推荐系统中的模型整理 (rank)
DeepFM
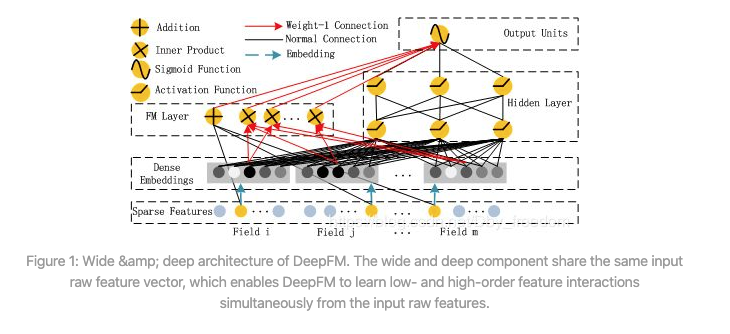
和Wide & Deep的模型类似,DeepFM模型同样由浅层模型和深层模型联合训练得到。不同点主要有以下两点:
- wide模型部分由LR替换为FM。FM模型具有自动学习交叉特征的能力,避免了原始Wide & Deep模型中浅层部分人工特征工程的工作。
- 共享原始输入特征。DeepFM模型的原始特征将作为FM和Deep模型部分的共同输入,保证模型特征的准确与一致。
文中通过大量实验证明,DeepFM模型的AUC和Logloss都优于目前的最好效果。效率上,DeepFM和目前最优的效果的深度模型相当。
主要做法:
- FM Component + Deep Component。FM提取低阶组合特征,Deep提取高阶组合特征。但是和Wide&Deep不同的是,DeepFM是端到端的训练,不需要人工特征工程。
- 共享feature embedding。FM和Deep共享输入和
feature embedding不但使得训练更快,而且使得训练更加准确。相比之下,Wide&Deep中,input vector非常大,里面包含了大量的人工设计的pairwise组合特征,增加了他的计算复杂度。
为了同时利用low-order和high-order特征,DeepFM包含FM和DNN两部分,结果可表示为:
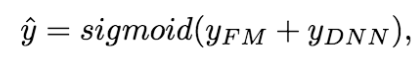
FM 部分
FM通过隐向量latent vector做内积来表示组合特征,从理论上解决了低阶和高阶组合特征提取的问题。但是实际应用中受限于计算复杂度,一般也就只考虑到2阶交叉特征。
后面又进行了改进,提出了FFM,增加了Field的概念。
FM部分的输出由两部分组成:一个 Addition Unit,多个 内积单元。
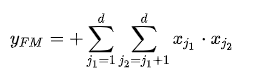
这里的d是输入one-hot之后的维度,我们一般称之为 `feature_size`。对应的是one-hot之前的特征维度,我们称之为 `field_size`。
Addition Unit 反映的是1阶的特征。内积单元反映的是2阶的组合特征对于预测结果的影响。
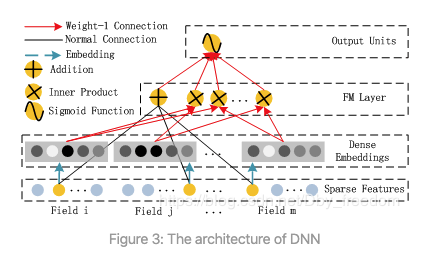
Deep Component
Deep Component架构图:
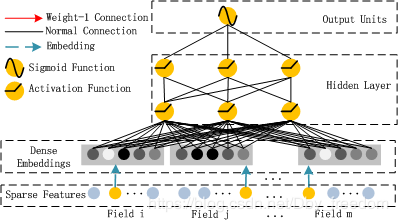
Deep Component是用来学习高阶组合特征的。网络里面黑色的线是全连接层,参数需要神经网络去学习。
由于CTR或推荐系统的数据one-hot之后特别稀疏,如果直接放入到DNN中,参数非常多,我们没有这么多的数据去训练这样一个网络。所以增加了一个Embedding层,用于降低纬度。
这里继续补充下Embedding层,两个特点:
1. 尽管输入的长度不同,但是映射后长度都是相同的.`embedding_size(k)`
2. embedding层的参数其实是全连接的Weights,是通过神经网络自己学习到的。
Embedding层的架构图:

embedding layer表示为:
其中 ei 是第 i个 filed 的 embedding,m 是 filed 数量; a(0) 传递给deep part,前馈过程如下:
其中 l是层深度,最外层是激活函数, a b w分别是第l层的输出,权重和偏置。
然后得到dense real-value 特征矢量,最后被送到sigmoid函数做CTR预测:
其中 |H| 是隐藏层层数 值得注意的是:FM模块和Deep模块是共享feature embedding的(也就是V)。
好处:
1. 模型可以从最原始的特征中,同时学习低阶和高阶组合特征 ;
2. 不再需要人工特征工程。Wide&Deep中低阶组合特征就是同过特征工程得到的。
DeepFM优势/优点:
- 不需要预训练FM得到隐向量
- 不需要人工特征工程
- 能同时学习低阶和高阶的组合特征
- FM模块和Deep模块共享Feature Embedding部分,可以更快更精确地训练

