

face recognition[Euclidean-distance-based loss][FaceNet]
本文来自《FaceNet: A Unified Embedding for Face Recognition and Clustering》。时间线为2015年6月。是谷歌的作品。
0 引言
虽然最近人脸识别领域取得了重大进展,但大规模有效地进行人脸验证和识别还是有着不小的挑战。Florian Schroff等人因此提出了FaceNet模型,该模型可以直接将人脸图片映射到欧式空间中。在该空间中,欧式embedding可以用平方的L2距离直接表示人脸的相似度:
- 相同ID的人脸距离较小;
- 不同ID的人脸距离较大。
也就是一旦如果是能直接映射到欧式空间中,那么如人脸识别,验证和人脸聚类都可以基于现有的标准方法直接用FaceNet生成的特征向量进行计算。
之前的人脸识别方法是在一个已知人脸ID数据集下,基于一个分类层训练深度网络,然后将中间的bottleneck层作为表征去做人脸识别的泛化(即基于训练集训练一个特征提取模型,然后将该模型,如sift一样在未知人脸甚至未知ID的人脸上提取特征)。此类方法缺点是间接性和低效性:
- 做预测的时候,期望bottleneck表征能够很好的对新人脸进行泛化;
- 通过使用该bottleneck层,每个人脸得到的特征向量维度是很大的(比如1k维)。虽然有工作基于PCA做特征约间,但是PCA是一个线性模型。
FaceNet使用训练后的深度卷积网络直接对嵌入向量进行优化,而不是如之前的DL方法一样去优化所谓的bottleneck层。FaceNet基于《Distance metric learning for large margin nearest neighbor classification》采用triplet loss进行训练,并输出只有128维的embedding向量。这里的triplet包含人脸三元组(即三张人脸图片\(a,b,c\),其中\(a,b\)是来自同一个ID的人脸,\(c\)是其他ID的人脸),loss的目的就是通过一个距离边际去划分正对和负样本。这里人脸图片是只包含人脸区域的图片块,并不需要严格的2D或者3D的对齐,只需要做尺度缩放和平移即可。
当然选择哪种triplet也是很重要的,受到《Curriculum learning》的启发,作者提出一个在线负样本挖掘策略,以此保证持续性增加网络训练过程中的困难程度(分类越是错误的,包含的修正信息越多)。为了提升聚类准确度,同时提出了硬正样本挖掘策略,以提升单人的embedding特征球形聚类效果(一个聚类簇就是一个人的多张人脸图片)。

正如图1所示,其中的阴影遮挡等对于之前的人脸验证系统简直是噩梦。
1 FaceNet
相似于其他采用深度网络的方法,FaceNet也是一个完全数据驱动的方法,直接从人脸像素级别的原始图像开始训练,得到整个人脸的表征。不使用工程化后的特征,作者暴力的通过一大堆标记人脸数据集去解决姿态,光照和其他不变性(数据为王)。本文中采用了2个深度卷积网络:
- 基于《Visualizing and understanding convolutional networks》的深度网络(包含多个交错的卷积层,非线性激活,局部响应归一化(local response normalizations)和最大池化层),增加了几个额外的1x1xd卷积层;
- 基于Inception模型。
作者实验发现这些模型可以减少20倍以上的参数,并且因为减少了FLOPS的数量,所以计算量也下降了。
FaceNet采用了一个深度卷积网络,这部分有2种选择(上述两种),整体结构如下图
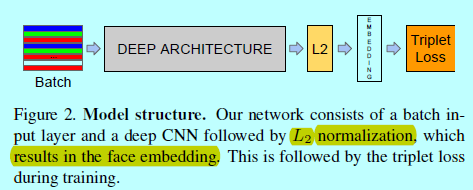
通过将深度卷积网络视为一个黑盒子,来进行介绍会更方便一些。整个FaceNet结构是end-to-end的,在结构的最后采用的itriplet loss,直接反映了人脸验证,识别和聚类所获取的本质。即获取一个embedding\(f(x)\),将一个图像\(x\)映射到特征空间\(R_d\)中,这样来自同一个ID的不同图像样本之间距离较小,反之较大。
这里采用Triplet loss是来自《Deep learning face representation by joint identification-verification》的灵感,相比而言,triplet loss更适合作为人脸验证,虽然前面《·》的loss更偏向一个ID的所有人脸都映射到embedding空间中一个点。不过triplet loss会增大不同ID之间的人脸边际,同时让一个ID的人脸都落在一个流行上。
1.1 triplet loss
embedding表示为\(f(x)\in R^d\)。通过将一个图片\(x\)嵌入到d维欧式空间中。另外,限制这个embedding,使其处在d维超球面上,即\(||f(x)||_2=1\)。这里要确保一个特定人的图片\(x_i^a\)(锚)和该人的其他图片\(x_i^p\)(正样本)相接近且距离大于锚与其他人的图片\(x_i^n\)(负样本)。如下图所示
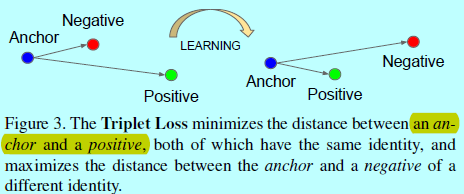
因此,符合如下形式:
这里\(\alpha\)是边际用于隔开正对和负对。\(T\)是训练集中所有可能的triplets,且其有\(N\)个候选三元组
这里loss可以写成如下形式:
基于所有可能的triplets组合,可以生成许多的triplet。这些triplet中有许多对网络训练没有什么帮助,会减慢网络的收敛所需时间,所以需要挑出那些信息量大的triplet组合。
1.2 triplet 选择
为了保证快速收敛,需要找到那些反模式的triplet,即给定\(x_i^a\),需要选择的\(x_i^p\)(硬正样本)能够满足\(\underset{x_i^p}{\arg max}||f(x_i^a)-f(x_i^p)||_2^2\),相似的,\(x_i^n\)(硬负样本)能够满足\(\underset{x_i^n}{\arg min}||f(x_i^a)-f(x_i^n)||_2^2\)。显然没法基于整个训练集计算\(\arg min\)和\(\arg max\)。而且,如一些误标记和质量不高的人脸图像也满足此类需求,而这些样本会导致训练引入更多噪音。这可以通过两个明显的选择避免此类问题:
- 每隔\(n\)步离线的生成triplets,使用最近的网络checkpoint,用其基于训练集的子集计算\(\arg min\),\(\arg max\);
- 在线生成triplet,这通过一个mini-batch内部选择硬正/负样本对来实现。
本文主要关注在线生成方式。通过使用一个包含上千个样本的大mini-batch去计算所需要的\(\arg min\),\(\arg max\)。而为了确保能计算到triplet,那么就需要训练使用的mini-batch中一定要包含(锚,正类,负类)样本。FaceNet的实验中,对训练数据集进行采样,如每个mini-batch中每个ID选择大概40个图片。另外在对每个mini-batch随机采样需要的负样本。
不直接挑选最硬的正样本,在mini-batch中会使用所有的(锚,正)样本对,同时也会进行负样本的选择。FaceNet中,并没有将所有的硬(锚,正)样本对进行比较,不过发现在实验中所有的(锚,正)样本对在训练的开始会收敛的更稳定,更快。作者同时也采用了离线生成triplet的方法和在线方法相结合,这可以让batch size变得更小,不过实验没做完。
在实际操作中,选择最硬的负样本会导致训练之初有较坏的局部最小,特别会导致形成一个折叠模型(collapsed model),即\(f(x)=0\)。为了减缓这个问题,即可以选择的负样本满足:
这些负样本称为”半硬(semi-hard)“,即虽然他们比正样本要远离锚,不过平方的距离是很接近(锚,正)样本对的距离的,这些样本处在边际\(\alpha\)内部。
如上所述,正确的triplets样本对的选择对于快速收敛至关重要。一方面,作者使用小的mini-batch以提升SGD的收敛速度;另一方面,仔细的实现步骤让batch是包含10或者百的样本对却更有效。所以主要的限制参数就是batch size。本实验中,batch size是包含1800个样本。
1.3 深度卷积网络
本实验中,采用SGD方式和AdaGrad方式训练CNN,在实验中,学习率开始设定为0.05,然后慢慢变小。模型如《Going deeper with convolutions》一样随机初始化,在一个CPU集群上训练了1k到2k个小时。在训练开始500h之后,loss的下降开始变缓,不过接着训练也明显提升了准确度,边际\(\alpha\)为0.2。如最开始介绍的,这里有2个深度模型的选择,他们主要是参数和FLOPS的不同。需要按照不同的应用去决定不同的深度网络。如数据中心跑的模型可以有许多模型,和较多的FLOPS,而运行在手机端的模型,就需要更少的参数,且要能放得下内存。所有的激活函数都是ReLU。
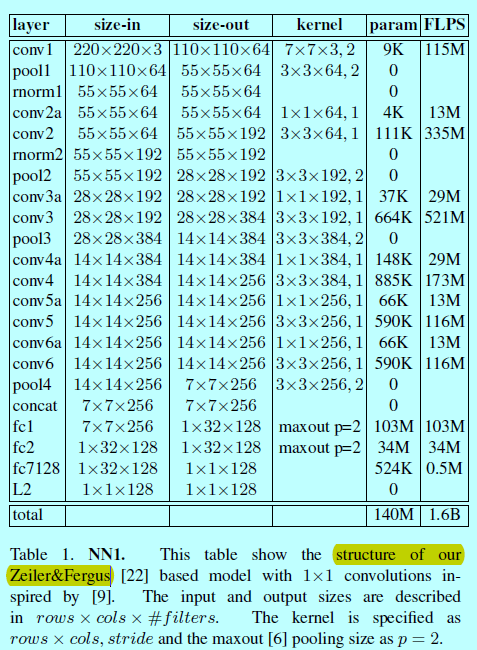
如表1中采用的是第一种方法,在标准的卷积层之间增加1x1xd的卷积层,得到一个22层的模型,其一共140百万个参数,每个图片需要1.6十亿个FlOPS的计算。
第二个策略就是GoogleNet,其相比少了20多倍的参数(大概6.6百万-7.5百万),且少了5倍的FLOPS(基于500M-1.6B)。所以这里的模型可以运行在手机端。如:
- NNS1只有26M参数量,需要220M FLOPS的计算;
- NNS2有4.3M参数量,且只需要20M FLOPS计算量。
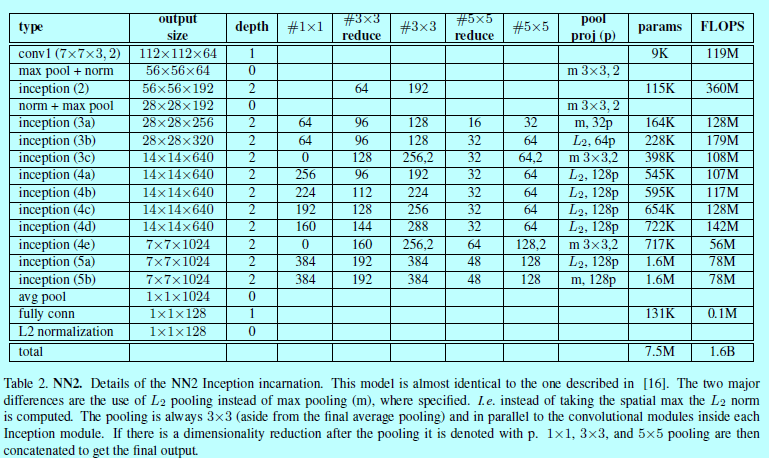
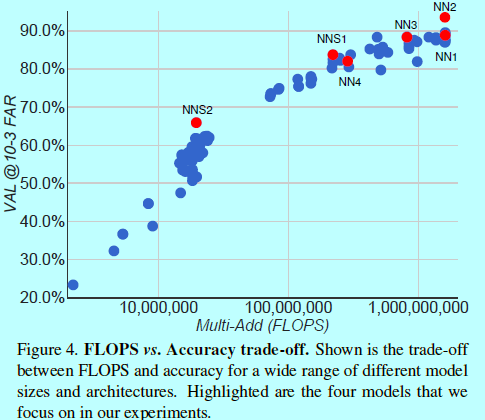
表2描述了NN2网络结构,NN3架构是一样的,只是输入层变成了160x160。NN4输入层只有96x96,因此需要更少的CPU计算量(285M的FLOPS,而NN2有1.6B)。另外,为了减少输入尺度,在高层网络层,也不使用5x5的卷积。而且实验发现移除了5x5的卷积,对最后结果没什么影响。如图4
2 实验及分析
......

