
大厂技术实现 | 腾讯信息流推荐排序中的并联双塔CTR结构 @推荐与计算广告系列
 双塔模型是推荐、搜索、广告等多个领域的算法实现中最常用和经典的结构,实际各公司应用时,双塔结构中的每个塔会做结构升级,用CTR预估中的新网络结构替代全连接DNN,本期看到的是腾讯浏览器团队的推荐场景下,巧妙并联CTR模型应用于双塔的方案。
双塔模型是推荐、搜索、广告等多个领域的算法实现中最常用和经典的结构,实际各公司应用时,双塔结构中的每个塔会做结构升级,用CTR预估中的新网络结构替代全连接DNN,本期看到的是腾讯浏览器团队的推荐场景下,巧妙并联CTR模型应用于双塔的方案。
💡 作者:韩信子@ShowMeAI,Joan@腾讯
📘 大厂解决方案系列教程:https://www.showmeai.tech/tutorials/50
📘 本文地址:https://www.showmeai.tech/article-detail/64
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏 ShowMeAI 查看更多精彩内容
一图读懂全文
本篇内容使用到的数据集为 🏆CTR预估方法实现数据集与代码,大家可以通过 ShowMeAI 的百度网盘地址快速下载。数据集和代码的整理花费了很多心思,欢迎大家 PR 和 Star!
🏆 大厂技术实现的数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『大厂』,或者点击 这里 获取本文 腾讯信息流推荐排序中的并联双塔CTR结构 『CTR预估方法实现数据集与代码』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub/multi-task-learning
一、双塔模型结构
1.1 模型结构介绍
双塔模型广泛应用于推荐、搜索、广告等多个领域的召回和排序阶段。双塔模型结构中,左侧是User塔,右侧是Item塔,对应的,我们也可以将特征拆分为两大类:
- User相关特征 :用户基本信息、群体统计属性以及交互过的Item序列等;如果有上下文特征(Context feature)可以放入用户侧塔。
- Item相关特征 :Item基本信息、属性信息等。
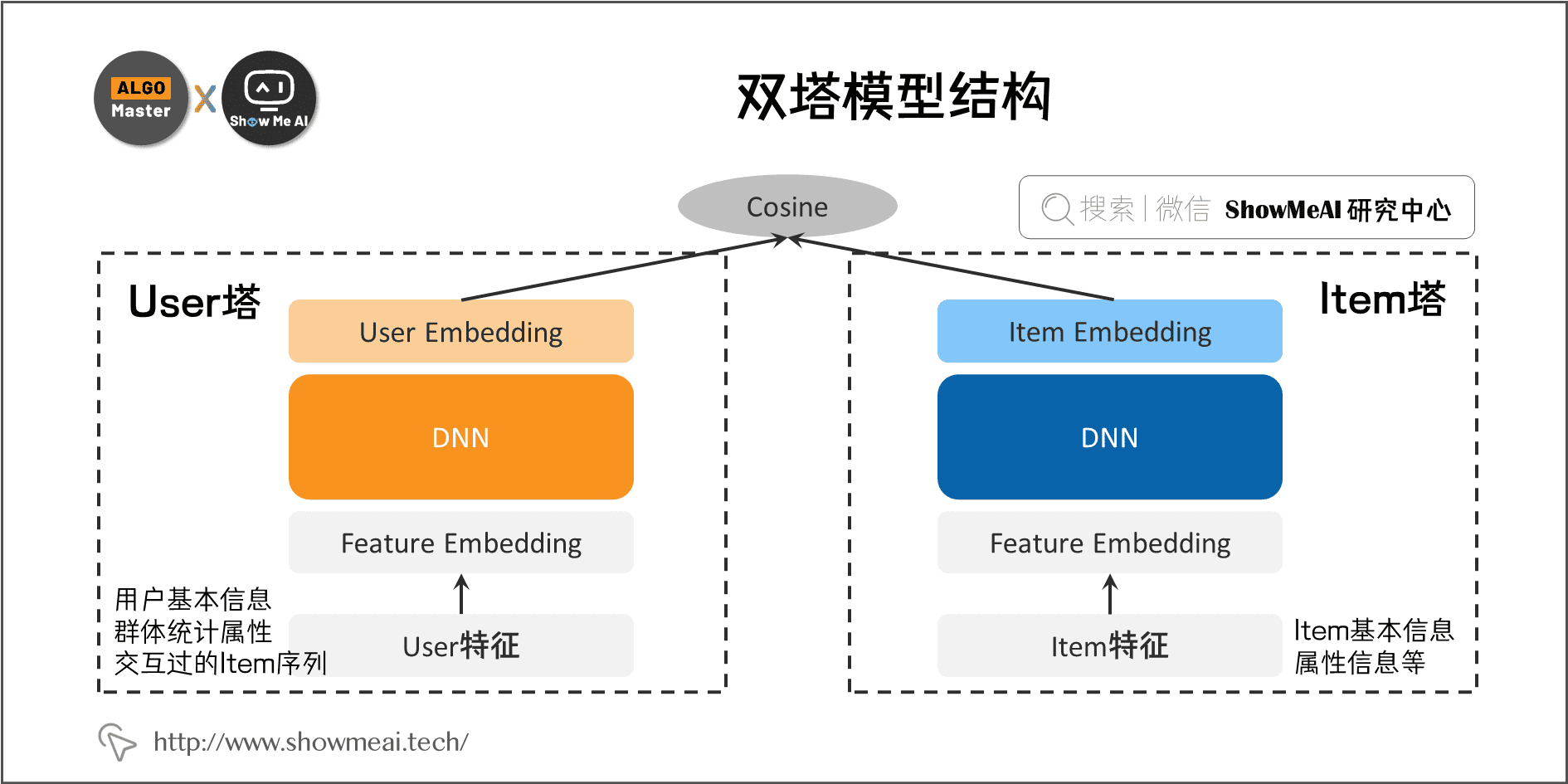
最初版本的结构中,这两个塔中间都是经典的 DNN 模型(即全连接结构),从特征 Embedding 经过若干层 MLP 隐层,两个塔分别输出 User Embedding 和 Item Embedding 编码。
在训练过程中,User Embedding 和 Item Embedding 做内积或者Cosine相似度计算,使得当前 User 和正例 Item 在 Embedding 空间更接近,和负例 Item 在 Embedding 空间距离拉远。损失函数则可用标准交叉熵损失(将问题当作一个分类问题),或者采用 BPR 或者 Hinge Loss(将问题当作一个表示学习问题)。
1.2 双塔模型优缺点
双塔模型优点很明显:
- 结构清晰。分别对 User 和 Item 建模学习之后,再交互完成预估。
- 训练完成之后,线上 inference 过程高效,性能优秀。在线 serving 阶段,Item 向量是预先计算好的,可根据变化特征计算一次 User 向量,再计算内积或者 cosine 即可。
**双塔模型也存在缺点 **:
- 原始的双塔模型结构,特征受限,无法使用交叉特征。
- 模型结构限制下,User 和 Item 是分开构建,只能通过最后的内积来交互,不利于 User-Item 交互的学习。

1.3 双塔模型的优化
腾讯信息流团队(QQ 浏览器小说推荐场景) 基于以上限制对双塔模型结构进行优化,增强模型结构与效果上,取得了不错的收益,具体做法为:
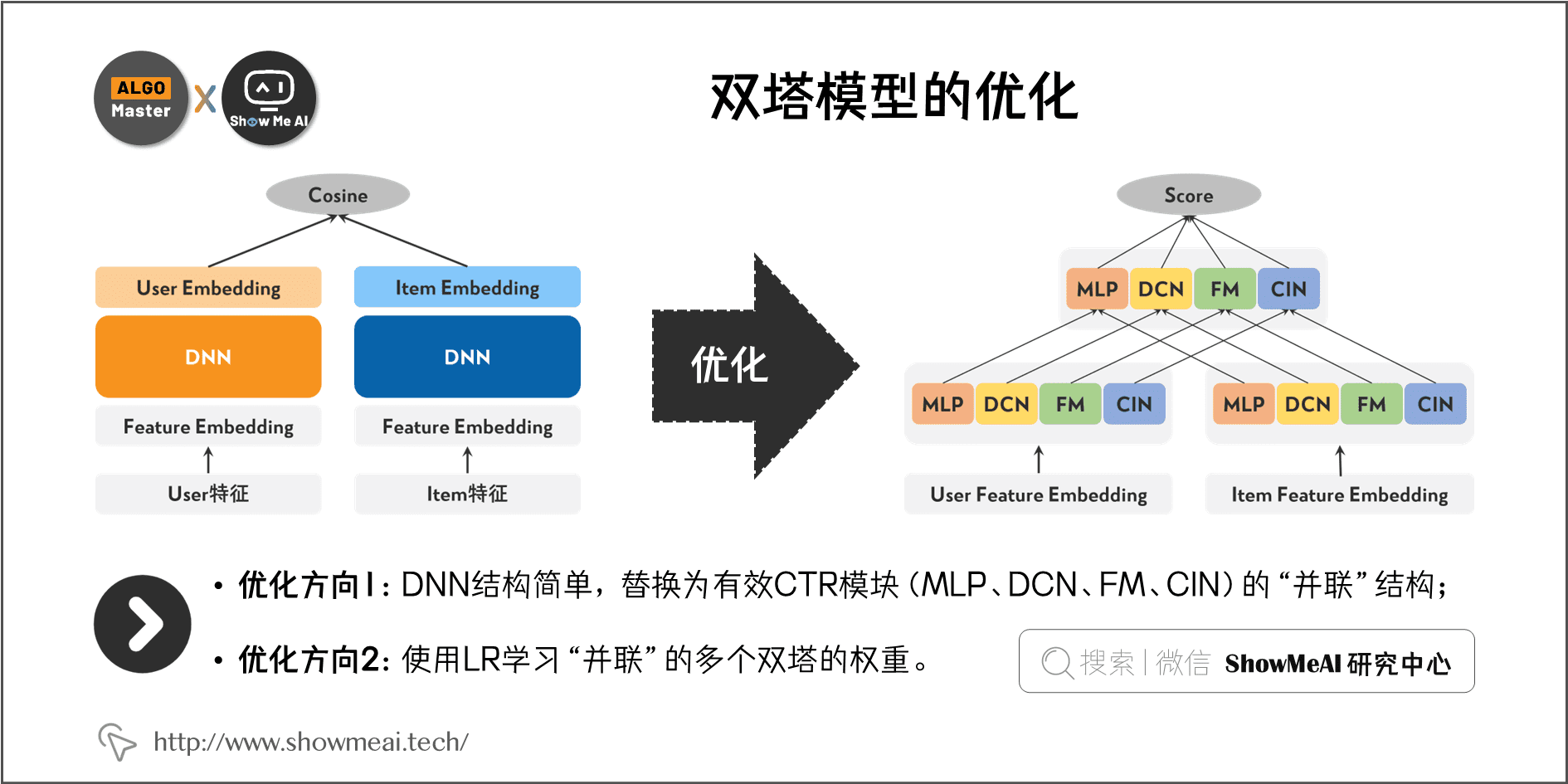
- 把双塔结构中的DNN简单结构,替换有效CTR模块(MLP、DCN、FM、FFM、CIN)的"并联"结构,充分利用不同结构的特征交叉优势,拓宽模型的"宽度"来缓解双塔内积的瓶颈。
- 使用LR学习"并联"的多个双塔的权重,LR 权重最终融入到 User Embedding 中,使得最终的模型仍然保持的内积形式。
二、并联双塔模型结构
并联的双塔模型可以分总分为三层: 输入层、表示层和匹配层 。对应图中的3个层次,分别的处理和操作如下。
2.1 输入层(Input Layer)
腾讯QQ浏览器小说场景下有以下两大类特征:
- User 特征 :用户 id、用户画像(年龄、性别、城市)、行为序列(点击、阅读、收藏)、外部行为(浏览器资讯、腾讯视频等)。
- Item 特征 :小说内容特征(小说 id、分类、标签等)、统计类特征等。
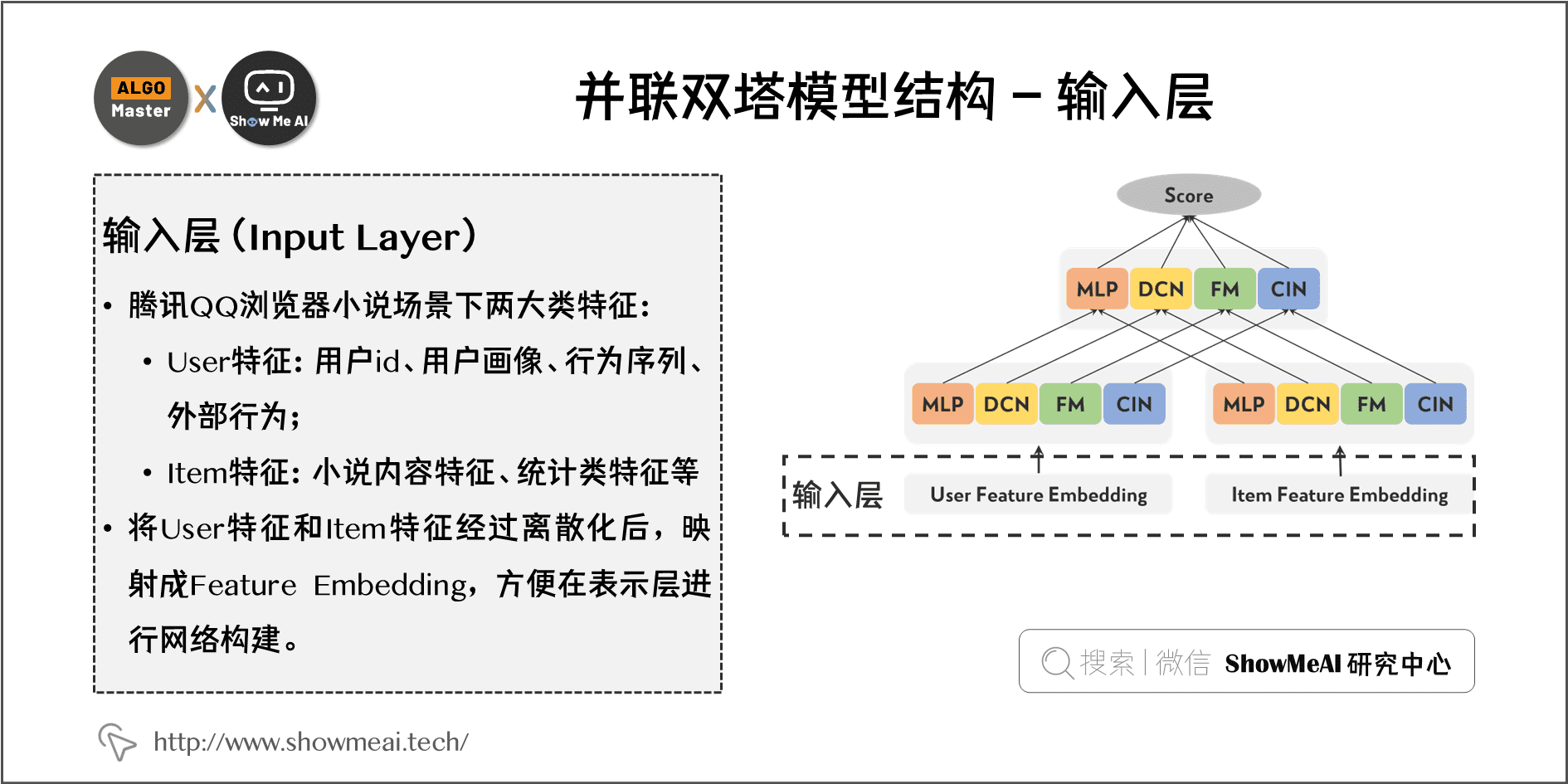
将 User 和 Item 特征都经过离散化后映射成 Feature Embedding,方便在表示层进行网络构建。
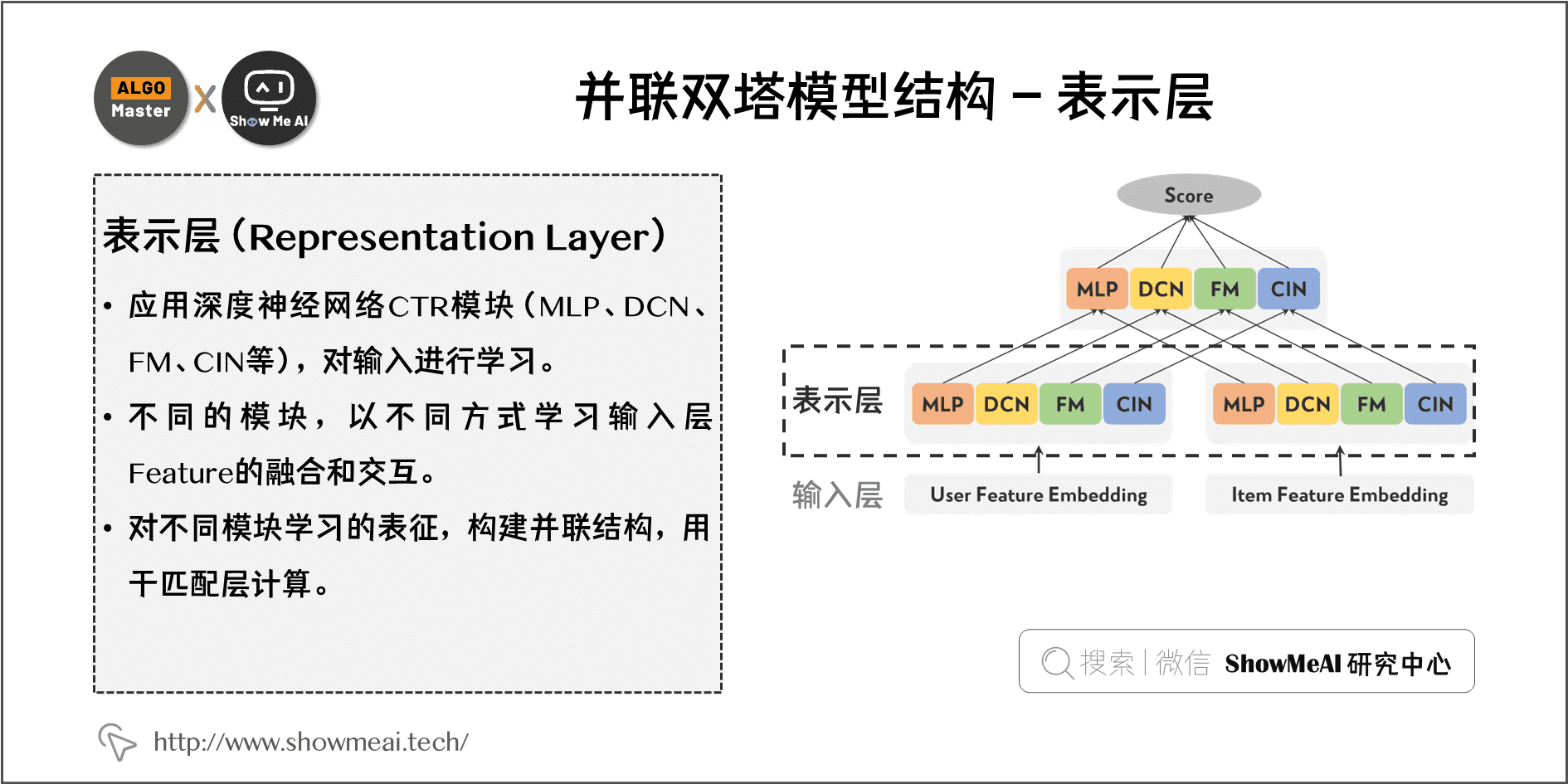
2.2 表示层(Representation Layer)
- 对输入应用深度神经网络CTR模块(MLP、DCN、FM、CIN 等)进行学习,不同的模块可以以不同方式学习输入层 feature 的融合和交互。
- 对不同模块学习的表征,构建并联结构用于匹配层计算。
- 表示层的 User-User 和 Item-Item 的特征交互(塔内信息交叉)在本塔分支就可以做到,而 User-Item 的特征交互只能通过上层操作实现。
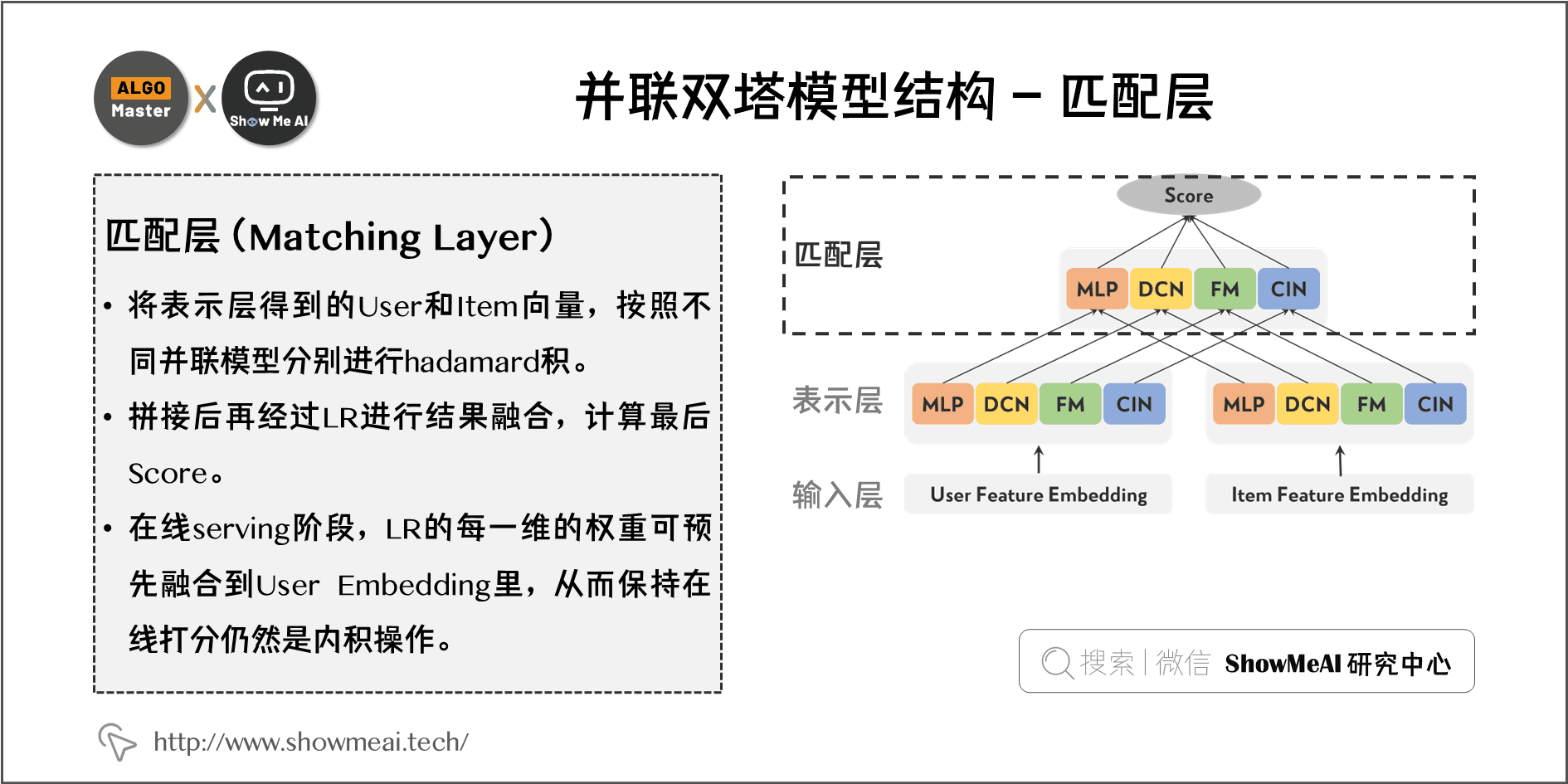
2.3 匹配层(Matching Layer)
- 将表示层得到的 User 和 Item 向量,按照不同并联模型分别进行 hadamard 积,拼接后再经过LR 进行结果融合计算最后score。
- 在线 serving 阶段 LR 的每一维的权重可预先融合到 User Embedding 里,从而保持在线打分仍然是内积操作。
三、双塔的表示层结构 -MLP/DCN结构
双塔内一般都会使用 MLP 结构(多层全连接),腾讯QQ浏览器团队还引入了 DCN 中的 Cross Network 结构用于显式的构造高阶特征交互,参考的结构是 Google 论文改进版 DCN-Mix。
3.1 DCN 结构
DCN 的特点是引入 Cross Network这种交叉网络结构,提取交叉组合特征,避免传统机器学习中的人工手造特征的过程,网络结构简单复杂度可控,随深度增加获得多阶交叉特征。DCN模型具体结构如图:
- 底层是 Embedding layer 并对 Embedding 做了stack。
- 上层是并行的 Cross Network 和 Deep Network。
- 头部是 Combination Layer 把 Cross Network 和 Deep Network 的结果 stack 得到 Output。

3.2 优化的DCN-V2结构引入
Google在DCN的基础上提出改进版 DCN-Mix/DCN-V2,针对 Cross Network 进行了改进,我们主要关注 Cross Network 的计算方式变更:
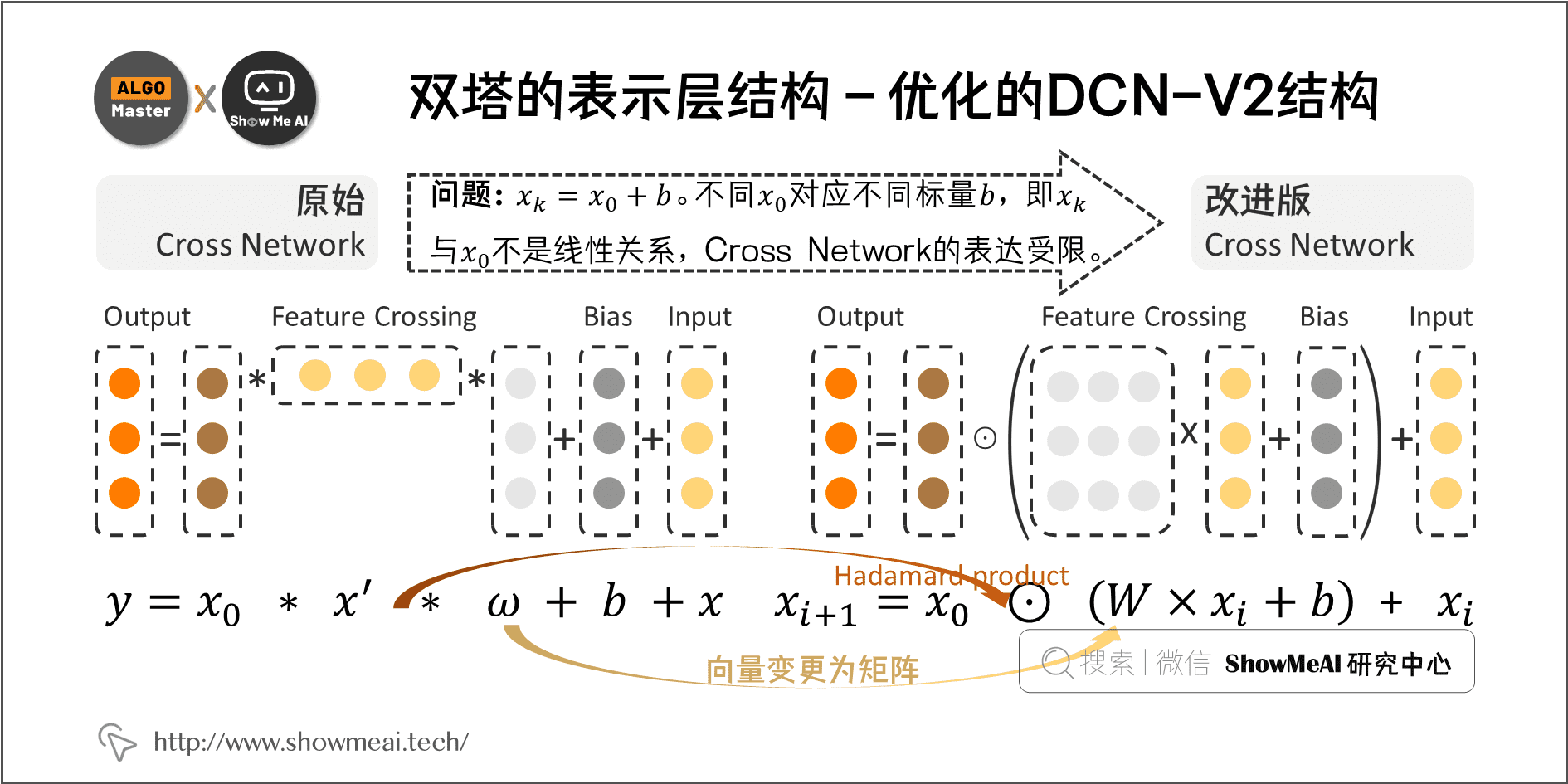
1)原始 Cross Network 计算方式
原始计算公式下,经过多层计算,可以显式地学习到高维的特征交互,存在的问题是被证明最终的 k 阶交互结果 等于 和一个标量的乘积(但不同的 这个标量不同, 和 并不是线性关系),这个计算方式下 Cross Network 的表达受限。
2)改进版 Cross Network 计算方式
Google改进版的 DCN-Mix 做的处理如下:
- 由向量变更为矩阵,更大的参数量带来了更强的表达能力(实际W 矩阵也可以进行矩阵分解)。
- 变更特征交互方式:不再使用外积,应用哈达玛积(Hadamard product)。
3)DCN-V2代码参考
DCN-v2的代码实现和ctr应用案例可以参考 Google官方实现 https://github.com/tensorflow/models/tree/master/official/recommendation/ranking
其中核心的改进后的 deep cross layer代码如下:
class Cross(tf.keras.layers.Layer): """Cross Layer in Deep & Cross Network to learn explicit feature interactions. A layer that creates explicit and bounded-degree feature interactions efficiently. The `call` method accepts `inputs` as a tuple of size 2 tensors. The first input `x0` is the base layer that contains the original features (usually the embedding layer); the second input `xi` is the output of the previous `Cross` layer in the stack, i.e., the i-th `Cross` layer. For the first `Cross` layer in the stack, x0 = xi. The output is x_{i+1} = x0 .* (W * xi + bias + diag_scale * xi) + xi, where .* designates elementwise multiplication, W could be a full-rank matrix, or a low-rank matrix U*V to reduce the computational cost, and diag_scale increases the diagonal of W to improve training stability ( especially for the low-rank case). References: 1. [R. Wang et al.](https://arxiv.org/pdf/2008.13535.pdf) See Eq. (1) for full-rank and Eq. (2) for low-rank version. 2. [R. Wang et al.](https://arxiv.org/pdf/1708.05123.pdf) Example: ```python # after embedding layer in a functional model: input = tf.keras.Input(shape=(None,), name='index', dtype=tf.int64) x0 = tf.keras.layers.Embedding(input_dim=32, output_dim=6) x1 = Cross()(x0, x0) x2 = Cross()(x0, x1) logits = tf.keras.layers.Dense(units=10)(x2) model = tf.keras.Model(input, logits) ``` Args: projection_dim: project dimension to reduce the computational cost. Default is `None` such that a full (`input_dim` by `input_dim`) matrix W is used. If enabled, a low-rank matrix W = U*V will be used, where U is of size `input_dim` by `projection_dim` and V is of size `projection_dim` by `input_dim`. `projection_dim` need to be smaller than `input_dim`/2 to improve the model efficiency. In practice, we've observed that `projection_dim` = d/4 consistently preserved the accuracy of a full-rank version. diag_scale: a non-negative float used to increase the diagonal of the kernel W by `diag_scale`, that is, W + diag_scale * I, where I is an identity matrix. use_bias: whether to add a bias term for this layer. If set to False, no bias term will be used. kernel_initializer: Initializer to use on the kernel matrix. bias_initializer: Initializer to use on the bias vector. kernel_regularizer: Regularizer to use on the kernel matrix. bias_regularizer: Regularizer to use on bias vector. Input shape: A tuple of 2 (batch_size, `input_dim`) dimensional inputs. Output shape: A single (batch_size, `input_dim`) dimensional output. """ def init( self, projection_dim: Optional[int] = None, diag_scale: Optional[float] = 0.0, use_bias: bool = True, kernel_initializer: Union[ Text, tf.keras.initializers.Initializer] = "truncated_normal", bias_initializer: Union[Text, tf.keras.initializers.Initializer] = "zeros", kernel_regularizer: Union[Text, None, tf.keras.regularizers.Regularizer] = None, bias_regularizer: Union[Text, None, tf.keras.regularizers.Regularizer] = None, **kwargs): super(Cross, self).__init__(**kwargs) self._projection_dim = projection_dim self._diag_scale = diag_scale self._use_bias = use_bias self._kernel_initializer = tf.keras.initializers.get(kernel_initializer) self._bias_initializer = tf.keras.initializers.get(bias_initializer) self._kernel_regularizer = tf.keras.regularizers.get(kernel_regularizer) self._bias_regularizer = tf.keras.regularizers.get(bias_regularizer) self._input_dim = None self._supports_masking = True if self._diag_scale < 0: raise ValueError( "`diag_scale` should be non-negative. Got `diag_scale` = {}".format( self._diag_scale)) def build(self, input_shape): last_dim = input_shape[-1] if self._projection_dim is None: self._dense = tf.keras.layers.Dense( last_dim, kernel_initializer=self._kernel_initializer, bias_initializer=self._bias_initializer, kernel_regularizer=self._kernel_regularizer, bias_regularizer=self._bias_regularizer, use_bias=self._use_bias, ) else: self._dense_u = tf.keras.layers.Dense( self._projection_dim, kernel_initializer=self._kernel_initializer, kernel_regularizer=self._kernel_regularizer, use_bias=False, ) self._dense_v = tf.keras.layers.Dense( last_dim, kernel_initializer=self._kernel_initializer, bias_initializer=self._bias_initializer, kernel_regularizer=self._kernel_regularizer, bias_regularizer=self._bias_regularizer, use_bias=self._use_bias, ) self.built = True def call(self, x0: tf.Tensor, x: Optionaltf.Tensor = None) -> tf.Tensor: """Computes the feature cross. Args: x0: The input tensor x: Optional second input tensor. If provided, the layer will compute crosses between x0 and x; if not provided, the layer will compute crosses between x0 and itself. Returns: Tensor of crosses. """ if not self.built: self.build(x0.shape) if x is None: x = x0 if x0.shape[-1] != x.shape[-1]: raise ValueError( "`x0` and `x` dimension mismatch! Got `x0` dimension {}, and x " "dimension {}. This case is not supported yet.".format( x0.shape[-1], x.shape[-1])) if self._projection_dim is None: prod_output = self._dense(x) else: prod_output = self._dense_v(self._dense_u(x)) if self._diag_scale: prod_output = prod_output + self._diag_scale * x return x0 * prod_output + x def get_config(self): config = { "projection_dim": self._projection_dim, "diag_scale": self._diag_scale, "use_bias": self._use_bias, "kernel_initializer": tf.keras.initializers.serialize(self._kernel_initializer), "bias_initializer": tf.keras.initializers.serialize(self._bias_initializer), "kernel_regularizer": tf.keras.regularizers.serialize(self._kernel_regularizer), "bias_regularizer": tf.keras.regularizers.serialize(self._bias_regularizer), } base_config = super(Cross, self).get_config() return dict(list(base_config.items()) + list(config.items()))
四、双塔的表示层结构 - FM/FFM/CIN结构
另一类在CTR预估中常用的结构是FM系列的结构,典型的模型包括FM、FFM、DeepFM、xDeepFM。他们特殊的建模方式也能挖掘有效的信息,腾讯QQ浏览器团队的最终模型上,也使用了上述模型的子结构。
上文提到的MLP和DCN的特征交互交叉,无法显式指定某些特征交互,而FM系列模型中的FM / FFM / CIN结构可以对特征粒度的交互做显式操作,且从计算公式上看,它们都具备很好的内积形式,从能方便直接地实现双塔建模 User-Item 的特征粒度的交互。
4.1 FM结构引入
FM是CTR预估中最常见的模型结构,它通过矩阵分解的方法构建特征的二阶交互。计算公式上表现为特征向量 和 的两两内积操作再求和(在深度学习里可以看做特征Embedding的组对内积),通过内积运算分配率可以转换成求和再内积的形式。
在腾讯QQ浏览器团队小说推荐场景中,只考虑 User-Item 的交互(因为User内部或者Item内部的特征二阶交互上文提到的模型已捕捉到)。
如上公式所示, 是 User 侧的特征, 是 Item 侧的特征,通过内积计算分配率的转换。User-Item 的二阶特征交互也可以转化为 User、Item 特征向量先求和(神经网络中体现为sum pooling)再做内积,很方便可以转为双塔结构处理。
4.2 FFM结构引入
FFM 模型是 FM 的升级版本,相比 FM,它多了 field 的概念。FFM 把相同性质的特征归于同一个field,构建的隐向量不仅与特征相关,也与field相关,最终的特征交互可以在不同的隐向量空间,进而提升区分能力加强效果,FFM 也可以通过一些方法转换成双塔内积的结构。
User 有 2 个特征 field、Item 有 3 个特征 field,图中任意2个特征交互都有独立的 Embedding 向量。根据 FFM 公式,计算 User-Item 的二阶交互,需要将所有的内积计算出来并求和。一个转换的例子如下:
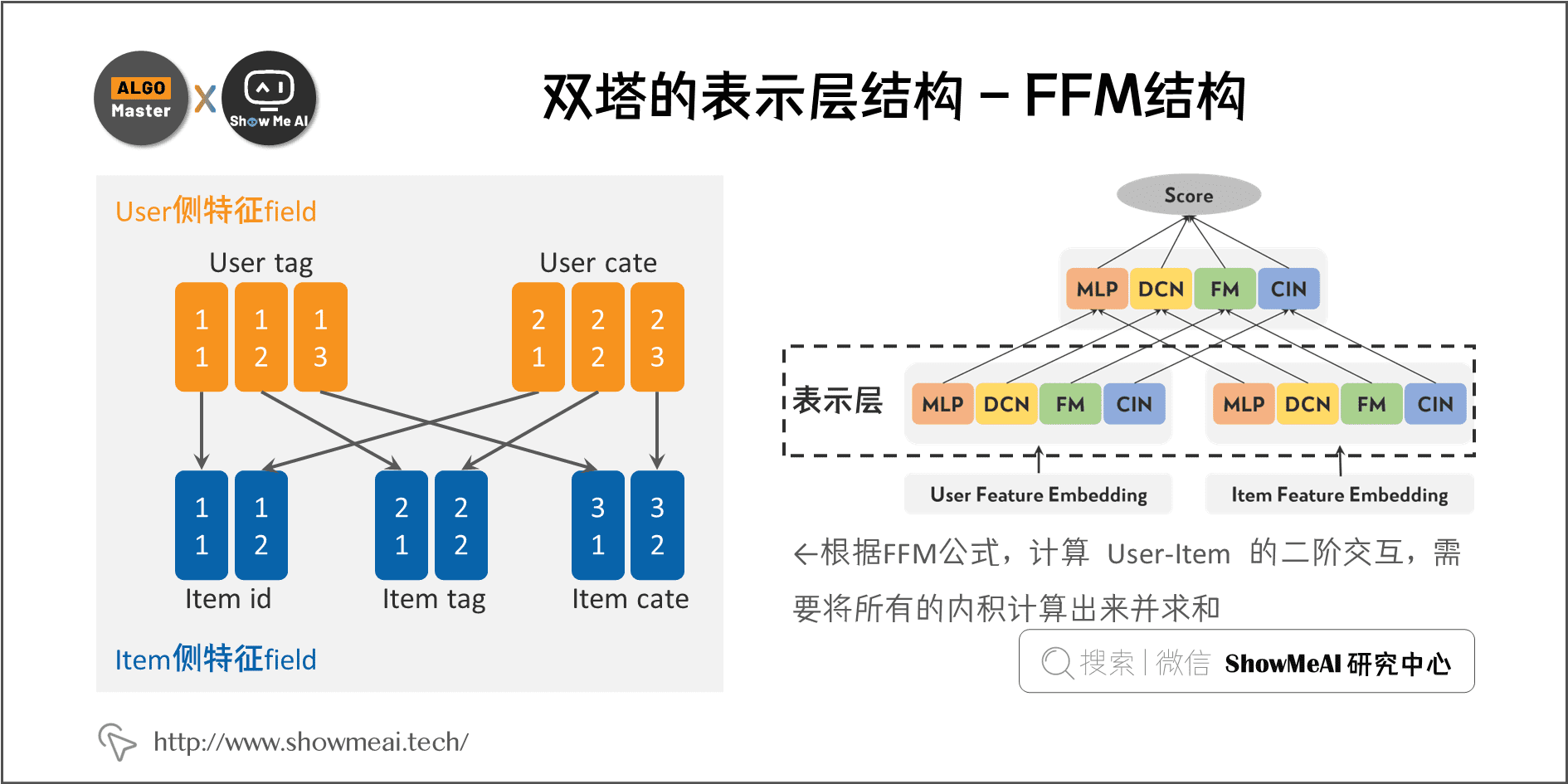
我们将User、Item 的特征 Embedding 做重新排序,再进行拼接,可以把 FFM 也转换成双塔内积形式。FFM 内的 User-User 和 Item-Item 都在塔内,所以我们可预先算好放入一阶项里。

腾讯QQ浏览器团队实践应用中发现:应用 FFM 的双塔,训练数据上 AUC 提升明显,但参数量的增加带来了严重的过拟合,且上述结构调整后双塔的宽度极宽(可能达到万级别),对性能效率影响较大,进一步尝试的优化方式如下:
- 人工筛选参与 FFM 训练特征交互的 User 和 Item 特征 field,控制双塔宽度(1000左右)。
- 调整 FFM 的 Embedding 参数初始化方式(接近 0)及学习率(降低)。

最终效果不是很理想,因此团队实际线上并未使用 FFM。
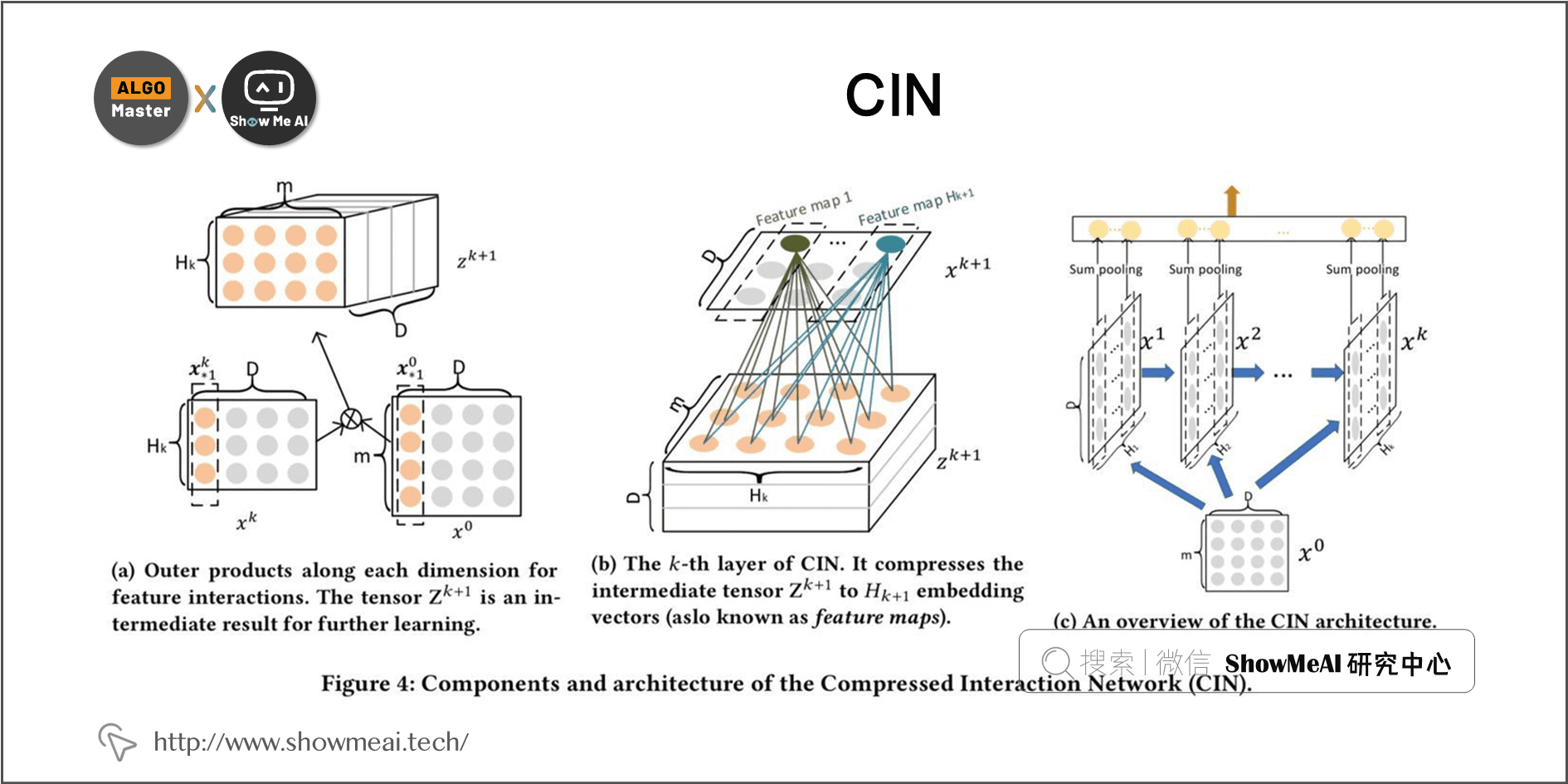
4.3 CIN结构引入
前面提到的FM和FFM能完成二阶特征交互,而xDeepFM模型中提出的 CIN 结构可以实现更高阶的特征交互(比如 User-User-Item、User-User-Item-Item、User-Item-Item 等3阶),腾讯QQ浏览器团队尝试了两种用法把CIN应用在双塔结构中:
1)CIN(User) * CIN(Item)
双塔每个塔内生成 User、Item 的自身多阶 CIN 结果,再分别 sum pooling 生成 User/Item 向量,然后User 与 Item 向量内积。
根据分配率,我们对 sum pooling 再内积的公式进行拆解,会发现这个计算方式内部其实已经实现了 User-Item 的多阶交互:
这个用法实现过程也比较简单,针对双塔结构,在两侧塔内做 CIN 生成各阶结果,再对结果做 sumpooling,最后类似 FM 原理通过内积实现 User-Item 的各阶交互。

这个处理方式有一定的缺点:生成的 User-Item 二阶及以上的特征交互,有着和 FM 类似的局限性(例U1 是由 User 侧提供的多个特征sumpooling所得结果,U1 与 Item 侧的结果内积计算,受限于sum pooling的计算,每个 User 特征在这里重要度就变成一样的了)。
2)CIN( CIN(User) , CIN(Item) )
第2种处理方式是:双塔每侧塔内生成 User、Item 的多阶 CIN 结果后,对 User、Item 的 CIN 结果再次两两使用 CIN 显式交互(而非 sum pooling 后计算内积),并转成双塔内积,如下图所示:
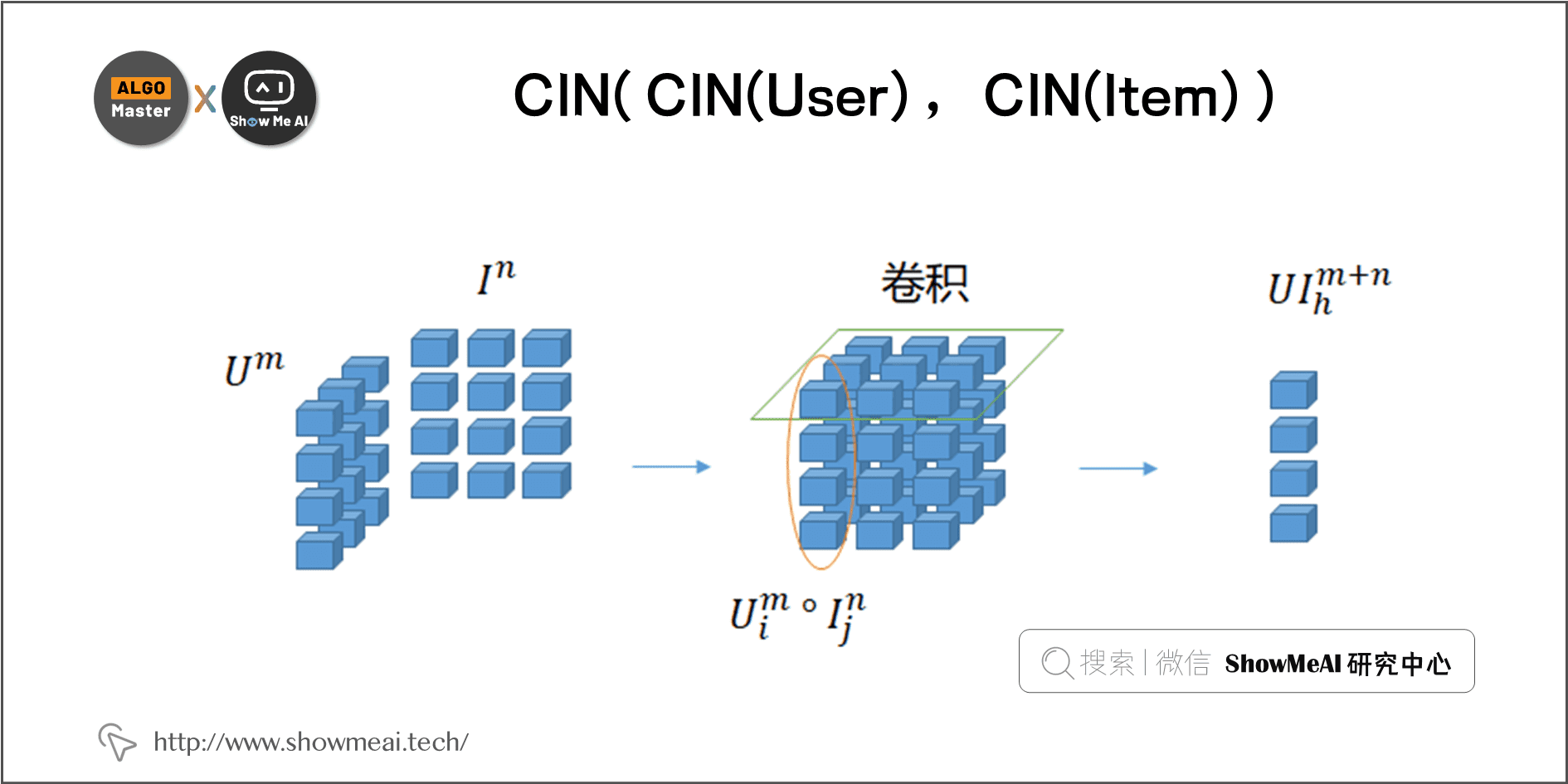
下图为 CIN 计算的公式表示,多个卷积结果做 sum pooling 后形式保持不变(两两 hadamard 积加权求和)。
CIN 的形式和 FFM 类似,同样可以通过 『重新排列+拼接』 操作转换成双塔内积形式,生成的双塔宽度也非常大(万级别)。但与 FFM 不同的是:CIN 的所有特征交互,底层使用的 feature Embedding 是共享的,而 FFM 对每个二阶交互都有独立的 Embedding。

因此腾讯QQ浏览器团队的实践尝试中基本没有出现过拟合问题,实验效果上第②种方式第①种用法略好。
五、腾讯业务效果
以下为腾讯QQ浏览器小说推荐业务上的方法实验效果(对比各种单CTR模型和并联双塔结构):

5.1 团队给出的一些分析如下
① CIN2 在单结构的双塔模型中的效果是最好的,其次是 DCN 和 CIN1的双塔结构。
② 并联的双塔结构相比于单一的双塔结构在效果上也有明显提升。
③ 并联方案二使用了 CIN2 的结构,双塔宽度达到了 2万+,对线上 serving 的性能有一定的挑战,综合考虑效果和部署效率可以选择并联双塔方案一。
5.2 团队给出的一些训练细节和经验
① 考虑到FM/FFM/CIN 等结构的计算复杂度,都只在精选特征子集上面训练,选取维度更高的 category 特征为主,比如用户id、行为历史id、小说id、标签id 等,还有少量统计特征,User 侧、Item 侧大概各选了不到 20 个特征field。
② 并联的各双塔结构,各模型不共享底层 feature Embedding,分别训练自己的 Embedding。
③ feature Embedding 维度选择,MLP/DCN 对 category 特征维度为 ,非 category特征维度是 。
④ FM/FFM/CIN 的 feature Embedding 维度统一为 。
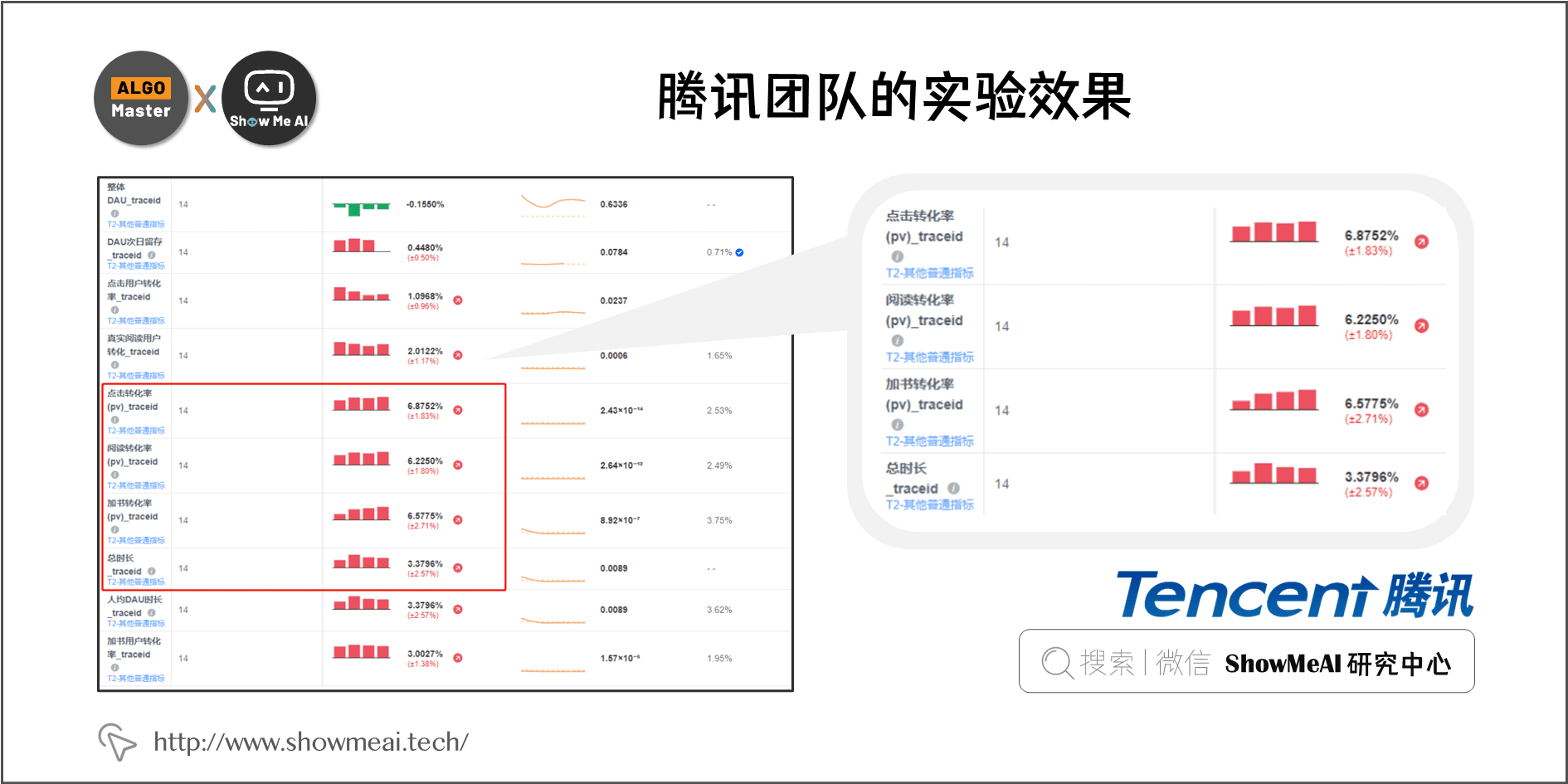
六、腾讯团队实验效果
在小说推荐场景的粗排阶段上线了 A/B Test 实验,实验组的点击率、阅读转化率模型使用了『并联双塔方案一』,对照组为 『MLP 双塔模型』,如下图所示,有明显的业务指标提升:
- 点击转化率
- 阅读转化率
- 加书转化率
- 阅读总时长
参考文献
- [1] Huang, Po-Sen, et al. "Learning deep structured semantic models for web search using clickthrough data." Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2013.
- [2] S. Rendle, “Factorization machines,” in Proceedings of IEEE International Conference on Data Mining (ICDM), pp. 995–1000, 2010.
- [3] Yuchin Juan, et al. "Field-aware Factorization Machines for CTR Prediction." Proceedings of the 10th ACM Conference on Recommender SystemsSeptember 2016 Pages 43–
- [4] Jianxun Lian, et al. "xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems" Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data MiningJuly 2018 Pages 1754–1763
- [5] Ruoxi Wang, et al. "Deep & Cross Network for Ad Click Predictions" Proceedings of the ADKDD'17August 2017 Article No.: 12Pages 1–
- [6] Wang, Ruoxi, et al. "DCN V2: Improved Deep & Cross Network and Practical Lessons for Webscale Learning to Rank Systems" In Proceedings of the Web Conference 2021 (WWW '21); doi:10.1145/3442381.3450078
ShowMeAI 大厂技术实现方案推荐
- 大厂解决方案系列 | 数据集&代码集(持续更新中):https://www.showmeai.tech/tutorials/50
- ShowMeAI官方GitHub(实现代码):https://github.com/ShowMeAI-Hub/
- 『推荐与广告』大厂解决方案
- 『计算机视觉 CV』大厂解决方案
- 『自然语言处理 NLP』大厂解决方案
- 『金融科技』大厂解决方案
- 『生物医疗』大厂解决方案
- 『智能制造』大厂解决方案
- 『其他AI垂直领域』大厂解决方案
ShowMeAI系列教程精选推荐
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人