

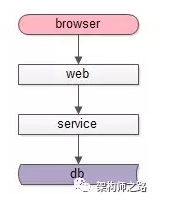
业务复杂、数据量大、并发量大的业务场景下,典型的互联网架构,一般会分为这么几层:
-
调用层,一般是处于端上的browser或者APP
-
站点层,一般是拼装html或者json返回的web-server层
-
服务层,一般是提供RPC调用接口的service层
-
数据层,提供固化数据存储的db
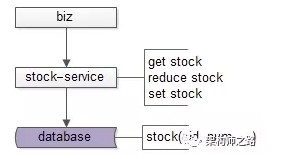
对于库存业务,一般有个库存服务,提供库存的查询、扣减、设置等RPC接口:
-
库存查询,stock-service本质上执行的是
select num from stock where sid=$sid -
库存扣减,stock-service本质上执行的是
update stock set num=num-$reduce where sid=$sid -
库存设置,stock-service本质上执行的是
update stock set num=$num_new where sid=$sid
用户下单前,一般会对库存进行查询,有足够的存量才允许扣减:
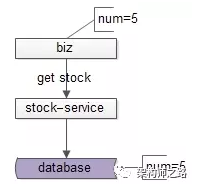
如上图所示,通过查询接口,得到库存是5。
用户下单时,接着会对库存进行扣减:
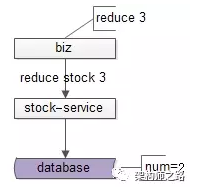
如上图所示,购买3单位的商品,通过扣减接口,最终得到库存是2。
希望设计往往有容错机制,例如“重试”,如果通过扣减接口来修改库存,在重试时,可能会得到错误的数据,导致重复扣减:
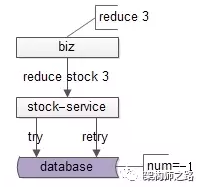
如上图所示,如果数据库层面有重试容错机制,可能导致一次扣减执行两次,最终得到一个负数的错误库存。
重试导致错误的根本原因,是因为“扣减”操作是一个非幂等的操作,不能够重复执行,改成设置操作则不会有这个问题:
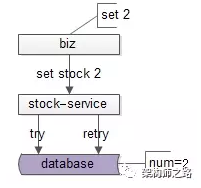
如上图所示,同样是购买3单位的商品,通过设置库存操作,即使有重试容错机制,也不会得到错误的库存,设置库存是一个幂等操作。
在并发量很大的情况下,还会有其他的问题:
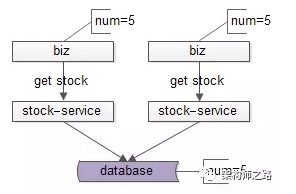
如上图所示,两个并发的操作,查询库存,都得到了库存是5。
接下来用户发生了并发的购买动作(秒杀类业务特别容易出现):
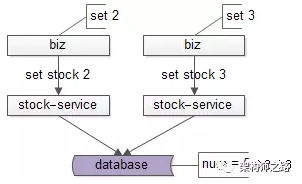
如上图所示:
-
用户1购买了3个库存,于是库存要设置为2
-
用户2购买了2个库存,于是库存要设置为3
-
这两个设置库存的接口并发执行,库存会先变成2,再变成3,导致数据不一致(实际卖出了5件商品,但库存只扣减了2,最后一次设置库存会覆盖和掩盖前一次并发操作)
其根本原因是,设置操作发生的时候,没有检查库存与查询出来的库存有没有变化,理论上:
-
库存为5时,用户1的库存设置才能成功
-
库存为5时,用户2的库存设置才能成功
实际执行的时候:
-
库存为5,用户1的set stock 2确实应该成功
-
库存变为2了,用户2的set stock 3应该失败掉
升级修改很容易,将库存设置接口,stock-service上执行的:
update stock set num=$y where sid=$sidupdate stock set num=$num_new where sid=$sid and num=$num_old总结
在业务复杂,数据量大,并发量大的情况下,库存扣减容易引发数据的不一致,常见的优化方案有两个:
-
调用“设置库存”接口,能够保证数据的幂等性
-
在实现“设置库存”接口时,需要加上原有库存的比较,才允许设置成功,能解决高并发下库存扣减的一致性问题

