

SVM-笔记(1)
1 目的
SVM推导是从讨论最优超平面开始的,即为了得到一个能够划分不同超平面的面,即公式1:
\begin{equation}w^Tx+b=0 \tag{1} \end{equation}
这个公式怎么来的,其实就是基于2维推导过来的,当二维图像时,也就是熟悉的x,y坐标系。我们将一条线的函数公式定义为\(Ax+By+C=0\),其法向量为(A,B),而平面上任意一点(x0,y0)到该线的距离为[参考]:式子2$$d = \frac{|Ax_0+By_0+C|}{\sqrt{A2+B2}} \tag{2}$$
类比得到,多维平面上的某个“线”,其公式为\(Ax+By+Cz+D=0\),可以看出就是一个向量\(w = [A,B,C]\)与另一个向量\(X = [x,y,z]\)之间的内积加上一个常量D。也就是上述式子1。所以,SVM中某点到该“线”的距离公式从式子2类比得到为,式子3:$$r = \frac{|w^Tx+b|}{||w||} \tag{3}$$
其法向量为\(w\)。
ps:下面参考自周志华老师的《机器学习》,支持向量机部分。
2 最优超平面
为了方便,则将此超平面记为\((w,b)\)。我们取二分类样本,即样本标签为\(\{+1,-1\}\)。我们希望超平面能够正确分类,也就是对于\(y_i = +1\)的样本,\(w^Tx_i+b>0\);而对于\(y_i = -1\)的样本,\(w^Tx_i+b<0\)。
ps:这里需要接着解释下为什么间隔取1,此部分资料在Andrew Ng的网易公开课讲义部分有说道,后续有空我过来补齐。
而为了获得最优的超平面,我们假设离该平面最近的点到该平面距离至少为1.则满足下面式子4:
所以两个不同类别之间最小的距离为,式子5:
所以式子5,也被称为"间隔"(margin)。
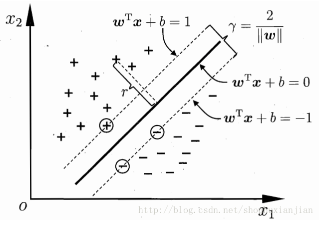
如果将该间隔最大化,那么也就是找到了最优超平面,因为该超平面就是中间那条线,而图上虚线上的正负点,就是所谓的支持向量。即只有这些点才对最优超平面的选取有关。
所以,问题就转换成了求取下面方程式的问题,式子6:
可以看到所谓最大化一个分数,其分子不变,也就是最小化一个分母即可,即式子6等同于式子7:
3 拉格朗日浅析
式子7,是一个凸二次规划问题,也就是其一定会有最值存在,为了更快的进行求解,需要用到拉格朗日乘子方法。其实拉格朗日乘子法,在《同济版高数书 第9章多元函数微分法及其应用 第8节多元函数的极值及其求法》上有简单介绍,不过其并没说到KKT等情况,这里还是以网上别人博客作为参考[2,3]:
- 拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush-Kuhn-Tucker)条件是求解约束优化问题的重要方法,在有等式约束时使用拉格朗日乘子法,在有不等约束时使用KKT条件。前提是:只有当目标函数为凸函数时,使用这两种方法才保证求得的是最优解[2]
如博文[3]所说,一般最优化问题,通常为3种,:
(1)无约束优化问题,:
(2) 等式约束优化问题,假设有n个等式约束:
(3)不等式约束优化问题,假设有n个等式约束,m个不等式约束:
- 对于第(1)类的优化问题,常常使用的方法就是Fermat定理,即使用求取\(f(x)\)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解[3] 。
即直接求其导数,然后求得导数为0的解即可。
- 对于第(2)类的优化问题,常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值 [3]。
即先将函数\(f(x)\)与其约束函数\(h_i(x)\)变换成一个单一函数,即:
然后针对每个变量参数求导,通过联合所有的求导式子,将其等于0,求得极值点,再将极值点带入,求得最值点即可。而KKT中有个要求即\(b_ig_i(x)=0\),但因为\(g_i(x) \leq 0\),所以要么\(b_i = 0\),要么\(g_i(x)=0\)。而这也和SVM中的支持向量有很密切的关系。
4 对偶问题
可以看出式子7可以通过KKT求解,添加拉格朗日乘子\(\alpha_i \geq 0\)写成拉格朗日函数为,式子12:
其中\(\alpha_i \geq 0\),这样就保证了后面一项一定小于0。其中$$\alpha = (\alpha_1;\alpha_2;...;\alpha_m) \tag{13}$$将\(L(w,b,\alpha)\)对\(w\),\(b\)进行求偏导得,式子14,式子15:
将上述式子14带入\(L(w,b,\alpha)\),将\(w\),\(b\)消去,再考虑式子15,得如下对偶问题, 式16:
在求得\(\alpha\)向量时,则通过式子14,即可得到\(w\),从而带入原式子,得到,式17:
这里的拉格朗日乘子就是$\alpha$,其中每一个变量$\alpha_i$都对应着一个样本$(x_i,y_i)$,且式子7中还有不等式存在,按照之前KKT部分说的,要求$(L(x,a,b))$不等式部分等于0,即$\alpha_i(y_if(x_i) - 1) = 0$,则要求联合一起,得到如下约束:
$$\begin{cases}
\alpha_i \geq 0; \\
y_if(x_i) -1 \geq 0;\\
\alpha_i(y_if(x_i) - 1) = 0
\end{cases} \tag{18}$$
所以对于任意训练样本\((x_i,y_i)\)总有\(\alpha_i = 0\)或者\(y_if(x_i)=1\).如果当前\(a_i=0\),那么该式在式17中则会不存在,而如果有\(\alpha_i \geq 0\)那么一定会有\(y_if(x_i)=1\),即对应的这个样本刚好位于最大间隔边界上,是一个支持向量。即SVM的一个性质:当训练完成后,大部分训练样本无需保留,只要保留支持向量即可,而且模型也只与支持向量有关。
因为这是一个二次规划问题,而且模型的训练速度正比于训练样本数,所以不适合超大数据集,而且中间会有一堆的开销,为了解决这种问题,通过问题本身的特性,有如SMO等高效方法来进行求解。(待更新)
5 - 核函数
对于线性不可分的样本集合来说,在低维空间中,是无法将其区分的。而且如果原始样本的特征维度是有限维,那么一定存在某个高维,能够将其线性区分,所以,升维,升到线性可分的维度,就能解决这个问题。
假设\(\phi(x)\)是\(x\)升维后的特征向量,则在能够划分超平面的特征空间中模型表示为:
表示成式子7如:
其对偶问题:
这样就将问题转换到了求高维特征的内积问题,可是如果这时候的特征空间维度太高,那么内积的计算都是很困难的。所以如果能够有这样一类函数:
即希望找到一个函数,使得\(x_i\)与\(x_j\)在特征空间的内积就等于他们在原始样本空间通过升维得到的内积。这样就免去了计算高维甚至无穷维度的问题,式子5.3重写成:
求解后:
(待续)
6 - 软间隔,惩罚系数
如前面说的,一直假定训练样本在样本空间或者特征空间中能够达到线性可分,可是现实问题总是更复杂的,也很难说找到合适的核函数来让训练样本在特征空间中线性可分,即使找到了,也难保这个线性可分的结果不是过拟合造成的。所以,由此那么就放宽条件,允许一部分样本是分类错误的,比如:
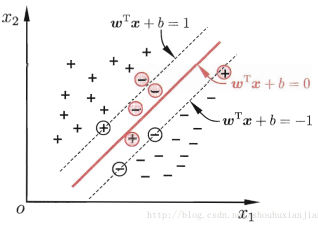
,所谓的"硬间隔",就是每个样本都完全满足SVM的目标函数定义,而“软间隔”,就是允许及个别的样本不满足:
为了尽可能的减少这种情况存在,所以需要惩罚这种样本,从而目标函数改成了:
其中\(C>0\) 是一个常量,即惩罚系数,\(l_{0/1}\)是"0/1损失函数":
可以发现当\(C\)无穷大时,满足最严格要求,即所有样本都必须分类正确,而当\(C\)有确定值时,就是一定程度的让步。
可是因为损失函数通常是非凸,非连续,数学性质不够完美,所以式子6.2很难求。所以通常是采用一些凸的连续的,且是损失函数上界的一些函数来代替。
2017/03/08 第一次修改!
- [1] 周志华 《机器学习》
- [2] 拉格朗日乘子法和KKT条件
- [3] 深入理解拉格朗日乘子法和KKT条件
- [4] 再生核希尔伯特空间

