Notes | Bert系列的预训练模型
参考:
ELMo Embeddings from Language Models
BERT Bidirectional Encoder Representations from Transformers
ERNIE Enhanced Representation through Knowledge Integration
Grover Generating aRticles by Only Viewing mEtadata Records
Big Bird Big Bird: Transformers for Longer Sequences
共同点:
contxtualized word embedding (base model):
- LSTM
- Self-attention layers
- Tree-based models (注重文法,但一般表现不佳,只有在文法结构非常清晰严谨的情况下表现好)
模型变小
- Distill BERT
- Tiny BERT
- Mobile BERT
- Q8BERT
- ALBERT
小模型方法:
Network Compression
- Network Pruning 剪枝
- Knowledge Distillation 知识蒸馏
- Parameter Quantization 参数量化
- Architecture Design 结构设计
网络结构改进
Transformer-XL (XLNet使用):跨块级结构的attention,不仅局限于max-len(512)的长度
Reformer、Longformer、Big Bird:减少self-attention的复杂度
训练方法
Predict Next Token (self-supervised):
language models:
LSTM:
- ELMo (双向LSTM)
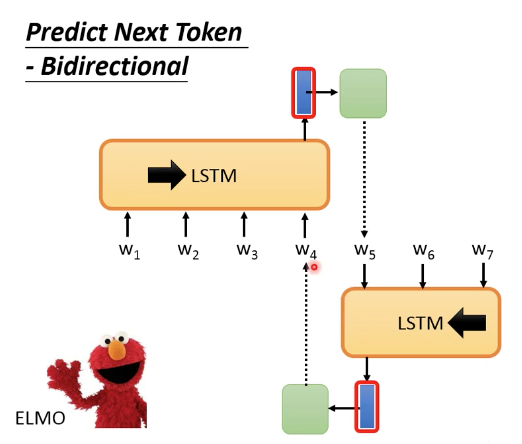
不是真正的双向,预测一个token时,不是真正地看到两边的内容,而是两个单向LSTM能力的拼接。
- Universal Language Model Fine-tuning (ULMFiT)
Self-attention:
这里可以attention的位置要有约束(目标是预测下一个token,不能看到未来的token答案)
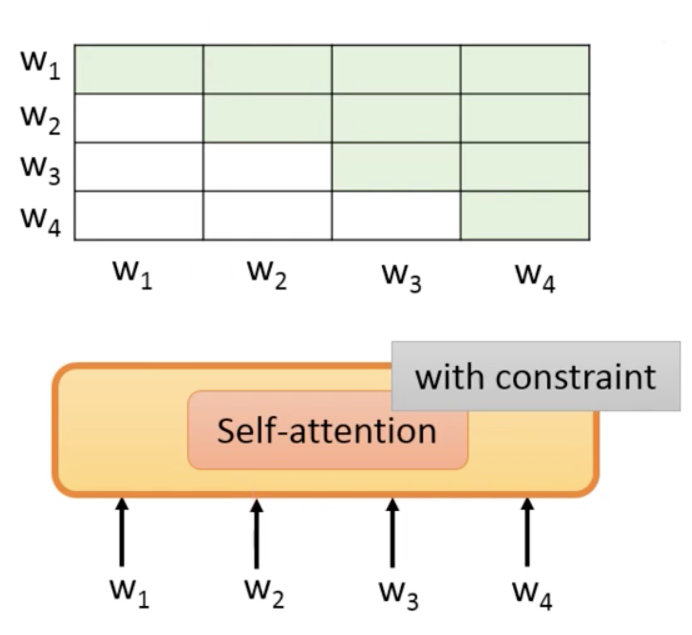
绿色部分是可以attention的部分。
- GPT系列
- Megatron
- BERT (mask机制,用transformer作为encoder,预测某一个masked token时,可以看到上下文信息,类似CBOW的思想)
Span Boundary Objective (SBO)
SpanBERT提出,用mask的一个完整span的左右边界来预测span内指定的某一个masked token。

预测token是否被mask
ELECTRA: Efficiently Learning an Encoder thtat Classifies Token Replacements Accurately

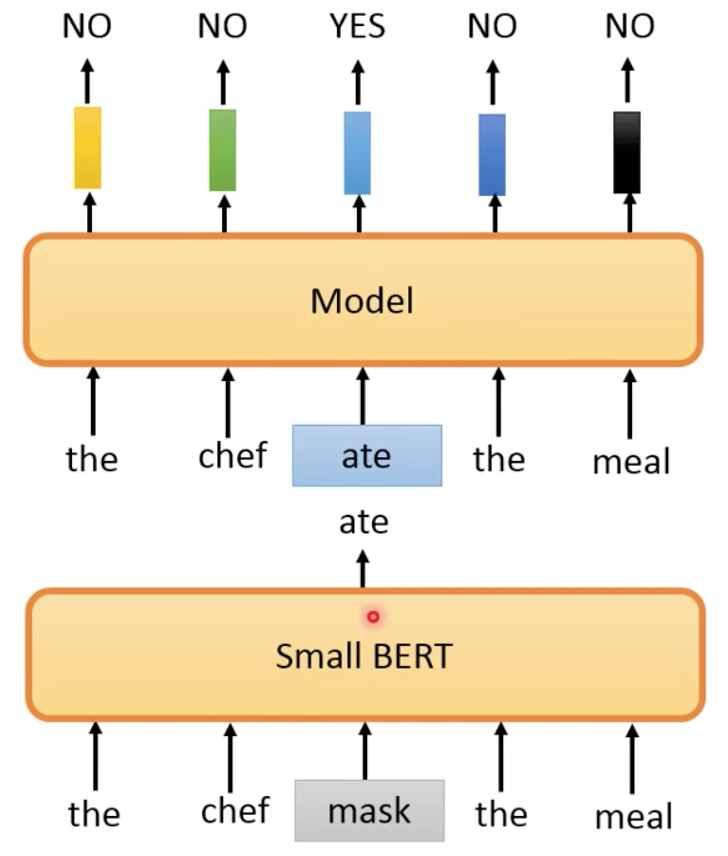
预测是否被是被小BERT置换过的词:
其中,小BERT模型随机选一个token进行mask,small BERT为这个masked token还原成它认为对的词。
NSP 预测是否是下一个句子
BERT:Next sentence prediction
RoBERTa 指出该预测方法没有用。
SOP Sentence order prediction
ALBERT中使用。
structBERT (Alice) 有用到类似的 (将 NSP 与 SOP 结合)
Mask机制改进
whole word masking(WWM) 整个词的mask

ERNIE: Phrase-level & Entity-level 短语&命名实体级别
SpanBert: 盖住n个token
seq2seq model
破坏输入进行预测:
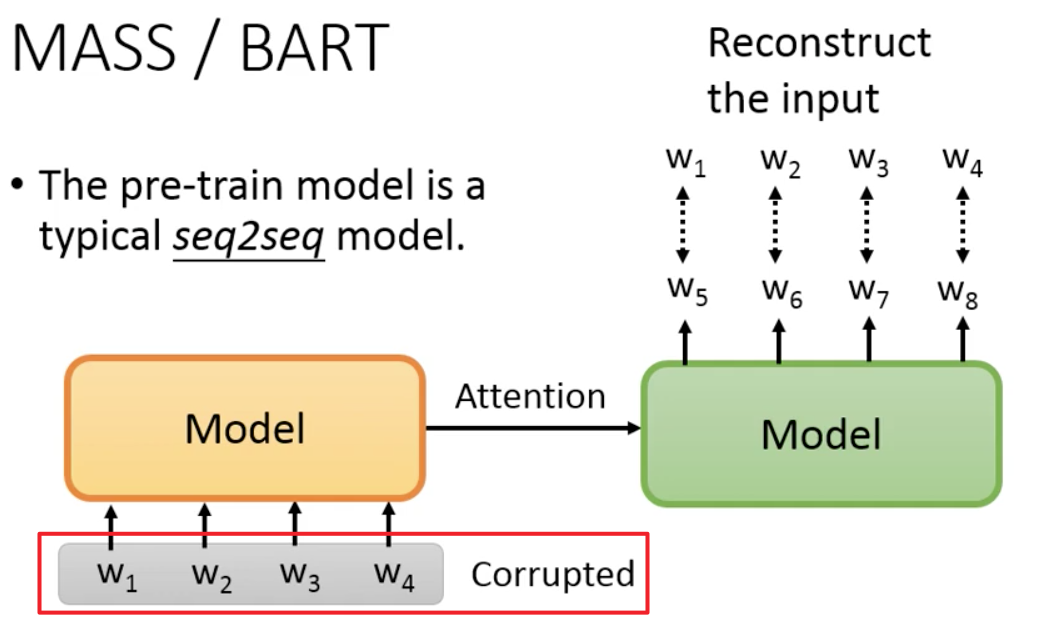
MASS: MAsked Sequence to Sequence pre-training(下图红框)
BART: Bidirectional and Auto-Regressive Transformers(下图蓝框)

BART给出了更多破坏输入进行预测的方式。
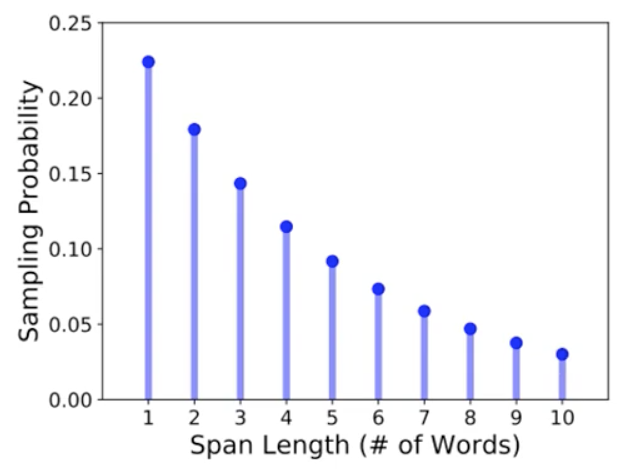
结论:Permutation 和 Rotation的效果不好;Text Infilling的效果好。
UniLM:模型可以是encoder decoder seq2seq的任意模型
同时进行多种训练:
- Bidirectional LM
- Left-to-Right LM
- Seq-to-Seq LM
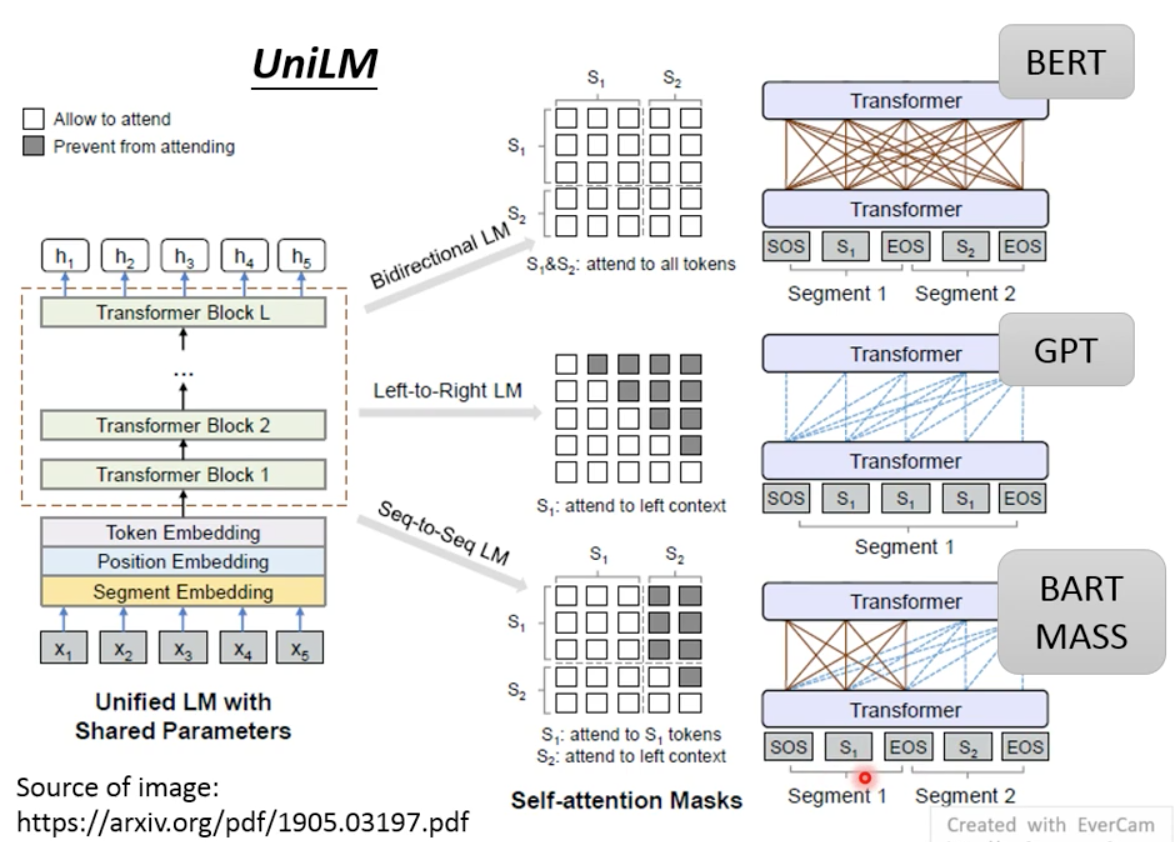
预训练方法对比:
Transfer Text-to-Text Transformer (T5) ,其中的训练集为C4。
加入知识:
清华的ERNIE。

