

Feature Extractor[ResNet]
0. 背景
众所周知,深度学习,要的就是深度,VGG主要的工作贡献就是基于小卷积核的基础上,去探寻网络深度对结果的影响。而何恺明大神等人发现,不是随着网络深度增加,效果就好的,他们发现了一个违背直觉的现象。
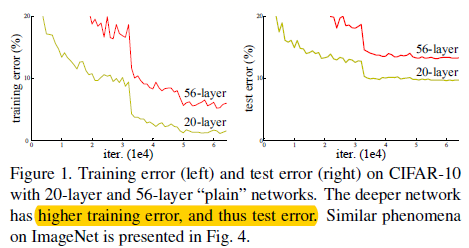
图0.1 不同层数的传统网络下的结果表现
最开始,我们认为随着深度的增加,网络效果不好,那是因为存在着梯度消失和梯度爆炸的原因。不过随着大家的努力,这些问题可以通过归一化初始化(即用特定的初始化算法)和归一化层(Batch Normailzation)来极大的缓解。
可是,我们仍然能够发现随着网络深度的增加,网络反而在某些时刻结果变差了,如图0.1所示。这并不是过拟合造成的,而且随着网络层数再增加,错误反而变得更高了。作者将这一现象称之为“退化”现象。从这个现象中,我们得知,不是所有系统的优化方式都是一样的。
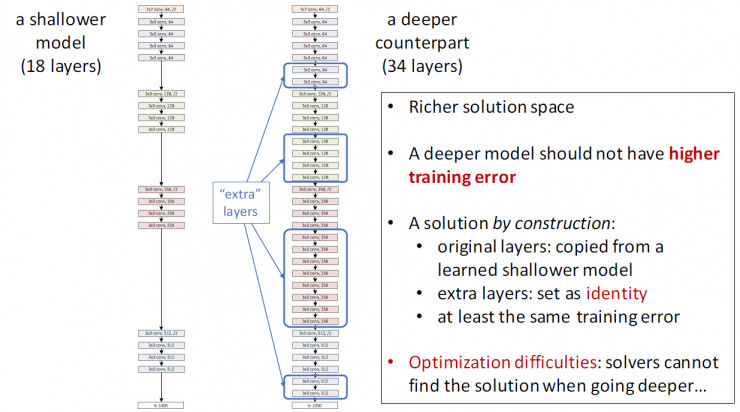
图0.1 "退化"现象
如图0.1所示。我们假设这么一个场景:先训练一个浅层的网络A,然后构建一个深层的网络B,其中网络B比网络A多出的那些层是为了学到恒等映射(identity mapping)(即y=x),然后与A相同的部分就直接用A代替。那么我们可以很自然的认为网络B的错误率应该不会超过网络A。可是我们现在能用到的方法都显示达不到这样的效果。
何恺明大神等人从恒等映射出发,并通过前人的工作中发现,如果将一个问题进行形式转换,那么可能可以得到更容易的解决方法(如SVM中的对偶),也就是对问题进行重新定义或者预先条件约束,那么就能更容易解决这个优化问题。他们发明的残差网络,直接将之前的googlenet和vgg等不到40层的网络直接提升到1000层(虽然大神实验发现101的挺不错),不过后续大家大多还是用着ResNet-101和ResNet-152这两个。
1. ResNet
1.1 残差学习
假设想要拟合的函数为\(H(x)\),我们用堆叠的非线性层网络去拟合另一个函数\(F(x)=H(x)-x\),从而想要学习的函数可以表示成\(H(x)=F(x)+x\)。假如在极端情况下,恒等映射是最优的(即我们学习的函数就是一个恒等函数),那么,将残差逼近到0(\(F(x)=0\))相比于只用堆叠非线性层的网络去拟合恒等映射(\(H(x)=x\))要更容易。这是因为如果直接学习该函数,并不是那么容易(前人的大量实验也证明了这点),可是如果学习的是残差,那么网络可以变得敏感起来,微小的扰动都能让网络产生较大的反映,即优化算法让网络中的权重都趋近于0从而达到恒等映射的目的。
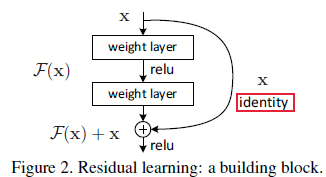
图1.1.1 残差学习:一个构建块
然而现实生活中,恒等映射并不是最优的。如果希望拟合的最优函数更像恒等函数(\(H(x)=x\))而不是0映射(\(F(x)=0\)),那么对于优化算法来说,找到扰动总比学习一个新函数要简单。后续实验也证实了ResNet通常有较小的响应,这表明恒等映射提供了对函数合理的预定义条件。
1.2 快捷连接
1 - feature map和通道维度相同时:
\begin{align}
y=F(x,{W_i})+x \
\end{align}
这里\(x\)和\(y\)分别对应输入和输出,函数\(F(x,{W_i})\)就是需要学的残差映射,如果拿图1.1.1举例,那么\(F=W_2\sigma(W_1x)\),其中\(\sigma\)就是ReLU了。\(F+x\)就是一个快捷连接,并且是逐像素的,所以他们能够计算的前提就是维度相同。而且该方法不需要引入新的参数
2 - 维度不同时:
- 1 - 采用维度相同时候的公式,只不过将不能匹配的部分用0填充;
- 2 - 如下面式子:
\begin{align}
y=F(x,{W_i})+W_sx \
\end{align}
其中\(W_s\)可以看成是\(1*1\)的卷积形式(如64通道需要输出x,连接到128通道上去)。
对于这2种方法,如果上下的feature map维度不同,那么采用stride的方式,如图1.3.1,虚线的部分就是stride=2进行跳跃的
因为恒等映射已经足够处理"退化"问题了,所以这里的\(W_s\)只是为了处理维度不匹配的问题而已(相对维度相同基础上,这里引入的额外参数就是\(W_s\))。
作者并比较了3种不同的升维方式,如图

图1.2.1 不同的模型结果对比
图1.2.1中,其中(A)表示用0扩展的方式来升维,此方法不增加额外的参数; (B) 在需要升维的部分使用\(W_s\)的方式,其他部分直连;(C) 都使用\(W_s\)的方式,且可以看出ABC都比没有快捷连接的效果好,而C比B只好一点点,所以通过\(W_s\)的方式升维的并不是处理"退化"问题的最优选择,所以为了时间复杂度和模型参数量(即尺度),后续都不再用C方法,从而在1.3部分,作者又设计出了瓶颈式构建块。
1.3 网络结构
如图1.1.1所示,ResNet相比传统的网络的区别就是将某一层的输出接着连接到后面的几层,这其中可以跳2层,3层(1层的话就是个线性层,一点效果都没了)。具体的网络结构对比如下。

图1.3.1 3种网络结构:VGG;没有残差快捷连接的网络;34层的ResNet网络
如图1.3.1所示,作者基于第二种模型基础上,增加了残差的快捷连接(ResNet网络中黑色实线表示直接连接,虚线表示需要处理升维的问题),且在每个卷积层中卷积后,激活函数前放置BN层。
为了对模型训练进行加速,作者对图1.1.1的构建块进行了重新设计,如图1.3.2。
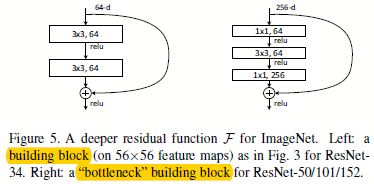
图1.3.2,正常构建块和瓶颈式构建块
其中\(1*1\)的卷积就是负责先降维,然后升维的。可以看出这种方式特别适合使用1.2中,维度相同时候的快捷连接方案。如果将瓶颈式构建块用1.2中维度不同时候的快捷连接方案,那么模型的复杂度和尺度都会翻倍。所以这种设计的构建块更能加速网络训练和减少网络尺度。
通过使用图1.3.2的瓶颈式构建块,作者设计出了不同层下的ResNet网络结构,如图1.3.3所示。
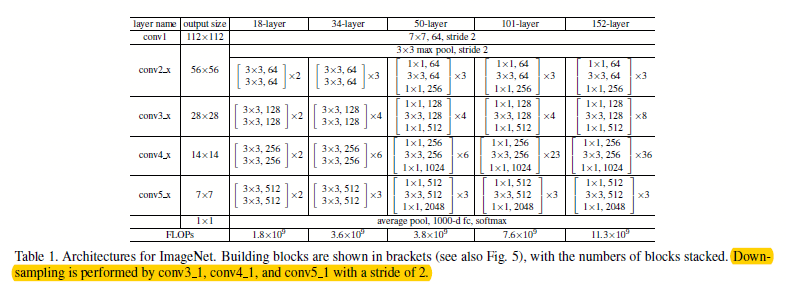
图1.3.3 不同层下的ResNet网络结构
ps:在不同数据集上,训练也略微有点不同,如在cifar-10上训练的时候,0.1开始的学习率太大了,模型不收敛,所以先设成0.01,然后在训练了大约400次迭代的时候,再将学习率设成0.1
ps:顺带贴上不同层下的ResNet的神经元响应
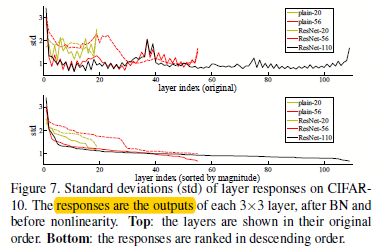
图1.3.4不同层下网络的响应
从图1.3.4中可以看出,越是深的ResNet就有越小的响应,而且越是深的Resnet,单层越是少的去修改信号。
参考文献:
- [本文] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
- [初始化] Y. LeCun, L. Bottou, G. B. Orr, and K.-R.M¨uller. Efficient backprop.In Neural Networks: Tricks of the Trade, pages 9–50. Springer, 1998.
- [初始化] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
- [初始化] A. M. Saxe, J. L. McClelland, and S. Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv:1312.6120, 2013.
- [初始化] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In ICCV, 2015
