
Redis(五)——持久化机制
Redis是内存数据库,需要将存储在内存中的数据库状态保存到磁盘里,避免数据丢失。持久化即把数据保存到可永久存储的设备中。
一、RDB持久化机制
RDB全称是redis database。
RDB文件是数据库 某个状态经过压缩后的二进制文件,通过该文件还原到数据库当初的状态。默认情况下,Redis的RDB文件名为dump.rdb。

1、RDB文件的创建和载入
(1)通过save和bgsave命令创建RDB文件
- save命令会阻塞Redis服务器进程,直到RDB文件创建完毕,阻塞期间不可以处理任何请求指令。(不消耗内存但阻塞)
- bgsave命令会派生出一个子进程fork,让子进程去创建RDB文件,相当于子进程执行save命令,自己(父进程)继续执行请求指令。在bgsave期间,父进程会拒绝save和bgsave指令,防止产生竞争条件;对于BGREWRITEAOF(AOF重写)指令也会延迟到bgsave后执行,该指令虽然是由子进程执行,没有冲突,但从性能方面考虑,不能同时执行。(消耗内存但不阻塞)
为什么bgsave不阻塞主线程?
写时复制。执行快照时的数据内存归主线程和子线程共有。 如果主线程需要执行写命令,对于这块数据,会复制出一块供主线程使用,与子线程无关。
(2)服务器启动时自动载入RDB文件
2、自动间隔性保存
在redis.window.conf配置文件中,有这么三行代码
save 900 1 save 300 10 save 60 10000
服务器在900s内,对数据库进行了至少1次修改
服务器在300s内,对数据库进行了至少10次修改
服务器在60s内,对数据库进行了至少10000次修改
只要满足任意一个条件,bgsave命令就会自动执行.
服务器状态的结构体 包含了 保存条件结构体,可以自行设置保存条件
//服务状态
struct redisServer{ //.. struct saveparam* saveparam;//记录保存条件的数组 //.. };
//保存条件 struct saveparam{ time_t seconds;//秒数 int changes;//修改数 };
服务器状态还有2个属性来判断是否执行保存
//服务器状态 struct redisServer{ //.. struct saveparam* saveparam;//记录保存条件的数组 long long dirty;//修改计数器,记录上一次修改后,数据库改了多少次 time_t lastsave;//上一次执行保存的时间戳 //.. };
3、RDB文件结构

- REDIS部分的长度为5字节,保存"REDIS"五个字符,通过这五个字符快速检查所载入的文件是不是RDB文件,这里不是C字符串"REDIS\0"。
- db_version长度为4字节,它的值是一个字符串表示的整数,例如"0006"就代表RDB文件的版本为第六版。
- databases部分包含零个或任意多个数据库,以及各个数据库中的键值对数据。如果服务器的数据库状态为空,则database为空;状态不为空也根据数据库所保存的键值对信息而长度不同。
- EOF(End of File)表示读入程序读到文件尾,占1字节。
- check_sum是一个8字节长的无符号整数,保存一个校验和,这个校验和是程序通过前四个部分计算得出的。载入文件时会将载入数据所计算出的结果和原本记录的check_sum进行对比,以此来检查RDB文件是否有误。
databases部分可以保存任意多个非空数据库

- SELECTDB常量的长度为1字节,当读入时就知道下一个是数据库号码。
- db_number保存着一个数据库号码,长度可以是1、2、5字节。读到这个东西会调用select命令,根据读入的号码切换。
- key_value_pairs部分保存了数据库中所有键值对信息,过期的键没删除的话也在里面,每个键值对信息如下,如果不带过期时间则没有前面两个信息。根据TYPE类型来选择保存的value对象类型。

4、RDB的优缺点
(1)优点
- RDB文件是某个时间节点的快照,默认使用LZF算法进行压缩,压缩后的文件体积远远小于内存大小,适用于备份、全量复制等场景;
- Redis加载RDB文件恢复数据要远远快于AOF方式;
(2)缺点
- RDB方式实时性不够,无法做到秒级的持久化;(秒级同步快照则太过频繁)
- 每次调用bgsave都需要fork子进程,fork子进程属于重量级操作,频繁执行成本较高;
- RDB文件是二进制的,没有可读性,AOF文件在了解其结构的情况下可以手动修改或者补全;
二、AOF持久化机制
AOF全称是Append Only File,通过保存Redis服务器所执行的写命令来记录数据库状态。是日志文件,通过执行命令还原数据库状态。被写入AOF文件的所有命令都是以Redis命令请求协议格式(纯文本)保存的,
1、AOF持久化的实现
- 命令追加:服务器执行完一个写命令之后会把该命令追加到aof_buf缓冲区的末尾
- 写入与同步:redis服务器进程是一个事件循环,负责接收客户端的命令请求并回复。时间事件负责执行像serverCron函数这样需要定时运行的函数。服务器每次结束一个事件循环之前,都会调用flushAppendOnlyFile函数,考虑是否需要将aof_buf缓冲区中的内容写入和保存到AOF文件里。不同的appendfsync值产生不同的持久化行为:
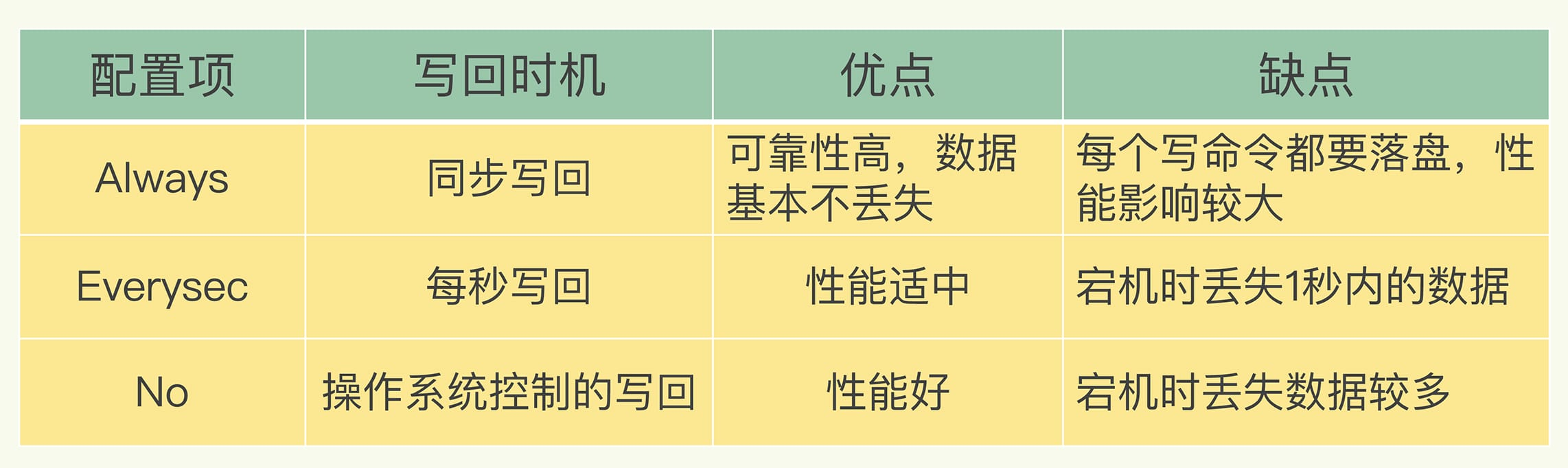
很显然,always效率最慢,安全性最高,即使出现故障最多也只是丢失一个事件循环中的命令数据;第二个折中;第三个写入AOF文件很快,不同步会导致数据累积,下一次同步时耗时最长。
2、AOF文件的载入和数据还原
服务器只要读入并重新执行一遍AOF文件里的命令就可以还原数据库状态
3、AOF重写
(1)定义
如果堆积很多命令造成文件庞大,不如保留键最后的值,将若干条命令替换成一条(设置键值)。
(2)执行
为了防止阻塞主线程,服务器将AOF重写交给子进程进行,主进程继续执行客户端请求的命令。子进程会copy出一份主进程的内存去重写,这个动作会阻塞主进程,copy这个动作会阻塞,后续重写期间不阻塞。 最后替换重写后的日志文件。
4、AOF重写时主进程执行写命令怎么办?
在AOF重写期间,主进程将此期间执行的写命令,追加两份AOF缓冲区:AOF缓冲区和AOF重写缓冲区。待重写完成,主进程把AOF重写缓冲区的内容追加到新的AOF文件,这就保证了状态一致。
5、AOF重写时主进程执行写命令过多怎么办?
高并发的情况下,AOF重写缓冲区积累可能会很大,这样就会造成阻塞,Redis后来通过Linux管道技术让AOF重写期间就能同时进行回放,这样aof重写结束后只需回放少量剩余的数据即可。
6、AOF重写时发生宕机怎么办?
还没有切换日志文件,所以恢复数据时,用的还是旧的日志文件。
7、写后日志(先写内存,后写日志)的好处与风险
(1)好处
- 无需检查,往AOF写日志不需要检查命令正确性。若先写日志再执行命令,使用日志恢复时可能报错;
- 不阻塞当前写操作;
(2)风险
- 命令执行完成,写日志前宕机,则会丢数据;
- 主进程写磁盘压力大,导致写盘慢,阻塞后续操作;
8、总结成三步
- 主进程fork出子进程重写aof日志
- 子进程重写日志完成后,主进程追加aof日志缓冲
- 替换日志文件

