恶心的hadoop集群
具体配置:网上一堆,我说一下我的问题好了!
“完全” 分布式集群
注意地方有三点:
1.你的"master" dfs目录中的某个Id不一致,具体位置,有空我再找找。(经过我找了一下,忘了哪篇文章说过
跟${HADOOP_TMP}/dfs/name/current的VERSION有关,
我查看了一下,正常的集群
master的VERSION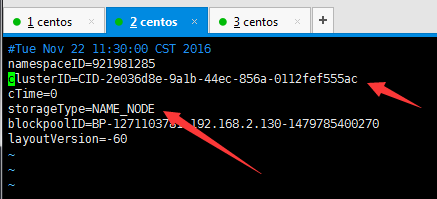
cluster1的VERSION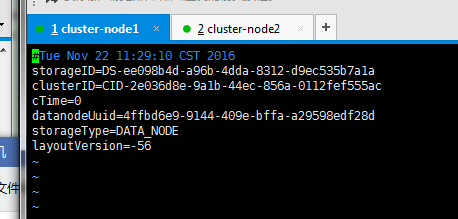
cluster2的VERSION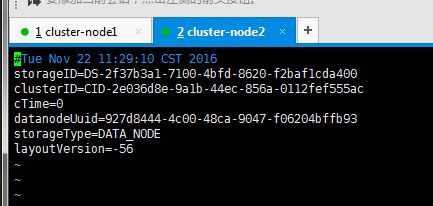
对比一下后,发现只有clusterID是一样的。
我在dfs还在启动状态,再执行bin/hdfs namenode -format,发现
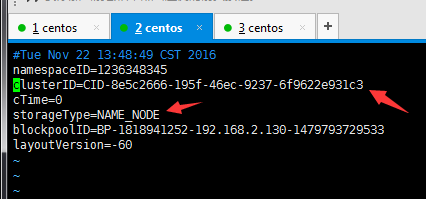
clusterID发生变化了,而集群下面的cluster的clusterID没有变化。
所以要更改nameNode的clusterID的话,记得要重启dfs,不然你自己玩泥巴。
)
(为什么不一致,这得问你了,你“bin/hdfs namenode -format” 格式化时,看到是否覆盖.
Re-format filesystem in Storage Directory /tmp/hadoop-root/dfs/name ? (Y or N)
这样的字样,你又傻傻的敲了:Y,那ID就自然变化了。
)
我简单又粗暴的方法的,直接删掉hadoop中的数据。(反正我自己玩而已)
如果你的core-site.xml和hdfs-site.xml,没有配置数据目录路径的话,
数据都在/tmp/hadoop-root底下,自己看着办!
(如果要删的话,最好把连同的cluster“集群数据”一起删除,不然在http://master-node:50070/dfshealth.html#tab-datanode是无法看到集群的cluster的datanode)
然后,
再./sbin/start-dfs.sh ,如果能顺利启动的话,就在master,cluster分别 查看hdfs的的目录
bin/hdfs dfs -ls / (如果都没有问题的话。再去看http://master-node:50070/dfshealth.html#tab-datanode是无法看到集群的cluster的datanode)
2./etc/hosts
假如配置错了
会出现
#127.0.0.1 master-node
#::1 master-node
类似的。
特别注意你的master的hosts最好与你cluster一样!
其实看 格式化时的日志,都能知道集群子节点是否成功
bin/hdfs namenode -format
看这句SHUTDOWN_MSG: Shutting down NameNode at "你的masterIP"
3.你的虚拟机问题。如果你的cluster是clone “master的”,也许能集群起来的。
但是如果你的cluster是clone “cluster”,不知道你能否启动,反正我是集群不了的。(因为我有一个是clone “master” ,另一个是clone "cluster",也不知道是否clone操作出问题,反正我的clone "cluster"死活集群不到,一气之下,删了clone "cluster",重新clone “master”, 然后,“就可以”)
至于网上的很多篇拼命让你“格式化namenode”的文章,只能说一句:我操。
(其实我是因为在看哪里都没有log相关信息,才搜索"hadoop2x Call From",然而
才看http://blog.csdn.net/wqetfg/article/details/50715541,才能解决
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号