


happens-before是JMM最核心的概念。对应Java程序员来说,理解happens-before是理解JMM的关键。
学习了 Java并发机制底层实现的三个关键要素:volatile、synchronized、原子性操作。以及Java内存模型是为了解决在并发环境下由于 CPU缓存、编译器和处理器的指令重排序 导致的可见性、有序性问题。 其中重点学习了 volatile 的内存语义,以及JMM是如何定义和实现的,在学习 volatile 内存语义实现原理时我们了解到了 JMM 解决指令重排其实是定义了一项 happens-before 规则,今天我们就来一窥究竟,尽量以通俗易懂的话语带大家学习 happens-before 。
如果还没有阅读 前面几篇关于 Java内存模型学习的文章,建议先翻到文末点击对应链接阅读,循序渐进比较好一点。
接下来,就进入主题,开始今天的表演。

JMM的设计
要学习 happens-before 这里首先介绍下JMM的设计意图。这个问题首先从实际出发:
- 我们程序员写代码时,是要求内存模型易于理解,易于编程,所以我们需要依赖一个强内存模型来编码。 也就是说向公理一样,定义好的规则,我们遵守规则写代码就完事了。
- 对于编译器和处理器的实现来说,它们希望约束尽量少一些,毕竟你限制它们肯定影响它们的执行效率,不能让他们尽己所能的优化来提供性能。所以他们需要一个弱内存模型。
好了,上面谈到的这两点明显就是冲突的,作为程序员我们希望JMM提供给我们一个强内存模型,而底层的编译器和处理器又需要一个弱内存模型来提高自己的性能。
在计算机领域,这种需要权衡的场景非常多,比如内存和CPU寄存器,就引入了CPU多级缓存来解决性能问题,不过也引入了多核cpu并发场景下的各种问题。 所以这里也一样,我们需要找到一个平衡点,来满足程序员的需求,同时也尽可能满足编译器和处理器限制放松,性能最大化。
因此JMM在设计时,定义了如下策略:
- 对于会改变程序执行结果的重排序,JMM要求编译器和处理器必须禁止这种重排序。
- 对于不会改变程序执行结果的重排序,JMM对编译器和处理器不做要求(JMM允许这种重排序)。
下面结合这副JMM设计图来理解下:
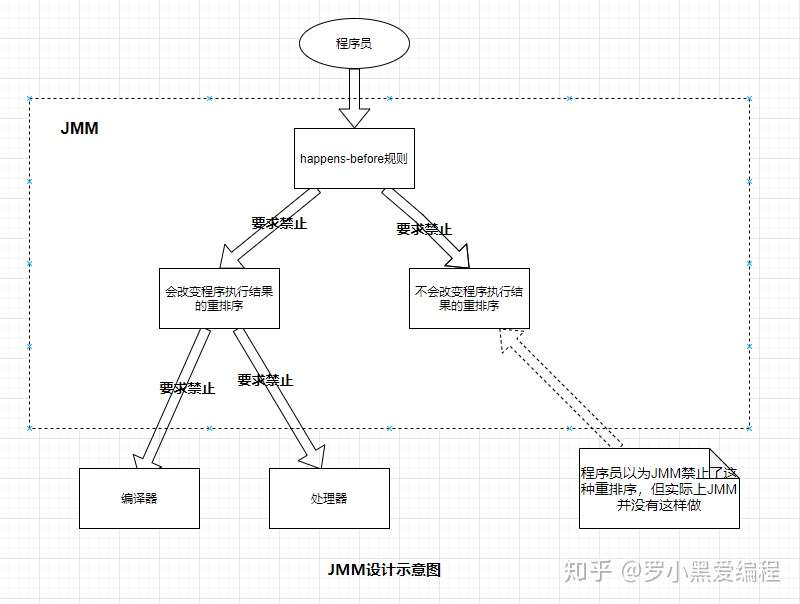
从上图中可以看到,JMM向我们程序员提供了足够强的内存可见性保证,在不影响程序执行结果的情况下,有些可见性保证并一定存在,比如下面的程序,A happens-before B 并不保证,因为其不影响程序执行结果;
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C这就引出了另一个方面,JMM为了满足编译器和处理器的约束尽可能少,它遵循的规则是:只要不改变程序的执行结果,编译器和处理器想怎么优化就怎么优化。例如,如果编译器经过细致的分析后,认定一个锁只会被单个线程访问,那么这个锁可以被消除。再如,如果编译器经过细致的分析后,认定一个volatile变量只会被单个线程访问,那么编译器可以把这个volatile变量当作一个普通变量来对待。这些优化既不会改变程序的执行结果,又能提高程序的执行效率。
happens-before 规则
如何 理解 happens-before规则呢? 如果仅仅望文生义理解为先行发生,那么南辕北辙了。happens-before 表达的并不是说前面一个操作发生在后面一个操作的前面,尽管从程序员编程角度来看也并不会出错,但它其实表达的是,前一个操作的结果对后续操作时可见的。
你可能会问这两种说法有什么区别呢?
这是因为JMM为程序员提供的视角就是按顺序执行的,且满足一个操作 happens-before 于另一个操作,那么第一个操作的执行结果将对第二个执行结果可见,而且第一个操作的执行顺序排在第二个顺序之前。注意,这是 JMM向程序员做出的保证。
但其实,JMM在对编译器和处理器进行约束时,如前面所说,遵循的规则是:再不改变程序执行结果的前提下,编译器和处理器怎么优化都行。也就是说两个操作之间存在 happens-before 规则Java平台并不一定按照规则定义的顺序来执行。 这么做的原因是因为,我们程序员并不关心两个操作是否被重排序,只要保证程序执行时语义不能改变就好了。
happens-before这么做的目的,都是为了在不改变程序执行结果的前提下,尽可能地提高程序执行的并行度。
理解了 happens-before 的含义后,我们一起来看下具体的 happens-before 规则定义。
1.程序顺序规则
一个线程中,按照程序顺序,前面的操作 Happens-Before 于后续的任意操作。这个还是非常好理解的,比如上面那三行代码,第一行的 "double pi = 3.14; " happens-before 于 “double r = 1.0;”,这就是规则1的内容,比较符合单线程里面的逻辑思维,很好理解。
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C2. 监视器锁规则
对一个锁的解锁,happens-before于随后对这个锁的加锁。
这个规则中说的锁其实就是Java里的 synchronized。例如下面的代码,在进入同步块之前,会自动加锁,而在代码块执行完会自动释放锁,加锁以及释放锁都是编译器帮我们实现的。
synchronized (this) { //此处自动加锁
// x是共享变量,初始值=10
if (this.x < 12) {
this.x = 12;
}
} //此处自动解锁所以结合锁规则,可以理解为:假设 x 的初始值是 10,线程 A 执行完代码块后 x 的值会变成 12(执行完自动释放锁),线程 B 进入代码块时,能够看到线程 A 对 x 的写操作,也就是线程 B 能够看到 x==12。这个也是符合我们直觉的,非常好理解。。
3. volatile变量规则
对一个volatile域的写,happens-before于任意后续对这个volatile域的读
这个就有点费解了,对一个 volatile 变量的写操作相对于后续对这个 volatile 变量的读操作可见,这怎么看都是禁用缓存的意思啊,貌似和 1.5 版本以前的语义没有变化啊(前面讲的1.5版本前允许volatile变量和普通变量之间重排序)?如果单看这个规则,的确是这样,但是如果我们关联一下规则 4,你就能感受到变化了
4. 传递性
如果A happens-before B,且B happens-before C,那么A happens-before C。
我们将规则 4 的传递性应用到我们下面的例子中,会发生什么呢?
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
// 这里x会是多少呢?
}
}
}可以看下面这幅图:
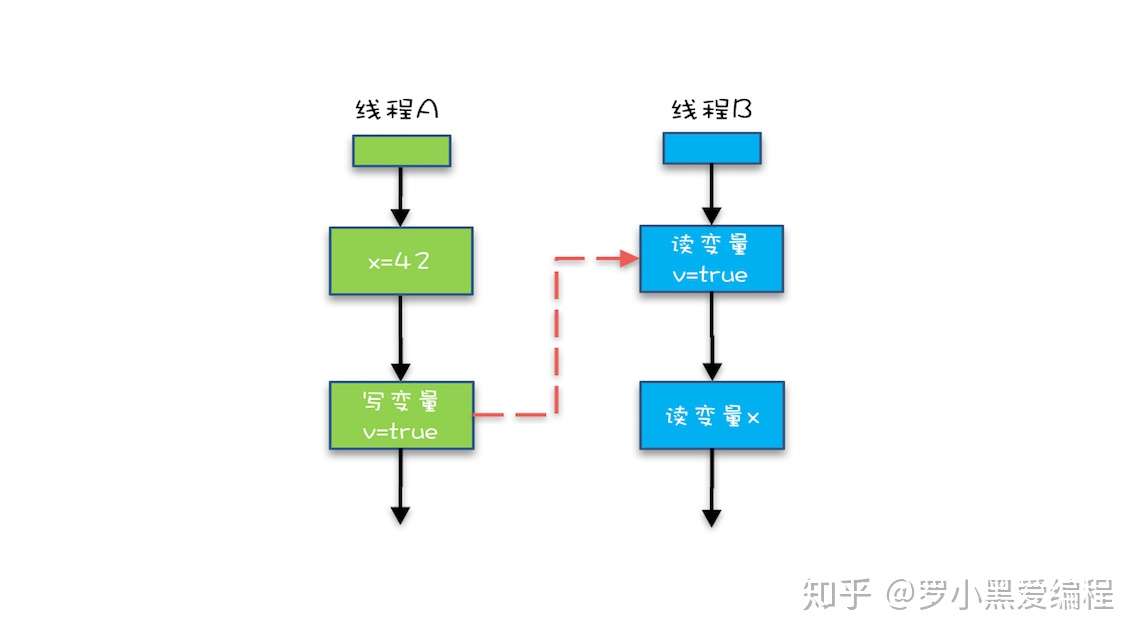
从图中,我们可以看到:
- “x=42” Happens-Before 写变量 “v=true” ,这是规则 1 的内容;
- 写变量“v=true” Happens-Before 读变量 “v=true”,这是规则 3 的内容 。
- 再根据这个传递性规则,我们得到结果:“x=42” Happens-Before 读变量“v=true”。这意味着什么呢?
如果线程 B 读到了“v=true”,那么线程 A 设置的“x=42”对线程 B 是可见的。也就是说,线程 B 能看到 “x == 42” ,有没有一种恍然大悟的感觉?这就是 1.5 版本对 volatile 语义的增强,这个增强意义重大,1.5 版本的并发工具包(java.util.concurrent)就是靠 volatile 语义来搞定可见性的。
5. start()规则
这条是关于线程启动的。它是指主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。
6. join()规则
如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
通过上面6中 happens-before 规则的组合就能为我们程序员提供一致的内存可见性。 常用的就是规则1和其他规则结合,为我们编写并发程序提供可靠的内存可见性模型。
总结
在 Java 语言里面,Happens-Before 的语义本质上是一种可见性,A Happens-Before B 意味着 A 事件对 B 事件来说是可见的,无论 A 事件和 B 事件是否发生在同一个线程里。例如 A 事件发生在线程 1 上,B 事件发生在线程 2 上,Happens-Before 规则保证线程 2 上也能看到 A 事件的发生。
JMM的设计分为两部分,一部分是面向我们程序员提供的,也就是happens-before规则,它通俗易懂的向我们程序员阐述了一个强内存模型,我们只要理解 happens-before规则,就可以编写并发安全的程序了。 另一部分是针对JVM实现的,为了尽可能少的对编译器和处理器做约束,从而提高性能,JMM在不影响程序执行结果的前提下对其不做要求,即允许优化重排序。 我们只需要关注前者就好了,也就是理解happens-before规则。毕竟我们是做程序员的,术业有专攻,能写出安全的并发程序就好了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)