Zookeeper技术分享
内容整理自组内分享PPT

一.概述
ZooKeeper 遵循一个简单的客户端-服务器模型,其中客户端 是使用服务的节点(即机器),而服务器 是提供服务的节点。ZooKeeper 服务器的集合形成了一个 ZooKeeper 集合体(ensemble)。在任何给定的时间内,一个 ZooKeeper 客户端可连接到一个 ZooKeeper 服务器。每个 ZooKeeper 服务器都可以同时处理大量客户端连接。每个客户端定期发送 ping 到它所连接的 ZooKeeper 服务器,让服务器知道它处于活动和连接状态。被询问的 ZooKeeper 服务器通过 ping 确认进行响应,表示服务器也处于活动状态。如果客户端在指定时间内没有收到服务器的确认,那么客户端会连接到集合体中的另一台服务器,而且客户端会话会被透明地转移到新的 ZooKeeper 服务器。
Zookeeper的节点兼具文件和目录两种特点,除此之外,Znode还有以下特性:
1.Znode可以被监控
2.Znode有版本
3.每个Znode存储的数据大小至多1M左右

二.节点的分类
ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变:
① 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。
② 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
三.读写分离
当客户端请求读取特定 znode 的内容时,读取操作是在客户端所连接的服务器上进行的。因此,由于只涉及集合体中的一个服务器,所以读取是快速和可扩展的。然而,为了成功完成写入操作,要求 ZooKeeper 集合体的严格意义上的多数节点都是可用的。在启动 ZooKeeper 服务时,集合体中的某个节点被选举为领导者。当客户端发出一个写入请求时,所连接的服务器会将请求传递给领导者。此领导者对集合体的所有节点发出相同的写入请求。如果严格意义上的多数节点(也被称为法定数量(quorum))成功响应该写入请求,那么写入请求被视为已成功完成。然后,一个成功的返回代码会返回给发起写入请求的客户端。
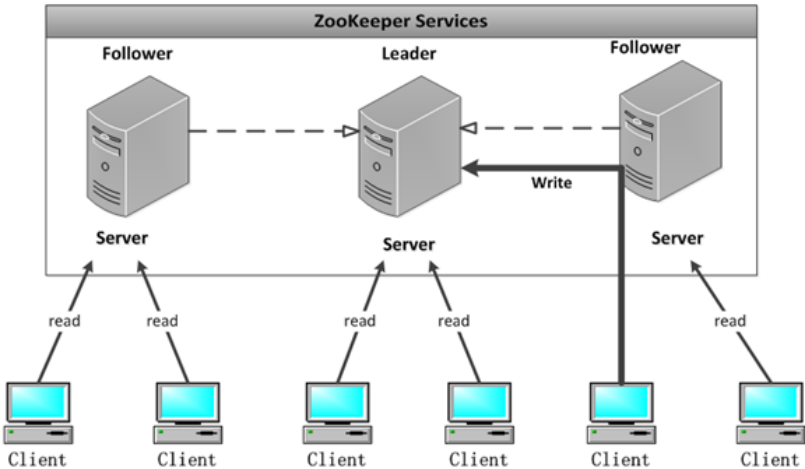
四.数据写入与节点选举
1.节点的角色:
(1) 投票Server:Leader、Follower
(2) 非投票Server:Observer:Observer的作用同Follower类似,唯一区别就是它不参与选主过程,为什么引入这个角色后文会讲到。
2.写入数据的流程:
来自Client的所有写请求,都要转发给ZK服务中唯一的Server—Leader,由Leader根据该请求发 起一个Proposal。然后,其他的Server对该Proposal进行Vote。之后,Leader对Vote进行收集,当Vote数量过半时 Leader会向所有的Server发送一个通知消息。最后,当Client所连接的Server收到该消息时,会把该操作更新到内存中并对Client 的写请求做出回应。当znode改变的时候服务器监听被触发,会回调客户端,客户端可以在回调中做自己需要处理的逻辑 ,以下这些操作会触发watcher:create、delete、setData、setACL。
3.为什么引入Observer:
ZooKeeper 服务器在上述的写入数据流程中实际扮演了两个职能。它们一方面从客户端接受连接与操作请求,另一方面对操作结果进行投票。这两个职能在 ZooKeeper集群扩展的时候彼此制约。例如,当我们希望增加 ZK服务中Client数量的时候,那么我们就需要增加Server的数量,来支持这么多的客户端。然而,我们可以发 现,增加服务器的数量,则增加了对协议中投票过程的压力。因为Leader节点必须等待集群中过半Server响应投票,于是节点的增加使得部分计算机运 行较慢,从而拖慢整个投票过程的可能性也随之提高,写操作也会随之下降。这正是我们在实际操作中看到的问题——随着 ZooKeeper 集群变大,写操作的吞吐量会下降。
我们不得不在增加Client数量的期望和我们希望保持较好吞吐性能的期望间进行权衡。要打破这一耦合关系,我们引入了不参与投票的服务器,称为Observer。 Observer可以接受客户端的连接,并将写请求转发给Leader节点。但是,Leader节点不会要求 Observer参加投票。相反,Observer不参与投票过程,仅仅在上述第3歩那样,和其他服务节点一起得到投票结果。
(zookeeper中规定只有当多余一半的节点同步完成整个write操作才算完成。也就是说可能会有少于一半的数据不是新数据,因此zookeeper中数据不是强一致性而是最终一致性。)

上图纵轴是单一客户端能够发出的每秒钟同步写操作的数量。横轴是 ZooKeeper 集群的尺寸。蓝色的是每个服务器都是投票Server的情况,而绿色的则只有三个是投票Server,其它都是 Observer。从图中我们可以看出,我们在扩充 Observer时写性能几乎可以保持不便。但是,如果扩展投票Server的数量,写性能会明显下降,显然 Observers 是有效的。这个简单的扩展,给 ZooKeeper 的可伸缩性带来了全新的景象。我们现在可以加入很多 Observer 节点,而无须担心严重影响写吞吐量。Observer即使fail掉也不影响zk集群服务。
由于上述这些条件,Zookeeper能够保证:
1.顺序一致性来自于客户端的更新,根据发送的先后被顺序实施。
2.唯一的系统映像 client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
3.可靠性 具有简单、健壮、良好的性能,如果消息m被一台服务器接受,那么它将被所有的服务器接受。
五.节点的删除
ZooKeeper类提供了一个delete()方法,该方法有两个参数: 1. 路径 2. 版本号
如果所提供的路径与版本号与某个znode一致,ZooKeeper会删除这个znode。这是一种乐观锁,使客户端能够检测出对znode的修改冲突。通过将版本号设置为-1,可以绕过这个版本检测机制,不管znode的版本号是什么而直接将其删除。
ZooKeeper不支持递归的删除操作,因此在删除父节点之前必须先删除子节点。
六.举例Zookeeper提供的服务
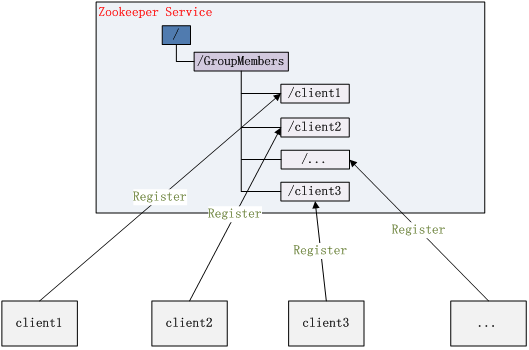
1.集群管理
集群内的所有机器在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用 getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。
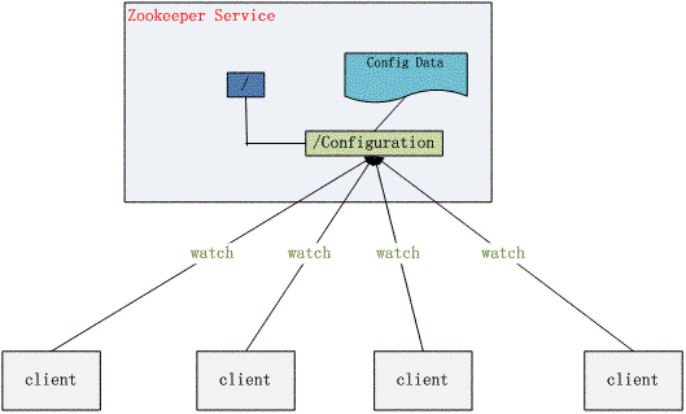
2.配置管理
分布式应用需要多台Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的Server,这样非常麻烦而且容易出错。可以将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
3.分布式锁

分布式锁在一组进程之间提供了一种互斥机制。在任何时刻,在任何时刻只有一个进程可以持有锁。分布式锁可以在大型分布式系统中实现领导者选举,在任何时间点,持有锁的那个进程就是系统的领导者。另外,请注意,这里所说的领导者选举指的是利用zk的特性帮助分布式应用选举领导,上文所说的是ZK内部的领导选举。
流程:每个需要获取锁的进程在ZK中注册一个临时而且顺序的Znode(EPHEMERAL_SEQUENTIAL类型),每个顺序Znode内部会维护一个zxid(顺序号),zxid是一个全局变量,随着Znode的每一次改变而递增,在任何时间点,zxid最小的进程将持有锁。删除节点即可释放锁,如果客户端进程死亡,对应的短暂Znode也会被删除。当leader挂掉的时候,剩余的flower选择zxid最大的节点作为新的leader。
七.Zookeeper的安装
1.单机模式:Zookeeper只运行在一台服务器上,适合测试环境;
2.伪集群模式:就是在一台物理机上运行多个Zookeeper 实例;
在一台机器上部署了3个server,需要注意的是在集群伪集群模式下我们使用的每个配置文档模拟一台机器,也就是说单台机器及上运行多个Zookeeper实例。但是,必须保证每个配置文档的各个端口号不能冲突,除了clientPort不同之外,Zookeeper安装目录也不能相同。另外,还要在dataDir所对应的目录中创建myid文件来指定对应的Zookeeper服务器实例,不同实例需要有不同的端口号。
3.集群模式(通常使用的模式):Zookeeper运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”(ensemble)
4.配置文件中的一些配置项:
client:监听客户端连接的端口
tickTime:基本事件单元,这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,每隔tickTime时间就会发送一个心跳;
最小的session过期时间为2倍tickTime
maxClientCnxns:这个操作将限制连接到Zookeeper的客户端数量,并限制并发连接的数量,通过IP来区分不同的客户端。
initLimit:此配置表示,允许follower连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
syncLimit:此配置项表示Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.A=B:C:D:A:其中 A 是一个数字,表示这个是服务器的编号;B:是这个服务器的 ip 地址;C:Leader选举的端口;D:Zookeeper服务器之间的通信端口。
参考资料:
http://www.douban.com/note/208430424/ rdc.taobao.com/blog/cs/?p=162 http://www.cnblogs.com/lpshou/archive/2013/06/14/3136738.html http://my.oschina.net/u/658658/blog/474277 http://www.cnblogs.com/sunddenly/p/4033574.html http://www.ibm.com/developerworks/cn/data/library/bd-zookeeper/ https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号