

Lucene 02 - Lucene的入门程序(Java API的简单使用)
1 准备环境
JDK: 1.8.0_162
IDE: Eclipse Neon.3
数据库: MySQL 5.7.20
Lucene: 4.10.4(已经很稳定了,高版本对部分分词器支持不好)
2 准备数据
SET FOREIGN_KEY_CHECKS=0;
--------------------------------
Table structure for `book`
--------------------------------
DROP TABLE IF EXISTS `book`;
CREATE TABLE `book` (
`id` int(11) DEFAULT NULL,
`bookname` varchar(500) DEFAULT NULL,
`price` float DEFAULT NULL,
`pic` varchar(200) DEFAULT NULL,
`bookdesc` varchar(2000) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--------------------------------
Records of book
--------------------------------
INSERT INTO `book` VALUES ('1', 'java从入门到精通', '56', '1.jpg', '《Java从入门到精通》是人民邮电出版社于 2010年出版的图书, 由国家863中部软件孵化器主编. 以零基础讲解为宗旨, 深入浅出地讲解Java的各项技术及实战技能. 本书从初学者角度出发, 通过通俗易懂的语言、丰富多彩的实例, 详细介绍了使用Java语言进行程序开发应该掌握的各方面技术.');
INSERT INTO `book` VALUES ('2', 'java web开发', '80', '2.jpg', 'Java Web, 是用Java技术来解决相关web互联网领域的技术总和. web包括: web服务器和web客户端两部分. Java在客户端的应用有java applet, 不过使用得很少, Java在服务器端的应用非常的丰富, 比如Servlet, JSP和第三方框架等等. Java技术对Web领域的发展注入了强大的动力. ');
INSERT INTO `book` VALUES ('3', 'lucene从入门到精通', '100', '3.jpg', '本书总结搜索引擎相关理论与实际解决方案, 并给出了 Java 实现, 其中利用了流行的开源项目Lucene和Solr, 而且还包括原创的实现. 本书主要包括总体介绍部分、爬虫部分、自然语言处理部分、全文检索部分以及相关案例分析. 爬虫部分介绍了网页遍历方法和如何实现增量抓取, 并介绍了从网页等各种格式的文档中提取主要内容的方法.');
INSERT INTO `book` VALUES ('4', 'lucene in action', '90', '4.jpg', '本书深入浅出地介绍了lucene——一个开源的使用java语言编写的全文搜索引擎开发包. 它通过浅显的语言、大量的图注、丰富的代码示例, 以及清晰的结构为读者呈现出作为优秀开源项目的lucene所体现的强大功能. ');
INSERT INTO `book` VALUES ('5', 'Lucene Java精华版', '80', '5.jpg', '本书总结搜索引擎相关理论与实际解决方案, 并给出了 Java 实现, 其中利用了流行的开源项目Lucene和Solr, 而且还包括原创的实现. 本书主要包括总体介绍部分、爬虫部分、自然语言处理部分、全文检索部分以及相关案例分析. 爬虫部分介绍了网页遍历方法和如何实现增量抓取, 并介绍了从网页等各种格式的文档中提取主要内容的方法. ');
3 创建工程
3.1 创建Maven Project(打包方式选jar即可)
3.2 配置pom.xml, 导入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.healchow</groupId>
<artifactId>lucene-first</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>lucene-first</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- mysql版本 -->
<mysql.version>5.1.44</mysql.version>
<!-- lucene版本 -->
<lucene.version>4.10.4</lucene.version>
</properties>
<dependencies>
<!-- mysql数据库依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- lucene依赖包 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
4 编写基础代码
4.1 编写图书POJO
public class Book {
private Integer id; // int(11) DEFAULT NULL,
private String bookname; // varchar(500) DEFAULT NULL,
private Float price; // float DEFAULT NULL,
private String pic; // varchar(200) DEFAULT NULL,
private String bookdesc; // varchar(2000) DEFAULT NULL
// Getters/Setters
@Override
public String toString() {
return "Book [id=" + id + ", bookname=" + bookname +
", price=" + price + ", pic=" + pic +
", bookdesc=" + bookdesc + "]";
}
}
4.2 编写图书DAO接口
public interface BookDao {
/**
* 查询全部图书
*/
List<Book> queryBookList();
}
4.3 实现图书DAO接口
public class BookDaoImpl implements BookDao {
/**
* 查询全部图书
*/
public List<Book> listAll() {
// 创建图书结果集合List
List<Book> books = new ArrayList<Book>();
Connection conn = null;
PreparedStatement preStatement = null;
ResultSet resultSet = null;
try {
// 加载驱动
Class.forName("com.mysql.jdbc.Driver");
// 创建数据库连接对象
conn = DriverManager.getConnection(
"jdbc:mysql://127.0.0.1:3306/lucene?useSSL=true",
"root",
"password");
// 定义查询SQL
String sql = "select * from book";
// 创建Statement语句对象
preStatement = conn.prepareStatement(sql);
// 执行语句, 得到结果集
resultSet = preStatement.executeQuery();
// 处理结果集
while (resultSet.next()) {
// 创建图书对象
Book book = new Book();
book.setId(resultSet.getInt("id"));
book.setBookname(resultSet.getString("bookname"));
book.setPrice(resultSet.getFloat("price"));
book.setPic(resultSet.getString("pic"));
book.setBookdesc(resultSet.getString("bookdesc"));
// 将查询到的结果添加到list中
books.add(book);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放资源
try {
if (null != conn) conn.close();
if (null != preStatement) preStatement.close();
if (null != resultSet) resultSet.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return books;
}
/**
* 测试功能的主方法
*/
public static void main(String[] args) {
// 创建图书Dao的实现对象
BookDao bookDao = new BookDaoImpl();
List<Book> books = bookDao.listAll();
// 如果结果不为空, 则便利输出
for (Book book : books) {
System.out.println(book);
}
}
}
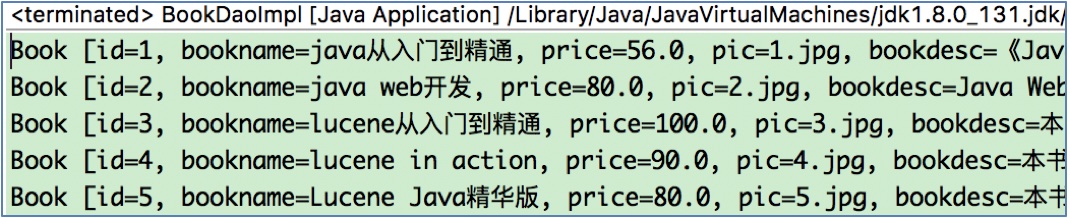
测试结果如下:
5 索引流程的实现
(1) 采集原始数据;
(2) 创建文档对象(Document);
(3) 创建分析器对象(Analyzer), 用于分词;
(4) 创建索引配置对象(IndexWriterConfig), 用于配置Lucene;
(5) 创建索引库目录位置对象(Directory), 指定索引库的存储位置;
(6) 创建索引写入对象(IndexWriter), 将文档对象写入索引库;
(7) 使用IndexWriter对象, 创建索引;
(8) 释放资源.
5.1 示例代码
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class IndexManager {
/**
* 创建索引功能的测试
* @throws Exception
*/
@Test
public void createIndex() throws IOException{
// 1. 采集数据
BookDao bookDao = new BookDaoImpl();
List<Book> books = bookDao.listAll();
// 2. 创建文档对象
List<Document> documents = new ArrayList<Document>();
for (Book book : books) {
Document document = new Document();
// 给文档对象添加域
// add方法: 把域添加到文档对象中, field参数: 要添加的域
// TextField: 文本域, 属性name:域的名称, value:域的值, store:指定是否将域值保存到文档中
document.add(new TextField("bookId", book.getId() + "", Store.YES));
document.add(new TextField("bookName", book.getBookname(), Store.YES));
document.add(new TextField("bookPrice", book.getPrice() + "", Store.YES));
document.add(new TextField("bookPic", book.getPic(), Store.YES));
document.add(new TextField("bookDesc", book.getBookdesc(), Store.YES));
// 将文档对象添加到文档对象集合中
documents.add(document);
}
// 3. 创建分析器对象(Analyzer), 用于分词
Analyzer analyzer = new StandardAnalyzer();
// 4. 创建索引配置对象(IndexWriterConfig), 用于配置Lucene
// 参数一:当前使用的Lucene版本, 参数二:分析器
IndexWriterConfig indexConfig = new IndexWriterConfig(Version.LUCENE_4_10_2, analyzer);
// 5. 创建索引库目录位置对象(Directory), 指定索引库的存储位置
File path = new File("/your_path/index");
Directory directory = FSDirectory.open(path);
// 6. 创建索引写入对象(IndexWriter), 将文档对象写入索引
IndexWriter indexWriter = new IndexWriter(directory, indexConfig);
// 7. 使用IndexWriter对象创建索引
for (Document doc : documents) {
// addDocement(doc): 将文档对象写入索引库
indexWriter.addDocument(doc);
}
// 8. 释放资源
indexWriter.close();
}
}
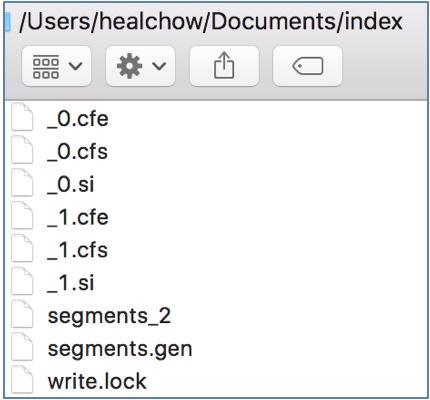
5.2 测试结果
说明: 只要看到以下文件, 说明索引已经创建成功了:
6 使用Luke工具查看索引

6.1 使用说明
Windows OS下,双击运行start.bat文件(前提是需要配置jdk的环境变量);
Mac OS下, 在终端中进入当前目录, 然后键入 ./start.sh 即可运行.
6.2 运行界面一
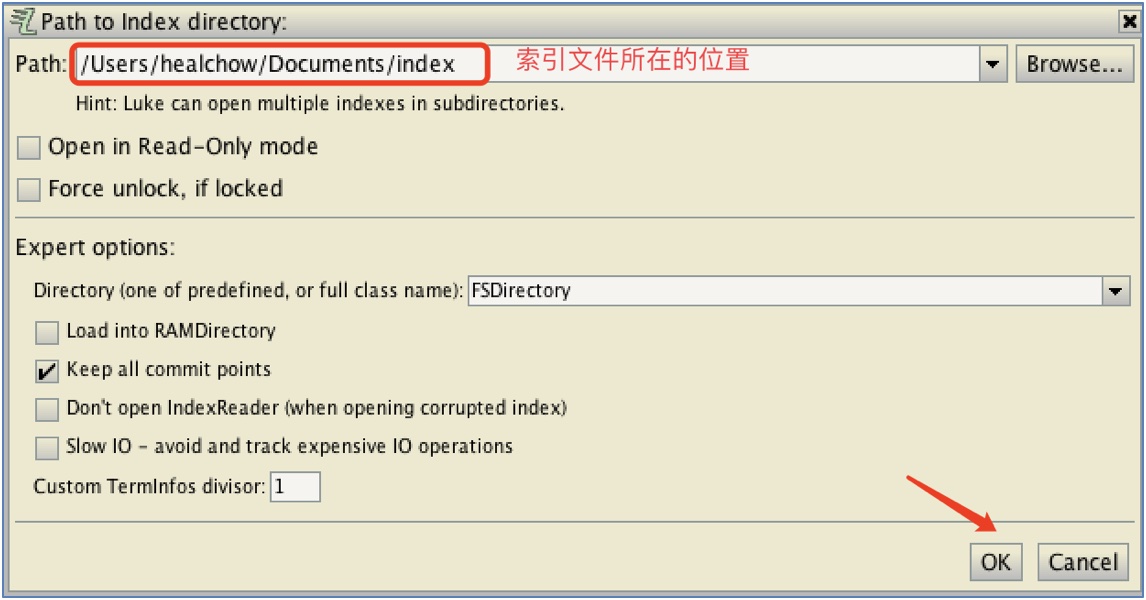
6.3 运行界面二
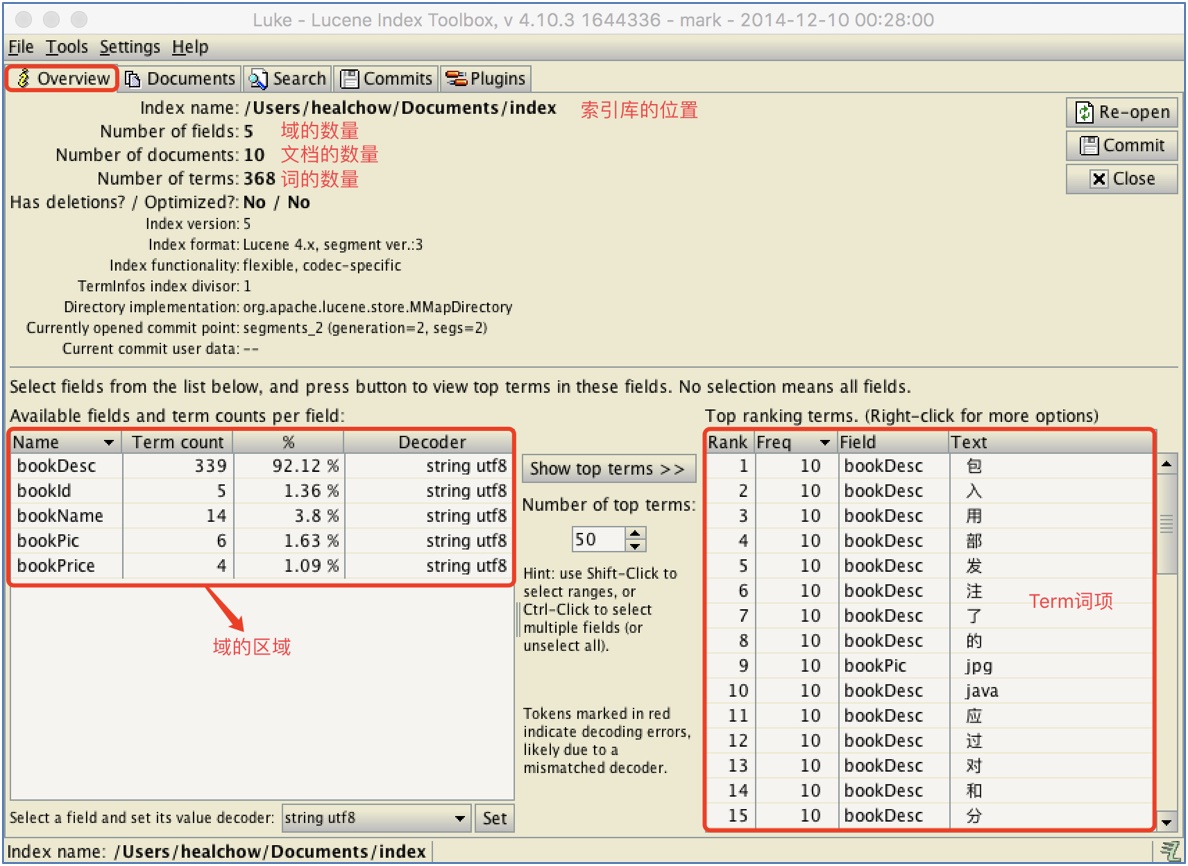
6.4 运行界面三

7 检索流程的实现
(1) 创建分析器对象(Analyzer), 用于分词;
(2) 创建查询对象(Query);
(3) 创建索引库目录位置对象(Directory), 指定索引库的位置;
(4) 创建索引读取对象(IndexReader), 用于读取索引;
(5) 创建索引搜索对象(IndexSearcher), 用于执行搜索;
(6) 使用IndexSearcher对象, 执行搜索, 返回搜索结果集TopDocs;
(7) 处理结果集;
(8) 释放资源.
7.1 使用Luke工具搜索

bookName:lucene—— 表示搜索bookName域中包含有lucene.
7.2 示例代码
/**
* 检索索引功能的测试
* @throws Exception
*/
@Test
public void searchIndexTest() throws Exception {
// 1. 创建分析器对象(Analyzer), 用于分词
Analyzer analyzer = new StandardAnalyzer();
// 2. 创建查询对象(Query)
// 2.1 创建查询解析器对象
// 参数一:默认的搜索域, 参数二:使用的分析器
QueryParser queryParser = new QueryParser("bookName", analyzer);
// 2.2 使用查询解析器对象, 实例化Query对象
Query query = queryParser.parse("bookName:lucene");
// 3. 创建索引库目录位置对象(Directory), 指定索引库位置
Directory directory = FSDirectory.open(new File("/your_path/index"));
// 4. 创建索引读取对象(IndexReader), 用于读取索引
IndexReader indexReader = DirectoryReader.open(directory);
// 5. 创建索引搜索对象(IndexSearcher), 用于执行索引
IndexSearcher searcher = new IndexSearcher(indexReader);
// 6. 使用IndexSearcher对象执行搜索, 返回搜索结果集TopDocs
// 参数一:使用的查询对象, 参数二:指定要返回的搜索结果排序后的前n个
TopDocs topDocs = searcher.search(query, 10);
// 7. 处理结果集
// 7.1 打印实际查询到的结果数量
System.out.println("实际查询到的结果数量: " + topDocs.totalHits);
// 7.2 获取搜索的结果数组
// ScoreDoc中有文档的id及其评分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
System.out.println("= = = = = = = = = = = = = = = = = = =");
// 获取文档的id和评分
int docId = scoreDoc.doc;
float score = scoreDoc.score;
System.out.println("文档id= " + docId + " , 评分= " + score);
// 根据文档Id, 查询文档数据 -- 相当于关系数据库中根据主键Id查询数据
Document doc = searcher.doc(docId);
System.out.println("图书Id: " + doc.get("bookId"));
System.out.println("图书名称: " + doc.get("bookName"));
System.out.println("图书价格: " + doc.get("bookPrice"));
System.out.println("图书图片: " + doc.get("bookPic"));
System.out.println("图书描述: " + doc.get("bookDesc"));
}
// 8. 关闭资源
indexReader.close();
}
7.3 测试结果

7.4 结果说明
(1) 索引库中包含索引域和文档域;
(2) 索引域保存索引数据(倒排索引), 用于索引;
(3) 文档域中保存文档数据, 用于搜索获取数据.
7.5 IndexSearcher方法
| 方法 | 说明 |
|---|---|
| indexSearcher.search(query, n) | 根据Query搜索, 返回评分最高的n条记录 |
| indexSearcher.search(query,filter,n) | 根据Query搜索, 添加过滤策略, 返回评分最高的n条记录 |
| indexSearcher.search(query, n, sort) | 根据Query搜索, 添加排序策略, 返回评分最高的n条记录 |
| indexSearcher.search(booleanQuery, filter, n, sort) | 根据Query搜索, 添加过滤策略, 添加排序策略, 返回评分最高的n条记录 |
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号