Spark 3.0.3集群安装文档
Spark 3.0.3集群安装文档
一、架构说明
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
192.168.10.62 node1
192.168.10.63 node2
192.168.10.64 node3
二、准备工作
2.1、Centos 7.9 安装 192.168.10.62、63、64
- 安装操作系统
- 配置网络
yum search ifconfig
yum -y install net-tools
2.2、Jdk-8u301安装
https://www.cnblogs.com/liugh/p/6623530.html
- Download jdk-8u301-linux-x64.tar.gz
- tar -zxvf jdk-8u301-linux-x64.tar.gz -C /usr/local/
- 配置环境变量
vi /etc/profile

- 测试
source /etc/profile
Java -version
- 同步安装其他几个服务器
2.3、Scala 下载、安装
ScalaSDK只需要在Windows安装即可
官方地址:https://www.scala-lang.org/download/scala2.html
2.4、spark下载
官方地址: http://spark.apache.org/downloads.html
spark-3.0.3-bin-hadoop2.7.tgz
注意:Note that, Spark 2.x is pre-built with Scala 2.11 except version 2.4.2, which is pre-built with Scala 2.12. Spark 3.0+ is pre-built with Scala 2.12.
2.5、zookeeper3.7
https://zookeeper.apache.org/doc/current/zookeeperStarted.html
http://zookeeper.apache.org/releases.html
三、Spark安装
3.1、上传文件
spark-3.0.3-bin-hadoop2.7.tgz
3.2、解压文件
tar -zxvf spark-3.0.3-bin-hadoop2.7.tgz -C /export/server/
mv spark-3.0.3-bin-hadoop2.7 spark
3.3、修改权限
chown -R root /export/server/
chgrp -R root /export/server/
3.4、测试
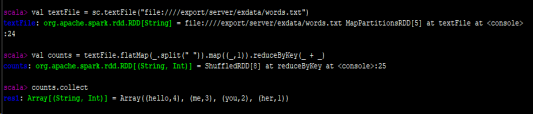
1、 打开spark交互窗口: ./spark-shell
3、准备文件
vi /export/server/exdata/words.txt

- 执行WordCount
![]()
四、配置spark集群
4.1、集群规划
node1:master
ndoe2:worker/slave
node3:worker/slave
4.2、配置slaves/workers
进入配置目录
cd /export/server/spark/conf
修改配置文件名称
mv slaves.template slaves
vi slaves

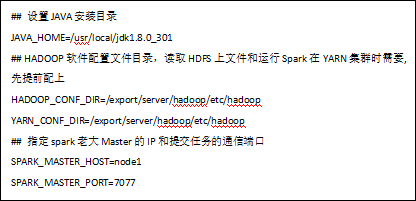
4.3、配置master
进入配置目录
cd /export/server/spark/conf
修改配置文件名称
mv spark-env.sh.template spark-env.sh
修改配置文件
vi spark-env.sh
4.4、分发
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
cd /export/server/
scp -r spark root@node2:$PWD
scp -r spark root@node3:$PWD
分别修改权限
chown -R root /export/server/
chgrp -R root /export/server/
4.5、测试

Master
Slaves
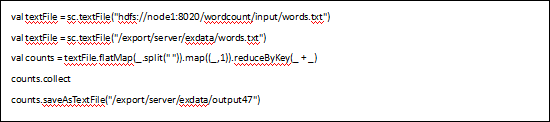
4.6、启动spark-shell 执行任务
/export/server/spark/bin/spark-shell --master spark://node1:7077
执行任务
4.7、spark管理界面
spark任务web-ui http://node1:4040/jobs/
master集群管理ui http://node1:8080
master提交任务的通讯端口 spark://node1:7077
五、配置Zookeeper集群
说明Node1、Node2、Node3做服务集群.
首先在node1上进行安装,随后分发到node2、node3节点上。
5.1、下载 zookeeper
官网下载地址:
http://mirror.bit.edu.cn/apache/zookeeper/
http://zookeeper.apache.org/doc/current/zookeeperStarted.htm
版本 :apache-zookeeper-3.7.0-bin.tar.gz
5.2、安装JDK
由于zookeeper集群的运行需要Java运行环境,所以需要首先安装 JDK
5.3、解压 zookeeper
在 /export/server 目录下新建 software 目录,然后将 zookeeper 压缩文件上传到该目录中,然后通过如下命令解压。
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /export/server
修改文件名
mv apache-zookeeper-3.7.0-bin zookeeper
5.4、修改配置文件 zoo.cfg
1、将zookeeper压缩文件解压后,我们进入到 conf 目录:
2、cd /export/server/zookeeper/conf
3、cp zoo_sample.cfg zoo.cfg
4、修改 zoo.cfg 文件

5.5、创建 myid 文件
在 上一步 dataDir 指定的目录下,创建 myid 文件
cd /opt/zookeeper/data
vi myid

5.6、分发
把zookeeper的安装目录同步到其他两个机器上
scp -r zookeeper root@node2:$PWD
scp -r zookeeper root@node3:$PWD
分别在node2和node3上创建按myid文件
5.7、测试
启动命令:
zkServer.sh start
停止命令:
zkServer.sh stop
重启命令:
zkServer.sh restart
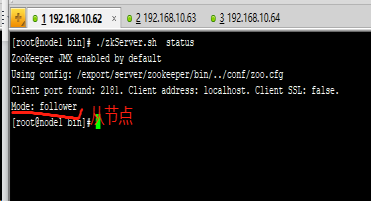
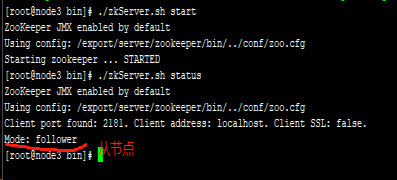
查看集群节点状态:
zkServer.sh status
Node1:
Node2:

Node3:
六、Zookeeper+Spark实现高可用
5.1、启动Zookeeper服务
zkServer.sh status
zkServer.sh stop
zkServer.sh start
5.2.修改配置
vi /export/server/spark/conf/spark-env.sh
注释:
#SPARK_MASTER_HOST=node1
增加:
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/export/spark-ha"
注意zookeeper安装完后8080端口就被占用了,可能影响到master-ui的默认端口.
SPARK_MASTER_WEBUI_PORT=8090
5.3.分发配置
cd /export/server/spark/conf
scp -r spark-env.sh root@node2:$PWD
scp -r spark-env.sh root@node3:$PWD
5.4、测试
1、启动zk服务
zkServer.sh status
zkServer.sh stop
zkServer.sh start
2、node1上启动Spark集群执行
/export/server/spark/sbin/start-all.sh
3、在node2上再单独只起个master:
/export/server/spark/sbin/start-master.sh
4、查看WebUI
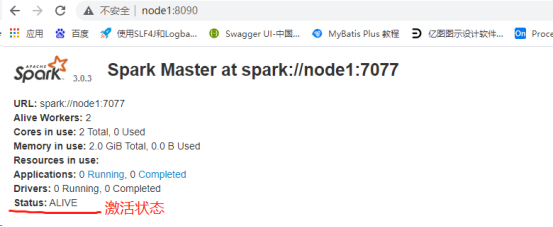
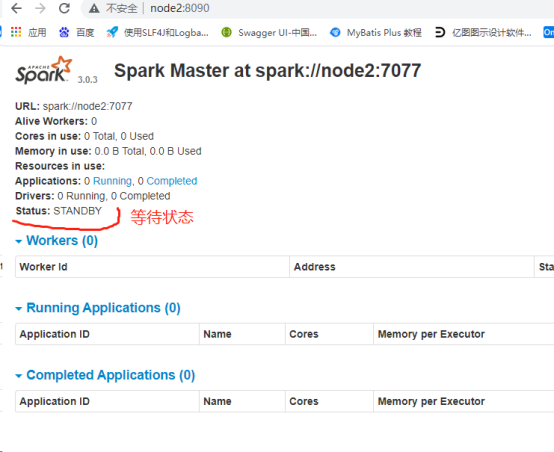
七、执行任务
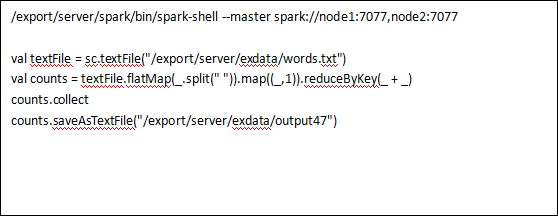
测试零个Master节点是否正常,node1上打开命令窗口
八、参考
7.1、spark官网
http://spark.apache.org/docs/latest/configuration.html#deploy
7.2、主机到从机的无密互通
https://www.jianshu.com/p/e180371f55a1
https://www.cnblogs.com/webnote/p/5787357.html

7.3、zookeeper 配置集群:
参考:https://www.jianshu.com/p/de90172ea680
官网:http://zookeeper.apache.org/doc/current/zookeeperStarted.html
https://www.cnblogs.com/ysocean/p/9860529.html#_label4
注意:集群过程中注意myid的配置,mid的路径必须放在data的路径下
7.4、 CentOS 7.9安装配置Chrony同步系统时钟
参考:https://blog.51cto.com/qiuyue/2344678

 浙公网安备 33010602011771号
浙公网安备 33010602011771号