例如,我们要根据数据集中的身高和体重计算每个人的BMI指数(体检时常用的指标,衡量人体肥胖程度和是否健康的重要标准),计算公式是:体重指数BMI=体重/身高的平方(国际单位kg/㎡)。
这个操作需要对每个样本(行)进行计算,我们使用apply并指定axis=1来完成,代码和图解如下:
def BMI(series):
weight = series["weight"]
height = series["height"]/100
BMI = weight/height**2
return BMI
data["BMI"] = data.apply(BMI,axis=1)
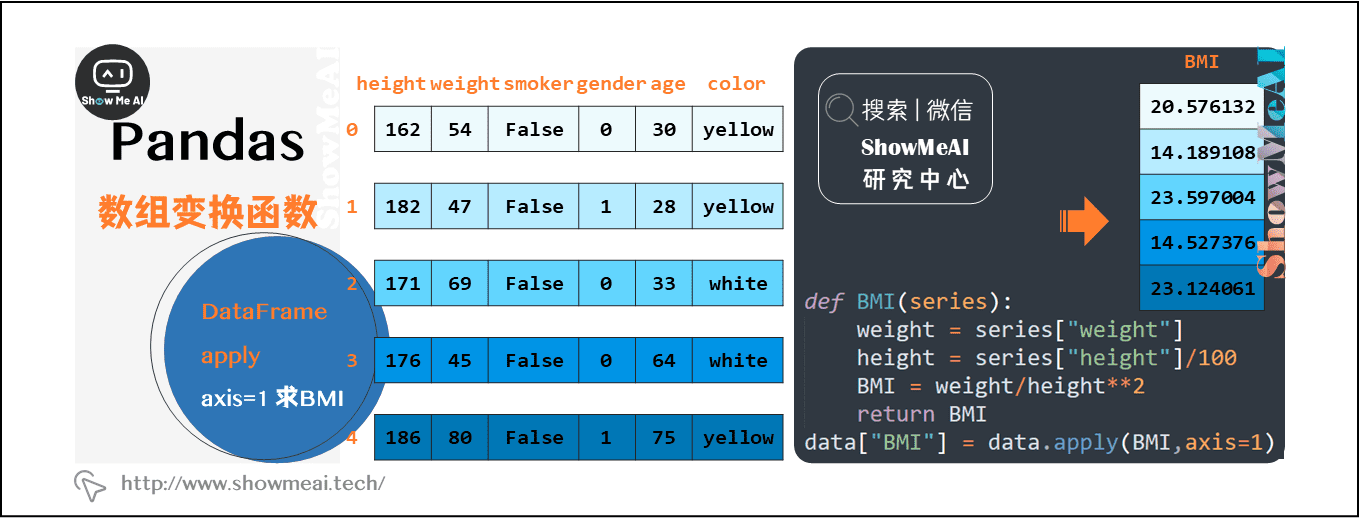
当apply设置了axis=1对行进行操作时,会默认将每一行数据以Series的形式(Series的索引为列名)传入指定函数,返回相应的结果。
做个总结,DataFrame中应用apply方法:
- 当axis=0时,对每列columns执行指定函数;当axis=1时,对每行row执行指定函数。
- 无论axis=0还是axis=1,其传入指定函数的默认形式均为Series,可以通过设置raw=True传入numpy数组。
- 对每个Series执行结果后,会将结果整合在一起返回(若想有返回值,定义函数时需要return相应的值)
- 当然,DataFrame的apply和Series的apply一样,也能接收更复杂的函数,如传入参数等,实现原理是一样的,具体用法详见官方文档。
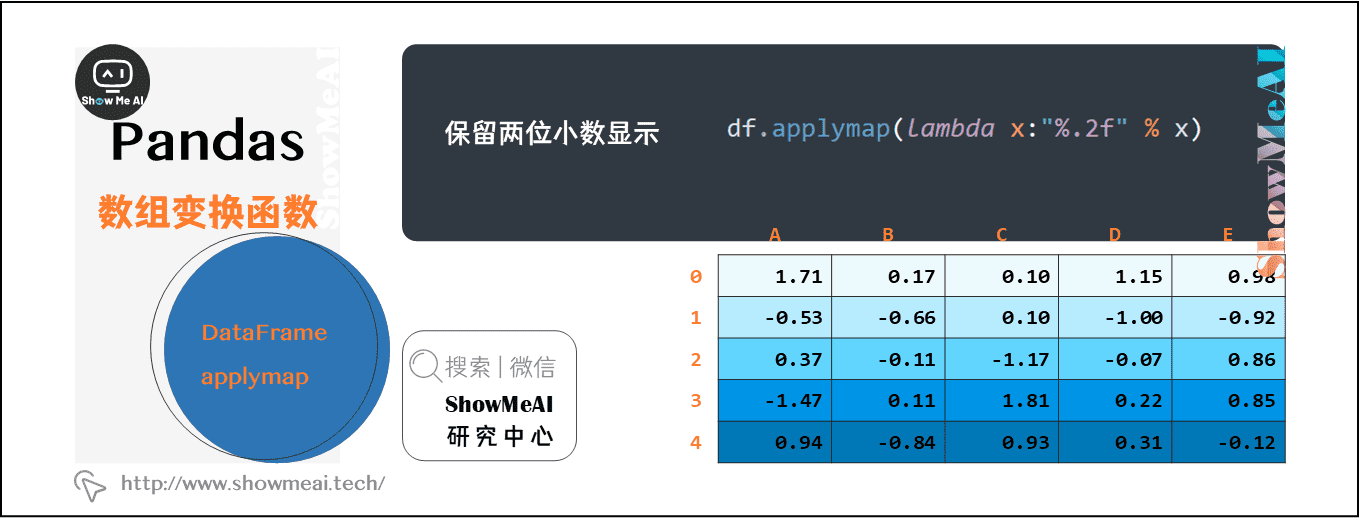
3.2 applymap方法
applymap是另一个DataFrame中可能会用到的方法,它会对DataFrame中的每个单元格执行指定函数的操作,如下例所示:
df = pd.DataFrame(
{
"A":np.random.randn(5),
"B":np.random.randn(5),
"C":np.random.randn(5),
"D":np.random.randn(5),
"E":np.random.randn(5),
}
)

我们希望对DataFrame中所有的数保留两位小数显示,applymap可以帮助我们很快完成,代码和图解如下:
df.applymap(lambda x:"%.2f" % x)
资料与代码下载
本教程系列的代码可以在ShowMeAI对应的github中下载,可本地python环境运行,能访问Google的宝宝也可以直接借助google colab一键运行与交互操作学习哦!
本系列教程涉及的速查表可以在以下地址下载获取
拓展参考资料
ShowMeAI图解数据分析系列推荐(数据科学家入门)
- 图解数据分析(1) | 数据分析介绍
- 图解数据分析(2) | 数据分析思维
- 图解数据分析(3) | 数据分析的数学基础
- 图解数据分析(4) | 核心步骤1 - 业务认知与数据初探
- 图解数据分析(5) | 核心步骤2 - 数据清洗与预处理
- 图解数据分析(6) | 核心步骤3 - 业务分析与数据挖掘
- 图解数据分析(7) | 数据分析工具地图
- 图解数据分析(8) | Numpy - 统计与数据科学计算工具库介绍
- 图解数据分析(9) | Numpy - 与1维数组操作
- 图解数据分析(10) | Numpy - 与2维数组操作
- 图解数据分析(11) | Numpy - 与高维数组操作
- 图解数据分析(12) | Pandas - 数据分析工具库介绍
- 图解数据分析(13) | Pandas - 核心操作函数大全
- 图解数据分析(14) | Pandas - 数据变换高级函数
- 图解数据分析(15) | Pandas - 数据分组与操作
- 图解数据分析(16) | 数据可视化原则与方法
- 图解数据分析(17) | 基于Pandas的数据可视化
- 图解数据分析(18) | 基于Seaborn的数据可视化
ShowMeAI系列教程精选推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读


 浙公网安备 33010602011771号
浙公网安备 33010602011771号