

Solr 10 - SolrCloud集群模式简介 + 组成结构的说明
1 什么是SolrCloud
SolrCloud是基于Solr和ZooKeeper的分布式搜索方案, 主要通过ZooKeeper作为集群的配置信息中心.
当你需要处理大规模数据的搜索, 并需要提供高可用、容错等方面的支持, 且具有分布式索引和检索能力的服务时, 可以考虑使用SolrCloud.
SolrCloud有下述特色:
(1) 集中式的配置信息;
(2) 自动容错;
(3) 近实时搜索;
(4) 查询时自动负载均衡.
2 SolrCloud的结构
SolrCloud为了降低单机的处理压力, 需要由多台服务器共同完成索引和搜索任务. 实现思路是将索引数据进行Shard(分片)拆分, 每个分片由多台服务器共同完成, 当客户端发起一个索引或搜索请求时, 并行地由各个Shard服务器进行相关的索引操作, 然后返回总的结果集.
SolrCloud需要多台服务器, 配置文件较多, 因而交由ZooKeeper协调管理SolrCloud.
下图是一个SolrCloud应用的例子, 以此图为例说明SolrCloud的结构:
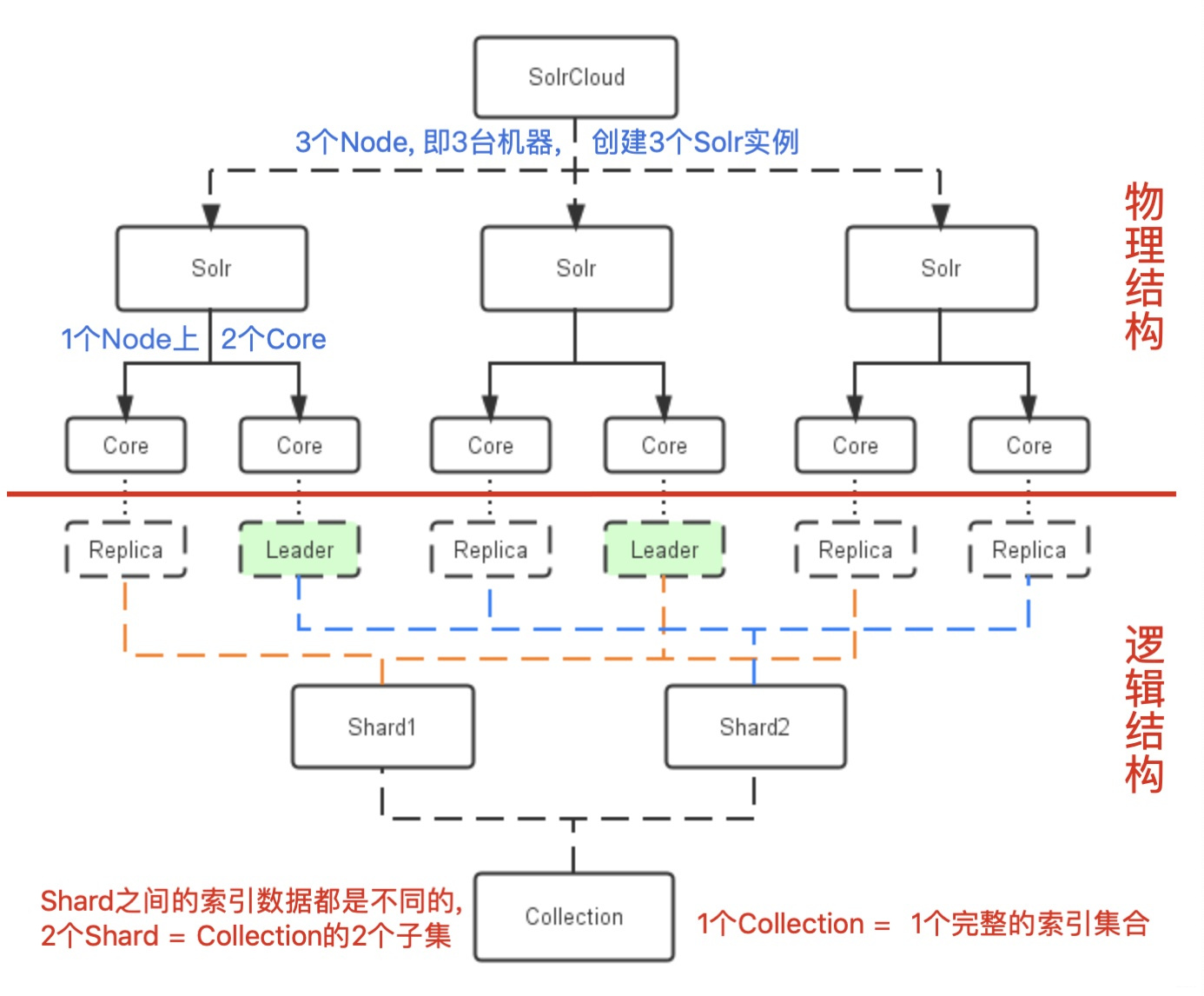
2.1 物理结构
三台服务器(或同一服务器, 通过伪集群的方式提供服务)用来部署Solr实例, 每个实例包括两个Solr Core(包括完整的索引和检索服务), 组成一个SolrCloud.
(1) Cluster(集群):
Cluster是一组Solr节点, 逻辑上作为一个单元进行管理, 整个集群必须使用同一套schema.xml和solrconfig.xml文件.
(2) Node(节点):
一个运行Solr的JVM实例.
2.2 逻辑结构
索引集合包括两个Shard(Shard1和Shard2), Shard1和Shard2分别由三个Core组成, 其中一个Leader两个Replication, Leader是由ZooKeeper选举产生, ZooKeeper负责每个Shard上三个Core的索引数据的一致性, 解决高可用问题.
用户发起的索引请求将分别从Shard1和Shard2上并行获取, 解决高并发问题.
2.2.1 Collection(集合)
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引;
常常被划分为一个或多个Shard(分片), 可以跨Node, 这些Shard使用相同的Config Set(配置信息);
如果Shard数超过一个, 这样的索引方案就是分布式索引.
用户通过Collection名称引用它,这样用户不需要关心分布式检索时需要使用的和Shard相关参数。
SolrCloud允许客户端通过Collection作为集群的访问入口, 用于区分不同的索引库 ---- 用户就不需要关心分布式检索时Shard等参数.
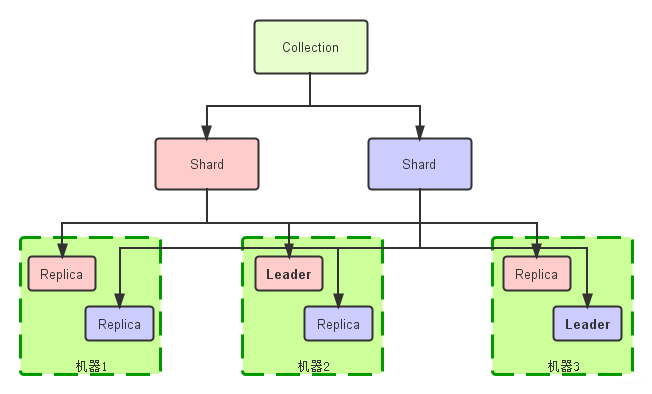
2.2.2 Core(内核)
Core是Solr中独立运行的单位, 独立提供索引和搜索服务:
在SolrCloud模式下, 同一Collection的所有Core的配置都相同;
一个Shard由一个(或多个)Core组成, 类似于collection_shard1_replica2;
Collection一般由多个Shard组成 ==> Collection一般由多个Core组成;
Core承担 Leader或Replica角色, 是由Solr内部自动协调决定的.
2.2.3 Shard(分片)
Shard是Collection的逻辑分片, 可以跨Node.
每个Shard被分为一个或多个Replica(副本), 通过选举确定哪个是Leader:
1个Shard可以有1个或多个Replica;
1个Shard有且只能有一个Leader;
Leader是某个活跃的Replica, 如果Leader宕机, Solr内部会发起选举, 从活跃的Replica中选出一个作为新的Leader.
各个Shard中存储的数据是互不重复的, 即它们的交集为空;
所有Shard的并集 == Collection中的所有文档;
同一Shard下的Replica(包括Leader)存储的数据相同, 即冗余副本, 提供高可用.
2.2.4 Replica(副本)
是Shard的一个拷贝, Replica都存在于Solr的某一个Core中.
即: 一个Solr Core对应着一个Replica.
举个例子🌰:
如一个命名为"test"的collection, 创建时指定
numShards=1&replicationFactor=2;
这会产生2个Replica, 对应2个Core, 分别存储在不同的机器或Solr实例上;
其中一个被命名为test_shard1_replica1, 另一个命名为test_shard1_replica2, 他们中的一个会被选举为Leader.
2.2.5 Leader(主节点)
在SolrCloud中没有Master/Slave, 即主/从节点的说法, 它的每个Shard至少包含一个物理副本, 其中一个作为Leader.
Leader是自动选出的 —— 由ZooKeeper根据先到先得的方式选出.
选举可以发生在任何时间, 但通常只在某个Solr实例发生故障时才会触发. 如果Leader挂掉, 该Shard的某一个副本将自动当选为新的Leader.
2.2.6 Config Set(配置集合)
Config Set是Solr Core必须提供的一组配置文件, 每个Config Set有一个名字, 至少需要包括solrconfig.xml和schema.xml文件.
除此之外, 依据这两个文件的配置内容, 可能还需要包含其它文件, 如从其他数据源导入数据的文件.
Config Set的更新:
① Config Set存储在ZooKeeper中, 可以重新上传或使用upconfig命令进行更新;
② 可使用Solr的启动参数bootstrap_confdir进行初始化或更新.
参考
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号