

HDFS 05 - HDFS 的元数据管理(FSImage、Edits、CheckPoint)
1 - NameNode 的元数据
NameNode 的所有操作及整个集群的状态都存储在 元数据 中,元数据通过 FSImage 和 Edits 文件保存。
【辅助理解】NameNode 的元数据存储在哪里?
假设:如果元数据存储在 NameNode 节点的磁盘中,由于需要频繁地随机访问,还要响应客户请求,效率会很低。因此元数据需要放在内存中。
但如果只存到内存中,一旦机器断电,元数据就会丢失,整个集群就无法工作了。
—— 因此需要在磁盘中备份元数据的 FSImage。
【 新问题】内存中的元数据更新时,如果同时更新 FSImage,效率会很低,但如果不更新 FSImage,就容易出现一致性问题,一旦 NameNode 断电,就会丢失数据。
—— 因此引入 Edits 文件(只追加,效率很高),每当元数据需要添加或更新时,既修改内存中的元数据,并追加到 Edits 文件中。
—— 即使 NameNode 节点断电,也可以通过 FSImage 和 Edits 的合并,合成元数据。
它们的主要作用是:在集群启动时将集群的状态恢复到关闭前的状态。
—— 也就是 Hadoop 集群因为各种原因需要重新启动,元数据能保证集群启动之后的状态和上次停止前的状态一致。
第一次启动 NameNode 前的格式化(
hdfs namenode -format)操作会创建 fsimage 和 edits 文件。非第一次启动,NameNode 会进行数据恢复:首先把 fsimage 加载到内存中形成文件系统镜像,然后再把 edits 中 fsimage_txid 之后的、所有事务 回放到这个文件系统镜像上。这个时候,集群也就恢复到关闭前的状态了。
它们的位置需要在 hdfs-site.xml 文件中指定:
<!-- NameNode 元数据的存放目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/Users/healchow/data/hadoop/namenode</value>
</property>
<!-- NameNode 日志文件的存放目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:/Users/healchow/data/hadoop/namenode/edits</value
</property>
1.1 FSImage 元数据镜像
1)FSImage 是 NameNode 中关于元数据的镜像,一般称为检查点的镜像;会在内存和磁盘中各保存一份;
2)FSImage 是 NameNode 自最后一次 CheckPoint 之前的全部元数据,并不是实时的数据;
3)FSImage 保存了 NameNode 管理下的所有 DataNode 的文件和目录信息:
对文件来说:包括文件的 block、各个 block 所在的 DataNode,以及它们的修改时间、访问时间等;
对目录来说:包括修改时间、访问权限控制信息(权限、属组)等。
FSImage 默认会保存2个,由属性 dfs.namenode.num.checkpoints.retained 控制。
内存中的 FSImage 用于 NameNode 向客户端提供读服务,而 EditLog 仅仅只是在数据恢复的时候发挥作用。
1.2 查看 FSImage 文件
FSImage 文件的文件名形如 fsimage_${end_txid},其中 ${end_txid} 表示这个 FSImage 文件中的最后一个事务的 id。
查看 FSImage 文件中的信息:
# hdfs oiv 回车后会显示命令的帮助信息:
cd ~/bigdata/data/hadoop/namenode
hdfs oiv -i fsimage_0000000000000000864 -p XML -o hello.xml
1.3 Edits 操作日志
1)客户端对 HDFS 的写操作会先记录到 edits 文件中 —— 自最后一次检查点之后的所有操作,有实时数据;
HDFS 客户端提交的创建、移动、删除文件等 写操作 的时候,NameNode 会首先把这些操作记录在 edits 文件中。
2)edits 修改完成之后,会再更新内存中的文件系统镜像;
edits 文件会不断增大(导致系统运行、重启恢复等过程非常缓慢),在一定条件下会和 fsimage 文件合并,从而减小 edits 文件的体积。
3)记录在 edits 中的每一个操作又称为一个事务,每个事务有一个整数形式的事务 id 作为编号。
(临时总结,不一定对)EditLog 就是事务日志,主要作用是用来记录写操作,以支持系统的恢复。
1.4 查看 Edits 文件
Edits 会被切割成很多段,每一段称为一个 Segment。正在写入的 Segment 处于 in-progress 状态,其文件名形如 edits_inprogress_${start_txid},其中 ${start_txid} 表示这个 Segment 的起始事务 id。
已经写入完成的 Segment 处于 finalized 状态,其文件名形如 edits_${start_txid}-${end_txid},其中 ${start_txid} 表示这个 Segment 的起始事务 id,${end_txid} 表示这个 Segment 的结束事务 id。
查看 Edits 中的文件信息
# hdfs oev 回车后会显示命令的帮助信息:
cd ~/data/hadoop/namenode
hdfs oev -i edits_0000000000000000865-0000000000000000866 -p XML -o myedit.xml
2 - NameNode 的启动流程
1)Loading FSImage - 从 FSImage File 中读取最新的元数据快照(最近生成的 fsimage_txid);
2)Loading Edits - 读取 fsimage_txid 之后的所有事务的 Eidts,将 Eidts 中的操作重新执行一遍,此时 NameNode 就恢复到上次停止时的状态了;
3)CheckPoint - 将当前状态写入新的 CheckPoint (检查点)中,即产生一个新的 fsimage.ckpt_txid 文件;
4)Safe mode - 等待各个 DataNodes 汇报自己的 block 信息,形成 blockMap,然后退出安全模式。
此时 NameNode 启动结束,等待接受用户的操作请求,并把用户操作写入新的 Eidts 中,定期进行 CheckPoint,对元数据执行快照。
3 - CheckPoint 检查点操作
3.1 为什么要 CheckPoint
HDFS 的每个写操作都会写入 edits 中,如果集群规模非常庞大,操作又很频繁,随着时间的积累 edits 会变的很大,极端情况下会占满整个磁盘。
另外,由于 NameNode 在启动的时候,需要将 edits 中的操作重新执行一遍,过大的 edits 会延长 NameNode 的启动时间。
所以,通过 CheckPoint 定期对元数据进行合并。
3.2 CheckPoint 的过程
CheckPoint 会把 FSImage 和 EditLog 的内容进行合并生成一个新的 FSImage。
这样在 NameNode 启动的时候就不用将巨大的 EditLog 中的事务再执行一遍,而是直接加载合并之后的新 FSImage ,然后重新执行未被合并的 EditLog 文件就可以了。
创建新 FSImage 的过程需要大量的I/O、内存等资源,为了减轻影响,可将 Checkpoint 过程放在 SecondaryNameNode 或 StandbyNameNode 中(不同机器上)。
NameNode 在 Checkpoint 的时候会限制用户的访问(Hadoop 进入安全模式,此时需要管理员使用 dfsadmin 的 save namespace 来创建新的检查点);
4 - SecondaryNameNode 辅助管理 FSImage 和 EditLog
【辅助理解】如果 Edits 文件被长时间追加,会导致该文件非常庞大,而且异常断电情况下,恢复元数据所需的时间也会很长。
—— 因此需要定期合并 FSImage 和 Edits,如果由 NameNode 节点去执行合并操作,会降低 NameNode 处理客户端请求的效率。
—— 因此引入一个新的节点 SecondaryNamenode,专门用于 FSImage 和 Edits 文件的合并。
4.1 管理元数据的相关配置
SNN(SecondaryNameNode,备份 NameNode)节点要在 conf/masters 文件中指定;
SNN 的 hdfs-site.xml 文件中需要配置下述参数:
<property>
<name>dfs.http.address</name>
<value>host:50070</value>
</property>
SecondaryNameNode 会定期合并 FSImage 和 EditLog,把 EditLog的体积控制在一个合理的范围内。
Checkpoint 的触发条件取决于两个参数,可在 NameNode / SNN 的 core-site.xml 中配置:
<!-- 两次 checkpoint 的时间间隔,默认3600秒,即1小时 -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
<!-- 新生成的 EditLog 中积累的事务数量达到了阈值,默认1000000次。优先级高于上述参数 -->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
</property>
<!-- 每隔多久检查一次 HDFS 未记录到检查点的事务数,默认60秒 -->
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
</property>
<!-- 一次记录文件的大小,默认64MB -->
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
4.2 管理元数据的流程
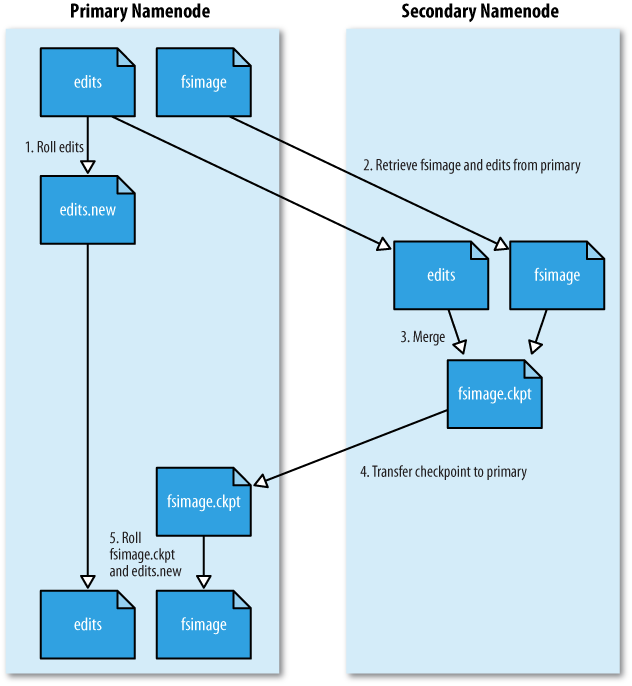
上面配置的2个条件,如果有任意一个满足了,就会触发 SecondaryNameNode 合并 FSImage 和 EditLog,具体流程为:
1)SecondaryNameNode 通知 NameNode 停止使用 EditLog,暂时将新的写操作存放到 edits.new 文件;
2)SecondaryNameNode 通过 HTTP GET 请求,从 NameNode 中获取 FSImage 和 EditLog,将它们加载到自己的内存中;
3)SecondaryNameNode 合并 FSImage 和 EditLog,合并完成后生成新的 FSImage,命名为 fsimage.ckpt;
4)SecondaryNameNode 通过 HTTP POST 请求方式,将新的 fsimage.ckpt 发送给 NameNode;
5)NameNode 把 fsimage.ckpt 改为 fsimage(覆盖掉原来的),并删掉旧的 edits 文件,把 edits.new 重命名为 edits,最后更新 fstime(即最后一个检查点的时间戳)。
通过这一系列操作,就避免了 edits 日志的无限增长,加快 Namenode 的启动过程。
参考资料
版权声明
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)
感谢阅读,公众号 「瘦风的南墙」 ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注🤝
本文版权归博主所有,欢迎转载,但 [必须在页面明显位置标明原文链接],否则博主保留追究相关人士法律责任的权利。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人