

Automl基于超大数据下的数据分发方案探讨
先定义几个关键字:
任务:用户一次上传的数据集并发起的automl任务,比如一次ocr任务,一次图像分类任务。
模型:一次任务中,需要运行的多个模型,比如ocr任务,需要ctpn模型,需要crnn模型。
单模型:一个模型只需要单个节点即可(只适合小数据集);
分布式模型:一个模型需要多个节点才能运行(适合大数据集)。
目前有2个角度的考虑,从而造成问题探讨方向的不同,这里主要有数据集角度和任务角度。
基于数据集角度
基于数据集角度考虑,希望数据集被所有的任务复用。任务之间,只要使用到同一个数据集,则不需要重复拉取。
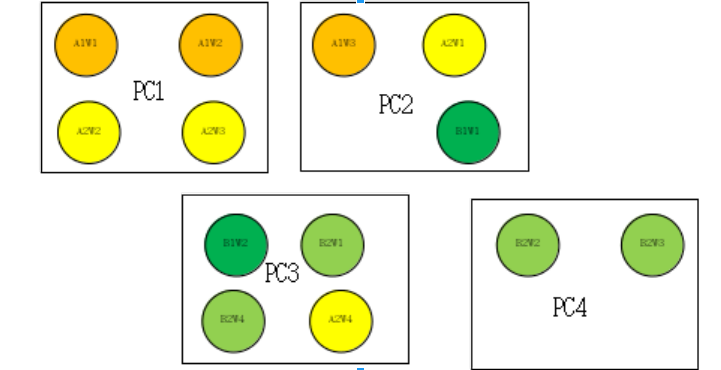
举例:目前现在有任务A,任务B,且共用一份数据集,数据集D。
其中:
- 任务A:有模型A1,模型A2;模型A1有三个worker,分别是A1W1,A1W2,A1W3;同理A2W1,A2W2,A2W3,A2W4;
- 任务B:有模型B1,模型B2;同上,有B1W1,B1W2,B2W1,B2W2,B2W3,B2W4
总结:基于数据集角度,进行任务之间共享,减少了不同任务之间需要拉取数据的需求,
缺点:
- 1 - 需要单台物理机能够存储一个完整的数据集;
- 2 – 如果单台物理机能够存储整个数据集,那为什么还需要每个worker去读取自己的对应部分,直接可以基于整个数据集进行训练即可。
改进1-整个数据集放不下单个物理机
基于单个分布式模型进行划分,各自去读取各自的那部分,以workerID拉取数据集对应部分:
比如对于模型A1,因其有三个节点,故而数据集需要划分成三份,
A1W1读取数据集D的前1/3; A1W2读取数据集D的中间1/3;A1W3读取数据集D的最后1/3.
缺点:
- 1 - 那么对于上述PC2中,A2W1和B1W1,因其A2和B2都刚好是数据集D的前面部分,可是A2有4个节点,B2有2个节点,会导致数据集划分冲突。
- 2 - 如果只基于worker的id去拉取,在当docker宕机,并且当前节点进行漂移,比如PC2上面的A2W2漂移到PC3上:就缺失了对当前数据的访问,需要重新拉取,如果PC2经历了多次宕机和启动,那么有可能其需要整个数据集都遍历一遍。
基于任务的角度
任务之间数据不共享,则
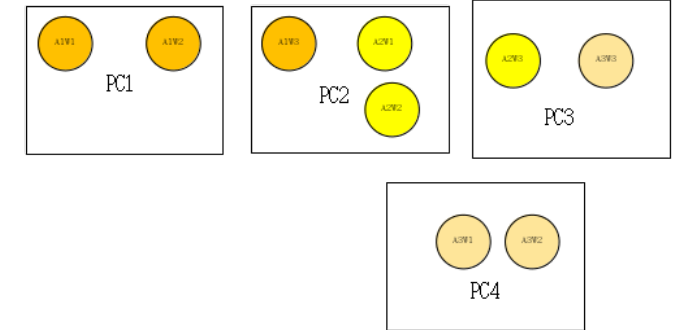
假设有如上机器配置,只有任务A存在,且有三个模型,其中A1有3个worker;A2有3个worker,A3有3个worker。
每个PC机器都去拉取各自共用的数据集。并且每个物理机上只有一个主worker负责拉取当前的数据集,其他worker等待
- 1- PC1的A1W1拉取数据集D的前2/3,
- 2- 可是当考虑到PC2的时候,假设当前主worker是A1W3拉取剩下1/3,可是A2的有2个节点,故而考虑拉取剩下的2/3,即数据集D划分三份的中间一份和最后一份,保证A1W3能够读取到,
- 3- 可是在PC3上假设当前主worker是A3W3,因需要单个模型能访问整个数据集,那么会造成读取数据集D的最后1/3.
缺点:
- 1 - 基于任务角度考虑数据集共享,增加了任务之间的数据拉取,
- 2 – 每个模型的worker中一个主worker去拉取,会导致数据集划分困难,最开始无法进行对应。且主worker拉取失败,则需要监控并重新交付任务,监控较为繁琐。
总结:可以看出,基于任务角度拉取,不考虑任务之间的数据共享,增加了一定的磁盘使用量,不过逻辑清晰,基于worker的ID去拉取各自的,保证了各自处理各自的数据,不需要做主worker的监控,防止监控繁琐。
结合方法
- 1 - 每个worker都有拉取的能力(非主次worker),保证了不需要维护主Worker的死亡。并且每个worker按照ID去拉取各自的数据。
- 2 – 因为worker id的id是人为定义的,对数据角度来看无异议,不过为了更好的进行数据划分,需要建立一个拓扑图,并进行对应的映射。
- 3 – 数据集按照公倍数粒度划分,并进行数据集到worker的映射,保证数据集的单一性,并进行拉取数据的任务分发。此时只需要监控worker的id和当前机器上已经存在数据集的对应关系,从而简单的进行任务分发即可,不需要特殊的监控。
如
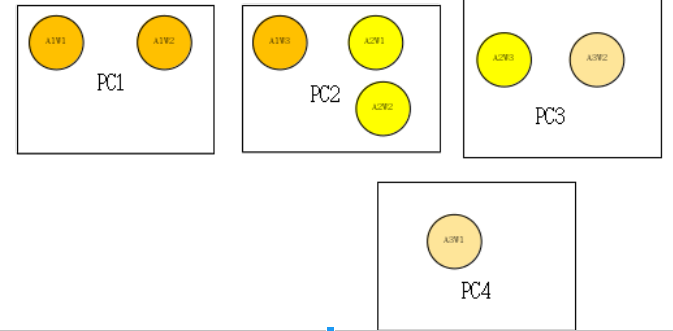
并通过拓扑映射的方式(进行节点的交换),将其对应成
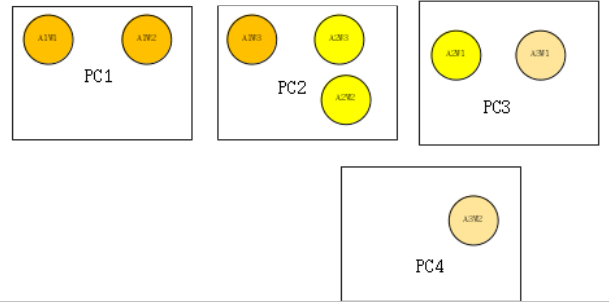
然后
1 - 基于最小粒度进行划分,即使其中存在两个worker和三个worker的情况,保证数据集的划分是公倍数可分的,如数据集D划分成6份【1,2,3,4,5,6】。
2 - 并且每个最小单元进行计数和映射
则PC1上A1W1 拉取【1,2】,A1W2拉取【3,4】;且【1】-> A1w1,【2】->A1W1,以此类推
此时PC1数据集有【1,2】【3,4】
PC2上A1W3应该拉取【5,6】,A2W3与其竞争,谁拉取了对应的最小单元,则谁胜利;A2W2拉取【3,4】
此时PC2数据集有【5,6】【3,4】
PC3上A2W1应该拉取【1,2】,A3W1应该拉取【1,2,3】,则对于数据集【1,2】,两个worker竞争,对于【3】则A3W1拉取
此时PC3上数据集有【1,2,3】
PC4上A3W2拉取【4,5,6】
此时PC4上数据集有【4,5,6】
情况1-刚好漂移到数据集可重用的PC上
如果此时PC2上A2W3宕机,并在PC4上复活

PC2上本有数据集【5,6】和【3,4】,因每个数据集都有映射
【5】->A1W3
【6】->A1W3
【3】->A2W2
【4】->A2W2
都有docker使用,故而不删除,假如出现某个数据单元已经无法进行映射,则表明当前数据集无主,可以删除。
PC4上,A2W3映射为【5,6】,此时机器上有【4,5,6】,满足需求,建立映射,无需下载。
总结:通过将数据集进行最细粒度的划分,并进行worker节点的映射,保证数据集的下载是单次的,且是可重复利用的。
情况2-漂移到数据集节点上不可重用
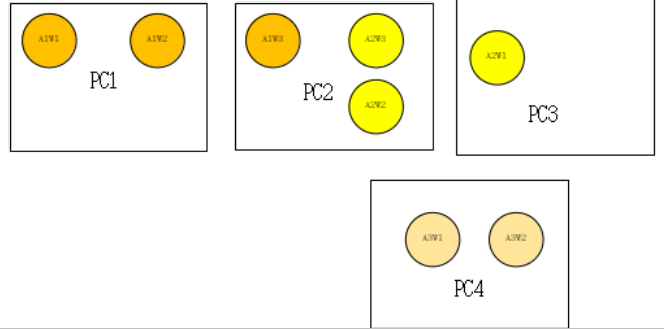
A3W1漂移到PC4上,此时PC3上的数据集【3】无法映射,进行删除
PC4上,因A3W1对应数据集【1,2,3】,如果当前机器支持当前【1,2,3,4,5,6】数据存储,则正常拉取,如果超出,则将A3W1杀死,重新进行路由,保证数据可以存放。

