

face recognition[variations of softmax][ArcFace]
本文来自《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》,时间线为2018年1月。是洞见的作品,一作目前在英国帝国理工大学读博。
CNN近些年在人脸识别上效果显著,为了增强softmax loss的辨识性特征学习能力,Sphereface提出的multiplicative angular margin,参考文献[43,44]提出的additive cosine margin等分别通过将角度边际和余弦边际整合到loss函数中。
本文中作者提出一个附加角度边际(additive angular margin,ArcFace),比目前提出的监督信号有更好的几何解释。特别的,提出的ArcFace \(cos(\theta+m)\)直接最大化角度空间中的决策边界,该角度空间是基于L2-norm的权重和特征生成的。与multiplicative angular margin(\(cos(m\theta)\))和additive cosine margin \((cos\theta-m)\)相比,ArcFace可以获得更具辨识性的深度特征。
0 引言
不同的人脸识别方法主要在以下三个方面有差异:
训练数据
目前主流的人脸数据集有VGG-Face, VGG2-Face, CAISA-WebFace, UMDFace, MS-Celeb-1M和MegaFace。其中MS-Celeb-1M和MegaFace虽然ID数量上很大,可是也受到标注噪音和长尾分布的影响。而之前谷歌的FaceNet中训练的ID就几百万。因为训练集量级的不同,工业界人脸识别的效果会好于学术界,而且因为人脸数据集的不同,很多论文效果也不能完全复现。
网络结构和配置
如ResNet,Inception-ResNet可以获得比VGG网络和Inception v1更好的效果,不同人脸识别的应用主要在速度和精度之间权衡。例如移动端的人脸验证,需要实时性的运行速度和紧凑的模型大小。而对于十亿级别的安全系统,高准确度才是最重要的。
loss函数的设计
- 基于欧式边际的loss:在最开始的人脸识别文献如[31,42],基于一系列已知ID的数据集上训练softmax,然后从网络的中间层输出特征向量,并用该向量去泛化训练集中未知的ID数据。后续的Center loss[46], Range loss[50], Marginal loss[10]对最后softmax loss增加了额外的惩罚,使得网络能压缩类内变化,扩大类间变化,以此提升检测率,但是他们仍然还是通过结合softmax 的方式去训练网络模型。基于分类的模型,当ID个数达到百万级别时,分类层会大量消耗GPU内存,而且网络本身更倾向平衡的,足够(每个ID的样本量)的训练数据。
contrastive loss和triplet loss利用了图像多元组的策略。contrastive loss需要正对和负对,loss的梯度会将正对拉近,负对推远。triplet loss最小化锚和一个正样本之间的距离,并最大化锚和一个负样本之间的距离。然而,contrastive loss和triplet loss的训练过程是需要技巧的,因为设计到训练样本的选择。- 基于角度和余弦边际的loss:L-Softmax通过增加multiplicative angular constraints到每个ID上,以提升特征辨识性。SphereFace \(cos(m\theta)\)基于L-Softmax,使用权重归一化方式去深度人脸识别。因为余弦函数的非单调性,SphereFace引入一个分段(piece-wise )函数保证单调性。在SphereFace的训练过程中,Softmax loss可以很容易的结合起来方便和确保收敛。为了解决SphereFace较难优化的问题,additive cosine margin \(cos(\theta)-m\)将角度边际移动到余弦空间中,additive cosine margin比SphereFace更容易实现和优化。而且additive cosine margin也更容易复现,且TencentAILab FaceCNN v1用此方法在当时MegaFace获得了第一名。相比于欧式边际的loss,角度和余弦边际loss是显式的在一个超球面流行上增加辨识性约束。
如上所述,三个方面中,按影响程度从高到低排序是:数据>> 网络>> loss。
本文也在这三个方面有所贡献:
数据
作者提炼了当前可用的最大公开数据集MS-Celeb-1M,通过自动和手动两种相结合。通过ResNet-27网络和在NIST人脸识别挑战赛上的marginal loss相结合,对MS1M数据集进行质量评估。作者发现在MegaFace一百万个干扰物与FaceScrub数据集之间存在数百个重叠的人脸图像,这会影响评估结果。所以从MegaFace干扰物中手动找到这些重叠的人脸。
网络结构
以VGG2作为训练数据,对卷积网络配置进行了广泛的对比实验,并在LFW,CFP和AgeDB上验证准确性。 所提出的网络配置在较大的姿态和年龄变化下都有鲁棒性的表现。并探讨了最近提出的网络结构上速度和准确性之间的权衡。
loss设计
提出一个新的loss函数,附加角度边际(additive angular margin,ArcFace)
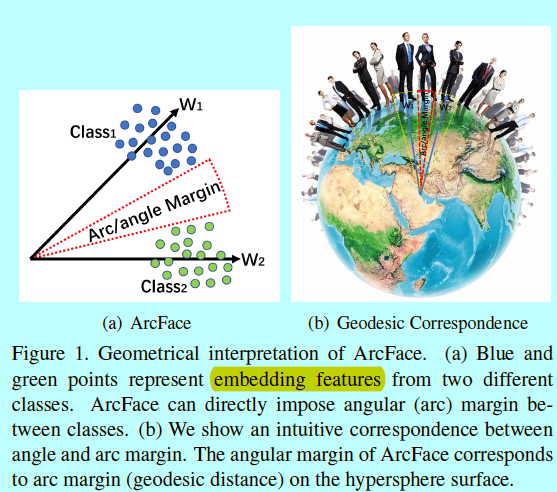
如图1,提出的loss函数\(cos(\theta+m)\)直接最大化角度空间中的决策边界,该角度空间是基于L2-norm的权重和特征生成的。可以发现ArcFace不知有更清晰的集合解释,同时优于一些baseline方法,如multiplicative angular margin 和additive cosine margin,本文后面从半硬样本分布上研究了为什么ArcFace要好于Softmax,SphereFace和CosineFace。
1 从softmax到ArcFace
1.1 sofmax
softmax函数是最广泛使用的分类函数,其式子为:
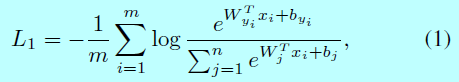
这里\(x_i \in R^d\)表示第\(i\)个样本的深度特征,属于第\(y_i\)类。特征维度d在本文中为512[参考文献23,43,46,50]。\(W_j \in R^d\)表示最后一层全连接层中权重矩阵\(W \in R^{d\times n}\)第\(j\)列,\(b\in R^n\)就是对应的偏置。batch-size和类别个数分别为m和n。
1.2 权重归一化
为了简洁,将偏置\(b_j=0\)。然后将目标logit转换成如下式子:
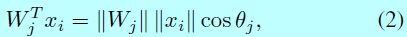
然后通过L2-norm固定\(||W_j||=1\),这让预测值以来特征向量和权重之间的角度:
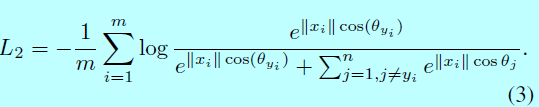
在SphereFace中,L2权重归一化基本没什么提升。
1.3 Multiplicative Angular Margin
在SphereFace中,角度边际m通过与角度相乘进入loss:
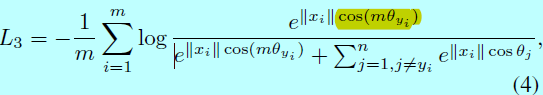
其中\(\theta_{y_i}\in [0, \frac{\pi}{m}]\),为了移除这个约束,\(cos(m\theta_{y_i})\)通过一个分段单调函数\(\psi (\theta_{y_i})\)代替,SphereFace式子写成:
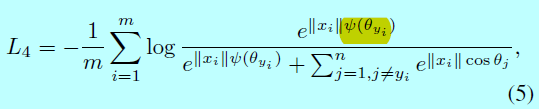
这里\(\psi (\theta_{y_i})=(-1)^kcos(m\theta_{y_i})-2k\),\(\theta_{y_i}\in \left [ \frac{k\pi}{m}, \frac{(k+1)\pi}{m}\right ]\),\(k \in [0, m-1]\),\(m \geq 1\)是整数,用于控制角度边际的size。然而在SphereFace实现中,softmax有监督也会包含进去以保证训练的收敛,且通过一个超参数\(\lambda\)去控制权重,在带有额外softmax loss下,\(\psi(\theta_{y_i})\)为:
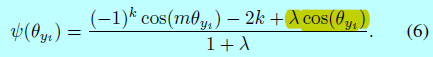
这里\(\lambda\)是一个额外的超参数以方便SphereFace训练,\(\lambda\)在最开始设为1000,然后减小到5以保证每个类别的角度空间更紧凑。这个超参数让SphereFace的训练也变得十分讲究技巧。
1.4 特征归一化**
在人脸验证中,特征归一化被广泛使用,如L2-norm的欧式距离和余弦距离[29]。[30]观察到使用softmax训练的L2-norm特征具有人脸质量的信息。对于高质量的正脸就有较高L2-norm,而对于模糊的人脸和极端姿态的人脸就有较低L2-norm。[33]将L2约束加入到特征描述中,以此限制特征位于一个固定半径的超球面上。[44]指出在当来自低质量人脸图的特征范数很小的时候梯度范数可能会变得相当大,这隐含了梯度爆炸的风险。
L2-norm在特征和权重上对于超球面的度量学习是很重要的一步。背后的直观感觉就是这样可以移除径向变化,并将每个特征推到一个超球面流行上。特征规范化的优势在参考文献[25,26,43,45]中都有揭示。
受到[参考文献33,43,44,45]的启发,作者在这里也将\(||x_i||\)通过L2-norm,并且rescale \(||x_i||\)到s,这就是超球面的半径,本文中,\(s=64\),基于特征和权重归一化,可以得到\(W_j^Tx_i=cos\theta_j\)。
如果特征规范化用在SphereFace上,可以得到一个特征规范化的SphereFace,即SphereFace-Norm:
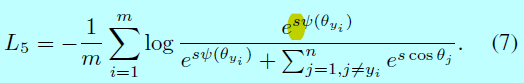
1.5 Additive Cosine Margin**
在文献[43,44]中,角度边际m从\(cos\theta\)中移除了,因此他们提出余弦边际loss函数:

本文中,余弦边际设为0.35.相比于SphereFace,额外的余弦边际(CosineFace)有三个优势:
- 不需要任何超参数就能容易实现;
- 更清晰,且能够在没有softmax的辅助下收敛;
- 明显的性能提升。
1.6 Additive Angular Margin**
虽然余弦边际是角度空间一对一的映射过来的,在这两个边际中仍然还是有不同的。事实上,角度边际有着更清晰的几何解释,角度空间中的边际对应超球面流行上角度(arc)距离。作者在\(cos\theta\)中增加了一个角度边际,因为当\(\theta\in [0,\pi-m]\)时,\(cos(\theta+m)\)小于\(cos(\theta)\),该约束对分类也更严格。这里将提出的ArcFace损失函数定义为:
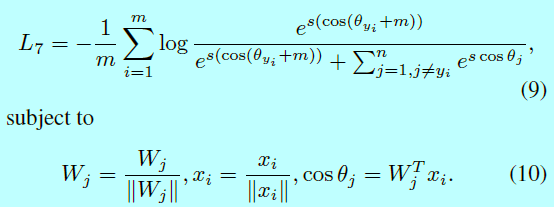
如果将提出的Additive Angular Margin \(cos(\theta+m)\)进行展开,得到\(cos(\theta+m)=cos\theta cos\, m-sin\theta sin\, m\)。相比于additive cosine margin \(cos(\theta)-m\),ArcFace是类似的,不过因为\(sin\, m\)使得边际是动态的。
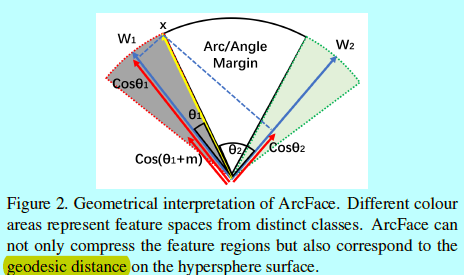
如图2,角度边际对应arc边际,相比于SphereFace和ConsineFace,ArcFace有着最好的度量解释。
1.7 二值情况下的对比
为了更好的理解softmax到ArcFace,基于表1和图3的二分类下决策面
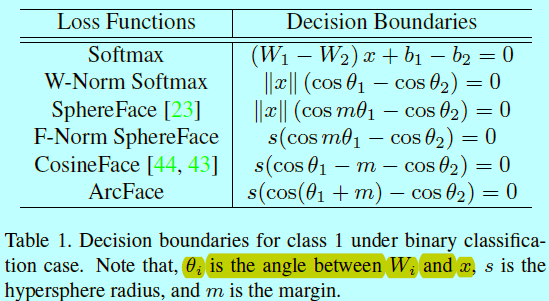
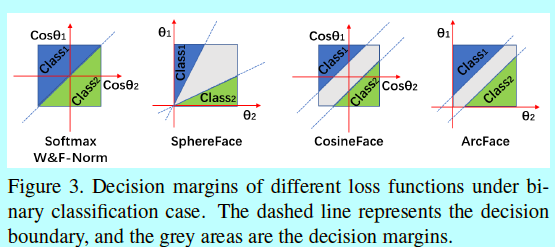
基于规范化后的权重和特征,这些方法的主要区别就是在哪放边际。
1.8 目标logit分析
为了调查为什么人脸识别可以被SphereFace,CosineFace和ArcFace所提升,需要分析训练过程中目标logits曲线和\(\theta\)的分布。这里使用LResNet34E-IR网络和提炼的MS1M数据集。
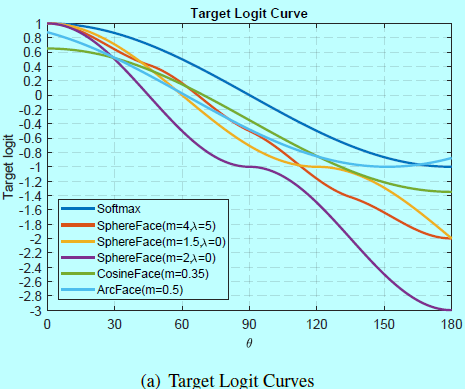

在图4a中,将softmax,SphereFace,CosineFace,ArcFace的目标logit曲线都展示了下。对于SphereFace,最好的配置是m=4,\(\lambda=5\),其相似于m=1.5,\(\lambda=0\)的曲线。然而,SphereFace的实现需要m是整数。当尝试最小相乘边际m=2,\(\lambda=0\)时,训练没法收敛。因此,从Softmax下稍微降低目标logit曲线可以增加训练难度并改善性能,但是减少太多可能导致训练发散。
CosineFace和ArcFace遵循相同的策略,如图4a,CosineFace沿着y轴负方向移动目标logit曲线,而ArcFace沿着x轴负方向移动目标logit曲线。现在,可以很容易的理解从Softmax到CosineFace到ArcFace的性能提升。
ArcFace的边际m=0.5时,\(\theta]in[0,180]\)度目标logit曲线不是单调下降的。事实上,当\(\theta>151.35\)时,目标logit曲线是上升的。然而如图4c,最开始随机初始化时,\(\theta\)在\(90\)度为中心部分是个高斯分布,其最大的角度小于105度。在训练阶段,几乎从未达到ArcFace的增长间隔,所以不需要显式处理这部分。
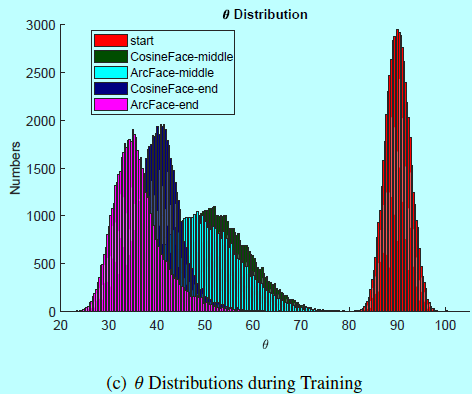
图4c中,主要展示了CosineFace和ArcFace在训练三个阶段的\(\theta\)分布:开始,中间,结束。分布中心逐渐的从90移动到35-40。
图4a中,发现30到90度时,ArcFace的目标logit曲线低于CosineFace。因此在这个区间内,ArcFace可以相比CosineFace有更多严格的边际惩罚。
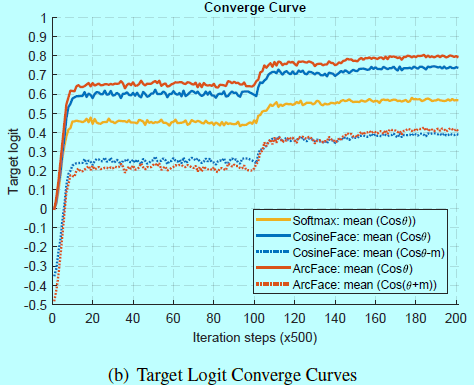
图4b中,展示了针对Softmax,CosineFace,ArcFace在训练集上目标logit收敛曲线。可以发现ArcFace的边际惩罚在最开始要重于CosineFace,如红线低于蓝线。在训练最后,ArcFace收敛要好于CosineFace如\(\theta\)的直方图在左边(图4c),目标logit收敛曲线更高(图4b)。从图4c中,还能发现在训练最后几乎所有的\(\theta\)要小于60度。这个领域外的样本都是最难的样本,就和训练集合中的噪音一样。即使CosineFace在\(\theta<30\)上放入更多严格边际惩罚(图4a),即使在训练最后也很难达到这个领域(图4c)。因此,可以理解为什么SphereFace即使在一个相对小的边际上也能获得很好的性能。
总结来说,当\(\theta\in[60,90]\)时,增加太多边际惩罚会导致训练发散,即SphereFace(m=2,\(\lambda=0\))。当\(\theta\in [30,60]\)时,增加边际可以潜在提升性能,因为这个区域对应的是最有效的半硬样本。当\(\theta<30\)时,不能明显提升效果,因为这个区域对应的是最简单的样本。当回头看图4a和介于\([30,60]\)之间的曲线,可以理解为什么从Softmax,SphereFace,CosineFace,ArcFace有性能提升(基于各自最好的超参数)。注意到这里30和60度是简单的作为简单和困难训练样本的划分阈值。
2 数据集
有些数据集直接用,有些数据集需要提炼,比如直接通过规则提炼,或者通过其他模型进行提炼。
以VGG2(直接使用)和MS=Celeb-1M(提炼过为MS1M)为训练集。
以LFW,Celebrities in Frontal Profile (CFP) 和 Age Database (AgeDB)为验证集
以MegaFace为测试集
3 网络设置
首先基于VGG2作为训练集在几个不同的网络上进行训练并评估人脸验证性能。采用softmax作为loss。batchsize为512,基于8张P40训练,学习率开始是0.1,然后在100k,140k,160k迭代上分别乘以0.1倍。总共迭代200k次,动量值为0.9,权重衰减项系数为0.0005。
3.1 输入设置
采用和MTCNN一样的对齐策略,人脸检测后会被裁减并缩放到112x112.每个RGB值先减去127.5,然后除以128。为了匹配大部分224x224的网络输入,作者这里用conv3x3和stride=1作为第一层卷积层,代替之前的conv7x7和stride=2。对于这2个配置,卷积网络的输出size分别是7x7(网络名前面有个"L")和3x3。
3.2 输出设置
在最后几层,一些不同的选择可以通过检测embedding是如何影响模型结果的方式来评估。对于Option-A,所有特征embedding维度都为512,因为Option-A中embedding size由最后一个卷积层的通道大小决定:
- Option-A:使用全局池化层(GP)
- Option-B:在GP后使用一个全连接层(FC);
- Option-C:在GP后面使用FC-BN;
- Option-D:在GP后使用FC-BN-PReLU;
- Option-E:在最后卷积层后面使用BN-Dropout-FC-BN;
在预测阶段,计算的得分是通过两个向量的余弦距离,最近邻和阈值对比是用在人脸识别和验证任务上。
3.3 块设置
如同最原始ResNet单元,我们同样调研一个更好的残差单元配置。
<center.>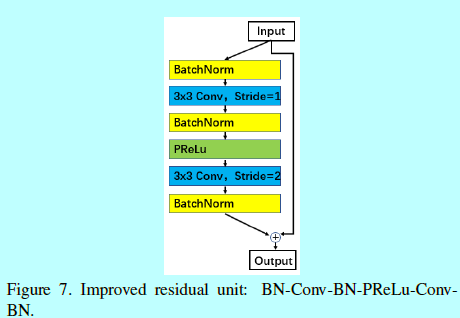
如图7,这里将改变后的残差单元称为"IR",其是一个BN-Conv-BN-PReLU-Conv-BN结构。相比于[12]中的残差单元,这里第二次卷积层的stride=2。另外,PReLU用来替换ReLU。
3.4 基底骨干网络
作者也调研了MobileNet,Inception-Resnet-V2,DenseNet,SENet,(Dual path network,DPN)。
3.5 不同配置实验结果
输入选择
在表2中,对比了有L和没有L的网络结构,当在第一层网络层使用conv3x3和stride=1时,网络输出是7x7;当第一层卷积层使用conv7x7和stride=2时,网络输出只有3x3.
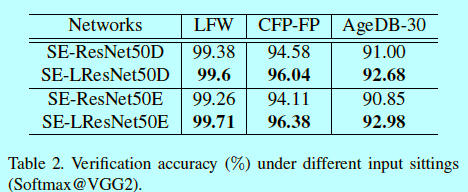
从表2可以发现,选择更大的feature map可以获得更高的验证准确度。
输出选择
在表3中,给定不同输出配置下的对比。Option-E获得最好的性能本文中dropout参数为0.4,dropout可以扮演一个正则化的角色来缓解过拟合从而获得更好的泛化效果

块选择
在表4中,给定原始残差块和改变的残差块的对比。
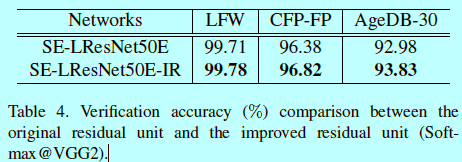
可以发现,提出的BN-Conv(stride=1)-BN-PReLu-Conv(stride=2)-BN可以获得更好效果。
骨干网络选择
从表8,给出了验证准确度,测试速度和模型size。运行时间是在P40上测的。因为在LFW上性能基本饱和了,所以关注与CFP-FP和AgeDB-30。Inception-Resnet-V2网络获得最好的性能,一次需要(53.6ms),模型也最大(642MB)。通过对比,MobileNet可以在4.2ms,112MB大小下运行。而性能只有稍微下降。
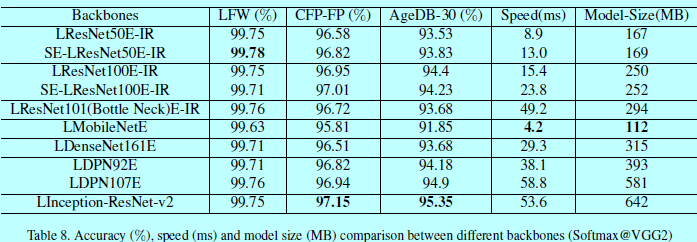
如表8,在大网络直接的性能差距还是挺小的,如ResNet-100, Inception-Resnet-V2, DenseNet, DPN 和 SE-Resnet-100。介于准确度,速度,模型size,最后选择LResNet100E-IR作为MegaFace挑战的模型预测。
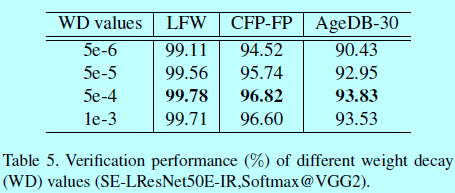
权值衰减
基于SE-LResNet50E-IR,也调研了权重值是怎么影响人脸验证性能。

当衰减值为0.0005时,验证准确度最高。因此在所有实验中,本文将其设为默认值。
4 loss设置
因为边际参数m在ArcFace中扮演很重要的角色,首先通过实验找到最佳边际参数。通过选取[0.2,0.8]之间的值,使用LMobileNetE和ArcFace的loss基于提炼后的MS1M上训练模型。
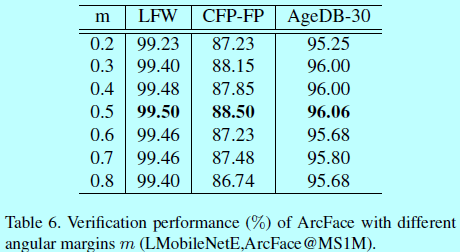
如表6,当m=0.2时性能开始提升,在m=0.5的时候性能饱和,然后开始下降。因此本文中m取值0.5。并基于LResNet100E-IR网络和MS1M数据集,对比了不同loss函数,如softmax,SphereFace,CosineFace和ArcFace。
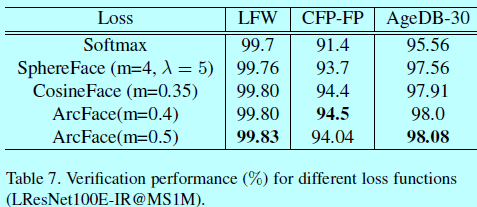
表7中,给出了基于LFW,CFP-FP,AgeDB-30数据集上的验证准确值。LFW上准确度都接近饱和了,所以提升效果不明显,不过可以发现:
- 相比softmax,其他如SphereFace,CosineFace和ArcFace都有明显提升,特别是基于较大姿态和年龄变化;
- CosineFace和ArcFace明显优于SphereFace,且容易实现,且他俩不需要添加额外的softmax来辅助收敛。而SphereFace需要softmax来帮助收敛;
- ArcFace稍好于CosineFace。然而,ArcFace更直观,且几何上解释更清晰。
5 FaceScrub上MegaFace 挑战1
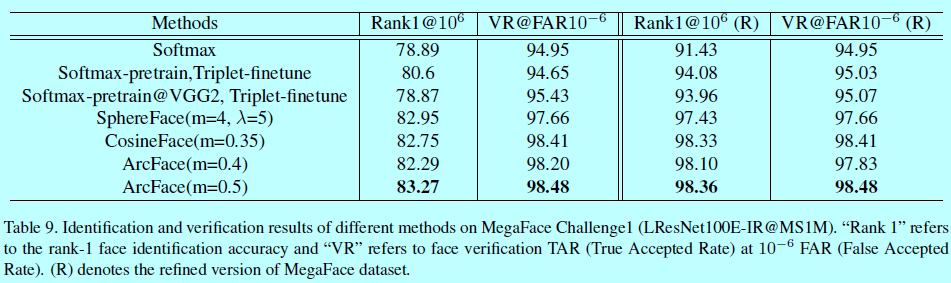
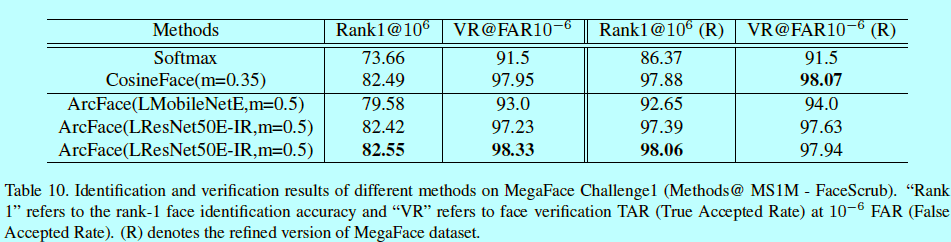
6 基于triplet loss的提升
reference:
- [1] Fg-net aging database, www-prima.inrialpes.fr/fgnet/.2002. 6
- [2] http://megaface.cs.washington.edu/results/facescrub.html. 1, 2, 9
- [3] https://github.com/davidsandberg/facenet. 2
- [4] https://www.nist.gov/programs-projects/face-recognitionvendor- test-frvt-ongoing. 1
- [5] http://www.yitutech.com/intro/. 1
- [6] A. Bansal, A. Nanduri, C. D. Castillo, R. Ranjan, and R. Chellappa. Umdfaces: An annotated face dataset for training deep networks. arXiv:1611.01484v2, 2016. 1
- [7] Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman. Vggface2: A dataset for recognising faces across pose and age. arXiv:1710.08092, 2017. 1, 2, 3, 6
- [8] T. Chen, M. Li, Y. Li, M. Lin, N. Wang, M. Wang, T. Xiao, B. Xu, C. Zhang, and Z. Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv:1512.01274, 2015. 7
- [9] Y. Chen, J. Li, H. Xiao, X. Jin, S. Yan, and J. Feng. Dual path networks. In Advances in Neural Information Processing Systems, pages 4470–4478, 2017. 8
- [10] J. Deng, Y. Zhou, and S. Zafeiriou. Marginal loss for deep face recognition. In CVPRW, 2017. 2, 6
- [11] Y. Guo, L. Zhang, Y. Hu, X. He, and J. Gao. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In European Conference on Computer Vision, pages 87–102. Springer, 2016. 1, 2, 6
- [12] D. Han, J. Kim, and J. Kim. Deep pyramidal residual networks. arXiv:1610.02915, 2016. 8
- [13] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015. 8
- [14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016. 2, 8
- [15] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In European Conference on Computer Vision, pages 630–645. Springer, 2016. 2
- [16] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko,W.Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861, 2017. 2, 8
- [17] J. Hu, L. Shen, and G. Sun. Squeeze-and-excitation networks. arXiv:1709.01507, 2017. 8
- [18] G. Huang, Z. Liu, K. Q. Weinberger, and L. van der Maaten. Densely connected convolutional networks. CVPR, 2016. 8
- [19] G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Technical report, Technical Report 07-49, University of Massachusetts, Amherst, 2007. 5, 6
- [20] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning, pages 448– 456, 2015. 8
- [21] I. Kemelmacher-Shlizerman, S. M. Seitz, D. Miller, and E. Brossard. The megaface benchmark: 1 million faces for recognition at scale. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4873– 4882, 2016. 1, 2, 5, 6
- [22] J. Liu, Y. Deng, T. Bai, Z.Wei, and C. Huang. Targeting ultimate accuracy: Face recognition via deep embedding. arXiv preprint arXiv:1506.07310, 2015. 10
- [23] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song. Sphereface: Deep hypersphere embedding for face recognition. CVPR, 2017. 1, 2, 3, 4, 7, 9
- [24] W. Liu, Y. Wen, Z. Yu, and M. Yang. Large-margin softmax loss for convolutional neural networks. In ICML, pages 507– 516, 2016. 2, 3
- [25] W. Liu, Y.-M. Zhang, X. Li, Z. Yu, B. Dai, T. Zhao, and L. Song. Deep hyperspherical learning. In Advances in Neural Information Processing Systems, pages 3953–3963, 2017. 3
- [26] Y. Liu, H. Li, and X. Wang. Rethinking feature discrimination and polymerization for large-scale recognition. arXiv:1710.00870, 2017. 3
- [27] S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, and S. Zafeiriou. Agedb: The first manually collected in-the-wild age database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop, 2017. 5, 6
- [28] H.-W. Ng and S. Winkler. A data-driven approach to cleaning large face datasets. In Image Processing (ICIP), 2014 IEEE International Conference on, pages 343–347. IEEE, 2014. 6
- [29] H. V. Nguyen and L. Bai. Cosine similarity metric learning for face verification. In ACCV, pages 709–720, 2010. 3
- [30] C. J. Parde, C. Castillo, M. Q. Hill, Y. I. Colon, S. Sankaranarayanan, J.-C. Chen, and A. J. O’Toole. Deep convolutional neural network features and the original image. arXiv:1611.01751, 2016. 3
- [31] O. M. Parkhi, A. Vedaldi, and A. Zisserman. Deep face recognition. In BMVC, volume 1, page 6, 2015. 1, 2, 3
- [32] G. Pereyra, G. Tucker, J. Chorowski, Ł. Kaiser, and G. Hinton. Regularizing neural networks by penalizing confident output distributions. arXiv:1701.06548, 2017. 3
- [33] R. Ranjan, C. D. Castillo, and R. Chellappa. L2- constrained softmax loss for discriminative face verification. arXiv:1703.09507, 2017. 3
- [34] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252, 2015. 7
- [35] F. Schroff, D. Kalenichenko, and J. Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, 2015. 1, 2, 5, 10
- [36] S. Sengupta, J.-C. Chen, C. Castillo, V. M. Patel, R. Chellappa, and D. W. Jacobs. Frontal to profile face verification in the wild. In WACV, pages 1–9, 2016. 5, 6
- [37] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 2
- [38] N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. Journal of machine learning research, 15(1):1929–1958, 2014. 8
- [39] Y. Sun, Y. Chen, X. Wang, and X. Tang. Deep learning face representation by joint identification-verification. In Advances in neural information processing systems, pages 1988–1996, 2014. 2
- [40] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In AAAI, pages 4278–4284, 2017. 2, 8
- [41] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015. 2
- [42] Y. Taigman, M. Yang, M. Ranzato, and L. Wolf. Deepface: Closing the gap to human-level performance in face verification. In CVPR, 2014. 1, 2
- [43] TencentAILab. Facecnn v1. 9/21/2017. 1, 2, 3, 4, 9
- [44] F. Wang, W. Liu, H. Liu, and J. Cheng. Additive margin softmax for face verification. In arXiv:1801.05599, 2018. 1, 2, 3, 4, 9
- [45] F. Wang, X. Xiang, J. Cheng, and A. L. Yuille. Normface: l 2 hypersphere embedding for face verification. arXiv:1704.06369, 2017. 3
- [46] Y. Wen, K. Zhang, Z. Li, and Y. Qiao. A discriminative feature learning approach for deep face recognition. In European Conference on Computer Vision, pages 499–515. Springer, 2016. 2, 3, 7
- [47] X. Wu, R. He, Z. Sun, and T. Tan. A light cnn for deep face representation with noisy labels. arXiv preprint arXiv:1511.02683, 2015. 1
- [48] D. Yi, Z. Lei, S. Liao, and S. Z. Li. Learning face representation from scratch. arXiv preprint arXiv:1411.7923, 2014.
- [49] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23(10):1499–1503, 2016. 7
- [50] X. Zhang, Z. Fang, Y. Wen, Z. Li, and Y. Qiao. Range loss for deep face recognition with long-tail. ICCV, 2017. 1, 2, 3
- [51] X. Zhang, X. Zhou, M. Lin, and J. Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. arXiv:1707.01083, 2017. 2

