

Generative Adversarial Nets[CAAE]
本文来自《Age Progression/Regression by Conditional Adversarial Autoencoder》,时间线为2017年2月。
该文很有意思,是如何通过当前图片生成你不同年龄时候的样子。
假设给你一张人脸(没有告诉你多少岁)和一堆网上爬取的人脸图像(包含不同年龄的标注人脸但不一定配对),你能给出那一张人脸80岁或者5岁时候的样子么。当然回答不能,当前现有的人脸年龄研究都试图学习一个年龄组间的变换,因此需要配对的样本和标注的询问图片。在本文中,作者从一个生成建模角度看待这个问题,从而不需要配对的样本。另外,给定一个无标注图片,生成的模型可以直接生成合适年龄的图片。本文提出的就是一个条件对抗自动编码器(conditional adversarial autoencoder ,CAAE),学习一个人脸流行,在该流行上滑动即得到平滑的年龄渐变。在CAAE中,人脸首先通过一个条件编码器映射到一个潜在向量,然后该向量通过一个解卷积生成器映射到基于年龄的人脸流行上。该潜在变量保留了个人的人脸特征,且具有年龄条件控制。两个对抗网络插入该编码器和生成器,强制生成更多真实性的人脸。
1 引言
人脸年龄预见(age progression)(即,预测未来的长相)和回溯(regression)(即,估计先前的长相),也叫做人脸衰老和青春复苏(face aging and rejuvenation),意在带有或者不带有年龄影响下的渲染人脸图片,但是依然保留人脸的个人特征(如个人属性)。这能影响到很多的应用,如思念/失踪人口的人脸预测,年龄不变性的验证,娱乐等等。该领域已经吸引了很多的研究人员。大多数挑战来自对训练和测试数据集的严格要求,以及在表情,姿势,分辨率,照明和遮挡方面在面部图像中呈现的大变化。对数据集的严格要求是指大多数现有工作需要可用的配对样本,即不同年龄的同一人的人脸图像,有些甚至需要在很长的年龄范围内配对样本,这是非常难以收集的。例如,最大的年龄数据集"Morph"[11]只抓取平均时间为164天的个人图像。另外,现在的工作同样需要查询的图片有真实年龄的标记,这就很不方便了。给定训练集,现在的工作基本都是将它们划分成不同的年龄组,然后学习不同年龄之间的一个变换,因此,必须标记查询图像才能正确定位图像。
虽然年龄预见和回溯是同等重要的,不过现在大多数工作还是在年龄预见上。只有非常少的工作在青春复苏上获得很好的效果,特别是从一个成年人得到其婴儿时候相片,因为他们只是基于表面进行建模,并简单移除给定图片上的纹理而已[7,14,18]。另一方面,研究者在年龄预见上有了很好的进展。如基于物理模型的方法[14,22,26,27]参数化模拟生物面部随年龄变化,例如肌肉,皱纹,皮肤等。然而,他们需要面对复杂的建模,还需要足够长时间的覆盖,而且计算代价较大;基于原型的方法[11,24,28,29]倾向将训练集划分成不同年龄组,并学习组间的变换。然而一些可以保留个人属性但是会引发严重的鬼影,其他的工作可以消除重影效应但会失去个性,而大多数工作放宽了长时间跨配对图像的要求,并且可以在两个相邻年龄组之间学习老化模式。尽管如此,他们仍然需要在短时间内配对样本。
本文中,作者从生成模型角度调研了年龄预见/回溯问题。在人脸图像生成领域GAN的快速发展也是有目共睹[17,19,21,31]。本文中,假设人脸图片位于一个高维流行上,
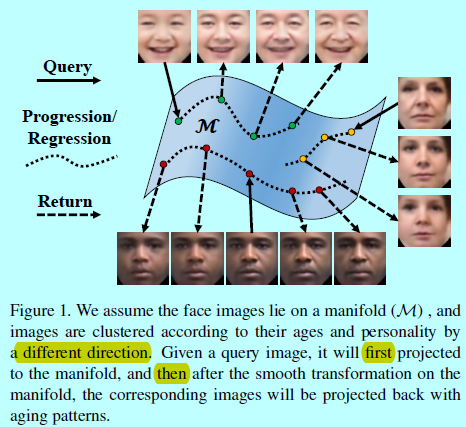
给定一个查询人脸,首先在流行上找到对应的点(人脸),然后朝着年龄变化的方向前进,去获取不同年龄段的人脸图片同时保留个性。作者提出一个条件对抗自动编码器(CAAE)网络来学习这个人脸流行。通过控制年龄属性,可以很灵活的同时得到年龄预见和回溯。因为很难直接在高维流行上进行操作,所以人脸首先通过一个卷积编码器映射到一个潜在向量上,然后该向量通过解卷积生成器去生成人脸。将两个对抗网络插入编码器和生成器,强制生成更多真实性人脸。
CAAE的好处有如下四点:
- 该网络结构同时获取年龄预见和回溯的时候还能生成真实性人脸图片;
- 抛弃基于组的学习,因此不需要在训练数据中有配对的样本或者测试数据中标注的人脸,使得框架更加灵活和通用;
- 潜在向量中的年龄和个性的解耦有助于保留个性同时避免鬼影;
- CAAE对于姿态,表情和光照有很好的鲁棒性。
2 在流行上遍历
我们假设人脸位于高维流行上,沿着特定方向遍历可以得到年龄预见/回溯的同时保留个性。该假设在下面用实验去证明。然而,对高维流行进行建模是很复杂的,也很难直接在流行上修改(遍历)。因此需要学习一个基于流行和更低维度空间(如潜在变量的空间)的映射,这就相对容易修改。

如图2所示,人脸\(x_1\)和\(x_2\)通过\(E\)(即一个编码器)映射到潜在变量空间,其提取个人特征\(z_1\)和\(z_2\)。与年龄标签\(l_1\)和\(l_2\)合并,从潜在空间中生成2个点,即\([z_1,l_1]\)和\([z_2,l_2]\)。注意到个性\(z\)和年龄\(l\)在潜在变量空间中是解耦的,因此只需要简单修改年龄的同时保留个性即可。从红色矩形开始\([z_2,l_2]\)(对应\(x_2\)),沿着年龄轴双向步进(如红色箭头),可以得到一系列新点(红色圆点)。通过另一个映射\(G\)(一个生成器),这些点映射到流行\(\mathcal{M}\)上,即生成一系列人脸图片,他们表示\(x_2\)的年龄预见/回溯。通过同样的逻辑,绿色点和箭头表示基于学到的流行和映射基础上,\(x_1\)的年龄预见/回溯。如果我们在潜在变量空间沿着虚线箭头移动,就可以同时改变个性和年龄。
3 方法
3.1 条件对抗自动编码器 CAAE
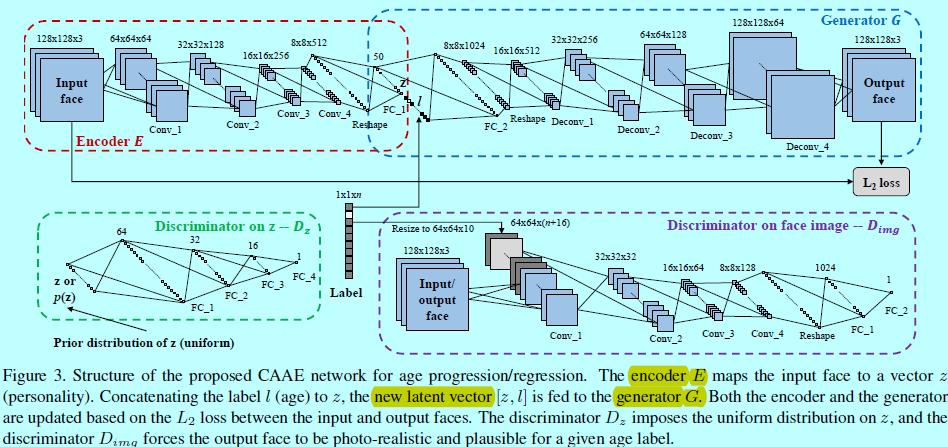
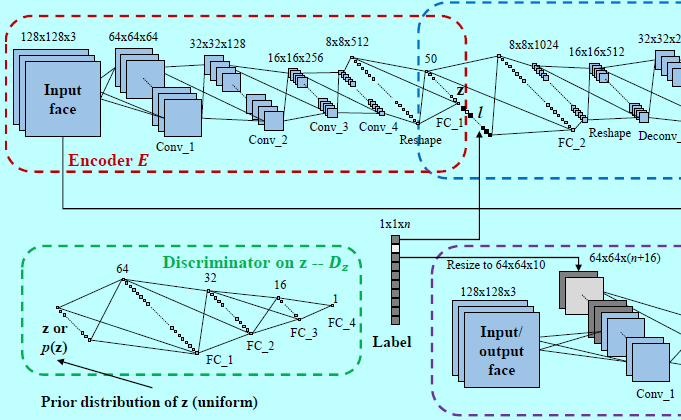
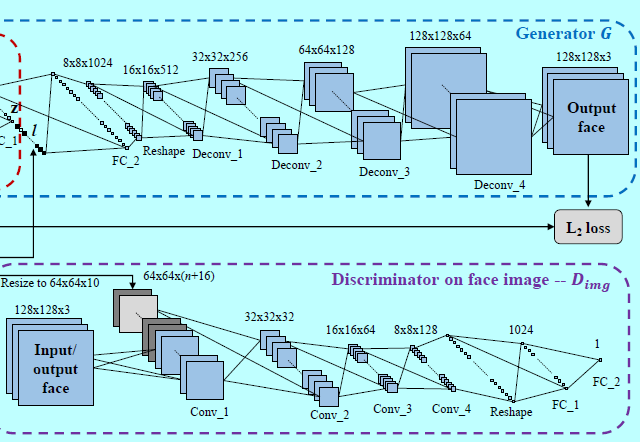
CAAE网络结构如图3.输入和输出的人脸图片都是128x128大小的RBG图片,一个CNN作为编码器。采用stride=2的卷积操作来代替池化操作(如最大池化),因为strided卷积是完全可微的,所以允许网络学到他自己的空间下采样[21]。编码器的输出\(E(x)=z\)保留了输入人脸\(x\)的高层个人特征。基于特定年龄的输出人脸可以通过\(G(z,l)=\hat x\)来表示,其中\(l\)是one-hot年龄label。不同于现存的GAN工作,这里插入一个编码器以避免\(z\)的随机采样,因为这里需要生成具有特定个性的人脸,而这些信息包含在\(z\)中。另外,还在编码器\(E\)和生成器\(G\)上插入两个判别器网络。\(D_z\)正则惩罚\(z\)为均匀分布,平滑年龄的变换。\(D_{img}\)为任意\(z\)和\(l\),强制\(G\)生成真实的相片和可接受的人脸。
3.2 目标函数
假设真实人脸图片都位于一个人脸流行\(\mathcal{M}\)上,所以输入的人脸图片具有\(x\in\mathcal{M}\),编码器\(E\)将输入人脸\(x\)映射到一个特征向量上,即\(E(x)=z\in\mathbb{R}^n\),这里\(n\)是人脸特征的维度。给定\(z\)和特定年龄label \(l\),生成器\(G\)生成的输出人脸\(\hat x=G(z,l)=G(E(x),l)\)。作者的目标是确保输出人脸\(\hat x\)位于流行的同时能够与输入人脸\(x\)共享个性和年龄。因此,输入和输出人脸期望是相似的,如式子2,这里\(\mathcal{L}(\cdot,\cdot)\)是L2范式:
同时,通过\(D_z\)判别器将均匀分布插入到\(z\)上。这里将训练数据的分布表示为\(p_{data}(\mathbf{x})\),然后\(z\)的分布为\(q(\mathbf{z}|\mathbf{x})\)。假设\(p(\mathbf{z})\)是一个先验分布,\(z^*\sim p(\mathbf{z})\)表示从\(p(\mathbf{z})\)上的随机采样过程。一个最小最大目标函数可以用来训练\(E\)和\(D_z\):
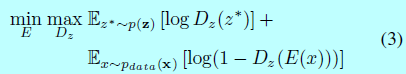
同样的逻辑,在人脸图像上的判别器\(D_{img}\)和带有条件\(l\)的\(G\)可以通过下面的目标函数训练:

最终的目标函数为:
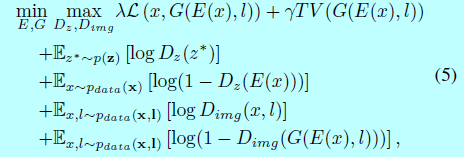
其中\(TV(\cdot)\)是有效去除鬼影的总变化。系数\(\lambda\)和\(\gamma\)用于权衡平滑和高分辨率。
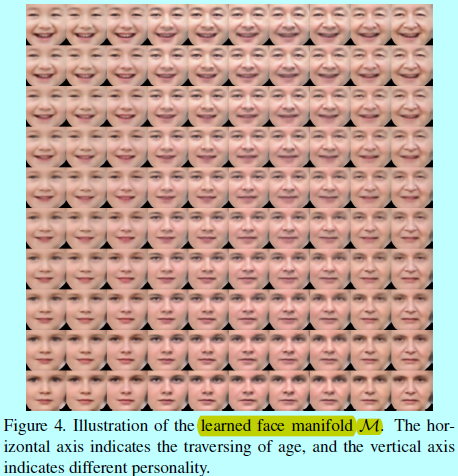
注意到年龄label是resize的,然后合并到\(D_{img}\)的第一个卷积层,让其能同时判别年龄和人脸。然后通过式子2,3,4去更新王最终学到如图4的流行\(\mathcal{M}\).
3.3 在\(z\)上的判别器
基于\(z\)的判别器,表示为\(D_z\),是在\(z\)上介入一个先验分布(即均匀分布)。特别的,\(D_z\)为了判别由编码器\(E\)生成的\(z\)。同时,\(E\)会生成\(z\)来愚弄\(D_z\)。这样的对抗过程可以让生成的\(z\)的分布逐步接近先验。作者用均匀分布作为先验,迫使\(z\)均匀的填充潜在空间,使其不会有明显的“洞”。
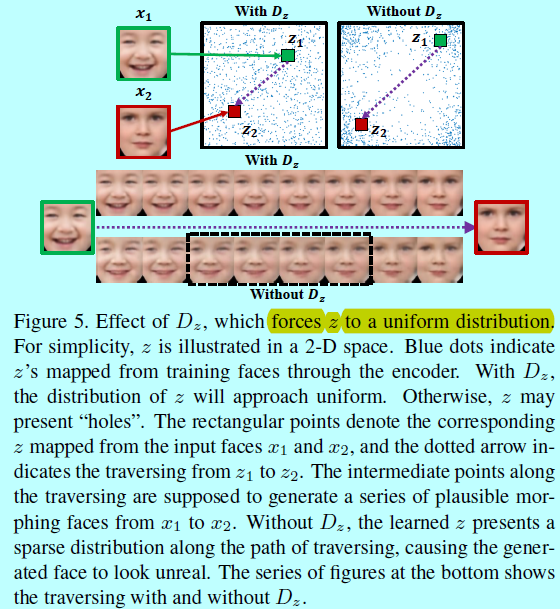
图5所示,生成的\(z\)(图中蓝色点)表示基于\(D_z\)正则的均匀分布,同时\(z\)的分布在没有\(D_z\)时候,就会有明显的“洞”。这些“洞”的出现表示通过在任意\(z\)之间插值产生的人脸图像可能不会位于面部流形上,即产生不切实际的人脸。如图5中给定两个人脸\(x_1\)和\(x_2\),通过\(E\),分别在有和没有\(D_z\)的参与下,得到对应的\(z_1\)和\(z_2\).在\(z_1\)和\(z_2\)之间插值(图5的虚线箭头),生成的人脸期望能够具有真实性和平滑变形(图5底部),然而在没有\(D_z\)的正则惩罚下,变形呈现的是扭曲(非真实)的人脸,即中间部分(图中黑色虚线矩形框),其对应着插值\(z\)时候经过的“洞”。
3.4 在人脸图像上的判别器
继承自GAN的相似性原则,在人脸图像上的判别器\(D_{img}\)强制生成器生成更具真实性的人脸。另外,插入\(D_{img}\)的年龄label,以区别不同年龄的非自然人脸。通过最小化输入和输出人脸之间的距离,如式子2,强制输出人脸更靠近真实人脸。当然式子2并不会确保框架从无采样人脸上生成合理的人脸。例如,给定训练过程中未看见的人脸和一个随机年龄label,逐像素loss 只能让框架生成的人脸靠近训练过的人脸,以插值的方式实现,这时候就会导致生成的人脸是十分模糊的。\(D_{img}\)会从年龄,真实性,分辨率角度判别从真实人脸上生成的人脸

图6展示了\(D_{img}\)的效果。其中\(D_{img}\)会增强纹理,特别是更老的人脸上。
3.5 与其他生成网络的区别
这里会介绍CAAE与VAE,AAE等的差别。
VAE vs GAN
VAE使用一个识别网络,在潜在变量基础上预测后验分布,而GAN使用一个对抗训练过程直接通过BP塑造网络的输出分布。因为VAE遵循一个编码解码过程,我们可以直接将生成的图片与输入进行对比,而在使用GAN的时候是不可能的。VAE的一个缺点是它是由均值平方差而不是对抗网络来生成图像,所以会生成更多模糊的图片[15]。
AAE vs GAN and VAE
AAE可以被看成GAN和VAE的结合,这保持如VAE的AE网络,但是用GAN中的对抗网络来替换其中的KL散度。不是如GAN中一样基于随机噪音生成图像,AAE利用编码器去学习潜在的变量,以此逼近某个先验,让生成的图像类型可控。另外,AAE相比VAE更好的抓取数据流行。
CAAE vs AAE
提出的CAAE更相似于AAE。与AAE的主要区别是提出的CAAE在编码器和生成器上加入了判别器。编码器上的判别器保证潜在空间中的平滑过渡,而生成器上的判别器有助于生成真实的人脸图像。因此,CAAE会生成比AAE质量更高的人脸。
4 实验评估
4.1 数据收集
首先获取Morph数据集[11]和CACD数据集[2]。Morph数据集是最大的,包含每个人多个年龄段的数据集,包含13000个人的55000张图片,从16岁到77岁。CACD数据集包含2000个人和13446个图片。因为两个数据集量都比较少,所以作者从Bing和google上基于关键字进行了搜索,如baby,boy,teenager,15 years old等等。因为提出的方法不需要来自同一个人的多个人脸,所以简单随机从Morph和CACD上挑选大概3000张图片和7670张搜索的图片。爬取人脸的年龄和性别是基于图片标题或者年龄估算器进行估算的[16]。作者这里将年龄划分成10个阶段,0-5,6-10,11-15,16-20,21-30,31-40,41-50,51-60,61-70,71-80。因此,可以使用10个元素的one-hot去只是训练过程中每个人脸的年龄。最终数据集包含10670张人脸图,基于性别和年龄均匀抽取。作者使用[5]中的检测算法和68个标注点进行裁剪和对齐人脸,使得训练更容易实现。
4.2 CAAE的实现
如图3,其中kernel size为5x5。输入图像的像素值归一化到[-1,1]。\(E\)的输出如\(z\)同样通过tanh函数限制到[-1,1]。然后合适的年龄label,一个oneh-hot向量合并到\(z\)上,构建\(G\)的输入。为了同等的合并,label的元素也限制到[-1,1],其中-1就是表示0.最后,输出同样通过tanh约束到[-1,1]。归一化输入可以让训练过程收敛更快。注意带这里没有使用BN,是因为它会模糊个人特征并让输出的人脸在测试中远离输入。然而如果用在\(D_{img}\)上,bn可以让框架更稳定。每个块(E,G,\(D_z\)和\(D_{img}\))的所有中间层都是用ReLU激活函数。
在训练中\(\lambda=100,\gamma=10\),这四个块是用minibatch size等于100进行交替更新的,采用的ADAM(\(\alpha=0.0002,\beta_1=0.5\)).人脸和年龄成对输送给网络。在50个epoch之后,就可以生成可接受的人脸。在测试阶段,只有\(E\)和\(G\)是活动的。给定一个没有真实年龄label的输入人脸,\(E\)会将其映射成\(z\)。合并一个任意年龄label到\(z\),\(G\)会生成一个基于年龄和个性的真实人脸。
4.3 定性和定量的对比
4.4 姿态,表情,光照的容忍度
reference:
[1] D. M. Burt and D. I. Perrett. Perception of age in adult caucasian male faces: Computer graphic manipulation of shape and colour information. Proceedings of the Royal Society of London B: Biological Sciences, 259(1355):137–143, 1995. 2
[2] B.-C. Chen, C.-S. Chen, and W. H. Hsu. Cross-age reference coding for age-invariant face recognition and retrieval. In Proceedings of the European Conference on Computer Vision, 2014. 6
[3] X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel. InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. In Advances in Neural Information Processing Systems, 2016. 3
[4] E. L. Denton, S. Chintala, R. Fergus, et al. Deep generative image models using a laplacian pyramid of adversarial networks. In Advances in Neural Information Processing Systems, pages 1486–1494, 2015. 3
[5] Dlib C++ Library. http://dlib.net/.
[Online]. 6
[6] Face Transformer (FT) demo. http://cherry.dcs. aber.ac.uk/transformer/.
[Online]. 8
[7] Y. Fu and N. Zheng. M-face: An appearance-based photorealistic model for multiple facial attributes rendering. IEEE Transactions on Circuits and Systems for Video Technology, 16(7):830–842, 2006. 2
[8] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D.Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems, pages 2672–2680, 2014. 2, 5
[9] K. Gregor, I. Danihelka, A. Graves, D. J. Rezende, and D. Wierstra. Draw: A recurrent neural network for image generation. arXiv preprint arXiv:1502.04623, 2015. 3
[10] D. J. Im, C. D. Kim, H. Jiang, and R. Memisevic. Generating images with recurrent adversarial networks. arXiv preprint arXiv:1602.05110, 2016. 3
[11] I. Kemelmacher-Shlizerman, S. Suwajanakorn, and S. M. Seitz. Illumination-aware age progression. In IEEE Conference on Computer Vision and Pattern Recognition, pages 3334–3341. IEEE, 2014. 1, 2, 6, 7, 8
[12] D. Kingma and J. Ba. ADAM: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 7
[13] D. P. Kingma and M. Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013. 5
[14] A. Lanitis, C. J. Taylor, and T. F. Cootes. Toward automatic simulation of aging effects on face images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(4):442–455, 2002. 2, 7
[15] A. B. L. Larsen, S. K. Sønderby, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015. 6
[16] G. Levi and T. Hassner. Age and gender classification using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 34–42, 2015. 6
[17] M. Y. Liu and O. Tuzel. Coupled generative adversarial networks. In Advances in neural information processing systems, 2016. 2, 3
[18] Z. Liu, Z. Zhang, and Y. Shan. Image-based surface detail transfer. IEEE Computer Graphics and Applications, 24(3):30–35, 2004. 2
[19] A. Makhzani, J. Shlens, N. Jaitly, and I. Goodfellow. Adversarial autoencoders. In International Conference on Learning Representations, 2016. 2, 3, 5, 6
[20] M. Mirza and S. Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014. 3
[21] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In International Conference on Learning Representations, 2016. 2, 3, 4
[22] N. Ramanathan and R. Chellappa. Modeling age progression in young faces. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, volume 1, pages 387–394. IEEE, 2006. 2
[23] N. Ramanathan and R. Chellappa. Modeling shape and textural variations in aging faces. In IEEE International Conference on Automatic Face & Gesture Recognition, pages 1–8. IEEE, 2008. 2
[24] X. Shu, J. Tang, H. Lai, L. Liu, and S. Yan. Personalized age progression with aging dictionary. In Proceedings of the IEEE International Conference on Computer Vision, pages 3970–3978, 2015. 2, 7, 8
[25] J. Suo, X. Chen, S. Shan, W. Gao, and Q. Dai. A concatenational graph evolution aging model. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(11):2083– 2096, 2012. 2
[26] J. Suo, S.-C. Zhu, S. Shan, and X. Chen. A compositional and dynamic model for face aging. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(3):385–401, 2010. 2, 7, 8
[27] Y. Tazoe, H. Gohara, A. Maejima, and S. Morishima. Facial aging simulator considering geometry and patch-tiled texture. In ACM SIGGRAPH 2012 Posters, page 90. ACM, 2012. 2
[28] B. Tiddeman, M. Burt, and D. Perrett. Prototyping and transforming facial textures for perception research. IEEE Computer Graphics and Applications, 21(5):42–50, 2001. 2
[29] W. Wang, Z. Cui, Y. Yan, J. Feng, S. Yan, X. Shu, and N. Sebe. Recurrent face aging. In IEEE Conference on Computer Vision and Pattern Recognition, pages 2378–2386. IEEE, 2016. 2, 7, 8
[30] X. Yu and F. Porikli. Ultra-resolving face images by discriminative generative networks. In European Conference on Computer Vision, pages 318–333. Springer, 2016. 3
[31] J. Zhao, M. Mathieu, and Y. LeCun. Energy-based generative adversarial network. arXiv preprint arXiv:1609.03126, 2016. 2, 3

