

python爬取数据保存到Excel中
1 # -*- conding:utf-8 -*- 2 3 # 1.两页的内容 4 # 2.抓取每页title和URL 5 # 3.根据title创建文件,发送URL请求,提取数据 6 import requests 7 from lxml import etree 8 import time, random, xlwt 9 10 11 # 专家委员会成员的xpath(‘//tbody//tr[@height='29']’) 12 13 class Doc_spider(object): 14 15 def __init__(self): 16 self.base_url = 'http://www.bjmda.com' 17 self.url = 'http://www.bjmda.com/Aboutus/ShowClass.asp?ClassID=12&page={}' 18 self.headers = { 19 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'} 20 21 def get_request(self, url): 22 '''发送请求,返回html''' 23 response = requests.get(url, headers=self.headers).content.decode('gbk') 24 # time.sleep(random.random()) 25 html = etree.HTML(response) 26 return html 27 28 def parse_page_html(self, html, url): 29 '''提取列表页的专家委员会title和URL''' 30 31 url_lists = html.xpath('//tr/td[2]/a[2]/@href')[1:] 32 temp_lists = html.xpath('//tr/td[2]/a[2]/text()')[1:] 33 title_lists = [title.rstrip() for title in temp_lists] 34 35 urls = [] 36 titles = [] 37 38 for i in range(len(title_lists)): 39 url = self.base_url + url_lists[i] 40 title = title_lists[i] 41 urls.append(url) 42 titles.append(title) 43 44 return urls, titles 45 46 def parse_detail(self, html): 47 '''详细页的提取数据,返回每组列表信息''' 48 49 lists = html.xpath("//td[@id='fontzoom']//tr") 50 content_list = [] 51 for list in lists: 52 contents = list.xpath('.//td//text()') 53 new = [] 54 for i in contents: 55 new.append(''.join(i.split())) 56 content_list.append(new) 57 58 return content_list 59 60 def save_excel(self, sheet_name, contents, worksheet, workbook): 61 '''保存数据到Excel''' 62 63 # 创建一个workbook 设置编码 64 #workbook = xlwt.Workbook() 65 # 创建一个worksheet 66 #worksheet = workbook.add_sheet(sheet_name) 67 68 try: 69 70 for i in range(len(contents)): 71 if len(contents[i+1])>1: 72 content_list = contents[i + 1] 73 74 # 写入excel 75 # 参数对应 行, 列, 值 76 worksheet.write(i, 0, label=content_list[0]) 77 worksheet.write(i, 1, label=content_list[1]) 78 worksheet.write(i, 2, label=content_list[2]) 79 if len(contents[i+1])>3: 80 worksheet.write(i, 3, label=content_list[3]) 81 82 # 保存 83 #workbook.save(sheet_name + '.xls') 84 # time.sleep(0.1) 85 except: 86 print(sheet_name,'保存OK') 87 88 pass 89 90 def run(self): 91 # 1.发送专家委员会列表页请求 92 urls = [self.url.format(i + 1) for i in range(2)] 93 94 # 创建一个workbook 设置编码 95 workbook = xlwt.Workbook() 96 97 for url in urls: 98 html = self.get_request(url) 99 # 2.提取委员会的title和URL 100 list_urls, titles = self.parse_page_html(html, url) 101 102 for i in range(len(list_urls)): 103 url_detail = list_urls[i] 104 # 每个委员会的名称 105 title_detail = titles[i] 106 # 3.创建每个委员会文件,发送每个委员会的请求 107 html_detail = self.get_request(url_detail) 108 # 4.提取专家委员会详细页的内容 109 contents = self.parse_detail(html_detail) 110 # 保存每个委员会的所有人 111 112 # 创建一个worksheet 113 worksheet = workbook.add_sheet(title_detail) 114 self.save_excel(title_detail, contents,worksheet,workbook) 115 workbook.save('专家委员会.xls') 116 print('保存结束,请查看') 117 118 119 120 if __name__ == '__main__': 121 doc = Doc_spider() 122 doc.run()
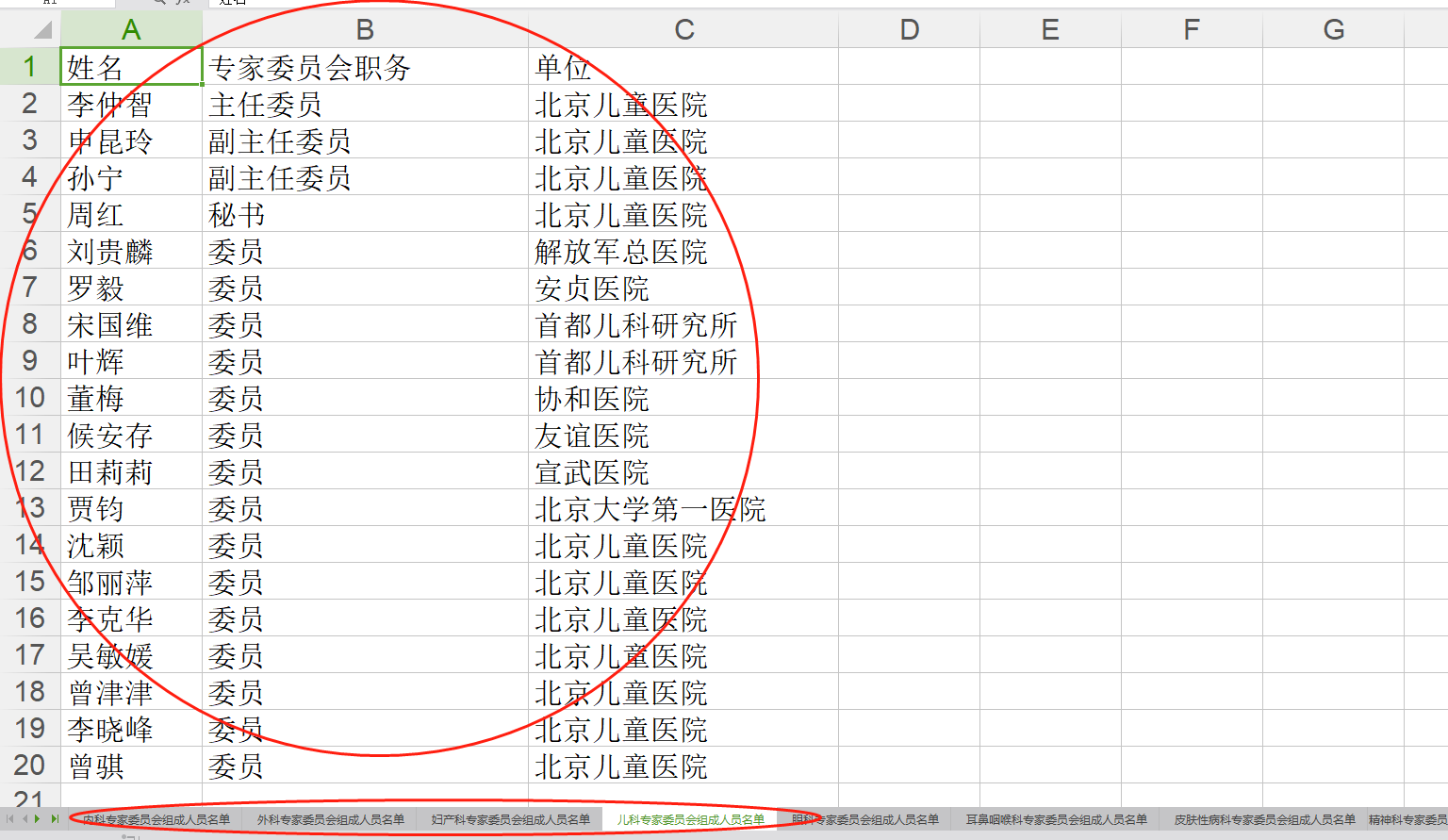
这个小程序可以爬取该网站的医生专家的信息,分不同的专科保存到同一个Excel中。
# -*- conding:utf-8 -*- import xlwt # 创建工作workbook workbook = xlwt.Workbook() # 创建工作表worksheet,填入表名 worksheet = workbook.add_sheet('表名') # 在表中写入相应的数据 worksheet.write(0, 0, 'hello world') worksheet.write(1, 1, '你好') # 保存表 workbook.save('hello.xls')
