
正则表达式
一、概述
1.概念
- 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成串”,这个 “规则字符串” 用来表达对字符串的一种过滤逻辑。
2.目的
给定一个正则表达式和另—个字符串,我们可以达到如下的目的:
- a.给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
例如:邮箱匹配,电话号码匹配
- b.可以通过正则表达式,从字符串中获取我们想要的特定部分。
爬虫中解析html数据
3.特点
- a.灵活性、逻辑性和功能性非常的强;
- b.可以迅速地用极简单的方式达到字符串的复杂控制。
- c.对于刚接触的人来说,比较晦涩难懂。
4.学习方法
- a.做好笔记,不要死记硬背
- b.大量练习
python 中通过系统库 re 实现 正则表达式 的所有功能
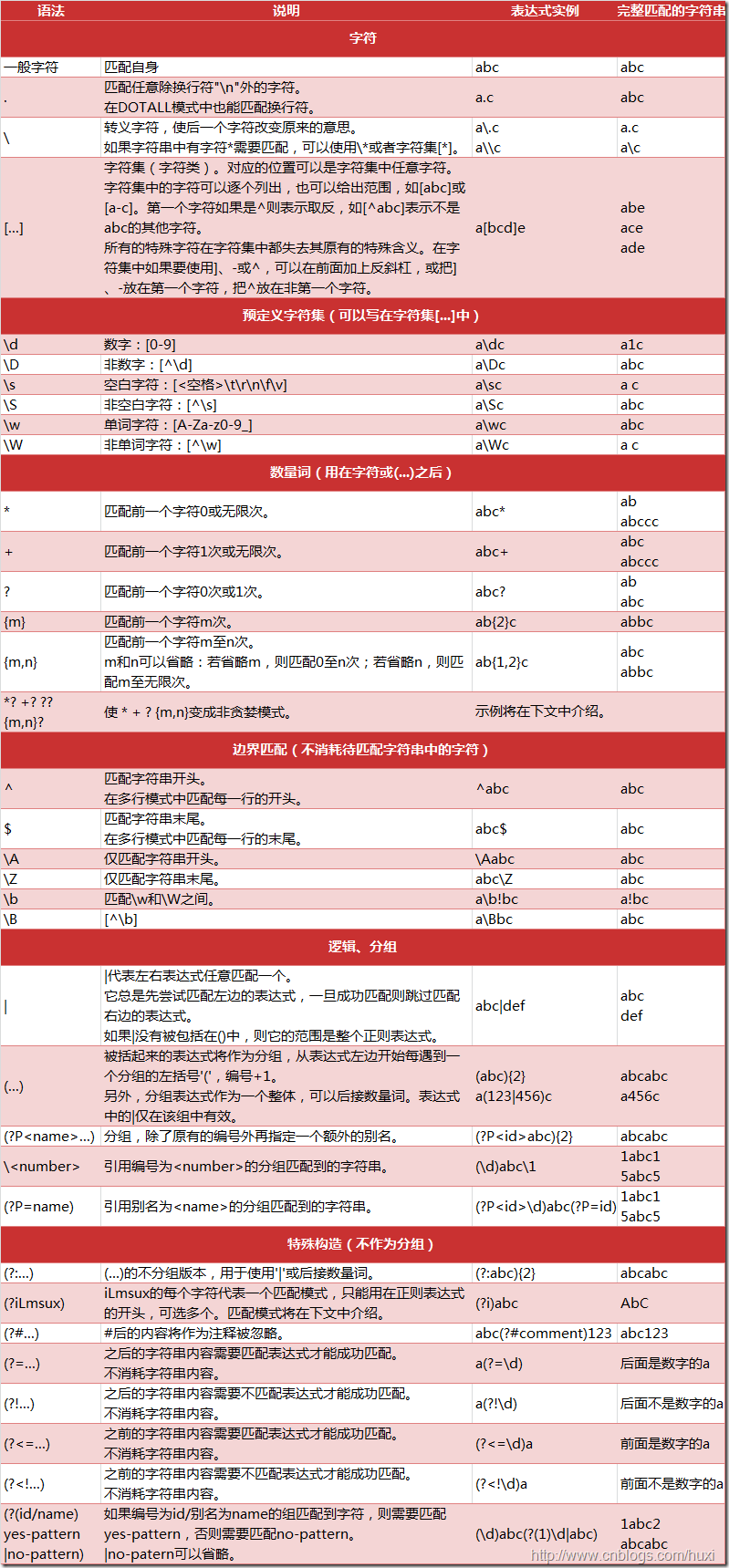
二、正则表达式符号
1.普通字符
下面的案例使用 re 模块的 findall() 函数,函数参考如下:
- re.findall(pattern, string, flag)
- 在字符串中找到正则表达式所匹配的所有子串,并返回列表,如果没有找到返回空列表
- pattern : 正则表达式
- string:被匹配的字符串
- flag:标志位用来控制正则表达式匹配方式
在最简单的情况下,一个正则表达式看上去就是一个普通的查找串
import re s1 = "testing123" s2 = "Testing123" r = re.findall("test", s1) # 表示在s1中找到字符串 "test" print(r) # 结果:['test'] r1 = re.findall("test", s2) # 默认情况下大小写敏感 print(r1) # 结果:[] r2 = re.findall("test", s2, re.I) # 修饰符re.I :使匹配对大小写不敏感(ignore) print(r2) # 结果:['Test']
2.元字符
- . ” $ * + ? { } [ ] | ( ) \
2.1通配符.
默认情况下匹配除 \n (换行符)之外的任何单个字符,依次匹配
import re s1 = "testing123" s2 = "testing123\n" s3 = "马保国" r = re.findall(".", s1) # 表示在s1中找到字符串 "." print(r) # 结果:['t', 'e', 's', 't', 'i', 'n', 'g', '1', '2', '3'] r1 = re.findall(".", s2) # 除"\n",换行不匹配 print(r1) # 结果:['t', 'e', 's', 't', 'i', 'n', 'g', '1', '2', '3'] r2 = re.findall("..", s1) # 匹配两个字符 print(r2) # 结果:['te', 'st', 'in', 'g1', '23'] r3 = re.findall("马..", s3) # 匹配两个字符 print(r3) # 结果:['马保国']
修饰符 re.S 使 "." 匹配包括换行在内的所有字符
r4 = re.findall(".", s2, re.S) # 同 re.DOTALL print(r4) # 结果:['t', 'e', 's', 't', 'i', 'n', 'g', '1', '2', '3', '\n']
2.2 脱字符 ^
匹配输入字符串的开始位置
s1 = "testing\nTesting\ntest" r = re.findall("^test", s1) # 匹配开始是否是 test,默认只匹配单行 print(r) # 结果:['test'] r_1 = re.findall("t", s1, re.I) # 所有的 t print(r_1) # 结果:['t', 't', 'T', 't', 't', 't'] r_2 = re.findall("^t", s1, re.I) # 字符串开始的 t print(r_2) # 结果:['t']
修饰符 re.M 表示 ^ 可以多行匹配
r1 = re.findall("^test", s1, re.M) # 修饰符re.M:多行匹配 print(r1) # 结果:['test', 'test']
"|"可以将多个修饰符结合起来使用
r2 = re.findall("^test", s1, re.I | re.M) print(r2) # 结果:['test', 'Test', 'test']
2.3 美元符 $
匹配输入字符串的结束位置
s4 = "testtesting\ntestTesting\ntest" r = re.findall("testing$", s4) # 默认匹配单行 print(r) # 输出:[] r1 = re.findall("testing$", s4, re.M) # 修饰符re.M:多行匹配 print(r1) # 输出:['testing’] r2 = re.findall("testing$", s4, re.I | re.M) # 多个修饰符通过oR(|)来指定 print(r2) # 输出:['testing', 'Testing']
2.4 重复元字符 *,+,?
- * 匹配前面的子表达式任意次
- +匹配前面的子表达式一次或多次(至少一次)
- ? 匹配前面的子表达式 0次 或 1次
import re s1 = "z\nzo\nzoo" r = re.findall("zo*", s1) # 匹配o{0,},逗号后不能空格 r1 = re.findall("zo{0,}", s1) print(r) # 输出:['z', 'zo', 'zoo’] print(r1) # 输出:['z', 'zo', 'zoo'] r2 = re.findall("zo+", s1) # 匹配o,一次或多次{1,} r3 = re.findall("zo{1,}", s1) print(r2) # 输出:['zo', 'zoo’] print(r3) # 输出:['zo', 'zoo'] r4 = re.findall("zo{2}", s1) # 匹配o,2次 print(r4) # 输出:['zoo'] s = 'zozozozo!' r5 = re.findall('(?:zo)+', s) # 匹配zo,?:zo后面代表整体;没有 ?:只返回括号里面的 print(r5) # 输出:['zozozozo']
2.5 重复元字符 { }
也是控制匹配前面的子表达式次数
import re s1 = "z\nzo\nzoo" r = re.findall("zo*", s1) # 匹配o{0,},逗号后不能空格 r1 = re.findall("zo{0,}", s1) print(r) # 输出:['z', 'zo', 'zoo’] print(r1) # 输出:['z', 'zo', 'zoo'] r2 = re.findall("zo+", s1) # 匹配o,一次或多次{1,} r3 = re.findall("zo{1,}", s1) print(r2) # 输出:['zo', 'zoo’] print(r3) # 输出:['zo', 'zoo'] r4 = re.findall("zo{2}", s1) # 匹配o,2次 print(r4) # 输出:['zoo']
2.6字符组 [ ]
表示匹配给出的任意字符
import re s1 = "test\nTesting\nzoo" r = re.findall("[eio]", s1) # 匹配包含的任意字符 print(r) # 结果:['e', 'e', 'i', 'o', 'o'] r = re.findall("[e-o]", s1) # 匹配包含的字符范围 print(r) # 结果:['e', 'e', 'i', 'n', 'g', 'o', 'o'] r1 = re.findall("[0-9]", "ab1234de554") # 匹配包含的字符范围 print(r1) # 结果:['1', '2', '3', '4', '5', '5', '4'] r = re.findall("^[eio]", s1, re.M) # re.M:多行匹配,回忆脱字符,匹配以[eio]开头字符。 print(r) # 结果:[] # 脱字符^放到里面组合,表示排除给定字符串 r = re.findall("[^estio]", s1) # 匹配未包含的任意字符 print(r) # 结果:['\n', 'T', 'n', 'g', '\n', 'z']
2.7选择元字符 |
表示两个表达式选择一个匹配
import re s1 = "z\nzood \nfood" r = re.findall("z |food", s1) # 匹配"z"或"food" print(r) # 结果:['food'] r = re.findall("[z|f]ood", s1) # 匹配"zood"或"food" print(r) # 结果:['zood', 'food']
2.8分组元字符()
将括号之间的表达式定义为组(group),并且将匹配这个子表达式的字符返回
import re s1 = "z\nzood\nfood" r = re.findall("[zlf]o*", s1) # 不加分组,拿到的引号内正则表达式匹配到的字符 print(r) # 结果:['z', 'zoo', 'foo'] r = re.findall("[z/f](o*)", s1) # 加上分组,返回的将是引号内正则表达式匹配到的字符中()中的内容 print(r) # 结果:['', 'oo', 'oo']
2.9 转义元字符 \
用来匹配元字符本身时的转义,和特定字符组成字符串,见预定义字符组
import re s = '12345@qq.com' r= re.findall('\.', s) print(r) # 结果:['.']
2.10 非贷婪模式
在默认情况下,元字符 *, + 和 {(n,m} 会尽可能多的匹配前面的子表达式,这叫贪婪模式。
import re s = "abcadcaec" r = re.findall(r"ab.*c", s) # 贪婪模式,尽可能多的匹配字符(.*或者.+) print(r) # 结果:['abcadcaec'] # 当在这些元字符后面加上?时,表示非贪婪,即尽可能少的匹配前面的子表达式 r = re.findall(r"ab.*?c", s) # 非贪婪模式,尽可能少的匹配字符 print(r) # 结果:['abc'] r = re.findall('ab.+c', s) # 贪婪 print(r) # 结果:['abcadcaec'] r = re.findall('ab.+?c', s) # 非贪婪 print(r) # 结果:['abcadc'] r = re.findall('ab.{0,}', s) # 贪婪 print(r) # 结果:['abcadcaec'] r= re.findall('ab.{0,}?', s) # 非贪婪 print(r) # 结果:['ab']
3.预定义字符组
元字符 \ 与某些字符组合在一起表示特定的匹配含义
3.1 1 \d
匹配单个数字,等价于[0-9]
s = "<a href=' asdf’>1360942725</a>" a = re.findall('\d', s) print(a) # 结果:['1', '3', '6', '0', '9', '4', '2', '7', '2', '5'] a= re.findall('\d+', s) print(a) # 结果:['1360942725']
3.2 \D
匹配任意单个非数字字符,等价于[0-9]
s = "<a href=' asdf’>1360942725</a>" a = re.findall('\D', s) print(a) # 结果:['<', 'a', ' ', 'h', 'r', 'e', 'f', '=', "'", ' ', 'a', 's', 'd', 'f', '’', '>', '<', '/', 'a', '>']
3.3 \s
匹配任意单个空白符,包括空格,制表符(tab),换行符等
s = 'fdfa**68687+我怕n fdgltf_d\n' a = re.findall('\s', s) print(a) # 结果:[' ', '\n']
3.4 \S
匹配任何非空白字符
s ='fdfa**68687+我怕n fdg\tf_d\n' a = re.findall('\S', s) print(a) # 结果:['f', 'd', 'f', 'a', '*', '*', '6', '8', '6', '8', '7', '+', '我', '怕', 'n', 'f', 'd', 'g', 'f', '_', 'd']
3.5 \w
匹配除符号外的单个字母,数字,下划线或汉字等
s ='fdfa**68687+我怕n fdg\tf_d\n' a = re.findall("\w", s) print(a) # 结果:['f', 'd', 'f', 'a', '6', '8', '6', '8', '7', '我', '怕', 'n', 'f', 'd', 'g', 'f', '_', 'd']
3.5 \W
匹配符号
s ='fdfa**68687+我怕n fdg\tf_d\n' a = re.findall("\w", s) print(a) # 结果:['f', 'd', 'f', 'a', '6', '8', '6', '8', '7', '我', '怕', 'n', 'f', 'd', 'g', 'f', '_', 'd']
小案例
1.检测邮箱
s = "3003756995@qq.com" a = re.findall('^\w+@\w+\.com$', s) if a: print('s=是正确格式的邮箱') else: print('s!=不是邮箱地址')
2.检测手机号
s = "13854467878" a = re.findall('^1[3-9]\d{9}$', s) if a: print('手机号格式正确') else: print('手机号不格式正确')
4. re 模块常用函数
- re.matc
- re.search
- re.sub
- re.findall
- re.compile
正则表达式是什么
- 是一串描述文本规则的代码
- 对文本的搜索、替换、校验,非常复杂的字符
- 可以进行参数化
- 任何编程语言基本上都支持正则表达式
- 绝对大多数的编辑器都是支持正则表达式
1. 可以在下面的网址对正则进行练习
在线正则表达式解析:https://regexper.com/
正则表达式在线测试:https://regex101.com/
2. 匹配单个字符
. : 匹配任意1个字符(除了\n)
[ ] : 匹配【】中列举的字符
\d : 匹配数字,0-9
\D : 匹配非数字,即不是数字
\s : 匹配空白,即 空格,tab 键
\S : 匹配非空白
\w : 匹配单词字符,即a-z、A-Z、0-9、-
\W : 匹配非单词字符
3. 匹配多个字符
* : 匹配前一个字符出现0 次或者 无限次,即可有可无
+ : 匹配前一个字符出现1次 或者 无限次,即至少有1 次
? : 匹配前一个字符出现 1 次 或者0 次,即 要么1次,要么没有
{m} : 匹配前一个字符出现 m 次
{m,n} : 匹配前一个字符出现 从m到n次;例如:/o{2,3}
*******请大家尊重原创,如要转载,请注明出处:转载自:https://www.cnblogs.com/shouhu/ 谢谢!!*******

 浙公网安备 33010602011771号
浙公网安备 33010602011771号