Graylog源码分析
上文主要介绍了Graylog的功能与架构,本篇我们来看看Graylog的源码
一. 项目启动(CmdLineTool)
启动基本做了这几件事:初始化logger,插件加载(这里用到了Java SPI机制),性能度量Metrics初始化(用的是codahale metrics,这个在开源软件中用的
还挺多的,Kafka用的也是这个),最后将使用了JMXReporter将性能监控暴露给JMX。
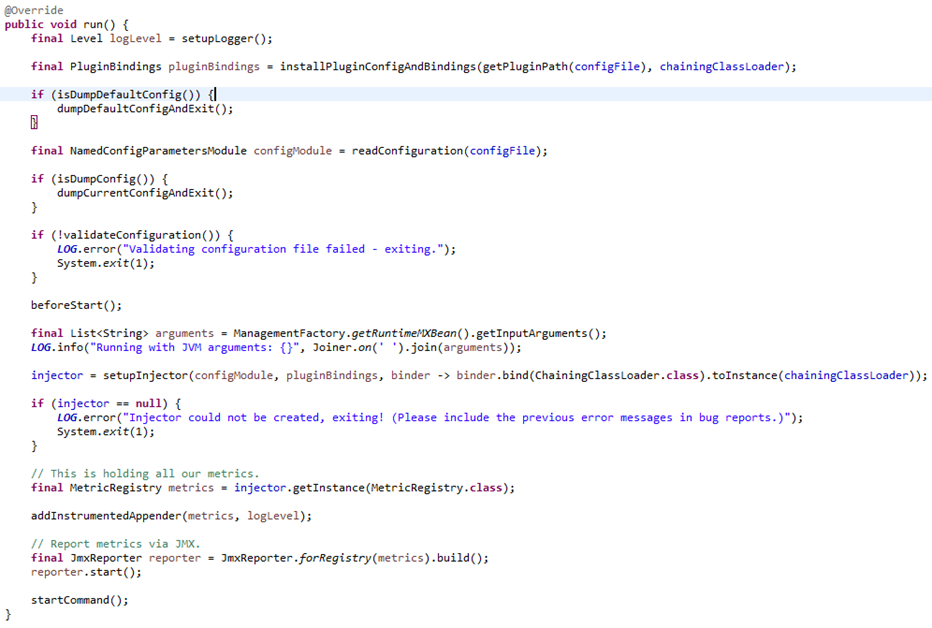
1. 插件加载(CmdLineTools类):
Graylog自定义了一个ClassLoader用于加载指定目录下的插件(ChainingClassLoader),将插件加载至内存后做了一个简单的版本校验。
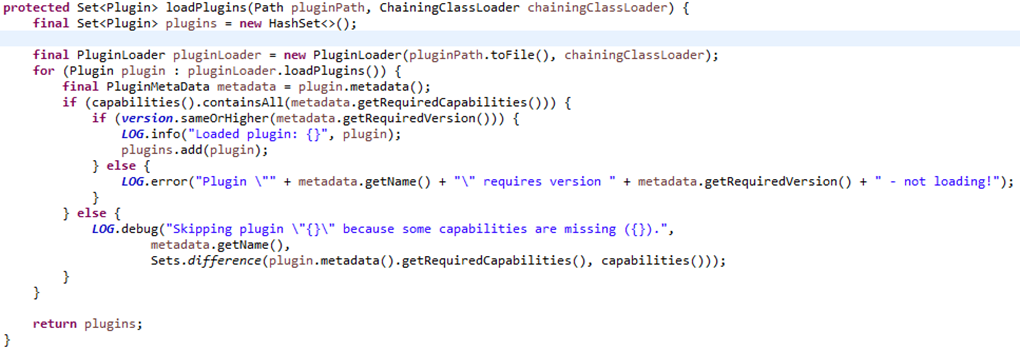
之前有提到Graylog插件采用的是Java SPI机制,可以在PluginLoader这个类中看到:

这里,终于看到了熟悉的ServiceLoader类,对SPI机制感兴趣的朋友,可以搜索相关文章。
2.Rest接口服务(JerseyService类):
Rest方面,Graylog使用的是Jersey提供的web service,Jersey在国内好像一直不温不火,但是国外的开源项目里用到的还挺多的。
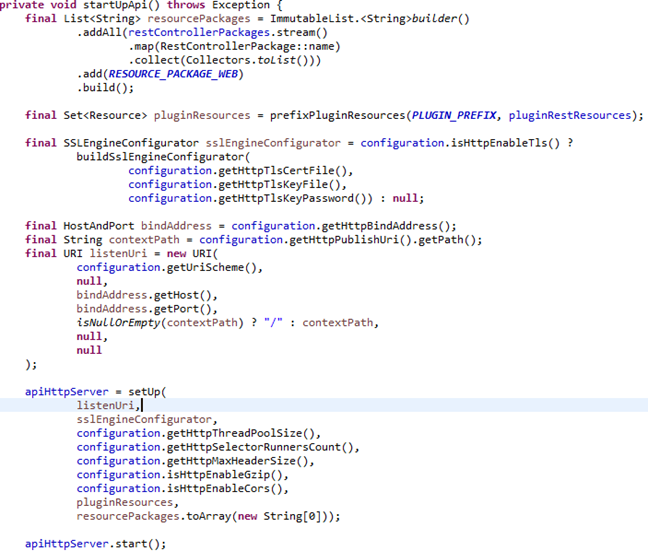
项目启动就介绍到这儿,Graylog在依赖注入方面,大量用到了Google的Guice框架,不过我对Guice一直是只闻其名,有机会再研究吧 :)。
二.Graylog的Journal机制
通常,在项目中,如果遇到大量日志处理问题,我们很可能会选择Kafka做消息队列,但在有些客户系统资源有限的情况下,消息队列集群显然是一个
奢侈的选择,Graylog的处理方式很有意思,它并没有完全实现自己的一套消息队列机制,而是使用了Kafka日志处理底层的API,你可以认为,Graylog
将Kafka做的一些工作(磁盘日志管理,日志缓冲,定时清理等)放到自己进程里进行。
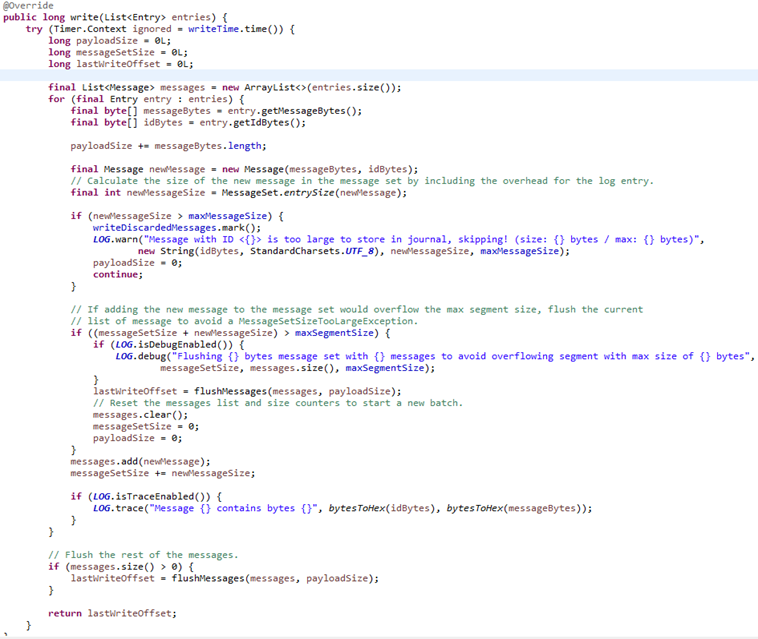
熟悉Kafka的朋友看到这里应该不会陌生了,Graylog同Kafka一样,将磁盘上的日志分为Segments进行管理。
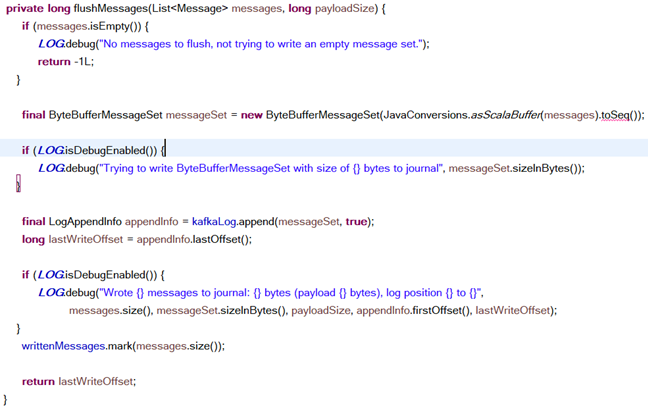
我们来看下Graylog写入磁盘的文件,你会发现和Kafka并没有什么不同

此外Graylog中还有PeriodicalsService定时服务(负责系统所有定时任务),ActivityWriter用户操作入库服务.etc,比较简单,在此不一一列举.。
三. Graylog中的数据流转
说了这么多,Graylog既然是日志处理软件,那么一条来自系统外部的日志进入Graylog server后的处理流程是什么呢?
我将Graylog对日志的处理进行了简单的分层,数据的处理流程大致是:
系统外部的原始数据->Transport(数据传输层) -> Input(数据接入层)-> InputBuffer(接入层缓冲ringBuffer)-> Encoder/Decoder(数据编解码层)-> 自带的Kafka(可选)->Process Buffer(业务处理层缓冲ringBuffer)-> ProcessBufferProcessor(日志业务处理器) –> OutputBuffer(日志输出/入库/转发缓冲RingBuffer) –> OutputBufferProcessor(输出/入库/转发处理器)
下面以Kafka日志接入为例,看看数据在graylog的整体处理流程:
- 日志接入层(KafkaTransport):
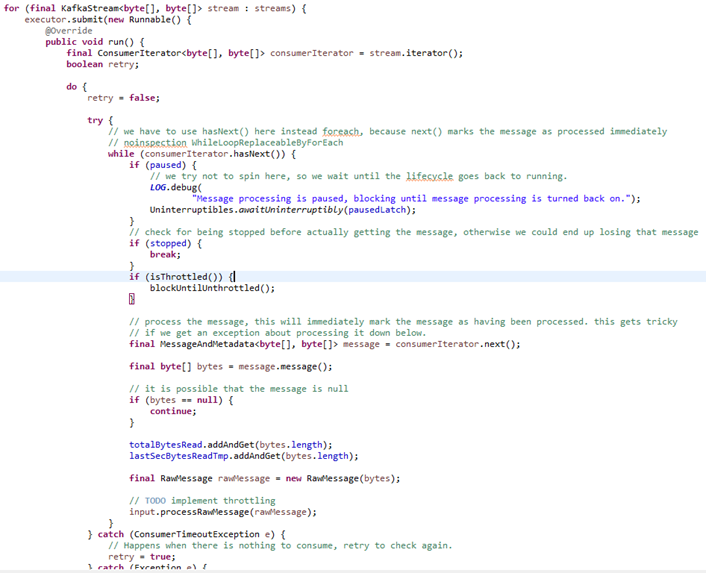
2.数据进入接入层缓冲(MessageInput)
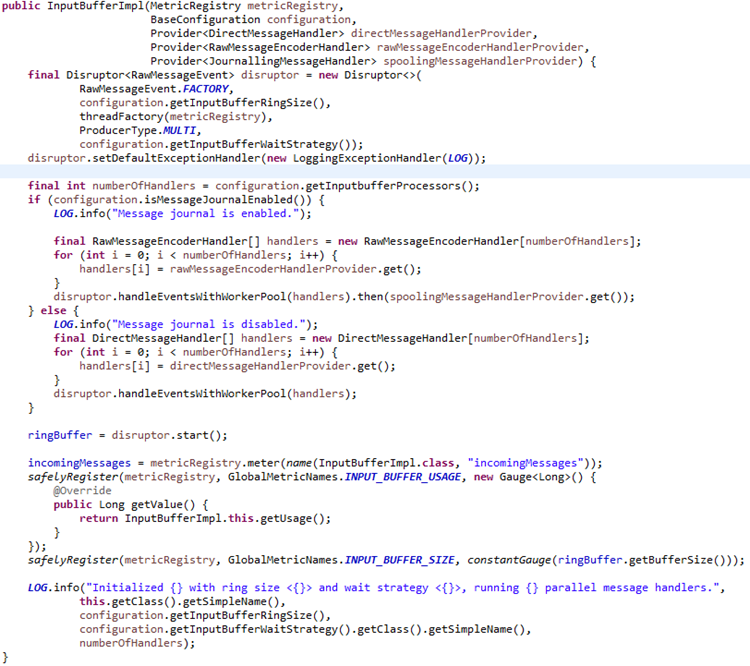
InputBufferImpl

3. 日志解码处理器+日志业务处理器+写入自带的Kafka,通过Disruptor Handler (InputBufferImpl)
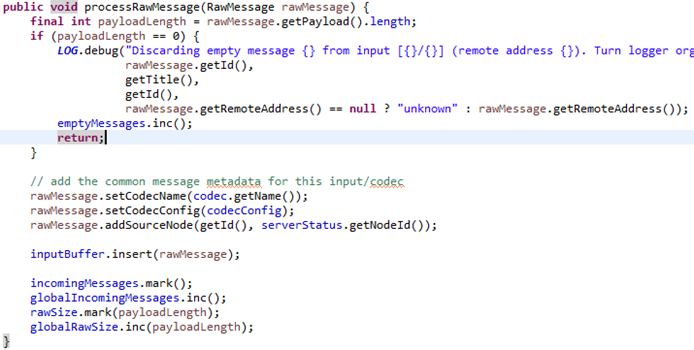
4. 日志直接写入业务逻辑缓冲RingBuffer(不通过Kafka)

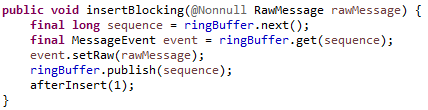
5. 日志写入kafka,由后续流程消费(JournallingMessageHandler)
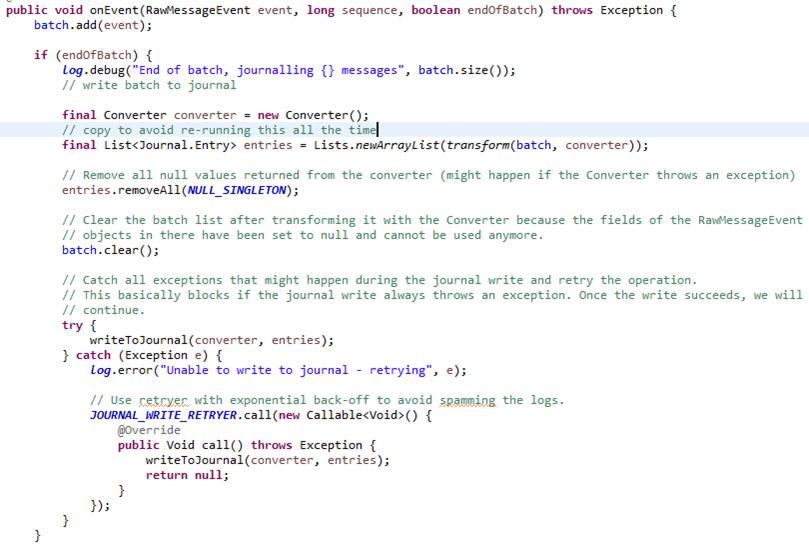
6. 一个后台线程,不断从自带的Kafka中读取数据,写入到下个流程的Buffer里(JournalReader类)
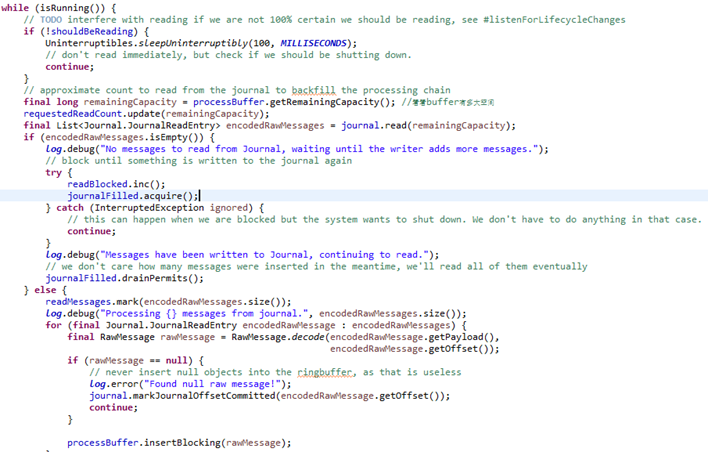
7. 业务处理器 ProcessBufferProcessor(graylog所有对日志进行的业务处理都绑定到了这个类里,如日志过滤,规则,威胁情报富化,地理位置富化,知识库…)

具体的处理器实现比较复杂,放到最后讲吧。
8. 数据输出/转发/入库Buffer

9. 数据输出(OutputBufferProcessor)
数据可能会有多个output,输出到output的过程是异步而且有时间限制,不会影响到系统整体吞吐量。
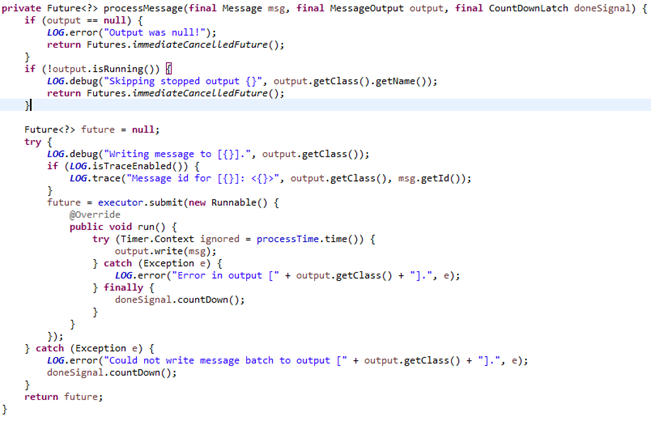
以写入ES为例(BlockingBatchedESOutput)

此外,系统还有一个线程负责定时将内存数据flush到ES,这里就不贴代码了。
10. MessageProcessor
系统自带的数据处理器包括GeoIpProcessor,MessageFilterChainProcessor,PipelineInterpreter
(1) GeoIpProcessor:数据富化(为原始日志添加地理位置,后续可视化时使用)

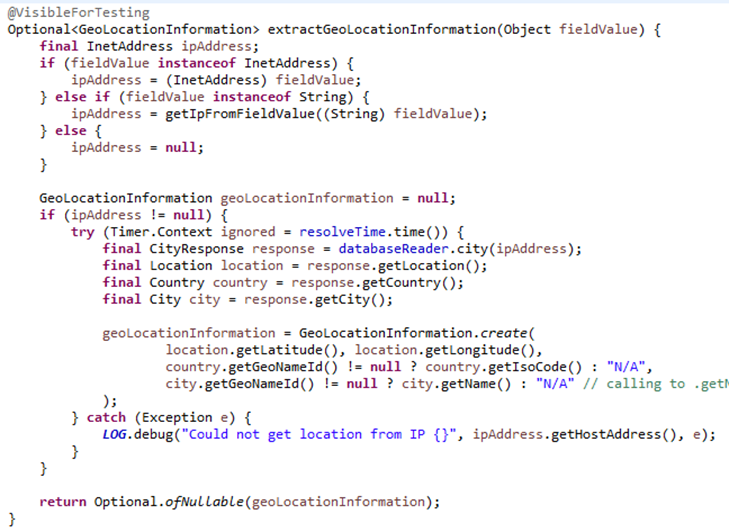
(2)MessageFilterChainProcessor(包含了所有的日志过滤器MessageFilter)

日志会一一经过排序后的过滤器,如果满足filter条件,标记为丢弃,并更新kafka offset。下面逐一分析过滤器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号