

Apache InLong 的 SPI 扩展实践
1 - Apache InLong 简介
1.1 项目简介
InLong 官网 的介绍:
Apache InLong(应龙)是一个一站式的海量数据集成框架,提供自动、安全、可靠和高性能的数据传输能力,方便业务构建基于流式的数据分析、建模和应用。
该项目最初于 2019 年 11 月由腾讯大数据团队捐献到 Apache 孵化器,2022 年 6 月正式孵化毕业,成为 Apache 顶级项目(TLP)。

https://inlong.apache.org/img/inlong-structure-zh.png
1.2 适用场景
Apache InLong 依托腾讯百万亿级别的数据接入和处理能力,整合了数据采集、汇聚、存储、分拣数据处理全流程,拥有简单易用、灵活扩展、稳定可靠等特性。
目前 InLong 正广泛应用于广告、支付、社交、游戏、运营商、人工智能等领域,为广大客户提供高效、便捷的数据采集、服务。
2 - InLong Manager 的作用
InLong 支持数据的采集、汇聚、缓存和分拣功能,用户只需要简单的配置就可把数据从源端导入到实时计算引擎或者写入离线存储系统。
从前面的架构图可以看出,InLong 系统涉及采集、汇聚、缓存、分拣 4 个主要流程,如何将这些流程串联起来?
答案是,我们通过 InLong Manager 来管理系统和任务的元数据,串联任务的全流程。
这里的元数据主要包括:
InLong 系统中的用户信息、审批信息、集群配置信息;
用户创建的数据源端、数据目标端,以及数据 schema 等信息。
其结构如下:
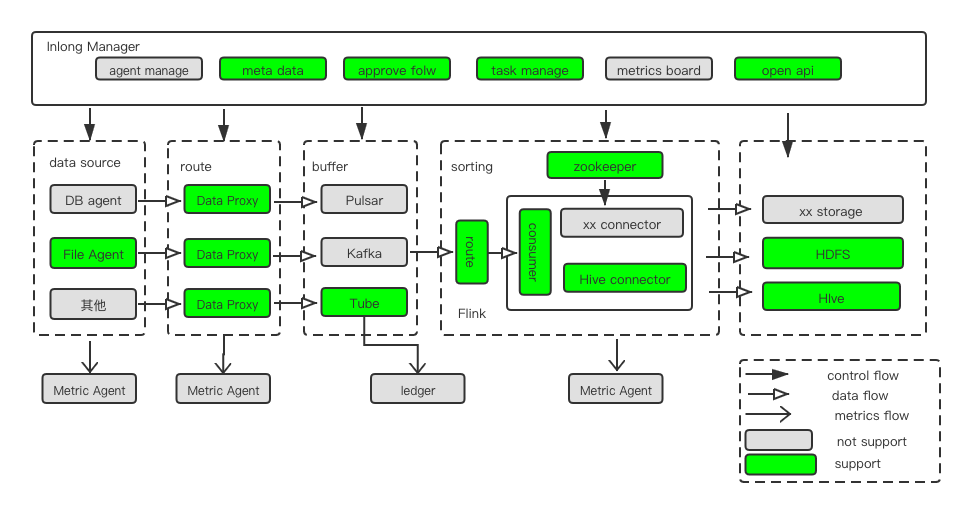
用户可在 InLong Dashboard 提供的 Web UI,或 通过 Manager Client 创建数据流任务,任务审批通过后,即可串联起全部流程,主要包括:
- 创建 MQ 的 Topic 和消费者;
- 创建目标端的库表结构;
- 启动 Flink 任务,从 MQ 消费数据,写入目标端。
3 - InLong Manager 的 SPI 实践
3.1 存在的问题
InLong 源于腾讯内网业务,在近10年的发展中,主要支持的数据源和数据存储如下:

以数据存储为例,由于存储系统的类型有限,且考虑到不同的存储类型的参数差异较大,因此我们的配置表是这样设计的:

由于篇幅所限,没有列出来状态、创建者、修改者、是否删除的标志,以及相关的时间、版本号等字段,可以看到,每张表里都有10多个相同的字段。
在 InLong 上云的过程中,数据源端和目标端的类型急剧增多,而且随着云上客户规模的增加,还会继续扩展更多类型的数据源和目标端。下图是在上面已有类型的基础上,新增的类型:

在扩展的过程中,我们很快发现了原有设计的痛点:
1)表多,重复字段多,增加了维护成本
2)配置管理存在大量的相似代码(比如修改、删除),即使提取出公共方法,也会存在大量的
if-else/switch-case语句来分别处理不同的逻辑,比如保存操作(还有创建 MQ 资源、创建存储端库表结构、下发任务等类似逻辑):
3)【更重要】如果要扩展1个新的存储类型,不仅要添加一张表(频繁变更 DDL 是大忌),还要入侵已有的代码,添加
else/case语句并补充特殊逻辑(不符合开闭原则)

3.2 什么是 SPI
带着上述痛点,我们来了解一下 Java SPI 技术。
SPI,全称 Service Provider Interface,是 Java 提供的一套用来被第三方实现或者扩展的 API,它可以用来启用框架扩展和替换组件。
翻译成中文,是“服务提供者接口”,顾名思义,这个接口是给“服务提供者”使用的。
比较常见的例子:
- 加载 数据库驱动 load 接口的实现类
- SLF4J 加载不同提供商的日志实现类 日志门面接口的实现类
- Spring 中自动类型转换 Type Conversion SPI (Converter SPI、Formatter SPI) 等
以常见的 JDBC 驱动的加载接口为例,加载操作不指定具体的 JDBC 驱动类型,而是通过用户传入的类型,去查找符合此类型的接口提供者,再由此接口去执行具体的逻辑。

以 Flink JDBC Connector 中对不同 JDBC 方言的处理为例:
1)首先定义一个开放给外部去实现的 JdbcDialectFactory 接口,由不同的 DB Dialect 去实现:

2)在 jar 包的 META-INF/services 目录下创建一个名称为此接口全限定名的文件,内容是各个实现类的全限定名:

3)应用程序中通过 java.util.ServiceLoder 扫描 META-INF/services 目录下的配置文件,根据实现类的全限定名来动态装载具体的实现类:

应用程序只需要调用 3)中 JdbcDialectLoader 的加载方法,即可根据传入的参数动态选中符合条件的实现类,比如传入的 JDBC URL 以 jdbc:mysql: 开头,那么在 JdbcDialectLoader 中,就会返回 MySqlDialectFactory:
public static JdbcDialect load(String url) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
List<JdbcDialectFactory> foundFactories = discoverFactories(cl);
// ...
final List<JdbcDialectFactory> matchingFactories =
foundFactories.stream().filter(f -> f.acceptsURL(url)).collect(Collectors.toList());
// ...
}
由上面的学习可以看出,Java SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。
留个问题:根据上述用法,能看出 SPI 的不足吗?
点击查看答案
1. 虽然 ServiceLoader 是延迟加载,但是只能通过遍历全部实现类,从中获取所需 —— 也就是会全部加载并实例化一遍接口的所有实现类。 2. 多线程并发访问 ServiceLoader 类,可能出现线程安全问题。
3.3 Manager 的 SPI 改造实践
根据 SPI 思想的指引,我们来改造 InLong Manager 的代码。
1)精简服务层代码,删除繁琐的 if-else / switch-case 语句。
收敛 Service 层的接口,同一领域模型的请求都在同一个 Service 接口中处理,以保存操作为例:
// 代码路径:org.apache.inlong.manager.service.sink.StreamSinkServiceImpl
public Integer save(SinkRequest request, String operator) {
// ...
// According to the sink type, save sink information
StreamSinkOperator sinkOperator = operatorFactory.getInstance(request.getSinkType());
return sinkOperator.saveOpt(request, operator);
}
根据不同的类型,通过执行器的工厂找到具体的配置执行器,由具体的执行器去执行真正的保存方法:
// 代码路径:org.apache.inlong.manager.service.sink;
@Service
public class SinkOperatorFactory {
// Spring 自动加载 StreamSinkOperator 接口的所有实现者,与 SPI 要达到的效果相同
@Autowired
private List<StreamSinkOperator> sinkOperatorList;
/**
* Get a sink operator instance via the given sinkType
*/
public StreamSinkOperator getInstance(String sinkType) {
return sinkOperatorList.stream()
.filter(inst -> inst.accept(sinkType))
.findFirst()
.orElseThrow(() -> new BusinessException(ErrorCodeEnum.SINK_TYPE_NOT_SUPPORT,
String.format(ErrorCodeEnum.SINK_TYPE_NOT_SUPPORT.getMessage(), sinkType)));
}
}
问题来了,在哪里用到了 SPI 接口呢?
由于我们是基于 SpringBoot 的后端服务,Spring 框架本身的 Bean 加载机制就是就能满足我们的需求。
2)重构数据库实体模型,一张表支持任意类型 Sink 的配置。
表中记录通用字段,对于不同类型 Sink 的特有字段,通过一个扩展字段来存储,可以是 KV,也可以是 JSON,我们这里选择 JSON:
CREATE TABLE IF NOT EXISTS `stream_sink`
(
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Incremental primary key',
`inlong_group_id` varchar(256) NOT NULL COMMENT 'Owning inlong group id',
`inlong_stream_id` varchar(256) NOT NULL COMMENT 'Owning inlong stream id',
`sink_type` varchar(15) DEFAULT 'HIVE' COMMENT 'Sink type, including: HIVE, ES, etc',
`sink_name` varchar(128) NOT NULL DEFAULT '' COMMENT 'Sink name',
`description` varchar(500) NULL COMMENT 'Sink description',
`enable_create_resource` tinyint(1) DEFAULT '1' COMMENT 'Whether to enable create sink resource? 0-disable, 1-enable',
`data_node_name` varchar(128) DEFAULT NULL COMMENT 'Node name, which links to data_node table',
`ext_params` text NULL COMMENT 'Another fields, will be saved as JSON type',
`operate_log` text DEFAULT NULL COMMENT 'Background operate log',
`status` int(11) DEFAULT '100' COMMENT 'Status',
`previous_status` int(11) DEFAULT '100' COMMENT 'Previous status',
`is_deleted` int(11) DEFAULT '0' COMMENT 'Whether to delete, 0: not deleted, > 0: deleted',
`creator` varchar(64) NOT NULL COMMENT 'Creator name',
`modifier` varchar(64) DEFAULT NULL COMMENT 'Modifier name',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Create time',
`modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Modify time',
`version` int(11) NOT NULL DEFAULT '1' COMMENT 'Version number, which will be incremented by 1 after modification',
PRIMARY KEY (`id`),
UNIQUE KEY `unique_sink_name` (`inlong_group_id`, `inlong_stream_id`, `sink_name`, `is_deleted`)
);
不同类型 Sink 的特有字段,转换成 JSON 格式存储到 ext_params 字段中,查询时再将其解析成其特有的 DTO,相关代码可以参考:
org.apache.inlong.manager.service.sink.AbstractSinkOperator 中 saveOpt 方法调用的 setTargetEntity 方法
org.apache.inlong.manager.service.sink.StreamSinkOperator 接口中 getFromEntity 方法的各个实现
3)其他地方的使用
上述操作,在数据源(StreamSource)、数据目标(StreamSink)配置的管理,InlongGroup 对不同类型 MQ 的扩展,MQ 主题和消费者的创建、Sink 库表结构的创建,等方面均有使用,感兴趣的朋友可以看看相关代码:
org.apache.inlong.manager.service.group.InlongGroupOperator
org.apache.inlong.manager.service.sink.StreamSinkOperator
org.apache.inlong.manager.service.source.StreamSourceOperator
org.apache.inlong.manager.service.resource.sink.SinkResourceOperator
org.apache.inlong.manager.service.resource.queue.QueueResourceOperator
3.4 改造后的收益
撇开收益谈优化就是耍流氓。
在经过上述改造后,至少带来了如下收益:
1)代码复用性提高,减少了大量重复/相似逻辑的代码,这也在一定程度上降低了维护成本
2)代码扩展性极大增强,扩展不同类型的配置,只需要依葫芦画瓢,去实现它自己的逻辑即可,也无需改动已有接口
3)表的 DDL 不用频繁变动(如果没有这个改造,可能就要创建一张大宽表,或者不断增加新的表),降低了维护成本,避免修改 DDL 引发线上问题
4)我们参与开源、使用开源,这个改造能够让我们在不侵入修改开源代码的情况下,扩展腾讯内部的配置类型,加入内网特有的业务逻辑。
看完还有疑问吗?评论区留言交流吧😄
版权声明
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)
感谢阅读,公众号 「瘦风的南墙」 ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注🤝
本文版权归博主所有,欢迎转载,但 [必须在页面明显位置标明原文链接],否则博主保留追究相关人士法律责任的权利。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号