
Redis(九)——主从模式
1、概念
主服务器叫master,从服务器叫slave,主人与奴隶。为了使得主从服务器状态一致,需要进行数据复制,数据复制是单向的,主节点->从节点。
5.0之前通过「salveof」命令,后面通过「replicaof」命令建立主从关系。
2、主从复制的好处
- 数据备份:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务,分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
3、全量复制

为什么全量复制使用RDB而不是AOF?
(1)RDB文件内容是经过压缩的二进制数据(不同数据类型数据做了针对性优化),文件很小。而AOF文件记录的是每一次写操作的命令,写操作越多文件会变得很大,其中还包括很多对同一个key的多次冗余操作。在主从全量数据同步时,传输RDB文件可以尽量降低对主库机器网络带宽的消耗,从库在加载RDB文件时,一是文件小,读取整个文件的速度会很快,二是因为RDB文件存储的都是二进制数据,从库直接按照RDB协议解析还原数据即可,速度会非常快,而AOF需要依次重放每个写命令,这个过程会经历冗长的处理逻辑,恢复速度相比RDB会慢得多,所以使用RDB进行主从全量复制的成本最低。
(2)假设要使用AOF做全量复制,意味着必须打开AOF功能,打开AOF就要选择文件刷盘的策略,选择不当会严重影响Redis性能。而RDB只有在需要定时备份和主从全量复制数据时才会触发生成一次快照。而在很多丢失数据不敏感的业务场景,其实是不需要开启AOF的。
4、增量复制

- repl_backlog_buffer:它是为了从库断开之后,如何找到主从差异数据而设计的环形缓冲区,从而避免全量复制带来的性能开销。如果从库断开时间太久,repl_backlog_buffer环形缓冲区被主库的写命令覆盖了,那么从库连上主库后只能乖乖地进行一次全量复制,所以repl_backlog_buffer配置尽量大一些,可以降低主从断开后全量复制的概率。而在repl_backlog_buffer中找主从差异的数据后,如何发给从库呢?这就用到了replication buffer。
- replication buffer:Redis和客户端通信也好,和从库通信也好,Redis都需要给分配一个 内存buffer进行数据交互,客户端是一个client,从库也是一个client,我们每个client连上Redis后,Redis都会分配一个client buffer,所有数据交互都是通过这个buffer进行的:Redis先把数据写到这个buffer中,然后再把buffer中的数据发到client socket中再通过网络发送出去,这样就完成了数据交互。所以主从在增量同步时,从库作为一个client,也会分配一个buffer,只不过这个buffer专门用来传播用户的写命令到从库,保证主从数据一致,我们通常把它叫做replication buffer。
5、不持久化的主服务器重启会发生什么?
假设主服务器是A,从服务器有B和C。如果A突然奔溃并自动重启,由于关闭了持久化,重启后是个空数据库。B、C复制后也变成空数据库。
6、无磁盘复制模式是什么?
Redis 默认是磁盘复制,但是如果使用比较低速的磁盘,这种操作会给主服务器带来较大的压力。Redis从2.8.18版本开始尝试支持无磁盘的复制。使用这种设置时,子进程直接将RDB通过网络发送给从服务器,不使用磁盘作为中间存储。
无磁盘复制模式:master创建一个新进程直接dump RDB到slave的socket,不经过主进程,不经过硬盘。适用于disk较慢,并且网络较快的时候。
7、主-从-从模式
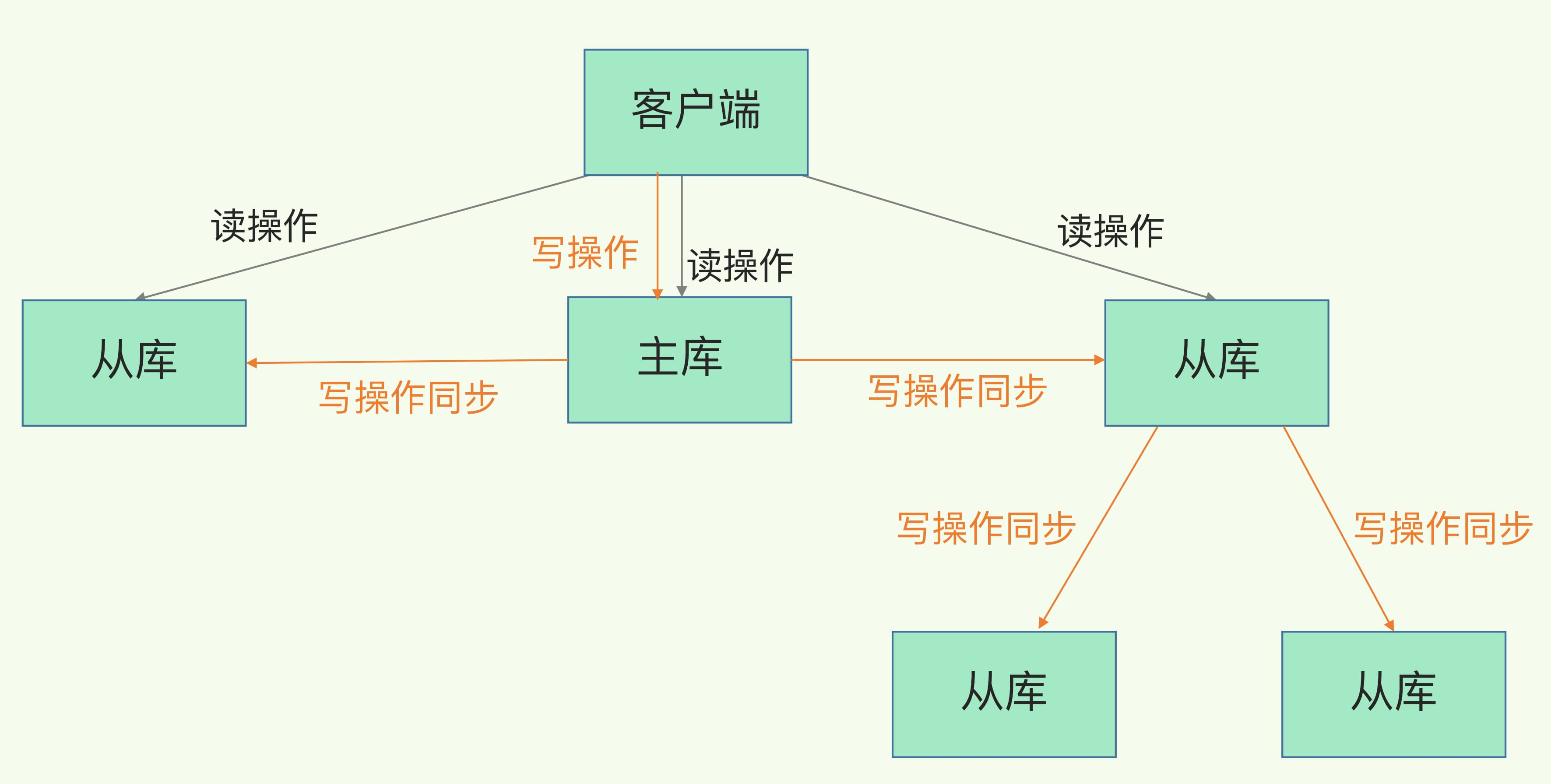
全量复制中,对于主库来说,需要完成两个耗时的操作:生成 RDB 文件和传输 RDB 文件。如果从库数量很多,而且都要和主库进行全量复制的话,就会导致主库忙于 fork 子进程生成 RDB 文件,进行数据全量复制。fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。此外,传输 RDB 文件也会占用主库的网络带宽,同样会给主库的资源使用带来压力。
「主-从-从模式」能将主库生成 RDB 和传输 RDB 的压力,以级联的方式分散到从库上。
8、读写分离中的问题
(1)延迟与不一致
主从复制的命令传播是异步的,所以延迟与数据不一致不可避免。优化手段有:
- 优化主从节点之间的网络环境(如在同机房部署);
- 监控主从节点延迟(通过offset)判断,如果从节点延迟过大,通知应用不再通过该从节点读取数据;
- 使用集群同时扩展写负载和读负载;
如果是连接中断导致的主从库数据不一致,slave-serve-stale-data可以控制从节点是否继续响应请求,yes继续响应,no不再响应。
(2)数据过期
redis3.2开始,从节点读取数据时,增加过期判断,如果过期不返还数据。

