
Java XML文档
概念
XML(EXtensible Markup Language),可扩展标记语言。可扩展就是<>内的东西可以自己定义,可以随便写。标记语言就是加了<>符号的 。HTML是超文本标记语言,不可以拓展,因为你写个<p> 浏览器知道这个是段落,你写个<shuyunquan>浏览器就不认识了,所以不可拓展。
XML书写格式
- 第一行是固定的:<?xml version="1.0" encoding="UTF-8"?>,告诉别人,我是xml文件。
- 只能有一个根元素
- 没了
其他语法和注意点
- <!--这是注释 -->
- <元素名 属性名="属性值">元素内容</元素名>,元素也称标签,XML文件是由一系列标签构成的。属性值不要使用乱七八糟的符号,如>\/<等
- 所有XML元素都必须有结束标签(</……>)
- XML标签对大小写敏感
- XML必须正确的嵌套
- 同级标签以缩进对齐
- 元素名称可以包含字母、数字或其他的字符
- 元素名称不能以数字或者标点符号开始(<5name>是错误的;<name5>是正确的)
- 元素名称中不能含空格(<student name>是错误的;<studentname>是正确的的)
DOM解析XML
- 文档对象模型(Document Object Model)
- DOM把XML文档映射成一个倒挂的树
<book id=”1234”> <title>三国演义</title> <author>罗贯中</author> <price>30元</price> </book>
所有带尖括号的叫元素节点,只有文本文字的叫属性节点,id=”1234”叫做属性节点
树形结构:易于增删改查

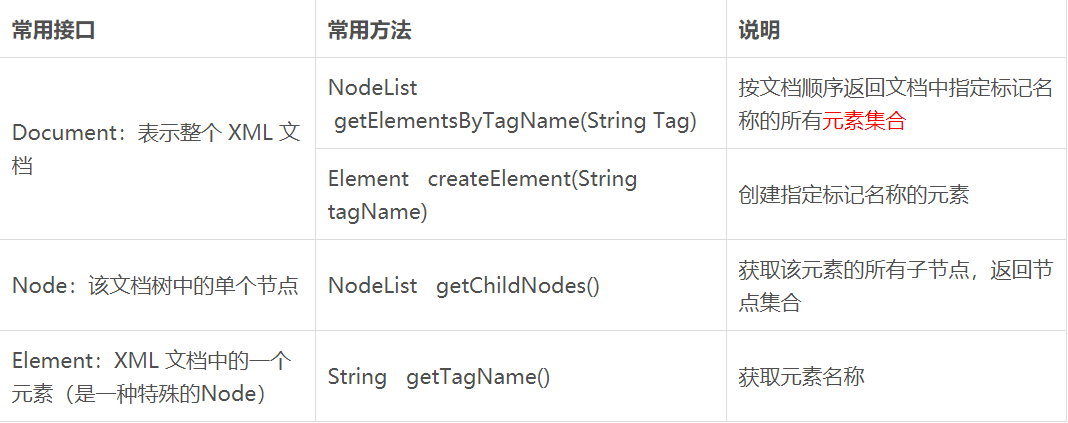
DOM解析XML文件步骤:
- 创建解析器工厂对象
- 解析器工厂对象创建解析器对象
- 解析器对象指定XML文件创建Document对象
- 以Document对象为起点操作DOM树
类似这种套路:


1 import javax.xml.parsers.*; 2 import org.w3c.dom.*; 3 import java.io.*; 4 import java.net.URL; 5 6 public class XMLUtil { 7 8 public static Object getBean() { 9 try { 10 //创建DOM文档对象 11 DocumentBuilderFactory dFactory=DocumentBuilderFactory.newInstance();//文档制造者工厂创建了一个 文档制造者工厂对象 12 DocumentBuilder builder=dFactory.newDocumentBuilder();//文档制造者类 通过 文档制造者工厂 创造一个 文档制造者对象 13 Document doc;//文档制造者 创建 文档 14 doc=builder.parse(new File("src/homework/config.xml"));//解析xml文件 15 16 //获取包含类名的文本节点 17 NodeList nl=doc.getElementsByTagName("className");//文本节点列表里有很多被className标签夹着的内容 18 Node classNode=nl.item(0).getFirstChild(); 19 //item(0)表示引用列表里第一个节点,这里只有一个。getFirstChild表示获取该节点的第一个孩子。 20 String cName=classNode.getNodeValue(); 21 22 //通过类名生成实例对象并返回 23 Class c=Class.forName(cName); 24 Object obj=c.newInstance(); 25 return obj; 26 }catch(Exception e) { 27 e.printStackTrace(); 28 return null; 29 } 30 } 31 }
参考:https://blog.csdn.net/baidu_29343517/article/details/81609732

