

nvidia[单卡内部的调度原理]
本人虽然研二开始接触cuda,但是终究未从事cuda开发,故而皆为零零散散的知识,虽然看了好几本cuda编程的书籍以及官网的文档(肯定没看全啊,我也不是专门从事cuda开发),市面上几乎都是关于如何cuda编程的书籍,而这些书籍中也看过不少《CUDA C编程权威指南》,《CUDA专家手册》,《CUDA并行程序设计 GPU编程指南》,《高性能CUDA应用设计与开发 方法与最佳实践 》等等,以及官网《CUDA_C_Programming_Guide》此类文档,还有论文《GPU Scheduling on the NVIDIA TX2: Hidden Details Revealed》,但是都没有完全的系统的去介绍底层的调度原理(当然本博文也没法做到完全系统的挖掘)。
1 引言
先介绍几个概念:
上下文(context):gpu也学着cpu的设计模式,创建了所谓上下文的概念,在cpu中:
CPU寄存器,是CPU内置的容量小、但速度极快的内存。程序计数器,则是用来存储CPU正在执行的指令的位置,或者即将执行的下一条指令的位置。他们都是CPU在运行任何任务前,必须依赖的环境,因此也被叫做CPU上下文。
那么(猜测,待验证)gpu的上下文也差不多就是内置的寄存器状态,L1缓存,以及指令计数器啥的。
进程:这里指host侧的进程
线程:这里指device侧的线程
任务:这里指linux系统下的线程
2 nvidia的gpu的三种模式
首先《CUDA_C_Programming_Guide》的3.5章节,介绍了gpu的三种模式:

如上图:
默认计算模式:多个进程在启动时,驱动可以开启多个上下文对象(context)分别绑定,比如一个进程绑定一个上下文对象,那么这时候就涉及到单卡多进程内部是如何调度的,
独占进程计算模式:即驱动只开启一个上下文对象,但是通常cpu测 进程之间是完全资源隔离的,那么所谓开启一个上下文,也估计只能对应一个进程(MPS除外,MPS就是工作在此模式下);
禁止计算模式:即在设备上不创建上下文(不明白这个模式的使用场景);
那么如上面介绍的三种模式,最常接触的就是默认模式,这时候不论是用户开启一个tensorflow-gpu程序,还是看nvidia-smi显示比较空闲去开启多个gpu的程序都会有个疑问:
1:我开多进程能更好的利用单卡么?
2:以及为什么nvidia又有个东西叫MPS?
3 上下文切换的时间粒度
接着看3.2.5.2章节下面截图的最后一句

官方也说了来自不同的上下文的kernel是不能同时执行的。那么针对这个问题就有疑问了,是整块卡不能同时执行,还是针对一个SM不能同时执行,还是针对SM中一个core不能同时执行。因为有传统操作系统知识的同学就知道了,cpu支持多进程(多任务)是通过时间片轮询的方式去抢占正在运行的任务的。但是cpu一个core我们理解就是一个单元啊,默认不可拆了啊,但是cuda可不是啊,一块卡内部一堆SM,然后每个SM内部一堆core,我们编写cuda代码时候是可以在一个线程里面操作的,然后外部写个<<<grid,block>>>去申请资源的,那假设我写2个进程,内部分别只申请不到50%的资源,那到底一块卡能不能同一时刻同时执行2个进程呢?带着这个问题又找到了另一个地方

我们看到3.6章节紧邻的最上部分,说在之前开普勒和麦克斯韦等架构上,抢占是线程块级别的,在后续帕斯卡等架构上,是能指令级别的。开始想那不就是指令级别可以互相抢占么,可是转念一想,这说的是时间上的抢占粒度,和空间上是卡级别?还是SM级别?还是core级别(当然这个粒度是不可能的,毕竟那么多书籍文档都说明是按照warp去调度的,最小粒度也就是一半warp)?没关系啊?
4 上下文切换的空间粒度
这里随便写个代码:
// nvcc test.cu -std=c++11 -o test
#include<iostream>
#include<chrono>
#include<stdio.h>
using namespace std;
using namespace chrono;
__global__ void kernel(int *a){
printf("grid:%d,block:%d,thread:%d\n",gridDim.x,blockIdx.x,threadIdx.x);
for(int i0=0;i0<1000;i0++)
for(int i=0;i<200000;i++){
for(int i=0;i<100;i++)
//a[i]=a[i]%3;
int b=i%3;
}
}
int main(){
auto st = high_resolution_clock::now();
int *a;
cudaMalloc((void**)&a,sizeof(int)*100000000);
kernel<<<1,1>>>(a);
cudaDeviceSynchronize();
auto ed = high_resolution_clock::now();
cout<<"take time: "<<duration_cast<milliseconds>(ed-st).count()<<" ms"<<endl;
return 0;
}
所以想法就是,创建一个1块1线程的程序,用它去跑(比如耗时100ms),然后同时运行好几个(比如10个),如果是卡级别的,那么几乎是大于10*100ms的时间(上下文切换的开销),而如果是sm级别的,那总的时间差不多稍大于等于100ms。
所以分别执行如下2个shell命令:
执行10次 test这个程序
for i in `seq 1 10`; do echo $i; done|xargs -n1 ./test
grid:1,block:0,thread:0
take time: 132 ms
grid:1,block:0,thread:0
take time: 116 ms
grid:1,block:0,thread:0
take time: 115 ms
grid:1,block:0,thread:0
take time: 114 ms
grid:1,block:0,thread:0
take time: 118 ms
grid:1,block:0,thread:0
take time: 117 ms
grid:1,block:0,thread:0
take time: 115 ms
grid:1,block:0,thread:0
take time: 115 ms
grid:1,block:0,thread:0
take time: 115 ms
grid:1,block:0,thread:0
take time: 115 ms
同时开启10个进程去执行test
for i in `seq 1 10`; do echo $i; done|xargs -n1 -P10 ./test
grid:1,block:0,thread:0
take time: 782 ms
grid:1,block:0,thread:0
take time: 790 ms
grid:1,block:0,thread:0
take time: 796 ms
grid:1,block:0,thread:0
take time: 802 ms
grid:1,block:0,thread:0
take time: 801 ms
grid:1,block:0,thread:0
grid:1,block:0,thread:0
take time: 811 ms
take time: 812 ms
grid:1,block:0,thread:0
take time: 968 ms
grid:1,block:0,thread:0
take time: 983 ms
grid:1,block:0,thread:0
take time: 983 ms
可以看出,几乎是10倍的时间,那为什么不是完全的大于等于10*100ms,就是因为nvcc和内部gcc自带一堆优化(真实原理只是猜测),
即使for循环改成:
for(int i1=0;i1<10000;i1++)
for(int i0=0;i0<10000;i0++)
for(int i=0;i<10000;i++){
for(int i=0;i<100;i++)
//a[i]=a[i]%3;
int b=i%3;
}
grid:1,block:0,thread:0
take time: 129 ms
也和没加一样,着实佩服。
从这里可以得出结论,所谓上下文切换,是基于整个卡而言的,即一块卡同一时刻只能运行一个上下文的指令。
5 nvidia-smi的gpu利用率解读
当然上述代码并未涉及到IO传输,一切都是在寄存器,SM内部就执行完了。所以耗时很短,从nvidia-smi可以看出,都不到100%,就一下子结束了,为了让nvidia-smi抓取到,直接让他运行100次。

如果将上面注释去掉,让他有访问全局显存的操作,这时候可以通过nvidia-smi发现一个有趣的现象
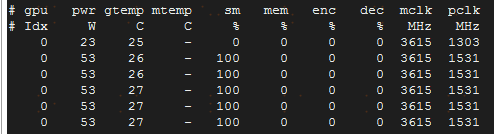

就是都是显示利用率为100%(而且跑了好久好久都没停,等了一分多钟还没结束,手动停止了).一切都在stackoverflow上找到了原因
nvidia-smi-volatile-gpu-utilization-explanation

即因为nvidia-smi是通过采样,然后所谓gpu的使用率是从时间线角度,当前程序SM是否在使用,那mem为什么为0?估计是获取数据太小,采样时刻没法监测到。但是这里的确说明一个问题,看nvidia-smi来衡量你的GPU当前是否繁忙,SM是否全都用上了,内部全局显存和L2到L1以及寄存器的IO传输使用率啥的一概不准。而再加上是基于整卡进行上下文切换,那更隐藏了很多资源使用率的有效信息。

