


你们团队使用SpringMVC+Spring+JPA框架,快速开发了一个NB的系统,上线后客户订单跟雪花一样纷沓而来。
慢慢地,你的心情开始变差,因为客户和产品的抱怨越来越频繁,抱怨的最多的一个问题就是:系统越来越慢了。
1 常规优化
你组织团队,进行了一系列的优化。
1.1 数据表索引优化
经过初步分析,发现瓶颈在数据库。WEB服务器的CPU闲来无事,但数据库服务器的CPU使用率高居不下。
于是,请来架构组的DBA同事,监控数据库的访问,整理出那些耗时的SQL,并且进行SQL查询分析。根据分析结果,对数据表索引进行重新整理。同时也对数据库本身的参数设置进行了优化。
优化后,页面速度明显提升,客户抱怨减少,又过了一段时间的安逸日子。
1.2 多点部署+负载均衡
慢慢的,访问速度又不行了,这次是WEB服务器压力很大,数据库服务器相对空闲。经过分析,发现是系统并发用户数太多,单WEB服务器不能够支持如此众多的并发请求。
于是,请架构协助进行WEB多点部署,前端使用nginx做负载分发。这时候必须要解决的一个问题就是用户会话保持的问题。这可以有几种不同解决方案:
1、nginx实现sticky分发
因为nginx缺省没有sticky机制,可以使用ip_hash方式来代替。
2、配置Tomcat实现Session复制
3、代码使用SpringSession,利用redis实现session复制。
具体做法就不一一介绍了。其中使用SpringSession的方法,可以参考我的文章《集群环境CAS的问题及解决方案》。
2 试用当当的Sharding JDBC框架
多点部署之后,系统又运行了一段时间,期间增加了更多的WEB节点,基本能应对客户需求。慢慢的,增加WEB服务器也不能解决问题了,因为系统瓶颈又回到了数据库服务器。SQL执行时间越来越长,而且无法优化。原因也很简单,数据量太大。
单表数据已经超过几千万行,通过数据库的优化已经不能满足速度的要求。分库分表提到了日程上,必须解决。
因为使用了JPA,如果分库分表需要对数据访问层做较大的改动,工作量太大,修改的风险也太高。恰好看到当当开源了其Sharding-JDBC组件,摘抄一段介绍:
https://github.com/dangdangdotcom/sharding-jdbc
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
-
可适用于任何基于java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
-
可基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid等。
-
理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle,SQLServer,DB2等数据库的计划。
它支持JPA,可以在几乎不修改代码的情况下完成分库分表的实现。因此,选择这个框架做一次分库分表的尝试。
先做一个最简单的试用,不做分库,仅做分表。选择数据表operate_history,这个数据表记录所有的操作历史,是整个系统中数据量最大的一个数据表。
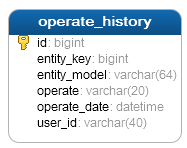
希望将这个表拆分为四个数据表,分别是 operate_history_0operate_history_1 operate_history_2 operate_history_3。数据能够分配保存到四个数据表中,降低单表的数据量。同时,为了尽量减少跨表的查询操作,决定使用字段 entity_key为分表依据,这样同一个entity对象的所有操作,将会记录在同一个数据表中。拆分后的数据表结构为:

3 实现过程
以下是针对JPA项目的修改过程。其他项目请参考官方网站的文档。
3.1 修改pom.xml增加dependency
需要添加两个jar,sharding-jdbc-core和sharding-jdbc-config-spring。
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>sharding-jdbc-config-spring</artifactId>
<version>1.3.0</version>
</dependency>
3.2 修改Spring中Database部分的配置
原Database配置
<bean id="dataSource"class="org.apache.tomcat.jdbc.pool.DataSource"destroy-method="close">
<propertyname="driverClassName"value="com.mysql.jdbc.Driver"></property>
<propertyname="url" value="jdbc:mysql://localhost:3306/sharding"></property>
<propertyname="username" value="root"></property>
<propertyname="password" value="sharding"></property>
</bean>
修改后的配置
<beanid="db-node-0"class="org.apache.tomcat.jdbc.pool.DataSource"destroy-method="close">
<property name="driverClassName"value="com.mysql.jdbc.Driver"></property>
<property name="url"value="jdbc:mysql://localhost:3306/sharding"></property>
<property name="username"value="root"></property>
<property name="password"value="sharding"></property>
</bean>
<rdb:strategyid="historyTableStrategy"
sharding-columns="entity_key"
algorithm-class="cn.codestory.sharding.SingleKeyTableShardingAlgorithm"/>
<rdb:data-sourceid="dataSource">
<rdb:sharding-ruledata-sources="db-node-0"default-data-source="db-node-0">
<rdb:table-rules>
<rdb:table-rulelogic-table="operate_history"
actual-tables="operate_history_0,operate_history_1,operate_history_2,operate_history_3"
table-strategy="historyTableStrategy" />
</rdb:table-rules>
</rdb:sharding-rule>
</rdb:data-source>
3.3 编写类SingleKeyTableShardingAlgorithm
这个类用来根据entity_key值确定使用的分表名。参考sharding提供的示例代码进行修改。核心代码如下
publicCollection<String> doInSharding(
Collection<String>availableTargetNames,
ShardingValue<Long>shardingValue) {
int targetCount = availableTargetNames.size();
Collection<String> result = newLinkedHashSet<>(targetCount);
Collection<Long> values =shardingValue.getValues();
for (Long value : values) {
for (String tableNames :availableTargetNames) {
if (tableNames.endsWith(value % targetCount+ "")) {
result.add(tableNames);
}
}
}
return result;
}
这是一个简单的实现,对entity_key进行求模,用余数确定数据表名。
3.4 修改主键生成方法
因为数据分表保存,不能使用identify方式生成数据表主键。如果主键是String类型,可以考虑使用uuid生成方法,但它查询效率会相对比较低。
如果使用long型主键,可以使用其他方式,一定要确保各个子表中的主键不重复。
3.5 历史数据的处理
根据数据分表的规则,需要对原有数据包的数据进行迁移,分别移动到四个数据表中。如果不做这一步,或者数据迁移到了错误的数据表,后续将会查询不到这些数据。
至此,对项目的修改基本完成,重新启动项目并增加operate_history数据,就会看到新添加的数据,已经根据我们的分表规则,插入到了某一个数据表中。查询的时候,能够同时查询到多个实际数据表中的数据。
4 数据分表规则的一些考虑
前面的例子,演示的是根据entity_key进行分表,也可以使用其他字段如主键进行分表。以下是我想到的一些分表规则:
-
根据主键进行分配
这种方式能够实现最平均的分配方法,每生成一条新数据,会依次保存到下一个数据表中。
-
根据用户ID进行分配
这种方式能够确保同一个用户的所有数据保存在同一个数据表中。如果经常按用户id查询数据,这是比较经济的一种做法。
-
根据某一个外键的值进行分配
前面的例子采用的就是这种方法,因为这个数据可能会经常根据这个外键进行查询。
-
根据时间进行分配
适用于一些经常按时间段进行查询的数据,将一个时间段内的数据保存在同一个数据表中。比如订单系统,缺省查询一个月之内的数据。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)