

Generative Adversarial Nets[CycleGAN]
本文来自《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,时间线为2017年3月。本文算是GAN的一个很大的应用里程点,其可以用在风格迁移,目标形变,季节变换,相片增强等等。
1 引言

如图1所示,本文提出的方法可以进行图像风格的变化,色调的变化等等。该问题可以看成是image-to-image变换,将给定场景下的一张图片表示\(x\)变换到另一个图片\(y\),例如:灰度图片到颜色,图像到语义标签,edge-map到photograph。然而现有的图像风格迁移的工作都需要样本图像对\(\{x_i,y_i\}_{i=1}^N\)(如图2左边)
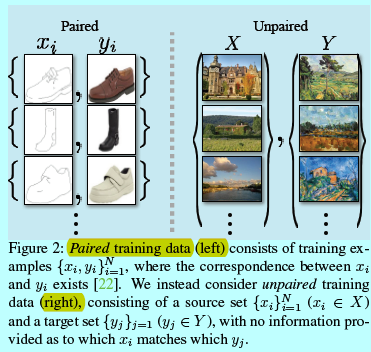
然而,获得成对的训练数据是很困难而且代价很大。只有一些任务如语义分割等才有这种数据集,而且他们的量还很小。而相对本文的任务,即图像风格迁移,还需要画家本人提供图像对,这就更不可能了。
所以本文提出一种算法用于学习没有成对输入输出样本的域之间的变换(图2 右)。首先假设存在某些潜在的基于这些域的关联,如他们是同一个场景下的不同渲染。虽然缺少有监督成对样本,还是可以在集合层面使用监督信号:基于域\(X\)的图片集合和域\(Y\)的图片集合。学习一个映射\(G:X\rightarrow Y\),使得输出\(\hat y=G(x),x\in X\)与\(y\in Y\)无法区分。理论上该目标可以产生一个基于\(\hat y\)的输出分布并匹配经验性分布\(p_{data}(y)\)(通常,这需要\(G\)是随机的)。因此,最优G可以变换域\(X\)到与\(Y\)相同域分布的域\(\hat Y\)。然而,这样的变换却不能保证独立输入\(x\)和输出\(y\)是基于有意义的成对形式,因为存在无穷个映射\(G\),可以生成基于\(\hat y\)同样的分布。实际上,作者发现很困难孤立的优化对抗目标:标准的过程会导致mode collapse,即所有输入图片会生成相同的输出图片。
这些问题需要在目标上增加更多的结构,因此,作者利用的变换应该是“循环一致”属性,从某种意义上说,如果变换,例如,从英语翻译成法语,然后将其从法语翻译成英语,应该回到原始句子。数学上,如果有个变换器\(G:X\rightarrow Y\)和另一个变换器\(F:Y\rightarrow X\),那么\(G,F\)应该为互逆状态,而且两个映射是双射(bijections)。作者通过同时训练映射G和F来完成这个结构性假设,并增加一个循环一致loss来鼓励\(F(G(x))\approx x\)和\(G(F(y))\approx y\)。在域X和域Y上,将这个loss与对抗loss相结合,可以得到无成对的image-to-image转换的最终目标。
2 公式
作者的目标是基于给定训练样本\(\{x_i\}_{i=1}^N\)其\(x_i\in X\)和标签\(\{y_j\}_{j=1}^M\)其\(y_j\in Y\)(下文会忽略下标),学习介于域\(X\)和域\(Y\)之间的映射函数。这里令数据分布为\(x\sim p_{data}(x)\)和\(y\sim p_{data}(y)\)。

如图3,本文模型生成2个映射\(G:X\rightarrow Y\)和\(F:Y\rightarrow X\)。另外,还有2个对抗判别器\(D_X\)和\(D_Y\)。这里\(D_X\)意在区分图像\(\{x\}\)和变换后的图像\(\{F(y)\}\);同样的,\(D_Y\)意在区分\(\{y\}\)和\(\{G(x)\}\)。本文目标包括两个:
- 对抗loss用于匹配生成的图片的分布到目标域中的数据分布;
- 循环一致loss,阻止学到的映射\(G\)和\(F\)之间互相矛盾。
2.1 对抗loss
作者这里在两个映射函数上采用对抗loss[16]。对于映射函数\(G:X\rightarrow Y\)和他的判别器\(D_Y\),这里的目标为:
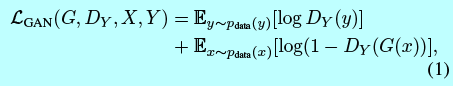
这里\(G\)试图生成的图像\(G(x)\)看上去很像来自域\(Y\)的,同时\(D_Y\)意在区分变换的图像\(G(x)\)和真实样本\(y\)。G意在最小化该目标,而D为了最大化该目标,即\(\min_G\max_{D_Y}\mathcal{L}_{GAN}(G,D_Y,X,Y)\)。这里为映射函数\(F:Y\rightarrow X\)引入一个相似的对抗loss和对应的判别器\(D_X\),即\(\min_F\max_{D_X}\mathcal{L}_{GAN}(G,D_X,X,Y)\)。
2.2 循环一致loss
理论上,对抗训练可以学习映射G和F,从而生成的输出与目标域Y和X具有一致性分布(严格的说,这需要G和F是随机函数)。然而,一个复杂的网络可以映射同样的输入图片集合到目标域中任意随机排列的图片,其中任意学好的映射生成的输出分布可以匹配目标分布。因此,单单对抗loss而言,不能保证学到的函数可以映射一个独立输入\(x_i\)到期望的输出\(y_i\)。为了减少映射函数空间的可能性,作者认为,学到的函数应该还是循环一致的:如图3(b),对于每个来自域\(X\)的图像\(x\),图像变换训练应该可以将\(x\)带回到原始图像上,即\(x\rightarrow G(x)\rightarrow F(G(x))\approx x\)。称这个为前向训练一致;类似的,如图3(c),每张来自域\(Y\)的图像\(y\),G和F可以满足后向循环一致:\(y\rightarrow F(y)\rightarrow G(F(y))\approx y\)。循环一致loss为:

在初步实验中,同时将该loss中的L1范数替换成介于\(F(G(x))\)和\(x\)之间的对抗loss,和介于\(G(F(y))\)与\(y\)之间的对抗loss,不过并没看到有效果提升。

通过循环一致oss生成的行为可以看图4,重构图像\(F(G(x))\)就是尽可能靠近输入图像\(x\)。
2.3 完整的目标函数
完整的最终目标是:
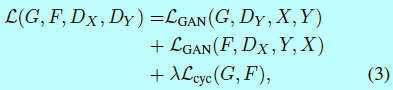
这里\(\lambda\)控制这两个目标的相关重要性。我们意在解决:

注意到这里的模型可以被视为训练两个“自动编码器”:即训练自动编码器\(F\circ G:X\rightarrow X\)的同时一起训练另一个自动编码器\(G\circ F:Y\rightarrow Y\)。然而,这些自动编码器每个都有特定的内在结构:他们通过一个中间表征来将图像映射回自身,该中间表征就是将一个图像映射到另一个域。这一步可以被视为“对抗自动编码器”[34]的特殊情况,其使用一个对抗loss来训练自动编码器的bottleneck 层,以匹配任意的目标分布。在本文中,\(X\rightarrow X\)的目标分布就是域\(Y\)。
3 实现
网络结构
本文的生成网络结构借鉴自[23],其结构在神经类型迁移和超分辨任务中有很好的应用。该网络结构包含两个stride=2的卷积,几个残差块,两个fractionallystrided的卷积,其stride=\(\frac{1}{2}\)。当图像输入为128x128时,作者采用6个块,当输入图像为256x256甚至更高时,采样9个块。相似于[23],作者使用实例归一化(instance normalization)[53]。对于判别器,使用70x70的PatchGAN[22,29,30],其意在区分是否70x70的窗口覆盖的图像块部分是真的还是假的。这样一个patch-level判别器结构拥有着比一个全图像判别器更少的参数,而且可以以全卷积方式[22]去做用在任意尺度的图像上。
训练细节
这里用两个方法去稳定模型训练过程:
- 对于\(\mathcal{L}_{GAN}\)(式子1),将负log似然目标替换成最小平方loss[35].该loss在训练过程中更稳定,并且可以生成更高质量的结果,特别对于一个GAN loss\(\mathcal{L}_{GAN}(G,D,X,Y)\),训练\(G\)来最小化\(\mathbb{E}_{x\sim p_{data}(x)}[D(G(x))-1]^2\),训练\(D\)来最小化\(\mathbb{E}_{x\sim p_{data}(y)}[D(y)-1]^2+\mathbb{E}_{x\sim p_{data}(x)}[D(G(x))^2]\)。
- 为了减少模型振荡[15],作者遵循Shrivastava等人的策略[46],更新判别器是使用之前生成的图像序列,而不是最新生成器生成的图像。并且保持该buffer大小为50。
对于所有的实验,设定式子3中\(\lambda=10\),使用Adam优化器,其batchsize=1.所有的网络都是以学习率为0.0002开始从头训练的。在前100 epochs时保持学习率不变,然后在接下来的100epochs中线性衰减学习率直到0。
3.1 附录的训练细节
3.2 附录的网络结构
生成器结构
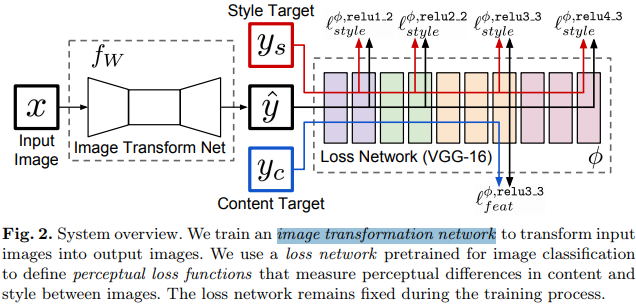
如上图,该图来自[23]。作者借鉴自[23]中该网络结构构件生成器部分。
判别器结构
4 结果
4.1 评估
4.1.1 评估指标
4.1.2 baselines
4.1.3 与baselines进行对比



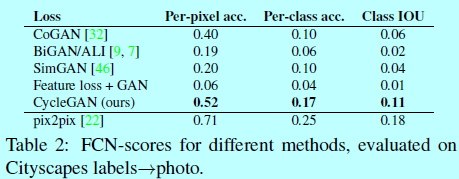
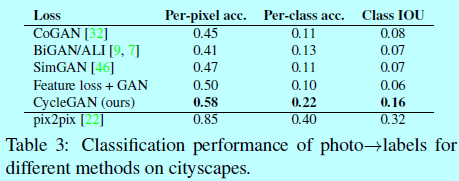
4.1.4 loss函数的分析
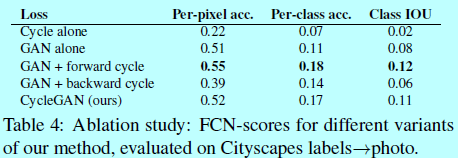
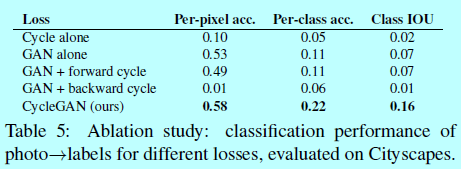

4.1.5 图像重构的质量
4.1.6 在有成对数据集上的额外结果

4.2 应用
5 限制和讨论

reference:
[1] Y. Aytar, L. Castrejon, C. Vondrick, H. Pirsiavash, and A. Torralba. Cross-modal scene networks. PAMI, 2016. 3
[2] K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Krishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. In CVPR, 2017. 3
[3] R. W. Brislin. Back-translation for cross-cultural research. Journal of cross-cultural psychology, 1(3):185–216, 1970. 2, 3
[4] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 2, 5, 6, 18
[5] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009. 8, 13, 18
[6] E. L. Denton, S. Chintala, R. Fergus, et al. Deep generative image models using a laplacian pyramid of adversarial networks. In NIPS, 2015. 2
[7] J. Donahue, P. Kr¨ahenb¨uhl, and T. Darrell. Adversarial feature learning. In ICLR, 2017. 6, 7
[8] A. Dosovitskiy and T. Brox. Generating images with perceptual similarity metrics based on deep networks. In NIPS, 2016. 7
[9] V. Dumoulin, I. Belghazi, B. Poole, A. Lamb, M. Arjovsky, O. Mastropietro, and A. Courville. Adversarially learned inference. In ICLR, 2017. 6, 7
[10] A. A. Efros and T. K. Leung. Texture synthesis by non-parametric sampling. In ICCV, 1999. 3
[11] D. Eigen and R. Fergus. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In ICCV, 2015. 2
[12] L. A. Gatys, M. Bethge, A. Hertzmann, and E. Shechtman. Preserving color in neural artistic style transfer. arXiv preprint arXiv:1606.05897, 2016. 3
[13] L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. CVPR, 2016. 3, 8, 9, 14, 15
[14] C. Godard, O. Mac Aodha, and G. J. Brostow. Unsupervised monocular depth estimation with left-right consistency. In CVPR, 2017. 3
[15] I. Goodfellow. NIPS 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160, 2016. 2, 4, 5
[16] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014. 2, 3, 4, 7
[17] D. He, Y. Xia, T. Qin, L. Wang, N. Yu, T. Liu, and W.-Y. Ma. Dual learning for machine translation. In NIPS, 2016. 3
[18] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 5
[19] A. Hertzmann, C. E. Jacobs, N. Oliver, B. Curless, and D. H. Salesin. Image analogies. In SIGGRAPH, 2001. 2, 3
[20] G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, 2006. 5
[21] Q.-X. Huang and L. Guibas. Consistent shape maps via semidefinite programming. In Symposium on Geometry Processing, 2013. 3
[22] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Imageto- image translation with conditional adversarial networks. In CVPR, 2017. 2, 3, 5, 6, 7, 8, 18
[23] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016. 2, 3, 5, 7, 18
[24] Z. Kalal, K. Mikolajczyk, and J. Matas. Forwardbackward error: Automatic detection of tracking failures. In ICPR, 2010. 3
[25] L. Karacan, Z. Akata, A. Erdem, and E. Erdem. Learning to generate images of outdoor scenes from attributes and semantic layouts. arXiv preprint arXiv:1612.00215, 2016. 3
[26] D. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, 2015. 5
[27] D. P. Kingma and M. Welling. Auto-encoding variational bayes. ICLR, 2014. 3
[28] P.-Y. Laffont, Z. Ren, X. Tao, C. Qian, and J. Hays. Transient attributes for high-level understanding and editing of outdoor scenes. ACM TOG, 33(4):149, 2014. 2
[29] C. Ledig, L. Theis, F. Husz´ar, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image superresolution using a generative adversarial network. In CVPR, 2017. 5
[30] C. Li and M. Wand. Precomputed real-time texture synthesis with markovian generative adversarial networks. ECCV, 2016. 5
[31] M.-Y. Liu, T. Breuel, and J. Kautz. Unsupervised image-to-image translation networks. In NIPS, 2017. 3
[32] M.-Y. Liu and O. Tuzel. Coupled generative adversarial networks. In NIPS, 2016. 3, 6, 7
[33] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. 2, 3, 6
[34] A. Makhzani, J. Shlens, N. Jaitly, I. Goodfellow, and B. Frey. Adversarial autoencoders. In ICLR, 2016. 5
[35] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. P. Smolley. Least squares generative adversarial networks. In CVPR. IEEE, 2017. 5
[36] M. Mathieu, C. Couprie, and Y. LeCun. Deep multiscale video prediction beyond mean square error. In ICLR, 2016. 2
[37] M. F. Mathieu, J. Zhao, A. Ramesh, P. Sprechmann, and Y. LeCun. Disentangling factors of variation in deep representation using adversarial training. In NIPS, 2016. 2
[38] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros. Context encoders: Feature learning by inpainting. CVPR, 2016. 2
[39] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016. 2
[40] R. ˇ S. Radim Tyleˇcek. Spatial pattern templates for recognition of objects with regular structure. In Proc. GCPR, Saarbrucken, Germany, 2013. 8, 18
[41] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image synthesis. In ICML, 2016. 2
[42] R. Rosales, K. Achan, and B. J. Frey. Unsupervised image translation. In ICCV, 2003. 3
[43] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, and X. Chen. Improved techniques for training GANs. In NIPS, 2016. 2
[44] P. Sangkloy, J. Lu, C. Fang, F. Yu, and J. Hays. Scribbler: Controlling deep image synthesis with sketch and color. In CVPR, 2017. 3
[45] Y. Shih, S. Paris, F. Durand, andW. T. Freeman. Datadriven hallucination of different times of day from a single outdoor photo. ACM TOG, 32(6):200, 2013. 2
[46] A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb. Learning from simulated and unsupervised images through adversarial training. In CVPR, 2017. 3, 5, 6, 7
[47] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. 7
[48] N. Sundaram, T. Brox, and K. Keutzer. Dense point trajectories by gpu-accelerated large displacement optical flow. In ECCV, 2010. 3
[49] Y. Taigman, A. Polyak, and L. Wolf. Unsupervised cross-domain image generation. In ICLR, 2017. 3, 8
[50] D. Turmukhambetov, N. D. Campbell, S. J. Prince, and J. Kautz. Modeling object appearance using context-conditioned component analysis. In CVPR, 2015. 8
[51] M. Twain. The Jumping Frog: in English, then in French, and then Clawed Back into a Civilized Language Once More by Patient, Unremunerated Toil. 1903. 3
[52] D. Ulyanov, V. Lebedev, A. Vedaldi, and V. Lempitsky. Texture networks: Feed-forward synthesis of textures and stylized images. In ICML, 2016. 3
[53] D. Ulyanov, A. Vedaldi, and V. Lempitsky. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022, 2016. 5
[54] C. Vondrick, H. Pirsiavash, and A. Torralba. Generating videos with scene dynamics. In NIPS, 2016. 2
[55] F. Wang, Q. Huang, and L. J. Guibas. Image cosegmentation via consistent functional maps. In ICCV, 2013. 3
[56] X. Wang and A. Gupta. Generative image modeling using style and structure adversarial networks. In ECCV, 2016. 2
[57] J. Wu, C. Zhang, T. Xue, B. Freeman, and J. Tenenbaum. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In NIPS, 2016. 2
[58] S. Xie and Z. Tu. Holistically-nested edge detection. In ICCV, 2015. 2
[59] Z. Yi, H. Zhang, T. Gong, Tan, and M. Gong. Dualgan: Unsupervised dual learning for image-to-image translation. In ICCV, 2017. 3
[60] A. Yu and K. Grauman. Fine-grained visual comparisons with local learning. In CVPR, 2014. 8, 18
[61] C. Zach, M. Klopschitz, and M. Pollefeys. Disambiguating visual relations using loop constraints. In CVPR, 2010. 3
[62] R. Zhang, P. Isola, and A. A. Efros. Colorful image colorization. In ECCV, 2016. 2
[63] J. Zhao, M. Mathieu, and Y. LeCun. Energy-based generative adversarial network. In ICLR, 2017. 2
[64] T. Zhou, P. Krahenbuhl, M. Aubry, Q. Huang, and A. A. Efros. Learning dense correspondence via 3dguided cycle consistency. In CVPR, 2016. 2, 3
[65] T. Zhou, Y. J. Lee, S. Yu, and A. A. Efros. Flowweb: Joint image set alignment by weaving consistent, pixel-wise correspondences. In CVPR, 2015. 3
[66] J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman, and A. A. Efros. Generative visual manipulation on the natural image manifold. In ECCV, 2016. 2.

