

HDFS 02 - macOS 系统安装 HDFS(Apache Hadoop 3.2.1)
始发于2021-06-06,修改于2021-12-13。
为了快速测试和体验,在本机环境中安装 Hadoop。
后续如果要模拟真实的分布式环境,可以开3台 Linux 虚拟机,然后搭建分布式 Hadoop 集群,暂时搁置。
1 - 准备安装包
到官网下载安装包 http://hadoop.apache.org/releases.html,这里以 3.2.1 版本为例,下载 binary 二进制文件即可。
下载后,拷贝到本地安装目录,比如我拷贝到了 ~/bigdata/ 目录(这里的 ~ 是当前用户的 home 目录)。
# 解压安装包到指定目录
mkdir ~/bigdata
cp hadoop-3.2.1.tar.gz ~/bigdata
tar -zxf hadoop-3.2.1.tar.gz
# 查看 Hadoop 对本地库的支持情况:
cd ~/bigdata/hadoop-3.2.1/ && ./bin/hadoop checknative
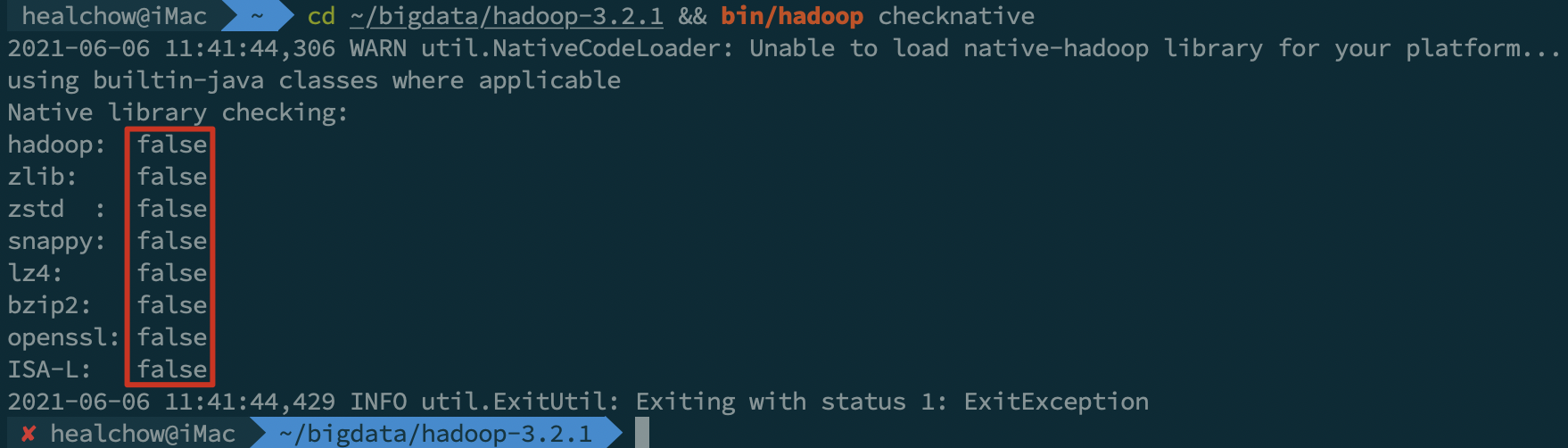
可以看到,从官网下载的安装包,不支持 snappy、bzip2 等压缩方式。如果有需要,我们可以自己重新编译安装包 ——
Hadoop - macOS 上编译 Hadoop 3.2.1
2 - 准备配置文件
说明:各个服务的配置文件中涉及到的端口号,都适用默认值。
2.1 修改 core-site.xml
cd ~/bigdata/hadoop-3.2.1/etc/hadoop
vim core-site.xml
官方详细文档:https://hadoop.apache.org/docs/r3.2.1/hadoop-project-dist/hadoop-common/core-default.xml
修改后的内容如下:
<configuration>
<property>
<!-- fs.default.name 已过期,推荐使用 fs.defaultFS -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!-- 缓冲区大小,根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
2.2 修改 hdfs-site.xml
cd ~/bigdata/hadoop-3.2.1/etc/hadoop
vim hdfs-site.xml
官方详细文档:https://hadoop.apache.org/docs/r3.2.1/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
修改后的内容如下:
👇点这里展开代码👇
<configuration>
<!-- 0.0.0.0 支持来自服务器外部的访问 -->
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>0.0.0.0:9868</value>
</property>
<!-- 数据存储位置,多个目录用英文逗号隔开 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/Users/healchow/bigdata/data/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/Users/healchow/bigdata/data/hadoop/datanode</value>
</property>
<!-- 元数据操作日志、检查点日志存储目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:/Users/healchow/bigdata/data/hadoop/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/Users/healchow/bigdata/data/hadoop/snn/checkpoint</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/Users/healchow/pebigdata/data/hadoop/snn/edits</value>
</property>
<!-- 临时文件目录 -->
<property>
<name>dfs.tmp.dir</name>
<value>file:/Users/healchow/bigdata/data/hadoop/tmp</value>
</property>
<!-- 文件切片的副本个数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- HDFS 的文件权限 -->
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
<!-- 每个 Block 的大小为128 MB,单位:KB -->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
2.3 修改 hadoop-env.sh
说明:在 macOS 系统下,可不用修改此文件。
如果是在 Linux 服务器中,需要执行如下操作:
# 查看 JAVA_HOME:
echo ${JAVA_HOME}
# 修改文件:
cd ~/bigdata/hadoop-3.2.1/etc/hadoop
vim hadoop-env.sh
把上面查看到的 Java 环境变量填进去,比如:
export JAVA_HOME=/bigdata/jdk1.8.0_202
2.4 修改 yarn-site.xml
cd ~/bigdata/hadoop-3.2.1/etc/hadoop
vim yarn-site.xml
官方详细文档:https://hadoop.apache.org/docs/r3.2.1/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
修改后的内容如下:
<configuration>
<property>
<!-- 支持来自服务器外部的访问 -->
<name>yarn.resourcemanager.hostname</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
2.5 修改 mapred-site.xml
cd ~/bigdata/hadoop-3.2.1/etc/hadoop
vim mapred-site.xml
修改后的内容如下:
<configuration>
<!-- 设置历史任务的主机和端口,0.0.0.0 支持来自服务器外部的访问 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<!-- 设置网页端的历史任务的主机和端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
2.6 修改 mapred-env.sh
说明:在 macOS 系统下,可不用修改此文件。如果是在 Linux 服务器中,需要如下执行:
# 查看 JAVA_HOME:
echo ${JAVA_HOME}
# 修改文件:
cd ~/bigdata/hadoop-3.2.1/etc/hadoop
vim mapred-env.sh
把上面查看到的 Java 环境变量填进去,比如:
export JAVA_HOME=/bigdata/jdk1.8.0_202
3 - 配置 Hadoop 环境变量
3.1 修改本机的 profile 文件
vim ~/.bash_profile
# 添加如下内容:
export HADOOP_HOME=/Users/healchow/bigdata/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置完成之后,使配置文件立即生效:
source ~/.bash_profile
3.2 添加 host 信息
由于上面的文件中,我们用了 hadoop 作为主机名,所以要把它设置到 /etc/hosts 中:
sudo vim /etc/hosts
# 添加如下内容:
127.0.0.1 hadoop
4 - 启动 Hadoop 集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个模块。
首次启动 HDFS 时,必须对其进行格式化操作 —— 一些必要的清理和准备工作,因为此时的 HDFS 文件系统物理上并不存在。
# 先格式化操作:
cd ~/bigdata/hadoop-3.2.1/
# 格式化命令:
bin/hdfs namenode -format # 或:bin/hadoop namenode –format
启动集群:
# 启动 HDFS:
sbin/start-dfs.sh
# 启动 Yarn:
sbin/start-yarn.sh
# 启动 HistoryServer:
sbin/mr-jobhistory-daemon.sh start historyserver
# 注意:上述命令已过时,应使用此命令启动 HistoryServer:
bin/mapred --daemon start historyserver
启动后,可通过 jps 命令查看运行的 Java 进程:
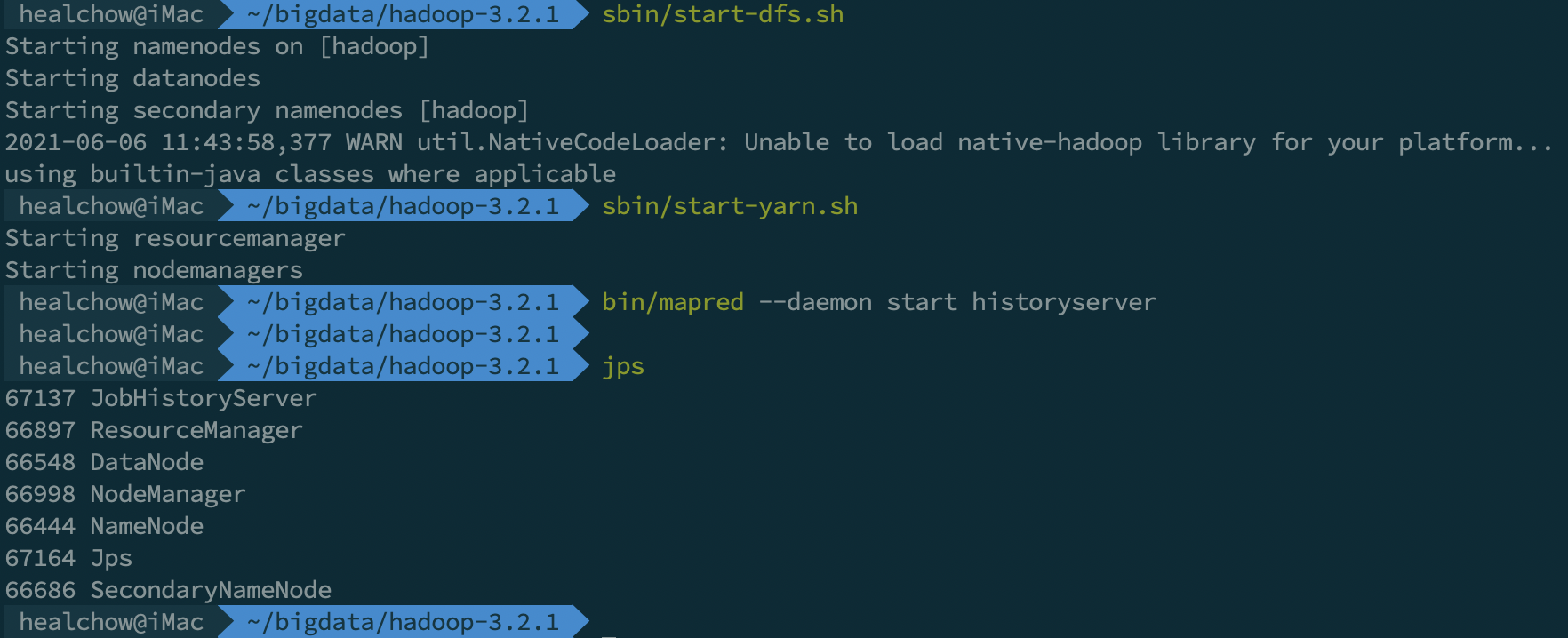
停止集群,按照与启动过程相反的顺序,执行停止命令:
bin/mapred --daemon stop historyserver
sbin/stop-yarn.sh
sbin/stop-dfs.sh
5 - 查看集群页面
1)查看 HDFS 页面:http://hadoop:9870/

2)查看 Yarn 页面:http://hadoop:8088/cluster
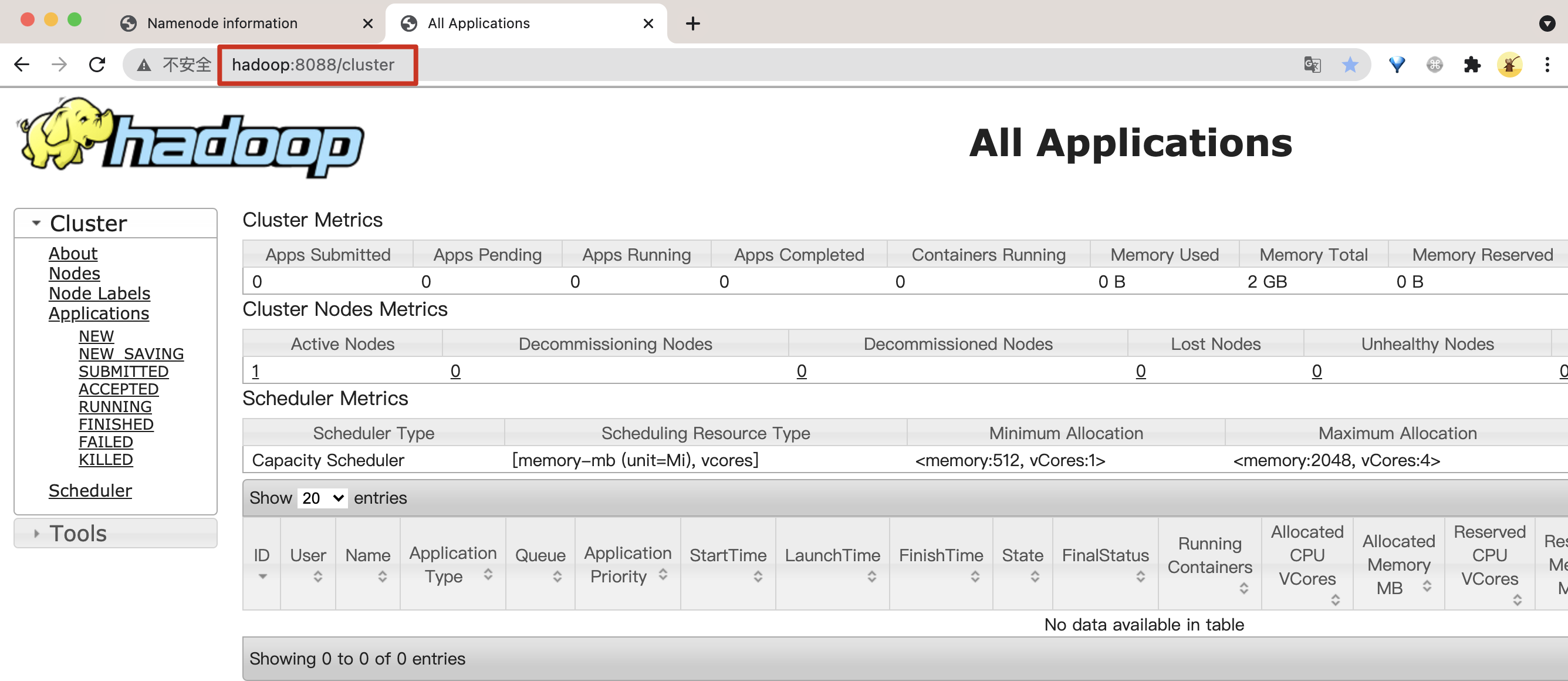
3)查看 HistoryServer 历史任务页面:http://hadoop:19888/jobhistory

6 - 常见问题及解决方法
6.1 root 用户安装 Hadoop 出错
在 /etc/profile 或 ~/.bash_profile 中添加下述配置,指定各个服务的用户为 root:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
或在下面两个启动脚本的开头空白处添加下属配置:
# start-dfs.sh 中添加:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# start-yarn.sh 中添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
6.2 ssh 使用非默认22端口号
启动服务时,抛出错误提示: ssh localhost port 22 Connection refused
这种情况,在 hadoop-env.sh 文件中添加下述命令即可:
export HADOOP_SSH_OPTS="-p 端口号" 即可。
又有新的问题了:ssh 使用非默认的 22 端口号后,启动 HDFS 时总是要输入密码,解决方法可参考:https://chengyanan.blog.csdn.net/article/details/108510672
6.3 Linux 服务器中安装,外部环境无法访问服务
本地安装、本地浏览器访问,IP 和 端口号配置,IP 可以是主机名,也可以是本机的 IP。
但如果是在 Linux 服务器中安装集群,然后要在外部的机器通过浏览器访问集群的 Web 服务,那么 IP 必须是 0.0.0.0 本地回环地址,否则外部环境访问就会失败。
版权声明
出处:博客园-瘦风的南墙(https://www.cnblogs.com/shoufeng)
感谢阅读,公众号 「瘦风的南墙」 ,手机端阅读更佳,还有其他福利和心得输出,欢迎扫码关注🤝
本文版权归博主所有,欢迎转载,但 [必须在页面明显位置标明原文链接],否则博主保留追究相关人士法律责任的权利。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号