Python数据分析 | Pandas核心操作函数大全
 本篇为pandas系列的导语,对『Pandas核心操作函数』进行介绍,讲解Pandas进行数据操作和处理的核心数据结构:Series、DataFrame和Index。
本篇为pandas系列的导语,对『Pandas核心操作函数』进行介绍,讲解Pandas进行数据操作和处理的核心数据结构:Series、DataFrame和Index。

作者:韩信子@ShowMeAI
教程地址:https://www.showmeai.tech/tutorials/33
本文地址:https://www.showmeai.tech/article-detail/146
声明:版权所有,转载请联系平台与作者并注明出处

当我们提到python数据分析的时候,大部分情况下都会使用Pandas进行操作。本篇为pandas系列的导语,对pandas进行简单介绍,整个系列覆盖以下内容:
本篇为『图解Pandas核心操作函数大全』,讲解Pandas进行数据操作和处理的核心数据结构:Series、DataFrame和Index。
一、Pandas Series
Series是一个一维的数组对象,它包含一个值序列和一个对应的索引序列。 Numpy中的一维数组也有隐式定义的整数索引,可以通过它获取元素值,而Series用一种显式定义的索引与元素关联。
显式索引让Series对象拥有更强的能力,索引可以是整数或别的类型(比如字符串),索引可以重复,也不需要连续,自由度非常高。
pandas.Series(data, index, dtype, copy)

1.1 从numpy array创建Series
如果数据是ndarray,则传递的索引必须具有相同的长度。如果没有传递索引值,那么默认的索引将是范围(n),其中n是数组长度,即 [0,1,2,3…,range(len(array))-1] 。
pandas.Series(np.array([47, 66, 48, 77, 16, 91]))

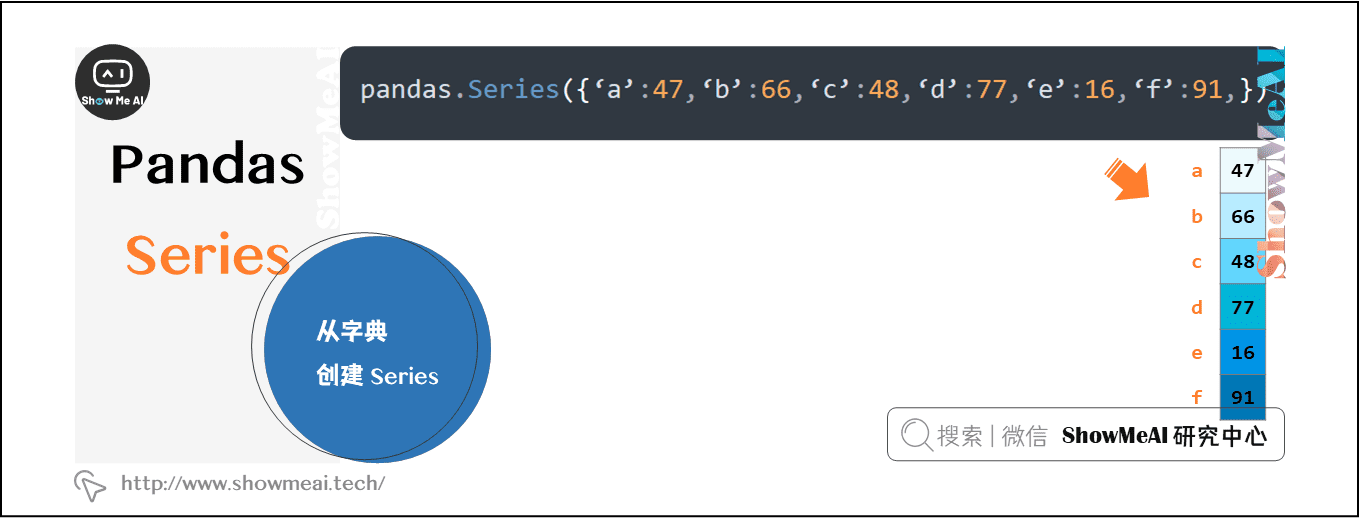
1.2 从字典创建Series
字典(dict)可以作为输入传递。如果没有指定索引,则按排序顺序取得字典键以构造索引。如果传递了索引,索引中与标签对应的数据中的值将被拉出。
pandas.Series({‘a’:47, ‘b’:66, ‘c’:48, ‘d’:77, ‘e’:16, ‘f’:91,})
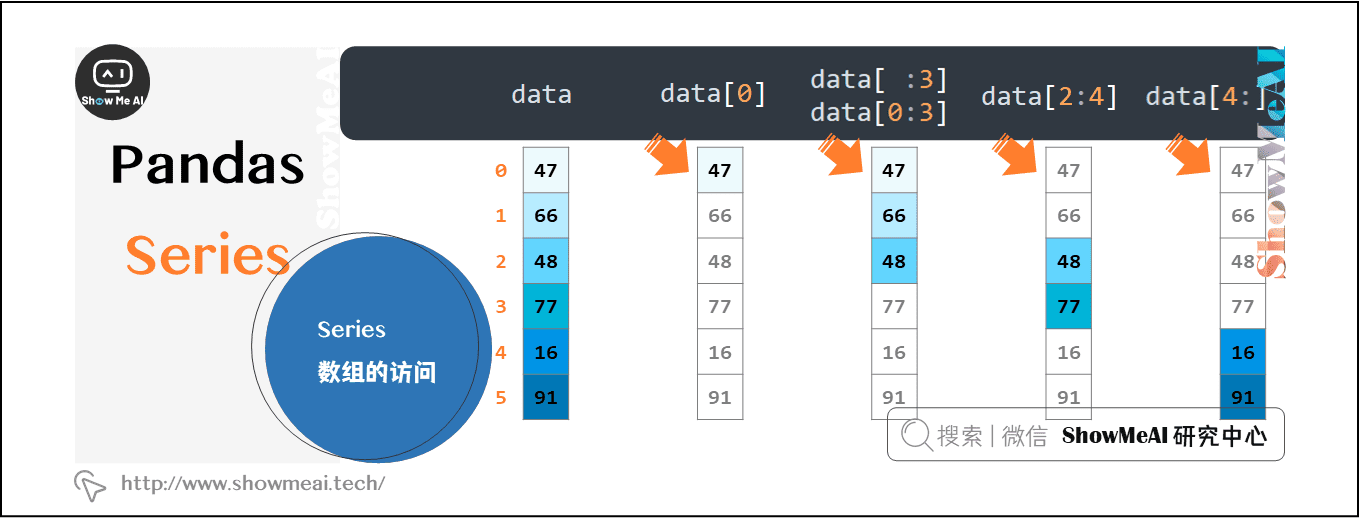
1.3 Series数据的访问
通过各种方式访问Series数据,系列中的数据可以使用类似于访问numpy中的ndarray中的数据来访问。
data
data[0]
data[ :3]
data[0:3]
data[2:4]
data[4:]
1.4 Series的聚合统计
Series有很多的聚合函数,可以方便的统计最大值、求和、平均值等

二、DataFrame(数据帧)
DataFrame是Pandas中使用最频繁的核心数据结构,表示的是二维的矩阵数据表,类似关系型数据库的结构,每一列可以是不同的值类型,比如数值、字符串、布尔值等等。
DataFrame既有行索引,也有列索引,它可以被看做为一个共享相同索引的Series的字典。它的列的类型可能不同,我们也可以把Dataframe想象成一个电子表格或SQL表。

pandas.DataFrame(data, index, columns, dtype, copy)

2.1 从列表创建DataFrame
从列表中很方便的创建一个DataFrame,默认行列索引从0开始。
s = [
[47, 94, 43, 92, 67, 19],
[66, 52, 48, 79, 94, 44],
[48, 21, 75, 14, 29, 56],
[77, 10, 70, 42, 23, 62],
[16, 10, 58, 93, 43, 53],
[91, 60, 22, 46, 50, 41],
]
pandas.DataFrame(s)

2.2 从字典创建DataFrame
从字典创建DataFrame,自动按照字典进行列索引,行索引从0开始。
s = [
‘a’:[47, 66, 48, 77, 16, 91],
‘b’:[94, 52, 21, 10, 10, 60],
‘c’:[43, 48, 75, 70, 58, 22],
‘d’:[92, 79, 14, 42, 93, 46],
‘e’:[67, 94, 29, 23, 43, 50],
‘f’:[19, 44, 56, 62, 55, 41],
]
pandas.DataFrame(s, columns=[‘a’,‘b’,‘c’,‘d’,‘e’,‘f’))

2.3 pandas Dataframe列选择
在刚学Pandas时,行选择和列选择非常容易混淆,在这里进行一下整理常用的列选择。
data[[‘a’]] # 返回a列,DataFrame格式
data.iloc[:,0] # 返回a列,Series格式
data.a # 返回a列,Series格式
data[‘a’] # 返回a列,Series格式
data.iloc[:,[0,3,4]]
data[[‘a’, ‘d’, ‘e’]]
data.iloc[:,[‘a’, ‘d’, ‘e’]]
data.iloc[:,2:] # 第3列及以后
data.iloc[:,2:5] # 第3、4、5列
data.iloc[:,:2] # 开始两列


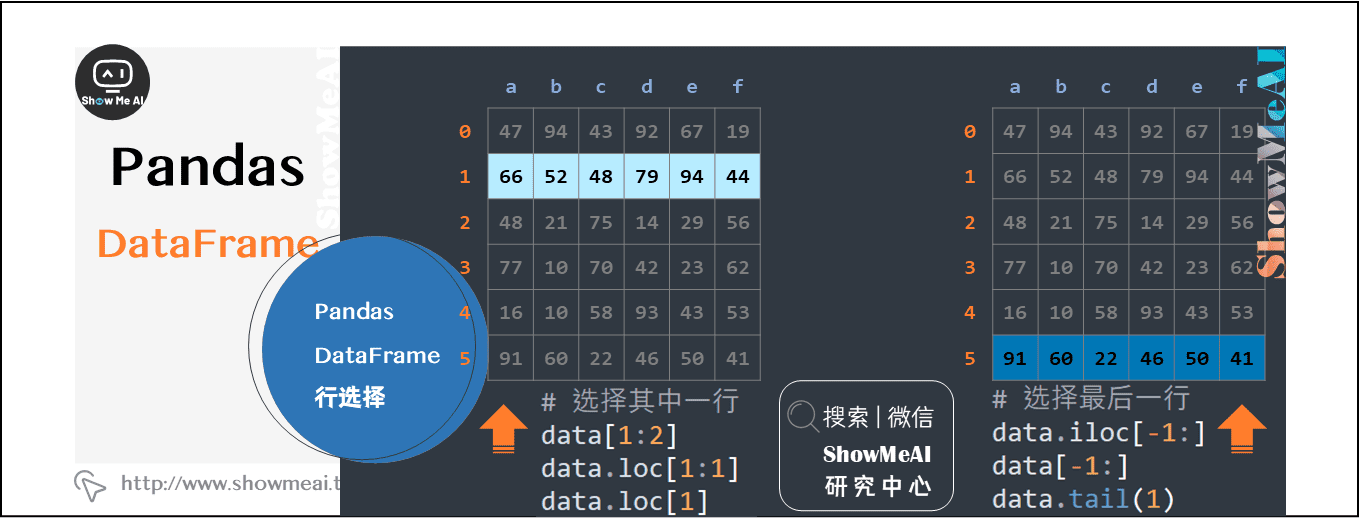
2.4 pandas Dataframe行选择
整理多种行选择的方法,总有一种适合你的。
data[1:2]
data.loc[1:1]
data.loc[1] #返回Series格式
data.iloc[-1:]
data[-1:]
data.tail(1)
data[2:5]
data.loc[2:4]
data.iloc[[2, 3, 5],:]

data.head(2)
data.tail(2)
data.sample(3)

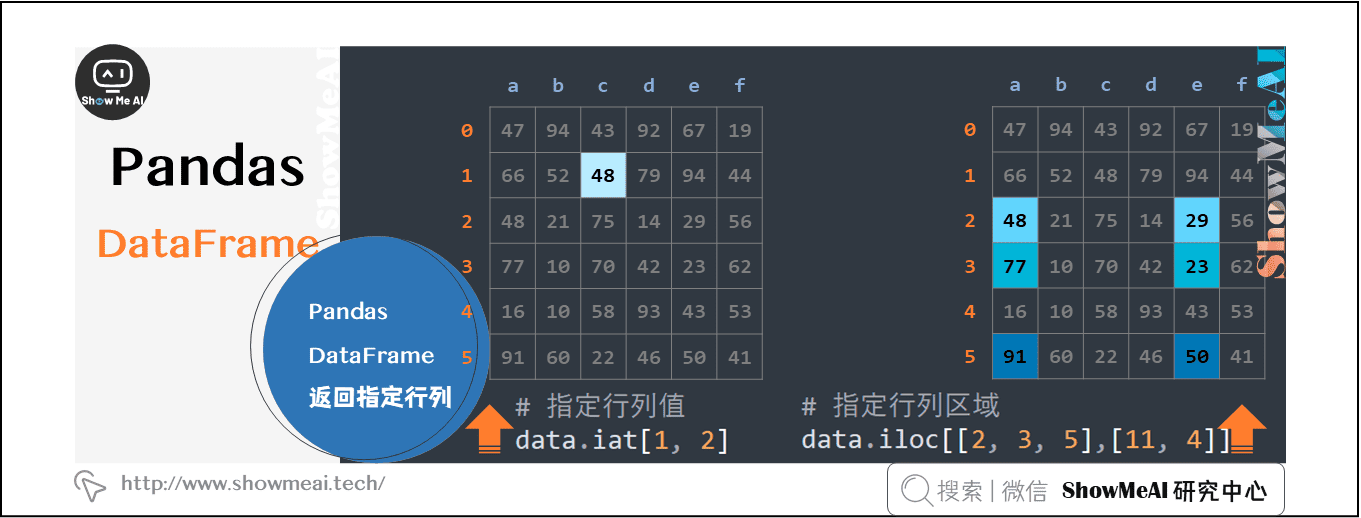
2.5 pandas Dataframe返回指定行列
pandas的DataFrame非常方便的提取数据框内的数据。
data.iat[1, 2]
data.iloc[[2, 3, 5],[11, 4]]
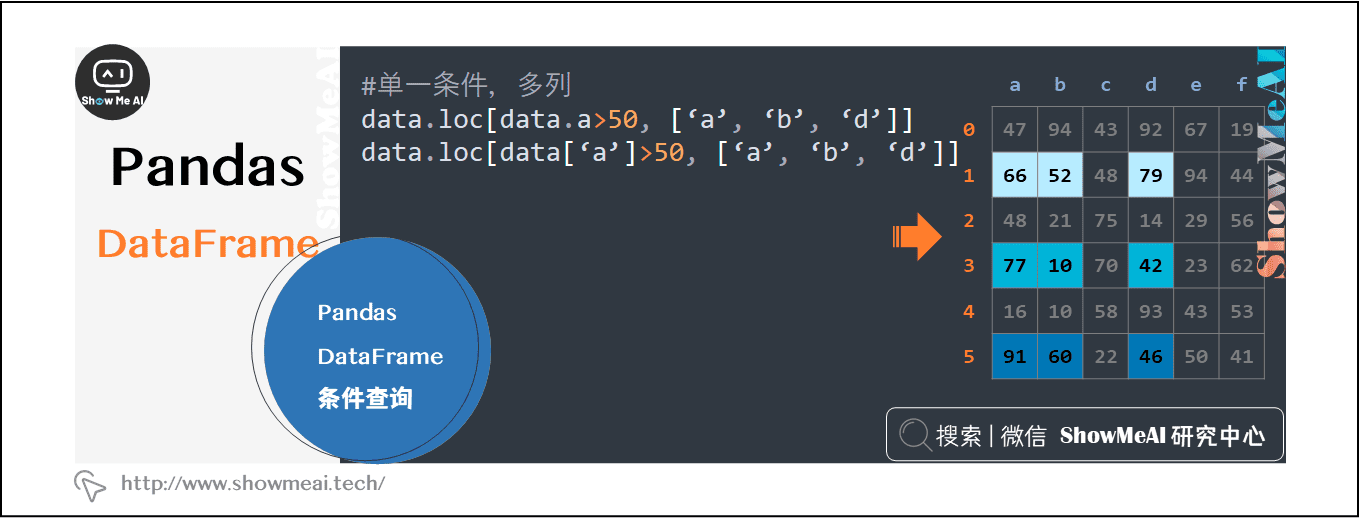
2.6 pandas Dataframe条件查询
对各类数值型、文本型,单条件和多条件进行行选择
data.[data.a>50]
data[data[‘a’]>50]
data.loc[data.a>50,:]
data.loc[data[‘a’]>50,:]

data.loc[(data.a>40) & (data.b>60),:]
data[(data.a>40)&(data.b>40)]

data.loc[data.a>50, [‘a’, ‘b’, ‘d’]]
data.loc[data[‘a’]>50, [‘a’, ‘b’, ‘d’]]
data.loc[(data.a>50)|(data.g==‘GD’),[‘a’, ‘b’, ‘g’]]
data.loc[(data.a>50)|(data.g.isin([‘GD’, ‘SH’])),[‘a’, ‘b’, ‘g’]]

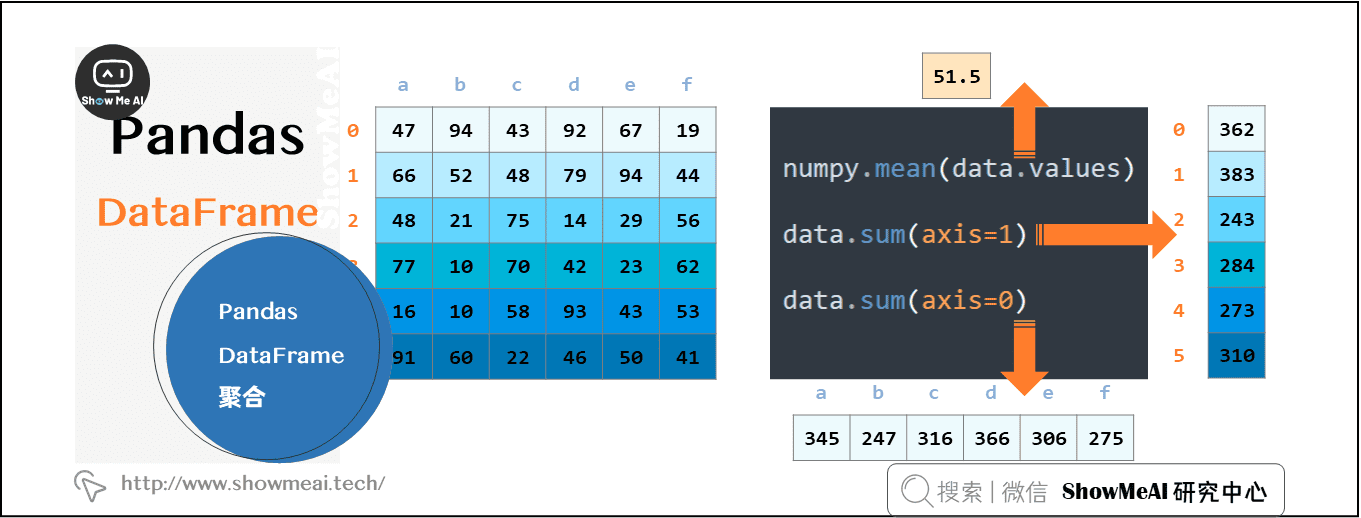
2.7 pandas Dataframe聚合
可以按行、列进行聚合,也可以用pandas内置的describe对数据进行操作简单而又全面的数据聚合分析。
data.sum(axis=1)
numpy.mean(data.values)
data.sum(axis=0)
data.describe()
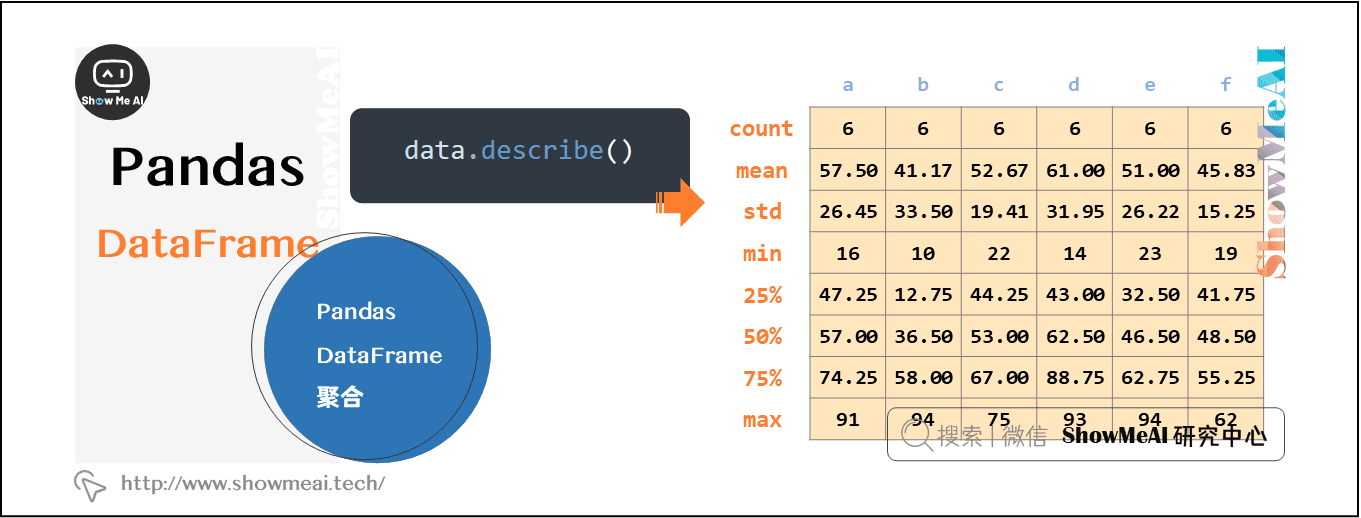
2.8 pandas Dataframe中的聚合函数
data.function(axis=0) # 按列计算
data.function(axis=1) # 按行计算

2.9 pandas Dataframe分组统计
可以按照指定的多列进行指定的多个运算进行汇总统计。
df.groupby(‘g’).sum
df.groupby(‘g’)([‘d’]).agg([numpy.sum, numpy.mean, numpy.std])
df.groupby([‘g’, ‘h’]).mean

2.10 pandas Dataframe透视表
透视表是pandas的一个强大的操作,大量的参数完全能满足你个性化的需求。
pandas.pivot_table(df, index=‘g’, values=‘a’, columns=[‘h’], aggfunc=[numpy.sum], fill_value = 0, margins=True)

2.11 pandas Dataframe处理缺失值
pandas对缺失值有多种处理办法,满足各类需求。
data.dropna(axis=0)
data.dropna(axis=1)
data.dropna(axis=0)

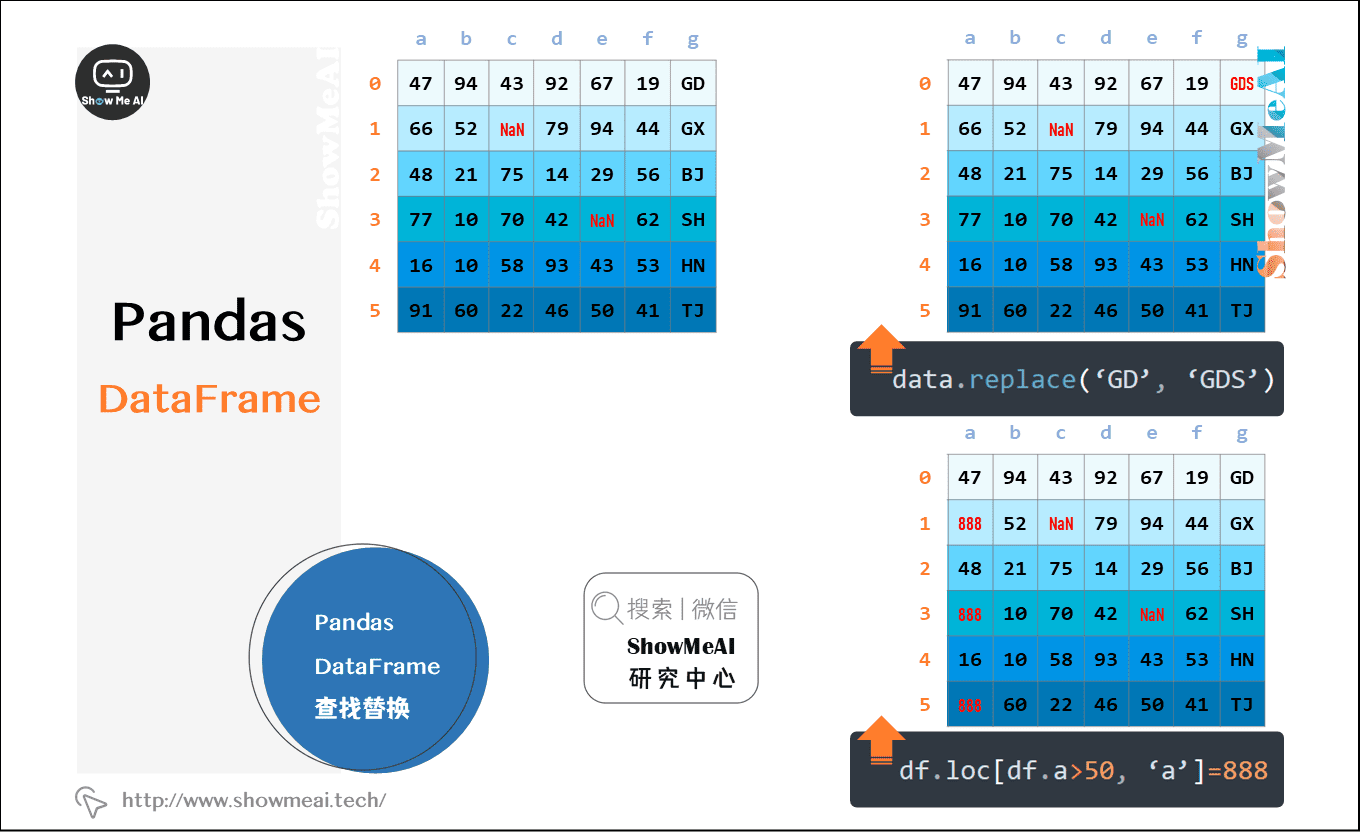
2.12 pandas Dataframe查找替换
pandas 提供简单的查找替换功能,如果要复杂的查找替换,可以使用map()、apply()和 applymap()
data.replace(‘GD’, ‘GDS’)
df.loc[df.a>50, ‘a’]=888
2.13 pandas Dataframe多数据源合并
两个DataFrame的合并,pandas会自动按照索引对齐,可以指定两个DataFrame的对齐方式,如内连接外连接等,也可以指定对齐的索引列。
df3 = pandas.merge(df1, df2, how=‘inner’)
df3 = pandas.merge(df1, df2, how=‘inner’, left_index=True, right_index=True)

2.14 pandas Dataframe更改列名
pandas要对Dataframe的列名进行修改,操作如下:
data.columns=[‘a’, ‘b’, ‘c’, ‘d’, ‘’e, ‘f’]

2.15 pandas Dataframe的apply变换函数
这是pandas的一个强大的函数,可以针对每一个记录进行单值运算,无需手动写循环进行处理。
df[‘i’]=df.apply(compute, axis=1) # a+b>100返回1,否则返回0,存放到新的一列
df[‘i’]=df.apply(compute2, axis=1) # g包含GD、FJ的,e小于50的,返回1,否则返回0

def compute(arr):
a = arr['a']
b = arr['b']
if a+b>100:
return 1
else:
return 0
def compute2(arr):
a = arr['e']
b = arr['g']
if (g in ['GD','FJ']) and (e<50):
return 1
else:
return 0

资料与代码下载
本教程系列的代码可以在ShowMeAI对应的github中下载,可本地python环境运行,能访问Google的宝宝也可以直接借助google colab一键运行与交互操作学习哦!
本系列教程涉及的速查表可以在以下地址下载获取:
拓展参考资料
ShowMeAI图解数据分析系列推荐(数据科学家入门)
- 图解数据分析(1) | 数据分析介绍
- 图解数据分析(2) | 数据分析思维
- 图解数据分析(3) | 数据分析的数学基础
- 图解数据分析(4) | 核心步骤1 - 业务认知与数据初探
- 图解数据分析(5) | 核心步骤2 - 数据清洗与预处理
- 图解数据分析(6) | 核心步骤3 - 业务分析与数据挖掘
- 图解数据分析(7) | 数据分析工具地图
- 图解数据分析(8) | Numpy - 统计与数据科学计算工具库介绍
- 图解数据分析(9) | Numpy - 与1维数组操作
- 图解数据分析(10) | Numpy - 与2维数组操作
- 图解数据分析(11) | Numpy - 与高维数组操作
- 图解数据分析(12) | Pandas - 数据分析工具库介绍
- 图解数据分析(13) | Pandas - 核心操作函数大全
- 图解数据分析(14) | Pandas - 数据变换高级函数
- 图解数据分析(15) | Pandas - 数据分组与操作
- 图解数据分析(16) | 数据可视化原则与方法
- 图解数据分析(17) | 基于Pandas的数据可视化
- 图解数据分析(18) | 基于Seaborn的数据可视化
ShowMeAI系列教程精选推荐
- 大厂技术实现方案系列
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读


 浙公网安备 33010602011771号
浙公网安备 33010602011771号