

Crowdsourcing[智能辅助标注]
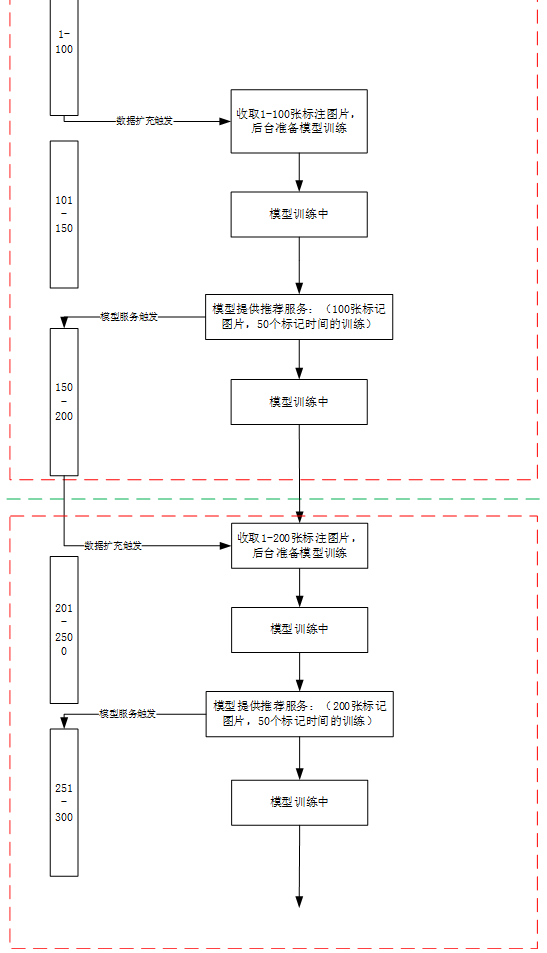
为了实现标注平台智能辅助标注的能力,即上传一个标注任务,开始不提供辅助任务,随着用户标注的进行,后台可以收集一部分的标记数据,然后开启模型训练,并接着提供模型服务功能。然后再收集数据,再不断的训练,然后更新服务端的模型。随着标记的进行,模型的准确度也会越来越高。从而达到随着时间的进行,人工标注会从最开始的从0标注转换成只是对模型预先标注的结果进行校对的目的。
即实现下述目的
其中对应的时序图如下
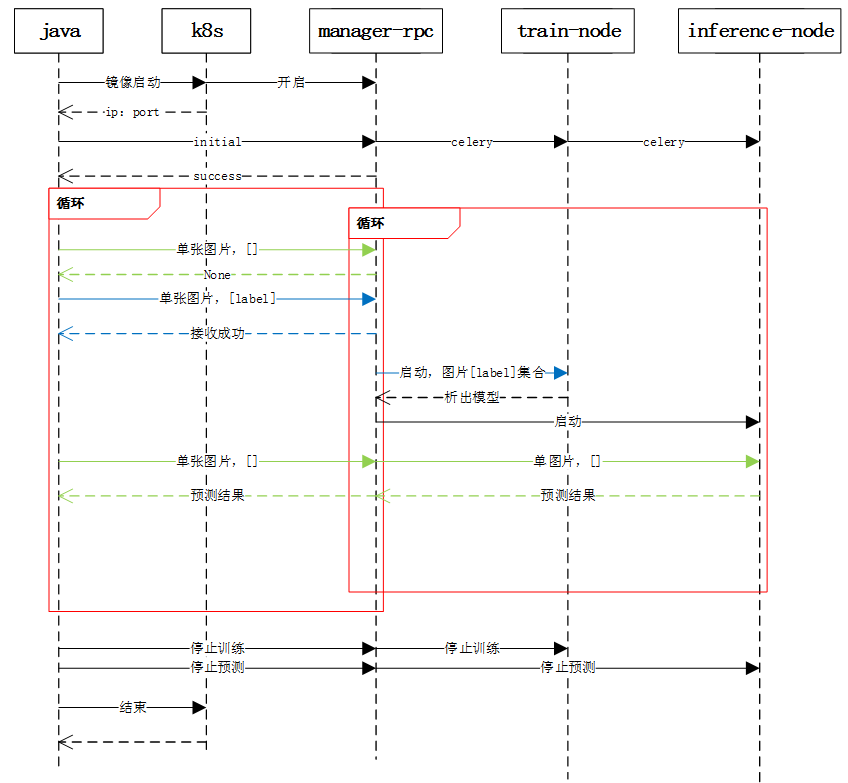
智能辅助标注时序图
这里要考虑的问题是任务之间独立性,即任务之间的模型不能干扰。
0 申请3(train)+4(inference)个docker(每个docker关联一块gpu),一个分布式存储,并fuse挂载

1 - 运行start.sh,其中开启manager_rpc.py
1.1– 内置运行init函数:
- i)收集本机ip,可用端口(用于manager_rpc的开启)
- ii)hostname (后续用于rabbitmq)
- iii)开启本机rabbitmq-server
- iv) erlang.cookie(用于后续rabbitmq集群构建)
1.2 基于注册地址,提交本机上述信息,并开启本机manager_rpc
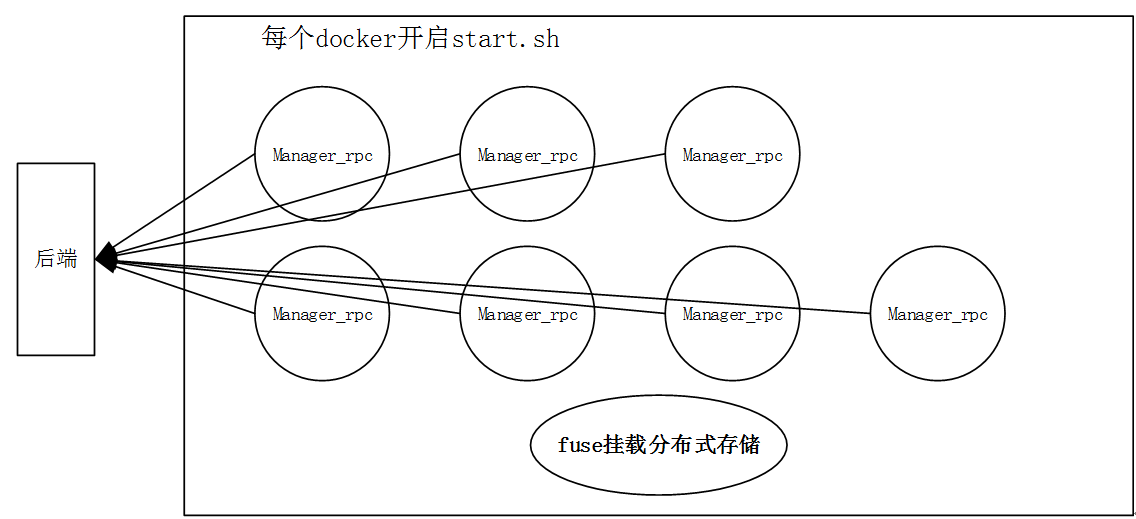
2 基于1.1收集的信息,需要指定哪几台用于train,哪几台用于inference
'''
machines_info:[{'hostname':'...', 'ip':'...', 'port':'...', 'erlang_hash':'...' ,'type':'train'},
{'hostname':'...', 'ip':'...', 'port':'...', 'erlang_hash':'...' ,'type':'train'}
...
{'hostname':'...', 'ip':'...', 'port':'...', 'erlang_hash':'...' ,'type':'inference'}
]
task_category: # 当前任务类别如 “图像分类”
task_extra_info: #当前任务的额外信息如: "多分类”
task_datastore_path当前任务所需要在共享存储上的位置:
映射到每个docker内部位置为:
/home/datastore: (生成下述三个子文件夹,分别为存储服务模型;数据预处理;训练节点恢复模型)
Inference/model-time0
model-time1
Proprecess/
Snapshot/***.ckpt
'''
将上述信息分别发送给这7个manager_rpc的initial

2.1 每个initial接口执行以下行为:
- i)通过接收的参数检测且ping是否能够ping通,划分好机器和坏机器;将好机器列表的[ip,hostname]写入到各自的/etc/hosts
- ii)基于好机器,选取当前对应的train_master,inference_master。选取规则为ip最小的那台
- iii)基于本机检测是否是inference,且非inference_master,则构建rabbitmq集群
- 停止rabbitmq-server;
- 修改erlang.cookie
- 开启rabbitmq-server
- 向inference_master注册构建集群
- iv)开启celery,其中celery按照本机的角色,开启对应的脚本,如果是train,则多开一个数据处理celery
if type == 'train':
sp.run(f'( {binpath}/start_data & )', shell=True)
sp.run(f'( {binpath}/start_{type} & )', shell=True)
- v)返回好机器和坏机器列表,自己节点当前的erlang.cookies,从而保证后台的全局同步,有利于新增节点的erlang.cookies
initial的返回数据
ans = {'rpc':rpc,
'bad_machines_info':badMachinesInfo,
'good_machines_info':goodMachinesInfo,
'master_train':master_train.get('ip',''),
'master_inference':master_inference.get('ip',''),
'erlang_hash':open('/var/lib/rabbitmq/.erlang.cookie').read(),
}
其中每个celery的配置broker和backend为
BROKER_URL = 'amqp://guest:guest@127.0.0.1:5672'
CELERY_RESULT_BACKEND = 'amqp:// '
Vi)开启对应角色rpc
- i)传递共享存储路径
- ii)返回服务角色的rpc

如果是inference_rpc,则自动按照好机器个数,开启fork形式的服务模式,此时集群由rabbitmq-server负责建立
如果是train,则只开启processes=1的主进程服务模式,此时train集群由train_node自己建立,如tensorflow的分布式版本。
master_train节点的Train_rpc接收有标签图片的数据链接,将其通过celery传递给后台worker的train_node,train_node负责下载,预处理等
master_inference节点的Inference_rpc接收无标签图片的数据连接,将其通过celery传递给后台worker的inference_node,inference_node负责下载,预处理,然后将结果通过celery返回,此时每个节点都可以作为master通过整个rabbitmq-server集群将任务分散给其他inference角色的docker.这里的master_inference仅仅是为了rabbitmq的erlang.cookies的同步。

