


face detection[PyramidBox]
本文来自《PyramidBox: A Context-assisted Single Shot Face Detector》,是来自百度的作品,时间线为2018年8月。
0 引言
最近基于锚的检测框架都是为了检测无约束条件下难检测的人脸,比如WIDER FACE,SSH,\(S^3FD\)等等都提出了尺度不变网络的单一网络结构,从不同的网络层获取不同的size来检测人脸。Face R-FCN重新权重化得分map上的响应值,并通过一个位置敏感平均池化消除不同人脸位置带来的非均匀分布影响。FAN提出一个锚级别的注意力机制,高亮人脸区域并检测遮挡的人脸。
虽然这些网络都提出一个设计锚的方法和对应网络去检测不同尺度的人脸,可是如何使用上下文信息去做人脸检测还是未被得到足够的重视,而这对于检测难检测的人脸而言却十分有帮助。如图1.

可以发现人脸从来都不是孤立存在于真实世界,通常会伴随肩膀或者身体,这在因为低分辨率,模糊和遮挡等场景下,人脸纹理不足以做判断的时候可提供丰富的上下文关联信息。这里作者通过引入一个上下文关联网络去使用上下文信息:
- 首先,网络应该学习不止人脸的特征,而且还有包含头和身体的上下文部分。为了达到这个目的,需要额外的标签,并且也需要设计对应的锚。本文中,作者使用了半监督方法去生成人脸上下文部分的相似标签和一系列锚,这里称其为Pyramid Anchors,且该锚也很容易加入到普通基于锚的结构中。
- 然后,high-level的上下文特征应该与low-level的特征适当结合起来。难检测和易检测的人脸外观通常是不同的,这意味着不是所有的high-level语义特征都对更小目标的检测有帮助。作者调研了特征金字塔网络(feature pyramid network)并将其修改为low-level特征金字塔网络(low-level feature pyramid network),以将相互有作用的特征聚合在一起。
- 预测的分支网络应该充分使用联合的特征。这里引入上下文敏感预测模块(context-sensitive prediction module,CPM)并与一个更宽更深的网络相结合,从而能够合并目标人脸周围的上下文信息。同时,在预测模块上提出一个max-in-out层,以此提升分类网络的能力。
- 提出一个训练策略叫data-anchor-sampling,调整了训练数据集上的分布。并通过数据增强的方式来增加难检测样本的多样性,以此获取更具表征的特征。
本文贡献:
- 提出一个基于锚的上下文辅助方法,PyramidAnchors,在为了检测小型,模糊和遮挡人脸上引入有监督信息去学习上下文特征;
- 设计一个low-level的特征金字塔网络,更好的融合上下文特征和人脸特征。同时提出的方法可以在单次前向传播中很好的处理不同尺度的人脸;
- 引入一个上下文敏感预测模块,由一个混合网络结构和max-in-out层组成,以从融合的特征中学习准确的位置和类别;
- 提出一个尺度敏感数据-锚-采样策略,改变训练样本的分布,更注重小型人脸;
- 在FDDB和WIDER FACE数据集上获得最好的效果。
1 结构
1.1 网络结构
基于锚的目标检测架构往往伴随着精妙的锚设计。同时大量的工作证明可以通过在不同层级的feature map上预测多尺度人脸。同时FPN结构着重将high-level特征与low-level特征相融合。如图2
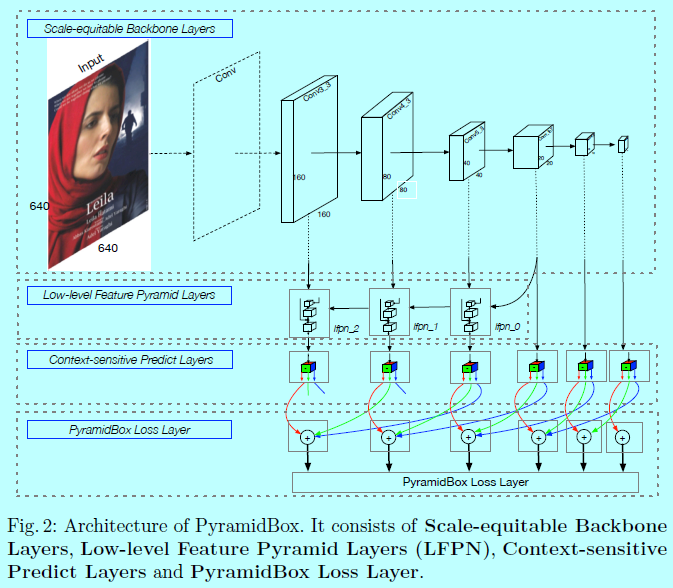
PyramidBox的结构也使用VGG16作为基底骨干网络,如\(S^3FD\)一样的锚尺度设计,即在不同层级上生成feature map和等比例间隔的锚。低层级FPN加在该基底骨干网络上,然后上下文敏感预测模块作为每个金字塔检测层的一个分支网络,从而得到最终的输出。关键在于作者设计了一个新颖的金字塔锚方法,能够在不同level的每个人脸上生成一系列锚。
尺度等同的基底网络层(Scale-equitable Backbone Layers)
这里使用\(S^3FD\)中的基底网络和额外卷积层作为本文中模型的基底层,保留了VGG的conv1_1到pool5,然后将fc6和fc7变成conv_fc层,然后增加额外的卷积层让整个网络变得更深。
低层级特征金字塔层(Low-level Feature Pyramid Layers)
为了提升人脸检测关于不同size人脸的效果,高分辨率的low-level特征扮演着十分重要的角色。因此别人的工作都在同一个网络结构中构建不同的子结构去检测不同尺度的人脸。其中high-level的特征被设计成检测大人脸,而low-level的特征可以检测小人脸。为了将high-level的语义特征融入高分辨率的low-level网络层中,FPN提出了一个自上而下结构,在所有的尺度(scale)上使用high-level语义feature map。近来,FPN类型的框架在目标检测和人脸检测上都获得了很好的反响。
几乎所有这种构建FPN的工作都开始于最顶层。当然不是所有high-level特征都有助于小型人脸的检测。
- 首先,人脸都是很小的,模糊的,遮挡的,不同于那些大的,清晰的,完整的人脸纹理。所以简单的直接将所有high-level特征拿去做小型人脸检测的辅助增强是不可取的;
- 其次,high-level特征部分基本没有了人脸纹理信息,同时还会引入噪音信息。例如,在本文的PyramidBox的基底层中,顶层两层conv7_2和conv6_2的感受野分别是724和468。注意到输入的训练图片大小是640,这意味着顶层两层包含太多噪音上下文特征,所以对于检测中型和小型人脸就没多大帮助。
作者建立了个低层级特征金字塔网络,从一个中间层开始构建一个自上而下的结构,其中感受野应该接近一半输入图片的size,而不是接近顶层的size。LFPN的每个块结构(和FPN中一样),如图3a。
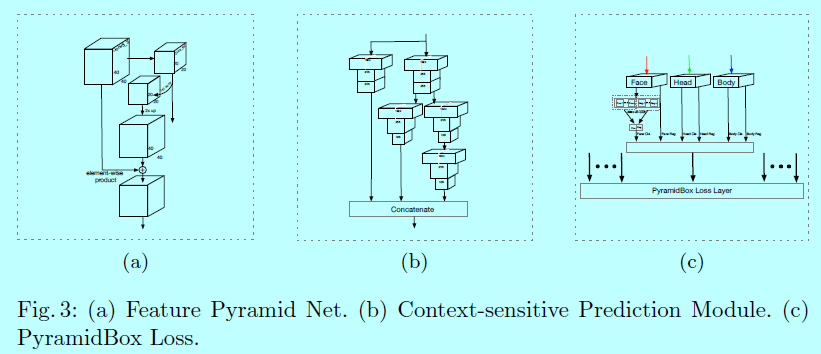
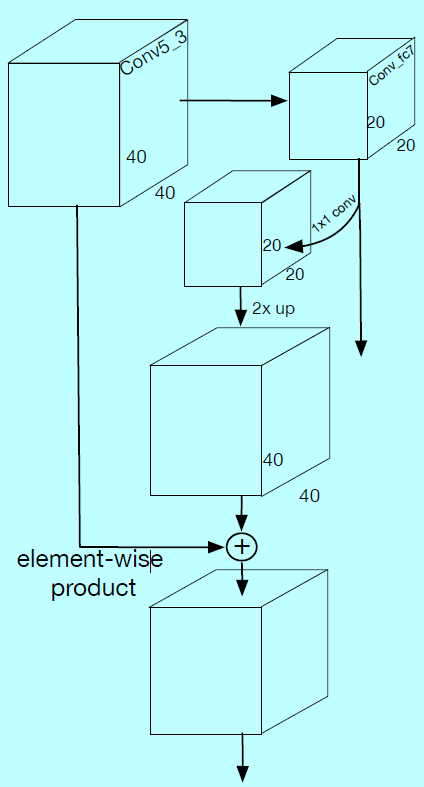
金字塔检测层(Pyramid Detection Layers)
这里选择lfpn_2,lfpn_1,lfpn_0,conv_fc7,conv6_2,conv7_2作为检测层,其中锚的size分别为16,32,64,128,256,512.这里lfpn_2,lfpn_1,lfpn_0都是LFPN基于conv3_3,conv4_3,conv5_3的输出层。相似于SSD结构,这里使用L2归一化缩放LFPN层的范数。
预测层(Predict Layers.)
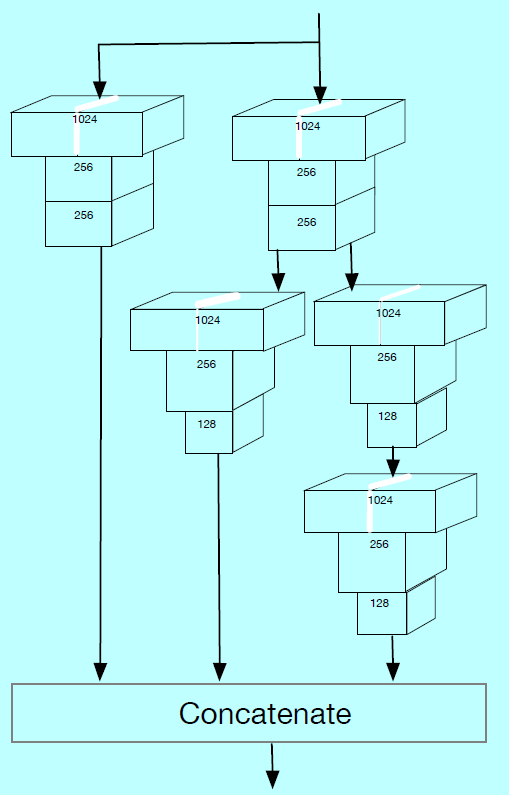
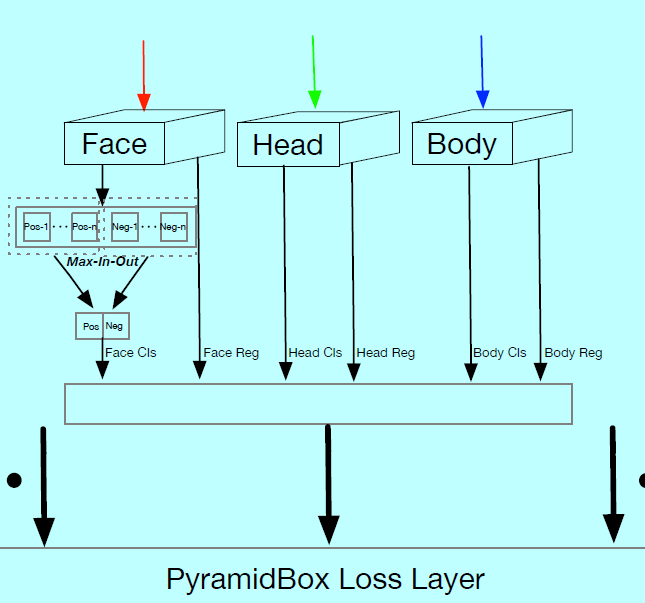
每个检测层后面跟一个上下文敏感预测模块(context-sensitive predict module,CPM),注意到CPM的输出是用来做监督金字塔锚(supervising pyramid anchors)的,而这近似覆盖一个人脸,头,身体区域。第\(l_{th}\)个CPM的输出尺寸是\(w_l\times h_l \times c_l\),这里\(w_l=h_l=640/2^{2+l}\)是对应的特征size,通道size\(c_l\)等于20(\(l=0,1,...5\))。每个通道的特征用来做人脸,头,身体的分类和回归,其中人脸的分类需要4(\(=cp_l+cn_l\))个通道,\(cp_l\)和\(cn_l\)是前景和背景的max-in-out,即:
而头和身体的分类需要2个通道(二分类),每个人脸,头,身体需要4个通道去定位(4个坐标)。
PyramidBox loss层
对于每个目标人脸,一系列金字塔锚同时去监督分类任务和回归任务。作者设计了一个金字塔loss,其中softmax loss做分类,平滑L1 loss做回归。
1.2 上下文敏感预测模块
预测模块
在最开始的基于锚的检测器中,如SSD和YOLO,其中的目标函数是直接基于选择的feature map上计算的,而如MS-CNN中所述,增强每个任务中的子网络可以提升准确度。近来的SSH通过在顶层放置一个不同stride的更宽卷积预测模块增大感受野。DSSD在每个预测模块上增加残差块。的确,SSH和DSSD可以让预测模块变得更深和更宽,所以预测模块在分类和定位上能得到更好的效果。
受到Inception-ResNet可以获得更深更宽的模型启发,因此设计上下文敏感预测模块,如图3b,其中将SSH中的上下文模块中的卷积层替换成DSSD中的residual-free预测模块。这可以让CPM获得所有DSSD模块的好处,同时保留SSH上下文模块中的上下文信息。
max-in-out
Maxout的概念首次是被GoodFellow提出的,\(S^3FD\)应用max-out背景标签去减少小的负样本的假阳性比例。在本文中,作者在正样本和负样本上都采用了该方法,称其为max-in-out,如图3c。首先对每个预测模型预测\(c_p+c_n\)得分,然后选择\(\max c_p\)作为正得分。相似的,选择\(\max c_n\)作为负得分。本实验中,因为小型人脸有更多完整的背景,第一个预测模块中\(c_p=1\),\(c_n=3\),而对于其他预测模块为了召回更多人脸,\(c_p=3\),\(c_n=1\)。
1.3 金字塔锚 PyramidAnchors
最近基于锚的目标检测和人脸检测获得了巨大成功,这证明了每个尺度上平衡的锚有助于检测小型人脸,但是在每个尺度上仍然忽略了上下文特征,因为所有的锚都设计用于人脸区域。为了解决该问题,作者提出了一个新的锚方法,叫做PyramidAnchors。
对于每个目标人脸,PyramidAnchros基于人脸周边(如头,肩膀和身体)包含上下文信息的区域生成一系列锚。作者在选定的网络层上设定一系列锚去匹配这些区域,其会监督higher-level网络层学习对lower-level尺度人脸具有更表征的特征。给定额外的头,肩膀和身体的标签,可以加速匹配ground-truth的锚生成loss。可是添加额外的标签也是很麻烦的,所以通过半监督的方式去实现。其中有个前提假设是:同样长宽比和偏移量的人脸区域拥有相似的上下文特征。
也就是说,我们可以使用一组统一的框来近似头部,肩部和身体的实际区域,只要这些框中的特征在不同的人脸之间是相似的。对于在原图中\(region_{target}\)区域上定位的目标人脸,考虑第\(i\)个特征层上第\(j\)个锚\(anchor_{i,j}\),其stride为\(s_i\),我们定义第\(k\)个金字塔锚的标签为:
这里\(k=0,1,...,K\),其中\(s_{pa}\)是金字塔锚的stride。\(anchor_{i,j}\cdot s_i\)表示锚\(anchor_{i,j}\)对应原图上的区域,\(anchor_{i,j}\cdot s_i/s_{pa}^k\)表示通过\(s_{pa}^k\)下采样的区域,其中threshold与其他基于锚的检测器值一样。同时下面会介绍PyramidBox的loss。
在本实验中,因为毗邻的预测模块的stride是2 所以\(s_{pa}=2\).且\(threshold=0.35,K=2\)。\(label_0\),\(label_1\),\(label_2\)分别是人脸,头和身体的标签。可以发现一个人脸会在三个连续的预测模块中生成3个目标,分别表示人脸本身,人脸对应的头和身体。图4 就是个例子
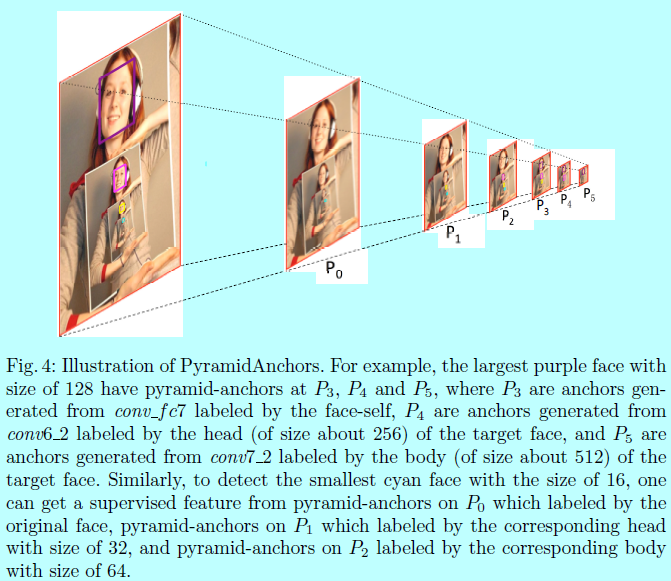
得益于PyramidBox,这里的人脸检测器可以更好的处理小的,模糊的,遮挡的人脸。而且这的金字塔锚是没有额外label的情况下自动生成的,这种半监督学习方法有助于PyramindAnchors提取近似的纹理特征。在预测阶段,只使用人脸分支网络的结果,所以也没有额外的计算代价。
1.4 训练
这里介绍下训练的数据集,数据增强,loss函数和其他细节
训练数据集
WIDER FACE,包含了颜色失真,随机裁剪,和水平翻转
data-anchor-sampling
数据采样是个经典的统计,机器学习,模式识别中的话题,近些年该方法也得到了广泛的关注。对于目标检测任务,Focus Loss通过reshap标准的交叉熵loss来解决类别不平衡的问题。
这里作者采用了一个数据增强采样方法叫做data-anchor-sampling。简单而言,该方法是通过reshape一个图片中的随机人脸到一个随机的更小的锚尺度。具体点,首先选择一个尺度为\(s_{face}\)的人脸,然后如之前提到的在PyramidBox中的锚尺度:
最后,resize 尺度为\(s_{face}\)的人脸到
因此,图片的resize尺度是
通过对图片进行\(s^*\)尺度的resize,然后随机的裁剪包含随机选定人脸的一个640x640的图片,就得到了一个锚采样的训练数据。例如,首先随机选定一个人脸,假设其size为140,然后选择最近的锚尺度,假设为128。然后从16,32,64,128,256中选择一个目标尺度。假设选择了32,那么缩放原图的尺度因子为32/140=0.2285。最后,从resize之后的图片中裁剪一个包含最初选定的人脸的640x640的图片块,这样就得到了采样的训练数据。
如图5所示,
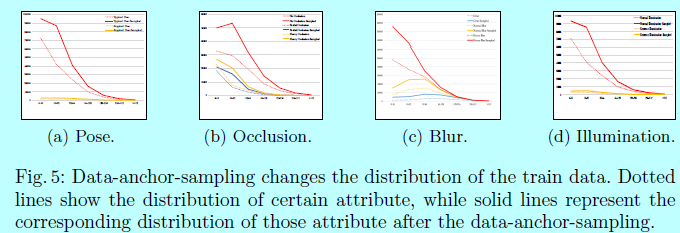
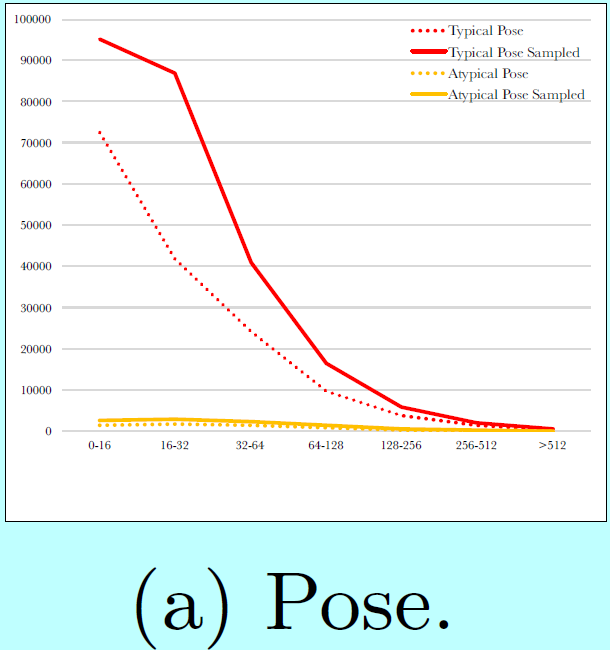
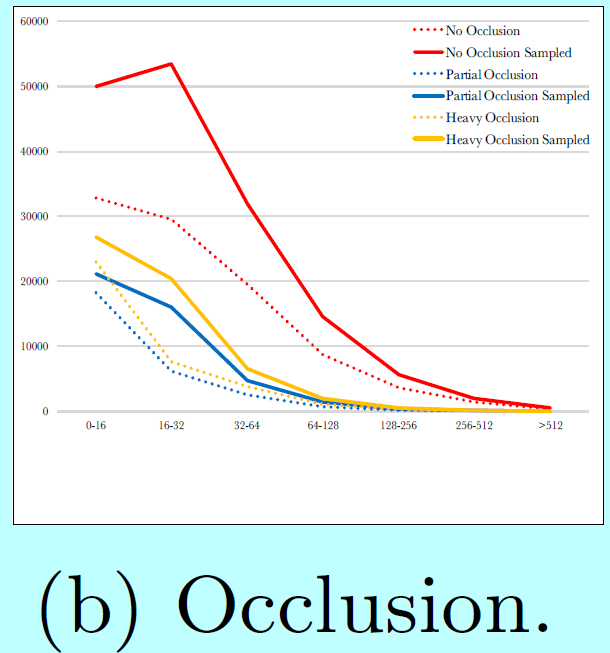
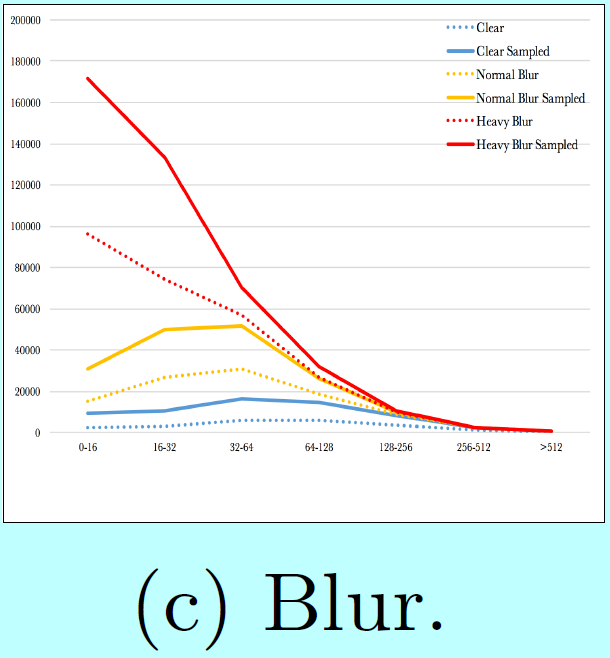
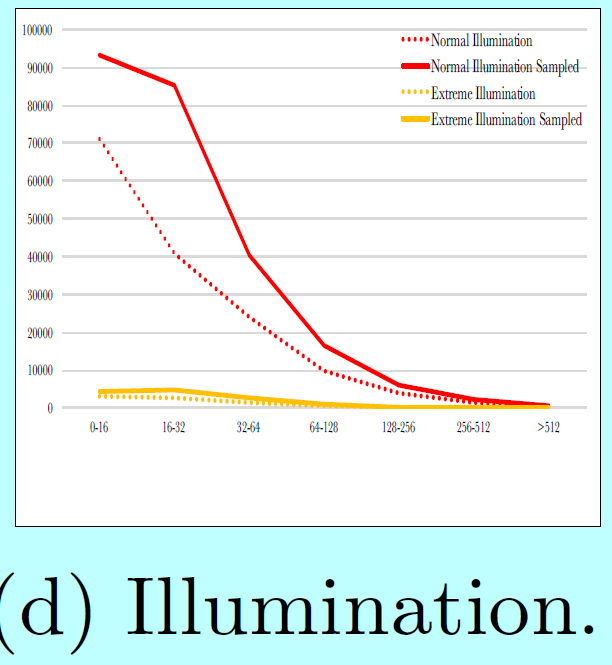
data-anchor-sampling改变了训练数据集的分布:
- 小型人脸的比例大于大型人脸的;
- 通过大型人脸中生成小型人脸,增加了更小尺度人脸样本的多样性
PyramidBox Loss
作为《Fastr-cnn》中多框损失的一个泛化方式,作者在每个图片上采用PyramidBox Loss,定义如下:
这里第\(k\)个金字塔锚loss的定义为:
这里\(k\)是金字塔锚的索引(k=0,1,2分别表示人脸,头和身体),\(i\)是锚的索引,\(p_{k,i}\)是第\(k\)个目标(人脸,头,身体)的第\(i\)个锚的预测概率。ground-truth标签定义为:
例如,当\(k=0\),这里的ground-truth 标签等于fast rcnn中的标签,而当\(k\geq 1\),可以通过介于下采样锚和ground-truth人脸之间的匹配来决定对应的标签。而且\(t_{k,i}\)是一个向量,对应预测边界框的4个参数化的坐标,\(k_{k,i}^*\)是关联正锚的ground-truth框,定义为:
这里\(\Delta_{x,k}\)和\(\Delta_{y,k}\)是偏移的偏移量,\(s_{w,k}\)和\(s_{h,k}\)是关于宽度和高度的缩放因子。本文中
- 当\(k<2\)时,\(\Delta_{x,k}=\Delta_{y,k}=0\),\(s_{w,k}=s_{h,k}=1\);
- 当\(k=2\)时,\(\Delta_{x,2}=0, \Delta_{y,2}=t_h^*\),\(s_{w,2}=\frac{7}{8},s_{h,2}=1\)
分类loss\(L_{k,cls}\)是基于二分类的log loss(有人脸还是没有人脸),回归分类\(L_{k,reg}\)是平滑L1 loss,与《Faster-cnn》中定义的一样。这里\(p_{k,i}^*L_{k,reg}\)表示只由正锚激活的回归loss。这两项分别被\(N_{k,cls}\)和\(N_{k,reg}\)所归一化,且通过\(\lambda\)和\(\lambda_k\)进行平衡,其中\(k=0,1,2\)
优化
正如参数初始化,PyramidBox使用VGG16预训练的参数,其中conv_fc67和conv_fc7是通过VGG16的fc6和fc7进行子采样得到的,其他层是通过xavier方式随机初始化。一共迭代120k次,前80k次学习率为0.001,后20k次学习率为0.0001,接着20k次学习率为0.00001,batchsize为16其中动量为0.9,权重衰减超参数为0.0005。
.

