

HDFS 08 - Hadoop Archive 存档的使用
1 - Archive 命令说明
Hadoop Archive(即 HAR),是一个高效地将小文件保存到HDFS block 中的文件存档工具。
它能把多个小文件打包成一个 HAR 文件,在减少NameNode 元数据的同时,仍然能够对文件进行访问(对客户端无影响,是透明操作)。
来看看这个命令的参数:
hadoop archive
archive <-archiveName <NAME>.har> <-p <parent path>> [-r <replication factor>] <src>* <dest>
Archive Name not specified.
参数说明:
<-archiveName <NAME>.har> 指定存档后的文件名,必填
<-p <parent path>> 指定被存档文件所属的父目录,必填
[-r <replication factor>] 指定复制因子,默认是10,选填
<src>* 源路径,可以多个,必填
<dest> 存档的目录结构
2 - 创建存档文件
我们试试把 HDFS 的某个目录下的所有文件,都进行存档。
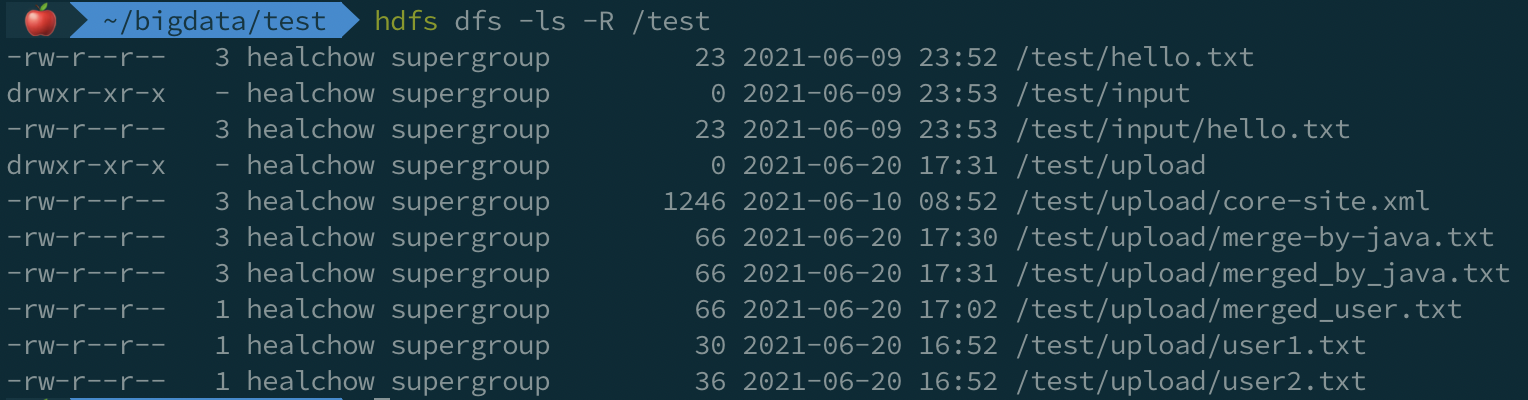
# 查看 /test 目录下的文件:
hdfs dfs -ls -R /test
# 创建存档文件,包括 input,upload 目录,存档到 /test/har 下
hadoop archive -archiveName test.har -p /test/ ./ input upload /test/har
说明:创建存档文件会生成一个 MapReduce 作业,因此需要有可运行 MapReduce 任务的集群。我们本地的 Hadoop 集群就能满足要求。
查看生成的文件:
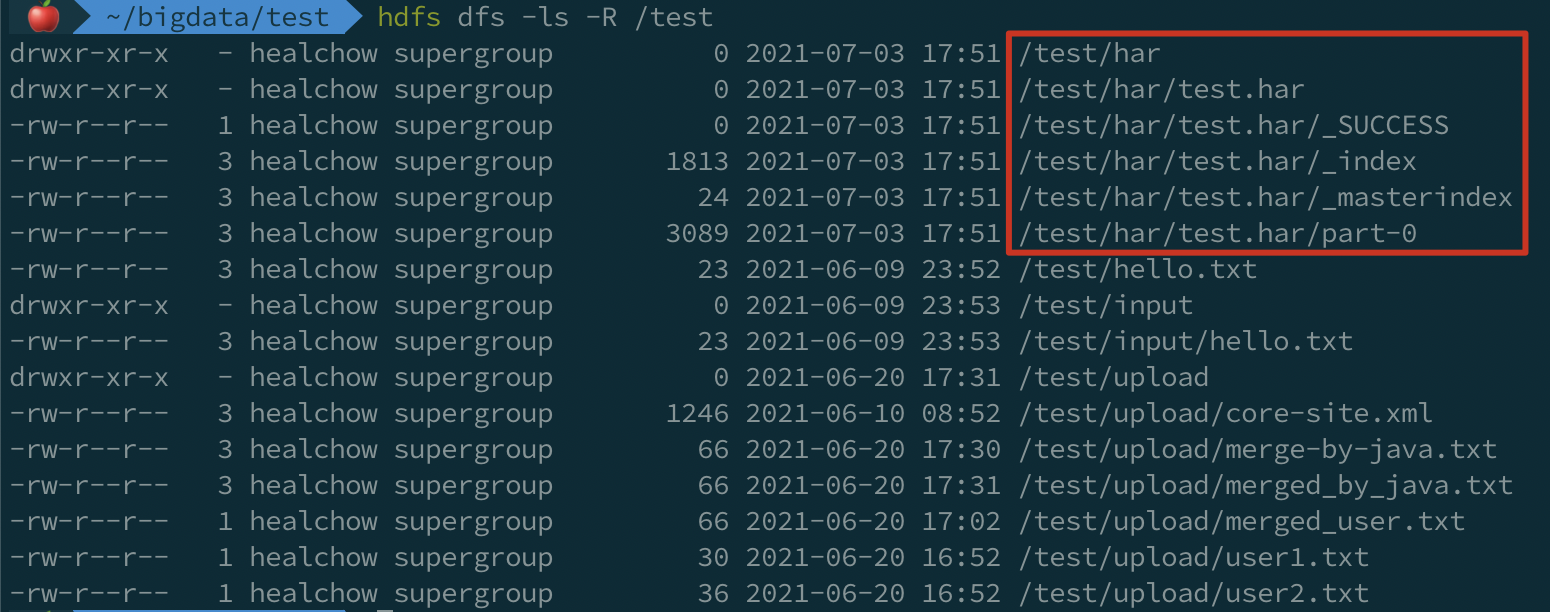
可以看到,存档后的文件带有 .har 扩展名,其中包含:
1)元数据部分,
_index和_masterindex
2)数据部分,part-*
_index 文件记录了存档文件的名称,以及内部文件的位置等信息。
3 - 查看存档文件
已经创建的存档文件是不可变的,所以重命名、追加或移除内部文件时会出错。
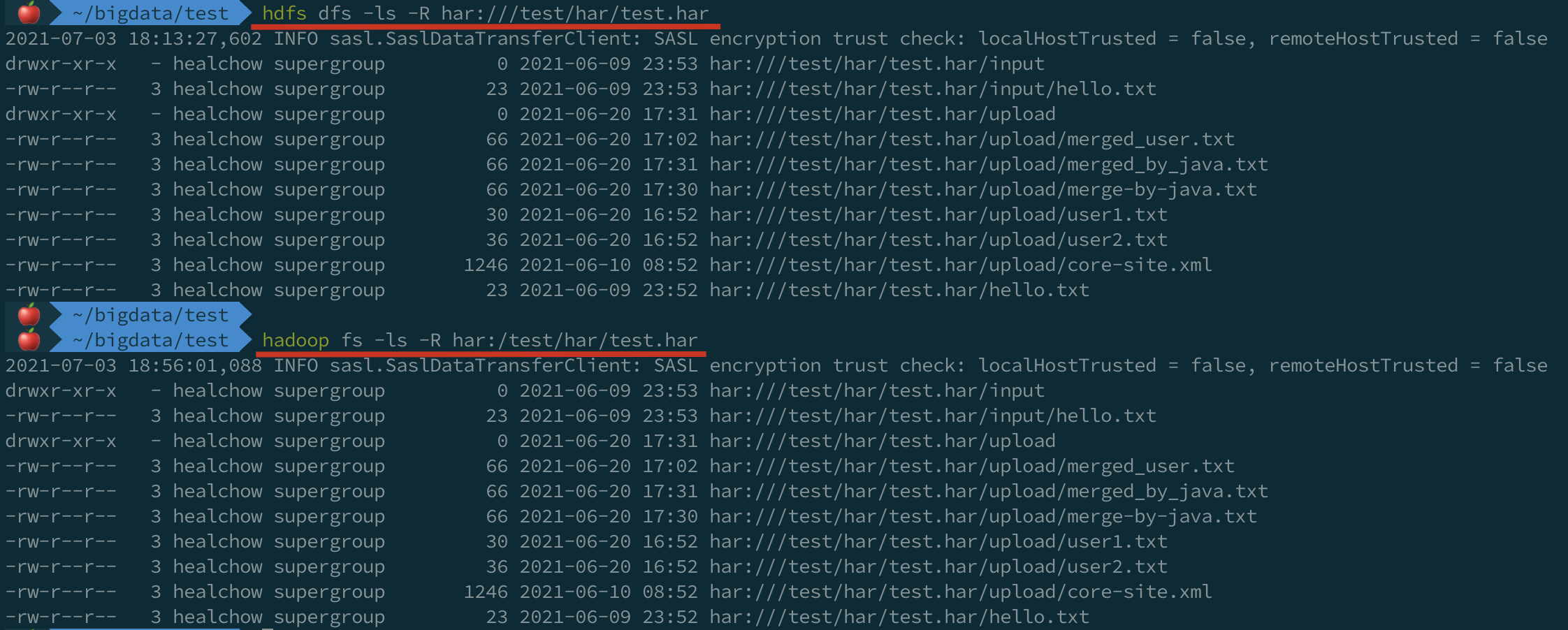
查看存档文件,需要通过特定的 URI 查看,在 HDFS 中,存档文件的默认 URI 是 har:///路径/存档文件名:
hdfs dfs -ls -R har:///test/har/test.har
# 或:
hadoop fs -ls -R har:/test/har/test.har
4 - 解除存档文件
解开存档文件,只需要执行复制操作即可:
# 将存档文件,解开到 /test/unhar 下:
hdfs dfs -mkdir -p /test/unhar
# 拷贝存档文件中的内容,到上面的路径:
hdfs dfs -cp har:///test/har/test.har/input /test/unhar/
# 可以通过 hadoop distcp 命令并行复制:
hadoop distcp har:/test/har/test.har/upload /test/unhar

另外,删除存档文件时,需要递归删除:
hdfs dfs -rm -r /test/har/test.har
5 - Hadoop 存档的特性
1)存档文件本身不支持压缩;
2)创建存档文件时用到的源文件及目录都不会自动删除,如有需要,可以手动删除。
3)存档文件一旦创建便不可修改,要想从中删除或增加文件,必须重新建立存档文件。
4)创建存档文件会创建原始文件的副本,所以至少需要有与存档文件容量相同的磁盘空间。
参考资料
版权声明
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)
感谢阅读,公众号 「瘦风的南墙」 ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注🤝
本文版权归博主所有,欢迎转载,但 [必须在页面明显位置标明原文链接],否则博主保留追究相关人士法律责任的权利。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号